Looker では、データベースのスクラッチ スキーマに永続的な派生テーブル(PDT)が書き込まれます。Looker は永続性戦略に基づいて PDT の永続化と再構築を行います。PDTの再構築がトリガーされると、Lookerはデフォルトでテーブル全体を再構築します。
その言語が増分 PDT をサポートしている場合は、PDT 全体を再構築する代わりに最新のデータを PDT に追加することもできます。
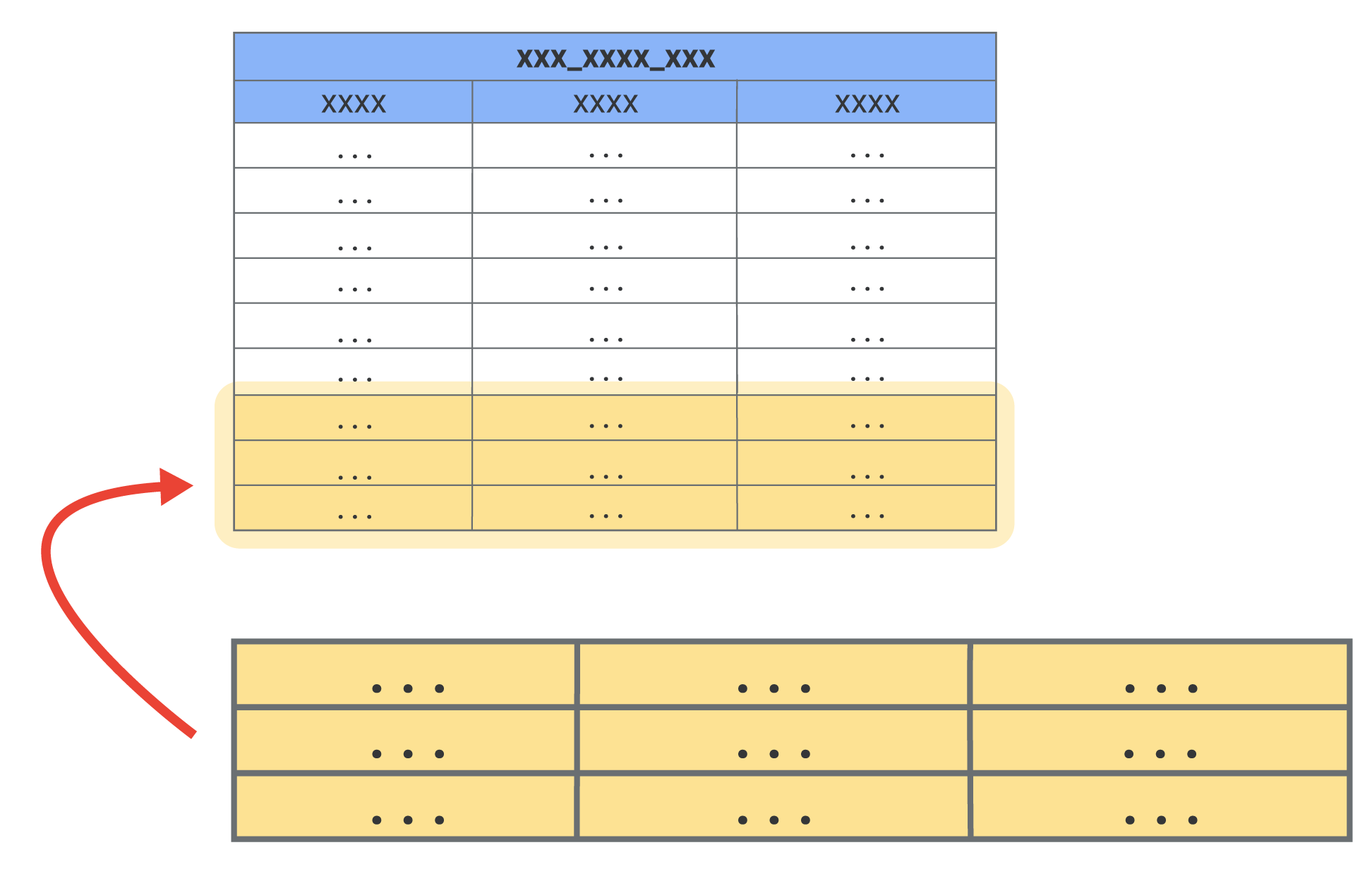
増分 PDT で初めてクエリを実行すると、Looker は PDT 全体をビルドして初期データを取得します。テーブルが大きい場合、大きなテーブルの作成と同様に、最初のビルドにかなりの時間がかかることがあります。初期テーブルが構築されると、戦略的に増分PDTが設定されているなら、それ以降の構築は増分になり必要な時間は短くなります。
さらに、増分 PDT のソーステーブルが時間ベースのクエリ用に最適化されていることを確認します。具体的には、インクリメント キーに使用される時間ベースの列には、パーティショニング、並べ替えキー、インデックスなどの最適化戦略、または言語でサポートされている最適化戦略が必要です。増分テーブルが更新されるたびに Looker がソーステーブルにクエリを実行し、インクリメント キーに使用される時間ベースの列の最新値を確認するため、ソーステーブルの最適化をおすすめします。ソーステーブルがこれらのクエリ用に最適化されていない場合、最新の値に対する Looker のクエリは速度が低下し、コストが高くなる可能性があります。
その言語が増分 PDT をサポートしている場合は、次の種類の PDT を増分 PDT にすることができます。
- 集計テーブル
- LookML ベース(ネイティブ)の PDT
SQL ベースの PDT
SQL ベースの PDT では、
sqlパラメータを使用してテーブルクエリを定義し、増分 PDT として使用する必要があります。sql_createパラメータまたはcreate_processパラメータで定義された SQL ベースの PDT は、増分ビルドできません。このページの例 1 からわかるように、Looker は INSERT または MERGE コマンドを使用して、増分 PDT の増分を作成します。Looker では正確な増分を作成するために必要な DDL ステートメントを決定できないため、カスタムのデータ定義言語(DDL)ステートメントを使用して派生テーブルを定義することはできません。
増分PDTを定義する
次のパラメーターを使用して、PDTを増分PDTにすることができます。
increment_key(PDT を増分 PDT にするために必要): 新しいレコードをクエリする期間を定義します。{% incrementcondition %}リキッド フィルタ(SQL ベースの PDT を増分 PDT にするために必要です。LookML ベースの PDT には適用されません): インクリメント キーをベースとするデータベース時間列にインクリメントキーを接続します。詳しくは、increment_keyのドキュメントをご覧ください。increment_offset(省略可): 増分ビルドごとに再ビルドされる過去の期間の数(インクリメント キーの粒度)を定義する整数。increment_offsetパラメータは、遅れて到着したデータ(これは、対応する増分が最初にビルドされて PDT に追加されたときに含まれていなかった新しいデータ)が以前の期間にある場合に便利です。
永続ネイティブ派生テーブル、永続 SQL ベースの派生テーブル、集約テーブルから増分 PDT を作成する方法については、increment_key パラメータのドキュメント ページをご覧ください。
LookMLベースの増分PDTを定義するビューファイルの簡単な例を以下に示します。
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
このテーブルは、クエリが初めて実行されるときに、全体として作成されます。その後、PDT は 1 日(increment_key: departure_date)単位で再ビルドされ、3 日(increment_offset: 3)戻ります。
increment キーは departure_date ディメンションに基づいています。これは実際には departure ディメンション グループの date 期間です。(ディメンション グループの仕組みの概要については、dimension_group パラメータのドキュメント ページをご覧ください)。ディメンション グループと期間の両方が flights ビュー(この PDT の explore_source)で定義されます。flights ビューファイルで departure ディメンション グループを定義する方法を次に示します。
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
増分パラメーターと永続性戦略の関係
PDT の increment_key 設定と increment_offset 設定は、PDT の永続性戦略とは別のものです。
- 増分 PDT の永続性戦略は、PDT が増分した場合にのみ決定されます。PDT ビルダーは、テーブルの永続化戦略がトリガーされた場合、または PDT が Explore の [Rebuild Derived Tables & Run] オプションによって手動でトリガーされない限り、増分 PDT を変更しません。
- PDT がインクリメントされると、PDT ビルダーは、最新のデータが時間増分(
increment_keyパラメータで定義された期間)の観点からテーブルに追加された日を判断します。それに基づき、PDTビルダーは、テーブルの中の最新の時間増分の開始時間までデータを切り捨てた後、そこから最新の増分を構築します。 - PDT に
increment_offsetパラメータがある場合、PDT ビルダーもincrement_offsetパラメータで指定された前の期間の数を再ビルドします。前の期間は、最新の時間単位(increment_keyパラメータで定義されている期間)の先頭から遡ります。
次のシナリオ例では、increment_key、increment_offset、永続性戦略の相互作用を示すことで、増分 PDT が更新される方法を示します。
例 1
この例で使用されるPDTのプロパティは次のとおりです:
- インクリメント キー: 日付
- 増分オフセット: 3
- 永続性戦略: 毎月 1 日にトリガーされます
このテーブルがどう更新されるかを以下に示します:
- 月ごとの永続性戦略では、テーブルは月に 1 回自動的に作成されます。つまり、例えば6月1日の時点で、テーブルに追加されていた最後の行は5月1日になります。
- このPDTの増分キーは日単位であるため、PDTビルダーは、5月1日をその日の初めまで切り捨て、5月1日と当日6月1日までのデータを再構築します。
- また、この PDT の増分オフセットは
3です。そのため、PDT ビルダーでも 5 月 1 日より前の 3 つの期間(日)のデータを再ビルドできます。その結果、4月28、29、30日、および当日6月1日までのデータが再構築されます。
SQLで言えば、既存PDTのうち再構築する必要のある行を判別するためにPDTビルダーが6月1日に実行するコマンドは次のとおりです:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
また、最新の増分を構築するためにPDTビルダーが6月1日に実行するSQLコマンドは次のとおりです:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
例 2
この例で使用されるPDTのプロパティは次のとおりです:
- 永続性戦略: 1 日に 1 回トリガーされます。
- 増分キー: 月
- 増分オフセット: 0
このテーブルが6月1日にどう更新されるかを以下に示します:
- 日次永続戦略は、テーブルが 1 日に 1 回自動的にビルドされることを意味します。6月1日の時点で、テーブルに追加されていたの最後の行は5月31日になります。
- 増分キーは月単位であるため、PDTビルダーは、5月31日からその月の初めまで切り捨て、5月のすべておよび6月1日を含む当日までのデータを再構築します。
- このPDTには増分オフセットがないため、再構築される以前の期間はありません。
このテーブルが6月2日にどう更新されるかを以下に示します:
- 6月2日の時点で、テーブルに追加されていた最後の行は6月1日になります。
- PDTビルダーは6月の月初めまでさかのぼって切り捨て、6月1日以降当日までのデータを再構築するため、再構築されるデータは6月1日と6月2日だけです。
- このPDTには増分オフセットがないため、再構築される以前の期間はありません。
例 3
この例で使用されるPDTのプロパティは次のとおりです:
- 増分キー: 月
- 増分オフセット: 3
- 永続性戦略: 1 日に 1 回トリガーされます。
このシナリオは、3 か月のオフセットで毎日トリガーされる PDT であるため、増分 PDT の設定が不十分であることを表しています。つまり、少なくとも 3 か月分のデータが毎日再構築され、インクリメンタル PDT の使用は非効率的になります。しかし、これは増分PDTの動作について理解を深める上で興味深いシナリオです。
このテーブルが6月1日にどう更新されるかを以下に示します:
- 日次永続戦略は、テーブルが 1 日に 1 回自動的にビルドされることを意味します。例えば6月1日の時点で、テーブルに追加されていた最後の行は5月31日になります。
- 増分キーは月単位であるため、PDTビルダーは、5月31日からその月の初めまで切り捨て、5月のすべておよび6月1日を含む当日までのデータを再構築します。
- また、この PDT の増分オフセットは
3です。つまり、PDT ビルダーでも、5 月より前の 3 つの期間(月単位)のデータを再ビルドするということです。その結果、2 月、3 月、4 月から現在までの 6 月 1 日までのデータが再ビルドされます。
このテーブルが6月2日にどう更新されるかを以下に示します:
- 6月2日の時点で、テーブルに追加されていた最後の行は6月1日になります。
- PDTビルダーは、6月1日までさかのぼって月を切り捨て、6月2日を含む6月のデータを再構築します。
- さらに、増分オフセットにより、PDT ビルダーは 6 月より前の過去 3 か月のデータを再構築します。その結果、3月、4月、5月、および当日6月2までのデータが再構築されます。
増分PDTを開発モードでテストする
新しい増分 PDT を本番環境にデプロイする前に、PDT をテストして、ビルドと増分が行われることを確認できます。増分PDTを開発モードでテストするには:
- PDT の Explore を作成します。
include: "/views/e_faa_pdt.view"
explore: e_faa_pdt {}
PDT用のExploreを開きます。
ヒント: モデルファイルにビューを追加して Explore を作成したら、LookML ファイルの上部にあるファイル操作メニューを使用して、LookML プロジェクトのビューファイルまたはモデルファイルから Explore に直接移動できます。
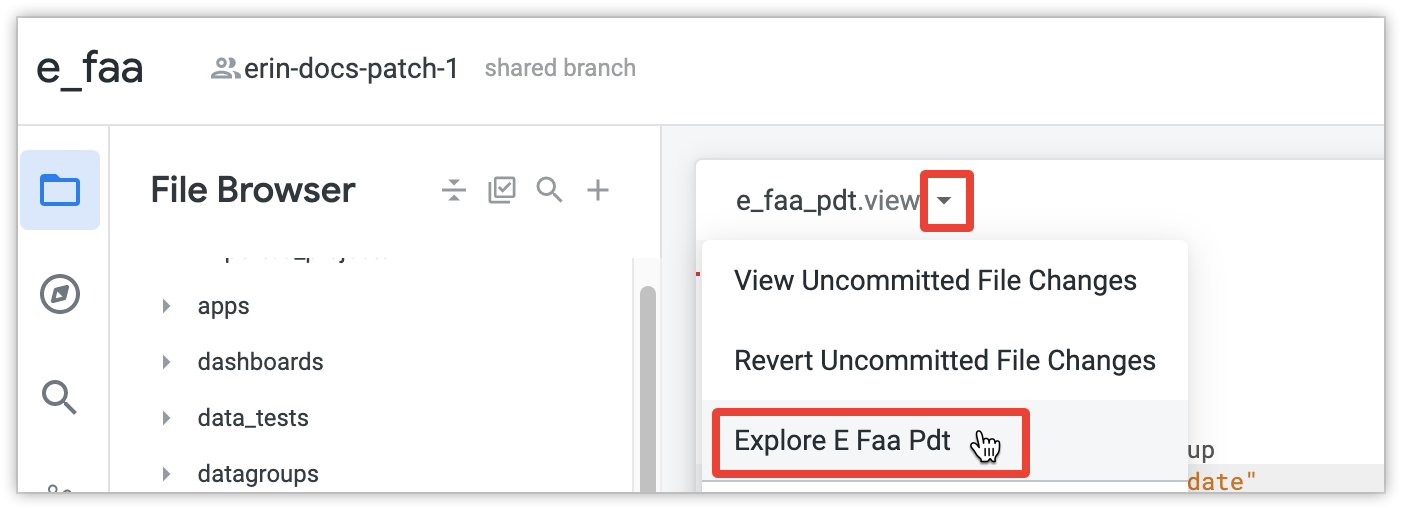
Explore でディメンションまたはメジャーを選択し、[Run] をクリックします。Looker が PDT 全体をビルドします。増分 PDT で初めて実行するクエリの場合、PDT ビルダーは PDT 全体をビルドして初期データを取得します。テーブルのサイズが大きい場合、初期構築には大規模なテーブル構築のためにかなり時間がかかる場合があります。
初期PDTが構築されたことは、次の方法で確認できます:
see_logs権限がある場合は、PDT イベントログでテーブルがビルドされたことを確認できます。PDT イベントログに PDT 作成イベントが表示されない場合は、PDT イベントログ データ探索の上部にあるステータス情報をご確認ください。[キャッシュから] と表示された場合は、[キャッシュを消去して更新] を選択すると、最新の情報を取得できます。- それ以外の場合は、Explore のデータバーの [SQL] タブでコメントを確認します。[SQL] タブに、クエリと、Explore でクエリを実行するときに実行されるアクションが表示されます。たとえば、[SQL] タブのコメントが
-- generate derived table e_incremental_pdt
PDT の初期ビルドを作成したら、Explore から [Rebuild Derived Tables & Run] オプションを使用して、PDT の増分ビルドを開始します。
前と同じ方法を使用することによりPDTの増分構築を確認できます。
see_logs権限がある場合は、PDT イベントログを使用して、増分 PDT のcreate increment completeイベントを確認できます。PDT イベントログにこのイベントが表示されず、クエリのステータスが「キャッシュから」の場合は、[キャッシュを消去して更新する] を選択して、最新の情報を表示します。- Explore の [Data] バーの [SQL] タブでコメントを確認します。この場合、コメントには PDT の増分が記載されます。(例:
-- increment persistent derived table e_incremental_pdt to generation 2
PDT のビルドと増分が正常に行われたことを確認したら、PDT 専用の Explore を保持しない場合は、モデルファイルから PDT の
exploreパラメータとincludeパラメータを削除またはコメントアウトします。
PDT が開発モードでビルドされると、テーブルの定義をさらに変更しない限り、変更をデプロイすると、同じテーブルが本番環境に使用されます。詳細については、Looker での派生テーブルのドキュメントで開発モードの永続テーブルをご覧ください。
増分PDT対応のデータベースダイアレクト
Looker プロジェクトで Looker の増分 PDT をサポートするには、データベース言語が、行の削除と挿入を可能にするデータ定義言語(DDL)コマンドをサポートしている必要があります。
Looker の最新リリースで増加した PDT をサポートする言語を次の表に示します。