Einführung in die BigQuery Storage Write API
Die BigQuery Storage Write API ist eine einheitliche API zur Datenaufnahme für BigQuery. Sie kombiniert die Streamingaufnahme und das Laden im Batch in einer einzigen Hochleistungs-API. Sie können die Storage Write API verwenden, um Datensätze in BigQuery in Echtzeit zu streamen oder eine beliebig große Anzahl von Datensätzen im Batch zu verarbeiten und sie in einem einzigen atomaren Vorgang per Commit zu übergeben.
Vorteile der Storage Write API
Genaue Auslieferungssemantik. Die Storage Write API unterstützt die genau einmalige Semantik durch Verwendung von Stream-Offsets. Anders als die Methode tabledata.insertAll schreibt die Storage Write API niemals zwei Nachrichten mit demselben Offset in einem Stream, wenn der Client Stream-Offsets beim Anhängen von Datensätzen bereitstellt.
Transaktionen auf Streamebene. Sie können Daten in einen Stream schreiben und die Daten in einer einzigen Transaktion per Commit speichern. Wenn der Commit-Vorgang fehlschlägt, können Sie den Vorgang sicher wiederholen.
Transaktionen über Streams. Mehrere Worker können eigene Streams erstellen, um Daten unabhängig voneinander zu verarbeiten. Wenn alle Worker fertig sind, können Sie alle Streams als Transaktion per Commit übergeben.
Effizientes Protokoll. Die Storage Write API ist effizienter als die alte insertAll-Methode, weil sie gRPC-Streaming statt REST über HTTP verwendet. Die Storage Write API unterstützt auch das binäre Format Protokollzwischenspeicher und das spaltenorientierte Format Apache Arrow, die effizientere Formate als JSON sind. Schreibanfragen sind mit garantierter Reihenfolge asynchron.
Schemaaktualisierungserkennung. Wenn sich das zugrunde liegende Tabellenschema während des Streamings ändert, benachrichtigt die Storage Write API den Client. Der Client kann entscheiden, ob die Verbindung mit dem aktualisierten Schema wiederhergestellt werden soll, oder es kann weiterhin in die vorhandene Verbindung geschrieben werden.
Niedrigere Kosten. Die Storage Write API ist wesentlich günstiger als die ältere insertAll-Streaming-API. Darüber hinaus können Sie bis zu 2 TiB pro Monat kostenlos aufnehmen.
Erforderliche Berechtigungen
Sie benötigen die Berechtigung bigquery.tables.updateData, um die Storage Write API verwenden zu können.
Die folgenden vordefinierten IAM-Rollen (Identity and Access Management) umfassen Berechtigungen des Typs bigquery.tables.updateData:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Vordefinierte Rollen und Berechtigungen.
Authentifizierungsbereiche
Für die Verwendung der Storage Write API ist einer der folgenden OAuth-Bereiche erforderlich:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
Weitere Informationen finden Sie in der Authentifizierungsübersicht.
Übersicht über die Storage Write API
Die Kernabstraktion in der Storage Write API ist ein Stream. Ein Stream schreibt Daten in eine BigQuery-Tabelle. Mehrere Streams können gleichzeitig in dieselbe Tabelle schreiben.
Standardstream
Die Storage Write API bietet einen Standardstream bereit, der für Streamingszenarien entwickelt wurde, in denen Sie kontinuierlich Daten erhalten. Sie hat folgende Merkmale:
- In den Standardstream geschriebene Daten stehen sofort für die Abfrage zur Verfügung.
- Der Standardstream unterstützt die "Mindestens einmal"-Semantik.
- Sie müssen den Standardstream nicht explizit erstellen.
Wenn Sie von der Legacy-tabledata.insertall API migrieren, sollten Sie den Standardstream verwenden. Sie hat eine ähnliche Schreibsemantik mit höherer Datenausfallsicherheit und weniger Skalierungsbeschränkungen.
API-Ablauf:
AppendRows(Schleife)
Weitere Informationen und Beispielcode finden Sie unter Standardstream für die "Mindestens einmal"-Semantik verwenden.
Von der Anwendung erstellte Streams
Sie können einen Stream explizit erstellen, wenn eine der folgenden Verhaltensweisen erforderlich ist:
- "Genau einmal"-Schreibsemantik unter Verwendung von Stream-Offsets.
- Unterstützung für zusätzliche ACID-Attribute.
Im Allgemeinen bieten in Anwendungen erstellte Streams mehr Kontrolle über die Funktionalität, allerdings auf Kosten zusätzlicher Komplexität.
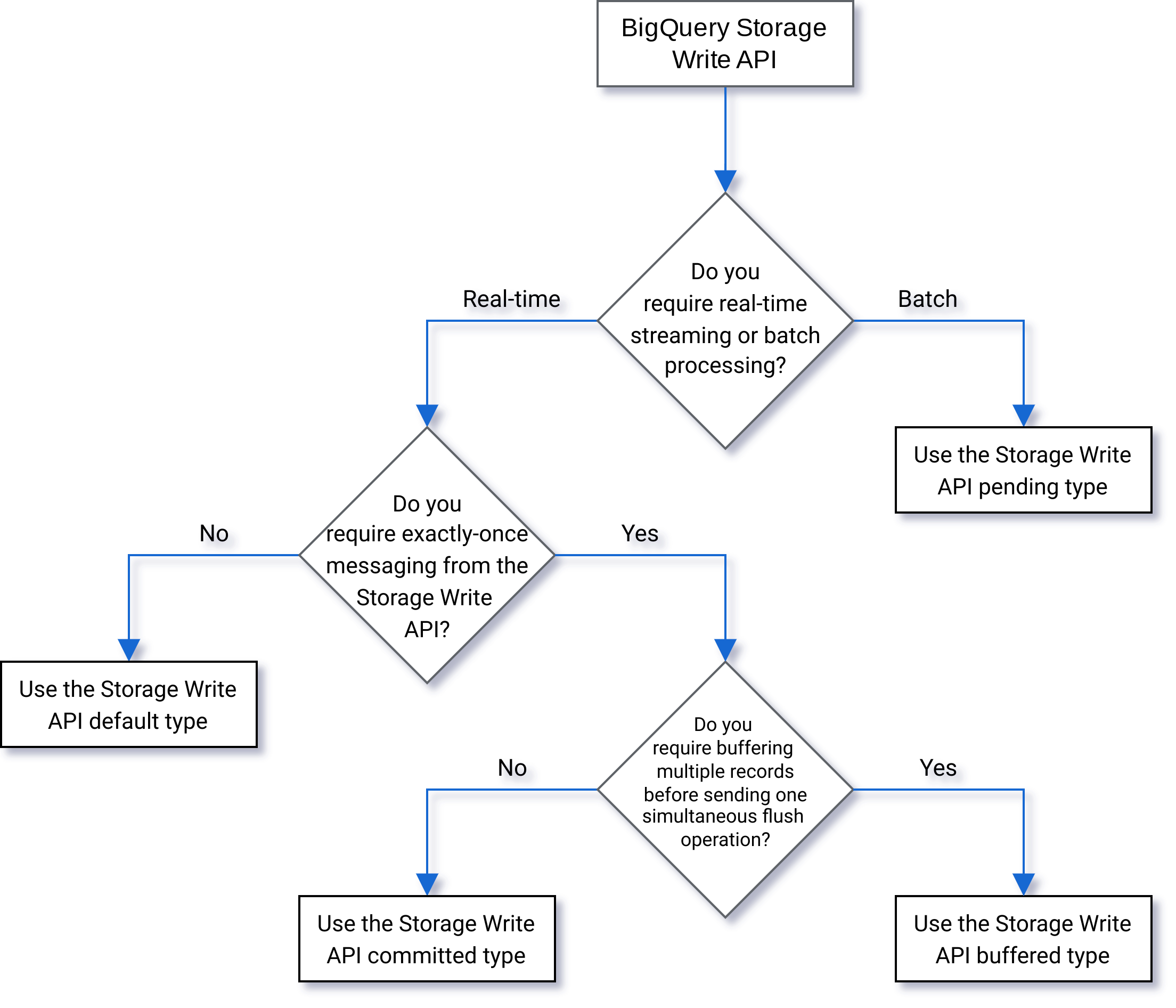
Geben Sie einen Typ an, wenn Sie einen Stream erstellen. Der Typ steuert, wann Daten, die in den Stream geschrieben werden, in BigQuery zum Lesen sichtbar werden.
Typ „Ausstehend“
Beim Typ „Ausstehend“ werden Datensätze im Status „Ausstehend“ zwischengespeichert, bis Sie für den Stream einen Commit ausführen. Wenn Sie einen Stream übergeben, stehen alle ausstehenden Daten zum Lesen zur Verfügung. Die Durchführung eines Commit ist ein atomarer Vorgang. Dieser Typ wird für Batcharbeitslasten als Alternative zu BigQuery-Ladejobs verwendet. Weitere Informationen finden Sie unter Daten mit der Storage Write API im Batch laden.
API-Ablauf:
Commit-Typ
Unter Commit-Typ können Datensätze sofort gelesen werden, während sie in den Stream geschrieben werden. Verwenden Sie diesen Typ für Streaming-Arbeitslasten, die eine minimale Leselatenz benötigen. Der Standardstream verwendet eine Mindestens-einmal-Form des Commit-Typs. Weitere Informationen finden Sie unter Commit-Typ für Genau-einmal-Semantik verwenden.
API-Ablauf:
CreateWriteStreamAppendRows(Schleife)FinalizeWriteStream(optional)
Zwischenspeichertyp
Der Zwischenspeichertyp ist ein erweiterter Typ, der normalerweise nicht verwendet werden sollte, mit dem BigQuery-E/A-Connector für Apache Beam. Verwenden Sie den Commit-Typ und senden Sie jeden Batch in einer Anfrage, wenn Sie kleine Batches haben, die zusammen angezeigt werden sollen. Bei diesem Typ werden Commits auf Zeilenebene bereitgestellt. Datensätze werden zwischengespeichert, bis die Zeilen durch das Leeren des Streams übergeben werden.
API-Ablauf:
CreateWriteStreamAppendRows⇒FlushRows(Schleife)FinalizeWriteStream(optional)
Typ auswählen
Verwenden Sie das folgende Flussdiagramm, um zu entscheiden, welcher Typ für Ihre Arbeitslast am besten geeignet ist:
API-Details
Beachten Sie bei der Verwendung der Storage Write API Folgendes:
AppendRows
Mit der Methode AppendRows werden ein oder mehrere Datensätze an den Stream angehängt. Der erste Aufruf von AppendRows muss einen Streamnamen zusammen mit dem Datenschema enthalten, das als DescriptorProto angegeben ist. Alternativ können Sie im ersten Aufruf von AppendRows ein serialisiertes Arrow-Schema hinzufügen, wenn Sie Daten im Apache Arrow-Format aufnehmen. Als Best Practice senden Sie einen Batch Zeilen in jedem AppendRows-Aufruf. Senden Sie Zeilen nicht einzeln.
Proto-Puffer verarbeiten
Protokollpuffer bieten einen sprachneutralen, plattformneutralen, erweiterbaren Mechanismus für die Serialisierung strukturierter Daten auf vorwärtskompatible und abwärtskompatible Weise. Sie haben den Vorteil, dass sie einen kompakten Datenspeicher mit schnellen und effizienten Parsing ermöglichen. Weitere Informationen zu Protokollpuffern finden Sie unter Protokollpuffer –Übersicht.
Wenn Sie die API direkt mit einer vordefinierten Protokollpuffer-Nachricht verwenden möchten, darf die Protokollpuffer-Nachricht keinen package-Bezeichner verwenden, und alle verschachtelten oder Aufzählungstypen müssen in der Root-Nachricht auf oberster Ebene definiert werden.
Verweise auf externe Nachrichten sind nicht zulässig. Ein Beispiel finden Sie unter sample_data.proto.
Die Java- und Go-Clients unterstützen beliebige Protokollpuffer, da die Clientbibliothek das Protokollzwischenspeicherschema normalisiert.
Apache Arrow-Verarbeitung
Wenn Sie Feedback geben oder Support für dieses Feature anfordern möchten, wenden Sie sich an bq-write-api-feedback@google.com.
Apache Arrow ist ein universelles spaltenorientiertes Format und eine mehrsprachige Toolbox für die Datenverarbeitung. Apache Arrow bietet ein sprachunabhängiges spaltenorientiertes Speicherformat für flache und hierarchische Daten, das für effiziente Analysevorgänge auf moderner Hardware optimiert ist. Weitere Informationen zu Apache Arrow finden Sie unter Apache Arrow.
Die Storage Write API unterstützt die Arrow-Aufnahme mit serialisiertem Arrow-Schema und Daten in der Klasse AppendRowsRequest.
Die Python-Clientbibliothek bietet integrierte Unterstützung für die Aufnahme von Apache Arrow-Daten. Für andere Sprachen ist möglicherweise ein Aufruf der Raw AppendRows API erforderlich, um Daten im Apache Arrow-Format aufzunehmen.
FinalizeWriteStream
Die Methode FinalizeWriteStream finalisiert den Stream, sodass keine neuen Daten an ihn angehängt werden können. Diese Methode ist erforderlich im
Pending-Typ und optional in den
Committed und
Buffered-Typen. Dieser Standardstream unterstützt diese Methode nicht.
Fehlerbehandlung
Wenn ein Fehler auftritt, kann der zurückgegebene google.rpc.Status einen StorageError in die Fehlerdetails aufnehmen. Informationen zum jeweiligen Fehlertyp finden Sie unter StorageErrorCode. Weitere Informationen zum Fehlermodell der Google API finden Sie unter Fehler.
Verbindungen
Die Storage Write API ist eine gRPC API und verwendet bidirektionale Verbindungen. Die Methode AppendRows erstellt eine Verbindung zu einem Stream. Sie können mehrere Verbindungen im Standardstream öffnen. Diese Anfügungen sind asynchron, sodass Sie eine Reihe von Schreibvorgängen gleichzeitig senden können. Antwortnachrichten auf jeder bidirektionalen Verbindung treffen in der gleichen Reihenfolge ein, in der die Anfragen gesendet wurden.
Von Anwendungen erstellte Streams können nur eine einzige aktive Verbindung haben. Als Best Practice gilt: Anzahl der aktiven Verbindungen begrenzen und so viele Verbindungen wie möglich für Datenschreibvorgänge verwenden. Wenn Sie den Standardstream in Java oder Go verwenden, können Sie mit dem Storage Write API-Multiplexverfahren in mehrere Zieltabellen mit gemeinsam verwendeten Verbindungen schreiben.
Im Allgemeinen unterstützt eine einzelne Verbindung einen Durchsatz von mindestens 1 Mbit/s. Die obere Grenze hängt von mehreren Faktoren ab, z. B. von der Netzwerkbandbreite, dem Schema der Daten und der Serverlast. Wenn eine Verbindung das Durchsatzlimit erreicht, können eingehende Anfragen abgelehnt oder in die Warteschlange gestellt werden, bis die Anzahl der Inflight-Anfragen sinkt. Erstellen Sie weitere Verbindungen, wenn Sie einen höheren Durchsatz benötigen.
BigQuery schließt die gRPC-Verbindung, wenn die Verbindung zu lange inaktiv ist. In diesem Fall lautet der Antwortcode HTTP 409. Die gRPC-Verbindung kann auch bei einem Serverneustart oder aus anderen Gründen geschlossen werden. Wenn ein Verbindungsfehler auftritt, erstellen Sie eine neue Verbindung. Die Java- und Go-Clientbibliotheken stellen automatisch wieder eine Verbindung her, wenn die Verbindung beendet wird.
Unterstützung von Clientbibliotheken
Clientbibliotheken für die Storage Write API sind in mehreren Programmiersprachen verfügbar und machen die zugrunde liegenden gRPC-basierten API-Konstrukte verfügbar. Diese API nutzt erweiterte Funktionen wie bidirektionales Streaming, für deren Unterstützung möglicherweise zusätzlicher Entwicklungsaufwand erforderlich ist. Dazu sind für diese API eine Reihe von Abstraktionen auf höherer Ebene verfügbar, die diese Interaktionen vereinfachen und die Bedenken der Entwickler verringern. Wir empfehlen, diese anderen Bibliotheksabstraktionen nach Möglichkeit zu nutzen.
In diesem Abschnitt finden Sie zusätzliche Informationen zu Sprachen und Bibliotheken, in denen Entwicklern zusätzliche Funktionen über die generierte API hinaus zur Verfügung gestellt wurden.
Codebeispiele zur Storage Write API finden Sie unter Alle BigQuery-Codebeispiele.
Java-Client
Die Java-Clientbibliothek stellt zwei Writer-Objekte bereit:
StreamWriter: Akzeptiert Daten im Protokollzwischenspeicherformat.JsonStreamWriter: Akzeptiert Daten im JSON-Format und konvertiert sie in Protokollzwischenspeicher, bevor sie übertragen werden. DerJsonStreamWriterunterstützt auch automatische Schemaaktualisierungen. Wenn sich das Tabellenschema ändert, stellt der Autor automatisch eine neue Verbindung zum neuen Schema her, sodass der Client Daten mit dem neuen Schema senden kann.
Das Programmiermodell für beide Writer ähnlich. Der Hauptunterschied besteht darin, wie Sie die Nutzlast formatieren.
Das Writer-Objekt verwaltet eine Storage Write API-Verbindung. Das Writer-Objekt bereinigt Anfragen automatisch, fügt den Anfragen die regionalen Routing-Header hinzu und stellt die Verbindung nach einem Verbindungsfehler wieder her. Wenn Sie die gRPC API direkt verwenden, müssen Sie diese Details berücksichtigen.
Go-Client
Der Go-Client verwendet eine Client-Server-Architektur, um Nachrichten mit Proto2 im Protokollzwischenspeicherformat zu codieren. Weitere Informationen zur Verwendung des Go-Clients, einschließlich Beispielcode, finden Sie in der Go-Dokumentation.
Python-Client
Der Python-Client ist ein untergeordneter Client, der die gRPC API umschließt. Um diesen Client zu verwenden, müssen Sie die Daten als Protokollzwischenspeicher senden und dem API-Ablauf für den angegebenen Typ folgen.
Vermeiden Sie die Verwendung der dynamischen Proto-Nachrichtengenerierung in Python, da die Leistung dieser Bibliothek unterdurchschnittlich ist.
Weitere Informationen zur Verwendung von Protokollzwischenspeichern mit Python finden Sie in der Anleitung zu Protokollzwischenspeichern in Python.
Sie können das Apache Arrow-Aufnahmeformat auch als alternatives Protokoll verwenden, um Daten mit der Storage Write API aufzunehmen. Weitere Informationen finden Sie unter Daten im Apache Arrow-Format aufnehmen.
Node.js-Client
Die NodeJS-Clientbibliothek akzeptiert JSON-Eingaben und unterstützt das automatische Herstellen einer neuen Verbindung. Weitere Informationen zur Verwendung des Clients finden Sie in der Dokumentation.
Nichtverfügbarkeit verarbeiten
Wiederholungsversuche mit exponentiellem Backoff können zufällige Fehler und kurze Zeiträume der Nichtverfügbarkeit von Diensten minimieren, aber um zu vermeiden, dass Zeilen bei längerer Nichtverfügbarkeit gelöscht werden, müssen Sie sorgfältiger vorgehen. Was soll insbesondere geschehen, wenn ein Client eine Zeile dauerhaft nicht einfügen kann?
Die Antwort hängt von Ihren Anforderungen ab. Wenn BigQuery beispielsweise für operative Analysen verwendet wird, bei denen einige fehlende Zeilen akzeptabel sind, kann der Client nach einigen Wiederholungsversuchen aufgeben und die Daten verwerfen. Wenn stattdessen jede Zeile für das Unternehmen von entscheidender Bedeutung ist, z. B. für Finanzdaten, müssen Sie eine Strategie zur nichtflüchtigen Speicherung der Daten entwickeln, bis diese später eingefügt werden können.
Eine gängige Methode zur Behebung persistenter Fehler besteht darin, die Zeilen zur späteren Auswertung und möglichen Einfügung in einem Pub/Sub-Thema zu veröffentlichen. Eine weitere gängige Methode besteht darin, die Daten auf dem Client vorübergehend zu speichern. Mit beiden Methoden können Sie die Blockierung von Clients gleichzeitig aufheben und gleichzeitig alle Zeilen einfügen, sobald die Verfügbarkeit wiederhergestellt ist.
In partitionierte Tabellen streamen
Die Storage Write API unterstützt das Streamen von Daten in partitionierte Tabellen.
Wenn die Daten gestreamt werden, werden sie anfangs in der Partition __UNPARTITIONED__ abgelegt. Sobald genügend nicht partitionierte Daten erfasst wurden, partitioniert BigQuery die Daten neu und platziert sie in der entsprechenden Partition.
Es gibt jedoch kein Service Level Agreement (SLA), das definiert, wie lange es dauern kann, bis diese Daten aus der Partition __UNPARTITIONED__ verschoben werden.
Bei nach Aufnahmezeit partitionierten und nach Zeiteinheit partitionierten Tabellen können nicht partitionierte Daten aus einer Abfrage ausgeschlossen werden. Dazu werden die NULL-Werte aus der Partition __UNPARTITIONED__ mit einer der Pseudospalten (_PARTITIONTIME oder _PARTITIONDATE, je nach bevorzugtem Datentyp) herausgefiltert.
Partitionierung nach Aufnahmezeit
Wenn Sie in eine nach Aufnahmezeit partitionierte Tabelle streamen, leitet die Storage Write API die Zielpartition aus der aktuellen UTC-Systemzeit ab.
Wenn Sie Daten in eine täglich partitionierte Tabelle streamen, können Sie die Datumsinferenz überschreiben. Geben Sie dazu einen Partition-Decorator als Teil der Anfrage an.
Füge den Decorator in den Parameter tableID ein. Beispielsweise können Sie mit dem table1$20250601-Partitions-Decorator in die Partition für den 1. Juni 2025 der Tabelle table1 streamen.
Wenn Sie mit einem Partitions-Decorator streamen, können Sie in Partitionen mit einem Datum innerhalb der letzten 31 Tage in der Vergangenheit bzw. 16 Tage in der Zukunft streamen. Wenn Sie in Partitionen mit Datumsangaben schreiben möchten, die außerhalb der zulässigen Grenzen liegen, verwenden Sie stattdessen einen Lade- oder Abfragejob, wie unter Daten in eine bestimmte Partition schreiben beschrieben.
Das Streaming mit einem Partitions-Decorator wird nur für täglich partitionierte Tabellen mit Standardstreams unterstützt, nicht für stündlich, monatlich oder jährlich partitionierte Tabellen oder von Anwendungen erstellte Streams.
Spaltenpartitionierung nach Zeiteinheit
Wenn Sie Daten in eine nach Zeiteinheit partitionierte Tabelle streamen, fügt BigQuery die Daten anhand der Werte der vordefinierten DATE-, DATETIME- oder TIMESTAMP-Partitionierungsspalte der Tabelle automatisch in die richtige Partition ein. Sie können Daten in eine nach Zeiteinheit und Spalte partitionierte Tabelle streamen, wenn die Daten, auf die in der Partitionierungsspalte verwiesen wird, zwischen 10 Jahren in der Vergangenheit und einem Jahr in der Zukunft liegen.
Partitionierung nach Ganzzahlbereich
Wenn Sie Daten in eine nach Ganzzahlbereich partitionierte Tabelle streamen, werden sie von BigQuery automatisch in die richtige Partition eingefügt. Die Zuordnung erfolgt anhand der Werte in der vordefinierten INTEGER-Partitionierungsspalte der Tabelle.
Fluent Bit-Ausgabe-Plug-in für die Storage Write API
Das Fluent Bit Storage Write API-Ausgabe-Plug-in automatisiert die Aufnahme von JSON-Einträgen in BigQuery, sodass Sie keinen Code schreiben müssen. Mit diesem Plug-in müssen Sie nur ein kompatibles Eingabe-Plug-in konfigurieren und eine Konfigurationsdatei einrichten, um mit dem Streamen von Daten zu beginnen. Fluent Bit ist ein Open-Source- und plattformübergreifender Log-Prozessor und -Forwarder, der mithilfe von Eingabe- und Ausgabe-Plug-ins verschiedene Arten von Datenquellen und -senken verarbeitet.
Dieses Plug-in unterstützt Folgendes:
- „Mindestens einmal“-Semantik mit dem Standardtyp.
- „Genau einmal“-Semantik mit dem Commit-Typ
- Dynamische Skalierung für Standardstreams, wenn ein Backpressure angezeigt wird.
Storage Write API-Projektmesswerte
Wenn Sie Messwerte zur Überwachung der Datenaufnahme mit der Storage Write API verwenden möchten, rufen Sie die INFORMATION_SCHEMA.WRITE_API_TIMELINE-Ansicht auf oder sehen Sie sich die Google Cloud -Messwerte an.
Datenbearbeitungssprache (Data Manipulation Language, DML) mit kürzlich gestreamten Daten verwenden
Mit der Datenbearbeitungssprache (DML), etwa mit den Anweisungen UPDATE, DELETE oder MERGE, können Sie Zeilen ändern, die kürzlich von der BigQuery Storage Write API in eine BigQuery-Tabelle geschrieben wurden. Die kürzlichen Schreibvorgänge sind jene, die innerhalb der letzten 30 Minuten ausgeführt wurden.
Weitere Informationen für die Verwendung von DML zum Ändern Ihrer gestreamten Daten finden Sie unter Datenbearbeitungssprache verwenden.
Beschränkungen
- Die Unterstützung für die Ausführung von DML-Anweisungen mit Mutationen für kürzlich gestreamte Daten gilt nicht für Daten, die mit der insertAll streaming API gestreamt wurden.
- Das Ausführen von DML-Anweisungen mit Mutationen in einer Transaktion mit mehreren Anweisungen für kürzlich gestreamte Daten wird nicht unterstützt.
Kontingente für Storage Write API
Informationen zu Kontingenten und Limits für die Storage Write API finden Sie unter Kontingente und Limits für die BigQuery Storage Write API.
Sie können Ihre gleichzeitigen Verbindungen und die Nutzung des Durchsatzkontingents auf der Seite „Kontingente“ derGoogle Cloud -Konsole prüfen.
Durchsatz berechnen
Angenommen, Sie möchten Logs von 100 Millionen Endpunkten erfassen und dabei Logdatensätze pro Minute erstellen. Anschließend können Sie den Durchsatz über 100 million * 1,500 / 60 seconds = 2.5 GB per second schätzen.
Sie müssen im Voraus sicherstellen, dass Sie ein ausreichendes Kontingent haben, um diesen Durchsatz bereitzustellen.
Storage Write API – Preise
Preisinformationen finden Sie unter Preise für die Datenaufnahme.
Anwendungsbeispiel
Angenommen, eine Pipeline verarbeitet Ereignisdaten aus Endpunktlogs. Ereignisse werden kontinuierlich generiert und müssen so schnell wie möglich für Abfragen in BigQuery verfügbar sein. Da die Datenaktualität für diesen Anwendungsfall von größter Bedeutung ist, ist die Storage Write API die beste Wahl, um Daten in BigQuery aufzunehmen. Eine empfohlene Architektur, um diese schlanken Endpunkte zu halten, sendet Ereignisse an Pub/Sub, von dem sie von einer Streaming-Dataflow-Pipeline verarbeitet werden, die direkt an BigQuery streamt.
Ein wichtiger Aspekt der Zuverlässigkeit dieser Architektur ist die Handhabung des Fehlschlagens des Einfügens eines Datensatzes in BigQuery. Wenn jeder Datensatz wichtig ist und nicht verloren gehen kann, müssen die Daten vor dem Einfügen zwischengespeichert werden. In der oben empfohlenen Architektur kann Pub/Sub die Rolle eines Zwischenspeichers mit seinen Funktionen zur Nachrichtenaufbewahrung spielen. Die Dataflow-Pipeline sollte so konfiguriert sein, dass BigQuery-Streaming-Insert-Anweisungen mit abgeschnittenem exponentiellem Backoff wiederholt werden. Sobald die Kapazität von Pub/Sub als Zwischenspeicher erschöpft ist, z. B. bei längerer Nichtverfügbarkeit von BigQuery oder einem Netzwerkfehler, müssen die Daten auf dem Client beibehalten werden und der Client benötigt einen Mechanismus zum Fortsetzen des Einfügens beibehaltener Datensätze, sobald die Verfügbarkeit wiederhergestellt ist. Weitere Informationen zum Umgang mit dieser Situation finden Sie im Blogpost Google Pub/Sub Reliability Guide.
Ein weiterer Fehlerfall ist die Verwendung eines Poisoning-Datensatzes. Ein Cache-Eintrag ist entweder ein Eintrag, der von BigQuery abgelehnt wurde, weil der Eintrag nicht mit einem nicht wiederholbaren Fehler eingefügt werden kann oder ein Eintrag, der nach der maximalen Anzahl von Wiederholungsversuchen nicht eingefügt wurde. Beide Datensatztypen sollten von der Dataflow-Pipeline zur weiteren Untersuchung in einer Warteschlange für unzustellbare Nachrichten gespeichert werden.
Wenn eine Genau-einmal-Semantik erforderlich ist, erstellen Sie einen Schreibstream im Commit-Typ mit vom Client bereitgestellten Datensatz-Offsets. Dadurch werden Duplikate vermieden, da der Schreibvorgang nur dann erfolgt, wenn der Versatzwert mit dem nächsten Anfüge-Offset übereinstimmt. Wenn kein Offset angegeben wird, werden Datensätze an das aktuelle Ende des Streams angehängt. Dies kann dazu führen, dass der Datensatz mehrmals im Stream angezeigt wird.
Wenn keine einmaligen Garantien erforderlich sind, ermöglicht das Schreiben in den Standardstream einen höheren Durchsatz und wird auch nicht auf das Kontingentlimit für die Erstellung von Schreibstreams angerechnet.
Schätzen Sie den Durchsatz Ihres Netzwerks ab und prüfen Sie vorab, ob Sie ein ausreichendes Kontingent für die Bereitstellung des Durchsatzes haben.
Werden Ihre Arbeitslast Daten mit einer sehr ungleichmäßigen Rate generiert oder verarbeitet, versuchen Sie, alle Lastspitzen auf dem Client auszugleichen und mit einem konstanten Durchsatz in BigQuery zu streamen. Dies kann die Kapazitätsplanung vereinfachen. Wenn dies nicht möglich ist, müssen Sie auf die Behandlung von 429-Fehlern (Ressource erschöpft) vorbereitet sein, falls Ihr Durchsatz bei kurzen Spitzen das Kontingent überschreitet.
Ein detailliertes Beispiel für die Verwendung der Storage Write API finden Sie unter Daten mit der Storage Write API streamen.
Nächste Schritte
- Daten mit der Storage Write API streamen
- Daten im Batch mit der Storage Write API laden
- Unterstützte Protokollzwischenspeicher- und Arrow-Datentypen
- Best Practices für die Storage Write API