Blob Storage の転送の概要
Azure Blob Storage 用 BigQuery Data Transfer Service を使用すると、Azure Blob Storage と Azure Data Lake Storage Gen2 から BigQuery へと繰り返し発生する読み込みジョブを自動的にスケジュールし、管理できます。
サポートされているファイル形式
BigQuery Data Transfer Service では現在、Blob Storage から次の形式でデータを読み込むことができます。
- カンマ区切り値(CSV)
- JSON(改行区切り)
- Avro
- Parquet
- ORC
サポートされている圧縮タイプ
Blob Storage 用 BigQuery Data Transfer Service は、圧縮されたデータの読み込みをサポートしています。BigQuery Data Transfer Service でサポートされている圧縮タイプは、BigQuery の読み込みジョブでサポートされているものと同じです。詳細については、圧縮データと非圧縮データを読み込むをご覧ください。
転送の前提条件
Blob Storage データソースからデータを読み込むには、まず、以下の情報を収集します。
- ソースデータの Blob Storage アカウント名、コンテナ名、データパス(省略可)。データパス フィールドは省略可能です。これは、一般的なオブジェクト接頭辞とファイル拡張子を照合するために使用されます。データパスを省略すると、コンテナ内のすべてのファイルが転送されます。
- データソースへの読み取りアクセス権を付与する Azure Shared Access Signature(SAS)トークン。SAS トークンの作成の詳細については、Shared Access Signature(SAS)をご覧ください。
転送ランタイムのパラメータ化
Blob Storage のデータパスと宛先テーブルの両方をパラメータ化して、日付で整理されたコンテナからデータを読み込むことができます。Blob Storage の転送で使用されるパラメータは、Cloud Storage の転送で使用されるパラメータと同じです。詳細については、転送のランタイム パラメータをご覧ください。
Azure Blob 転送のデータの取り込み
Azure Blob 転送を設定するときに、転送構成で書き込み設定を選択して、BigQuery へのデータの読み込み方法を指定できます。
書き込み設定には、増分転送と切り捨て転送の 2 種類があります。増分転送
APPEND または WRITE_APPEND の書き込み設定がある転送構成(増分転送とも呼ばれる)では、前回成功した BigQuery の宛先テーブルへの転送以降の新しいデータの増分が追加されます。転送構成が APPEND の書き込み設定で実行されると、BigQuery Data Transfer Service は、前回の転送実行後に変更されたファイルを絞り込みます。ファイルが変更されたタイミングを判断するため、BigQuery Data Transfer Service は、ファイルのメタデータで「最終更新日時」プロパティを確認します。たとえば、BigQuery Data Transfer Service は、Cloud Storage ファイルの updated タイムスタンプ プロパティを参照します。BigQuery Data Transfer Service では、「最終更新日時」が最後に成功した転送のタイムスタンプより後のファイルが見つかると、BigQuery Data Transfer Service によってそれらのファイルが増分転送で転送されます。
増分転送の仕組みを示すために、次の Cloud Storage 転送の例を考えます。時刻 2023-07-01T00:00Z に、あるユーザーが Cloud Storage バケットに file_1 というファイルを作成します。file_1 の updated タイムスタンプは、ファイルが作成された時刻です。次にユーザーは、Cloud Storage バケットからの増分転送を作成し、2023-07-01T03:00Z から、毎日 1 回、時刻 03:00Z に実行されるようにスケジュール設定します。
- 2023-07-01T03:00Z に、最初の転送実行が開始されます。これがこの構成での最初の転送実行であるため、BigQuery Data Transfer Service は、転送元 URI に一致するすべてのファイルを宛先 BigQuery テーブルに読み込むことを試みます。転送実行は成功し、BigQuery Data Transfer Service が宛先 BigQuery テーブルに
file_1を正常に読み込みます。 - 次の転送実行(2023-07-02T03:00Z)では、最後に成功した転送実行(2023-07-01T03:00Z)より
updatedタイムスタンプ プロパティが大きいファイルは検出されません。転送実行は、転送先の BigQuery テーブルに追加のデータを読み込むことなく成功します。
前述の例は、BigQuery Data Transfer Service がソースファイルの updated タイムスタンプ プロパティを確認し、ソースファイルに変更が加えられているかどうかを判断して、変更が検出された場合はその変更を転送する方法を示しています。
同じ例に沿って、ユーザーが Cloud Storage バケットに、別のファイルを file_2 という名前で時刻 2023-07-03T00:00Z に作成したとします。file_2 の updated タイムスタンプは、ファイルが作成された時刻です。
- 次の転送実行(2023-07-03T03:00Z)で、
file_2のupdatedタイムスタンプが最後に成功した転送実行(2023-07-01T03:00Z)より大きいことが検出されます。転送実行の開始時に、一時的なエラーで失敗したとします。このシナリオでは、file_2は宛先 BigQuery テーブルに読み込まれません。最後に成功した転送実行のタイムスタンプは 2023-07-01T03:00Z のままです。 - 次の転送実行(2023-07-04T03:00Z)で、
file_2のupdatedタイムスタンプが最後に成功した転送実行(2023-07-01T03:00Z)より大きいことが検出されます。今回は、転送実行が問題なく完了するため、転送先 BigQuery テーブルにfile_2が正常に読み込まれます。 - 次の転送実行(2023-07-05T03:00Z)では、最後に成功した転送実行(2023-07-04T03:00Z)より
updatedタイムスタンプが大きいファイルは検出されません。転送実行は、転送先の BigQuery テーブルに追加のデータを読み込むことなく成功します。
前述の例では、転送が失敗した場合、BigQuery の宛先テーブルに転送されるファイルがありません。ファイルの変更は、次に転送の実行が成功したときに転送されます。失敗した転送に続いて成功した転送で重複データは発生しません。転送が失敗した場合は、定期的に予定されている時間外に転送を手動でトリガーすることもできます。
切り捨て転送
MIRROR または WRITE_TRUNCATE の書き込み設定がある転送構成(切り捨て転送とも呼ばれる)は、各転送の実行時に、BigQuery 宛先テーブルのデータを、ソース URI に一致するすべてのファイルのデータで上書きします。MIRROR は、宛先テーブル内のデータの新しいコピーを上書きします。宛先テーブルがパーティション デコレータを使用している場合、転送実行では指定されたパーティションのデータのみが上書きされます。パーティション デコレータがある宛先テーブルの形式は、my_table${run_date} になります(例: my_table$20230809)。
同じ増分転送や切り捨て転送を 1 日で繰り返しても、データの重複は発生しません。ただし、同じ BigQuery 宛先テーブルに影響する複数の転送構成を実行すると、BigQuery Data Transfer Service がデータを重複させる可能性があります。
Blob Storage データパスのワイルドカード サポート
データパスでワイルドカードとしてアスタリスク(*)を 1 つ以上指定することで、複数のファイルに分割されたソースデータを選択できます。
データパスには複数のワイルドカードを使用できますが、ワイルドカードを 1 つだけ使用すると、最適化が可能になります。
- 転送実行ごとの最大ファイル数には上限があります。
- ワイルドカードはディレクトリの境界をまたがって適用されます。たとえば、データパス
my-folder/*.csvはファイルmy-folder/my-subfolder/my-file.csvと一致します。
Blob Storage のデータパスの例
Blob Storage の転送で有効なデータパスの例を次に示します。データパスは / で始まらないことに注意してください。
例: 単一ファイル
Blob Storage から BigQuery に単一のファイルを読み込むには、Blob Storage のファイル名を指定します。
my-folder/my-file.csv
例: すべてのファイル
Blob Storage コンテナから BigQuery にすべてのファイルを読み込むには、データパスを 1 つのワイルドカードで設定します。
*
例: 共通の接頭辞を持つファイル
共通の接頭辞を持つすべてのファイルを Blob Storage から読み込むには、共通の接頭辞を指定します。ワイルドカードの使用は任意です。
my-folder/
または
my-folder/*
例: パスが類似しているファイル
Blob Storage から類似したパスを持つすべてのファイルを読み込むには、共通の接頭辞と接尾辞を指定します。
my-folder/*.csv
ワイルドカードを 1 つだけ使用した場合、範囲が複数のディレクトリにまたがることになります。この例では、my-folder 内のすべての CSV ファイルと、my-folder のすべてのサブフォルダ内のすべての CSV ファイルが選択されます。
例: パスの最後にあるワイルドカード
次のデータパスについて考えてみましょう。
logs/*
次のファイルがすべて選択されています。
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
例: パスの先頭にあるワイルドカード
次のデータパスについて考えてみましょう。
*logs.csv
次のファイルがすべて選択されています。
logs.csv
system/logs.csv
some-application/logs.csv
次のいずれのファイルも選択されていません。
metadata.csv
system/users.csv
some-application/output.csv
例: 複数のワイルドカード
複数のワイルドカードを使用すると、下限が低くなりますが、ファイルの選択をより詳細に制御できます。複数のワイルドカードを使用する場合、個々のワイルドカードの範囲は 1 つのサブディレクトリに限定されます。
次のデータパスについて考えてみましょう。
*/*.csv
次の両方のファイルが選択されています。
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
次のどちらのファイルも選択されていません。
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Shared Access Signature(SAS)
Azure SAS トークンは、ユーザーの代わりに Blob Storage データにアクセスするために使用されます。転送用の SAS トークンを作成する手順は次のとおりです。
- Blob Storage コンテナのストレージ アカウントにアクセスするには、Blob Storage ユーザーを作成するか、既存のユーザーを使用します。
ストレージ アカウント レベルで SAS トークンを作成します。Azure ポータルを使用して SAS トークンを作成する手順は次のとおりです。
- [Allowed services] で [Blob] を選択します。
- [Allowed resource types] で、[Container] と [Object] の両方を選択します。
- [Allowed permissions] で [Read] と [List] を選択します。
- SAS トークンのデフォルトの有効期限は 8 時間です。転送スケジュールに適した有効期限を設定します。
- [Allowed IP addresses] フィールドには IP アドレスを指定しないでください。
- [Allowed protocols] で [HTTPS only] を選択します。
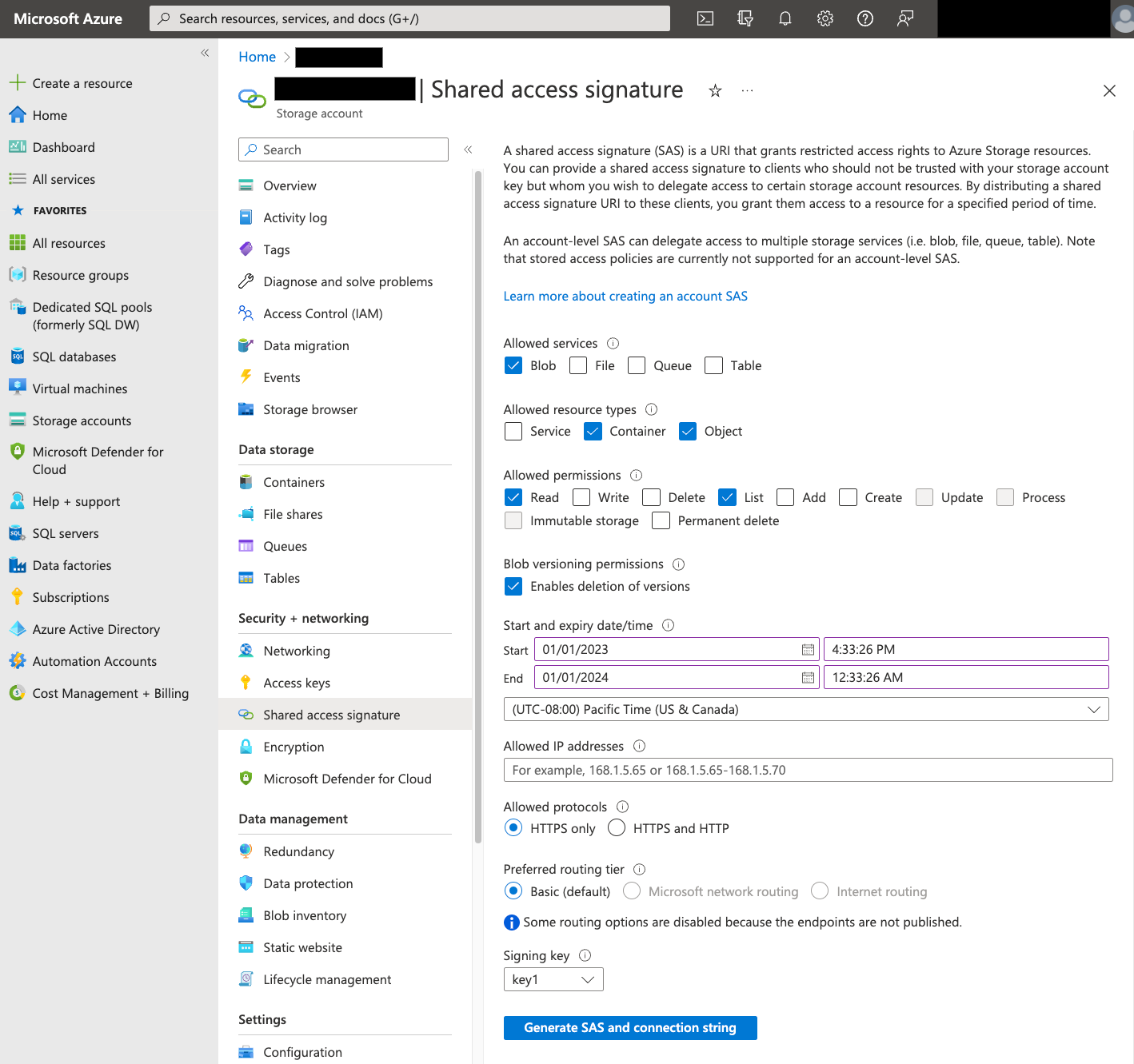
SAS トークンが作成されたら、返された SAS トークンの値をメモします。この値は、転送を構成するときに必要になります。
IP の制限
Azure Storage ファイアウォールを使用して Azure リソースへのアクセスを制限する場合は、BigQuery Data Transfer Service ワーカーで使用される IP 範囲を、許可された IP のリストに追加する必要があります。
IP 範囲を許可された IP として Azure Storage ファイアウォールに追加するには、IP 制限をご覧ください。
整合性に関する留意事項
ファイルが Blob Storage コンテナに追加されてから BigQuery Data Transfer Service で使用できるようになるまでに約 5 分かかります。
下り(外向き)の費用を抑えるためのベスト プラクティス
宛先テーブルが正しく構成されていないと、Blob Storage からの転送が失敗する可能性があります。構成が適切でない原因としては、次のことが考えられます。
- 宛先テーブルが存在しない。
- テーブル スキーマが定義されていない。
- テーブル スキーマと転送されるデータとの互換性がない。
Blob Storage の下り(外向き)料金が発生しないようにするには、まず、サイズが小さく、代表的なファイルのサブセットで転送をテストします。このテストでは、データサイズとファイル数の両方を小さくしてください。
また、データパスの接頭辞の照合は Blob Storage からファイルが転送される前に行われますが、 Google Cloud内ではワイルドカードの照合が行われることに注意してください。この違いにより、Google Cloud に転送されても BigQuery に読み込まれないファイルに対する、Blob Storage の下り(外向き)費用が増加する可能性があります。
たとえば、次のデータパスを考えてみます。
folder/*/subfolder/*.csv
次のファイルは接頭辞 folder/ が付いているため、どちらも Google Cloudに転送されます。
folder/any/subfolder/file1.csv
folder/file2.csv
ただし、BigQuery に読み込まれるのは folder/any/subfolder/file1.csv ファイルのみです(完全なデータパスと一致するため)。
料金
詳細については、BigQuery Data Transfer Service の料金をご覧ください。
このサービスを使用することで、Google 以外の場所で費用が発生する可能性があります。詳細については、Blob Storage の料金をご覧ください。
割り当てと上限
BigQuery Data Transfer Service は読み込みジョブを使用して、Blob Storage データを BigQuery に読み込みます。定期的な Blob Storage 転送には、BigQuery の読み込みジョブに対するすべての割り当てと上限に加え、次の考慮事項も適用されます。
| 上限 | デフォルト |
|---|---|
| 読み込みジョブの転送実行ごとの最大サイズ | 15 TB |
| Blob Storage のデータパスに 0 個または 1 個のワイルドカードが含まれている場合の、転送ごとの最大ファイル数 | 10,000,000 ファイル |
| Blob Storage のデータパスに 2 個以上のワイルドカードが含まれている場合の、転送ごとの最大ファイル数 | 10,000 ファイル |
次のステップ
- Blob Storage の転送設定について確認する。
- 転送のランタイム パラメータについて確認する。
- BigQuery Data Transfer Service の詳細を確認する。