Ce tutoriel vous explique comment utiliser un modèle de k-moyennes dans BigQuery ML pour identifier des clusters dans un ensemble de données.
L'algorithme k-moyennes qui regroupe vos données en clusters est une forme de machine learning non supervisé. Contrairement au machine learning supervisé, qui permet d'effectuer des analyses prédictives, le machine learning non supervisé permet d'obtenir des analyses descriptives. Le machine learning non supervisé peut vous aider à comprendre vos données afin de prendre des décisions basées sur les données.
Les requêtes de ce tutoriel utilisent les fonctions de géographie disponibles dans l'analyse géospatiale. Pour en savoir plus, consultez Présentation des analyses géospatiales.
Ce tutoriel utilise l'ensemble de données public "London Bicycle Hires". Les données comprennent l'heure de début et de fin de la location, le nom des stations de retrait et la durée de l'emprunt.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle k-means :
Dans la console Google Cloud , accédez à la page "BigQuery".
Dans le panneau de gauche, cliquez sur Explorer :

Si le volet de gauche n'apparaît pas, cliquez sur Développer le volet de gauche pour l'ouvrir.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.

Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez UE (plusieurs régions dans l'Union européenne).
L'ensemble de données public "London Bicycle Hires" est stocké dans l'emplacement multirégional
EU. Votre ensemble de données doit être stocké dans le même emplacement.Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.

Examiner les données d'entraînement
Examinez les données que vous utiliserez pour entraîner votre modèle de k-moyennes. Dans ce tutoriel, vous allez regrouper les stations de vélos en fonction des attributs suivants :
- Durée de la location
- Nombre de trajets par jour
- Distance du centre-ville
SQL
Cette requête extrait les données spécifiques à la location de vélos, y compris les colonnes start_station_name et duration, puis les fusionne avec les informations de la station. Cela inclut la création d'une colonne calculée contenant la distance entre la station et le centre-ville. Elle calcule ensuite les attributs de la station dans une colonne stationstats, y compris la durée moyenne des trajets et le nombre de trajets, ainsi que la colonne distance_from_city_center calculée.
Pour examiner les données d'entraînement, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
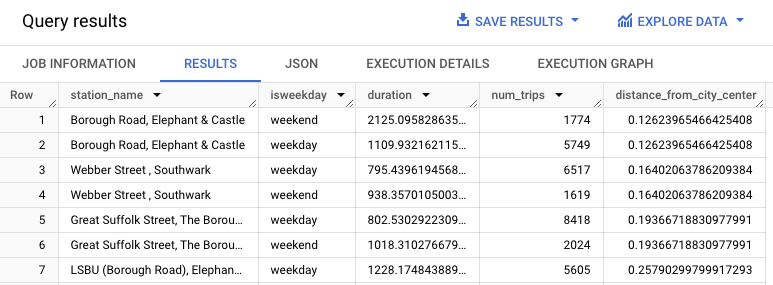
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
Le résultat doit ressembler à ce qui suit :
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Créer un modèle de k-moyennes
Créez un modèle de k-moyennes à l'aide des données d'entraînement "London Bicycle Hires".
SQL
Dans la requête suivante, l'instruction CREATE MODEL spécifie le nombre de clusters à utiliser, soit quatre. Dans l'instruction SELECT, la clause EXCEPT exclut la colonne station_name, car elle ne contient pas de caractéristique. La requête crée une ligne unique par station_name, et seules les caractéristiques sont mentionnées dans l'instruction SELECT.
Pour créer un modèle de k-moyennes :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Interpréter les clusters de données
Les informations de l'onglet Évaluation des modèles peuvent vous aider à interpréter les clusters produits par le modèle.
Pour afficher les informations d'évaluation du modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le panneau de gauche, cliquez sur Explorer :
Dans le volet Explorateur, développez votre projet et cliquez sur Ensembles de données.
Cliquez sur l'ensemble de données
bqml_tutorial, puis accédez à l'onglet Modèles.Sélectionnez le modèle
london_station_clusters.Sélectionnez l'onglet Évaluation. Cet onglet affiche les visualisations des clusters identifiés par le modèle de k-moyennes. Dans la section Caractéristiques numériques, des graphiques à barres affichent les valeurs de caractéristiques numériques les plus importantes pour chaque centroïde. Chaque centroïde représente un cluster de données donné. Le menu déroulant permet de sélectionner les caractéristiques à afficher.
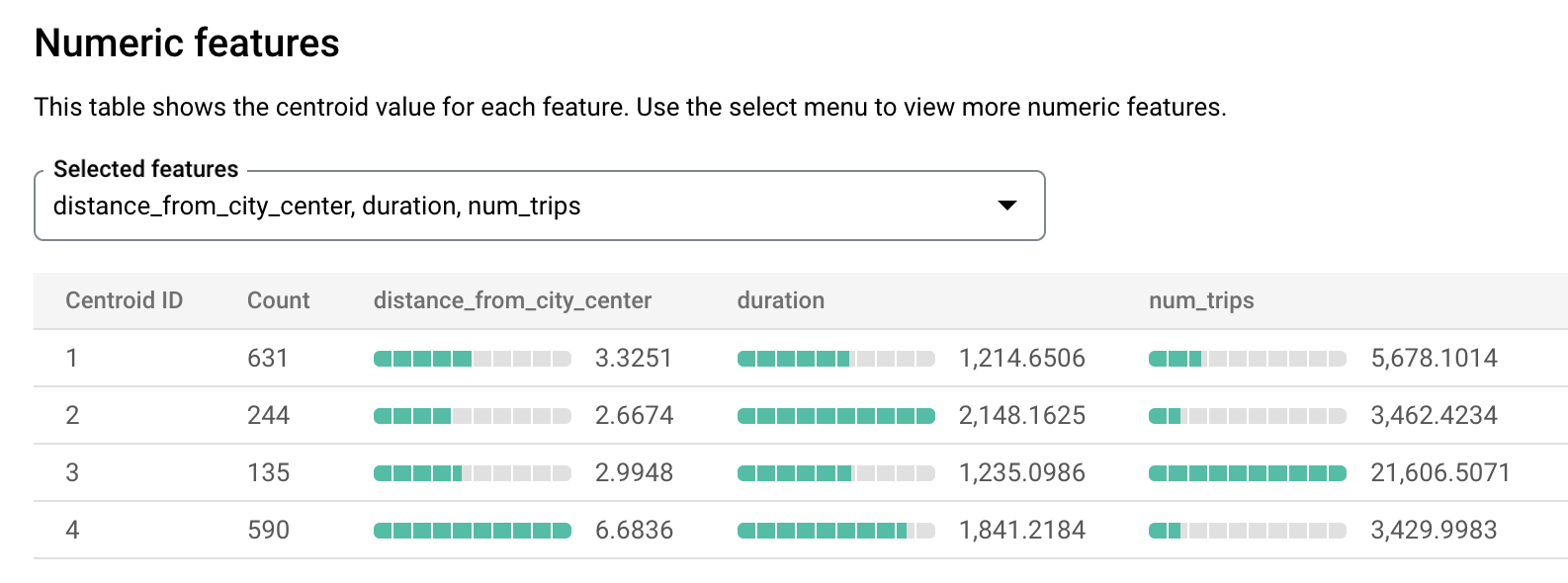
Ce modèle crée les centroïdes suivants :
- Le centroïde 1 indique une station urbaine moins sollicitée, avec des durées de location plus courtes.
- Le centroïde 2 indique la deuxième station urbaine, moins sollicitée et utilisée pour des durées de location plus longues.
- Le centroïde 3 montre une station urbaine très sollicitée proche du centre-ville.
- Le centroïde 4 indique une station de banlieue avec des trajets plus longs.
Si vous gériez une entreprise de location de vélos, vous pourriez utiliser ces informations pour prendre des décisions commerciales. Exemple :
Supposons que vous souhaitiez essayer un nouveau type d'antivol. Quel cluster de stations choisir pour cette expérience ? Les stations du centroïde 1, du centroïde 2 ou du centroïde 4 semblent être des choix logiques, car ce ne sont pas les stations les plus sollicitées.
Supposons que vous souhaitiez munir certaines stations de vélos de course. Quelles stations devriez-vous choisir ? Le centroïde 4 regroupe les stations les plus éloignées du centre-ville, avec les trajets les plus longs. Elles semblent appropriées pour proposer des vélos de course.
Prédire le cluster d'une station à l'aide de la fonction ML.PREDICT
Pour déterminer l'appartenance d'une station à un cluster, utilisez la fonction SQL ML.PREDICT ou la fonction BigQuery DataFrames predict.
SQL
La requête suivante utilise la fonction REGEXP_CONTAINS pour trouver toutes les entrées de la colonne station_name contenant la chaîne Kennington. Ces valeurs permettent à la fonction ML.PREDICT d'identifier les clusters qui pourraient comprendre ces stations.
Pour prédire le cluster de toutes les stations dont le nom contient la chaîne Kennington, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
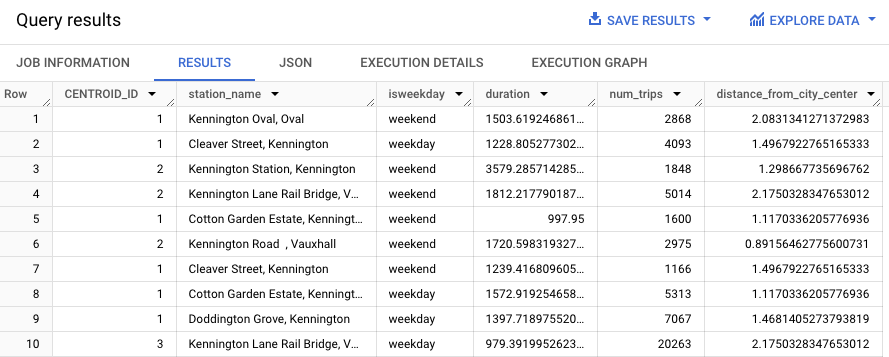
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
Les résultats doivent ressembler à ce qui suit.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.