予測を使用すると、アナリストは新規または既存の Explore クエリにデータ プロジェクションを迅速に追加し、ユーザーが特定のデータポイントを予測し、モニタリングできるようにします。予測された Explore の結果とビジュアリゼーションをダッシュボードに追加し、Look として保存できます。予測結果と可視化は、埋め込み Looker コンテンツで作成、表示することもできます。
予測を作成する権限があれば、データを予測できます。
予測結果の作成方法と表示方法
予測機能では、Explore のデータテーブルのデータ結果を使用して、将来のデータポイントを計算します。予測計算には、Explore クエリの表示結果のみが含まれます。行の制限により表示されない結果は含まれません。予測の計算に使用されるアルゴリズムの詳細については、このページの ARIMA アルゴリズム セクションをご覧ください。
予測結果は、既存のデータ探索の可視化の続きとして表示され、可視化の設定の対象になります。予測されたデータポイントは、予測されないデータポイントと以下の点で区別されます。
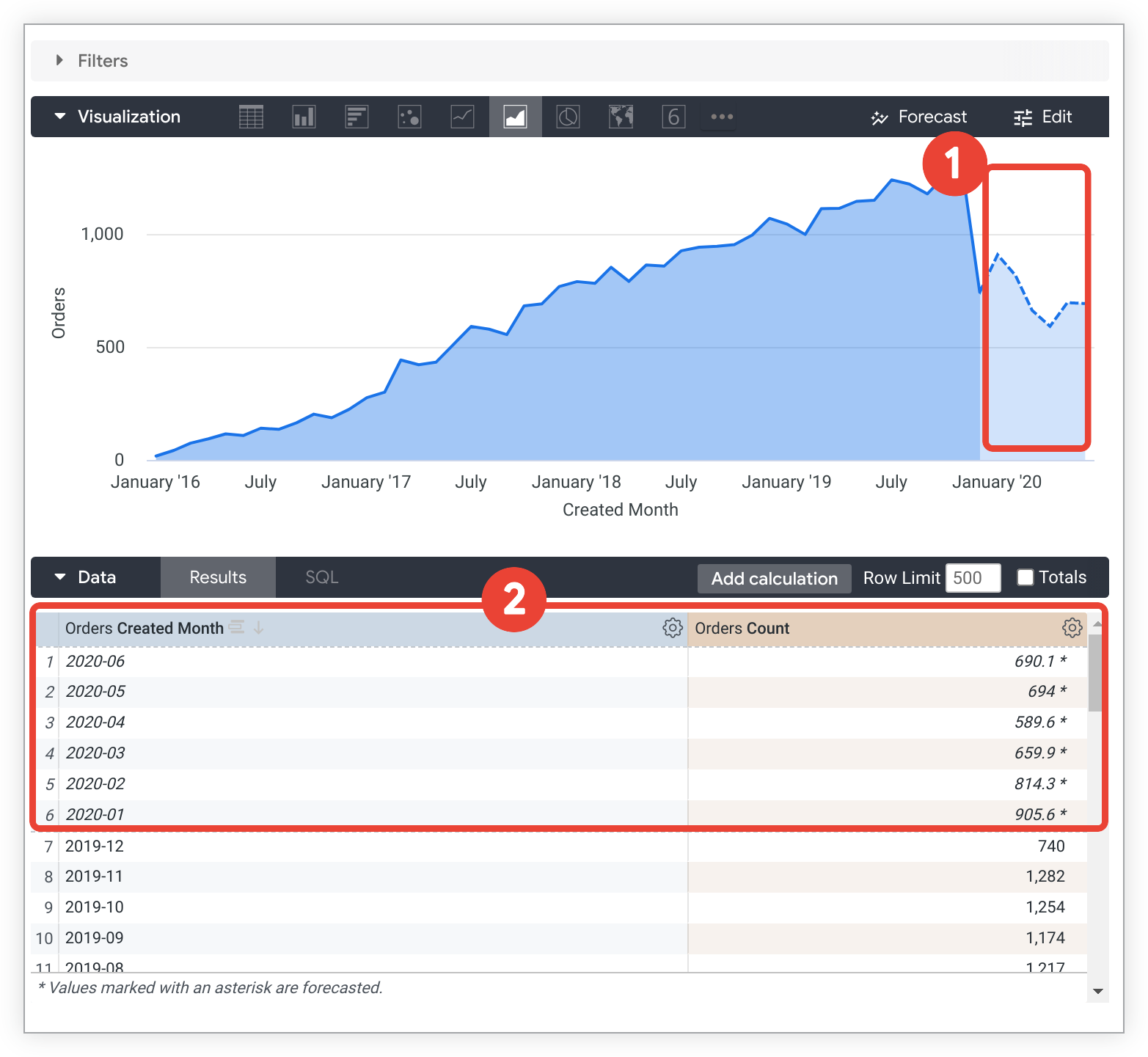
- サポートされているデカルト図では、予測されたデータポイントは、明るい色または破線でレンダリングされるため、予測できないデータポイントと区別されます。
- サポートされているテキスト形式と表形式のグラフでは、予測されたデータポイントが斜体で表示され、アスタリスクが追加されます。
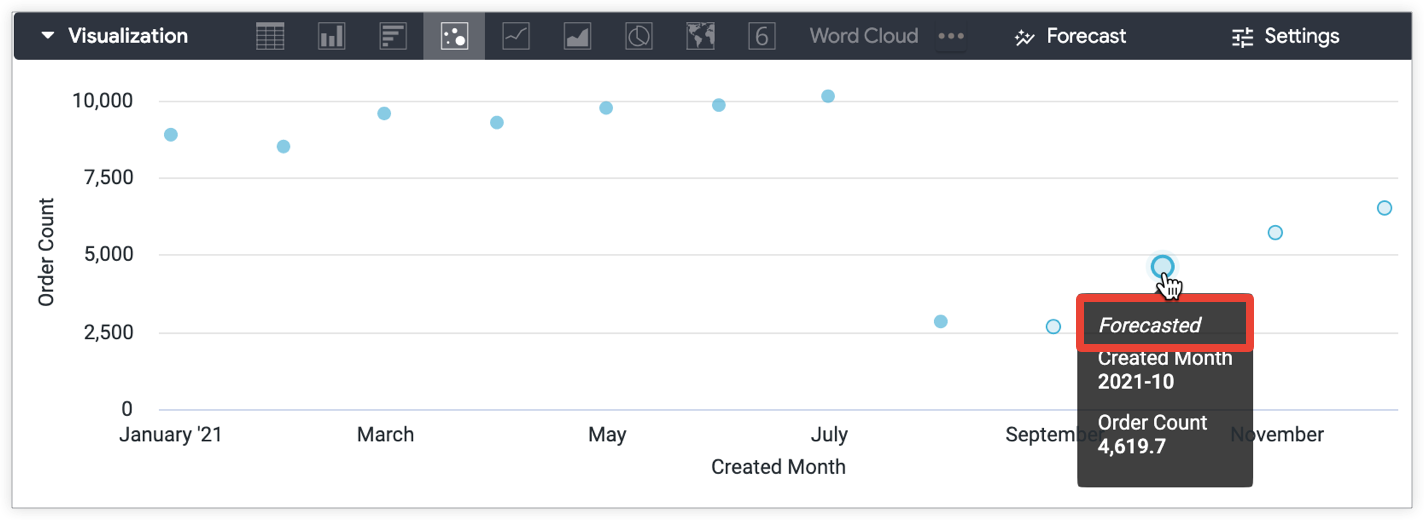
予測されたデータポイントにカーソルを合わせたときに表示されるツールチップでも、予測データが明示的に識別されます。
次のセクションで説明するように、予測データのサポート対象は特定の種類のビジュアリゼーションのみです。
ARIMA アルゴリズム
予測では、自動回帰統合移動平均(ARIMA)アルゴリズムを活用して、予測に入力されたデータに最適な方程式を作成します。データに最適なマッチを見つけるため、Looker は一連の初期変数を使用して ARIMA を実行し、初期変数のバリエーションのリストを作成してから、それらのバリエーションを使用して ARIMA を再度実行します。いずれかのバリエーションによって入力データにより適した計算式がある場合、そのバリエーションが新しい初期変数として使用され、追加のバリエーションが作成されて評価されます。Looker は、最適な変数が特定されるか、すべてのオプションまたは割り当てられたコンピューティング時間がなくなるまで、このプロセスを繰り返します。
このプロセスは、遺伝子アルゴリズムと考えることができます。このアルゴリズムは、数百世代にわたる個人がそれぞれ 1 ~ 10 の子孫を生じさせ(親によって変数が異なります)、最適な子源は「より優れた」世代を生き残るために生き残ることができます。Looker では、遺伝子アルゴリズムアプローチで ARIMA の多くの呼び出しを使用する方法を「AutoARIMA」と呼びます。
AutoARIMA について詳しくは、pmdarima ユーザーガイドの auto_arima の使用に関するヒントをご覧ください。これは、Looker が AutoARIMA を実行するために使用するライブラリではありませんが、pmdarima によって、プロセスおよび使用されるさまざまな変数の最適な説明が提供されます。
クロスフィルタリング対応のビジュアリゼーションタイプ
次のデカルト表現タイプでは、予測データのレンダリングがサポートされています。
次のテキストと表グラフの種類では、予測データのレンダリングがサポートされています。
現在のところ、カスタム ビジュアリゼーションなど、他の種類のビジュアリゼーションでは、予測データをレンダリングできません。
予測用のクエリ要件について確認する
予測を作成するには、Explore が次の要件を満たしている必要があります。
- ディメンションを 1 つだけ含めます(ディメンションの塗りつぶしを有効にして、期間ディメンションにする必要があります)
- 少なくとも 1 つのメジャーまたはカスタム メジャーを含めます(予測には、最大 5 つのメジャーまたはカスタム メジャーを含めることができます)。
- 結果を期間ディメンションの降順で並べ替え
留意事項
新しい Explore クエリを作成して予測するか、既存の Explore クエリに予測を追加する際には、次の基準も考慮する必要があります。
- ピボット - 前の要件が満たされていれば、ピボット Explore で予測を実行できます。
- 行の合計と小計 - 行の合計と小計には予測値は含まれません。小数や行の合計を予測に使用することはおすすめしません。予期しない数値が生じる可能性があるためです。
- 不完全な期間を含むフィルタ - 予測を正確に保つために、Explore のフィルタで完全な期間ロジックと組み合わせて、Explore に期間不完全なデータが含まれている場合にのみ、予測を使用してください。たとえば、あるユーザーが未来の 1 か月間のデータを予測している間、その Explore がフィルタされて過去 3 か月間のデータを表示する場合、その Explore には、現在の未完成な月のデータが含まれます。予測では不完全なデータが計算に組み込まれるため、より信頼性の高い結果が表示されるようになります。より正確な予測をするため、Explore に不完全な期間が含まれている場合(たとえば、Explore に今月のデータが不完全な場合)、過去 3 か月分ではなく過去 3 か月分などのフィルタ ロジックを使用してください。
- 表計算 - 1 つ以上の予測メジャーに基づく表計算が自動的に予測に追加されます。
- 行の上限 - データ行全体(予測された行を含む)に行の上限を適用する方法を確認できます。
その他のヒントとトラブルシューティング リソースについては、このページの一般的な問題と注意事項をご覧ください。
通常、データセットの行数が多く、予測長さが短いほど、予測の精度は高くなります。
予測メニューのオプション
[予測] タブの [予測] メニューにあるオプションを使用して、予測データをカスタマイズできます。[予測] メニューには次のオプションがあります。
フィールドを選択
[フィールドを選択] プルダウン メニューには、Explore クエリのメジャーまたはカスタム メジャーが表示され、予測に使用できます。最大 5 つのメジャー、またはカスタム メジャーを選択できます。
長さ
[長さ] オプションは、データ値を予測する行数または期間を示します。予測期間の間隔は、Explore クエリの時間枠のディメンションに基づいて自動的に入力されます。
通常、データセットの行数が多く、予測長さが短い場合、予測精度が高くなります。
予測間隔
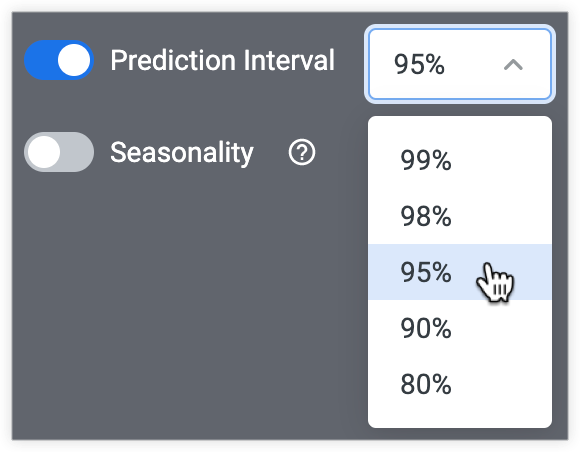
[予測間隔] オプションを使用すると、アナリストは予測の不確実性を表現して、精度を高めることができます。有効にすると、[予測間隔] オプションにより、予測データ値の境界を選択できます。たとえば、95% の予測間隔は、95% の確率で予測された測定値が予測の上限と下限の間に収まることを示しています。
選択した予測間隔が大きいほど、上限と下限は広くなります。
季節性
[季節性] オプションを使用すると、アナリストは予測サイクルにおける既知のサイクルや繰り返しのデータ トレンドを考慮し、サイクル内のデータの行数を確認できます。たとえば、Explore のデータテーブルには 1 時間あたり 1 行があり、データが毎日繰り返される場合、季節性は 24 です。
デフォルトの予測設定では、Looker は Explore の日付ディメンションを参照し、可能な季節性サイクルをいくつかスキャンして、最終的な予測に最も一致するものを探します。たとえば、時間別データを使用する場合、Looker は日、週、4 週間の季節性サイクルを試すことがあります。Looker では、ディメンションの頻度も考慮されます。ディメンションが 6 時間を表す場合、Looker は 1 日に 4 行のみであることを認識し、それに応じて季節性を調整します。
一般的なユースケースでは、自動オプションを使用して、特定のデータセットに最適な季節性を検出します。データセット内の特定のサイクルを認識している場合、[カスタム] オプションを使用して、予測の各メジャーのサイクルを構成する行数を指定できます。
複数のメジャーのデータ値を予測する際は、メジャーごとに異なる季節性オプション(なしを含む)を選択できます。[季節性] プルダウン メニューには、いくつかのオプションがあります。
予測では、[季節性] オプションが有効になっていない場合でも、デフォルトで [自動] の季節性のオプションが予測に適用されます。
自動
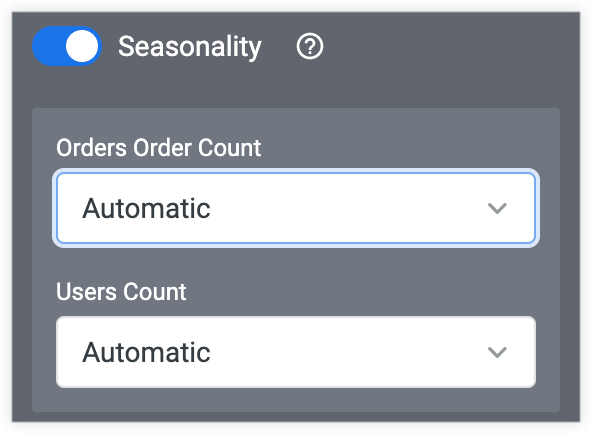
自動の季節性オプションでは、Looker は一般的な複数の季節性(1 日、1 時間、1 か月など)のデータから最適なオプションを選択します。
カスタム
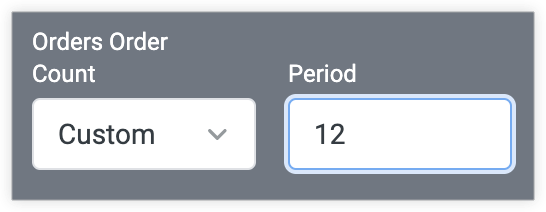
データセットの各シーズンまたはサイクルを構成する特定の行数がわかっている場合は、[期間] フィールドで数値を指定できます。データが特定の行数で循環していることがわかっている場合は、[カスタム] を選択すると便利です。
月単位でサイクルするが、より粒度が高い(例: Explore で日付または週単位の粒度を使用する)データを扱う場合、通常は 4 週間または 30 日間の期間が月単位のサイクルに適しています。
なし
季節性は予測の強力なコンポーネントですが、入力データによっては、必ずしも推奨されるものではありません。データに予測可能なサイクルがない場合、季節性を有効にすると、アルゴリズムがパターンを見つけ出して誤ったパターンを予測に適合させようとする場合に、不正確な予測につながることがあります。その結果、予測が不明瞭になります。
複数のメジャーのデータ値を予測し、1 つまたは少数のデータに対してのみ季節性を有効にする場合は、季節性を有効にしないすべてのメジャーに対して [なし] を選択します。
予測を作成する
予測を作成できるのは、権限を持つユーザーのみです。
予測を作成するには:
Explore が予測の要件を満たしていることを確認します。たとえば、Users Created Month、Users Count、Orders Count を含む Explore クエリは、Users Created Month で選択され、降順で並べ替えられています。
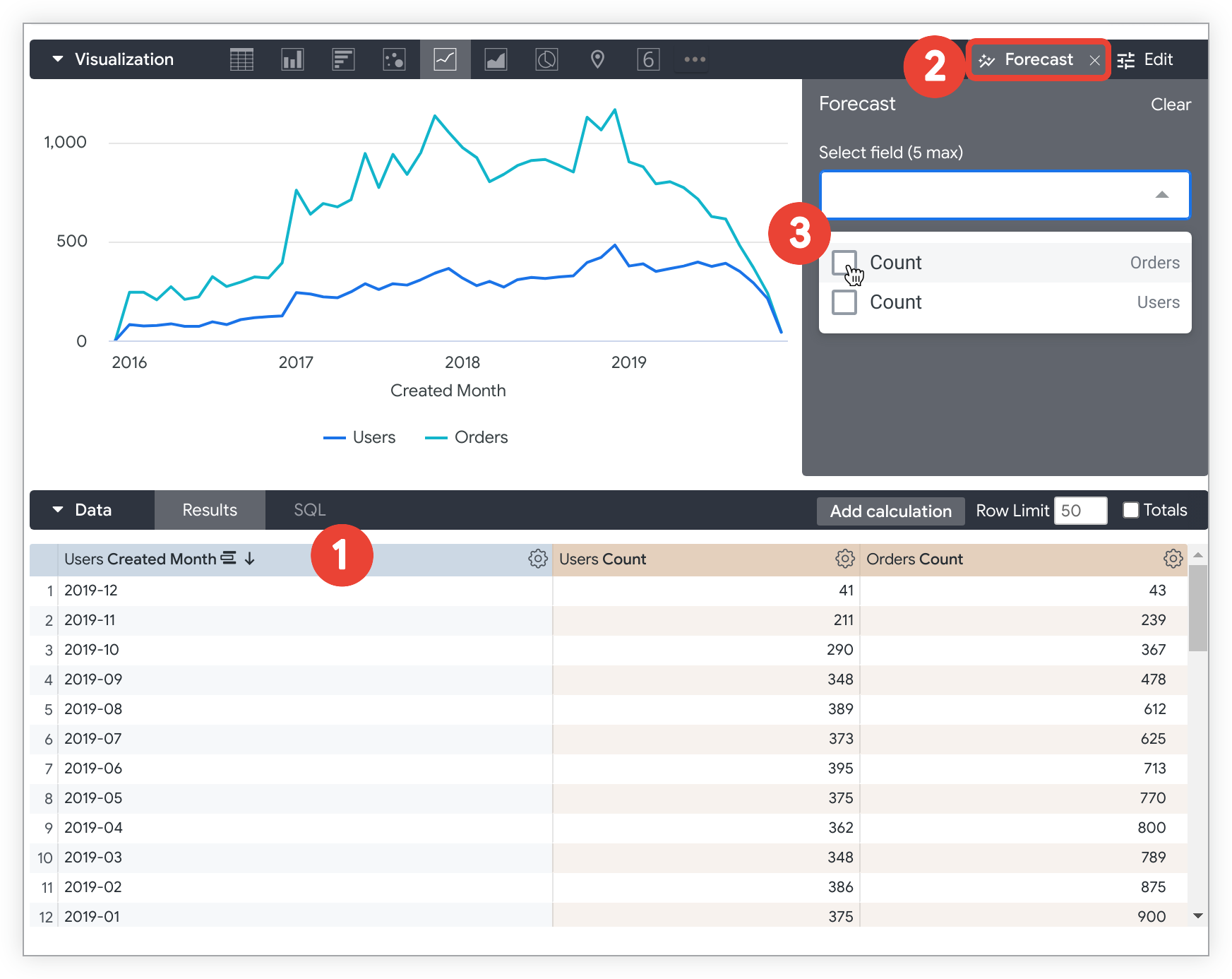
Explore の [Visualization] タブで [予測] を選択し、[予測] メニューを開きます。
[フィールドを選択] プルダウン メニューを選択して、予測するメジャーまたはカスタム メジャーを最大 5 つ選択します。
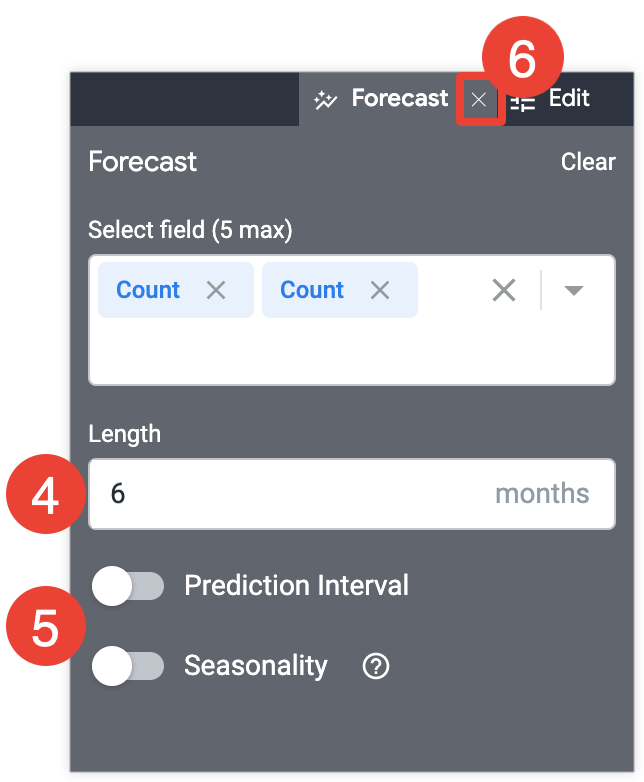
今後予測する期間を [長さ] に入力します。
メニュータブの [予測] の横にある [x] を選択して設定を保存し、メニューを終了します。
[Run] を選択して、Explore クエリを再実行します。(予測に変更を加えた場合は、Explore を再実行する必要があります)。
Explore の結果と可視化に、指定した期間の予測値が表示されるようになりました。このサンプルの Explore では、2020-01 から 2020-06 までの 6 か月間の [Users Count] と [Orders Count] の予測データが表示されます。
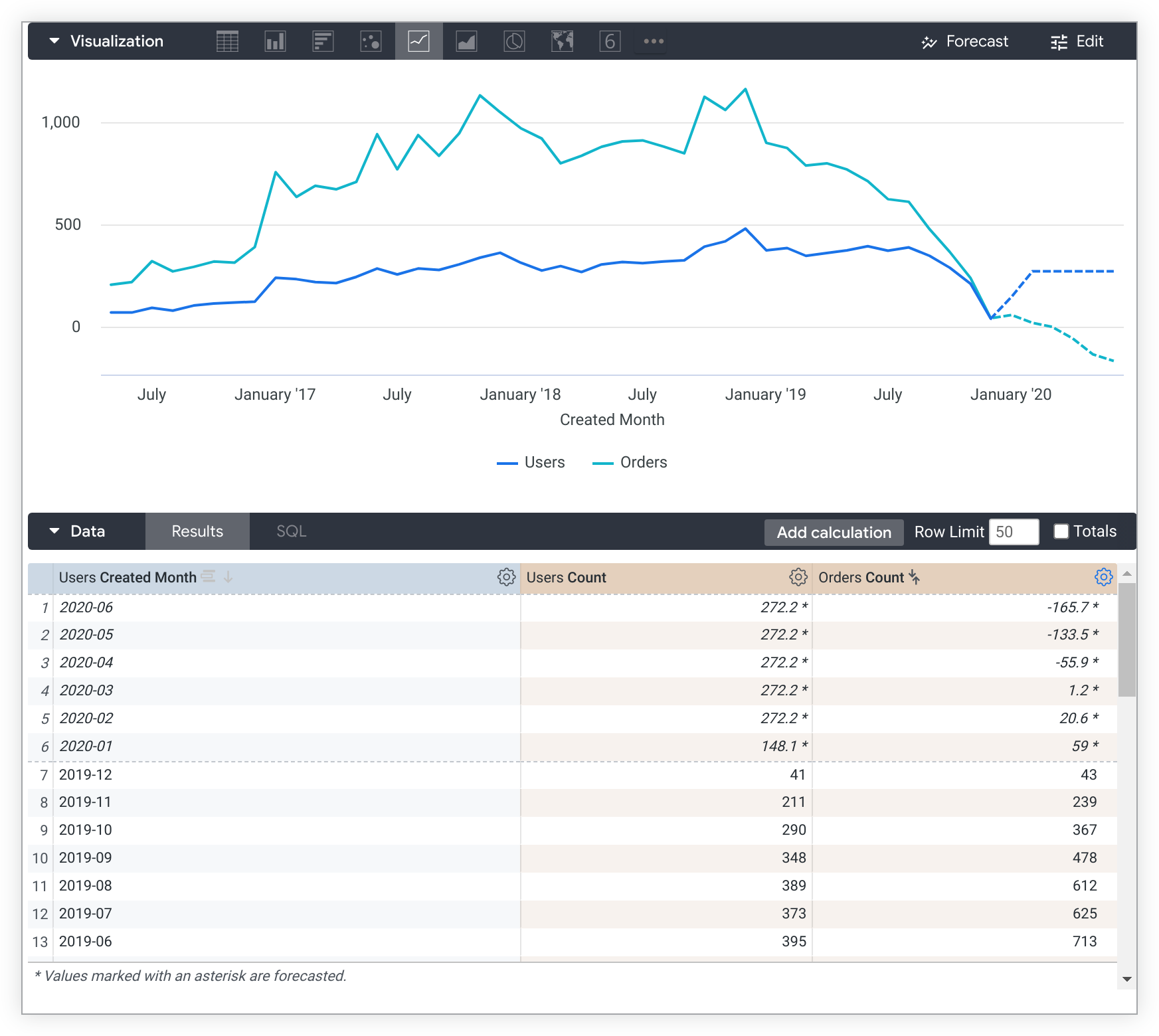
予測計算はデータの並べ替え順序に依存するため、予測クエリを実行すると並べ替えは無効になります。
予測の編集
予測を編集できるのは、権限を持つユーザーのみです。
予測を編集するには:
必要に応じて、Explore クエリを編集して、さまざまなメジャーや期間のフィールドを追加または削除します。Explore が予測の要件を満たしていることを確認します。
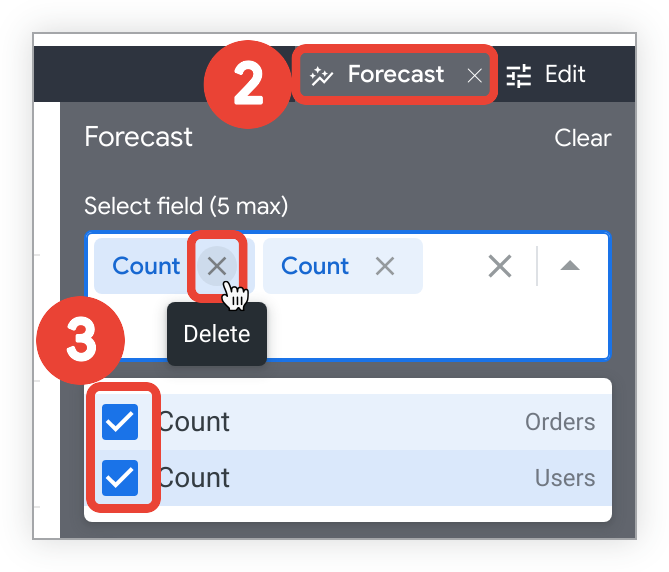
Explore の [Visualization] タブで [予測] を選択し、[予測] メニューを開きます。
[フィールドを選択] プルダウン メニューを選択して、予測フィールドを変更します。予測フィールドを削除するには:
- 展開した [フィールドを選択] プルダウン メニューで、予測フィールドの横にあるチェックボックスをオンにして、予測からフィールドを削除します。
- または、折りたたまれた [フィールドを選択] メニューで、フィールド名の横にある [x] を選択します。
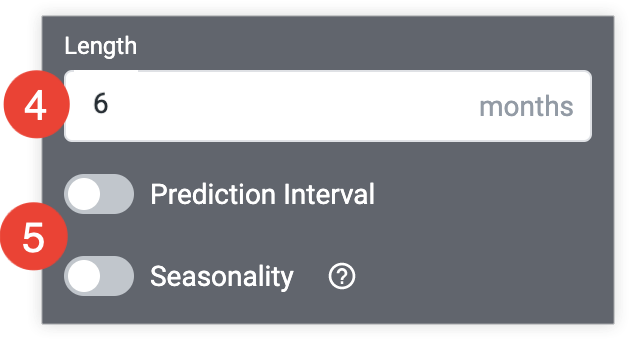
今後指定する期間を編集して、必要に応じて [長さ] フィールドで予測します。
[予測間隔] または [季節性] スイッチを選択して、各機能を有効にし、関連するオプションをカスタマイズします。
- [予測間隔] または [季節性] のいずれかがすでに有効になっている場合、カスタマイズが表示されます。必要に応じてカスタム設定を編集するか、スイッチを選択して予測から関数を削除します。
メニュータブの [予測] の横にある [x] を選択して設定を保存し、メニューを終了します。
[Run] を選択して、Explore クエリを再実行します。(予測に変更を加えたら、Explore を再実行する必要があります)。
Explore の結果と可視化に、修正された予測が表示されるようになりました。予測計算はデータの並べ替え順序に依存するため、予測クエリを実行すると並べ替えは無効になります。
予測の削除
予測を削除できるのは、権限を持つユーザーのみです。
Explore から予測を削除するには:
- Explore の [Visualization] タブで [予測] を選択し、[予測] メニューを開きます。
- [消去] を選択します。
予測は自動的に適用されず、クエリが自動的に再実行されます。
一般的な問題と知っておくべきこと
どのくらい正確ですか?
予測の精度は、入力データによって異なります。Looker の AutoARIMA 実装を使用すると、非常に正確な予測を行い、入力データから微妙なニュアンスをうまく組み合わせることができます。また、アルゴリズムが入力データの奇妙なパターンに追いつき、予測で不自然に強調されている場合もあります。予測結果を最大限に活用するには、十分なデータが提供されていることと、データができるだけ正確であることを確認してください。
予測を生成できませんでした
予測を生成できない正当な理由があります。通常は、入力データの量が少なすぎるか、リクエストした予測時間が大きすぎる場合に関係します。どちらの要素にも明確な制限はありません。また、一定の予測期間に必要な入力データの正確な比率はありません。入力データが散在していて予測不可能であるほど、AutoARIMA アルゴリズムによる一致検出の難易度は高くなります。予測を生成する最も効果的な方法は、クリーンな入力データの量を増やし、季節性の設定が正しいことを確認して、予測の長さを必要な時間だけに短縮することです。[予測間隔] オプションを使用する場合は、さらに短い間隔を選択することをおすすめします。
入力データのクリーニングには、次の作業が含まれます。
- データが含まれていない期間の先頭行または末尾行をトリミングする
- より大きな日付ディメンションを選択して、データセット内のノイズを低減する
- 予測に利益を及ぼさないフィルタの外れ値の変更
クエリ結果が予測なしで返され、不明瞭なエラーが発生した
そうならないようにする必要があります。発生した場合は、予測構成から 1 つまたは複数のメジャーを削除してから、もう一度追加してみてください。
予測が表示されるが、明らかに不正確または役に立たない
この場合、入力データを追加して、できる限りクリーンアップし、カスタム 季節性を設定する(データの特定のサイクルを認識している場合)か、なしを選択して [季節性] オプションを完全に無効にすることをおすすめします。
入力データのクリーニングには次のタスクが伴う場合があります。
- データが含まれていない期間の先頭行または末尾行をトリミングする
- より大きな日付ディメンションを選択して、データセット内のノイズを低減する
- 予測に利益を及ぼさないフィルタの外れ値の変更