Neste documento, você verá as causas comuns de desligamentos e reinicializações inesperados de instâncias de máquina virtual (VM, na sigla em inglês) e como evitá-los.
Desligamentos e reinicializações da VM podem ser causados por eventos do sistema ou atividades do administrador. Desligamentos e reinicializações causados por eventos do sistema são gerados pelos sistemas do Google ou pelo sistema operacional da VM. Os encerramentos e reinicializações causados por atividades do administrador são gerados por uma chamada de API gerada pelo usuário ou pela conta de serviço. Todos as desligamentos e reinicializações são registrados, exceto as reinicializações que são iniciadas de dentro da VM.
Antes de começar
-
Configure a autenticação, caso ainda não tenha feito isso.
A autenticação é
o processo de verificação da sua identidade para acesso a serviços e APIs do Google Cloud.
Para executar códigos ou amostras de um ambiente de desenvolvimento local, autentique-se no
Compute Engine da seguinte maneira.
Selecione a guia para como planeja usar as amostras nesta página:
Console
Quando você usa o console do Google Cloud para acessar os serviços e as APIs do Google Cloud, não é necessário configurar a autenticação.
gcloud
-
Instale a Google Cloud CLI e inicialize-a executando o seguinte comando:
gcloud init
- Defina uma região e uma zona padrão.
-
Como diagnosticar desligamentos e reinicializações da VM
Para diagnosticar a causa do desligamento ou da reinicialização espontânea de uma VM, é necessário consultar os registros da VM. Para identificar rapidamente a causa de futuros desligamentos ou reinicializações da VM,
crie um painel que contenha os registros. Depois de consultar os registros, revise os campos method e principalEmail para determinar qual evento e qual usuário ou serviço iniciou o encerramento ou a reinicialização.
Como consultar o Cloud Audit Logging
Consulte o Cloud Audit Logging para ver uma lista de eventos do sistema e atividades do administrador que podem ter causado o desligamento ou a reinicialização.
Console
No console do Google Cloud, acesse a página do Explorador de registros.
No campo Consulta, digite a seguinte consulta:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Substitua
VM_NAMEpelo nome da VM que desligou ou foi reiniciada.Se o evento que você está procurando aconteceu há mais de uma hora, defina um período personalizado clicando no símbolo do relógio e inserindo um intervalo personalizado.
Clique em Run query. Os resultados são exibidos na seção Resultados da consulta.
Clique na seta de expansão ao lado de cada resultado para mostrar informações detalhadas.
Consulte Como analisar os registros de auditoria do Cloud para saber mais sobre os campos
methodeprincipalEmailassociados a desligamentos e reinicializações e o que é possível fazer para evitá-los.
gcloud
Visualize os registros de auditoria do Cloud usando o comando
gcloud logging read:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Substitua:
TIME: o intervalo de tempo que você quer consultar. Por exemplo,1hconsulta entradas de registro na última hora. Para informações sobre formatos de data e hora, consulte Data e hora no gcloud.VM_NAME: o nome da VM que foi desligada ou reinicializada.
Os resultados serão exibidos.
Consulte Como analisar os registros de auditoria do Cloud para saber mais sobre os campos
methodeprincipalEmailassociados a desligamentos e reinicializações e o que é possível fazer para evitá-los.
Como analisar o Cloud Audit Logging
Revise os campos method e principalEmail do Cloud Audit Logging para
determinar o motivo pelo qual a VM foi desligada ou reinicializada.
Revise os campos
methoddo Cloud Audit Logging e compare-os com os métodos listados na tabela a seguir.Método Tipo de desligamento Descrição compute.instances.repair.recreateInstanceEvento do sistema Se a VM pertence a um grupo gerenciado de instâncias (MIG, na sigla em inglês), o MIG recriará a VM se o estado da VM mudar de
RUNNINGe o MIG não iniciou a alteração no estado.As alterações do estado da instância que não são iniciadas pelo MIG incluem:
- Falhas de hardware.
- Encerrar uma instância preemptiva.
- Eventos de manutenção de infraestrutura quando a instância de VM não está definida para migração em tempo real.
- Como excluir uma instância do MIG usando um dos seguintes métodos:
- O método da API
instances.delete. - O comando
gcloud compute instances delete
- O método da API
compute.instances.hostErrorEvento do sistema Um erro de host (
compute.instances.hostError) significa que houve um problema de hardware ou software na máquina física que hospeda a VM que causou a falha da VM. Um erro de host que envolve falha total de hardware ou outros problemas de hardware pode impedir a migração em tempo real da VM. Se a VM estiver configurada para reiniciar automaticamente, o que é a configuração padrão, o Google a reiniciará, normalmente em três minutos a partir do momento em que o erro foi detectado. Dependendo do problema, a reinicialização pode levar até 5,5 minutos.VMs com discos SSD locais
Se ocorrer um erro de host em uma VM que tenha um ou mais discos SSD locais anexados, o Compute Engine tentará se reconectar à VM e preservar o SSD local dados. Enquanto o Compute Engine recupera a VM e o disco SSD local, o sistema host e o disco subjacente não respondem.
É possível especificar quanto tempo o Compute Engine gasta tentando recuperar dados do SSD local definindo o tempo limite de recuperação do SSD local.
Para mais informações sobre como os discos SSD locais se comportam quando ocorre um erro de host, consulte Persistência de dados do SSD local.
VMs que não respondem
Ás vezes, uma VM pode não responder antes que um erro do host seja detectado. É possível reduzir o tempo que o Compute Engine aguarda para reiniciar ou encerrar a VM definindo o tempo limite da recuperação do erro do host (Visualização). Para mais informações, consulte Definir políticas de disponibilidade.
Falhas físicas de hardware e software podem acontecer ocasionalmente, mas são raras. Para proteger aplicativos e serviços contra esses eventos de sistema potencialmente prejudiciais, analise os seguintes recursos:
- Como projetar sistemas robustos
- Padrões para apps escalonáveis e resilientes
- Como criar grupos de instâncias gerenciadas
O Google também oferece serviços gerenciados, como o App Engine e o ambiente flexível do App Engine.
compute.instances.automaticRestartEvento do sistema Esse evento ocorrerá após um evento
hostErrorouterminateOnHostMaintenancese a política de manutenção do hostautomaticRestartda VM estiver definida comotrue. Nos registros, uma entradahostErrorouterminateOnHostMaintenanceprecede esse registro.Se você quiser alterar a política de manutenção do host da VM, consulte Como atualizar opções para uma instância.
compute.instances.guestTerminateEvento do sistema O sistema operacional da VM iniciou o desligamento. compute.instances.terminateOnHostMaintenanceEvento do sistema Se você definir a política de manutenção do host
onHostMaintenanceda VM comoTERMINATE, o Compute Engine interrompe a VM quando há um evento de manutenção em que o Google precise mover a VM para outro host.Se você quiser alterar a política
onHostMaintenanceda VM, consulte Como atualizar opções de uma instância.compute.instances.preemptedEvento do sistema O Compute Engine forçou a interrupção da VM do Spot ou da VM preemptiva legada:
- Quando o Compute Engine força a interrupção de uma VM do Spot, ele para ou exclui a VM do Spot com base na ação de encerramento. As VMs do Spot não têm tempo de execução máximo.
- Quando o Compute Engine força a interrupção de uma VM preemptiva, ele para a VM após um tempo de execução máximo de 24 horas. Para evitar essas limitações, use VMs do Spot.
As VMs do Spot e as VMs preemptivas são capacidade extra do Compute Engine. Por isso, o Compute Engine pode encerrá-las sempre que essa capacidade for necessária em outro lugar. É possível reduzir os efeitos da preempção seguindo as práticas recomendadas. Como alternativa, se você precisar de VMs com ambientes de execução controlados pelo usuário, crie VMs padrão.
compute.instances.stopAtividade administrativa Um usuário ou conta de serviço interrompeu a VM.
Passe para a próxima etapa para identificar a conta de serviço ou o usuário que interrompeu a VM. Para mais informações sobre como reiniciar a VM, consulte Como reiniciar uma instância interrompida.
compute.instances.deleteAtividade administrativa Um usuário ou conta de serviço excluiu a VM.
Passe para a próxima etapa para identificar a conta de serviço ou o usuário que excluiu a VM. Para informações sobre como criar uma nova VM, consulte Como criar e iniciar uma VM.
compute.instances.insertAtividade administrativa Um usuário ou uma conta de serviço criou sua VM.
Passe para a próxima etapa para identificar a conta de serviço ou o usuário que criou a VM. Para informações sobre como criar uma nova VM, consulte Como criar e iniciar uma VM.
compute.instances.resetAtividade administrativa Um usuário ou uma conta de serviço redefine a VM.
Passe para a próxima etapa para identificar a conta de serviço ou o usuário que interrompeu a VM.
Revise os campos
principalEmaildo Cloud Audit Logging para identificar o usuário ou serviço que iniciou o desligamento ou a reinicialização. A tabela a seguir inclui serviços comuns gerenciados pelo Google que iniciam reinicializações ou desligamentos.E-mail Descrição system@google.comUm evento do sistema causou o desligamento ou reinicialização. project-number@cloudservices.gserviceaccount.comUma conta de serviço gerenciada pelo Google iniciou o desligamento.
Para determinar de qual projeto o serviço iniciou o desligamento, revise o
project-numberda conta de serviço.Para determinar qual serviço do Google fez a solicitação, revise o campo
protoPayload.requestMetadata.callerSuppliedUserAgent.Se um usuário tiver acionado o encerramento ou a reinicialização, o endereço de e-mail dele aparecerá no campo
principalEmail. Por exemplo,cloudysanfrancisco@gmail.com.Os administradores podem impedir que os usuários alterem o estado das VMs do projeto alterando as permissões do Identity and Access Management nas contas de usuário. Saiba mais em Como conceder, alterar e revogar o acesso a recursos.
Monitorar eventos do ciclo de vida da VM
É possível monitorar eventos de ciclo de vida de VMs (incluindo desligamentos, reinicializações e erros do host) criando um painel do Cloud Monitoring.
Esse painel permite visualizar eventos do sistema e atividades do administrador, que são descritos em mais detalhes na seção Como analisar registros de auditoria deste documento.
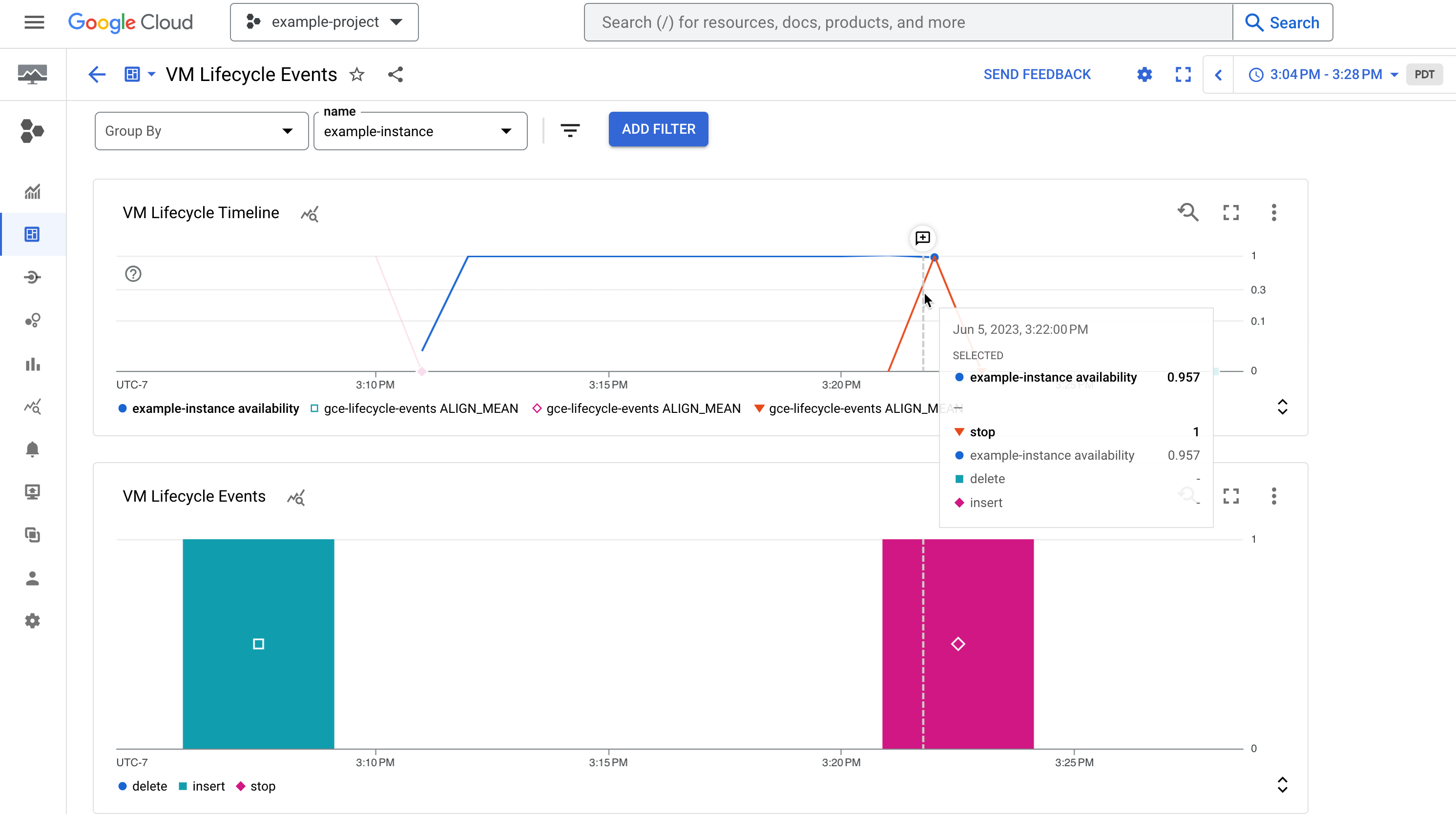 Figura 1. Um exemplo de painel que mostra a disponibilidade de uma instância e os eventos de ciclo de vida dela, como uma instância interrompida.
Figura 1. Um exemplo de painel que mostra a disponibilidade de uma instância e os eventos de ciclo de vida dela, como uma instância interrompida.
Criar métrica com base em registros
Para capturar eventos de ciclo de vida da VM, crie uma métrica com base em registros definida pelo usuário. Essa métrica usa registros de auditoria para registrar quantas vezes ocorreu um determinado evento de ciclo de vida da VM.
Para receber as permissões necessárias para criar a métrica,
peça ao administrador para conceder a você o
Gravador de registros (roles/logging.logWriter) do IAM um papel no projeto.
Para mais informações sobre como conceder papéis, consulte Gerenciar acesso.
Também é possível conseguir as permissões necessárias com papéis personalizados ou outros papéis predefinidos.
Para criar uma métrica com base em registros definida pelo usuário, faça o seguinte:
No console do Google Cloud, acesse a página Métricas com base em registros.
Clique em Criar métrica.
Na seção Tipo de métrica, faça o seguinte:
- Selecione
Counter. - Deixe Distribuição com a configuração padrão desmarcada.
Na seção Detalhes, digite o seguinte:
- Nome da métrica com base em registros:
vm-lifecycle-events. Use esse nome exato para que o painel funcione corretamente. - Descrição (opcional): insira uma descrição para a métrica.
- Unidades:
1
Na seção Seleção de filtros, especifique o seguinte:
- No menu suspenso Selecionar escopo do registro, escolha: Registros do projeto.
- Em Criar filtro, digite:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
Na seção Marcadores, clique em Adicionar marcador.
Especifique o seguinte:
- Nome do rótulo:
method - Tipo de rótulo:
STRING - Nome do campo:
protoPayload.methodName - Expressão regular:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Nome do rótulo:
Clique em Concluir.
Clique em Criar métrica.
Usar o painel
Nenhum dado vai aparecer no painel até que uma VM apresente um evento do sistema ou uma atividade do administrador. Para testar se o painel funciona, execute uma atividade de administrador, como uma operação stop e start:
- Execute uma operação
stopestartem qualquer VM ou crie uma nova para fins de teste.
Para receber as permissões necessárias para usar o painel, peça ao administrador para conceder a você o Leitor do painel do Monitoring (roles/monitoring.dashboardViewer) papel do IAM no projeto.
Para mais informações sobre como conceder papéis, consulte Gerenciar acesso.
Também é possível conseguir as permissões necessárias com papéis personalizados ou outros papéis predefinidos.
Abra Painéis no console do Google Cloud.
Na guia Lista de painéis, abra o painel do
GCE VM Lifecycle Events Monitoring.Selecione a VM no menu suspenso Nome.
Restrinja a série temporal a um período relevante.
Para conhecer outras formas de filtrar o painel, consulte Adicionar um filtro temporário.
O painel contém dois gráficos que exibem uma linha do tempo de eventos do sistema e atividades de administração que ocorrem em uma VM:
O gráfico Cronograma do ciclo de vida da VM mostra o seguinte:
- A métrica
compute.googleapis.com/instance/uptimeque indica se a VM estava sendo executada em um determinado momento, em que 1 está ativo e 0 está inativo. Essa métrica reflete a disponibilidade como resultado da atividade do usuário e de eventos do sistema, e não é uma indicação do SLA do Compute Engine. - A métrica com base em registros
vm-lifecycle-eventspara contar o número de ações do ciclo de vida, comostopoustart, que foram realizadas na VM em um determinado momento
- A métrica
O gráfico de eventos mostra a mesma métrica com base em registros do
vm-lifecycle-events, mas em uma visualização ampliada para facilitar a leitura. Embora os eixos X estejam alinhados, as cores não são sincronizadas entre os dois gráficos.
Investigação em massa do encerramento da VM entre projetos
O Compute Engine pode encerrar várias VMs conectadas a um projeto host da VPC compartilhada se o faturamento do projeto host estiver inativo ou desativado.
Para determinar se as VMs foram encerradas por uma solicitação de encerramento em massa, procure as operações de parada iniciadas por cloud-cluster-manager@prod.google.com.
Iniciar uma instância afetada retorna um erro semelhante ao seguinte:
Starting instance(s) INSTANCE_NAME...failed.
ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.
Para resolver esse problema, faça o seguinte:
Identifique a VPC compartilhada usada pelas VMs com o comando
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
O resultado será assim:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Verifique no projeto host da VPC compartilhada se o faturamento tiver sido desativado.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Se aplicável, ative o faturamento no projeto host.
Para ajudar a evitar que esse problema ocorra novamente, leia Proteger o vínculo entre um projeto e a conta de faturamento.