このドキュメントでは、外部アプリケーション ロードバランサまたは内部アプリケーション ロードバランサの処理能力に基づいてマネージド インスタンス グループ(MIG)をスケールする方法について説明します。この方法では、グループが最大能力のうちの一定の割合(この値は構成可能)に達したことをロードバランサが示したときに、自動スケーリングによって VM インスタンスがグループに追加または削除されます。最大能力は、バックエンド インスタンス グループの、選択されている分散モードのターゲット容量によって定義されます。
また、CPU 使用率またはモニタリング指標に基づいて MIG をスケーリングすることもできます。
制限事項
外部アプリケーション ロードバランサと内部アプリケーション ロードバランサの処理能力に基づいて、マネージド インスタンス グループを自動スケーリングできます。他のタイプのロードバランサはサポートされていません。
始める前に
- オートスケーラーの制限事項を確認します。
- オートスケーラーの基礎知識を確認します。
-
まだ設定していない場合は、認証を設定します。認証では、 Google Cloud サービスと API にアクセスするための ID が確認されます。ローカル開発環境からコードまたはサンプルを実行するには、次のいずれかのオプションを選択して Compute Engine に対する認証を行います。
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Google Cloud CLI をインストールします。 インストール後、次のコマンドを実行して Google Cloud CLI を初期化します。
gcloud init外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
- Set a default region and zone.
REST
このページの REST API サンプルをローカル開発環境で使用するには、gcloud CLI に指定した認証情報を使用します。
Google Cloud CLI をインストールします。 インストール後、次のコマンドを実行して Google Cloud CLI を初期化します。
gcloud init外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
詳細については、 Google Cloud 認証ドキュメントの REST を使用して認証するをご覧ください。
HTTP(S) ロード バランシング処理能力に基づくスケーリング
Compute Engine ではインスタンス グループ内でのロード バランシングのサポートが提供されています。インスタンスの負荷に基づいてスケーリングするオートスケーラーをセットアップすることによって、自動スケーリングを負荷分散と組み合わせて使用できます。
外部または内部の HTTP(S)ロードバランサは、URL マップに従ってバックエンド サービスにリクエストを分散します。ロードバランサには 1 つまたは複数のバックエンド サービスを接続できます。それぞれのバックエンド サービスが、インスタンス グループまたはネットワーク エンドポイント グループ(NEG)バックエンドをサポートします。バックエンドがインスタンス グループである場合、HTTP(S)ロードバランサでは
UTILIZATIONとRATEの 2 つの分散モードを使用できます。UTILIZATIONでは、インスタンス グループ内のインスタンスの平均バックエンド使用率の最大ターゲットを指定できます。RATEでは、インスタンス単位またはグループ単位での 1 秒あたりのリクエスト数のターゲット数を指定する必要があります(グループ全体の最大レートを指定できるのは、ゾーン インスタンス グループのみです。リージョン マネージド インスタンス グループでは、グループ単位の最大レートを定義できません)。分散モードとターゲット容量を指定することで、バックエンド VM が最大容量に達したと Google Cloud が判断する条件を定義します。 Google Cloud は、容量が残っている正常な VM にトラフィックを送信しようとします。すべての VM がすでに容量に達すると、ターゲット使用率またはレートの超過が発生します。
HTTP(S)ロードバランサのインスタンス グループ バックエンドにオートスケーラーを接続すると、オートスケーラーはマネージド インスタンス グループをスケーリングしてロードバランスの処理能力の割合を維持します。
たとえば、マネージド インスタンス グループの負荷分散処理能力が、インスタンスあたり 100 RPS であると仮定します。HTTP(S) ロード バランシング ポリシーを使用するオートスケーラーを作成し、0.8 つまり 80% のターゲット使用率レベルを維持するように設定している場合、オートスケーラーは、マネージド インスタンス グループからインスタンスを追加または削除して、80% の処理能力つまりインスタンスあたり 80 RPS を維持します。
次の図は、オートスケーラーとマネージド インスタンス グループおよびバックエンド サービスとのやり取りを示しています。
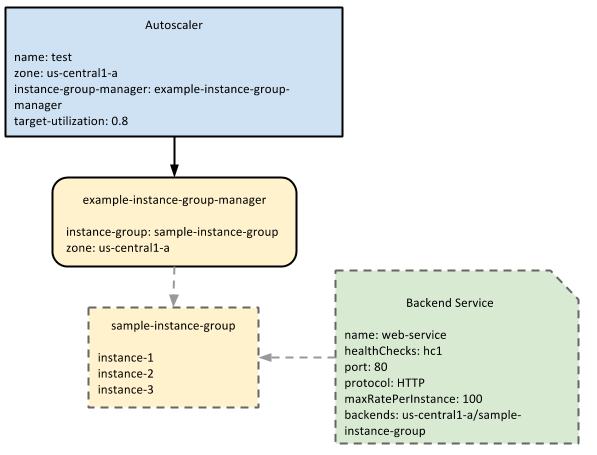
オートスケーラーは、バックエンド サービスで定義されている、マネージド インスタンス グループの処理能力を監視し、ターゲット使用率に基づいてスケーリングします。この例では、処理能力は maxRatePerInstanceの値で測定されています。適用可能な負荷分散構成
負荷分散処理能力は 3 つのうちのいずれかを設定できます。バックエンドを最初に作成する際に、最大バックエンド使用率、インスタンスごとの 1 秒あたりの最大リクエスト数、グループ全体での 1 秒あたりの最大リクエスト数から選択できます。最大バックエンド使用率と秒 / インスタンスあたりの最大リクエスト数の値は、インスタンスの追加または削除によって制御できるため、オートスケーラーではこれらの設定のみを使用できます。たとえば、あるバックエンドがインスタンスにつき毎秒 10 個のリクエストを処理するように設定し、その能力の 80% を維持するようにオートスケーラーを構成している場合、インスタンス / 秒あたりのリクエスト数が変化するとオートスケーラーはインスタンスを追加または削除できます。
グループあたりの最大リクエスト数の設定はインスタンス グループ内のインスタンス数とは無関係であるため、オートスケーラーではこの設定を使用できません。ロードバランサは、グループ内のインスタンス数に関係なく、グループあたりの最大数のリクエストをそのインスタンス グループに送信し続けます。
たとえば、グループあたり 1 秒あたりの最大 100 個のリクエスト数を処理するようにバックエンドを設定している場合、そのグループのインスタンス数が 2 であっても 100 であっても、ロードバランサはそのグループに 1 秒あたり 100 個のリクエストを送信します。この値は調整できないため、自動スケーリングでは、グループごとに 1 秒あたりの最大リクエスト数を使用するロード バランシング構成を使用できません。
負荷分散処理能力に基づく自動スケーリングの有効化
コンソール
- Google Cloud コンソールの [インスタンス グループ] ページに移動します。
- インスタンス グループがある場合は、それを選択して [編集] をクリックします。インスタンス グループがない場合は、[インスタンス グループを作成] をクリックします。
- [グループ サイズと自動スケーリング] をクリックして、セクションを開きます。
- [自動スケーリング モード] リストで、[オン: グループに対してインスタンスを追加および削除します] が選択されていることを確認します。
- このグループでオートスケーラーが作成するインスタンスの数の最小値と最大値を指定します。
- [自動スケーリング シグナル] セクションで、[シグナルを追加] をクリックします。
- [シグナルタイプ] を [HTTP ロード バランシングの使用率] に設定します。
[HTTP ロード バランシング使用率の目標値] にパーセンテージで値を入力します。たとえば、HTTP 負荷分散使用率 60% を指定するには「
60」と入力します。初期化期間フィールドを使用して初期化期間を設定できます。これにより、アプリケーションの初期化に要する時間をオートスケーラーに指示できます。正確な初期化期間を指定することで、オートスケーラーによる判断が向上します。たとえば、スケールアウト時、オートスケーラーは初期化中の VM のデータを無視します。初期化中の VM はアプリケーションの通常の使用状況を表していない可能性があるためです。デフォルトの初期化期間は 60 秒です。
変更を保存します。
gcloud
処理能力に基づいてスケーリングするオートスケーラーを有効にするには、
set-autoscalingサブコマンドを使用します。たとえば次のコマンドでは、対象のマネージド インスタンス グループが処理能力の 60% を維持するようにスケーリングするオートスケーラーが作成されます。オートスケーラーを作成する場合は、--target-load-balancing-utilizationパラメータだけではなく、--max-num-replicasパラメータも必要です。gcloud compute instance-groups managed set-autoscaling example-managed-instance-group \ --max-num-replicas 20 \ --target-load-balancing-utilization 0.6 \ --cool-down-period 90--cool-down-periodフラグを使用して初期化期間を設定できます。これにより、アプリケーションの初期化に要する時間をオートスケーラーに指定できます。正確な初期化期間を指定することで、オートスケーラーによる判断が向上します。たとえば、スケールアウト時、オートスケーラーは初期化中の VM のデータを無視します。初期化中の VM はアプリケーションの通常の使用状況を表していない可能性があるためです。デフォルトの初期化期間は 60 秒です。instance-groups managed describeサブコマンドを使用して、オートスケーラーが正常に作成されたことを確認できます。gcloud compute instance-groups managed describe example-managed-instance-group
利用可能な
gcloudコマンドとフラグの一覧については、gcloudリファレンスをご覧ください。REST
オートスケーラーを作成するには、
autoscalers.insertメソッド(ゾーン MIG の場合)またはregionAutoscalers.insertメソッド(リージョン MIG の場合)を使用します。次の例では、ゾーン MIG にオートスケーラーを作成します。
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/autoscalers/
リクエスト本文には
nameフィールド、targetフィールド、autoscalingPolicyフィールドを含める必要があります。autoscalingPolicyでloadBalancingUtilizationを定義する必要があります。coolDownPeriodSecフィールドを使用して初期化期間を設定できます。これにより、アプリケーションの初期化に要する時間をオートスケーラーに指示できます。正確な初期化期間を指定することで、オートスケーラーによる判断が向上します。たとえば、スケールアウト時、オートスケーラーは初期化中の VM のデータを無視します。初期化中の VM はアプリケーションの通常の使用状況を表していない可能性があるためです。デフォルトの初期化期間は 60 秒です。{ "name": "example-autoscaler", "target": "zones/us-central1-f/instanceGroupManagers/example-managed-instance-group", "autoscalingPolicy": { "maxNumReplicas": 20, "loadBalancingUtilization": { "utilizationTarget": 0.8 }, "coolDownPeriodSec": 90 } }ロード バランシングの処理能力に基づく自動スケーリングの有効化の詳細については、チュートリアルの Compute Engine でウェブサービスのグローバルな自動スケーリングを行うを完了してください。
次のステップ
- オートスケーラーの管理について学習する。
- オートスケーラーによる決定の仕組みについて確認する。
- 複数の自動スケーリング信号を使用してグループをスケールする方法を確認する。
特に記載のない限り、このページのコンテンツはクリエイティブ・コモンズの表示 4.0 ライセンスにより使用許諾されます。コードサンプルは Apache 2.0 ライセンスにより使用許諾されます。詳しくは、Google Developers サイトのポリシーをご覧ください。Java は Oracle および関連会社の登録商標です。
最終更新日 2025-10-19 UTC。
-