Amazon S3-Übertragungen
Mit BigQuery Data Transfer Service für Amazon S3 connector können Sie wiederkehrende Ladejobs von Amazon S3 in BigQuery automatisch planen und verwalten.
Vorbereitung
Bevor Sie eine Amazon S3-Datenübertragung erstellen, sind folgende Schritte erforderlich:
- Überprüfen Sie, ob Sie alle erforderlichen Aktionen ausgeführt haben, damit Sie den BigQuery Data Transfer Service aktivieren können.
- Erstellen Sie ein BigQuery-Dataset zum Speichern Ihrer Daten.
- Erstellen Sie die Zieltabelle für Ihre Datenübertragung und geben Sie die Schemadefinition an. Die Zieltabelle muss den Regeln für die Tabellenbenennung folgen. In Namen von Zieltabellen sind auch Parameter möglich.
- Rufen Sie Ihren Amazon S3-URI, Ihre Zugriffsschlüssel-ID und Ihren geheimen Zugriffsschlüssel ab. Informationen zum Verwalten Ihrer Zugriffsschlüssel finden Sie in der AWS-Dokumentation.
- Wenn Sie Benachrichtigungen über die Übertragungsausführung für Pub/Sub einrichten möchten, benötigen Sie die Berechtigungen
pubsub.topics.setIamPolicy. Pub/Sub-Berechtigungen sind nicht erforderlich, wenn Sie nur E-Mail-Benachrichtigungen einrichten. Weitere Informationen finden Sie unter Ausführungsbenachrichtigungen im BigQuery Data Transfer Service.
Beschränkungen
Amazon S3-Datenübertragungen unterliegen den folgenden Beschränkungen:
- Der Bucket-Teil des Amazon S3-URI kann nicht parametrisiert werden.
- Bei Datenübertragungen von Amazon S3 mit dem auf
WRITE_TRUNCATEeingestellten Parameter Schreibanordnung werden bei jeder Ausführung alle übereinstimmenden Dateien in Google Cloud übertragen. Dies kann zu zusätzlichen Kosten für die ausgehende Amazon S3-Datenübertragung führen. Weitere Informationen dazu, welche Dateien während einer Ausführung übertragen werden, finden Sie unter Auswirkungen von Präfixabgleichen gegenüber Platzhalterabgleichen. - Datenübertragungen aus AWS GovCloud-Regionen (
us-gov) werden nicht unterstützt. - Datenübertragungen zu BigQuery Omni-Speicherorten werden nicht unterstützt.
Je nach Format Ihrer Amazon S3-Quelldaten sind weitere Beschränkungen möglich. Weitere Informationen erhalten Sie hier:
Das Standardintervall für wiederkehrende Datenübertragungen beträgt 24 Stunden. Das Standardintervall für eine wiederkehrende Datenübertragung beträgt 24 Stunden.
Erforderliche Berechtigungen
Vor dem Erstellen einer Amazon S3-Datenübertragung sind folgende Schritte erforderlich:
Sorgen Sie dafür, dass die Person, die die Datenübertragung erstellt, die folgenden Berechtigungen in BigQuery hat:
bigquery.transfers.update-Berechtigungen zum Erstellen der Datenübertragung- Die Berechtigungen
bigquery.datasets.getundbigquery.datasets.updatefür das Ziel-Dataset
Die vordefinierte IAM-Rolle
bigquery.adminenthält die Berechtigungenbigquery.transfers.update,bigquery.datasets.updateundbigquery.datasets.get. Weitere Informationen zu IAM-Rollen in BigQuery Data Transfer Service finden Sie in der Zugriffssteuerung.Prüfen Sie anhand der Dokumentation zu Amazon S3, ob Sie alle erforderlichen Berechtigungen zum Aktivieren der Datenübertragung konfiguriert haben. Auf die Amazon S3-Quelldaten muss mindestens die AWS-Verwaltungsrichtlinie
AmazonS3ReadOnlyAccessangewendet werden.
Eine Amazon S3-Datenübertragung einrichten
Führen Sie zum Erstellen einer Amazon S3-Datenübertragung folgende Schritte aus:
Console
Rufen Sie in der Google Cloud Console die Seite Datenübertragungen auf.
Klicken Sie auf Übertragung erstellen.
Auf der Seite Übertragung erstellen:
Wählen Sie im Abschnitt Source type (Quelltyp) für Source (Quelle) die Option Amazon S3 aus.

Geben Sie im Abschnitt Transfer config name (Konfigurationsname für Übertragung) für Display name (Anzeigename) einen Namen wie
My Transferfür die Übertragung ein. Der Übertragungsname kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.
Im Abschnitt Zeitplanoptionen:
Wählen Sie eine Wiederholungshäufigkeit aus. Wenn Sie Stunden, Tage, Wochen oder Monate auswählen, müssen Sie auch eine Häufigkeit angeben. Sie können auch Benutzerdefiniert auswählen, um eine genauere Wiederholungshäufigkeit festzulegen. Wenn Sie On-Demand auswählen, wird diese Datenübertragung nur ausgeführt, wenn Sie die Übertragung manuell auslösen.
Wählen Sie gegebenenfalls Jetzt starten oder Zu festgelegter Zeit starten aus und geben Sie ein Startdatum und eine Laufzeit an.
Wählen Sie im Abschnitt Destination settings (Zieleinstellungen) für Destination dataset (Ziel-Dataset) das Dataset aus, das Sie zum Speichern Ihrer Daten erstellt haben.

Im Abschnitt Data source details:
- Geben Sie für Destination table (Zieltabelle) den Namen der Tabelle ein, die Sie zum Speichern Ihrer Daten in BigQuery erstellt haben. In Namen von Zieltabellen sind auch Parameter möglich.
- Für Amazon S3-URI geben Sie den URI im folgenden Format ein
s3://mybucket/myfolder/.... In URIs sind auch Parameter möglich. - Geben Sie für die Access key ID (Zugangsschlüssel-ID) Ihre Zugangsschlüssel-ID ein.
- Geben Sie für Secret access key (geheimer Zugriffsschlüssel) Ihren geheimen Zugriffsschlüssel ein.
- Wählen Sie für File format (Dateiformat) Ihr Datenformat aus: newline delimited JSON (durch Zeilenumbruch getrennte JSON), Avro, Parquet oder ORC.
Wählen Sie unter Schreibanordnung eine der folgenden Optionen aus:
WRITE_APPEND, um neue Daten an die vorhandene Zieltabelle inkrementell anzuhängen.WRITE_APPENDist der Standardwert für die Schreibeinstellung.WRITE_TRUNCATE, um Daten in der Zieltabelle bei jeder Datenübertragungsausführung zu überschreiben.
Weitere Informationen dazu, wie der BigQuery Data Transfer Service Daten mit
WRITE_APPENDoderWRITE_TRUNCATEaufnimmt, finden Sie unter Datenaufnahme für Amazon S3-Übertragungen. Weitere Informationen zum FeldwriteDispositionfinden Sie unterJobConfigurationLoad.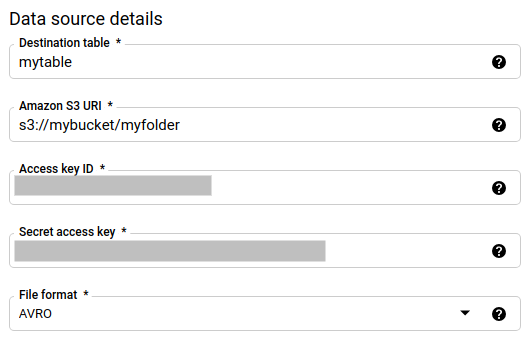
Im Bereich Übertragungsoptionen – alle Formate gehen Sie so vor:
- Geben Sie unter Anzahl zulässiger Fehler einen ganzzahligen Wert für die maximale Anzahl der fehlerhaften Datensätze ein, die ignoriert werden können.
- (Optional) Geben Sie unter Dezimalzieltypen eine durch Kommas getrennte Liste möglicher SQL-Datentypen ein, in die Quelldezimalwerte konvertiert werden können. Welcher SQL-Datentyp für die Konvertierung ausgewählt wird, hängt von folgenden Bedingungen ab:
- Der für die Konvertierung ausgewählte Datentyp ist der erste Datentyp in der folgenden Liste, der die Genauigkeit und die Skalierung der Quelldaten in dieser Reihenfolge unterstützt: NUMERIC, BIGNUMERIC und STRING.
- Wenn keiner der aufgelisteten Datentypen die Genauigkeit und die Skalierung unterstützt, wird der Datentyp ausgewählt, der den in der angegebenen Liste breitesten Bereich unterstützt. Geht ein Wert beim Lesen der Quelldaten über den unterstützten Wert hinaus, wird ein Fehler ausgegeben.
- Der Datentyp STRING unterstützt alle Genauigkeits- und Skalierungswerte.
- Wenn dieses Feld leer bleibt, wird der Datentyp standardmäßig auf „NUMERIC,STRING“ für ORC und „NUMERIC“ für die anderen Dateiformate gesetzt.
- Dieses Feld darf keine doppelten Datentypen enthalten.
- Die Reihenfolge der Datentypen, die Sie in diesem Feld auflisten, wird ignoriert.

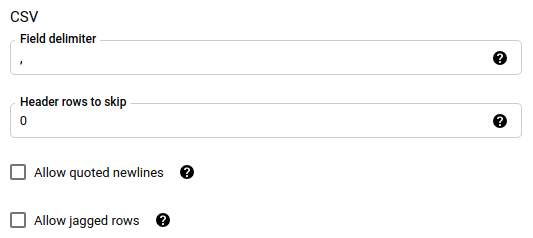
Wenn Sie als Dateiformat CSV oder JSON ausgewählt haben, aktivieren Sie im Abschnitt JSON, CSV die Option Ignore unknown values (Unbekannte Werte ignorieren), um Zeilen zu akzeptieren, die Werte enthalten, die nicht mit dem Schema übereinstimmen. Unbekannte Werte werden ignoriert. Bei CSV-Dateien werden zusätzliche Werte am Ende einer Zeile ignoriert.

Wenn Sie als Dateiformat CSV oder JSON ausgewählt haben, geben Sie im Abschnitt CSV weitere CSV-Optionen zum Laden von Daten ein.
Wählen Sie im Menü Dienstkonto ein Dienstkonto aus den Dienstkonten aus, die mit Ihrem Google Cloud-Projekt verknüpft sind. Sie können Ihre Datenübertragung mit einem Dienstkonto verknüpfen, anstatt Ihre Nutzeranmeldedaten zu verwenden. Weitere Informationen zur Verwendung von Dienstkonten mit Datenübertragungen finden Sie unter Dienstkonten verwenden.
- Wenn Sie sich mit einer föderierten Identität angemeldet haben, ist ein Dienstkonto zum Erstellen einer Übertragung erforderlich. Wenn Sie sich mit einem Google-Konto angemeldet haben, ist ein Dienstkonto für die Datenübertragung optional.
- Das Dienstkonto muss die erforderlichen Berechtigungen haben.
(Optional) Im Abschnitt Notification options (Benachrichtigungsoptionen):
- Klicken Sie auf den Umschalter, um E-Mail-Benachrichtigungen zu aktivieren. Wenn Sie diese Option aktivieren, erhält der Übertragungsadministrator eine E-Mail-Benachrichtigung, wenn ein Datenübertragungsvorgang fehlschlägt.
- Wählen Sie für Select a Pub/Sub topic (Pub/Sub-Thema auswählen) den Namen Ihres Themas aus oder klicken Sie auf Create a topic (Thema erstellen), um eines zu erstellen. Mit dieser Option werden Pub/Sub-Ausführungsbenachrichtigungen für Ihre Datenübertragung konfiguriert.
Klicken Sie auf Speichern.
bq
Geben Sie den Befehl bq mk ein und geben Sie das Flag --transfer_config für die Übertragungserstellung an.
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
Dabei gilt:
- project_id: Optional. Ihre Google Cloud-Projekt-ID.
Wenn
--project_idnicht bereitgestellt wird, um ein bestimmtes Projekt anzugeben, wird das Standardprojekt verwendet. - data_source: erforderlich. Die Datenquelle:
amazon_s3. - display_name: erforderlich. Der Anzeigename für die Datenübertragungskonfiguration. Der Übertragungsname kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.
- dataset: erforderlich. Das Ziel-Dataset für die Datenübertragungskonfiguration.
- service_account ist der Name des Dienstkontos, der zur Authentifizierung der Datenübertragung verwendet wird. Das Dienstkonto sollte zum selben
project_idgehören, das für die Erstellung der Datenübertragung verwendet wurde, und sollte alle erforderlichen Berechtigungen haben. parameters: erforderlich. Die Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel:
--params='{"param":"param_value"}'. Im Folgenden finden Sie die Parameter für eine Amazon S3-Übertragung:- destination_table_name_template: erforderlich. Der Name der Zieltabelle.
data_path: erforderlich. Der Amazon S3-URI im folgenden Format:
s3://mybucket/myfolder/...In URIs sind auch Parameter möglich.
access_key_id: erforderlich. Ihre Zugriffsschlüssel-ID.
secret_access_key: erforderlich. Ihr geheimer Zugriffsschlüssel.
file_format: Optional. Gibt den Typ der Dateien an, die Sie übertragen möchten:
CSV,JSON,AVRO,PARQUEToderORC. Der Standardwert istCSV.write_disposition: Optional.
WRITE_APPENDüberträgt nur die Dateien, die seit der letzten erfolgreichen Ausführung geändert wurden.WRITE_TRUNCATEüberträgt alle übereinstimmenden Dateien, einschließlich Dateien, die bei einer vorherigen Ausführung übertragen wurden. Der Standardwert istWRITE_APPEND.max_bad_records: Optional. Die Anzahl der zulässigen ungültigen Datensätze. Der Standardwert ist
0.decimal_target_types: Optional. Eine durch Kommas getrennte Liste möglicher SQL-Datentypen, in die die Dezimalwerte der Quelle konvertiert werden können. Wenn dieses Feld nicht angegeben ist, ist der Datentyp standardmäßig für "NUMERIC,STRING" für ORC und "NUMERIC" für die anderen Dateiformate festgelegt.
ignore_unknown_values: Optional und wird ignoriert, wenn file_format nicht
JSONoderCSVist. Gibt an, ob unbekannte Werte in Ihren Daten ignoriert werden sollen.field_delimiter: Optional und gilt nur, wenn
file_formatgleichCSVist. Das Zeichen, das Felder trennt. Der Standardwert ist ein Komma.skip_leading_rows: Optional und gilt nur, wenn file_format gleich
CSVist. Gibt die Anzahl der Kopfzeilen an, die nicht importiert werden sollen. Der Standardwert ist0.allow_quoted_newlines: Optional und gilt nur, wenn file_format gleich
CSVist. Gibt an, ob Zeilenumbrüche in Feldern in Anführungszeichen zulässig sind.allow_jagged_rows: Optional und gilt nur, wenn file_format gleich
CSVist. Gibt an, ob Zeilen ohne nachgestellte optionale Spalten zulässig sind. Die fehlenden Werte werden mit NULL gefüllt.
Mit dem folgenden Befehl wird beispielsweise eine Amazon S3-Datenübertragung mit dem Namen My Transfer erstellt. Dabei werden ein data_path mit einem Wert von s3://mybucket/myfile/*.csv, das Ziel-Dataset mydataset und bei file_format das Dateiformat CSV verwendet. Dieses Beispiel enthält nicht standardmäßige Werte für die optionalen Parameter, die dem CSV-Dateiformat zugeordnet sind.
Die Datenübertragung wird im Standardprojekt erstellt:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
Nachdem Sie den Befehl ausgeführt haben, erhalten Sie eine Meldung wie die Folgende:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Folgen Sie der Anleitung und fügen Sie den Authentifizierungscode in die Befehlszeile ein.
API
Verwenden Sie die Methode projects.locations.transferConfigs.create und geben Sie eine Instanz der Ressource TransferConfig an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Auswirkungen von Präfixabgleichen gegenüber Platzhalterabgleichen
Die Amazon S3 API unterstützt den Präfixabgleich, nicht aber den Platzhalterabgleich. Alle Amazon S3-Dateien, die mit einem Präfix übereinstimmen, werden in Google Cloud übertragen. Dabei werden jedoch nur die Dateien in BigQuery geladen, die mit der Amazon S3-URI in der Übertragungskonfiguration übereinstimmen. Das kann zu übermäßigen Kosten bei der ausgehenden Amazon S3-Datenübertragung für Dateien führen, die zwar übertragen, aber nicht in BigQuery geladen werden.
Sehen Sie sich als Beispiel diesen Datenpfad an:
s3://bucket/folder/*/subfolder/*.csv
Zusammen mit diesen Dateien am Quellspeicherort:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
Damit werden alle Amazon S3-Dateien mit dem Präfix s3://bucket/folder/ an Google Cloud übertragen. In diesem Beispiel werden file1.csv und file2.csv übertragen.
Es werden aber nur Dateien, die mit s3://bucket/folder/*/subfolder/*.csv übereinstimmen, in BigQuery geladen. In diesem Beispiel wird nur file1.csv in BigQuery geladen.
Fehler bei der Übertragungseinrichtung beheben
Bei Problemen mit dem Einrichten von Datenübertragungen finden Sie weitere Informationen unter Amazon S3-Übertragungsprobleme.
Nächste Schritte
- Eine Einführung in Amazon S3-Datenübertragungen finden Sie unter Übersicht über Amazon S3-Übertragungen.
- Eine Übersicht über BigQuery Data Transfer Service finden Sie unter Einführung in BigQuery Data Transfer Service.
- Informationen zum Verwenden von Datenübertragungen, einschließlich des Abrufs von Informationen zu einer Übertragungskonfiguration, des Auflistens von Übertragungskonfigurationen und des Aufrufs des Ausführungsverlaufs der Übertragung finden Sie unter Mit Übertragungen arbeiten.
- Daten mit cloudübergreifenden Vorgängen laden