Zugriff auf Ressourcen mit IAM steuern
In diesem Dokument wird beschrieben, wie Sie Zugriffssteuerungen für BigQuery-Datasets und für die Ressourcen in Datasets (Tabellen, Ansichten und Routinen) aufrufen, gewähren und widerrufen. Obwohl Modelle auch Ressourcen auf Dataset-Ebene sind, können Sie mit IAM-Rollen keinen Zugriff auf einzelne Modelle gewähren.
Sie können Zugriff auf Google Cloud -Ressourcen gewähren, indem Sie Zulassungsrichtlinien verwenden. Diese werden auch als IAM-Richtlinien (Identity and Access Management) bezeichnet und mit Ressourcen verknüpft. Sie können jeweils nur eine Zulassungsrichtlinie an eine Ressource anhängen. Die Zulassungsrichtlinie steuert den Zugriff auf die Ressource selbst sowie auf alle Nachfolgerelemente dieser Ressource, die die Zulassungsrichtlinie übernehmen.
Weitere Informationen zu Zulassungsrichtlinien finden Sie in der IAM-Dokumentation unter Richtlinienstruktur.
In diesem Dokument wird davon ausgegangen, dass Sie mit Identity and Access Management (IAM) in Google Cloudvertraut sind.
Beschränkungen
- Access Control Lists (ACLs) für Routinen sind nicht in replizierten Routinen enthalten.
- Routinen in externen oder verknüpften Datasets unterstützen keine Zugriffssteuerungen.
- Tabellen in externen oder verknüpften Datasets unterstützen keine Zugriffssteuerungen.
- Zugriffssteuerungen für Abläufe können nicht mit Terraform festgelegt werden.
- Regelmäßige Zugriffssteuerungen können nicht mit dem Google Cloud SDK festgelegt werden.
- Routinezugriffssteuerungen können nicht mit der BigQuery Data Control Language (DCL) festgelegt werden.
- Data Catalog unterstützt keine routinemäßigen Zugriffssteuerungen. Wenn ein Nutzer den Zugriff auf Routinen auf Bedingungsebene gewährt hat, werden seine Routinen nicht in der BigQuery-Seitenleiste angezeigt. Als Problemumgehung können Sie stattdessen Zugriff auf Dataset-Ebene gewähren.
- In der
INFORMATION_SCHEMA.OBJECT_PRIVILEGES-Ansicht werden keine Zugriffssteuerungen für Routinen angezeigt.
Hinweise
Weisen Sie IAM-Rollen (Identity and Access Management) zu, die Nutzern die erforderlichen Berechtigungen zum Ausführen der einzelnen Aufgaben in diesem Dokument gewähren.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle BigQuery-Dateninhaber (roles/bigquery.dataOwner) für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Ändern von IAM-Richtlinien für Ressourcen benötigen.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierte Rolle enthält die Berechtigungen, die zum Ändern von IAM-Richtlinien für Ressourcen erforderlich sind. Erweitern Sie den Abschnitt Erforderliche Berechtigungen, um die erforderlichen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind erforderlich, um IAM-Richtlinien für Ressourcen zu ändern:
-
bigquery.datasets.get -
bigquery.datasets.update -
So rufen Sie die Zugriffsrichtlinie eines Datasets ab (nurGoogle Cloud -Konsole):
bigquery.datasets.getIamPolicy -
So legen Sie die Zugriffsrichtlinie eines Datasets (nur Konsole) fest:
bigquery.datasets.setIamPolicy -
bigquery.tables.getIamPolicy -
bigquery.tables.setIamPolicy -
So rufen Sie die Zugriffsrichtlinie einer Routine ab:
bigquery.routines.getIamPolicy -
So legen Sie die Zugriffsrichtlinie einer Routine fest:
bigquery.routines.setIamPolicy -
So erstellen Sie das bq-Tool oder SQL BigQuery-Jobs (optional):
bigquery.jobs.create
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Mit Dataset-Zugriffssteuerungen arbeiten
Sie können Zugriff auf ein Dataset gewähren, indem Sie einem IAM-Hauptkonto eine vordefinierte oder benutzerdefinierte Rolle zuweisen, die festlegt, was das Hauptkonto mit dem Dataset tun kann. Dies wird auch als Anhängen einer Zulassungsrichtlinie an eine Ressource bezeichnet. Nachdem Sie Zugriff gewährt haben, können Sie die Zugriffssteuerungen des Datasets aufrufen und den Zugriff auf das Dataset widerrufen.
Zugriff auf ein Dataset gewähren
Sie können beim Erstellen eines Datasets mit der BigQuery-Web-UI oder dem bq-Befehlszeilentool keinen Zugriff auf das Dataset gewähren. Sie müssen zuerst das Dataset erstellen und dann Zugriff darauf gewähren.
Mit der API können Sie Zugriff während der Dataset-Erstellung gewähren, indem Sie die Methode datasets.insertmit einer definierten Dataset-Ressource aufrufen.
Ein Projekt ist die übergeordnete Ressource für ein Dataset und ein Dataset ist die übergeordnete Ressource für Tabellen und Ansichten, Routinen und Modelle. Wenn Sie eine Rolle auf Projektebene zuweisen, werden die Rolle und ihre Berechtigungen vom Dataset und den Ressourcen des Datasets übernommen. Wenn Sie eine Rolle auf Dataset-Ebene zuweisen, werden die Rolle und ihre Berechtigungen von den Ressourcen innerhalb des Datasets übernommen.
Sie können Zugriff auf ein Dataset gewähren, indem Sie eine IAM-Rolle mit der Berechtigung für den Zugriff auf das Dataset zuweisen oder den Zugriff mithilfe einer IAM-Bedingung bedingt gewähren. Weitere Informationen zum Gewähren von bedingtem Zugriff finden Sie unter Zugriff mit IAM Conditions steuern.
Wenn Sie einer IAM-Rolle Zugriff auf ein Dataset gewähren möchten, ohne Bedingungen zu verwenden, wählen Sie eine der folgenden Optionen aus:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und wählen Sie ein Dataset für die Freigabe aus.
Klicken Sie auf Freigabe > Berechtigungen.
Klicken Sie auf Hauptkonto hinzufügen.
Geben Sie im Feld Neue Hauptkonten ein Hauptkonto ein.
Wählen Sie in der Liste Rolle auswählen eine vordefinierte oder eine benutzerdefinierte Rolle aus.
Klicken Sie auf Speichern.
Klicken Sie auf Schließen, um zu den Dataset-Informationen zurückzukehren.
SQL
Verwenden Sie die DCL-Anweisung GRANT, um Hauptkonten Zugriff auf Datasets zu gewähren:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
GRANT `ROLE_LIST` ON SCHEMA RESOURCE_NAME TO "USER_LIST"
Ersetzen Sie Folgendes:
ROLE_LIST: eine Rolle oder Liste mit durch Kommas getrennten Rollen, die Sie zuweisen möchtenRESOURCE_NAME: der Name des Datasets, für das Sie Zugriff gewährenUSER_LIST: eine durch Kommas getrennte Liste von Nutzern, denen die Rolle zugewiesen wirdEine Liste der gültigen Formate finden Sie unter
user_list.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Im folgenden Beispiel wird myDataset die Rolle „BigQuery Data Viewer“ zugewiesen:
GRANT `roles/bigquery.dataViewer`
ON SCHEMA `myProject`.myDataset
TO "user:user@example.com", "user:user2@example.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq show, um die vorhandenen Dataset-Informationen (einschließlich Zugriffssteuerungen) in eine JSON-Datei zu schreiben:bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID
- DATASET: der Name Ihres Datasets
- PATH_TO_FILE: der Pfad zur JSON-Datei auf dem lokalen Computer
Nehmen Sie die Änderungen im Abschnitt
accessder JSON-Datei vor. Sie können jeden derspecialGroup-Einträge verwenden:projectOwners,projectWriters,projectReadersundallAuthenticatedUsers. Sie können auch eine der folgenden Optionen hinzufügen:userByEmail,groupByEmailunddomain.Der Abschnitt
accessder JSON-Datei eines Datasets sieht zum Beispiel so aus:{ "access": [ { "role": "READER", "specialGroup": "projectReaders" }, { "role": "WRITER", "specialGroup": "projectWriters" }, { "role": "OWNER", "specialGroup": "projectOwners" }, { "role": "READER", "specialGroup": "allAuthenticatedUsers" }, { "role": "READER", "domain": "domain_name" }, { "role": "WRITER", "userByEmail": "user_email" }, { "role": "READER", "groupByEmail": "group_email" } ], ... }
Wenn die Änderungen abgeschlossen sind, führen Sie den Befehl
bq updateaus und fügen die JSON-Datei mit dem Flag--sourcehinzu. Wenn sich das Dataset in einem anderen Projekt als Ihrem Standardprojekt befindet, fügen Sie dem Dataset-Namen die Projekt-ID im FormatPROJECT_ID:DATASEThinzu.bq update
--source PATH_TO_FILE
PROJECT_ID:DATASETGeben Sie den Befehl
bq shownoch einmal ein, ohne die Informationen in eine Datei zu schreiben, um die Änderungen der Zugriffssteuerung zu prüfen:bq show --format=prettyjson PROJECT_ID:DATASET
- Rufen Sie Cloud Shell auf.
-
Legen Sie das Standardprojekt Google Cloud fest, auf das Sie Ihre Terraform-Konfigurationen anwenden möchten.
Sie müssen diesen Befehl nur einmal pro Projekt und in jedem beliebigen Verzeichnis ausführen.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Umgebungsvariablen werden überschrieben, wenn Sie in der Terraform-Konfigurationsdatei explizite Werte festlegen.
-
Erstellen Sie in Cloud Shell ein Verzeichnis und eine neue Datei in diesem Verzeichnis. Der Dateiname muss die Erweiterung
.tfhaben, z. B.main.tf. In dieser Anleitung wird die Datei alsmain.tfbezeichnet.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Wenn Sie einer Anleitung folgen, können Sie den Beispielcode in jedem Abschnitt oder Schritt kopieren.
Kopieren Sie den Beispielcode in das neu erstellte
main.tf.Kopieren Sie optional den Code aus GitHub. Dies wird empfohlen, wenn das Terraform-Snippet Teil einer End-to-End-Lösung ist.
- Prüfen und ändern Sie die Beispielparameter, die auf Ihre Umgebung angewendet werden sollen.
- Speichern Sie die Änderungen.
-
Initialisieren Sie Terraform. Dies ist nur einmal für jedes Verzeichnis erforderlich.
terraform init
Fügen Sie optional die Option
-upgradeein, um die neueste Google-Anbieterversion zu verwenden:terraform init -upgrade
-
Prüfen Sie die Konfiguration und prüfen Sie, ob die Ressourcen, die Terraform erstellen oder aktualisieren wird, Ihren Erwartungen entsprechen:
terraform plan
Korrigieren Sie die Konfiguration nach Bedarf.
-
Wenden Sie die Terraform-Konfiguration an. Führen Sie dazu den folgenden Befehl aus und geben Sie
yesan der Eingabeaufforderung ein:terraform apply
Warten Sie, bis Terraform die Meldung „Apply complete“ anzeigt.
- Öffnen Sie Ihr Google Cloud Projekt, um die Ergebnisse aufzurufen. Rufen Sie in der Google Cloud Console Ihre Ressourcen in der Benutzeroberfläche auf, um sicherzustellen, dass Terraform sie erstellt oder aktualisiert hat.
Terraform
Verwenden Sie die google_bigquery_dataset_iam-Ressourcen, um den Zugriff auf ein Dataset zu aktualisieren.
Zugriffsrichtlinie für ein Dataset abrufen
Im folgenden Beispiel wird gezeigt, wie Sie die google_bigquery_dataset_iam_policy-Ressource verwenden, um die IAM-Richtlinie für das mydataset-Dataset festzulegen. Dadurch wird jede vorhandene Richtlinie ersetzt, die bereits an das Dataset angehängt ist:
# This file sets the IAM policy for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". data "google_iam_policy" "iam_policy" { binding { role = "roles/bigquery.admin" members = [ "user:user@example.com", ] } binding { role = "roles/bigquery.dataOwner" members = [ "group:data.admin@example.com", ] } binding { role = "roles/bigquery.dataEditor" members = [ "serviceAccount:bqcx-1234567891011-12a3@gcp-sa-bigquery-condel.iam.gserviceaccount.com", ] } } resource "google_bigquery_dataset_iam_policy" "dataset_iam_policy" { dataset_id = google_bigquery_dataset.default.dataset_id policy_data = data.google_iam_policy.iam_policy.policy_data }
Rollenmitgliedschaft für ein Dataset festlegen
Im folgenden Beispiel wird gezeigt, wie Sie mit der Ressource google_bigquery_dataset_iam_binding die Mitgliedschaft in einer bestimmten Rolle für das Dataset mydataset festlegen. Dadurch wird jede vorhandene Mitgliedschaft in dieser Rolle ersetzt.
Andere Rollen in der IAM-Richtlinie für das Dataset werden beibehalten:
# This file sets membership in an IAM role for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". resource "google_bigquery_dataset_iam_binding" "dataset_iam_binding" { dataset_id = google_bigquery_dataset.default.dataset_id role = "roles/bigquery.jobUser" members = [ "user:user@example.com", "group:group@example.com" ] }
Rollenmitgliedschaft für ein einzelnes Hauptkonto festlegen
Im folgenden Beispiel wird gezeigt, wie Sie die google_bigquery_dataset_iam_member-Ressource verwenden, um die IAM-Richtlinie für das Dataset mydataset zu aktualisieren und einem Hauptkonto eine Rolle zuzuweisen. Das Aktualisieren dieser IAM-Richtlinie hat keine Auswirkungen auf den Zugriff für andere Principals, denen diese Rolle für das Dataset zugewiesen wurde.
# This file adds a member to an IAM role for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". resource "google_bigquery_dataset_iam_member" "dataset_iam_member" { dataset_id = google_bigquery_dataset.default.dataset_id role = "roles/bigquery.user" member = "user:user@example.com" }
Führen Sie die Schritte in den folgenden Abschnitten aus, um Ihre Terraform-Konfiguration auf ein Google Cloud -Projekt anzuwenden.
Cloud Shell vorbereiten
Verzeichnis vorbereiten
Jede Terraform-Konfigurationsdatei muss ein eigenes Verzeichnis haben (auch als Stammmodul bezeichnet).
Änderungen anwenden
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf, um Zugriffssteuerungen anzuwenden, wenn das Dataset erstellt wird.
Rufen Sie zum Aktualisieren Ihrer Zugriffssteuerungen die Methode datasets.patch auf und verwenden Sie das Attribut access in der Ressource Dataset.
Da die Methode datasets.update die gesamte Dataset-Ressource ersetzt, ist datasets.patch die bevorzugte Methode zum Aktualisieren von Zugriffssteuerungen.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Legen Sie die neue Zugriffsliste fest, indem Sie den neuen Eintrag mitDatasetMetadataToUpdate type an die vorhandene Liste anhängen.
Rufen Sie dann die dataset.Update()-Funktion auf, um das Attribut zu aktualisieren.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Legen Sie die neue Zugriffsliste fest, indem Sie den neuen Eintrag mit der Methode Dataset#metadata an die vorhandene Liste anhängen. Rufen Sie dann die Funktion Dataset#setMetadata() auf, um das Attribut zu aktualisieren.Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Legen Sie das Attributdataset.access_entries mit den Zugriffssteuerungen für ein Dataset fest. Rufen Sie dann die client.update_dataset()-Funktion auf, um das Attribut zu aktualisieren.
Vordefinierte Rollen, die Zugriff auf Datasets gewähren
Sie können den folgenden vordefinierten IAM-Rollen Zugriff auf ein Dataset gewähren.
| Rolle | Beschreibung |
|---|---|
BigQuery-Dateninhaber
(roles/bigquery.dataOwner) |
Wenn diese Rolle für ein Dataset gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery-Dateneditor
(roles/bigquery.dataEditor) |
Wenn diese Rolle für ein Dataset gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery Data Viewer
(roles/bigquery.dataViewer) |
Wenn diese Rolle für ein Dataset gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery Metadata Viewer
(roles/bigquery.metadataViewer) |
Wenn diese Rolle für ein Dataset gewährt wird, werden die folgenden Berechtigungen erteilt:
|
Dataset-Berechtigungen
Die meisten Berechtigungen, die mit bigquery.datasets beginnen, gelten auf Dataset-Ebene.
bigquery.datasets.create nicht. Zum Erstellen von Datasets muss einer Rolle im übergeordneten Container (dem Projekt) die Berechtigung bigquery.datasets.create gewährt werden.
In der folgenden Tabelle sind alle Berechtigungen für Datasets und die Ressource der niedrigsten Ebene aufgeführt, auf die die Berechtigung angewendet werden kann.
| Berechtigung | Ressource | Aktion |
|---|---|---|
bigquery.datasets.create |
Projekt | Neue Datasets im Projekt erstellen |
bigquery.datasets.get |
Dataset | Metadaten und Zugriffssteuerungen für das Dataset abrufen. Zum Aufrufen von Berechtigungen in der Konsole ist außerdem die Berechtigung bigquery.datasets.getIamPolicy erforderlich. |
bigquery.datasets.getIamPolicy |
Dataset | Von der Konsole benötigt, um dem Nutzer die Berechtigung zu erteilen, die Zugriffssteuerung eines Datasets abzurufen. Fails open. Außerdem ist die Berechtigung bigquery.datasets.get erforderlich, um das Dataset in der Console aufzurufen. |
bigquery.datasets.update |
Dataset | Metadaten und Zugriffssteuerungen für das Dataset aktualisieren. Zum Aktualisieren von Zugriffssteuerungen in der Konsole ist außerdem die Berechtigung bigquery.datasets.setIamPolicy erforderlich.
|
bigquery.datasets.setIamPolicy |
Dataset | Von der Konsole benötigt, um dem Nutzer die Berechtigung zum Festlegen der Zugriffssteuerung eines Datasets zu erteilen. Fails open. Für die Konsole ist außerdem die Berechtigung bigquery.datasets.update erforderlich, um das Dataset zu aktualisieren. |
bigquery.datasets.delete |
Dataset | Datasets löschen. |
bigquery.datasets.createTagBinding |
Dataset | Hängen Sie Tags an das Dataset an. |
bigquery.datasets.deleteTagBinding |
Dataset | Trennen Sie die Tags vom Dataset. |
bigquery.datasets.listTagBindings |
Dataset | Tags für das Dataset auflisten. |
bigquery.datasets.listEffectiveTags |
Dataset | Gültige Tags (angewendet und übernommen) für das Dataset auflisten. |
bigquery.datasets.link |
Dataset | Erstellen Sie ein verknüpftes Dataset. |
bigquery.datasets.listSharedDatasetUsage |
Projekt | Listet Nutzungsstatistiken für freigegebene Datasets auf, auf die Sie im Projekt Zugriff haben. Diese Berechtigung ist zum Abfragen der Ansicht INFORMATION_SCHEMA.SHARED_DATASET_USAGE erforderlich. |
Zugriffssteuerungen für ein Dataset ansehen
Sie können die explizit festgelegten Zugriffssteuerungen für ein Dataset auf eine der folgenden Arten aufrufen. Wenn Sie übernommene Rollen für ein Dataset ansehen möchten, verwenden Sie die BigQuery-Web-UI.
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und wählen Sie ein Dataset aus.
Klicken Sie auf Freigabe > Berechtigungen.
Die Zugriffssteuerung des Datasets wird im Bereich Dataset-Berechtigungen angezeigt.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie in Cloud Shell den Befehl
bq show, um eine vorhandene Richtlinie abzurufen und in eine lokale Datei in JSON auszugeben:bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID
- DATASET: der Name Ihres Datasets
- PATH_TO_FILE: der Pfad zur JSON-Datei auf dem lokalen Computer
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
SELECT COLUMN_LIST FROM PROJECT_ID.`region-REGION`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_name = "DATASET";
Ersetzen Sie Folgendes:
- COLUMN_LIST: Eine durch Kommas getrennte Liste von Spalten aus der Ansicht
INFORMATION_SCHEMA.OBJECT_PRIVILEGES. - PROJECT_ID: Ihre Projekt-ID.
- REGION: Ein Regions-Qualifier.
- DATASET: der Name eines Datasets in Ihrem Projekt
- COLUMN_LIST: Eine durch Kommas getrennte Liste von Spalten aus der Ansicht
Klicken Sie auf Ausführen.
SQL
Fragen Sie die Ansicht INFORMATION_SCHEMA.OBJECT_PRIVILEGES ab.
Bei Abfragen zum Abrufen von Zugriffssteuerungen für ein Dataset muss der object_name angegeben werden.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Beispiel:
Mit dieser Abfrage werden die Zugriffssteuerungen für mydataset abgerufen.
SELECT object_name, privilege_type, grantee FROM my_project.`region-us`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_name = "mydataset";
Die Ausgabe sollte so aussehen:
+------------------+-----------------------------+-------------------------+
| object_name | privilege_type | grantee |
+------------------+-----------------------------+-------------------------+
| mydataset | roles/bigquery.dataOwner | projectOwner:myproject |
| mydataset | roles/bigquery.dataViwer | user:user@example.com |
+------------------+-----------------------------+-------------------------+
API
Rufen Sie die Methode datasets.get mit einer definierten dataset-Ressource auf, um die Zugriffssteuerungen für ein Dataset aufzurufen.
Die Zugriffssteuerungen werden im Attribut access der Ressource dataset angezeigt.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie die Funktionclient.Dataset().Metadata() auf. Die Zugriffsrichtlinie ist in der Access-Property verfügbar.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie die Dataset-Metadaten mit derDataset#getMetadata()-Funktion ab.
Die Zugriffsrichtlinie ist in der Eigenschaft „access“ des resultierenden Metadatenobjekts verfügbar.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie die Funktionclient.get_dataset() auf.
Die Zugriffsrichtlinie ist in der dataset.access_entries-Property verfügbar.
Zugriff auf ein Dataset widerrufen
Wählen Sie eine der folgenden Optionen aus, um den Zugriff auf ein Dataset zu widerrufen:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und wählen Sie ein Dataset aus.
Klicken Sie im Detailbereich auf Freigabe > Berechtigungen.
Erweitern Sie im Dialogfeld Dataset-Berechtigungen das Hauptkonto, dessen Zugriff Sie widerrufen möchten.
Klicken Sie auf Hauptkonto entfernen.
Klicken Sie im Dialogfeld Rolle aus Hauptkonto entfernen? auf Entfernen.
Klicken Sie auf Schließen, um zu den Dataset-Details zurückzukehren.
SQL
Verwenden Sie die DCL-Anweisung REVOKE, um den Zugriff eines Hauptkontos auf ein Dataset zu entfernen:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
REVOKE `ROLE_LIST` ON SCHEMA RESOURCE_NAME FROM "USER_LIST"
Ersetzen Sie Folgendes:
ROLE_LIST: eine Rolle oder Liste mit durch Kommas getrennten Rollen, die Sie widerrufen möchtenRESOURCE_NAME: der Name der Ressource, für die Sie die Berechtigung widerrufen möchtenUSER_LIST: eine durch Kommas getrennte Liste von Nutzern, deren Rollen widerrufen werdenEine Liste der gültigen Formate finden Sie unter
user_list.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Im folgenden Beispiel wird die Rolle „BigQuery Data Owner“ für myDataset widerrufen:
REVOKE `roles/bigquery.dataOwner`
ON SCHEMA `myProject`.myDataset
FROM "group:group@example.com", "serviceAccount:user@test-project.iam.gserviceaccount.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq show, um die vorhandenen Dataset-Informationen (einschließlich Zugriffssteuerungen) in eine JSON-Datei zu schreiben:bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID
- DATASET: der Name Ihres Datasets
- PATH_TO_FILE: der Pfad zur JSON-Datei auf dem lokalen Computer
Nehmen Sie die Änderungen im Abschnitt
accessder JSON-Datei vor. Sie können allespecialGroup-Einträge entfernen:projectOwners,projectWriters,projectReadersundallAuthenticatedUsers. Sie können auch die folgenden Elemente entfernen:userByEmail,groupByEmailunddomain.Der Abschnitt
accessder JSON-Datei eines Datasets sieht zum Beispiel so aus:{ "access": [ { "role": "READER", "specialGroup": "projectReaders" }, { "role": "WRITER", "specialGroup": "projectWriters" }, { "role": "OWNER", "specialGroup": "projectOwners" }, { "role": "READER", "specialGroup": "allAuthenticatedUsers" }, { "role": "READER", "domain": "domain_name" }, { "role": "WRITER", "userByEmail": "user_email" }, { "role": "READER", "groupByEmail": "group_email" } ], ... }
Wenn die Änderungen abgeschlossen sind, führen Sie den Befehl
bq updateaus und fügen die JSON-Datei mit dem Flag--sourcehinzu. Wenn sich das Dataset in einem anderen Projekt als Ihrem Standardprojekt befindet, fügen Sie dem Dataset-Namen die Projekt-ID im FormatPROJECT_ID:DATASEThinzu.bq update
--source PATH_TO_FILE
PROJECT_ID:DATASETGeben Sie den Befehl
shownoch einmal ein, ohne die Informationen in eine Datei zu schreiben, um die Änderungen der Zugriffssteuerung zu prüfen:bq show --format=prettyjson PROJECT_ID:DATASET
API
Rufen Sie die Methode datasets.patch auf und verwenden Sie das Attribut access in der Ressource Dataset, um die Zugriffssteuerungen zu aktualisieren.
Da die Methode datasets.update die gesamte Dataset-Ressource ersetzt, ist datasets.patch die bevorzugte Methode zum Aktualisieren von Zugriffssteuerungen.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Legen Sie die neue Zugriffsliste fest, indem Sie den Eintrag aus der vorhandenen Liste mitDatasetMetadataToUpdate-Typ entfernen. Rufen Sie dann die dataset.Update()-Funktion auf, um das Attribut zu aktualisieren.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Aktualisieren Sie die Liste mit dem Dataset-Zugriff, indem Sie den angegebenen Eintrag aus der vorhandenen Liste entfernen. Verwenden Sie dazu die MethodeDataset#get(), um die aktuellen Metadaten abzurufen. Ändern Sie das Attribut „access“, um die gewünschte Entität auszuschließen, und rufen Sie dann die Funktion Dataset#setMetadata() auf, um die aktualisierte Zugriffsliste anzuwenden.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Legen Sie das Attributdataset.access_entries mit den Zugriffssteuerungen für ein Dataset fest. Rufen Sie dann die client.update_dataset()-Funktion auf, um das Attribut zu aktualisieren.
Mit Tabellen- und Ansichtszugriffssteuerungen arbeiten
Ansichten werden in BigQuery als Tabellenressourcen behandelt. Sie können den Zugriff auf eine Tabelle oder Ansicht gewähren, indem Sie einem IAM-Hauptkonto eine vordefinierte oder benutzerdefinierte Rolle zuweisen, die festlegt, was das Hauptkonto mit der Tabelle oder Ansicht tun kann. Dies wird auch als Anhängen einer Zulassungsrichtlinie an eine Ressource bezeichnet. Nachdem Sie Zugriff gewährt haben, können Sie die Zugriffssteuerungen für die Tabelle oder Ansicht aufrufen und den Zugriff auf die Tabelle oder Ansicht widerrufen.
Zugriff auf eine Tabelle oder Ansicht gewähren
Für eine detaillierte Zugriffssteuerung können Sie eine vordefinierte oder benutzerdefinierte IAM-Rolle für eine bestimmte Tabelle oder Ansicht zuweisen. Die Tabelle oder Ansicht erbt auch die Zugriffssteuerung, die auf Dataset- und höherer Ebene angegeben ist. Wenn Sie einem Hauptkonto beispielsweise die Rolle „BigQuery Data Owner“ für ein Dataset zuweisen, hat dieses Hauptkonto auch die Berechtigungen „BigQuery Data Owner“ für die Tabellen und Ansichten im Dataset.
Wählen Sie eine der folgenden Optionen aus, um Zugriff auf eine Tabelle oder Ansicht zu gewähren:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und wählen Sie eine Tabelle oder Ansicht aus, die Sie freigeben möchten.
Klicken Sie auf Freigeben.
Klicken Sie auf Hauptkonto hinzufügen.
Geben Sie im Feld Neue Hauptkonten ein Hauptkonto ein.
Wählen Sie in der Liste Rolle auswählen eine vordefinierte oder eine benutzerdefinierte Rolle aus.
Klicken Sie auf Speichern.
Klicken Sie auf Schließen, um zu den Tabellen- oder Ansichtsdetails zurückzukehren.
SQL
Verwenden Sie die DCL-Anweisung GRANT, um Hauptkonten Zugriff auf Tabellen oder Ansichten zu gewähren:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
GRANT `ROLE_LIST` ON RESOURCE_TYPE RESOURCE_NAME TO "USER_LIST"
Ersetzen Sie Folgendes:
ROLE_LIST: eine Rolle oder Liste mit durch Kommas getrennten Rollen, die Sie widerrufen möchtenRESOURCE_TYPE: der Ressourcentyp, auf den die Rolle angewendet wirdUnterstützte Werte sind:
TABLE,VIEW,MATERIALIZED VIEWundEXTERNAL TABLE.RESOURCE_NAME: der Name der Ressource, für die Sie die Berechtigung gewähren möchtenUSER_LIST: eine durch Kommas getrennte Liste von Nutzern, denen die Rolle zugewiesen wirdEine Liste der gültigen Formate finden Sie unter
user_list.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Im folgenden Beispiel wird die Rolle „BigQuery Data Viewer“ für myTable zugewiesen:
GRANT `roles/bigquery.dataViewer`
ON TABLE `myProject`.myDataset.myTable
TO "user:user@example.com", "user:user2@example.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq add-iam-policy-binding, um Zugriff auf eine Tabelle oder Ansicht zu gewähren:bq add-iam-policy-binding --member=MEMBER_TYPE:MEMBER --role=ROLE --table=true RESOURCE
Ersetzen Sie Folgendes:
- MEMBER_TYPE: der Mitgliedstyp, z. B.
user,group,serviceAccountoderdomain. - MEMBER: Die E-Mail-Adresse oder der Domainname des Mitglieds.
- ROLE: Die Rolle, die Sie dem Mitglied zuweisen möchten.
- RESOURCE: Der Name der Tabelle oder Ansicht, deren Richtlinie Sie aktualisieren möchten.
- MEMBER_TYPE: der Mitgliedstyp, z. B.
- Rufen Sie Cloud Shell auf.
-
Legen Sie das Standardprojekt Google Cloud fest, auf das Sie Ihre Terraform-Konfigurationen anwenden möchten.
Sie müssen diesen Befehl nur einmal pro Projekt und in jedem beliebigen Verzeichnis ausführen.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Umgebungsvariablen werden überschrieben, wenn Sie in der Terraform-Konfigurationsdatei explizite Werte festlegen.
-
Erstellen Sie in Cloud Shell ein Verzeichnis und eine neue Datei in diesem Verzeichnis. Der Dateiname muss die Erweiterung
.tfhaben, z. B.main.tf. In dieser Anleitung wird die Datei alsmain.tfbezeichnet.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Wenn Sie einer Anleitung folgen, können Sie den Beispielcode in jedem Abschnitt oder Schritt kopieren.
Kopieren Sie den Beispielcode in das neu erstellte
main.tf.Kopieren Sie optional den Code aus GitHub. Dies wird empfohlen, wenn das Terraform-Snippet Teil einer End-to-End-Lösung ist.
- Prüfen und ändern Sie die Beispielparameter, die auf Ihre Umgebung angewendet werden sollen.
- Speichern Sie die Änderungen.
-
Initialisieren Sie Terraform. Dies ist nur einmal für jedes Verzeichnis erforderlich.
terraform init
Fügen Sie optional die Option
-upgradeein, um die neueste Google-Anbieterversion zu verwenden:terraform init -upgrade
-
Prüfen Sie die Konfiguration und prüfen Sie, ob die Ressourcen, die Terraform erstellen oder aktualisieren wird, Ihren Erwartungen entsprechen:
terraform plan
Korrigieren Sie die Konfiguration nach Bedarf.
-
Wenden Sie die Terraform-Konfiguration an. Führen Sie dazu den folgenden Befehl aus und geben Sie
yesan der Eingabeaufforderung ein:terraform apply
Warten Sie, bis Terraform die Meldung „Apply complete“ anzeigt.
- Öffnen Sie Ihr Google Cloud Projekt, um die Ergebnisse aufzurufen. Rufen Sie in der Google Cloud Console Ihre Ressourcen in der Benutzeroberfläche auf, um sicherzustellen, dass Terraform sie erstellt oder aktualisiert hat.
Rufen Sie die Methode
tables.getIamPolicyauf, um die aktuelle Richtlinie abzurufen.Bearbeiten Sie die Richtlinie, um Mitglieder oder Zugriffssteuerungen oder beides hinzuzufügen. Das für die Richtlinie erforderliche Format finden Sie im Referenzthema Richtlinien.
Rufen Sie
tables.setIamPolicyauf, um die aktualisierte Richtlinie zu erstellen.
Terraform
Mit den google_bigquery_table_iam-Ressourcen können Sie den Zugriff auf eine Tabelle aktualisieren.
Zugriffsrichtlinie für ein Dataset festlegen
Das folgende Beispiel zeigt, wie Sie die google_bigquery_table_iam_policy-Ressource verwenden, um die IAM-Richtlinie für die Tabelle mytable festzulegen. Dadurch wird jede vorhandene Richtlinie ersetzt, die bereits an die Tabelle angehängt ist:
# This file sets the IAM policy for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". data "google_iam_policy" "iam_policy" { binding { role = "roles/bigquery.dataOwner" members = [ "user:user@example.com", ] } } resource "google_bigquery_table_iam_policy" "table_iam_policy" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id policy_data = data.google_iam_policy.iam_policy.policy_data }
Rollenmitgliedschaft für eine Tabelle festlegen
Im folgenden Beispiel wird gezeigt, wie Sie mit der google_bigquery_table_iam_binding-Ressource die Mitgliedschaft in einer bestimmten Rolle für die Tabelle mytable festlegen. Dadurch wird jede vorhandene Mitgliedschaft in dieser Rolle ersetzt.
Andere Rollen in der IAM-Richtlinie für die Tabelle werden beibehalten.
# This file sets membership in an IAM role for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". resource "google_bigquery_table_iam_binding" "table_iam_binding" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id role = "roles/bigquery.dataOwner" members = [ "group:group@example.com", ] }
Rollenmitgliedschaft für ein einzelnes Hauptkonto festlegen
Im folgenden Beispiel wird gezeigt, wie Sie die google_bigquery_table_iam_member-Ressource verwenden, um die IAM-Richtlinie für die Tabelle mytable zu aktualisieren und einem Hauptkonto eine Rolle zuzuweisen. Das Aktualisieren dieser IAM-Richtlinie hat keine Auswirkungen auf den Zugriff für andere Principals, denen diese Rolle für das Dataset zugewiesen wurde.
# This file adds a member to an IAM role for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". resource "google_bigquery_table_iam_member" "table_iam_member" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id role = "roles/bigquery.dataEditor" member = "serviceAccount:bqcx-1234567891011-12a3@gcp-sa-bigquery-condel.iam.gserviceaccount.com" }
Führen Sie die Schritte in den folgenden Abschnitten aus, um Ihre Terraform-Konfiguration auf ein Google Cloud -Projekt anzuwenden.
Cloud Shell vorbereiten
Verzeichnis vorbereiten
Jede Terraform-Konfigurationsdatei muss ein eigenes Verzeichnis haben (auch als Stammmodul bezeichnet).
Änderungen anwenden
API
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie dieIAM().SetPolicy()-Funktion der Ressource auf, um Änderungen an der Zugriffsrichtlinie für eine Tabelle oder Ansicht zu speichern.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie die FunktionTable#getIamPolicy() auf, um die aktuelle IAM-Richtlinie für eine Tabelle oder Ansicht abzurufen, ändern Sie die Richtlinie, indem Sie neue Bindungen hinzufügen, und verwenden Sie dann die Funktion Table#setIamPolicy(), um Änderungen an der Zugriffsrichtlinie zu speichern.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie dieclient.set_iam_policy()-Funktion auf, um Änderungen an der Zugriffsrichtlinie für eine Tabelle oder Ansicht zu speichern.
Vordefinierte Rollen, die Zugriff auf Tabellen und Ansichten gewähren
Ansichten werden in BigQuery als Tabellenressourcen behandelt. Für eine detaillierte Zugriffssteuerung können Sie eine vordefinierte oder benutzerdefinierte IAM-Rolle für eine bestimmte Tabelle oder Ansicht zuweisen. Die Tabelle oder Ansicht erbt auch die Zugriffssteuerung, die auf Dataset- und höherer Ebene angegeben ist. Wenn Sie einem Hauptkonto beispielsweise die Rolle „BigQuery-Dateninhaber“ für ein Dataset zuweisen, hat dieses Hauptkonto auch die Berechtigungen eines Dateninhabers für die Tabellen und Ansichten im Dataset.
Die folgenden vordefinierten IAM-Rollen haben Berechtigungen für Tabellen oder Ansichten.
| Rolle | Beschreibung |
|---|---|
BigQuery-Dateninhaber
(roles/bigquery.dataOwner) |
Wenn diese Rolle für eine Tabelle oder Ansicht gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery-Dateneditor
(roles/bigquery.dataEditor) |
Wenn diese Rolle für eine Tabelle oder Ansicht gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery Data Viewer
(roles/bigquery.dataViewer) |
Wenn diese Rolle für eine Tabelle oder Ansicht gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery Metadata Viewer
(roles/bigquery.metadataViewer) |
Wenn diese Rolle für eine Tabelle oder Ansicht gewährt wird, werden die folgenden Berechtigungen erteilt:
|
Berechtigungen für Tabellen und Ansichten
Ansichten werden in BigQuery als Tabellenressourcen behandelt. Alle Berechtigungen auf Tabellenebene gelten für Ansichten.
Die meisten Berechtigungen, die mit bigquery.tables beginnen, gelten auf Tabellenebene.
bigquery.tables.create und bigquery.tables.list nicht. Zum Erstellen und Auflisten von Tabellen oder Ansichten müssen einer Rolle in einem übergeordneten Container (dem Dataset oder dem Projekt) die Berechtigungen bigquery.tables.create und bigquery.tables.list gewährt werden.
In der folgenden Tabelle sind alle Berechtigungen für Tabellen und Ansichten sowie die Ressource der niedrigsten Ebene aufgeführt, für die sie gewährt werden können.
| Berechtigung | Ressource | Aktion |
|---|---|---|
bigquery.tables.create |
Dataset | Erstellen Sie neue Tabellen im Dataset. |
bigquery.tables.createIndex |
Tabelle | Erstellen Sie einen Suchindex für die Tabelle. |
bigquery.tables.deleteIndex |
Tabelle | Löschen Sie einen Suchindex für die Tabelle. |
bigquery.tables.createSnapshot |
Tabelle | Erstellen Sie einen Snapshot der Tabelle. Zum Erstellen eines Snapshots sind mehrere zusätzliche Berechtigungen auf Tabellen- und Dataset-Ebene erforderlich. Weitere Informationen finden Sie unter Berechtigungen und Rollen für das Erstellen von Tabellen-Snapshots. |
bigquery.tables.deleteSnapshot |
Tabelle | Löschen eines Snapshots der Tabelle |
bigquery.tables.delete |
Tabelle | Eine Tabelle löschen |
bigquery.tables.createTagBinding |
Tabelle | Ressourcen-Tag-Bindungen für eine Tabelle erstellen. |
bigquery.tables.deleteTagBinding |
Tabelle | Ressourcen-Tag-Bindungen für eine Tabelle löschen. |
bigquery.tables.listTagBindings |
Tabelle | Ressourcen-Tag-Bindungen für eine Tabelle auflisten |
bigquery.tables.listEffectiveTags |
Tabelle | Effektive Tags (angewendet und übernommen) für die Tabelle auflisten. |
bigquery.tables.export |
Tabelle | Exportieren Sie die Daten der Tabelle. Für die Ausführung eines Exportjobs sind außerdem Berechtigungen des Typs bigquery.jobs.create erforderlich. |
bigquery.tables.get |
Tabelle | Metadaten für eine Tabelle abrufen. |
bigquery.tables.getData |
Tabelle | Tabellendaten abfragen Zum Ausführen eines Abfragejobs sind außerdem bigquery.jobs.create-Berechtigungen erforderlich. |
bigquery.tables.getIamPolicy |
Tabelle | Zugriffssteuerungen für die Tabelle abrufen. |
bigquery.tables.list |
Dataset | Alle Tabellen und Tabellenmetadaten im Dataset auflisten. |
bigquery.tables.replicateData |
Tabelle | Tabellendaten replizieren. Diese Berechtigung ist zum Erstellen von Replikaten für materialisierte Ansichten erforderlich. |
bigquery.tables.restoreSnapshot |
Tabelle | Tabellen-Snapshot wiederherstellen |
bigquery.tables.setCategory |
Tabelle | Legen Sie Richtlinien-Tags im Schema der Tabelle fest. |
bigquery.tables.setColumnDataPolicy |
Tabelle | Zugriffsrichtlinien auf Spaltenebene für eine Tabelle festlegen. |
bigquery.tables.setIamPolicy |
Tabelle | Zugriffssteuerungen für eine Tabelle festlegen |
bigquery.tables.update |
Tabelle | Tabelle aktualisieren. metadata. bigquery.tables.get ist auch erforderlich, um Tabellenmetadaten in der Konsole zu aktualisieren. |
bigquery.tables.updateData |
Tabelle | Tabellendaten aktualisieren. |
bigquery.tables.updateIndex |
Tabelle | Aktualisieren Sie einen Suchindex für die Tabelle. |
Zugriffssteuerung für eine Tabelle oder Ansicht ansehen
Wählen Sie eine der folgenden Optionen aus, um die Zugriffssteuerung für eine Tabelle oder Ansicht aufzurufen:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und ein Dataset und wählen Sie eine Tabelle oder Ansicht aus.
Klicken Sie auf Freigeben.
Die Zugriffssteuerung für eine Tabelle oder Ansicht wird im Bereich Freigeben angezeigt.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie in Cloud Shell den Befehl
bq get-iam-policy, um eine vorhandene Zugriffsrichtlinie abzurufen und in eine lokale Datei in JSON auszugeben:bq get-iam-policy \ --table=true \ PROJECT_ID:DATASET.RESOURCE > PATH_TO_FILE
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID
- DATASET: der Name Ihres Datasets
- RESOURCE: der Name der Tabelle oder Ansicht, deren Richtlinie Sie aufrufen möchten
- PATH_TO_FILE: der Pfad zur JSON-Datei auf dem lokalen Computer
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
SELECT COLUMN_LIST FROM PROJECT_ID.`region-REGION`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_schema = "DATASET" AND object_name = "TABLE";
Ersetzen Sie Folgendes:
- COLUMN_LIST: Eine durch Kommas getrennte Liste von Spalten aus der Ansicht
INFORMATION_SCHEMA.OBJECT_PRIVILEGES. - PROJECT_ID: Ihre Projekt-ID.
- REGION: Ein Regions-Qualifier.
- DATASET: der Name eines Datasets, das die Tabelle oder Ansicht enthält
- TABLE: der Name der Tabelle oder Ansicht
- COLUMN_LIST: Eine durch Kommas getrennte Liste von Spalten aus der Ansicht
Klicken Sie auf Ausführen.
SQL
Fragen Sie die Ansicht INFORMATION_SCHEMA.OBJECT_PRIVILEGES ab.
Bei Abfragen zum Abrufen von Zugriffssteuerungen für eine Tabelle oder Ansicht müssen der object_schema und das object_name angegeben werden.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Beispiel:
SELECT object_name, privilege_type, grantee FROM my_project.`region-us`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_schema = "mydataset" AND object_name = "mytable";
+------------------+-----------------------------+--------------------------+
| object_name | privilege_type | grantee |
+------------------+-----------------------------+--------------------------+
| mytable | roles/bigquery.dataEditor | group:group@example.com|
| mytable | roles/bigquery.dataOwner | user:user@example.com|
+------------------+-----------------------------+--------------------------+
API
Rufen Sie die Methode tables.getIamPolicy auf, um die aktuelle Richtlinie abzurufen.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie dieIAM().Policy()-Funktion der Ressource auf. Rufen Sie dann die Funktion Roles() auf, um die Zugriffsrichtlinie für eine Tabelle oder Ansicht abzurufen.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie die IAM-Richtlinie für eine Tabelle oder Ansicht mit derTable#getIamPolicy()-Funktion ab.
Die Details der Zugriffsrichtlinie sind im zurückgegebenen Richtlinienobjekt verfügbar.
Zugriff auf eine Tabelle oder Ansicht aufheben
Wählen Sie eine der folgenden Optionen aus, um den Zugriff auf eine Tabelle oder Ansicht zu widerrufen:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und ein Dataset und wählen Sie eine Tabelle oder Ansicht aus.
Klicken Sie im Detailbereich auf Freigeben.
Erweitern Sie im Dialogfeld Freigeben das Hauptkonto, dessen Zugriff Sie widerrufen möchten.
Klicken Sie auf Löschen.
Klicken Sie im Dialogfeld Rolle aus Hauptkonto entfernen? auf Entfernen.
Klicken Sie auf Schließen, um zu den Tabellen- oder Ansichtsdetails zurückzukehren.
SQL
Verwenden Sie die DCL-Anweisung REVOKE, um den Zugriff auf Tabellen oder Ansichten aus Hauptkonten zu entfernen:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
REVOKE `ROLE_LIST` ON RESOURCE_TYPE RESOURCE_NAME FROM "USER_LIST"
Ersetzen Sie Folgendes:
ROLE_LIST: eine Rolle oder Liste mit durch Kommas getrennten Rollen, die Sie widerrufen möchtenRESOURCE_TYPE: der Ressourcentyp, von dem die Rolle widerrufen wirdUnterstützte Werte sind:
TABLE,VIEW,MATERIALIZED VIEWundEXTERNAL TABLE.RESOURCE_NAME: der Name der Ressource, für die Sie die Berechtigung widerrufen möchtenUSER_LIST: eine durch Kommas getrennte Liste von Nutzern, deren Rollen widerrufen werdenEine Liste der gültigen Formate finden Sie unter
user_list.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Im folgenden Beispiel wird die Rolle „BigQuery-Dateninhaber“ für myTable widerrufen:
REVOKE `roles/bigquery.dataOwner`
ON TABLE `myProject`.myDataset.myTable
FROM "group:group@example.com", "serviceAccount:user@myproject.iam.gserviceaccount.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq remove-iam-policy-binding, um den Zugriff auf eine Tabelle oder Ansicht aufzuheben:bq remove-iam-policy-binding --member=MEMBER_TYPE:MEMBER --role=ROLE --table=true RESOURCE
Ersetzen Sie Folgendes:
- MEMBER_TYPE: der Mitgliedstyp, z. B.
user,group,serviceAccountoderdomain - MEMBER: Die E-Mail-Adresse oder der Domainname des Mitglieds.
- ROLE: Die Rolle, die Sie dem Mitglied entziehen möchten.
- RESOURCE: der Name der Tabelle oder Ansicht, deren Richtlinie Sie aktualisieren möchten
- MEMBER_TYPE: der Mitgliedstyp, z. B.
Rufen Sie die Methode
tables.getIamPolicyauf, um die aktuelle Richtlinie abzurufen.Bearbeiten Sie die Richtlinie, um Mitglieder oder Bindungen oder beides zu entfernen. Das für die Richtlinie erforderliche Format finden Sie im Referenzthema Richtlinien.
Rufen Sie
tables.setIamPolicyauf, um die aktualisierte Richtlinie zu erstellen.
API
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie diepolicy.Remove()-Funktion auf, um den Zugriff zu entfernen.
Rufen Sie dann die IAM().SetPolicy()-Funktion auf, um Änderungen an der Zugriffsrichtlinie für eine Tabelle oder Ansicht zu speichern.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Rufen Sie die aktuelle IAM-Richtlinie für eine Tabelle oder Ansicht mit der MethodeTable#getIamPolicy() ab.
Ändern Sie die Richtlinie, um die gewünschte Rolle oder das gewünschte Hauptkonto zu entfernen, und wenden Sie dann die aktualisierte Richtlinie mit der Methode Table#setIamPolicy() an.
Zugriffssteuerungen für Routinen verwenden
Wenn Sie Feedback geben oder Support für dieses Feature anfordern möchten, senden Sie eine E-Mail an bq-govsec-eng@google.com.
Sie können den Zugriff auf eine Routine gewähren, indem Sie einem IAM-Hauptkonto](/iam/docs/principal-identifiers#allow) eine vordefinierte oder benutzerdefinierte Rolle zuweisen, die festlegt, was das Hauptkonto mit der Routine tun kann. Dies wird auch als Anhängen einer Zulassungsrichtlinie an eine Ressource bezeichnet. Nachdem du Zugriff gewährt hast, kannst du die Zugriffssteuerung für den Ablauf aufrufen und den Zugriff auf den Ablauf widerrufen.
Zugriff auf eine Routine gewähren
Für eine detaillierte Zugriffssteuerung können Sie eine vordefinierte oder benutzerdefinierte IAM-Rolle für eine bestimmte Routine zuweisen. Die Routine übernimmt auch die auf Dataset-Ebene und höher angegebenen Zugriffssteuerungen. Wenn Sie einem Hauptkonto beispielsweise die Rolle „BigQuery Data Owner“ für ein Dataset zuweisen, hat dieses Hauptkonto auch die Berechtigungen „Data Owner“ für die Routinen im Dataset.
Wählen Sie eine der folgenden Optionen aus:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und Ihr Dataset, maximieren Sie Abläufe und wählen Sie dann einen Ablauf aus.
Klicken Sie auf Freigeben.
Klicken Sie auf Mitglieder hinzufügen.
Geben Sie im Feld Neue Mitglieder ein Hauptkonto ein.
Wählen Sie in der Liste Rolle auswählen eine vordefinierte oder eine benutzerdefinierte Rolle aus.
Klicken Sie auf Speichern.
Klicke auf Fertig, um zu den Informationen zur Routine zurückzukehren.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq get-iam-policy, um die vorhandenen Routineninformationen (einschließlich Zugriffssteuerungen) in eine JSON-Datei zu schreiben:bq get-iam-policy \ PROJECT_ID:DATASET.ROUTINE \ > PATH_TO_FILE
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID.
- DATASET: der Name des Datasets, das die Routine enthält, die Sie aktualisieren möchten.
- ROUTINE: der Name der Ressource, die aktualisiert werden soll
- PATH_TO_FILE: der Pfad zur JSON-Datei auf dem lokalen Computer
Nehmen Sie die Änderungen im Abschnitt
bindingsder JSON-Datei vor. Eine Bindung bindet ein oder mehrere Hauptkonten an eine einzelnerole. Hauptkonten können Nutzerkonten, Dienstkonten, Google-Gruppen und Domains sein. Der Abschnittbindingsder JSON-Datei einer Routine sieht beispielsweise so aus:{ "bindings": [ { "role": "roles/bigquery.dataViewer", "members": [ "user:user@example.com", "group:group@example.com", "domain:example.com", ] }, ], "etag": "BwWWja0YfJA=", "version": 1 }
Aktualisieren Sie Ihre Zugriffsrichtlinie mit dem Befehl
bq set-iam-policy.bq set-iam-policy PROJECT_ID:DATASET.ROUTINE PATH_TO_FILE
Geben Sie den Befehl
bq get-iam-policynoch einmal ein, ohne die Informationen in eine Datei zu schreiben, um die Änderungen der Zugriffssteuerung zu prüfen:bq get-iam-policy --format=prettyjson \\ PROJECT_ID:DATASET.ROUTINE
Rufen Sie die Methode
routines.getIamPolicyauf, um die aktuelle Richtlinie abzurufen.Bearbeiten Sie die Richtlinie, um Hauptkonten, Bindungen oder beides hinzuzufügen. Das für die Richtlinie erforderliche Format finden Sie im Referenzthema Richtlinien.
Rufen Sie
routines.setIamPolicyauf, um die aktualisierte Richtlinie zu erstellen.
API
Vordefinierte Rollen, die Zugriff auf Routinen gewähren
Für eine detaillierte Zugriffssteuerung können Sie eine vordefinierte oder benutzerdefinierte IAM-Rolle für eine bestimmte Routine zuweisen. Die Routine übernimmt auch die auf Dataset-Ebene und höher angegebenen Zugriffssteuerungen. Wenn Sie einem Hauptkonto beispielsweise die Rolle „Data Owner“ für ein Dataset zuweisen, hat dieses Hauptkonto durch Vererbung auch die Berechtigungen „Data Owner“ für die Routinen im Dataset.
Die folgenden vordefinierten IAM-Rollen haben Berechtigungen für Routinen.
| Rolle | Beschreibung |
|---|---|
BigQuery-Dateninhaber
(roles/bigquery.dataOwner) |
Wenn diese Rolle für eine Routine gewährt wird, werden die folgenden Berechtigungen erteilt:
Sie sollten die Rolle „Dateneigentümer“ nicht auf Routineebene zuweisen. Mit der Rolle „Datenbearbeiter“ werden auch alle Berechtigungen für die Routine erteilt. Sie ist eine weniger permissive Rolle. |
BigQuery-Dateneditor
(roles/bigquery.dataEditor) |
Wenn diese Rolle für eine Routine gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery Data Viewer
(roles/bigquery.dataViewer) |
Wenn diese Rolle für eine Routine gewährt wird, werden die folgenden Berechtigungen erteilt:
|
BigQuery Metadata Viewer
(roles/bigquery.metadataViewer) |
Wenn diese Rolle für eine Routine gewährt wird, werden die folgenden Berechtigungen erteilt:
|
Berechtigungen für Routinen
Die meisten Berechtigungen, die mit bigquery.routines beginnen, gelten auf Routineebene.
bigquery.routines.create und bigquery.routines.list nicht. Zum Erstellen und Auflisten von Routinen müssen einer Rolle im übergeordneten Container (dem Dataset) die Berechtigungen bigquery.routines.create und bigquery.routines.list gewährt werden.
In der folgenden Tabelle sind alle Berechtigungen für Routinen und die Ressource der niedrigsten Ebene aufgeführt, für die sie gewährt werden können.
| Berechtigung | Ressource | Beschreibung |
|---|---|---|
bigquery.routines.create |
Dataset | Erstellen Sie eine Routine im Dataset. Für diese Berechtigung ist auch bigquery.jobs.create erforderlich, um einen Abfragejob auszuführen, der eine CREATE FUNCTION-Anweisung enthält. |
bigquery.routines.delete |
Routine | Einen Ablauf löschen |
bigquery.routines.get |
Routine | Auf einen von einer anderen Person erstellten Ablauf verweisen Für diese Berechtigung ist auch bigquery.jobs.create erforderlich, um einen Abfragejob auszuführen, der auf die Routine verweist. Außerdem benötigen Sie die Berechtigung für den Zugriff auf alle Ressourcen, auf die die Routine verweist, z. B. auf Tabellen oder Ansichten. |
bigquery.routines.list |
Dataset | Routinen im Dataset auflisten und Metadaten für Routinen anzeigen. |
bigquery.routines.update |
Routine | Routinendefinitionen und -metadaten aktualisieren. |
bigquery.routines.getIamPolicy |
Routine | Zugriffssteuerungen für die Routine abrufen. |
bigquery.routines.setIamPolicy |
Routine | Zugriffssteuerung für die Routine festlegen |
Zugriffssteuerungen für einen Ablauf aufrufen
Wählen Sie eine der folgenden Optionen aus, um die Zugriffssteuerung für eine Routine aufzurufen:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt, das Dataset und Abläufe und wählen Sie dann einen Ablauf aus.
Klicken Sie auf Freigeben.
Die Zugriffssteuerungen der Routine werden im Bereich Freigeben angezeigt.
bq
Der Befehl bq get-iam-policy bietet keine Unterstützung für das Aufrufen von Zugriffssteuerungen für Routinen.
SQL
In der INFORMATION_SCHEMA.OBJECT_PRIVILEGES-Ansicht werden keine Zugriffssteuerungen für Routinen angezeigt.
API
Rufen Sie die Methode routines.getIamPolicy auf, um die aktuelle Richtlinie abzurufen.
Zugriff auf eine Routine widerrufen
Wähle eine der folgenden Optionen aus, um den Zugriff auf eine Routine zu widerrufen:
Console
Rufen Sie die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt, ein Dataset und Abläufe und wählen Sie dann einen Ablauf aus.
Klicken Sie im Detailbereich auf Freigabe > Berechtigungen.
Erweitern Sie im Dialogfeld Berechtigungen für Routinen das Hauptkonto, dessen Zugriff Sie widerrufen möchten.
Klicken Sie auf Hauptkonto entfernen.
Klicken Sie im Dialogfeld Rolle aus Hauptkonto entfernen? auf Entfernen.
Klicken Sie auf Schließen.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq get-iam-policy, um die vorhandenen Routineninformationen (einschließlich Zugriffssteuerungen) in eine JSON-Datei zu schreiben:bq get-iam-policy --routine PROJECT_ID:DATASET.ROUTINE > PATH_TO_FILE
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID.
- DATASET: der Name des Datasets, das die Routine enthält, die Sie aktualisieren möchten.
- ROUTINE: der Name der Ressource, die aktualisiert werden soll
- PATH_TO_FILE: der Pfad zur JSON-Datei auf dem lokalen Computer
In der Richtliniendatei bleibt der Wert für
version1. Diese Nummer bezieht sich auf die Schemaversion der IAM-Richtlinie, nicht auf die Version der Richtlinie. Der Wert füretagist die Versionsnummer der Richtlinie.Nehmen Sie die Änderungen im Abschnitt
accessder JSON-Datei vor. Sie können beliebigespecialGroup-Einträge entfernen:projectOwners,projectWriters,projectReadersundallAuthenticatedUsers. Sie können auch die folgenden Elemente entfernen:userByEmail,groupByEmailunddomain.Der Abschnitt
accessder JSON-Datei einer Routine sieht beispielsweise so aus:{ "bindings": [ { "role": "roles/bigquery.dataViewer", "members": [ "user:user@example.com", "group:group@example.com", "domain:google.com", ] }, ], "etag": "BwWWja0YfJA=", "version": 1 }
Aktualisieren Sie Ihre Zugriffsrichtlinie mit dem Befehl
bq set-iam-policy.bq set-iam-policy --routine PROJECT_ID:DATASET.ROUTINE PATH_TO_FILE
Geben Sie den Befehl
get-iam-policynoch einmal ein, ohne die Informationen in eine Datei zu schreiben, um die Änderungen der Zugriffssteuerung zu prüfen:bq get-iam-policy --routine --format=prettyjson PROJECT_ID:DATASET.ROUTINE
Rufen Sie die Methode
routines.getIamPolicyauf, um die aktuelle Richtlinie abzurufen.Bearbeiten Sie die Richtlinie, um Hauptkonten oder Bindungen oder beides hinzuzufügen. Das für die Richtlinie erforderliche Format finden Sie im Referenzthema Richtlinien.
API
Geerbte Zugriffssteuerungen für eine Ressource ansehen
Sie können die geerbten IAM-Rollen für eine Ressource über die BigQuery-Web-UI ansehen. Sie benötigen die entsprechenden Berechtigungen, um die Übernahme in der Console aufzurufen. So prüfen Sie die Übernahme für ein Dataset, eine Tabelle, eine Ansicht oder eine Routine:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Wählen Sie im Bereich Explorer das Dataset aus oder maximieren Sie es und wählen Sie eine Tabelle, Ansicht oder Routine aus.
Klicken Sie für ein Dataset auf Freigabe. Klicken Sie bei einer Tabelle, Ansicht oder Routine auf Freigeben.
Prüfen Sie, ob die Option Geerbte Rollen in Tabelle anzeigen aktiviert ist.

Maximieren Sie eine Rolle in der Tabelle.
In der Spalte Übernahme gibt das sechseckige Symbol an, ob die Rolle von einer übergeordneten Ressource übernommen wurde.
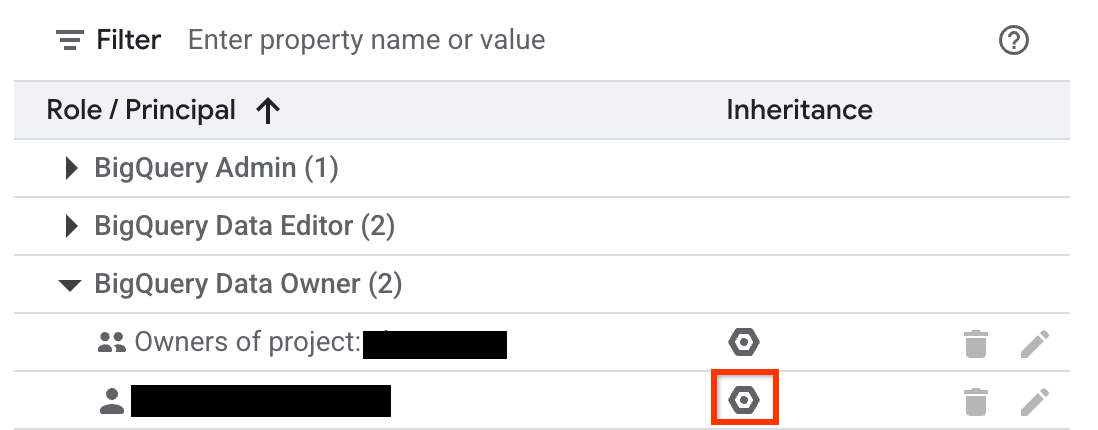
Zugriff auf eine Ressource verweigern
Mit IAM-Ablehnungsrichtlinien können Sie Leitlinien für den Zugriff auf BigQuery-Ressourcen festlegen. Sie können Ablehnungsregeln definieren, die verhindern, dass ausgewählte Hauptkonten bestimmte Berechtigungen verwenden, unabhängig von den ihnen zugewiesenen Rollen.
Informationen zum Erstellen, Aktualisieren und Löschen von Ablehnungsrichtlinien finden Sie unter Zugriff auf Ressourcen verweigern.
Sonderfälle
Berücksichtigen Sie die folgenden Szenarien, wenn Sie IAM-Ablehnungsrichtlinien für einige BigQuery-Berechtigungen erstellen:
Mit dem Zugriff auf autorisierte Ressourcen (Ansichten, Routinen, Datasets oder gespeicherte Prozeduren) können Sie eine Tabelle erstellen, löschen} oder bearbeiten sowie Tabellendaten lesen und ändern, auch wenn Sie keine direkte Berechtigung für diese Vorgänge haben. Sie können außerdem Modelldaten oder Metadaten abrufen und andere gespeicherte Prozeduren für die zugrunde liegende Tabelle aufrufen. Das bedeutet, dass die autorisierten Ressourcen die folgenden Berechtigungen haben:
bigquery.tables.getbigquery.tables.listbigquery.tables.getDatabigquery.tables.updateDatabigquery.tables.createbigquery.tables.deletebigquery.routines.getbigquery.routines.listbigquery.datasets.getbigquery.models.getDatabigquery.models.getMetadata
Wenn Sie den Zugriff auf diese autorisierten Ressourcen verweigern möchten, fügen Sie beim Erstellen der Ablehnungsrichtlinie einen der folgenden Werte in das Feld
deniedPrincipalein:Wert Anwendungsfall principalSet://goog/public:allBlockiert alle Hauptkonten, einschließlich autorisierter Ressourcen. principalSet://bigquery.googleapis.com/projects/PROJECT_NUMBER/*Blockiert alle autorisierten BigQuery-Ressourcen im angegebenen Projekt. PROJECT_NUMBERist eine automatisch generierte eindeutige Kennung für Ihr Projekt vom TypINT64.Wenn Sie bestimmte Hauptkonten von der Ablehnungsrichtlinie ausnehmen möchten, geben Sie diese Hauptkonten im Feld
exceptionPrincipalsIhrer Ablehnungsrichtlinie an. Beispiel:exceptionPrincipals: "principalSet://bigquery.googleapis.com/projects/1234/*"BigQuery speichert Abfrageergebnisse eines Jobinhabers 24 Stunden lang im Cache. Der Jobinhaber kann darauf zugreifen, ohne die Berechtigung
bigquery.tables.getDatafür die Tabelle mit den Daten zu benötigen. Wenn Sie also der Berechtigungbigquery.tables.getDataeine IAM-Ablehnungsrichtlinie hinzufügen, wird der Zugriff auf zwischengespeicherte Ergebnisse für den Jobinhaber erst blockiert, wenn der Cache abläuft. Wenn Sie den Zugriff des Jobinhabers auf zwischengespeicherte Ergebnisse blockieren möchten, erstellen Sie eine separate Ablehnungsrichtlinie für die Berechtigungbigquery.jobs.create.Um unbeabsichtigten Datenzugriff zu verhindern, wenn Sie Richtlinien zum Verweigern verwenden, um Lesevorgänge für Daten zu blockieren, empfehlen wir, dass Sie auch alle vorhandenen Abonnements für das Dataset überprüfen und widerrufen.
Wenn Sie eine IAM-Ablehnungsrichtlinie zum Ansehen von Dataset-Zugriffssteuerungen erstellen möchten, lehnen Sie die folgenden Berechtigungen ab:
bigquery.datasets.getbigquery.datasets.getIamPolicy
Wenn Sie eine IAM-Ablehnungsrichtlinie zum Aktualisieren der Zugriffssteuerung für Datasets erstellen möchten, lehnen Sie die folgenden Berechtigungen ab:
bigquery.datasets.updatebigquery.datasets.setIamPolicy
Nächste Schritte
projects.testIamPermissions-Methode zum Testen des Nutzerzugriffs auf eine Ressource