Ce document présente les stratégies de reprise après sinistre (DR) de Microsoft SQL Server pour les architectes et les responsables techniques en charge de la conception et de la mise en œuvre de la reprise après sinistre sur Google Cloud.
Les bases de données peuvent devenir indisponibles pour diverses raisons, par exemple des pannes matérielles ou réseau. Pour fournir un accès continu à la base de données lors de défaillances, une base de données secondaire, qui est une instance dupliquée d’une base de données principale, est mise à disposition. Lorsqu'une base de données principale devient indisponible, le fait de disposer d'une base de données secondaire dans un autre emplacement offre davantage de chances de maintenir la disponibilité des données.
Si la base de données principale devient indisponible, votre application stratégique se connecte à une base de données secondaire en partant du dernier état de cohérence des données connu, afin de réduire ou éliminer les temps d'arrêt pour les utilisateurs de vos services.
Le processus de mise à disposition d'une base de données secondaire en cas d'échec de la base de données principale est appelé reprise après sinistre de base de données. Avec ce processus, la base de données secondaire prend le relais au moment où la base de données principale devient indisponible. Dans l'idéal, la base de données secondaire doit présenter exactement le même état de cohérence que la base de données principale au moment de la défaillance, ou ne présenter qu'un nombre minimal de transactions récentes manquantes par rapport à la base de données principale.
La reprise après sinistre de base de données est une fonctionnalité essentielle pour les entreprises. L'objectif principal est d'assurer la continuité des opérations pour les applications critiques. Il peut s'agir, par exemple, de générer des revenus (e-commerce), d'assurer la fiabilité et la continuité de certains services (gestion de vol ou de centrale électrique) ou de gérer des fonctions vitales en milieu médical (surveillance des patients). Dans tous ces exemples, la disponibilité permanente des applications est de la plus haute importance, car celles-ci sont considérées comme essentielles.
La plupart des systèmes de gestion de base de données intègrent une fonctionnalité de reprise après sinistre, y compris Microsoft SQL Server. Ce document d'architecture décrit la mise en œuvre des fonctionnalités de reprise après sinistre fournies par SQL Server dans le contexte de Google Cloud.
Terminologie
Les sections suivantes expliquent les termes utilisés tout au long de ce document.
Architecture générale de reprise après sinistre
Le schéma ci-dessous montre la topologie générale de l’architecture de DR.
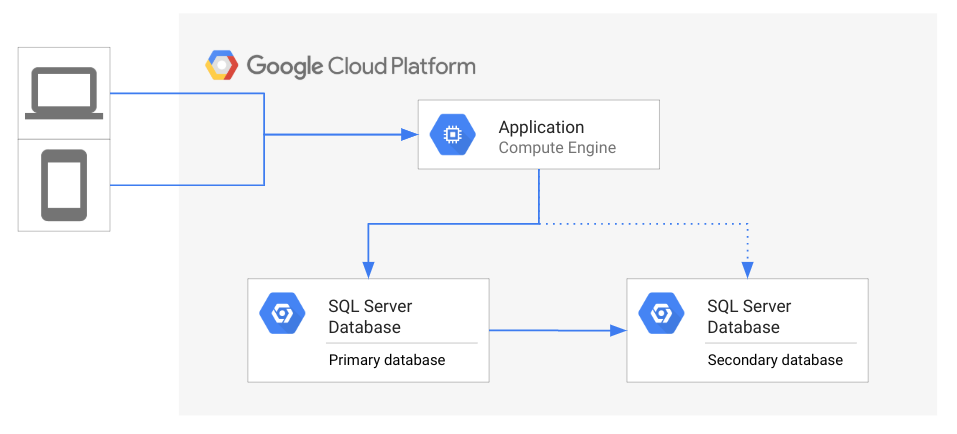
Dans ce schéma, une application accède à une base de données principale, tandis qu'une base de données secondaire est en attente et reflète l'état de la base de données principale. Les clients accèdent à l'application qui s'exécute sur Google Cloud.
Si la base de données principale devient indisponible, c'est aux administrateurs de la base de données ou à l'équipe chargée des opérations de déterminer s'il faut lancer le processus de reprise après sinistre. Si le processus est lancé, l'application est reconnectée à la base de données secondaire. Une fois connectée, l'application peut à nouveau servir ses clients. Dans l'idéal, l'application est disponible sur la base de données secondaire le plus vite possible afin d'éviter aux clients de subir des pannes. L'une des solutions consiste à attendre que la base de données principale redevienne accessible, au lieu de lancer une reprise après sinistre. Par exemple, si la défaillance est intermittente, il peut être plus rapide de résoudre le problème plutôt que d'effectuer le basculement.
Bases de données principale et secondaire
Une ou plusieurs applications ont accès à une base de données principale afin de fournir des services de persistance pour la gestion de l'état de l'application. Une base de données secondaire est liée à une base de données principale et contient une réplique de celle-ci. Idéalement, le contenu de la base de données secondaire correspond exactement et à tout moment à celui de la base de données principale. Dans de nombreux cas, la base de données secondaire est en retard par rapport à la base de données principale en raison du délai d'application des modifications transactionnelles apportées à la base de données principale. Toutefois, selon la technologie utilisée, il est possible d'associer plusieurs bases de données secondaires à une base de données principale. SQL Server est compatible avec l'association de plusieurs bases de données secondaires à une base de données primaire.
Reprise après sinistre
Si une base de données principale devient indisponible, la reprise après sinistre modifie le rôle de la base de données secondaire qui devient ainsi la base de données principale. S'il existe plusieurs bases de données secondaires, l'une d'entre elles est sélectionnée manuellement ou sur la base d'une liste des modes de basculement privilégiés. Les applications doivent se reconnecter à la nouvelle base de données principale pour continuer à accéder à leur état. Si cette dernière n'a pas été synchronisée avec le dernier état connu de l'ancienne base de données principale, l'application démarre à partir d'un état antérieur (également appelé flashback).
Il est important de disposer d'au moins une base de données secondaire à tout moment pour chaque base de données principale. Après une reprise après sinistre, assurez-vous qu'une nouvelle base de données secondaire est configurée pour gérer les futurs scénarios de reprise après sinistre.
Basculement, commutation et repli
Il existe plusieurs manières de modifier le rôle entre les bases de données principale et secondaire :
- Basculement : processus consistant à modifier le rôle d'une base de données secondaire pour devenir la nouvelle base de données principale et y connecter toutes les applications. Le basculement est involontaire car il est déclenché par l'indisponibilité d'une base de données principale. Le basculement peut être déclenché automatiquement ou manuellement selon la configuration choisie.
- Commutation : contrairement au basculement, la commutation d'une base de données principale vers une base de données secondaire (nouvelle base de données principale) est déclenchée de façon intentionnelle pour les tests initiaux et la maintenance planifiée. Testez votre système de DR avec une commutation périodique régulière pour garantir la fiabilité continue de la reprise après sinistre.
- Repli : le repli inverse le processus par lequel la nouvelle base de données principale devient la base de données secondaire, après réparation de la première. Un repli est déclenché intentionnellement pour rétablir l'état avant le basculement ou la commutation. Cette opération n'est pas obligatoire et dépend des exigences de reprise après sinistre, telles que la localisation ou la disponibilité des ressources.
Google Cloud zones et régions
Les ressources telles que les bases de données sont situées dans des zones et régionsGoogle Cloud , chaque zone appartenant à une région. Une zone représente un point de défaillance unique. Nous vous recommandons de déployer une ressource de haute disponibilité et tolérante aux pannes dans plusieurs zones d'une région.
Pour éviter les pannes dans une région entière, établissez des stratégies multirégionales de reprise après sinistre. Par exemple, la base de données secondaire associée sera située dans une région différente de celle de la base de données principale.
Modes actifs : actif-passif et actif-actif
Une base de données principale est une base de données ouverte permettant d'effectuer des opérations en lecture et écriture (opérations LMD) afin que les applications qui y ont accès puissent gérer leur état. La base de données principale est appelée base de données active. La base de données secondaire correspondante est passive car elle réplique la base de données principale, mais aucune application ne peut y accéder pour effectuer des opérations de modification d'état. Après un basculement ou une commutation, la base de données secondaire devient la nouvelle base de données principale, soit une base de données active.
La base de données principale ainsi que la base de données secondaire peuvent être actives ensemble si la technologie de base de données intègre cette fonctionnalité, appelée mode actif-actif. Dans ce cas, les applications peuvent se connecter à l'une ou à l'autre, car les deux bases de données sont disponibles pour la gestion d'état. La reprise après sinistre en mode actif-actif ne nécessite pas de basculement si une seule des bases de données actives devient indisponible. Dans ce cas, l'autre base de données active demeure disponible. Le mode actif-actif n'est pas abordé dans cet article, car il n'est pas proposé par SQL Server.
Modes de secours : Hot Standby, Warm Standby et No Standby
Pour que la base de données principale soit la base de données active, elle doit être en cours d'exécution et capable d'exécuter des instructions LMD. La base de données secondaire n'a pas besoin d'être en cours d'exécution et peut être fermée. Dans ce cas, le délai nécessaire à la reprise après sinistre augmente, car la nouvelle base de données principale doit d'abord être mise en état de fonctionner, avant d'assumer le rôle de nouvelle base de données principale.
Il existe plusieurs façons de configurer la base de données secondaire :
- Hot Standby (secours automatique) : la base de données secondaire est opérationnelle et prête à être connectée aux clients. La dernière modification disponible dans la base de données principale est toujours appliquée dès qu'elle devient disponible.
- Warm Standby (secours semi-automatique) : une base de données secondaire est opérationnelle, mais toutes les modifications de la base de données principale n'ont pas encore été nécessairement appliquées.
- Cold Standby (reprise progressive) : une base de données secondaire n'est pas en cours d'exécution. Elle doit d'abord être démarrée, puis synchronisée sur le dernier état disponible.
- No Standby : le logiciel de base de données doit d'abord être installé, puis démarré avant que toutes les modifications de la base de données principale ne soient appliquées. Ce mode est le moins coûteux, car aucune ressource n'est consommée lorsqu'il n'est pas utilisé. Cependant, comparé aux autres modes, la mise en service de la nouvelle base de données principale prend plus de temps.
Stratégies de DR
Les sections suivantes décrivent les stratégies de reprise après sinistre disponibles dans Microsoft SQL Server.
Dimensions des stratégies de reprise après sinistre
Plusieurs dimensions clés doivent être prises en compte lors de la sélection ou de la mise en œuvre d'une stratégie de reprise après sinistre de base de données. La portée, le comportement et les exigences des différentes stratégies de reprise après sinistre dépendent des choix en matière de points de récupération. Les principales dimensions sont les suivantes :
- Objectif de point de récupération (RPO) : durée maximale acceptable pendant laquelle votre application peut perdre des données en raison d'un incident majeur. Cette dimension varie selon la manière dont les données sont utilisées. Le RPO peut être exprimé en durée (secondes, minutes ou heures) à partir du moment de l'indisponibilité de la base de données principale ou en tant qu'états de traitement identifiables (dernière sauvegarde complète ou incrémentielle). Quelle que soit la manière dont le RPO est spécifié, la stratégie de reprise après sinistre doit appliquer la mesure en question de manière à satisfaire à l'exigence du RPO. Le cas le plus exigeant concerne la dernière transaction validée, qui exige qu'aucune perte ne survienne pendant le transfert entre la base de données principale et la base de données secondaire.
- Objectif de temps de récupération (RTO) : durée maximale acceptable pendant laquelle votre application peut être indisponible. Cette valeur est généralement définie dans le cadre d'un contrat de niveau de service plus vaste. Le RTO est généralement exprimé en durée à partir du moment de l'indisponibilité de la base de données principale. Par exemple, l'application doit être entièrement opérationnelle dans les 5 minutes. La récupération immédiate constitue le cas le plus exigeant, l'objectif étant que les utilisateurs d'applications ne s'aperçoivent pas qu'une reprise après sinistre a eu lieu.
- Domaine de point de défaillance unique : il vous appartient de décider si une région est considérée comme un domaine de point de défaillance unique pour vos besoins en matière de reprise après sinistre. Si, pour votre système, une région présente cette caractéristique, la reprise après sinistre doit être configurée de sorte à impliquer deux ou plusieurs régions dans la configuration réelle. Si une défaillance se produit dans la région contenant la base de données principale, la base de données secondaire d'une autre région devient la nouvelle base de données principale. Si le domaine du point de défaillance unique correspond à une zone, la reprise après sinistre peut être configurée sur plusieurs zones de la même région. Si une défaillance survient dans une zone, la reprise après sinistre utilise une autre zone et assure la disponibilité de la nouvelle base de données principale dans cette zone.
Décider laquelle de ces dimensions clés vous devez privilégier revient à faire un choix entre le coût et la qualité. Plus le RTO et le RPO sont bas, plus la solution de reprise après sinistre coûte cher à mesure que d'autres ressources actives sont consommées. Les sections suivantes abordent plusieurs stratégies de reprise après sinistre, qui correspondent à des points sur les dimensions dans le contexte de la base de données Microsoft SQL Server.
Stratégies de DR pour SQL Server
La section Continuité des activités et récupération de la base de données – SQL Server décrit les fonctionnalités de disponibilité que vous pouvez utiliser pour mettre en œuvre des stratégies de reprise après sinistre.
Préliminaires
SQL Server s'exécute sous Windows et Linux. Cependant, toutes les fonctionnalités de disponibilité ne sont pas présentes sous Linux. SQL Server comprend plusieurs éditions dont certaines n'intègrent pas toutes les fonctionnalités de disponibilité.
SQL Server fait une distinction entre les instances et les bases de données. Une instance représente le logiciel SQL Server en cours d'exécution, tandis qu'une base de données désigne l'ensemble des données gérées par une instance SQL Server.
Groupes de disponibilité Always On
Les groupes de disponibilité "Always On" (toujours activés) fournissent une protection au niveau de la base de données. Un groupe de disponibilité comporte au moins deux instances dupliquées. L'une d'entre elles constitue l'instance dupliquée principale disposant des accès en lecture et en écriture. Les instances dupliquées restantes sont des instances secondaires pouvant fournir un accès en lecture. Chaque instance dupliquée de base de données est gérée par une instance SQL Server autonome. Un groupe de disponibilité peut contenir une ou plusieurs bases de données. Le nombre de bases de données pouvant être incluses dans un groupe de disponibilité et le nombre d'instances dupliquées secondaires disponibles dépendent de l'édition de SQL Server. Toutes les bases de données d'un groupe de disponibilité subissent les mêmes changements de cycle de vie au même moment. Les groupes de disponibilité appliquent le mode actif-passif, car seule la base de données principale autorise l'accès en écriture.
Lorsqu'un basculement se produit, une instance dupliquée secondaire devient la nouvelle instance dupliquée principale. Etant donné qu'un groupe de disponibilité inclut des instances SQL Server autonomes, toutes les opérations consignées dans les journaux des transactions sont disponibles dans les instances dupliquées. Toute modification non consignée dans un journal des transactions doit être synchronisée manuellement, telles que les connexions au niveau instance de SQL Server ou les tâches de l'agent SQL Server. Afin de fournir une protection au niveau de la base de données et une protection des instances SQL Server, vous devez configurer des instances de cluster de basculement (FCI). Cette architecture de déploiement est décrite plus loin dans la section Instances de cluster de basculement Always On.
Vous pouvez protéger les applications contre les modifications de rôle à l'aide d'un écouteur. L'écouteur s'exécute sur les applications qui se connectent au groupe de disponibilité. Les applications ignorent par quelles instances SQL Server la base de données principale ou les instances dupliquées secondaires sont gérées à un moment donné. La configuration .NET minimale des clients exigée par les écouteurs est la version 3.5 mise à jour ou la version 4.0 ou ultérieure, comme indiqué dans la section Continuité des activités et récupération de la base de données – SQL Server.
Pour fournir leurs fonctionnalités, les groupes de disponibilité s'appuient sur des couches d'abstraction sous-jacentes et s'exécutent dans un cluster de basculement Windows Server (WSFC), comme indiqué dans la section Clustering de basculement Windows Server avec SQL Server. Tous les nœuds qui exécutent des instances SQL Server doivent faire partie du même WSFC.
Les transactions sont envoyées de la base de données principale vers toutes les instances dupliquées secondaires. Il existe deux façons d'envoyer les transactions : le mode synchrone et le mode asynchrone. Chaque instance dupliquée peut être configurée indépendamment pour utiliser l'un ou l'autre mode. En mode d'envoi synchrone, la transaction sur la base de données principale n'aboutit que si elle réussit sur toutes les instances dupliquées secondaires reliées de manière synchrone. En mode asynchrone, la transaction sur la base de données principale aboutit même si elle n'est pas appliquée à toutes les instances dupliquées secondaires.
Le choix du mode d’envoi influe sur les valeurs RTO et RPO, ainsi que sur votre mode de secours. Par exemple, si les transactions sont envoyées à toutes les instances dupliquées en mode synchrone, celles-ci ont toutes exactement le même état. La condition de RPO la plus exigeante (transaction la plus récente) est remplie car toutes les instances dupliquées sont entièrement synchronisées. Les instances dupliquées secondaires sont en mode hot standby, ce qui permet de les utiliser immédiatement comme base de données principale.
Le basculement peut être automatique ou manuel. Le basculement automatique est possible si toutes les instances dupliquées sont entièrement synchronisées. C'est le cas dans l'exemple précédent, car toutes les instances dupliquées sont toujours entièrement synchronisées.
Le schéma suivant montre un groupe de disponibilité Always On dans une seule région.
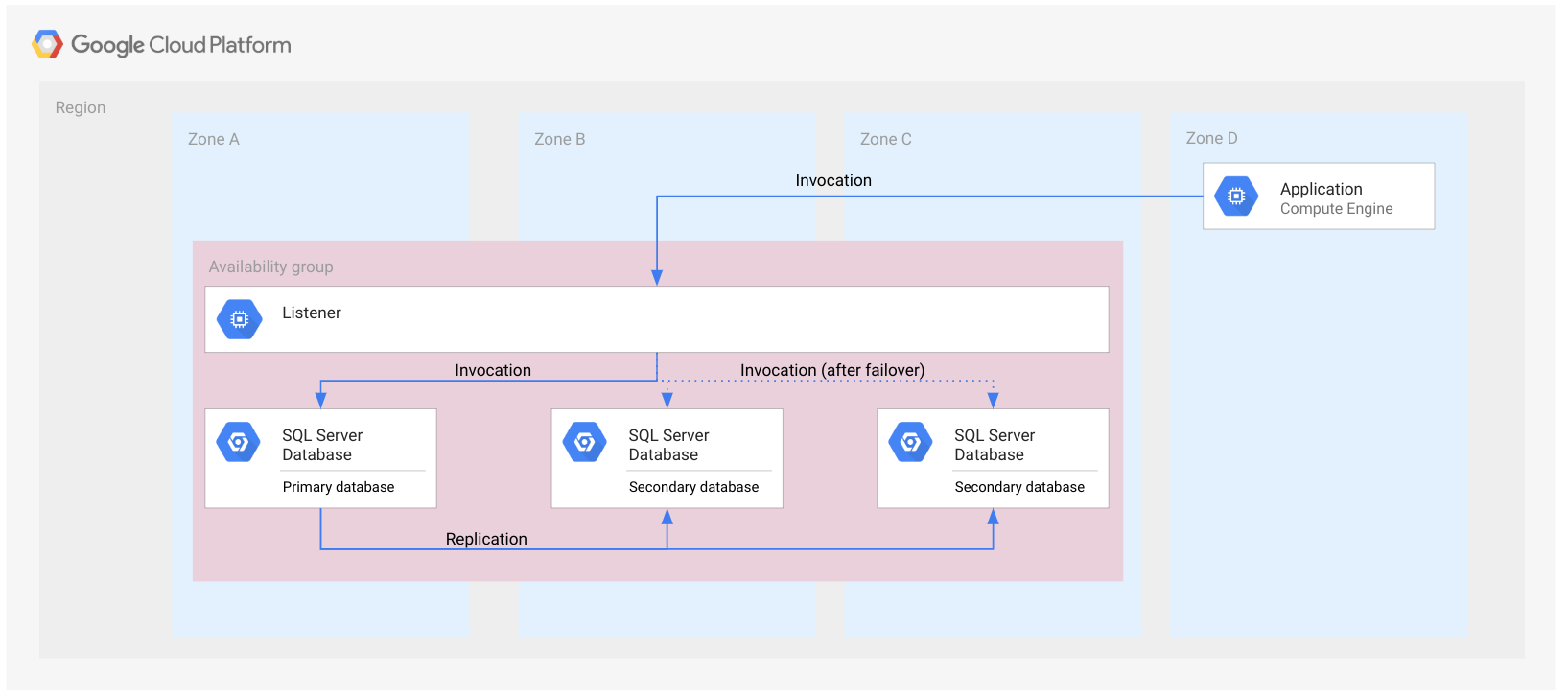
Le groupe de disponibilité est représenté sous forme de rectangles délimitant les zones. Cette présentation n'est fournie qu'à des fins d'illustration pour indiquer que toutes les bases de données appartiennent au même groupe de disponibilité. Le groupe de disponibilité n'est pas une ressource cloud et, à ce titre, n'est pas mis en œuvre dans un nœud ni dans aucun autre type de ressource.
Instance de cluster de basculement Always On
Pour vous protéger contre les défaillances de nœud, vous pouvez utiliser des instances de cluster de basculement (FCI) au lieu d'instances SQL Server autonomes. Une base de données (principale et secondaire) est gérée par deux ou plusieurs nœuds qui exécutent des instances SQL Server. Les nœuds qui gèrent une base de données constituent un cluster de basculement. L'un des nœuds du cluster exécute une instance SQL Server de façon active et les autres nœuds n'interviennent pas dans le processus. En cas d'échec du nœud qui exécute l'instance SQL Server, un autre nœud du cluster démarre une instance SQL Server et assure la gestion de la base de données (basculement de nœud). Ce processus de démarrage automatique d'une instance SQL Server fournit la fonctionnalité de haute disponibilité.
Le cluster FCI apparaît en tant qu'unité unique et les clients accédant au cluster ne perçoivent pas le basculement entre les nœuds, sauf peut-être pendant un court délai d'indisponibilité. Le basculement d'un nœud n'entraîne aucune perte de données. Tout ce qui s'exécute dans l'instance SQL Server défaillante est transféré vers une autre instance SQL Server du même cluster. Par exemple, les tâches de l'agent SQL Server ou les serveurs associés sont déplacés vers une autre instance.
Les nœuds de cluster FCI peuvent être configurés dans différentes Google Cloud zones. Cette architecture offre non seulement une haute disponibilité en cas de défaillance de nœud, mais également en cas de défaillance de zone. La section Autres solutions de déploiement de reprise après sinistre présente un exemple de mise en œuvre de cette stratégie.
Même si, dans un cluster FCI, plusieurs nœuds gèrent la même base de données et la partagent, il n'est pas nécessaire de prévoir un stockage commun pour les différents nœuds. SQL Server utilise la fonctionnalité S2D (Storage Space Direct) pour gérer les bases de données sur des disques de nœud dédiés. Pour plus d'informations, consultez la section Configurer des instances de cluster de basculement SQL Server.
Le schéma suivant montre l'exemple de la section précédente Groupes de disponibilité Always On avec des instances FCI au lieu d'instances SQL Server autonomes. Chaque instance FCI dispose d'une instance SQL Server active qui gère la base de données.
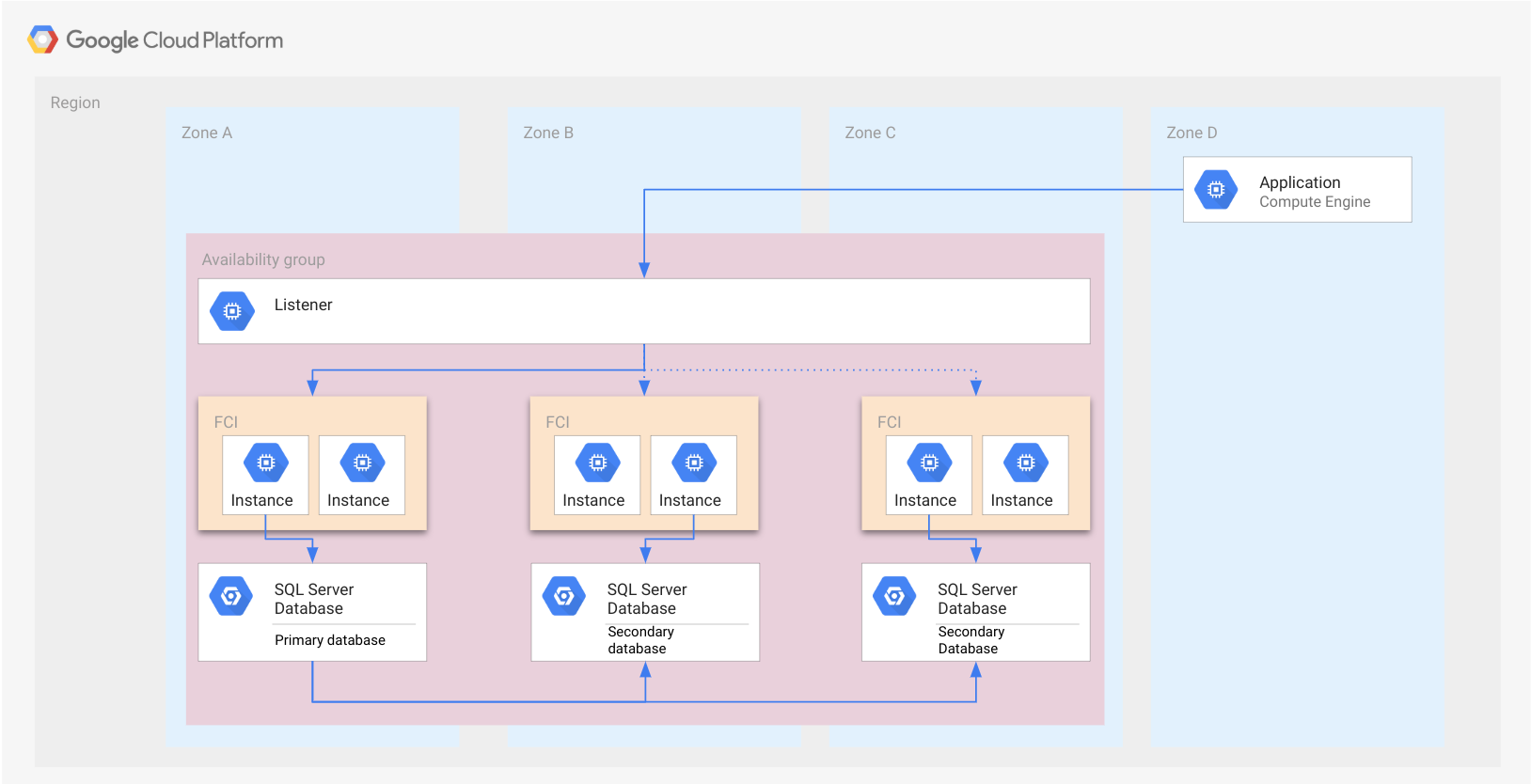
Comme dans le cas du groupe de disponibilité, une FCI est représentée par un rectangle. Cette présentation n'est fournie qu'à des fins d'illustration pour indiquer que les nœuds appartiennent tous à la même interface FCI. Une FCI n'est pas une ressource cloud et n'est donc pas mise en œuvre dans un nœud ni dans aucun autre type de ressource.
Pour des explications plus détaillées, reportez-vous à la section Instances de cluster de basculement Always On (SQL Server).
Groupes de disponibilité distribués
Un groupe de disponibilité distribué est un type particulier qui englobe deux groupes de disponibilité aux rôles différents, l'un comme groupe de disponibilité principal et l'autre comme groupe de disponibilité secondaire. Les groupes de disponibilité distribués peuvent envoyer des transactions en mode synchrone ou asynchrone du groupe de disponibilité principal au groupe de disponibilité secondaire.
Même si chacun des groupes de disponibilité possède sa propre base de données principale, il ne s'agit pas d'un déploiement en mode actif-actif. Seule la base de données principale du groupe de disponibilité principal peut recevoir des opérations d'écriture. La base de données principale du groupe de disponibilité secondaire s'appelle le redirecteur. Celui-ci reçoit les transactions du groupe de disponibilité principal et les transmet aux bases de données secondaires du groupe de disponibilité secondaire. En l'absence de redirecteur, le basculement du groupe de disponibilité principal vers le groupe de disponibilité secondaire rendrait la base de données principale du nouveau groupe de disponibilité principal accessible aux opérations d'écriture.
Les groupes de disponibilité principal et secondaire ne doivent pas nécessairement se trouver au même emplacement, ni appartenir au même système d'exploitation. Cependant, chaque groupe de disponibilité doit avoir un écouteur installé. En soi, le groupe de disponibilité distribué n'a pas d'écouteur. Les groupes de disponibilité distribués fonctionnent même si les deux groupes de disponibilité ne se situent pas dans le même WSFC. Toutes les fonctions nécessaires au fonctionnement des groupes de disponibilité distribués sont incluses dans la fonctionnalité SQL Server. Aucune installation supplémentaire de composants sous-jacents n'est nécessaire.
Un groupe de disponibilité distribué couvre exactement deux groupes de disponibilité. Un groupe de disponibilité peut faire partie de deux groupes de disponibilité distribués. Cette possibilité est compatible avec différentes topologies, telles que les appels en série d’un groupe de disponibilité à l’autre entre plusieurs emplacements, ou une topologie sous forme d'arborescence dans laquelle le groupe de disponibilité principal fait partie de deux groupes de disponibilité distribués distincts.
Les groupes de disponibilité distribués constituent le principal moyen de mettre en œuvre une reprise après sinistre sur l'ensemble des systèmes d'exploitation. Par exemple, le groupe de disponibilité principal peut être configuré sous Windows et un deuxième groupe correspondant sous Linux, les deux formant un groupe de disponibilité distribué.
Le schéma suivant montre deux groupes de disponibilité faisant partie d'un groupe de disponibilité distribué.
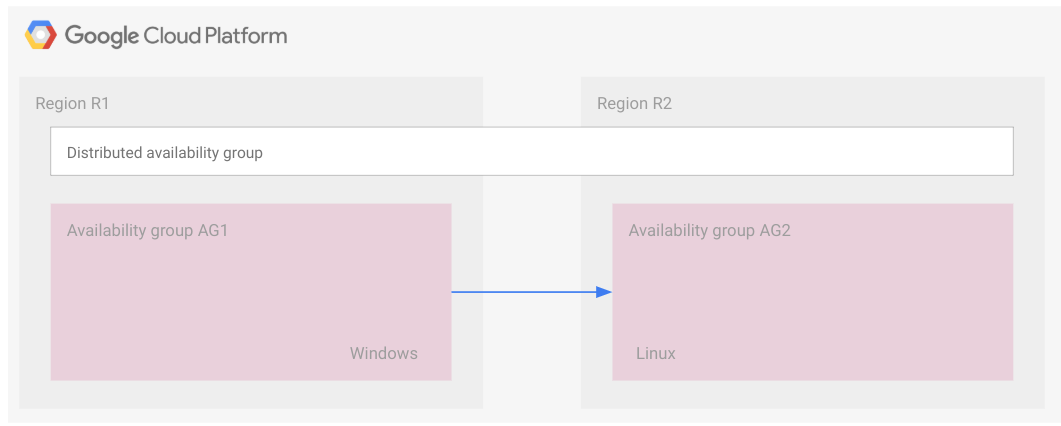
Le groupe de disponibilité 1 est le groupe de disponibilité principal et le groupe de disponibilité 2 le groupe de disponibilité secondaire.
Comme pour les instances FCI, un groupe de disponibilité distribué est représenté par un rectangle. Cette présentation n'est fournie qu'à titre d'illustration pour indiquer que les groupes de disponibilité appartiennent tous au même groupe de disponibilité distribué. Un groupe de disponibilité distribué, de même qu'un groupe de disponibilité, n'est pas une ressource cloud et n'est donc pas mis en œuvre dans un nœud ni dans aucun autre type de ressource.
Pour plus d'informations, consultez la section Groupes de disponibilité distribués.
Envoi des journaux
L'envoi des journaux (log shipping) des transactions est une fonctionnalité de disponibilité de SQL Server lorsque les conditions RTO et RPO sont peu contraignantes (RTO faible ou RPO récent), car la différence d'état entre une base de données principale et sa base de données secondaire est nettement plus importante. L'ampleur de la différence s'explique par les nombreux changements d'état que contiennent les fichiers journaux des transactions. La différence en matière de latence est également importante car les fichiers journaux des transactions sont envoyés de manière asynchrone et appliqués en intégralité à une base de données secondaire.
Les fichiers journaux des transactions sont créés par la base de données principale et sauvegardés, par exemple, sur Cloud Storage. Chaque fichier journal des transactions est copié dans chaque base de données secondaire et appliqué à celle-ci. Comme la base de données secondaire est en retard par rapport à la base de données principale, le mode de secours est semi-automatique (warm standby). Les objets et les modifications qui ne sont pas consignés dans les journaux des transactions doivent être appliqués manuellement aux bases de données secondaires pour assurer une synchronisation complète sans perte de données.
L'agent SQL Server automatise l'ensemble du processus de création, de copie et d'application des journaux des transactions. L'envoi des journaux doit être configuré séparément pour chaque base de données. Si un groupe de disponibilité gère plusieurs bases de données, vous devez configurer autant de processus d'envoi des journaux.
En cas d'échec, le processus de reprise après sinistre doit être lancé manuellement car il n'existe pas de dispositif d'assistance automatisé. En outre, l'accès client n'est pas extrait de la base de données principale et des bases de données secondaires par un écouteur. En cas de basculement, les clients doivent pouvoir gérer eux-mêmes le changement de rôle d'une base de données, du rôle secondaire au nouveau rôle principal, en se connectant à la nouvelle base de données principale à la suite d'une reprise après sinistre. Il est possible de créer des abstractions distinctes indépendamment des instances SQL Server, par exemple au moyen d'adresses IP flottantes, comme décrit dans les bonnes pratiques pour les adresses IP flottantes.
L'envoi des journaux étant pour partie un processus manuel, vous pouvez différer de façon intentionnelle l'application des fichiers journaux copiés aux bases de données secondaires, contrairement aux groupes de disponibilité et aux groupes de disponibilité distribués dans lesquels les modifications sont appliquées immédiatement. Un cas d'utilisation possible consiste à éviter que des erreurs de modification de données sur la base de données principale soient appliquées à des bases de données secondaires tant que ces erreurs ne sont pas corrigées. Dans ce cas, une base de données secondaire pour laquelle aucune erreur de modification de données n'a encore été appliquée pourrait devenir la base de données principale jusqu'à ce que l'erreur de modification de données soit corrigée. Ensuite, le traitement normal peut reprendre.
Comme pour les groupes de disponibilité distribués, vous pouvez utiliser l'envoi des journaux pour des solutions multiplates-formes où, par exemple, la base de données principale s'exécute sous Linux, tandis que les bases de données secondaires s'exécutent sous Linux et Windows.
Le schéma suivant montre un déploiement multiplate-forme avec envoi des journaux. Notez qu'il n'y a pas de configuration commune sur l'ensemble des régions comme c'est le cas pour un groupe de disponibilité distribué dans cette topologie.
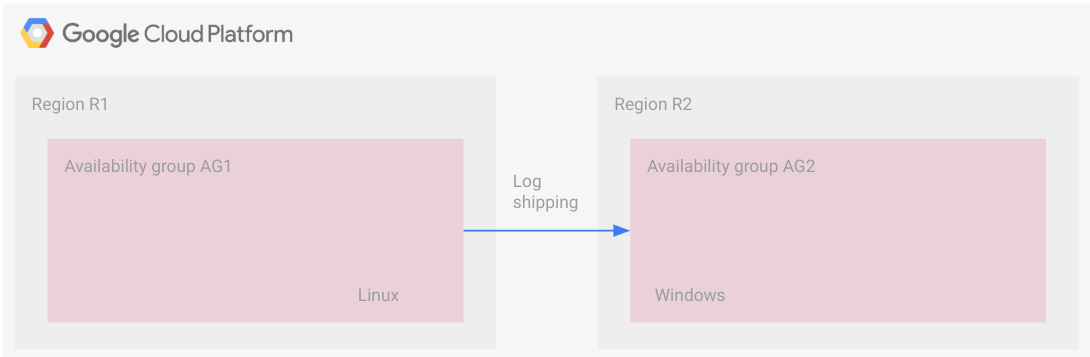
Les groupes de disponibilité résident dans des régions distinctes, l'un s'exécutant sous Linux et l'autre sous Windows.
Pour plus d'informations sur l'envoi des journaux SQL Server, reportez-vous à la section À propos de l'envoi des journaux (SQL Server).
Combiner des fonctionnalités de disponibilité de SQL Server
Vous pouvez déployer les fonctionnalités de disponibilité SQL Server selon différentes combinaisons. Par exemple, dans le cas d'utilisation précédent, l'envoi des journaux était appliqué à différents groupes de disponibilité installés sur différents systèmes d'exploitation.
Voici une liste de certaines fonctionnalités de disponibilité de SQL Server qu'il est possible de combiner :
- Appliquer l'envoi des journaux aux différents groupes de disponibilité installés sur le même système d'exploitation.
- Combiner des instances FCI pour un groupe de disponibilité principal avec un groupe de disponibilité secondaire qui n'utilise que des instances SQL Server autonomes.
- Combiner un groupe de disponibilité distribué sur plusieurs régions voisines avec l'envoi des journaux dans des régions situées sur des continents différents.
Ce ne sont que quelques-unes des combinaisons possibles des fonctionnalités de disponibilité de SQL Server.
La flexibilité offerte par les fonctionnalités de disponibilité de SQL Server permet de définir avec précision une stratégie de reprise après sinistre en fonction des exigences spécifiées.
Réplication SQL Server
La réplication SQL Server n'est généralement pas considérée comme une fonctionnalité de disponibilité, mais il est possible de l'utiliser pour la reprise après sinistre, comme décrit dans cette section.
La fonctionnalité de réplication permet de créer et de gérer des instances dupliquées de bases de données. Différents types d'agents SQL Server interviennent conjointement pour consigner les modifications, effectuer leur transmission et les appliquer aux instances dupliquées. Ce processus est asynchrone et les instances dupliquées sont généralement en retard par rapport à la base de données en cours de réplication, à des degrés divers.
Par exemple, il est possible d'avoir une instance dupliquée d'une base de données de production. Dans le contexte d'une reprise après sinistre, la base de données de production constitue la base de données principale et l'instance dupliquée la base de données secondaire. La fonctionnalité de réplication de SQL Server ignore les différents rôles assurés par les bases de données dans le cas d'une reprise après sinistre. Par conséquent, certaines opérations intégrées au processus de reprise après sinistre, comme les changements de rôle, ne sont pas possibles dans la réplication. La reprise après sinistre doit donc être mise en œuvre séparément de la fonctionnalité SQL Server et exécutée par l'organisation qui en est chargée, car il n'existe aucune abstraction des accès client.
Envoi des fichiers de sauvegarde
L'envoi des fichiers de sauvegarde est une autre stratégie de mise en œuvre de la reprise après sinistre. L'approche standard pour configurer et mettre à jour en permanence une base de données secondaire consiste à effectuer une sauvegarde complète initiale de la base de données principale et des sauvegardes incrémentielles par la suite. Toutes les sauvegardes incrémentielles sont appliquées aux bases de données secondaires dans le bon ordre. Il existe de nombreuses variantes de cette approche en fonction de la fréquence des sauvegardes incrémentielles, puis de l'emplacement de stockage du fichier de sauvegarde (emplacement global ou réellement copié entre les emplacements).
Cette stratégie n'implique aucune fonctionnalité de disponibilité de SQL Server lors de la réplication des modifications d'état de la base de données principale vers une base de données secondaire. L'agent SQL Server n'est pas utilisé dans le cas de l'envoi des journaux.
Pour plus d'informations, consultez la page Exemple : stratégie de sauvegarde et restauration de reprise après sinistre.
Par rapport à l'approche de réplication exposée dans la section précédente, la réplication et l'envoi du fichier de sauvegarde ont en commun une mise en œuvre du processus de reprise après sinistre distincte et extérieure à l'ensemble de fonctionnalités de SQL Server. Du point de vue de l'envoi des modifications capturées, la réplication SQL Server est plus pratique car cette partie est mise en œuvre automatiquement à l'aide d'agents SQL Server.
Remarque sur les interactions entre le cycle de vie de la base de données et celui des applications
Un basculement de base de données n'est pas complètement séparé et indépendant des applications qui accèdent à la base de données. En principe, deux scénarios d'échec peuvent se présenter.
Tout d'abord, l'application reste opérationnelle pendant le basculement de la base de données. À partir du moment où la base de données principale est indisponible jusqu'au moment où la nouvelle base de données principale est opérationnelle, les applications ne peuvent plus accéder à la base de données. Les connexions existantes échouent et aucune nouvelle connexion n'est établie. Pendant ce temps, l'application n'est pas en mesure de servir ses clients, du moins lorsque la fonctionnalité nécessite un accès à la base de données. Les applications doivent reconnaître le moment où la nouvelle base de données principale est disponible afin de pouvoir reprendre le traitement normal.
Les applications peuvent avoir un état extérieur à la base de données, par exemple, dans les caches de la mémoire principale. L'application s'assure que le cache est cohérent (synchronisé) avec la nouvelle base de données principale. S'il n'existe aucune perte de transactions pendant le basculement, le cache peut être cohérent sans autre intervention. Toutefois, si une perte (de données) survient au cours du basculement, le cache risque de ne pas être cohérent par rapport à la nouvelle base de données principale. Une problématique analogue concerne les états partagés lorsque, par exemple, certaines données de la base de données font également partie de messages dans des files d'attente ou de fichiers dans le système de fichiers. Cet aspect de la cohérence des données n'est pas abordé dans ce document car il n'est pas directement lié à la reprise après sinistre de base de données.
Ensuite, une ou plusieurs applications peuvent devenir indisponibles en même temps que la base de données principale. Par exemple, si une région est déconnectée, un système d'application s'exécutant dans cette région sera tout autant indisponible que la base de données principale de cette même région. Dans ce cas, outre le système de base de données principale, l'application doit également être récupérée. Parallèlement au processus de reprise après sinistre de base de données, vous devez lancer un processus similaire de récupération de l'application. L'application récupérée doit se connecter à la nouvelle base de données principale et être reconfigurée au moyen, par exemple, d'adresses IP flottantes. La récupération de l'application n'entre pas dans le cadre de ce document.
Relation entre la sauvegarde et restauration et la reprise après sinistre
La sauvegarde d'une base de données est indépendante et perpendiculaire à la reprise après sinistre de base de données. Le but de la sauvegarde de base de données est de pouvoir restaurer un état cohérent, dans le cas, par exemple, où une base de données serait perdue ou corrompue, ou si un état précédent devait être restauré en raison de défaillances d'applications ou de bugs.
La section suivante explique comment utiliser les sauvegardes comme mécanisme possible pour mettre en œuvre une reprise après sinistre de base de données. Dans ce scénario, vous copiez les fichiers de sauvegarde à l'emplacement de la base de données secondaire afin que celle-ci puisse être restaurée. Toutefois, les fichiers de sauvegarde ne sont pas une condition préalable à la reprise après sinistre. Des solutions alternatives ont été présentées dans la section précédente consacrée aux fonctionnalités de disponibilité.
Haute disponibilité et reprise après sinistre
La haute disponibilité et la reprise après sinistre ont en commun le fait de fournir des solutions pour l’indisponibilité des bases de données. Si une base de données principale devient indisponible, une base de données secondaire devient la nouvelle base de données principale cohérente et disponible.
La différence entre la haute disponibilité et la reprise après sinistre réside dans le domaine du point de défaillance unique. La haute disponibilité corrige une panne dans une région, par exemple, en cas de défaillance d'une seule région ou d'un nœud. Une solution à haute disponibilité fournit une nouvelle base de données principale dans une autre zone de la même région. De plus, outre les problèmes de bases de données, la haute disponibilité résout aussi les problèmes de nœuds. Si un nœud exécutant une instance SQL Server échoue, un nouveau nœud est rendu disponible en exécutant une nouvelle instance SQL Server (voir les explications dans la section Instance de cluster de basculement Always On).
La reprise après sinistre concerne au moins deux régions. Le processus s'applique dans le cas où une région entière devient indisponible. La reprise après sinistre peut alors fournir une nouvelle base de données principale dans une région différente.
Les fonctionnalités de haute disponibilité de SQL Server proposent à la fois des solutions de haute disponibilité et de reprise après sinistre. Un seul groupe de disponibilité peut couvrir les zones d'une région ainsi que les régions elles-mêmes. Un groupe de disponibilité peut contenir des instances de cluster de basculement pour répondre aux exigences de haute disponibilité.
SQL Server peut établir des groupes de disponibilité dans une région pour gérer la haute disponibilité et les défaillances de zone, et les combiner à l'envoi des journaux sur l'ensemble des régions pour gérer la reprise après sinistre.
Autres solutions de déploiement de DR
Les sections suivantes présentent d'autres topologies de reprise après sinistre possibles, en plus de celles décrites jusqu'ici. Ces topologies répondent à différentes exigences de RPO et de RTO. Cette liste n'est pas exhaustive.
DR intrarégionale et haute disponibilité
Ce déploiement est une variante d'un groupe de disponibilité contenant des instances FCI, au sein d'une région composée de trois zones. Dans ce scénario, les zones sont considérées comme le point de défaillance unique.
Par rapport au déploiement présenté précédemment, chaque interface FCI comporte trois nœuds, chacun s’exécutant dans une zone différente. L'avantage de cette configuration est qu'une ou plusieurs zones peuvent échouer sans qu'un processus de reprise après sinistre ne soit nécessaire.
Le schéma suivant illustre cette configuration.
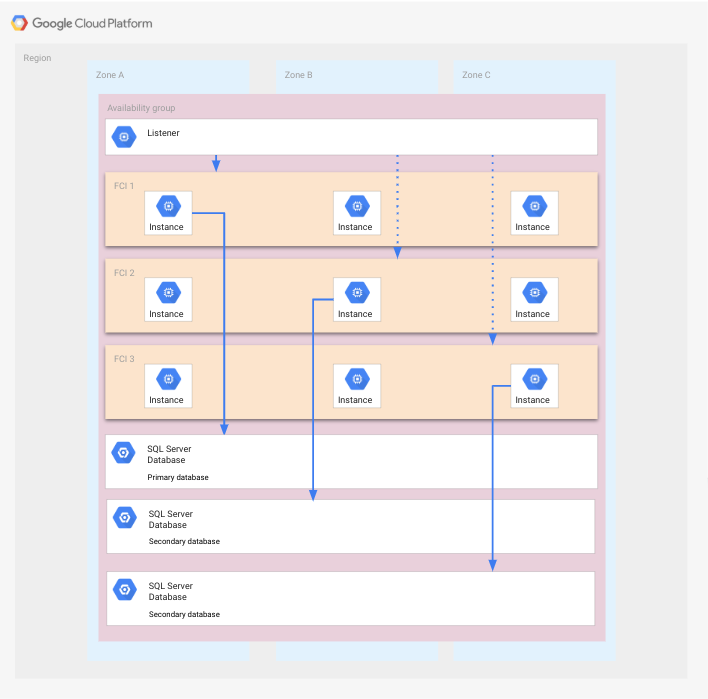
Les instances FCI couvrent toutes les zones et chacune d'entre elles dispose d'une instance SQL Server en cours d'exécution accédant à la base de données correspondante. Chaque instance FCI comporte également deux autres instances SQL Server, non exécutées et pouvant être démarrées en cas de défaillance d'une zone. Les bases de données sont affichées sur plusieurs zones, car chaque base de données utilise les disques de tous les nœuds d'une instance FCI donnée. Par souci de clarté, l'application n'est pas indiquée.
DR interrégionale : groupe de disponibilité couvrant les régions
Dans ce scénario, un groupe de disponibilité s'exécute sur un cluster de basculement Windows Server et s'étend sur deux régions. Les régions sont considérées comme un seul point de défaillance.
Cette configuration est expliquée dans le schéma suivant.

Afin de résoudre les problèmes de latence potentiels, vous pouvez configurer les instances dupliquées de la région R1 pour utiliser la propagation des transactions en mode synchrone, tandis que les instances dupliquées de la région R2 sont configurées pour utiliser la propagation des transactions en mode asynchrone.
DR interrégionale : transfert des fichiers de sauvegarde
Ce scénario utilise le transfert des fichiers de sauvegarde. Deux groupes de disponibilité dans deux régions sont liés. Les instances dupliquées de chaque groupe de disponibilité reçoivent les transactions de manière synchrone. Les instances dupliquées secondaires de chaque région sont donc dans une configuration de secours à chaud (Hot Standby).
Cette configuration est expliquée dans le schéma suivant.
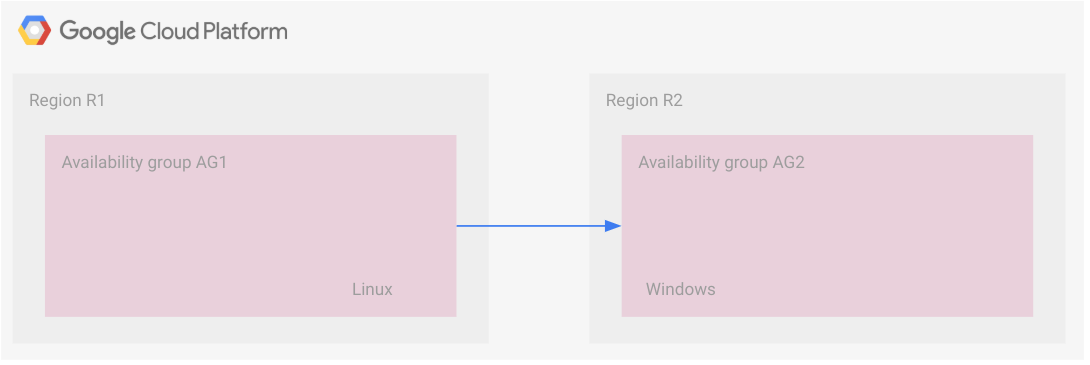
Cependant, les deux groupes de disponibilité sont connectés par transfert de fichier de sauvegarde. Le groupe de disponibilité AG1 est le groupe de disponibilité principal et le groupe de disponibilité AG2 est le groupe de disponibilité secondaire. Lorsque les fichiers de sauvegarde sont mis à la disposition du groupe de disponibilité secondaire, ils y sont appliqués. Ce scénario est décrit plus en détail dans la section suivante, Exemple : stratégie de sauvegarde et restauration de reprise après sinistre.
Topologie d'emplacement double et d'emplacement tertiaire
S'il n'y a que deux bases de données, une base de données principale et une base de données secondaire, chacune dans une région distincte, il existe une durée non protégée après un basculement entre le moment où la nouvelle base de données principale est opérationnelle et celui où la nouvelle base de données secondaire est prête. Si la nouvelle base de données principale devient indisponible alors que la base de données secondaire n'est pas encore opérationnelle, il s'ensuit un temps d'arrêt important qui ne peut être récupéré qu'à partir du moment où une nouvelle base de données principale est établie. Les groupes de disponibilité sont soumis aux mêmes conditions.
Pour contourner le problème de durée non protégée après un basculement, un troisième emplacement exécutant une autre base de données secondaire ou un groupe de disponibilité peut être défini. Cette configuration doit garantir que l’une des deux bases de données secondaires reste une base de données secondaire et soit réaffectée à une nouvelle base de données principale afin qu’aucune perte de données ne se produise. Comme précédemment, la situation est la même pour les groupes de disponibilité.
Cycle de vie d'une DR
Quelle que soit la solution de reprise après sinistre que vous choisissez, différentes étapes du cycle de vie s’appliquent.
Lors d'une reprise après sinistre en conditions réelles, toutes les parties prenantes (propriétaires d'applications, groupes opérationnels et administrateurs de base de données) doivent être disponibles et participer activement à la gestion du processus. Les intervenants doivent décider de l'autorité de décision (parfois appelée maître de cérémonie) et des processus décisionnels à suivre. De plus, tous doivent se mettre d’accord sur la terminologie employée et les méthodes de communication.
Décider de lancer un processus de basculement
À moins que le basculement ne soit déclenché automatiquement, les parties prenantes doivent prendre la décision de lancer un basculement. Cette décision doit être étroitement coordonnée entre les différents intervenants.
Le lancement d'un processus de basculement dépend de plusieurs facteurs, en premier lieu l'indisponibilité de la base de données principale.
Si le processus de reprise après sinistre prend plus de temps que celui nécessaire pour résoudre l'indisponibilité de la base de données principale, un basculement serait préjudiciable. Vous devez d'abord évaluer la faisabilité d'une restauration de la base de données principale.
Plus la stratégie de reprise après sinistre est testée, plus sa mise en œuvre est rapide, et plus le processus de basculement est facile, selon le principe de moindre incertitude dont la décision doit tenir compte.
Exécution du processus de basculement
Le processus de basculement doit normalement être testé régulièrement. Il devrait donc être bien connu des différentes parties prenantes.
L'autorité de décision doit être informée de toutes les étapes en cours et de tous les problèmes inattendus. L'autorité de décision dirige le processus de basculement et les intervenants sont tenus de l'assister.
Vous devez conserver des statistiques pour l'analyse post-mortem et l'amélioration du processus de basculement, y compris la durée des activités, les problèmes survenus et toute confusion ayant affecté les différentes étapes.
Protection manquante
Si vous ne disposez que d'une base de données secondaire, aucune protection DR n'existe, à partir du moment où la nouvelle base de données principale est disponible et opérationnelle, jusqu'à la création d'une nouvelle base de données secondaire. Une indisponibilité pendant cet intervalle peut provoquer une panne matérielle, car aucun basculement vers une autre base de données n'est possible. Si cette situation se présente, une autre base de données principale doit être configurée et le RPA est le dernier point pouvant être reconstruit en fonction des sauvegardes disponibles.
À moins que la stratégie de reprise après sinistre ne soit configurée de manière à assurer une protection permanente, chaque intervenant doit être conscient de cet intervalle de protection manquante de façon à prendre des précautions supplémentaires lors de la configuration ou des modifications de la configuration de l'environnement.
Vous pouvez éviter cet intervalle sans protection si l'accès des applications à la nouvelle base de données principale est retardé jusqu'à ce que la nouvelle base de données secondaire soit opérationnelle. Dès que les modifications de la base de données principale sont appliquées, celle-ci est disponible pour les applications. Bien que cette approche évite tout intervalle pendant lequel les applications ne sont pas protégées de la DR, elle retarde l'achèvement du processus de reprise après sinistre.
Éviter les situations de split-brain
Il est important que les applications ne puissent pas accéder simultanément à une base de données principale et à une base de données secondaire, en lançant des opérations LMD. Dans cette situation, une incohérence dans les données se produit lorsque la base de données principale et la base de données secondaire sont en désaccord sur les valeurs de données du même élément de données (split-brain ou cerveau divisé). Cette architecture est particulièrement importante si la base de données principale devient indisponible alors que son exécution se poursuit et qu'elle peut recevoir des opérations d'écriture. Si l'indisponibilité est provoquée par un partitionnement intermittent du réseau, celui-ci peut cesser à tout moment et une application peut à nouveau avoir accès. Si un processus de basculement se produit à ce moment, les modifications apportées à l'ancienne base de données principale risquent d'être perdues, ou certaines applications peuvent commencer à fonctionner sur la nouvelle base de données principale, tandis que d'autres continuent d'accéder à l'ancienne.
Tous les accès aux applications sont désactivés pour toutes les bases de données pendant le processus de basculement, afin qu'aucun changement d'état ne puisse se produire dans aucune des bases de données. Après le basculement, une seule base de données est disponible pour les opérations d'écriture, soit la nouvelle base de données principale.
Déclaration d'achèvement
Une fois le processus de basculement terminé, tous les intervenants doivent être explicitement informés par l'autorité de décision que le processus est terminé. Tout problème qui apparaît après l'achèvement doit être considéré comme un incident séparé ne faisant plus partie du processus de basculement mais d'un traitement normal. L'incident peut être la conséquence d'un problème lié au processus de basculement ou totalement indépendant. Cependant, l'approche consistant à traiter le problème une fois le processus de basculement terminé peut différer de la manière dont il est traité lors de l'exécution du processus de basculement.
Analyse post-mortem et rapport
Pour référence future et afin d'améliorer votre processus de basculement, réalisez immédiatement une analyse post-mortem pour prendre note des aspects, des résultats et des éléments d'action importants.
Rédigez un rapport qui résume l'événement de reprise après sinistre, les causes premières et toutes les actions entreprises. Ce rapport peut être obligatoire si vous mettez en œuvre des exigences réglementaires.
Tests et vérification de DR
Étant donné que la reprise après sinistre ne fait pas partie des opérations quotidiennes normales, votre solution DR doit être testée régulièrement pour en garantir le bon fonctionnement en cas de besoin.
La fréquence des tests dépend des exigences opérationnelles et varie en fonction de la base de données, de l'application et de l'entreprise. En outre, les modifications apportées à l'environnement, telles que les modifications de la configuration réseau et les mises à jour des composants d'infrastructure, doivent déclencher un test de reprise après sinistre si les modifications sont apportées aux systèmes sur lesquels repose la solution de DR choisie. Toute modification pourrait entraîner l'échec de la solution de reprise après sinistre ou nécessiter un ajustement du processus.
Vous pouvez réaliser un test manuellement en lançant le processus de basculement, ou automatiquement en suivant une approche d'ingénierie du chaos, comme décrit dans la page Ingénierie du chaos. En procédant manuellement, vous pouvez minimiser l'impact du test sur votre entreprise si vous anticipez des temps d'arrêt significatifs.
Un aspect important du test consiste à collecter des statistiques bien définies. Voici quelques statistiques importantes à considérer :
- Temps de récupération réel : mesurez le temps de récupération réel et comparez-le avec le RTO.
- Point de récupération réel : observez le point de récupération réel et comparez-le avec le RPO.
- Détection du délai avant échec : délai nécessaire aux administrateurs de base de données ou à l'équipe chargée des opérations pour prendre conscience de la nécessité du basculement.
- Délai avant lancement de la récupération : temps nécessaire au démarrage du processus de basculement après la détection de la défaillance.
- Fiabilité : dans quelle mesure le processus de basculement a-t-il été suivi ? Des divergences ont-elles été nécessaires ? Des problèmes inattendus ont-ils surgi qui nécessitent un examen, ce qui pourrait entraîner une modification de la stratégie de reprise ?
Sur la base des statistiques collectées, il est possible que le processus de basculement doive être ajusté ou amélioré afin de mieux correspondre aux attentes du RPO et du RTO.
Exemple : stratégie de sauvegarde et restauration de reprise après sinistre
Les sections suivantes décrivent un exemple de stratégie de reprise après sinistre par sauvegarde et restauration. Ce scénario minimise l'utilisation des fonctionnalités de disponibilité de SQL Server afin d'illustrer l'effort nécessaire pour spécifier une stratégie de sauvegarde et restauration de reprise après sinistre et de décrire les aspects non visibles des configurations davantage automatisées.
Cas d'utilisation
Un groupe de disponibilité principal Always On est situé et opérationnel dans la région R1. Le groupe de disponibilité secondaire Always On est ajouté dans la région R2 pour assurer une protection interrégionale supplémentaire et est disponible en tant que cible de basculement ou de commutation.
Stratégie
La stratégie de reprise après sinistre est basée sur les sauvegardes de base de données. Une sauvegarde complète initiale est effectuée, suivie de sauvegardes différentielles ultérieures. Les sauvegardes sont appliquées au groupe de disponibilité secondaire Always On au fur et à mesure de leur création. Toutes les sauvegardes sont stockées dans un bucket Cloud Storage.
Dans cet exemple, une fois le basculement terminé, il est acceptable que le nouveau groupe de disponibilité principal Always On de la région R2 soit actif et non protégé pendant une durée limitée, jusqu'à ce que le nouveau groupe de disponibilité secondaire de la région R1 soit opérationnel.
Aucun basculement n'est nécessaire, car le groupe de disponibilité Always On dans chacune des régions est également qualifié pour servir de groupe de disponibilité de production Always On.
RTO et RPO
Le RPO étant défini dans cet exemple sur une durée maximale de 60 minutes, une sauvegarde différentielle est effectuée toutes les 60 minutes.
Le RTO n'est pas défini explicitement sur une durée, mais sa valeur doit être la plus faible possible, voire égale à zéro dans le meilleur des cas pour une récupération immédiate. Le groupe de disponibilité secondaire doit être configuré en mode Hot Standby. Dans ce mode, toutes les sauvegardes sont immédiatement appliquées afin que le basculement ne retarde pas l'application des sauvegardes.
Stratégie DR de premier niveau
La stratégie de reprise après sinistre est décrite dans les sections suivantes. La présentation est volontairement brève afin de se concentrer sur les étapes essentielles.
Configuration initiale
- Créez un groupe de disponibilité secondaire Always On dans la région R2.
- Empêchez les applications d'accéder au groupe de disponibilité secondaire afin d'éviter toute situation de split-brain.
- Créez le bucket des fichiers de sauvegarde B1 dans Cloud Storage qui contiendra la sauvegarde complète initiale du groupe de disponibilité Always On de la région R1 et les sauvegardes différentielles horaires suivantes du groupe de disponibilité Always On de la région R1. L'ordre des sauvegardes différentielles doit être établi pour que le processus qui applique les sauvegardes au groupe de disponibilité secondaire puisse le respecter. Vous pouvez, par exemple, définir une convention d'attribution de nom permettant d’établir l'ordre chronologique en fonction de la date et de l’heure spécifiées dans les différents noms de fichiers.
Stratégie de lancement
- Appliquez la sauvegarde complète au groupe de disponibilité secondaire Always On de la région R2.
- Lorsque les sauvegardes différentielles deviennent disponibles, appliquez-les immédiatement au groupe de disponibilité secondaire Always On de la région R2. L'application immédiate est nécessaire afin de répondre aux conditions du RTO.
- Une fois la sauvegarde complète initiale et toutes les sauvegardes incrémentielles appliquées, le groupe de disponibilité secondaire Always On est prêt.
- Testez la stratégie de reprise après sinistre en effectuant un basculement du groupe de disponibilité principal vers le groupe de disponibilité secondaire. Un minimum d'une sauvegarde incrémentielle doit être disponible pendant les tests.
Basculement ou commutation
Dans la région R2, les étapes essentielles sont les suivantes :
- Assurez-vous que la dernière sauvegarde différentielle a été appliquée au groupe de disponibilité secondaire Always On de la région R2.
- Désignez R2 comme nouveau groupe de disponibilité principal Always On.
- Créez un nouveau bucket B2, effectuez une sauvegarde complète en tant que version de référence et ouvrez le nouveau groupe de disponibilité principal pour l'accès aux applications.
- Commencez à effectuer des sauvegardes différentielles.
Dans la région R1, les étapes essentielles sont les suivantes :
- Supprimez le bucket B1 car il n'est plus nécessaire.
- Lorsque le groupe de disponibilité Always On de la région R1 redevient disponible (en tant que nouveau groupe de disponibilité secondaire Always On), interdisez l'accès aux applications et supprimez toutes les données de la base de données ou effectuez une réinitialisation à l'état initial (vide) (sauf s'il s'agit d'une création).
- Appliquez la sauvegarde complète à partir du nouveau groupe de disponibilité principal Always On dans R2 et appliquez les sauvegardes différentielles immédiatement dès qu'elles sont disponibles (stockées dans le bucket B2).
Améliorations possibles
Une amélioration possible de la stratégie de reprise après sinistre consiste à éviter d'effectuer une sauvegarde complète après un basculement ou une commutation, tout en étant en mesure de configurer rapidement le nouveau groupe de disponibilité secondaire. Plutôt qu'une sauvegarde complète unique et des sauvegardes différentielles ultérieures, effectuez une sauvegarde complète chaque semaine et créez un bucket hebdomadaire contenant la sauvegarde complète de la semaine et toutes les sauvegardes différentielles ultérieures de cette semaine. Le nouveau groupe de disponibilité principal ne doit créer des sauvegardes différentielles qu'après le basculement (et non une sauvegarde complète) et les ajouter au bucket. Le nouveau groupe de disponibilité secondaire applique simplement toutes les sauvegardes du bucket de la semaine en cours. Si cette approche hebdomadaire est utilisée, vous devez mettre en œuvre une stratégie de nettoyage ou de suppression définitive pour supprimer les sauvegardes obsolètes.
Une autre amélioration repose sur le fait que le nouveau groupe de disponibilité secondaire soit l'ancien groupe de disponibilité principal. Si la base de données existe et qu'elle est opérationnelle une fois à nouveau disponible, une récupération à un moment précis de sa dernière sauvegarde différentielle évite de la restaurer intégralement à partir de la dernière sauvegarde complète, comme décrit dans la section Restaurer une base de données SQL Server à un moment précis (modèle de récupération complet). Ce scénario réduit les efforts et la durée pendant lesquels le nouveau groupe de disponibilité principal n'est pas protégé.
Bonnes pratiques en production
Cette solution ne précise pas si les instances SQL Server des groupes de disponibilité Always On sont des instances autonomes ou FCI. Le type d'instances utilisé doit être décidé avant la mise en œuvre.
Jusqu'à ce qu'un nouveau groupe de disponibilité secondaire Always On soit opérationnel après un basculement, il existe un délai pendant lequel la reprise après sinistre n'est pas assurée. Vous devez configurer un troisième groupe de disponibilité Always On dans une troisième région.
En outre, vous devez mettre en œuvre la surveillance pour vous assurer que toute défaillance ou erreur est détectée. Le sujet de la surveillance n'est pas traité dans ce document. Il s'agit toutefois d'un élément essentiel au bon fonctionnement d'une solution de reprise après sinistre.
Étape suivante
- Configurez des groupes de disponibilité Always On avec SQL Server.
- Déployez un groupe de disponibilité Always On Microsoft SQL Server 2016 à plusieurs sous-réseaux sur Compute Engine.
- Configurez des instances de cluster de basculement SQL Server.
- Exécuter un clustering de basculement Windows Server
- Comment activer Cloud Logging, Cloud Monitoring et Error Reporting pour les applications .NET
- Installer l'agent Cloud Monitoring.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.