BigQuery サンドボックスを有効にする
BigQuery サンドボックスでは、制限付きの BigQuery の機能を料金なしで試すことができるため、お客様のニーズに適合するかどうかを確認できます。BigQuery サンドボックスでは、クレジット カード情報の登録、請求先アカウントの作成を行うことなく、BigQuery を体験できます。請求先アカウントがすでに作成されている場合でも、無料枠で BigQuery を料金なしで使用できます。
BigQuery サンドボックスの使用を開始する
Google Cloud コンソールで、[BigQuery] ページに移動します。
ブラウザで次の URL を入力して、 Google Cloud コンソールで BigQuery を開くこともできます。
https://console.cloud.google.com/bigquery
Google Cloud コンソールは、BigQuery リソースの作成と管理、SQL クエリの実行に使用できるグラフィカル インターフェースです。
Google アカウントで認証するか、新しいアカウントを作成します。
[ようこそ] ページで、次の操作を行います。
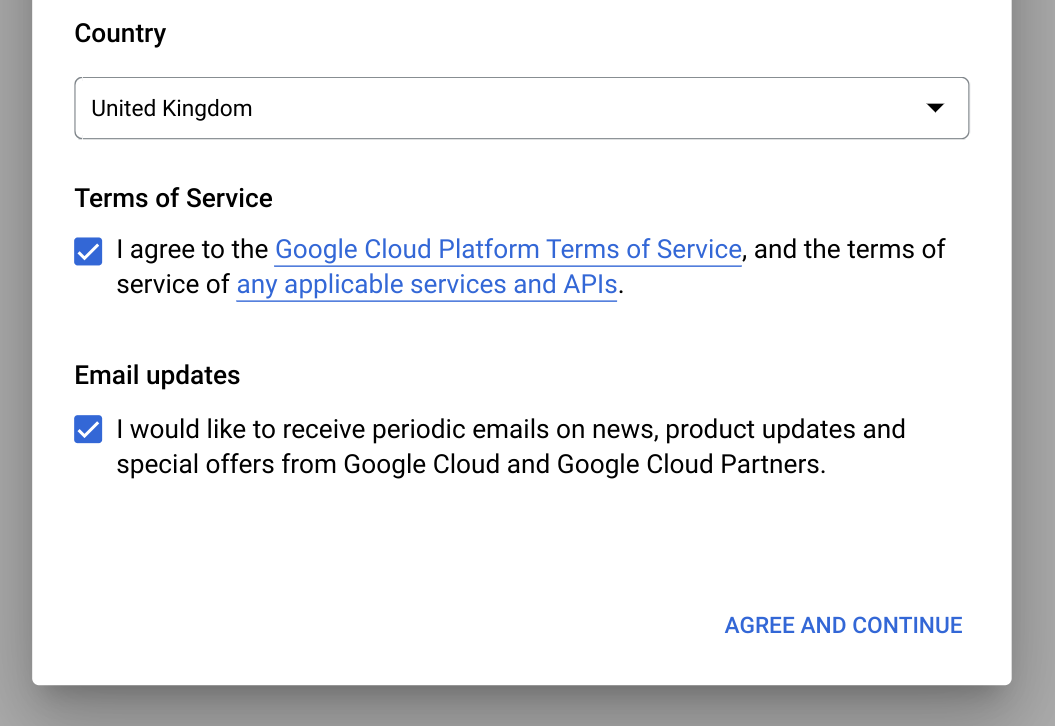
[国] で国を選択します。
[利用規約] で、利用規約に同意する場合はチェックボックスをオンにします。
省略可: 最新情報に関する通知メールについて尋ねられたら、最新情報に関する通知メールで受け取る場合はチェックボックスをオンにします。
[同意して続行] をクリックします。
[プロジェクトの作成] をクリックします。
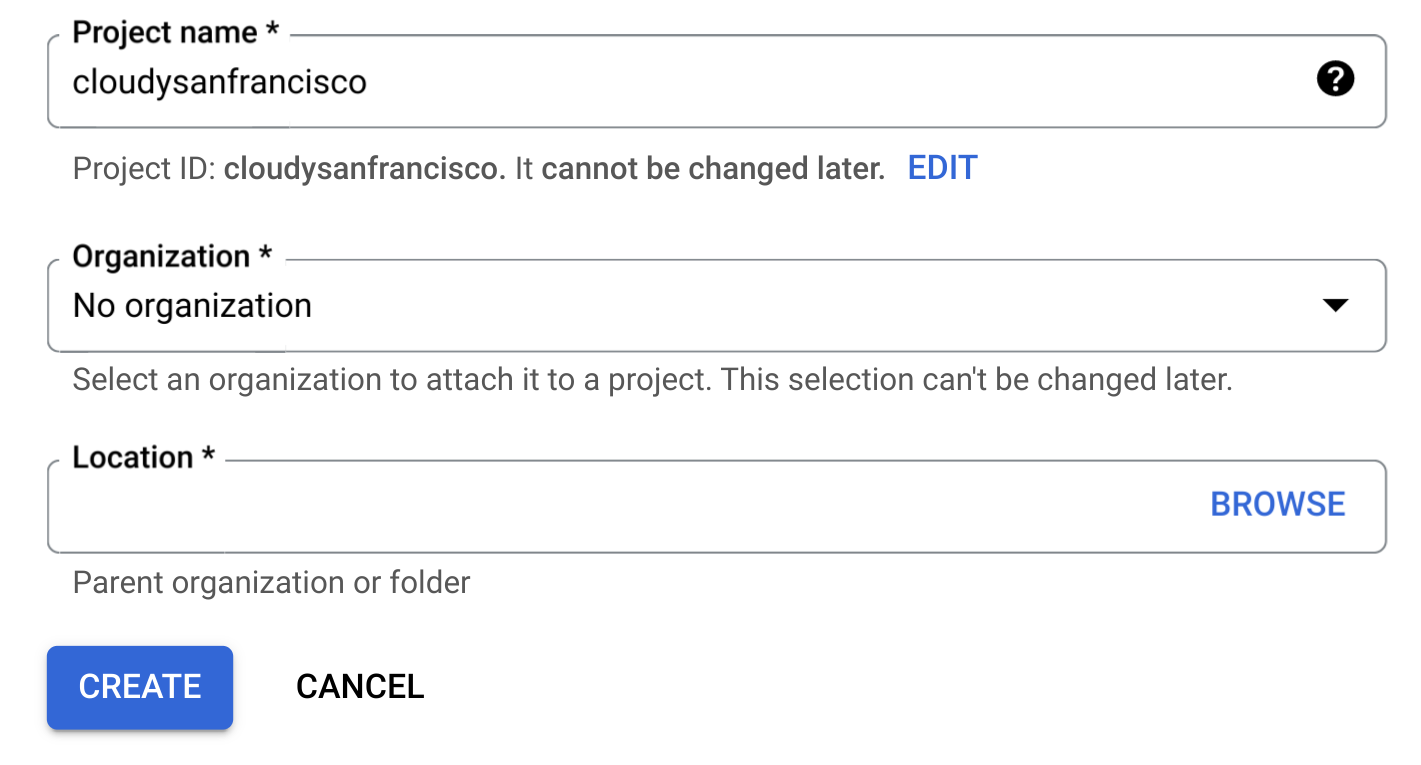
[新しいプロジェクト] ページで、次の操作を行います。
[プロジェクト名] にプロジェクトの名前を入力します。
[組織] で組織を選択します。組織に属していない場合は、[組織なし] を選択します。 管理対象アカウント(学術機関に関連付けられたアカウントなど)では、組織を選択する必要があります。
ロケーションを選択するように求められたら、[参照] をクリックしてプロジェクトのロケーションを選択します。
[作成] をクリックします。 Google Cloud コンソールの [BigQuery] ページにリダイレクトされます。
BigQuery サンドボックスが有効になりました。これで、[BigQuery] ページに BigQuery サンドボックスに関する通知が表示されます。

BigQuery サンドボックスを有効にしたので、次に Google Cloud コンソールで一般公開データセットにクエリを実行するクイックスタートを試してみることをおすすめします。同様の bq コマンドライン ツール用のクイックスタートを試すこともできます。これは多くの管理タスクで役立ちます。また、同様のクライアント ライブラリ用のクイックスタートでは、Java や Python などのプログラミング言語で BigQuery を使用できます。
BigQuery サンドボックスからアップグレードする
BigQuery サンドボックスを使用すると、一部の BigQuery 機能を費用なしで利用して、BigQuery を試すことができます。ストレージとクエリの機能を増やす準備が整ったら、BigQuery サンドボックスからアップグレードします。
アップグレードする手順は次のとおりです。
プロジェクトに対する課金を有効にします。
BigQuery の各エディションを確認して、最適な料金モデルを決定します。
BigQuery サンドボックスからアップグレードしたら、テーブル、ビュー、パーティションなどの BigQuery リソースのデフォルトの有効期限を更新する必要があります。
制限事項
BigQuery サンドボックスには次の制限があります。
- すべての BigQuery の割り当てと上限が適用されます。
- BigQuery の無料枠と同じ無料使用量の上限(毎月 10 GB のアクティブ ストレージと 1 TB のクエリデータ処理)が設定されます。
- すべての BigQuery データセットにはデフォルトのテーブルの有効期限があり、すべてのテーブル、ビュー、パーティションは 60 日後に自動的に有効期限が切れます。
BigQuery サンドボックスは、次のような一部の BigQuery 機能をサポートしていません。
次のステップ
- Google Cloud コンソールを使用して一般公開データセットに対してクエリを実行する方法を確認する。
- bq ツールを使用して一般公開データセットにクエリを実行する方法を確認する。
- クライアント ライブラリを使用して一般公開データセットに対してクエリを実行する方法を確認する。
- 無料枠で BigQuery を費用なしで使用する方法については、無料枠をご覧ください。
- BigQuery のリリースに関する最新情報を確認する。
- Firebase をご利用の場合は、BigQuery を Firebase にリンクするをご覧ください。