Dieses Dokument ist Teil einer Reihe, die wichtige Informationen und Anleitungen zur Planung und Durchführung von Oracle® 11g/12c-Datenbankmigrationen zu Cloud SQL for PostgreSQL Version 12 enthält. Zusätzlich zum Teil der anfänglichen Einrichtung umfasst die Reihe die folgenden Teile:
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Terminologie und Funktionalität (dieses Dokument)
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Datentypen, Nutzer und Tabellen
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Abfragen, gespeicherte Verfahren, Funktionen und Trigger
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Sicherheit, Vorgänge, Monitoring und Logging
- Oracle Database-Nutzer und -Schemas zu Cloud SQL for PostgreSQL migrieren
Terminologie
In diesem Abschnitt werden die Gemeinsamkeiten und Unterschiede in der Datenbankterminologie zwischen Oracle und Cloud SQL for PostgreSQL beschrieben. Hierin werden die Kernaspekte der einzelnen Datenbankplattformen geprüft und verglichen. Beim Vergleich wird zwischen den Versionen 11g und 12c von Oracle aufgrund von Architekturunterschieden unterschieden (z. B. führt Oracle 12c die Funktion für mehrere Mandanten ein). Die hier erwähnte Cloud SQL for PostgreSQL-Version ist 12.
In diesem Abschnitt werden die wichtigsten Unterschiede zwischen der Terminologie in Oracle und Cloud SQL for PostgreSQL hervorgehoben. Eine detaillierte Beschreibung finden Sie weiter unten in diesem Dokument.
| Oracle 11g | Beschreibung | Cloud SQL for PostgreSQL | Wichtige Unterschiede |
|---|---|---|---|
| instance | Eine einzelne Oracle 11g-Instanz kann nur eine Datenbank enthalten. | instance | Eine Cloud SQL for PostgreSQL-Instanz enthält genau einen Datenbankcluster. Ein Datenbankcluster ist eine Sammlung von Datenbanken, die in einem gemeinsamen Datenbereich gespeichert sind. |
| database | Eine Datenbank gilt als eine einzelne Instanz (der Name der Datenbank ist mit dem Instanznamen identisch). | database | Mehrere oder einzelne Datenbanken stellen mehrere Anwendungen bereit. |
| schema | Schema und Nutzer sind identisch, da beide als Eigentümer von Datenbankobjekten betrachtet werden (ein Nutzer kann ohne Angabe oder Zuweisung zu einem Schema erstellt werden). | schema | Eine Datenbank enthält mindestens ein Schema. Objekte wie Tabellen sind in Schemas enthalten. Derselbe Objektname könnte konfliktfrei in verschiedenen Schemas innerhalb derselben Datenbank verwendet werden. |
| Nutzer | Identisch mit Schema, da beide Inhaber von Datenbankobjekten sind, z. B. Instanz → Datenbank → Schemas/Nutzer → Datenbankobjekte. | Rolle | Eine Rolle kann entweder ein Datenbanknutzer oder eine Gruppe von Datenbanknutzern sein, je nachdem, wie sie eingerichtet ist. Sie kann Datenbankobjekte wie Tabellen besitzen.
Rollen sind für einen gesamten Datenbankcluster vorgesehen und es kann eine Rolle einer anderen Rolle zugewiesen werden. |
| Rolle | Definierte Gruppe von Datenbankberechtigungen, die als Gruppe verkettet und Datenbanknutzern zugewiesen werden können. | ||
| Admin-/ SYSTEM-Nutzer |
Oracle-Administratoren mit der höchsten Zugriffsebene:SYS
|
cloudsqlsuperuser | Cloud SQL for PostgreSQL verfügt über den Standardnutzer postgres. Dieser Nutzer gehört zur cloudsqlsuperuser-Rolle und hat die folgenden Attribute (Berechtigungen): CREATEROLE, CREATEDB und LOGIN. Da Cloud SQL for PostgreSQL ein verwalteter Dienst ist, wird der Zugriff auf bestimmte Systemprozeduren und -tabellen eingeschränkt, für die erweiterte Berechtigungen erforderlich sind. Daher hat der postgres-Nutzer nicht die Attribute SUPERUSER oder REPLICATION. Sie können keine Nutzer mit superuser-Attributen erstellen oder darauf zugreifen. |
| Wörterbuch/ Metadaten |
Oracle verwendet die folgenden Metadatentabellen:USER_TableName
|
Wörterbuch/ Metadaten |
Cloud SQL for PostgreSQL verwendet den ANSI-Standard INFORMATION_SCHEMA, um Wörterbuch- und Metadateninformationen bereitzustellen. |
| Dynamische Systemansichten | Dynamische Oracle-Ansichten:V$ViewName |
Dynamische Systemansichten |
Cloud SQL for PostgreSQL bietet die folgenden dynamischen Statistikansichten:pg_stat_ViewNamepg_statio_ViewName |
| Tablespace | Die primären logischen Speicherstrukturen von Oracle-Datenbanken; jeder Tablespace kann eine oder mehrere Datendateien enthalten. | Tablespace | In Cloud SQL for PostgreSQL werden Datendateien mit einer vordefinierten Verzeichnisstruktur im Datenverzeichnis PGDATA des Datenbankclusters gespeichert. Tablespaces in Cloud SQL for PostgreSQL bieten einen Mechanismus, um benutzerdefinierte Speicherorte im Dateisystem zu definieren, wo Datendateien gespeichert werden können.Da Cloud SQL for PostgreSQL ein verwalteter Dienst ist, Google Cloud wird das zugrunde liegende Dateisystem des Hostcomputers für Sie verwaltet. Sie können keine neuen Tablespaces in Cloud SQL for PostgreSQL erstellen. |
| Datendateien | Die physischen Elemente einer Oracle-Datenbank, die die Daten enthalten und in einem bestimmten Tablespace definiert sind. Eine einzelne Datendatei wird durch die anfängliche und die maximale Größe definiert und kann Daten für mehrere Tabellen enthalten. Oracle-Datendateien verwenden das Suffix .dbf (nicht obligatorisch). |
Datendateien | Cloud SQL for PostgreSQL speichert jede Datenbank in einem Datenbankcluster in ihrem eigenen Unterverzeichnis. Jede Tabelle und jeder Index innerhalb einer Datenbank wird in einer separaten Datei in diesem Unterverzeichnis gespeichert. |
| System-Tablespace | Enthält die Datenwörterbuch-Tabellen und -Ansichtsobjekte für die gesamte Oracle-Datenbank. | Existiert nicht | Datenwörterbuch-Tabellen und -Ansichtsobjekte werden inINFORMATION_SCHEMA im Datenverzeichnis PGDATA eines Datenbankclusters mithilfe einer vordefinierten Verzeichnisstruktur gespeichert. |
| Temporärer Tablespace | Enthält Schemaobjekte, die für die Dauer einer Sitzung gültig sind. Darüber hinaus unterstützt es die Ausführung von Vorgängen, die nicht in den Serverspeicher passen. |
Temporäre Dateien | Temporäre Dateien werden zum Speichern von Vorgängen verwendet, die nicht in den Arbeitsspeicher des Servers passen. Diese Dateien werden in einem Verzeichnis mit dem Namen pgsql_tmp gespeichert. Sie werden nur erstellt, während die SQL-Anweisung ausgeführt wird. |
| Tablespace rückgängig machen | Ein spezieller Typ von system-permanentem Tablespace, der von Oracle zur Verwaltung von Rollback-Operationen verwendet wird, wenn die Datenbank im automatischen Rückgängig-machen-Verwaltungsmodus ausgeführt wird (Standard). |
Existiert nicht | Um Rollback-Vorgänge zu ermöglichen, speichert Cloud SQL for PostgreSQL Zeilen, die in der Datendatei der Tabelle aktualisiert oder gelöscht werden. Beim Vacuuming handelt es sich um den Vorgang zur Wiederherstellung oder Wiederverwendung von Speicherplatz, der von aktualisierten oder gelöschten Zeilen belegt wird. |
| ASM | Die automatische Speicherverwaltung von Oracle (ASM, Automatic Storage Management) ist ein integriertes Hochleistungs-Datenbankdateisystem und ein Festplattenmanager, die alle automatisch von einer Oracle-Datenbank ausgeführt werden, die mit ASM konfiguriert wurde. | Nicht unterstützt | Cloud SQL for PostgreSQL benötigt das Betriebssystem des Dateisystems, um Datendateien zu speichern, und hat kein Oracle-ASM-Äquivalent. Cloud SQL for PostgreSQL unterstützt viele Funktionen zur Speicherautomatisierung, z. B. automatische Speichererweiterungen, Leistung und Skalierbarkeit. |
| Tabellen/Ansichten | Vom Nutzer erstellte grundlegende Datenbankobjekte. | Tabellen/Ansichten | Identisch mit Oracle. |
| Materialisierte Ansichten | Wird mit bestimmten SQL-Anweisungen definiert und kann je nach Konfiguration manuell oder automatisch aktualisiert werden. |
Materialisierte Ansichten | Materialisierte Ansichten funktionieren ähnlich wie Oracle. Sie werden manuell mit REFRESH
MATERIALIZED VIEW-Anweisungen aktualisiert. |
| Sequenz | Oracle-Wertgenerator für eindeutige Werte. | Sequenz | Ähnlich wie Oracle. |
| Synonym | Oracle-Datenbankobjekte, die als alternative Kennzeichnungen für andere Datenbankobjekte dienen. | Nicht unterstützt | Cloud SQL for PostgreSQL bietet keine Synonyme. Als Problemumgehung können Ansichten verwendet werden, während die entsprechenden Berechtigungen festgelegt werden. |
| Partitionierung | Oracle bietet viele Partitionierungslösungen zum Aufteilen großer Tabellen in kleinere verwaltete Teile. | Partitionierung | Cloud SQL for PostgreSQL unterstützt sowohl die deklarative Partitionierung des Oracle-Stils als auch die Partitionierung mithilfe von Übernahme. Dies ermöglicht eine größere Partitionierungsflexibilität. |
| Flashback-Datenbank | Oracle-eigene Funktion, mit der eine Oracle-Datenbank für eine zuvor definierte Zeit initialisiert werden kann, um Daten abzufragen oder wiederherzustellen, die versehentlich geändert oder beschädigt wurden. | Nicht unterstützt | Als alternative Lösung können Sie Cloud SQL-Sicherungen und die Wiederherstellung zu einem bestimmten Zeitpunkt verwenden, um eine Datenbank in einen vorherigen Zustand zurückzusetzen (z. B. vor dem Löschen einer Tabelle). |
| sqlplus | Oracle-Befehlszeilenschnittstelle, mit der Sie die Datenbankinstanz abfragen und verwalten können. | psql | Cloud SQL for PostgreSQL – gleichwertige Befehlszeile zur Abfrage und Verwaltung. Kann von jedem Client mit den entsprechenden Berechtigungen für Cloud SQL verbunden werden. |
| PL/SQL | Oracle hat die Verfahrenssprache auf ANSI SQL erweitert. | PL/pgSQL | Cloud SQL for PostgreSQL hat eine eigene prozedurale Sprache namens PL/pgSQL, die PL/SQL von Oracle in vielen Aspekten ähnlich ist. Eine Zusammenfassung der Hauptunterschiede zwischen den beiden Sprachen finden Sie unter Porting von Oracle PL/SQL. |
| Paket und Pakettext | Oracle-spezifische Funktionen zum Gruppieren von gespeicherten Verfahren und Funktionen unter derselben logischen Referenz. | Nicht unterstützt | Cloud SQL for PostgreSQL organisiert Funktionen mithilfe von Schemas. |
| Gespeicherte Verfahren und Funktionen | Verwendet PL/SQL zur Implementierung der Codefunktionalität. | Gespeicherte Verfahren und Funktionen | Cloud SQL for PostgreSQL unterstützt die Implementierung gespeicherter Prozeduren und Funktionen mit verschiedenen Programmiersprachen wie PL/pgSQL und C. |
| Trigger | Oracle-Objekt zur Steuerung der DML-Implementierung über Tabellen. | Trigger | Ähnlich wie Oracle. |
| PFILE/SPFILE | Die Parameter der Oracle-Instanz und der Datenbankebene werden in einer Binärdatei mit dem Namen SPFILE (in früheren Versionen hieß die Datei PFILE) gespeichert, die als Textdatei für die manuelle Einstellung von Parametern verwendet werden kann. |
Datenbank-Flags für Cloud SQL for PostgreSQL | Sie können Cloud SQL for PostgreSQL-Parameter über das Dienstprogramm Datenbank-Flags festlegen oder ändern. |
| SGA/PGA/ AMM |
Oracle-Speicherparameter, die die Speicherzuweisung für die Datenbankinstanz steuern. | Verschiedene speicherbezogene Parameter | Cloud SQL for PostgreSQL hat eigene Speicherparameter. Ähnliche Parameter sind shared_buffers, temp_buffers und work_mem. In Cloud SQL for PostgreSQL sind diese Parameter vom ausgewählten Instanztyp vordefiniert und der Wert ändert sich entsprechend. Sie können einige dieser Parameter mit dem Datenbank-Flag-Dienstprogramm anpassen. |
| Zwischenspeichercache | Reduziert SQL-E/A-Vorgänge durch das Abrufen von im Cache gespeicherten Daten aus dem Zwischenspeichercache. Speicherparameter können auf Datenbankebene und auf Sitzungsebene mithilfe von Abfragehinweisen verwaltet werden. | Ähnliche Funktionen | Die Größe des Zwischenspeichercache bei Cloud SQL for PostgreSQL wird über den Parameter shared_buffer gesteuert, der in Cloud SQL nicht verfügbar ist. Cloud SQL bietet einen Messwert zur Speichernutzung, mit dem die Größe der Instanz angepasst wird. |
| Datenbankhinweise | Oracle-Möglichkeit, die Auswirkungen von SQL-Anweisungen zu kontrollieren, die das Optimierungstool-Verhalten beeinflussen, um eine bessere Leistung zu erzielen. Oracle bietet mehr als 50 verschiedene Datenbankhinweise. | Nicht unterstützt | Cloud SQL for PostgreSQL unterstützt keine Datenbankhinweise. In begrenztem Umfang können Sie den Abfrageplaner von Cloud SQL for PostgreSQL mithilfe der expliziten JOIN-Syntax steuern. |
| RMAN | Wiederherstellungs-Manager von Oracle. Wird für Datenbanksicherungen mit erweiterter Funktionalität verwendet, um mehrere Szenarien der Notfallwiederherstellung und mehr (Klonen usw.) zu unterstützen. | Cloud SQL for PostgreSQL-Sicherung | Cloud SQL for PostgreSQL bietet zwei Methoden zum Anwenden vollständiger Sicherungen: On-Demand- und automatische Sicherungen. |
| Data Pump (EXPDP/ IMPDP) |
Oracle-Dump-Generierungsprogramm, das für viele Funktionen verwendet werden kann, z. B. Export/Import, Datenbanksicherung (auf Schema- oder Objektebene), Schemametadaten, Schema-SQL-Dateien generieren und mehr. | Cloud SQL for PostgreSQL-Export/Import | Cloud SQL for PostgreSQL bietet zwei Export-/Importformate in und aus Cloud Storage-Buckets: SQL und CSV. Alternativ können Sie mit Export-/Import-Dienstprogrammen wie pg_dump eine Verbindung zur Datenbankinstanz herstellen. |
| SQL*Loader | Tool, mit dem Sie Daten aus externen Dateien wie Textdateien oder CSV-Dateien hochladen können. | psql \copy |
Mit dem Befehl \copy im psql-Client können Text-, CSV- oder Binärdateien in einer Datenbanktabelle mit der entsprechenden Struktur geladen werden. Oracle unterstützt weitere Dateiformate. |
| Data Guard | Oracle-Notfallwiederherstellungslösung mit einer Standby-Instanz, mit der Nutzer READ-Vorgänge von der Standby-Instanz aus durchführen können. |
Hochverfügbarkeit und Replikation in Cloud SQL for PostgreSQL | Für eine Notfallwiederherstellung oder Hochverfügbarkeit bietet Cloud SQL for PostgreSQL die Architektur mit Failover-Replikat und schreibgeschützte Vorgänge (READ/WRITE-Trennung) mit dem Lesereplikat. |
| Active Data Guard/ GoldenGate |
Die Hauptreplikationslösungen von Oracle, die verschiedene Zwecke erfüllen, z. B. Standby (DR), schreibgeschützte Instanz, bidirektionale Replikation (Multi-Master), Data-Warehouse-Prozesse und mehr. | Cloud SQL for PostgreSQL-Lesereplikat | Cloud SQL for PostgreSQL-Lesereplikat zum Implementieren von Clustern mit Lese-/Schreib-Trennung. Derzeit wird Multi-Master-Konfiguration wie die bidirektionale GoldenGate-Replikation oder die heterogene Replikation nicht unterstützt. |
| RAC | Oracle Real Application Cluster. Oracle-eigene Clustering-Lösung für Hochverfügbarkeit durch Bereitstellung mehrerer Datenbankinstanzen mit einer einzigen Speichereinheit. | Nicht unterstützt | Cloud SQL for PostgreSQL unterstützt keine Multi-Master-Architektur. Cloud SQL for PostgreSQL bietet Hochverfügbarkeit durch eine Standby-Instanz und erhöhte Skalierbarkeit beim Lesen durch Lesereplikate. |
| Grid/Cloud Control (OEM) | Oracle-Software zur Verwaltung und Überwachung von Datenbanken und anderen zugehörigen Diensten in einem Webanwendungsformat. Dieses Tool ist für die Datenbankanalyse in Echtzeit nützlich, um hohe Arbeitslasten zu verstehen. | Google Cloud Console, Cloud Monitoring |
Verwenden Sie Cloud SQL for PostgreSQL für das Monitoring, einschließlich detaillierter zeit- und ressourcenbasierter Grafiken. Mit Cloud Monitoring können Sie auch bestimmte Cloud SQL for PostgreSQL-Monitoringmesswerte und Loganalysen für erweiterte Monitoringfunktionen speichern. |
| REDO-Logs | Oracle-Transaktionslogs, die aus zwei (oder mehr) vordefinierten Dateien bestehen, in denen alle Datenänderungen gespeichert werden. Der Hauptzweck des Redo-Logs ist es, die Datenbank beim Ausfall einer Instanz zu schützen. | WAL-Logs | Cloud SQL for PostgreSQL verwendet Write-Ahead Logging (WAL), damit Änderungen an Datendateien dauerhaft gespeichert werden, um eine Wiederherstellung nach Absturz zu ermöglichen. |
| Archivlogs | Archivlogs bieten Unterstützung für Sicherungs- und Replikationsvorgänge und mehr. Oracle schreibt nach jedem Wechsel des Redo-Logs in Archivlogs (falls aktiviert). | WAL-Archivierung | Cloud SQL for PostgreSQL-Implementierung der WAL-Logaufbewahrung. Die WAL-Archivierung wird mit der Wiederherstellung zu einem bestimmten Zeitpunkt verwendet und aktiviert. |
| Kontrolldatei | Die Oracle-Kontrolldatei enthält Informationen über die Datenbank, z. B. Datendateien, Namen von Redo-Logs, Speicherorte, die aktuelle Logsequenznummer und Informationen zum Instanzprüfpunkt. | PGDATA and pg_control
|
Die Architektur von Cloud SQL for PostgreSQL hat nicht das gleiche Konzept wie eine Oracle-Kontrolldatei. Datenbankbezogene Dateien sind in einem Verzeichnis organisiert, das häufig als PGDATA bezeichnet wird. WAL-Informationen zu Einträgen und Prüfpunkten werden in pg_control gespeichert. |
| Nummer der Systemänderung (SCN) | Die SCN kennzeichnet einen bestimmten Zeitpunkt in einer Oracle-Datenbank. | Logsequenznummer (LSN) | Das Äquivalent in Cloud SQL for PostgreSQL ist die LSN. Genau wie bei SCNs werden steigen LSNs im Laufe der Zeit kontinuierlich an. |
| AWR | Oracle AWR (automatisches Arbeitslast-Repository) ist ein ausführlicher Bericht mit detaillierten Informationen zur Leistung der Oracle-Datenbankinstanz und gilt als DBA-Tool für die Leistungsdiagnose. | Statistikerfassungsmodul | Für Cloud SQL for PostgreSQL gibt es keinen Bericht, der mit Oracle AWR übereinstimmt, aber PostgreSQL erfasst die vom Statistikerfassungsmodul erfassten Leistungsdaten. Die erfassten Statistiken werden über die Ansichten pg_stat_* und pg_statio_* bereitgestellt. |
DBMS_SCHEDULER
|
Oracle-Dienstprogramm zum Festlegen und Planen vordefinierter Vorgänge. | Nicht unterstützt | Cloud SQL for PostgreSQL bietet kein integriertes Dienstprogramm. Google Cloud bietet Cloud Scheduler, mit dem Sie Datenbankaufgaben wie Exporte planen können. |
| Transparente Datenverschlüsselung | Verschlüsselung von auf Laufwerken gespeicherten Daten als Schutz für inaktive Daten. | Cloud SQL Advanced Encryption Standard | Cloud SQL for PostgreSQL verwendet den Advanced Encryption Standard mit 256 Bit zum Schutz inaktiver und übertragener Daten. |
| Erweiterte Komprimierung | Um den Speicherbedarf der Datenbank zu verbessern, die Speicherkosten zu senken und die Datenbankleistung zu verbessern, bietet Oracle erweiterte Datenkomprimierungsfunktionen (Tabellen/Indexe). | TOAST | Obwohl Cloud SQL for PostgreSQL nicht direkt mit der erweiterten Komprimierung vergleichbar ist, verwendet Cloud SQL for PostgreSQL eine Infrastruktur mit dem Namen TOAST, um Daten in variabler Länge, die zu groß werden, um auf eine einzelne Datenseite zu passen, automatisch und transparent zu komprimieren. |
| SQL-Entwickler | Die kostenlose SQL-GUI von Oracle zur Verwaltung und Ausführung von SQL- und PL/SQL-Anweisungen. | pgAdmin | Die kostenlose SQL-GUI von Cloud SQL for PostgreSQL zum Verwalten und Ausführen von SQL- und PostgreSQL-Codeanweisungen. |
| Benachrichtigungslogs | Das Hauptlog von Oracle für allgemeine Datenbankvorgänge und -fehler. | PostgreSQL-Fehlerberichte und -Logging | Verwenden Sie die Loganzeige von Cloud Logging, um PostgreSQL-Fehlerlogs zu überprüfen. |
| DUAL-Tabelle | Oracle-Sondertabelle zum Abrufen von Pseudospaltenwerten wie SYSDATE oder USER. |
Existiert nicht | Mit Cloud SQL for PostgreSQL können FROM-Klauseln aus SQL-Anweisungen weggelassen werden. Beispiel:SELECT NOW();
ist eine gültige Anweisung in PostgreSQL. |
| Externe Tabelle | Mit Oracle können Nutzer externe Tabellen mit den Quelldaten für Dateien außerhalb der Datenbank erstellen. | Nicht unterstützt | Als verwalteter Dienst stellt Cloud SQL for PostgreSQL nicht das zugrunde liegende Dateisystem des Hosts bereit, der die Datenbankinstanz ausführt. Als Problemumgehung können Sie die Quelldaten in eine PostgreSQL-Tabelle importieren, um die Daten abzufragen. |
| Listener | Oracle-Netzwerkprozess mit der Aufgabe, eingehende Datenbankverbindungen zu überwachen. | Für Cloud SQL autorisierte Netzwerke | Cloud SQL for PostgreSQL akzeptiert Verbindungen von Remotequellen, sobald diese auf der Konfigurationsseite für autorisierte Netzwerke von Cloud SQL zugelassen wurden. |
| TNSNAMES | Oracle-Netzwerkkonfigurationsdatei, die Datenbankadressen für den Verbindungsaufbau mithilfe von Verbindungsaliasen definiert. | Existiert nicht | Cloud SQL for PostgreSQL akzeptiert externe Verbindungen über den Verbindungsnamen der Cloud SQL-Instanz oder die private/öffentliche IP-Adresse. Cloud SQL-Proxy ist eine weitere sichere Zugriffsmethode für die Verbindung mit Cloud SQL for PostgreSQL, ohne dass bestimmte IP-Adressen zugelassen werden müssen oder SSL konfiguriert werden muss. |
| Standardport der Instanz | 1521 | Standardport der Instanz | 5432 |
| Link zur Datenbank | Oracle-Schemaobjekte, die zur Interaktion mit lokalen/Remote-Datenbankobjekten verwendet werden können. | Foreign Data Wrapper (FDW) | Die Erweiterung postgres_fdw in Cloud SQL for PostgreSQL ermöglicht die Verwendung von Tabellen aus anderen PostgreSQL-Datenbanken, die in der aktuellen Datenbank als "fremde" Tabellen bereitgestellt werden. Diese Tabellen können dann beinahe genauso verwendet werden wie lokale Tabellen. |
Unterschiede in der Terminologie zwischen Oracle 12c und Cloud SQL for PostgreSQL
| Oracle 12c | Beschreibung | Cloud SQL for PostgreSQL | Wichtige Unterschiede |
|---|---|---|---|
| Instanz | Bei der mit Oracle 12c eingeführten Mehrmandantenfähigkeit kann eine Instanz mehrere Datenbanken als plug-in-fähige Datenbanken (PDBs) enthalten, im Gegensatz zu Oracle 11g, wo eine Oracle-Instanz eine einzelne Datenbank hosten kann. | Instanz | Eine Cloud SQL for PostgreSQL-Instanz enthält genau einen Datenbankcluster. Ein Datenbankcluster ist eine Sammlung von Datenbanken, die in einem gemeinsamen Datenbereich gespeichert sind. |
| CDB | Eine mehrmandantenfähige Containerdatenbank (CDB) kann ein oder mehrere PDBs unterstützen, während globale CDB-Objekte (betrifft alle PDBs) wie z. B. Rollen erstellt werden können. | PostgreSQL-Instanz | Die Cloud SQL for PostgreSQL-Instanz ist mit der Oracle-CDB vergleichbar. Beide stellen eine Systemebene für die gehosteten Datenbanken bereit. |
| PDB | PDBs (Plug-in-Datenbanken) können verwendet werden, um Dienste und Anwendungen voneinander zu isolieren und als mobile Sammlung von Schemas zu verwenden. | PostgreSQL-Datenbanken/ -Schemas |
Eine Cloud SQL for PostgreSQL-Datenbank kann mehrere Dienste und Anwendungen sowie viele Datenbanknutzer bereitstellen. |
| Sitzungssequenzen | Ab Oracle 12c können Sequenzen auf Sitzungsebene (zurückgegebene eindeutige Werte nur innerhalb einer Sitzung) oder auf globaler Ebene (z. B. bei Verwendung temporärer Tabellen) erstellt werden. | Temporäre Sequenz | Eine temporäre Sequenz wird für die aktuelle Datenbanksitzung erstellt und beim Beenden der Sitzung automatisch gelöscht. |
| Identitätsspalten | Der Oracle 12c-Typ IDENTITY generiert eine Sequenz und verknüpft sie mit einer Tabellenspalte, ohne dass manuell ein separates Sequenzobjekt erstellt werden muss. |
SERIELLE Spalte | Wenn Sie den Datentyp einer Spalte als SERIELL definieren, wird von Cloud SQL for PostgreSQL automatisch eine Sequenz erstellt. Der Spaltenwert wird anhand dieser Sequenz festgelegt, wenn neue Zeilen in die Tabelle eingefügt werden. |
| Sharding | Oracle Sharding ist eine Lösung, bei der eine Oracle-Datenbank in mehrere kleinere Datenbanken (Shards) partitioniert wird, um Skalierbarkeit, Verfügbarkeit und Geoverteilung für OLTP-Umgebungen zu ermöglichen. | Nicht unterstützt (als Funktion) | Cloud SQL for PostgreSQL hat keine gleichwertige Fragmentierungsfunktion. Fragmentierung kann mit Cloud SQL for PostgreSQL (als Datenplattform) mit einer unterstützenden Anwendungsschicht implementiert werden. |
| In-Memory-Datenbank | Oracle bietet eine Reihe von Features, die die Datenbankleistung für OLTP sowie für gemischte Arbeitslasten verbessern können. | Nicht unterstützt | In Cloud SQL for PostgreSQL ist kein entsprechendes Feature eingebunden. Sie können jedoch auch unseren verwalteten Redis-Dienst Memorystore verwenden. |
| Entfernen | Als Teil der erweiterten Sicherheitsfunktionen von Oracle kann das Entfernen eine Spaltenmaskierung durchführen, um zu verhindern, dass sensible Daten von Nutzern und Anwendungen abgerufen werden. | Nicht unterstützt | In Cloud SQL for PostgreSQL ist kein entsprechendes Feature eingebunden. Sie können jedoch mit Sensitive Data Protection sensible Daten de-identifizieren. |
Funktionen
Oracle 11g/12c- und Cloud SQL for PostgreSQL-Datenbanken basieren auf verschiedenen Architekturen (Infrastruktur und erweiterte prozedurale Sprachen), sie haben jedoch die gleichen grundlegenden Aspekte eines relationalen Datenbanksystems. Sie unterstützen Datenbankobjekte, Arbeitslasten mit mehreren gleichzeitigen Nutzern sowie Transaktionen mit ACID-Attributen. Außerdem verwalten sie Sperren mit mehreren Isolationsebenen (basierend auf den Anwendungsanforderungen) und stellen laufende Anwendungsanforderungen sowohl für OLTP-Vorgänge (Online Transactional Processing) als auch für Online Analytical Processing (OLAP) bereit.
Der folgende Abschnitt bietet einen Überblick über die wichtigsten funktionalen Unterschiede zwischen Oracle und Cloud SQL for PostgreSQL. In einigen Fällen, wo es notwendig ist, die Unterschiede hervorzuheben, enthält der Abschnitt detaillierte technische Vergleiche.
Vorhandene Datenbanken erstellen und anzeigen
| Oracle 11g/12c | Cloud SQL for PostgreSQL 12 |
|---|---|
Sie erstellen Datenbanken in der Regel mit dem Oracle-Dienstprogramm Database Creation Assistant (DBCA) und sehen sich vorhandene Datenbanken an. Bei manuell erstellten Datenbanken oder Instanzen müssen Sie zusätzliche Parameter angeben:SQL> CREATE DATABASE ORADB
|
Verwenden Sie eine Anweisung im Format CREATE DATABASE Name;, wie in diesem Beispiel:postgres=> CREATE DATABASE PGSQLDB;
|
| Oracle 12c | Cloud SQL for PostgreSQL 12 |
In Oracle 12c können Sie PDBs aus dem Startwert erstellen, entweder aus einer Containerdatenbankvorlage (CDB) oder durch Klonen eines PDB aus einem vorhandenen PDB. Sie verwenden mehrere Parameter:SQL> CREATE PLUGGABLE DATABASE PDB
|
Verwenden Sie eine Anweisung im Format CREATE DATABASE Name;, wie in diesem Beispiel:postgres=> CREATE DATABASE PGSQLDB;
|
Alle PDBs auflisten:SQL> SHOW is PDBS; |
Alle vorhandenen Datenbanken auflisten:postgres=> \list |
Verbindung zu einem anderen PDB herstellen:SQL> ALTER SESSION SET CONTAINER=pdb; |
Verbindung zu einer anderen Datenbank herstellen:postgres=> \connect databaseName;
Oder: postgres=> \c databaseName. |
Bestimmte PDB öffnen oder schließen (offen/schreibgeschützt):SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
Wird für eine einzelne Datenbank nicht unterstützt. Alle Datenbanken befinden sich unter derselben Cloud SQL for PostgreSQL-Instanz. Daher sind alle Datenbanken hoch- oder heruntergefahren. |
Datenbank über die Google Cloud Console verwalten
Gehen Sie in der Google Cloud Console zu Datenbanken> SQL> Instanz>(PostgreSQL-Instanz auswählen) > Datenbanken.
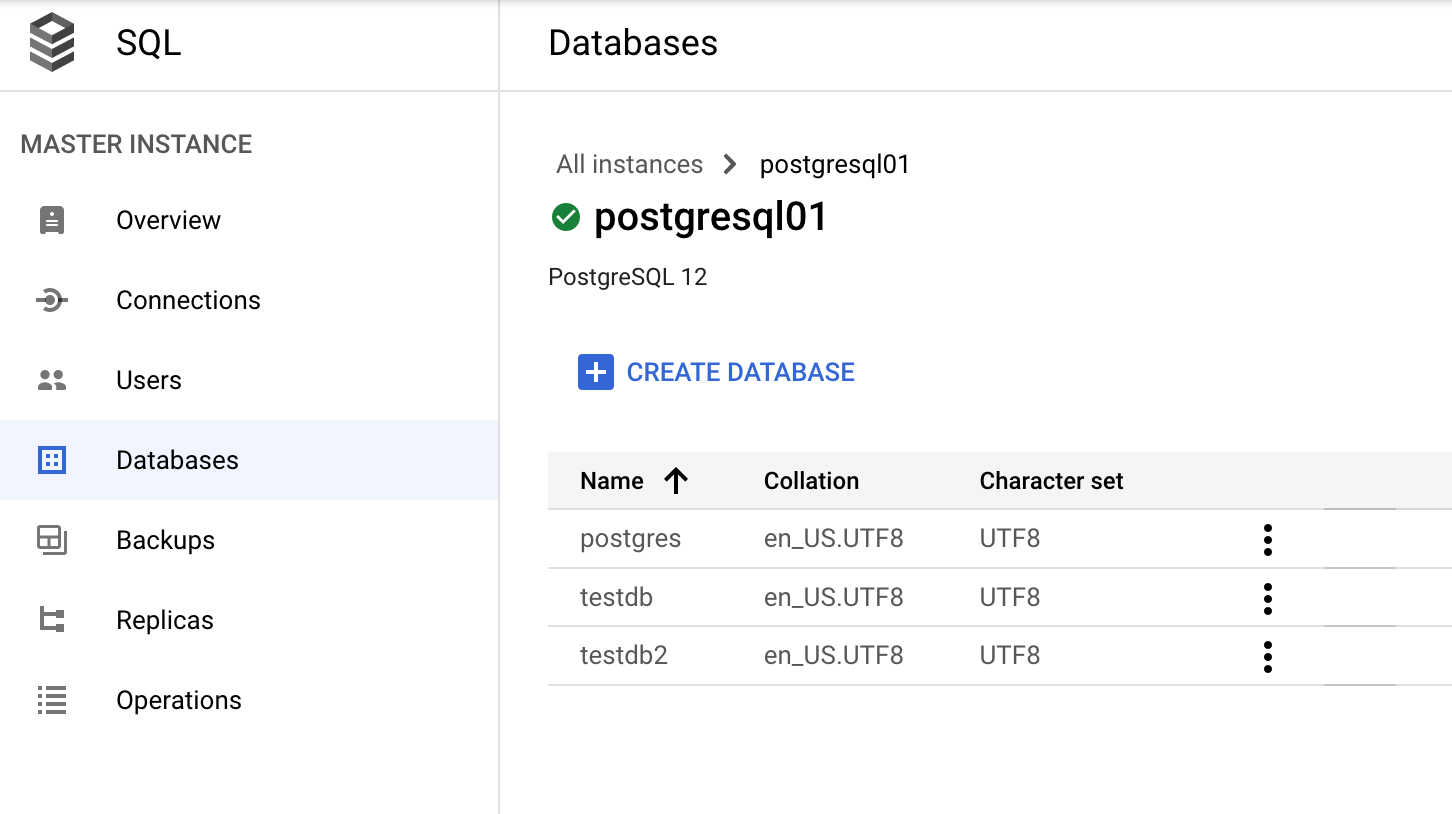
Datenwörterbuch und dynamische Ansichten
Oracle-Datenbanken bieten ein Datenwörterbuch sowie dynamische Leistungsansichten (V$-Ansichten), die eine Vielzahl von Aufgaben zur Datenbankpflege und -überwachung ermöglichen. Im Datenwörterbuch werden alle Informationen gespeichert, mit denen die Objekte in der Datenbank verwaltet werden. Dynamische Ansichten enthalten hingegen viele Informationen zur Leistung der Datenbank. Diese Ansichten werden kontinuierlich aktualisiert, während die Datenbank ausgeführt wird.
Im Gegensatz dazu bietet PostgreSQL mehrere Metadatenkataloge, die einen ähnlichen Zweck wie das Datenwörterbuch und die dynamischen Leistungsansichten von Oracle bieten:
- Systemkatalog: Metadaten zu allen Datenbankobjekten.
- Statistische Sammlungsansichten: Berichte zu den Aktivitäten von PostgreSQL.
- Informationsschemaansichten: Metadaten zu allen Datenbankobjekten, die gemäß dem ANSI SQL-Standard gemeldet werden.
Metadaten und dynamische Systemansichten ansehen
Dieser Abschnitt bietet einen Überblick über einige der am häufigsten verwendeten Metadatentabellen und dynamischen Systemansichten, die in Oracle verwendet werden, sowie die entsprechenden Datenbankobjekte in Cloud SQL for PostgreSQL Version 12.
Oracle stellt Hunderte von Systemmetadatentabellen und -ansichten bereit (in bestimmten Systemschemas, z. B. SYS oder SYSTEM), während PostgreSQL nur einige Dutzend bietet. Für jeden Fall kann es mehr als ein Datenbankobjekt geben, das einem bestimmten Zweck dient.
Oracle bietet mehrere Ebenen von Metadatenobjekten, die jeweils unterschiedliche Berechtigungen erfordern:
USER_TableName: für den Nutzer sichtbar.ALL_TableName: für alle Nutzer sichtbar.DBA_TableName: nur für Nutzer mit der DBA-Berechtigung wieSYSundSYSTEMsichtbar.
Für dynamische Leistungsansichten verwendet Oracle die V$/GV$-Präfixe. Die Metadaten und Ansichten von Cloud SQL for PostgreSQL befinden sich dagegen in den Schemas information_schema und pg_catalog.
| Metadatentyp | Oracle-Tabelle/-Ansicht | Tabelle/Ansicht/Abfrage für Cloud SQL for PostgreSQL |
|---|---|---|
| Offene Sitzungen | V$SESSION |
pg_catalog.pg_stat_activity |
| Transaktionen ausführen | V$TRANSACTION |
Nicht unterstützt. Als Problemumgehung stellt pg_locks eine Liste der offenen Transaktionen bereit, die eine oder mehrere Sperren enthalten. |
| Datenbankobjekte | DBA_OBJECTS |
pg_catalog.pg_class |
| Tabellen | DBA_TABLES |
pg_catalog.pg_tables |
| Tabellenspalten | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| Berechtigungen für Tabellen und Spalten | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| Partitionen | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| Aufrufe | DBA_VIEWS |
pg_catalog.pg_views |
| Einschränkungen | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| Indexe | DBA_INDEXES |
pg_catalog.pg_index |
| Materialisierte Ansichten | DBA_MVIEWS |
pg_catalog.pg_matviews |
| Gespeicherte Prozeduren | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Gespeicherte Funktionen | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Trigger | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| Nutzer | DBA_USERS |
pg_catalog.pg_user |
| Nutzerberechtigungen | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| Jobs/ Planer |
DBA_JOBS |
Nicht unterstützt. |
| Tablespaces | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| Datendateien | DBA_DATA_FILES |
Nicht unterstützt. |
| Synonyme | DBA_SYNONYMS |
Nicht unterstützt. |
| Sequenzen | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| Datenbank-Links | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| Statistiken | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| Locks | DBA_LOCK |
pg_catalog.pg_locks |
| Datenbankparameter | V$PARAMETER |
pg_catalog.pg_settings
show |
| Segmente | DBA_SEGMENTS |
Nicht unterstützt. |
| Rollen | DBA_ROLES |
pg_catalog.pg_roles |
| Sitzungsverlauf | V$ACTIVE_SESSION_HISTORY |
Nicht unterstützt. |
| Version | V$VERSION |
select version(); |
| Warteereignisse | V$WAITCLASSMETRIC |
Nicht unterstützt. |
| SQL-Abstimmung und Analyse |
V$SQL |
Nicht unterstützt. |
| Instanz Arbeitsspeicheroptimierung |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
Nicht in Cloud SQL for PostgreSQL eingebunden. Verwenden Sie die Erweiterung pg_buffercache, um den freigegebenen Zwischenspeichercache in Echtzeit zu untersuchen. |
Systemparameter
Sowohl Oracle- als auch Cloud SQL for PostgreSQL-Datenbanken können speziell konfiguriert werden, um bestimmte Funktionen über die Standardkonfiguration hinaus zu erreichen. Zum Ändern von Konfigurationsparametern in Oracle sind bestimmte Administratorberechtigungen erforderlich (vor allem die SYS/SYSTEM-Nutzerberechtigungen).
Das folgende Beispiel zeigt die Änderung der Oracle-Konfiguration mithilfe der Anweisung ALTER SYSTEM. In diesem Beispiel ändert der Nutzer den Parameter "Maximale Anzahl fehlgeschlagener Anmeldeversuche" nur auf der Konfigurationsebene spfile (die Änderung gilt erst nach einem Neustart):
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
Im nächsten Beispiel möchte der Nutzer einfach den Oracle-Parameterwert anzeigen:
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
Die Ausgabe sieht etwa so aus:
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
Die Änderung des Oracle-Parameters funktioniert in drei Bereichen:
- SPFILE: Parameteränderungen werden in das Oracle-
spfilegeschrieben, wobei ein Neustart der Instanz erforderlich ist, damit der Parameter wirksam wird. - SPEICHER: Parameteränderungen werden in der Speicherebene nur angewendet, wenn keine statischen Parameteränderungen zulässig sind.
- BEIDE: Parameteränderungen werden sowohl in der Serverparameterdatei als auch im Instanzspeicher angewendet, wobei statische Parameteränderungen nicht zulässig sind.
Cloud SQL for PostgreSQL-Konfigurations-Flags
Sie können die Systemparameter von Cloud SQL for PostgreSQL mithilfe der Konfigurations-Flags in der Google Cloud Console, der gcloud CLI oder CURL ändern. Sehen Sie sich die vollständige Liste aller Parameter an, die von Cloud SQL for PostgreSQL unterstützt werden und die Sie ändern können.
PostgreSQL-Parameter können in mehrere Bereiche unterteilt werden:
- Dynamische Parameter: Können während der Laufzeit geändert werden.
- Datenbankparameter: Gilt nur für eine bestimmte Datenbank innerhalb einer PostgreSQL-Instanz.
- Rollenparameter: Gelten nur für eine bestimmte Datenbankrolle.
- Statische Parameter: Damit die Instanz wirksam wird, muss sie neu gestartet werden.
- Sitzungsparameter: Können auf Sitzungsebene nur für die aktuelle Sitzungsdauer geändert werden, getrennt von anderen Sitzungen.
- Globale Parameter: Wirkt sich global auf alle aktuellen und zukünftigen Sitzungen aus.
Beispiele für das Ändern von Cloud SQL for PostgreSQL-Parametern
Console
Verwenden Sie die Google Cloud Console, um den Parameter log_connections zu aktivieren.
Rufen Sie in Cloud Storage die Seite Instanz bearbeiten auf.
Klicken Sie unter Flags auf Element hinzufügen und suchen Sie wie im folgenden Screenshot nach
log_connections.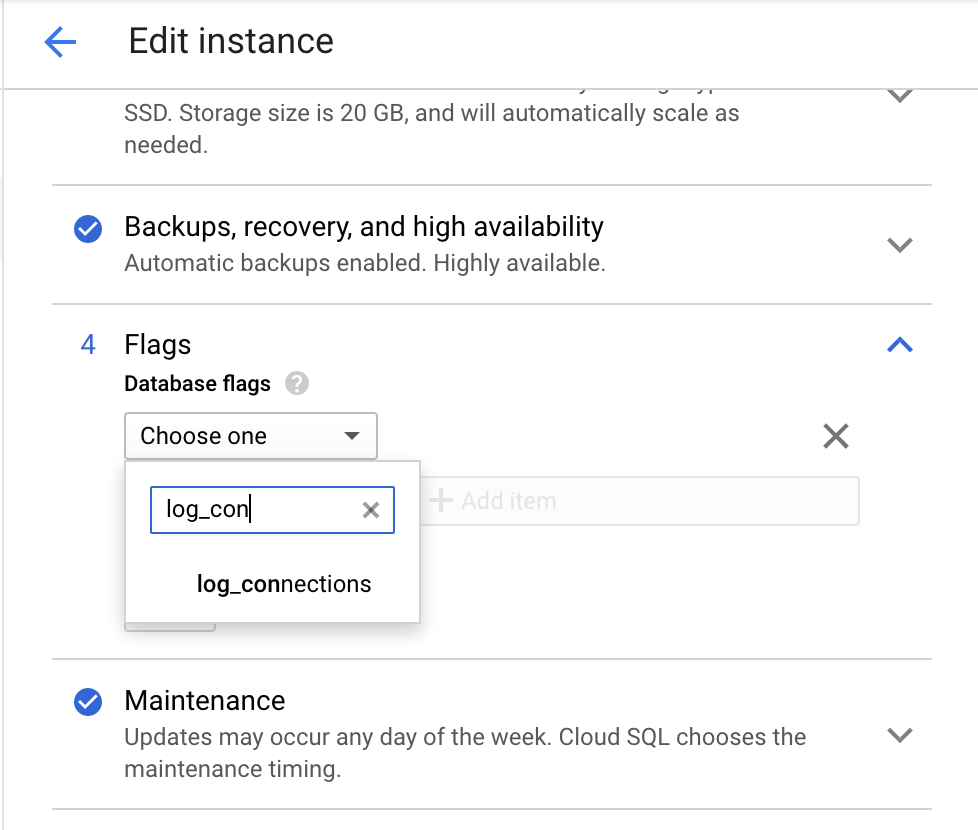
gcloud
- Verwenden Sie die gcloud CLI, um den Parameter
log_connectionszu aktivieren:
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
Die Ausgabe sieht so aus:
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL for PostgreSQL
Legen Sie auf Sitzungsebene timezone fest. Diese Änderung gilt für die aktuelle Sitzung und gilt nur für die gesamte Lebensdauer der Sitzung.
timezone-Konfigurationsparameter anzeigen:postgres=> SHOW timezone;Sie sehen die folgende Ausgabe, wobei
timezoneset to UTCist:TimeZone ---------- UTC (1 row)
Legen Sie
timezoneauf UTC-9 fest:postgres=> SET timezone='UTC-9';timezone-Konfigurationsparameter anzeigen:postgres> SHOW timezone;Sie sehen die folgende Ausgabe, wobei für
timezoneder WertUTC-9festgelegt ist:TimeZone ---------- UTC-9 (1 row)
Transaktionen und Isolationsebenen
In diesem Abschnitt werden die Hauptunterschiede bei der Transaktionsausführung und den Isolationsebenen zwischen Oracle und Cloud SQL for PostgreSQL beschrieben.
Commit-Modus
Oracle funktioniert standardmäßig im Nicht-Autocommit-Modus, in dem jede DML-Transaktion mit COMMIT/ROLLBACK-Anweisungen bestimmt werden muss. Einer der Hauptunterschiede zwischen Oracle und PostgreSQL ist, dass PostgreSQL implizit einen COMMIT nach jedem Befehl durchführt, der nicht START TRANSACTION (oder BEGIN) entspricht. Dies wird bei einigen anderen Datenbanken auch als "Autocommit" bezeichnet.
Obwohl Autocommit standardmäßig aktiviert ist, können Sie es mit SET AUTOCOMMIT OFF auf Sitzungsebene deaktivieren.
Isolationsebenen
Der ANSI/ISO-SQL-Standard (SQL:92) definiert vier Isolationsebenen. Jede Ebene bietet einen anderen Ansatz für die gleichzeitige Ausführung von Datenbanktransaktionen:
- Lesevorgang ohne Commit: Eine aktuell verarbeitete Transaktion kann nicht festgelegte Daten der anderen Transaktion sehen. Wenn ein Rollback durchgeführt wird, werden alle Daten auf ihren vorherigen Zustand zurückgesetzt.
- Lesevorgang mit Commit: Eine Transaktion sieht nur Datenänderungen, für die ein Commit durchgeführt wurde. Nicht festgeschriebene Änderungen ("fehlerhafte Lesevorgänge") sind nicht möglich.
- Wiederholbarer Lesevorgang: Eine Transaktion kann Änderungen, die von der anderen Transaktion vorgenommen wurden, erst dann ansehen, wenn beide Transaktionen einen
COMMITausgegeben haben oder wenn für beide ein Rollback durchgeführt wurde. - Serialisierbar: Die strengste/stärkste Isolationsebene. Diese Ebene wird für alle Datensätze gesperrt, auf die zugegriffen wird, und sperrt die Ressource, sodass keine Datensätze an die Tabelle angehängt werden können.
Transaktionsisolationsebenen verwalten die Sichtbarkeit von geänderten Daten für andere ausgeführte Transaktionen. Wenn mehrere Transaktionen gleichzeitig auf dieselben Daten zugreifen, wirkt sich die ausgewählte Transaktionsisolationebene auf die Interaktion verschiedener Transaktionen aus.
Oracle unterstützt die folgenden Isolationsebenen:
- Lesevorgang mit Commit (Standard)
- Serializable
- Schreibgeschützt (nicht Teil des ANSI/ISO-SQL-Standards (SQL:92)
Oracle MVCC (Multiversion-Gleichzeitigkeitserkennung):
- Oracle verwendet den MVCC-Mechanismus, um eine automatische Lesekonsistenz für die gesamte Datenbank und alle Sitzungen bereitzustellen.
- Oracle verwendet die System Change Number (SCN) der aktuellen Transaktion, um eine konsistente Ansicht der Datenbank zu erhalten. Daher geben alle Datenbankabfragen nur Daten zurück, für die zum Zeitpunkt der Abfrageausführung in Bezug auf das SCN ein Commit durchgeführt wurde.
- Die Isolationsebenen können auf Transaktions- und Sitzungsebene geändert werden.
Hier ein Beispiel für das Festlegen von Isolationsebenen:
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
Cloud SQL for PostgreSQL unterstützt die folgenden vier Transaktionsisolationsebenen, die im Standard ANSI SQL:92 angegeben werden:
- Lesevorgang ohne Commit (entspricht "Lesevorgang mit Commit")
- Lesevorgang mit Commit (Standard)
- Wiederholbarer Lesevorgang
- Serializable
Die standardmäßige Isolationsebene von Cloud SQL for PostgreSQL ist READ COMMITTED.
Diese Isolationsebenen können auf SESSION-, TRANSACTION- und INSTANCE-Ebene geändert werden.
Verwenden Sie die folgende Anweisung, um die aktuellen Isolationsebenen sowohl auf TRANSACTION- als auch auf SESSION- Ebene zu prüfen:
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
Die Ausgabe sieht so aus:
current_setting ----------------- read committed (1 row)
Sie können die Syntax der Isolationsebene so ändern:
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
Und Sie können die Isolationsebene auf SESSION-Ebene ändern:
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
Die Ausgabe sieht so aus:
current_setting ----------------- repeatable read (1 row)
Die Isolationsebene auf INSTANCE-Ebenen wird mit dem Datenbank-Flag
default_transaction_isolation gesteuert. Sie können dies anhand der folgenden Anweisung überprüfen:
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
Die Ausgabe sieht so aus:
default_transaction_isolation ------------------------------- repeatable read (1 row)
Nächste Schritte
- Mehr über Cloud SQL for PostgreSQL-Nutzerkonten erfahren.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center