Utilizzare il plug-in BigQuery JupyterLab
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bigquery-ide-plugin@google.com.
Questo documento mostra come installare e utilizzare il plug-in BigQuery JupyterLab per:
- Esplora i dati BigQuery.
- Utilizza l'API BigQuery DataFrames.
- Esegui il deployment di un notebook BigQuery DataFrames in Cloud Composer.
Il plug-in BigQuery JupyterLab include tutte le funzionalità del plug-in Dataproc JupyterLab, come la creazione di un modello di runtime Dataproc Serverless, l'avvio e la gestione dei blocchi note, lo sviluppo con Apache Spark, il deployment del codice e la gestione delle risorse.
Installa il plug-in BigQuery JupyterLab
Per installare e utilizzare il plug-in BigQuery JupyterLab, segui questi passaggi:
Nel terminale locale, verifica che sul sistema sia installato Python 3.8 o versioni successive:
python3 --versionNel terminale locale, inizializza gcloud CLI:
gcloud initInstalla Pipenv, uno strumento per l'ambiente virtuale Python:
pip3 install pipenvCrea un nuovo ambiente virtuale:
pipenv shellInstalla JupyterLab nel nuovo ambiente virtuale:
pipenv install jupyterlabInstalla il plug-in BigQuery JupyterLab:
pipenv install bigquery-jupyter-pluginSe la versione installata di JupyterLab è precedente alla 4.0.0, attiva l'estensione del plug-in:
jupyter server extension enable bigquery_jupyter_pluginAvvia JupyterLab:
jupyter labJupyterLab si apre nel browser.
Aggiornare le impostazioni del progetto e della regione
Per impostazione predefinita, la sessione viene eseguita nel progetto e nella regione che hai impostato quando hai eseguito gcloud init. Per modificare le impostazioni del progetto e della regione per la sessione, procedi nel seguente modo:
- Nel menu di JupyterLab, fai clic su Impostazioni > Impostazioni di Google BigQuery.
Per applicare le modifiche, devi riavviare il plug-in.
Esplora i dati
Per lavorare con i dati di BigQuery in JupyterLab:
- Nella barra laterale di JupyterLab, apri il riquadro Esplora set di dati: fai clic sull'icona
 dei set di dati.
dei set di dati. Per espandere un progetto, nel riquadro Esplora set di dati, fai clic sulla freccia di espansione accanto al nome del progetto.
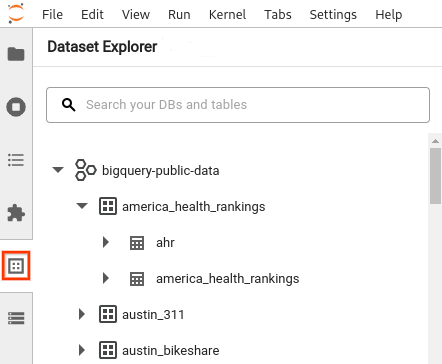
Il riquadro Esplora set di dati mostra tutti i set di dati di un progetto che si trovano nella regione BigQuery configurata per la sessione. Puoi interagire con un progetto e un set di dati in vari modi:
- Per visualizzare informazioni su un set di dati, fai clic sul suo nome.
- Per visualizzare tutte le tabelle di un set di dati, fai clic sulla freccia di espansione accanto al set di dati.
- Per visualizzare informazioni su una tabella, fai clic sul suo nome.
- Per modificare il progetto o la regione BigQuery, aggiorna le impostazioni.
Esegui i notebook
Per eseguire query sui dati BigQuery da JupyterLab:
- Per aprire la pagina di avvio, fai clic su File > Nuovo avvio.
- Nella sezione BigQuery Notebooks, fai clic sulla scheda BigQuery DataFrames. Si apre un nuovo blocco note che mostra come iniziare a utilizzare BigQuery DataFrames.
I blocchi note BigQuery DataFrames supportano lo sviluppo in Python in un kernel Python locale. Le operazioni BigQuery DataFrames vengono eseguite in remoto su BigQuery, ma il resto del codice viene eseguito localmente sulla tua macchina. Quando un'operazione viene eseguita in BigQuery, sotto la cella di codice vengono visualizzati un ID job query e un link al job.
- Per visualizzare il job nella console Google Cloud , fai clic su Apri job.
Esegui il deployment di un notebook BigQuery DataFrames
Puoi eseguire il deployment di un notebook BigQuery DataFrames in Cloud Composer utilizzando un modello di runtime Dataproc Serverless. Devi utilizzare la versione 2.1 o successive del runtime.
- Nel blocco note JupyterLab, fai clic su calendar_monthJob Scheduler.
- In Nome job, inserisci un nome univoco per il job.
- In Environment (Ambiente), inserisci il nome dell'ambiente Cloud Composer in cui vuoi eseguire il deployment del job.
- Se il notebook è parametrizzato, aggiungi i parametri.
- Inserisci il nome del modello di runtime serverless.
- Per gestire gli errori di esecuzione del blocco note, inserisci un numero intero per Numero di tentativi e un valore (in minuti) per Ritardo tra i tentativi.
Seleziona le notifiche di esecuzione da inviare, quindi inserisci i destinatari.
Le notifiche vengono inviate utilizzando la configurazione SMTP di Airflow.
Seleziona una pianificazione per il notebook.
Fai clic su Crea.
Quando pianifichi correttamente il notebook, questo viene visualizzato nell'elenco dei job pianificati nell'ambiente Cloud Composer selezionato.
Passaggi successivi
- Prova la guida rapida di BigQuery DataFrames.
- Scopri di più sull'API Python BigQuery DataFrames.
- Utilizza JupyterLab per sessioni batch e del notebook serverless con Dataproc.