라벨 보기
이 페이지에서는 BigQuery 리소스의 라벨을 보는 방법을 설명합니다.
다음 방법으로 라벨을 볼 수 있습니다.
- Google Cloud 콘솔 사용
INFORMATION_SCHEMA뷰 쿼리- bq 명령줄 도구의
bq show명령어 사용 datasets.get또는tables.getAPI 메서드 호출하기- 클라이언트 라이브러리 사용
뷰는 테이블 리소스와 같이 취급되므로 tables.get 메서드를 사용하여 뷰와 테이블의 라벨 정보를 모두 가져올 수 있습니다.
시작하기 전에
사용자에게 이 문서의 각 작업을 수행하는 데 필요한 권한을 부여하는 Identity and Access Management(IAM) 역할을 부여합니다.
필수 권한
라벨을 보기 위해 필요한 권한은 액세스할 수 있는 리소스 유형에 따라 다릅니다. 이 문서의 태스크를 수행하려면 다음 권한이 필요합니다.
데이터 세트 세부정보를 볼 수 있는 권한
데이터 세트 세부정보를 보려면 bigquery.datasets.get IAM 권한이 필요합니다.
다음과 같은 사전 정의된 각 IAM 역할에는 데이터 세트 세부정보를 확인하는 데 필요한 권한이 포함되어 있습니다.
roles/bigquery.userroles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
또한 bigquery.datasets.create 권한이 있으면 생성한 데이터 세트의 세부정보를 볼 수 있습니다.
BigQuery의 IAM 역할과 권한에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
테이블을 보거나 세부정보를 볼 수 있는 권한
테이블 세부정보나 뷰 세부정보를 보려면 bigquery.tables.get IAM 권한이 필요합니다.
사전 정의된 모든 IAM 역할에는 roles/bigquery.user 또는 roles/bigquery.jobUser를 제외하고 테이블 또는 세부정보를 보는 데 필요한 권한이 포함되어 있습니다.
또한 bigquery.datasets.create 권한이 있으면 만드는 데이터 세트에서 테이블 및 뷰의 세부정보를 삭제할 수 있습니다.
BigQuery의 IAM 역할과 권한에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
작업 세부정보를 볼 수 있는 권한
작업 세부정보를 보려면 bigquery.jobs.get IAM 권한이 필요합니다.
다음과 같은 사전 정의된 각 IAM 역할에는 작업 세부정보를 확인하는 데 필요한 권한이 포함되어 있습니다.
roles/bigquery.admin(프로젝트의 모든 작업 세부정보를 볼 수 있음)roles/bigquery.user(작업 세부정보를 볼 수 있음)roles/bigquery.jobUser(작업 세부정보를 볼 수 있음)
BigQuery의 IAM 역할과 권한에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
데이터 세트, 테이블, 뷰 라벨 보기
리소스의 라벨을 보려면 다음 옵션 중 하나를 선택합니다.
콘솔
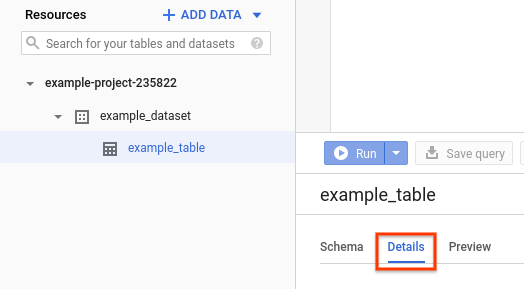
데이터세트의 경우 데이터세트 세부정보 페이지가 자동으로 열립니다. 테이블 및 뷰의 경우 세부정보를 클릭하여 세부정보 페이지를 엽니다. 리소스 정보 테이블에 라벨 정보가 표시됩니다.
SQL
INFORMATION_SCHEMA.SCHEMATA_OPTIONS 뷰를 쿼리하여 데이터 세트의 라벨을 확인하거나 INFORMATION_SCHEMA.TABLE_OPTIONS 뷰를 쿼리하여 테이블의 라벨을 확인합니다. 예를 들어 다음 SQL 쿼리는 mydataset라는 데이터 세트의 라벨을 반환합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
SELECT * FROM INFORMATION_SCHEMA.SCHEMATA_OPTIONS WHERE schema_name = 'mydataset' AND option_name = 'labels';
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
bq
bq show 명령어를 리소스 ID와 함께 사용합니다. --format 플래그를 사용하면 출력을 제어할 수 있습니다. 리소스가 기본 프로젝트 이외의 프로젝트에 있으면 [PROJECT_ID]:[DATASET] 형식으로 프로젝트 ID를 추가합니다. 가독성을 위해 --format 플래그를 pretty로 설정하여 출력을 제어합니다.
bq show --format=pretty [RESOURCE_ID]
여기서 [RESOURCE_ID]는 유효한 데이터 세트, 테이블, 뷰 또는 작업 ID입니다.
예를 들면 다음과 같습니다.
다음 명령어를 입력하여 기본 프로젝트에 있는 mydataset의 라벨을 표시합니다.
bq show --format=pretty mydataset
출력은 다음과 같이 표시됩니다
+-----------------+--------------------------------------------------------+---------------------+ | Last modified | ACLs | Labels | +-----------------+--------------------------------------------------------+---------------------+ | 11 Jul 19:34:34 | Owners: | department:shipping | | | projectOwners, | | | | Writers: | | | | projectWriters | | | | Readers: | | | | projectReaders | | +-----------------+--------------------------------------------------------+---------------------+
다음 명령어를 입력하여 mydataset.mytable의 라벨을 표시합니다.
mydataset는 기본 프로젝트가 아닌 myotherproject에 있습니다.
bq show --format=pretty myotherproject:mydataset.mytable
클러스터형 테이블 출력은 다음과 같습니다.
+-----------------+------------------------------+------------+-------------+-----------------+------------------------------------------------+------------------+---------+ | Last modified | Schema | Total Rows | Total Bytes | Expiration | Time Partitioning | Clustered Fields | Labels | +-----------------+------------------------------+------------+-------------+-----------------+------------------------------------------------+------------------+---------+ | 25 Jun 19:28:14 | |- timestamp: timestamp | 0 | 0 | 25 Jul 19:28:14 | DAY (field: timestamp, expirationMs: 86400000) | customer_id | org:dev | | | |- customer_id: string | | | | | | | | | |- transaction_amount: float | | | | | | | +-----------------+------------------------------+------------+-------------+-----------------+------------------------------------------------+------------------+---------+
API
datasets.get 메서드 또는 tables.get 메서드를 호출합니다. 응답에는 리소스와 연결된 모든 라벨이 포함됩니다.
또는 datasets.list를 사용하여 여러 데이터 세트의 라벨을 보거나 tables.list를 사용하여 여러 테이블과 뷰의 라벨을 볼 수 있습니다.
뷰는 테이블 리소스와 같이 취급되므로 tables.get 메서드와 tables.list 메서드를 사용하여 뷰와 테이블의 라벨 정보를 볼 수 있습니다.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Java
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
테이블 라벨 보기
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Java
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
작업 라벨 보기
작업 라벨을 확인하려면 다음 옵션 중 하나를 선택합니다.
SQL
INFORMATION_SCHEMA.JOB_BY_* 뷰를 쿼리하여 작업 라벨을 확인합니다. 예를 들어 다음 SQL 쿼리는 현재 프로젝트에서 현재 사용자가 제출하는 작업에 대한 쿼리 텍스트 및 라벨을 반환합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
SELECT query, labels FROM INFORMATION_SCHEMA.JOBS_BY_USER;
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
bq
bq 명령줄 도구를 사용하여 쿼리 작업의 라벨을 확인하려면 bq show -j 명령어를 쿼리 작업의 작업 ID와 함께 입력합니다. --format 플래그를 사용하면 출력을 제어할 수 있습니다. 예를 들어 쿼리 작업의 작업 ID가 bqjob_r1234d57f78901_000023746d4q12_1이면 다음 명령어를 입력합니다.
bq show -j --format=pretty bqjob_r1234d57f78901_000023746d4q12_1
출력은 다음과 같이 표시됩니다.
+----------+---------+-----------------+----------+-------------------+-----------------+--------------+----------------------+ | Job Type | State | Start Time | Duration | User Email | Bytes Processed | Bytes Billed | Labels | +----------+---------+-----------------+----------+-------------------+-----------------+--------------+----------------------+ | query | SUCCESS | 03 Dec 15:00:41 | 0:00:00 | email@example.com | 255 | 10485760 | department:shipping | | | | | | | | | costcenter:logistics | +----------+---------+-----------------+----------+-------------------+-----------------+--------------+----------------------+
API
jobs.get 메서드를 호출합니다. 응답에는 리소스와 연결된 모든 라벨이 포함됩니다.
예약 라벨 보기
예약 라벨을 확인하려면 다음 옵션 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색 메뉴에서 용량 관리를 클릭합니다.
슬롯 예약 탭을 클릭합니다.
각 예약의 라벨은 라벨 열에 나열됩니다.
SQL
INFORMATION_SCHEMA.RESERVATIONS 뷰를 쿼리하여 예약 라벨을 확인합니다. 예를 들어 다음 SQL 쿼리는 예약 이름과 라벨을 반환합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
SELECT reservation_name, labels FROM INFORMATION_SCHEMA.RESERVATIONS WHERE reservation_name = RESERVATION_NAME;
다음을 바꿉니다.
RESERVATION_NAME: 예약 이름.
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
bq
bq show 명령어를 사용하여 예약 라벨을 확인합니다.
bq show --format=prettyjson --reservation=true --location=LOCATION RESERVATION_NAME
다음을 바꿉니다.
LOCATION: 예약 위치RESERVATION_NAME: 예약 이름.
결과는 다음과 유사합니다.
{
"autoscale": {
"maxSlots": "100"
},
"creationTime": "2023-10-26T15:16:28.196940Z",
"edition": "ENTERPRISE",
"labels": {
"department": "shipping"
},
"name": "projects/myproject/locations/US/reservations/myreservation",
"updateTime": "2025-06-05T19:37:28.125914Z"
}
다음 단계
- BigQuery 리소스에 라벨 추가 방법 알아보기
- BigQuery 리소스의 라벨 업데이트 방법 알아보기
- 라벨을 사용한 리소스 필터링 방법 알아보기
- BigQuery 리소스의 라벨 삭제 방법 알아보기
- Resource Manager 문서의 라벨 사용 읽어보기