Batchinferenzen sind asynchrone Anfragen, die Inferenzen direkt von der Modellressource anfordern, ohne das Modell auf einem Endpunkt bereitstellen zu müssen.
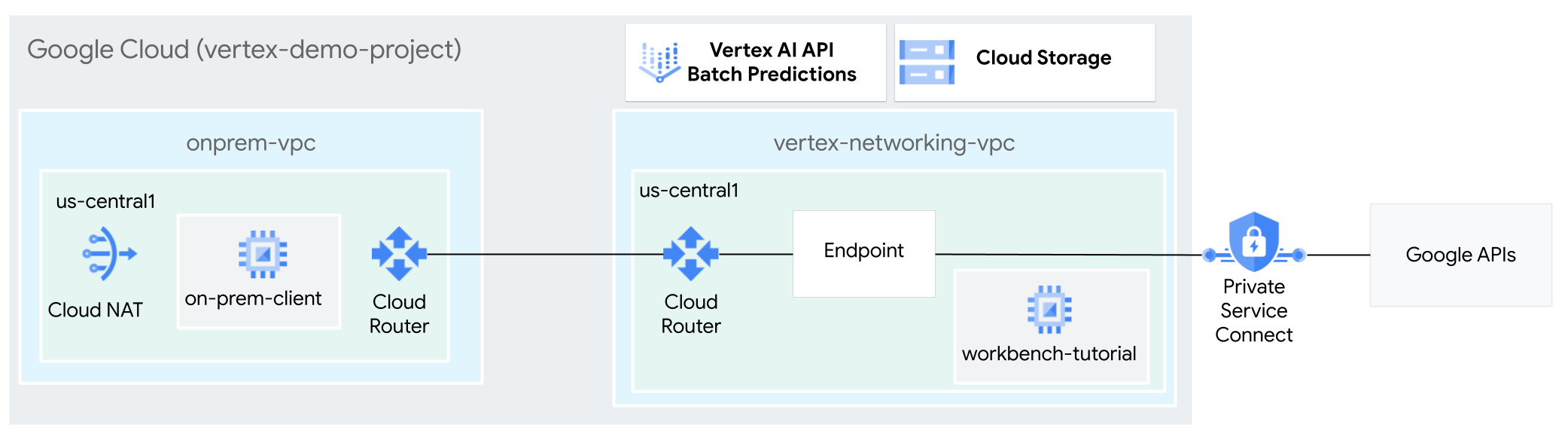
In dieser Anleitung verwenden Sie ein Hochverfügbarkeits-VPN (HA VPN), um Batchinferenzanfragen privat an ein trainiertes Modell zu senden, zwischen zwei Virtual Private Cloud-Netzwerken, die als Grundlage für Multi-Cloud-Netzwerke dienen können und lokale private Verbindung.
Diese Anleitung richtet sich an Unternehmensnetzwerkadministratoren, Data Scientists und Forscher, die mit Vertex AI, Virtual Private Cloud (VPC), der Google Cloud Console und Cloud Shell vertraut sind. Kenntnisse über Vertex AI Workbench sind hilfreich, aber nicht erforderlich.
VPC-Netzwerke erstellen
In diesem Abschnitt erstellen Sie zwei VPC-Netzwerke: Ein VPC-Netzwerk für den Zugriff auf Google APIs für die Batchinferenz und das andere zur Simulation eines lokalen Netzwerks. In jedem der beiden VPC-Netzwerke erstellen Sie einen Cloud Router und ein Cloud NAT-Gateway. Ein Cloud NAT-Gateway bietet ausgehende Verbindungen für Compute Engine-VM-Instanzen ohne externe IP-Adressen.
vertex-networking-vpc-VPC-Netzwerk erstellengcloud compute networks create vertex-networking-vpc \ --subnet-mode customErstellen Sie im Netzwerk
vertex-networking-vpcein Subnetz mit dem Namenworkbench-subnetund dem primären IPv4-Bereich von10.0.1.0/28:gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessErstellen Sie das VPC-Netzwerk, um das lokale Netzwerk (
onprem-vpc) zu simulieren:gcloud compute networks create onprem-vpc \ --subnet-mode customErstellen Sie im Netzwerk
onprem-vpcein Subnetz mit dem Namenonprem-vpc-subnet1und dem primären IPv4-Bereich von172.16.10.0/29:gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
Prüfen, ob die VPC-Netzwerke richtig konfiguriert sind
Rufen Sie in der Google Cloud Console den Tab Netzwerke im aktuellen Projekt auf der Seite VPC-Netzwerke auf.
Prüfen Sie in der Liste der VPC-Netzwerke, ob die beiden Netzwerke erstellt wurden:
vertex-networking-vpcundonprem-vpc.Klicken Sie auf den Tab Subnetze im aktuellen Projekt.
Prüfen Sie in der Liste der VPC-Subnetze, ob die Subnetze
workbench-subnetundonprem-vpc-subnet1erstellt wurden.
Hybridkonnektivität konfigurieren
In diesem Abschnitt erstellen Sie zwei HA VPN-Gateways, die miteinander verbunden sind. Eines befindet sich im VPC-Netzwerk vertex-networking-vpc. Das andere befindet sich im VPC-Netzwerk onprem-vpc. Jedes Gateway enthält einen Cloud Router und ein VPN-Tunnelpaar.
HA VPN-Gateways erstellen
Erstellen Sie in Cloud Shell das HA VPN-Gateway für das VPC-Netzwerk
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Erstellen Sie das HA VPN-Gateway für das VPC-Netzwerk
onprem-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1Wechseln Sie in der Google Cloud -Console auf der Seite VPN zum Tab Cloud VPN-Gateways.
Prüfen Sie, ob die beiden Gateways (
vertex-networking-vpn-gw1undonprem-vpn-gw1) erstellt wurden und ob jedes Gateway zwei Schnittstellen-IP-Adressen hat.
Cloud Router und Cloud NAT-Gateways erstellen
In jedem der beiden VPC-Netzwerke erstellen Sie zwei Cloud Router: einen allgemeinen und einen regionalen. In jedem der regionalen Cloud Router erstellen Sie ein Cloud NAT-Gateway. Cloud NAT-Gateways bieten ausgehende Verbindungen für Compute Engine-VM-Instanzen ohne externe IP-Adressen.
Erstellen Sie in Cloud Shell einen Cloud Router für das VPC-Netzwerk
vertex-networking-vpc:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001Erstellen Sie einen Cloud Router für das VPC-Netzwerk
onprem-vpc:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002Erstellen Sie einen regionalen Cloud Router für das VPC-Netzwerk
vertex-networking-vpc:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Konfigurieren Sie ein Cloud NAT-Gateway auf dem regionalen Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Erstellen Sie einen regionalen Cloud Router für das VPC-Netzwerk
onprem-vpc:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1Konfigurieren Sie ein Cloud NAT-Gateway auf dem regionalen Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Rufen Sie in der Google Cloud Console die Seite Cloud Router auf.
Prüfen Sie in der Liste Cloud Router, ob die folgenden Router erstellt wurden:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
Möglicherweise müssen Sie den Browsertab der Google Cloud -Konsole aktualisieren, um die neuen Werte zu sehen.
Klicken Sie in der Liste der Cloud Router auf
cloud-router-us-central1-vertex-nat.Prüfen Sie auf der Seite Routerdetails, ob das Cloud NAT-Gateway
cloud-nat-us-central1erstellt wurde.Klicken Sie auf den Zurückpfeil, um zur Seite Cloud Router zurückzukehren.
Klicken Sie in der Liste der Router auf
cloud-router-us-central1-onprem-nat.Prüfen Sie auf der Seite Routerdetails, ob das Cloud NAT-Gateway
cloud-nat-us-central1-on-premerstellt wurde.
VPN-Tunnel erstellen
Erstellen Sie in der Cloud Shell im Netzwerk
vertex-networking-vpceinen VPN-Tunnel mit dem Namenvertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Erstellen Sie im Netzwerk
vertex-networking-vpceinen VPN-Tunnel mit dem Namenvertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Erstellen Sie im Netzwerk
onprem-vpceinen VPN-Tunnel mit dem Namenonprem-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Erstellen Sie im Netzwerk
onprem-vpceinen VPN-Tunnel mit dem Namenonprem-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Rufen Sie in der Google Cloud Console die Seite VPN auf.
Prüfen Sie in der Liste der VPN-Tunnel, ob die vier VPN-Tunnel erstellt wurden.
BGP-Sitzungen erstellen
Cloud Router verwendet das Border Gateway Protocol (BGP), um Routen zwischen Ihrem VPC-Netzwerk (in diesem Fall vertex-networking-vpc) und Ihrem lokalen Netzwerk (dargestellt durch onprem-vpc) auszutauschen. Auf dem Cloud Router konfigurieren Sie eine Schnittstelle und einen BGP-Peer für Ihren lokalen Router.
Die Konfigurationen für Schnittstelle und BGP-Peer bilden zusammen eine BGP-Sitzung.
In diesem Abschnitt erstellen Sie zwei BGP-Sitzungen für vertex-networking-vpc und zwei für onprem-vpc.
Nachdem Sie die Schnittstellen und BGP-Peers zwischen Ihren Routern konfiguriert haben, beginnen sie automatisch mit dem Austausch von Routen.
BGP-Sitzungen für vertex-networking-vpc erstellen
Erstellen Sie in Cloud Shell im Netzwerk
vertex-networking-vpceine BGP-Schnittstelle fürvertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Erstellen Sie im Netzwerk
vertex-networking-vpceinen BGP-Peer fürbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Erstellen Sie im Netzwerk
vertex-networking-vpceine BGP-Schnittstelle fürvertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Erstellen Sie im Netzwerk
vertex-networking-vpceinen BGP-Peer fürbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
BGP-Sitzungen für onprem-vpc erstellen
Erstellen Sie im Netzwerk
onprem-vpceine BGP-Schnittstelle füronprem-vpc-tunnel0:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1Erstellen Sie im Netzwerk
onprem-vpceinen BGP-Peer fürbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Erstellen Sie im Netzwerk
onprem-vpceine BGP-Schnittstelle füronprem-vpc-tunnel1:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1Erstellen Sie im Netzwerk
onprem-vpceinen BGP-Peer fürbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
BGP-Sitzungserstellung prüfen
Rufen Sie in der Google Cloud Console die Seite VPN auf.
Prüfen Sie in der Liste der VPN-Tunnel, ob sich der Wert in der Spalte BGP-Sitzungsstatus für jeden Tunnel von BGP-Sitzung konfigurieren in BGP eingerichtet gändert. Möglicherweise müssen Sie den Browsertab der Google Cloud -Konsole aktualisieren, um die neuen Werte zu sehen.
Erkannte Routen vertex-networking-vpc validieren
Rufen Sie in der Google Cloud Console die Seite VPC-Netzwerke auf.
Klicken Sie in der Liste der VPC-Netzwerke auf
vertex-networking-vpc.Klicken Sie auf den Tab Routen.
Wählen Sie in der Liste Region die Option us-central1 (Iowa) aus und klicken Sie auf Ansehen.
Prüfen Sie in der Spalte Ziel-IP-Adressbereich, ob der IP-Bereich des Subnetzes
onprem-vpc-subnet1(172.16.10.0/29) zweimal angezeigt wird.
Erkannte Routen onprem-vpc validieren
Klicken Sie auf den Zurückpfeil, um zur Seite VPC-Netzwerke zurückzukehren.
Klicken Sie in der Liste der VPC-Netzwerke auf
onprem-vpc.Klicken Sie auf den Tab Routen.
Wählen Sie in der Liste Region die Option us-central1 (Iowa) aus und klicken Sie auf Ansehen.
Prüfen Sie in der Spalte Ziel-IP-Adressbereich, ob der Subnetz-IP-Bereich
workbench-subnet(10.0.1.0/28) zweimal angezeigt wird.
Private Service Connect-Nutzerendpunkt erstellen
Reservieren Sie in Cloud Shell eine Nutzerendpunkt-IP-Adresse, die für den Zugriff auf Google APIs verwendet wird:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcErstellen Sie eine Weiterleitungsregel, um den Endpunkt mit Google APIs und Google-Diensten zu verbinden.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Benutzerdefinierte beworbene Routen für vertex-networking-vpc erstellen
In diesem Abschnitt konfigurieren Sie den benutzerdefinierten Advertisement-Modus von Cloud Router, um benutzerdefinierte IP-Bereiche anzubieten für vertex-networking-vpc-router1 (den Cloud Router für vertex-networking-vpc). ) um die IP-Adresse des PSC-Endpunkts gegenüber dem Netzwerk onprem-vpc anzubieten.
Rufen Sie in der Google Cloud Console die Seite Cloud Router auf.
Klicken Sie in der Liste der Cloud Router auf
vertex-networking-vpc-router1.Klicken Sie auf der Seite Routerdetails auf Bearbeiten.
Wählen Sie im Abschnitt Beworbene Routen für Routen die Option Benutzerdefinierte Routen erstellen.
Wählen Sie das Kästchen Alle für den Cloud Router sichtbaren Subnetze bewerben aus. Damit können Sie weiterhin die Subnetze bewerben, die für den Cloud Router zur Verfügung stehen. Wenn Sie diese Option aktivieren, entspricht dies dem Verhalten von Cloud Router im standardmäßigen Advertisement-Modus.
Klicken Sie auf Benutzerdefinierte Route hinzufügen.
Wählen Sie für Quelle die Option Benutzerdefinierter IP-Bereich aus.
Geben Sie als IP-Adressbereich die folgende IP-Adresse ein:
192.168.0.1Geben Sie unter Beschreibung den folgenden Text ein:
Custom route to advertise Private Service Connect endpoint IP addressKlicken Sie auf Fertig und anschließend auf Speichern.
Prüfen, ob onprem-vpc die beworbenen Routen erlernt hat
Rufen Sie in der Google Cloud Console die Seite Routen auf.
Führen Sie auf dem Tab Aktive Routen folgende Schritte aus:
- Wählen Sie für Netzwerk die Option
onprem-vpcaus. - Wählen Sie bei Region die Option
us-central1 (Iowa)aus. - Klicken Sie auf Ansehen.
Prüfen Sie in der Liste der Routen, ob Einträge vorhanden sind, deren Namen mit
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0undonprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1beginnen, und dass beide einen Ziel-IP-Bereich von192.168.0.1haben..Wenn diese Einträge nicht sofort angezeigt werden, warten Sie einige Minuten und aktualisieren Sie dann den Browsertab der Google Cloud -Konsole.
- Wählen Sie für Netzwerk die Option
VM in onprem-vpc erstellen, die ein vom Nutzer verwaltetes Dienstkonto verwendet
In diesem Abschnitt erstellen Sie eine VM-Instanz, die eine lokale Clientanwendung simuliert, die Batchinferenzanfragen sendet. Gemäß den Best Practices für Compute Engine und IAM verwendet diese VM ein nutzerverwaltetes Dienstkonto anstelle des Compute Engine-Standarddienstkontos.
Ein vom Nutzer verwaltetes Dienstkonto erstellen
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Erstellen Sie ein Dienstkonto mit dem Namen
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"Weisen Sie dem Dienstkonto die IAM-Rolle Vertex AI User (
roles/aiplatform.user) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Weisen Sie dem Dienstkonto die IAM-Rolle Storage Object Viewer (
storage.objectViewer) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
on-prem-client
VM-Instanz erstellen
Die von Ihnen erstellte VM-Instanz hat keine externe IP-Adresse und lässt keinen direkten Zugriff über das Internet zu. Zum Aktivieren des Administratorzugriffs auf die VM verwenden Sie die TCP-Weiterleitung von Identity-Aware Proxy (IAP).
Erstellen Sie in Cloud Shell die VM-Instanz
on-prem-client:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Erstellen Sie eine Firewallregel, damit IAP eine Verbindung zu Ihrer VM-Instanz herstellen kann:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Öffentlichen Zugriff auf die Vertex AI API prüfen
In diesem Abschnitt führen Sie mit dem Dienstprogramm dig einen DNS-Lookup von der VM-Instanz on-prem-client zur Vertex AI API (us-central1-aiplatform.googleapis.com) durch. Die Ausgabe dig zeigt, dass der Standardzugriff nur öffentliche VIPs für den Zugriff auf die Vertex AI API verwendet.
Im nächsten Abschnitt konfigurieren Sie den privaten Zugriff auf die Vertex AI API.
Melden Sie sich in Cloud Shell mit IAP bei der VM-Instanz
on-prem-clientan:gcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iapFühren Sie auf der VM-Instanz
on-prem-clientden Befehldigaus:dig us-central1-aiplatform.googleapis.comDie
dig-Ausgabe sollte in etwa so aussehen, wobei die IP-Adressen im Antwortbereich öffentliche IP-Adressen sind:; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
Privaten Zugriff auf die Vertex AI API konfigurieren und validieren
In diesem Abschnitt konfigurieren Sie den privaten Zugriff auf die Vertex AI API, sodass beim Senden von Batchinferenzanfragen diese an Ihren PSC-Endpunkt weitergeleitet werden. Der PSC-Endpunkt wiederum leitet diese privaten Anfragen an die Vertex AI Batch Inference REST API weiter.
zu Aktualisieren die Datei /etc/hosts, sodass sie auf den PSC-Endpunkt verweist.
In diesem Schritt fügen Sie der Datei /etc/hosts eine Zeile hinzu, die bewirkt, dass an den öffentlichen Dienstendpunkt (us-central1-aiplatform.googleapis.com) gesendete Anfragen an den PSC-Endpunkt (192.168.0.1) weitergeleitet werden.
Verwenden Sie auf der VM-Instanz
on-prem-clienteinen Texteditor wievimodernano, um die Datei/etc/hostszu öffnen:sudo vim /etc/hostsFügen Sie der Datei die folgende Zeile hinzu:
192.168.0.1 us-central1-aiplatform.googleapis.comDiese Zeile weist dem vollständig qualifizierten Domainnamen für die Vertex AI Google API (
us-central1-aiplatform.googleapis.com) die IP-Adresse des PSC-Endpunkts (192.168.0.1) zu.Die bearbeitete Datei sollte folgendermaßen aussehen:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleSpeichern Sie die Datei so:
- Wenn Sie
vimverwenden, drücken Sie die TasteEscund geben Sie dann:wqein, um die Datei zu speichern und zu beenden. - Wenn Sie
nanoverwenden, geben SieControl+Oein und drücken SieEnter, um die Datei zu speichern. Geben Sie dann zum BeendenControl+Xein.
- Wenn Sie
Pingen Sie den Vertex AI-Endpunkt so an:
ping us-central1-aiplatform.googleapis.comDer Befehl
pingsollte Folgendes zurückgeben:192.168.0.1ist die IP-Adresse des PSC-Endpunkts:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Geben Sie
Control+Cein, umpingzu beenden.Geben Sie
exitein, um dieon-prem-client-VM-Instanz zu beenden.
Ein vom Nutzer verwaltetes Dienstkonto für Vertex AI Workbench in vertex-networking-vpc erstellen
In diesem Abschnitt erstellen Sie ein nutzerverwaltetes Dienstkonto und weisen dem Dienstkonto dann IAM-Rollen zu, um den Zugriff auf die Vertex AI Workbench-Instanz zu steuern. Wenn Sie die Instanz erstellen, geben Sie das Dienstkonto an.
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Erstellen Sie ein Dienstkonto mit dem Namen
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Weisen Sie dem Dienstkonto die IAM-Rolle Vertex AI User (
roles/aiplatform.user) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Weisen Sie dem Dienstkonto die IAM-Rolle BigQuery-Nutzer (
roles/bigquery.user) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"Weisen Sie dem Dienstkonto die IAM-Rolle Storage Admin (
roles/storage.admin) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Weisen Sie dem Dienstkonto die IAM-Rolle Logbetrachter (
roles/logging.viewer) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
Vertex AI Workbench-Instanz erstellen
Erstellen Sie in Cloud Shell eine Vertex AI Workbench-Instanz und geben Sie das Dienstkonto
workbench-saan:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.comRufen Sie in der Google Cloud Console auf der Seite Vertex AI Workbench den Tab Instanzen auf.
Klicken Sie neben dem Namen der Vertex AI Workbench-Instanz (
workbench-tutorial) auf JupyterLab öffnen.Ihre Vertex AI Workbench-Instanz öffnet JupyterLab.
Wählen Sie File > New > Notebook aus.
Wählen Sie im Menü Kernel auswählen die Option Python 3 (lokal) aus und klicken Sie auf Auswählen.
Wenn Ihr neues Notebook geöffnet wird, wird eine Standard-Codezelle angezeigt, in die Sie Code eingeben können. Sie sieht so aus:
[ ]:, gefolgt von einem Textfeld. In das Textfeld fügen Sie den Code ein.Fügen Sie den folgenden Code in die Zelle ein und klicken Sie auf Ausgewählte Zellen ausführen und fortfahren, um das Vertex AI SDK für Python zu installieren:
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2Fügen Sie in diesem und jedem der folgenden Schritte eine neue Codezelle (wenn nötig) hinzu, indem Sie auf Zelle unten einfügen klicken, den Code in die Zelle einfügen und dann auf Ausgewählte Zellen ausführen und fortfahren klicken.
Um die neu installierten Pakete in dieser Jupyter-Laufzeit zu verwenden, müssen Sie die Laufzeit neu starten:
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)Legen Sie die folgenden Umgebungsvariablen in Ihrem JupyterLab-Notebook fest und ersetzen Sie PROJECT_ID durch Ihre Projekt-ID.
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"Erstellen Sie einen Cloud Storage-Bucket für das Staging des Trainingsjobs:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gcloud storage buckets create {BUCKET_URI} --location={REGION} --project={PROJECT_ID}
Trainingsdaten vorbereiten
In diesem Abschnitt bereiten Sie Daten zum Trainieren eines Inferenzmodells vor.
Erstellen Sie in Ihrem JupyterLab-Notebook einen BigQuery-Client:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)Rufen Sie Daten aus dem öffentlichen BigQuery-Dataset
ml_datasetsab:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()Verwenden Sie die Bibliothek
sklearn, um die Daten für Training und Tests aufzuteilen:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)Exportieren Sie die Trainings- und Test-DataFrames in CSV-Dateien im Staging-Bucket:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
Trainingsanwendung vorbereiten
In diesem Abschnitt erfahren Sie, wie Sie die Python-Trainingsanwendung erstellen und erstellen und im Staging-Bucket speichern.
Erstellen Sie in Ihrem JupyterLab-Notebook einen neuen Ordner für die Trainingsanwendungsdateien:
!mkdir -p training_package/trainerSie sollten jetzt im JupyterLab-Navigationsmenü einen Ordner mit dem Namen
training_packagesehen.Definieren Sie die Features, das Ziel, das Label und die Schritte zum Trainieren und Exportieren des Modells in eine Datei:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))Erstellen Sie in jedem Unterverzeichnis eine Datei
__init__.py, um sie zu einem Paket hinzuzufügen:!touch training_package/__init__.py !touch training_package/trainer/__init__.pyErstellen Sie ein Skript zur Einrichtung des Python-Pakets:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )Verwenden Sie den Befehl
sdist, um die Quellverteilung der Trainingsanwendung zu erstellen.!cd training_package && python setup.py sdist --formats=gztarKopieren Sie das Python-Paket in den Staging-Bucket:
!gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/Prüfen Sie, ob der Staging-Bucket drei Dateien enthält:
!gcloud storage ls $BUCKET_URIDie Ausgabe sollte wie folgt aussehen:
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
Modell trainieren
In diesem Abschnitt trainieren Sie das Modell, indem Sie einen benutzerdefinierten Trainingsjob erstellen und ausführen.
Führen Sie in Ihrem JupyterLab-Notebook den folgenden Befehl aus, um einen benutzerdefinierten Trainingsjob zu erstellen:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGIONDie Ausgabe sollte ungefähr so aussehen: Die erste Zahl in jedem benutzerdefinierten Jobpfad ist die Projektnummer (PROJECT_NUMBER). Die zweite Zahl ist die benutzerdefinierte Job-ID (CUSTOM_JOB_ID). Notieren Sie sich diese Nummern, damit Sie sie im nächsten Schritt verwenden können.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832Führen Sie den benutzerdefinierten Trainingsjob aus und zeigen Sie den Fortschritt an, indem Sie Logs aus dem Job während der Ausführung streamen:
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_IDErsetzen Sie die folgenden Werte:
- PROJECT_NUMBER: die Projektnummer aus der Ausgabe des vorherigen Befehls
- CUSTOM_JOB_ID: die benutzerdefinierte Job-ID aus der Ausgabe des vorherigen Befehls
Ihr benutzerdefinierter Trainingsjob wird jetzt ausgeführt. Dieser Vorgang dauert etwa 10 Minuten.
Wenn der Job abgeschlossen ist, können Sie das Modell aus dem Staging-Bucket in Vertex AI Model Registry importieren.
Modell importieren
Ihr benutzerdefinierter Trainingsjob lädt das trainierte Modell in den Staging-Bucket hoch. Wenn der Job abgeschlossen ist, können Sie das Modell aus dem Bucket in Vertex AI Model Registry importieren.
Importieren Sie das Modell mit dem folgenden Befehl in Ihr JupyterLab-Notebook:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGIONSo listen Sie die Vertex AI-Modelle im Projekt auf:
!gcloud ai models list --region=us-central1Die Ausgabe sollte so aussehen: Wenn zwei oder mehr Modelle aufgelistet sind, ist das erste Modell in der Liste das zuletzt importierte Modell.
Notieren Sie sich den Wert in der Spalte MODEL_ID. Sie benötigen diesen, um die Batchinferenzanfrage zu erstellen.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-modelAlternativ können Sie die Modelle in Ihrem Projekt so auflisten:
Rufen Sie in der Google Cloud Console im Bereich „Vertex AI“ die Seite Vertex AI Model Registry auf.
Zur Seite "Vertex AI Model Registry"
Klicken Sie auf den Modellnamen und dann auf den Tab Versionsdetails, um die Modell-IDs und andere Details für ein Modell aufzurufen.
Batchinferenzen aus dem Modell abrufen
Jetzt können Sie Batchinferenzen vom Modell anfragen. Die Batchinferenzanfragen werden von der VM-Instanz on-prem-client gestellt.
Batchinferenzanfrage erstellen
In diesem Schritt melden Sie sich mit ssh bei der VM-Instanz on-prem-client an.
In der VM-Instanz erstellen Sie eine Textdatei mit dem Namen request.json, die die Nutzlast für eine curl-Beispielanfrage enthält, die Sie an Ihr Modell senden, um Batchinferenzen zu erhalten.
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Melden Sie sich mit
sshbei der VM-Instanzon-prem-clientan:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-aErstellen Sie auf der VM-Instanz
on-prem-clientmit einem Texteditor wievimodernanoeine neue Datei namensrequest.json, die den folgenden Text enthält:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }Ersetzen Sie die folgenden Werte:
- PROJECT_ID: Ihre Projekt-ID.
- MODEL_ID: die Modell-ID für Ihr Modell
- BUCKET_URI: der URI für den Storage-Bucket, in dem Sie das Modell bereitgestellt haben
Führen Sie den folgenden Befehl aus, um die Batchinferenzanfrage zu senden:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID.
In der Antwort sollte die folgende Zeile angezeigt werden:
"state": "JOB_STATE_PENDING"Der Batchinferenzjob wird jetzt asynchron ausgeführt. Die Ausführung dauert etwa 20 Minuten.
Rufen Sie in der Google Cloud Console unter „Vertex AI“ die Seite Batchvorhersagen auf.
Während der Batchinferenzjob ausgeführt wird, ist der Status
Running. Wenn er abgeschlossen ist, ändert sich sein Status inFinished.Klicken Sie auf den Namen Ihres Batchinferenzjobs (
income-classification-batch-job) und dann auf den Link Exportspeicherort auf der Detailseite, um die Ausgabedateien für Ihren Batchjob in Cloud Storage anzusehen.Alternativ können Sie auch auf das Symbol Vorhersageausgabe in Cloud Storage ansehen klicken (zwischen der Spalte Zuletzt aktualisiert und dem Menü Aktionen).
Klicken Sie auf den Link
prediction.results-00000-of-00002oderprediction.results-00001-of-00002und dann auf den Link Authentifizierte URL, um die Datei zu öffnen.Die Ausgabe des Batchinferenzjobs sollte in etwa so aussehen:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}