Este documento faz parte de uma série que fornece informações importantes e orientações relacionadas ao planejamento e à realização de migrações de banco de dados Oracle® 11g/12c para o Cloud SQL para PostgreSQL versão 12. Além da parte de configuração introdutória, a série inclui as seguintes partes:
- Como migrar usuários do Oracle para o Cloud SQL para PostgreSQL: terminologia e funcionalidade (este documento)
- Como migrar usuários do Oracle para o Cloud SQL para PostgreSQL: tipos de dados, usuários e tabelas
- Como migrar usuários do Oracle para o Cloud SQL para PostgreSQL: consultas, procedimentos armazenados, funções e gatilhos
- Como migrar usuários da Oracle para o Cloud SQL para MySQL: segurança, operações, monitoramento e geração de registros
- Como migrar usuários e esquemas do banco de dados da Oracle para o Cloud SQL para PostgreSQL
Terminologia
Nesta seção, detalhamos as semelhanças e diferenças de terminologia de banco de dados entre o Oracle e o Cloud SQL para PostgreSQL. Analisamos e comparamos os principais aspectos de cada plataforma de banco de dados. A comparação distingue as versões 11g e 12c do Oracle devido a diferenças de arquitetura (por exemplo, o Oracle 12c introduz o recurso multilocatário). O Cloud SQL para PostgreSQL mencionado aqui é a versão 12.
Nesta seção, são enfatizadas as principais diferenças de terminologia entre Oracle e Cloud SQL para PostgreSQL. Uma descrição de nível inferior é detalhada posteriormente neste documento.
| Oracle 11g | Descrição | Cloud SQL para PostgreSQL | Principais diferenças |
|---|---|---|---|
| instance | Uma única instância do Oracle 11g pode conter apenas um banco de dados. | instance | Uma instância do Cloud SQL para PostgreSQL contém exatamente um cluster de banco de dados. Um cluster de banco de dados é um conjunto de bancos de dados armazenado em uma área de dados comum. |
| database | Um banco de dados se qualifica como instância única (o nome do banco de dados é idêntico ao nome da instância). | database | Bancos de dados múltiplos ou únicos atendem a vários aplicativos. |
| schema | O esquema e os usuários são idênticos porque ambos são considerados proprietários de objetos de banco de dados (um usuário pode ser criado sem especificar ou ser alocado para um esquema). | schema | Um banco de dados contém um ou mais esquemas. Objetos como tabelas estão contidos em esquemas. O mesmo nome de objeto pode ser usado em diferentes esquemas dentro do mesmo banco de dados, sem conflito. |
| user | Idêntico ao esquema porque ambos são proprietários de objetos de banco de dados. Por exemplo, instância → banco de dados → esquemas/usuários → objetos de banco de dados. | role | Um papel pode ser um usuário do banco de dados ou um grupo de usuários do banco de dados, dependendo da configuração dele. Ele pode ter objetos de banco de dados como tabelas.
Os papéis têm escopo de todo um cluster de banco de dados, e é possível conceder a função de um papel a outro. |
| role | Conjunto definido de permissões de banco de dados que podem ser encadeadas como um grupo e atribuídas a usuários de banco de dados. | ||
| usuários administradores/ do sistema |
Usuários administradores do Oracle com o nível mais alto de acesso:SYS
|
cloudsqlsuperuser | O Cloud SQL para PostgreSQL vem com o usuário postgres padrão. Esse usuário faz parte do papel cloudsqlsuperuser e tem os seguintes atributos (privilégios): CREATEROLE, CREATEDB e LOGIN. Como o Cloud SQL para PostgreSQL é um serviço gerenciado, ele restringe o acesso a determinados procedimentos e tabelas do sistema que exigem privilégios avançados. Portanto, o usuário postgres não tem os atributos SUPERUSER ou REPLICATION. Não é possível criar ou ter acesso a usuários com atributos superuser. |
| dicionário/ metadados |
O Oracle usa as tabelas de metadados a seguir:USER_TableName
|
dicionário/ metadados |
O Cloud SQL para PostgreSQL usa o INFORMATION_SCHEMA padrão ANSI para fornecer informações de dicionário e metadados. |
| visualizações dinâmicas do sistema | Visualizações dinâmicas do Oracle:V$ViewName |
visualizações dinâmicas do sistema |
O Cloud SQL para PostgreSQL tem as seguintes visualizações de estatísticas dinâmicas:pg_stat_ViewNamepg_statio_ViewName |
| tablespace | As principais estruturas de armazenamento lógico dos bancos de dados Oracle. Cada tablespace pode conter um ou mais arquivos de dados. | tablespace | No Cloud SQL para PostgreSQL, os arquivos de dados são armazenados juntos no diretório de dados de um cluster de banco de dados PGDATA usando uma estrutura de diretório predefinida. Os tablespaces no Cloud SQL para PostgreSQL fornecem um mecanismo para definir locais personalizados no sistema de arquivos em que os arquivos de dados podem ser armazenados.Como o Cloud SQL para PostgreSQL é um serviço gerenciado, o Google Cloud gerencia para você o sistema de arquivos subjacente da máquina host. Não é possível criar novos tablespaces no Cloud SQL para PostgreSQL. |
| arquivos de dados | Os elementos físicos de um banco de dados Oracle que armazenam os dados e são definidos em um tablespace específico. Um único arquivo de dados é definido pelos tamanhos inicial e máximo, podendo conter dados de várias tabelas. Arquivos de dados Oracle usam o sufixo .dbf (não obrigatório). |
arquivos de dados | O Cloud SQL para PostgreSQL armazena cada banco de dados em um cluster de banco de dados no próprio subdiretório. Cada tabela e índice dentro de um banco de dados é armazenada em um arquivo separado nesse subdiretório. |
| tablespace do sistema | Contém as tabelas do dicionário de dados e exibe objetos de todo o banco de dados Oracle. | não existe | Tabelas de dicionário de dados e objetos de visualizações são armazenados em INFORMATION_SCHEMA no diretório de dados de um cluster de banco de dados PGDATA usando uma estrutura de diretórios predefinida. |
| tablespace temporário | Contém objetos de esquema válidos durante a sessão. Além disso, acomoda a execução de operações que não cabem na memória do servidor. |
arquivos temporários | Os arquivos temporários são usados para armazenar operações em execução que não cabem na memória do servidor. Esses arquivos são armazenados em um diretório chamado pgsql_tmp e são criados apenas enquanto a instrução SQL está em execução. |
| tablespace Undo | Um tipo especial de tablespace permanente do sistema usado pelo Oracle para gerenciar operações de reversão ao executar o banco de dados no modo de gerenciamento desfazer automaticamente (padrão). |
não existe | Para permitir operações de reversão, o Cloud SQL para PostgreSQL retém as linhas que são atualizadas ou excluídas no próprio arquivo de dados da tabela. O comando vaccum é o processo de recuperar ou reutilizar o espaço em disco ocupada por linhas atualizadas ou excluídas. |
| ASM | O Gerenciamento automático de armazenamento do Oracle é um sistema de arquivos de banco de dados integrado de alto desempenho e gerenciador de disco executado automaticamente por um banco de dados Oracle configurado com ASM. | incompatível | O Cloud SQL para PostgreSQL depende do sistema de arquivos do SO para armazenar arquivos de dados e não tem um equivalente Oracle ASM. O Cloud SQL para PostgreSQL é compatível com muitos recursos para automação de armazenamento, como aumentos automáticos, desempenho e escalonabilidade. |
| tabelas/visualizações | Objetos de banco de dados fundamentais criados pelo usuário. | tabelas/visualizações | Recurso idêntico ao do Oracle. |
| visualizações materializadas | Definidas com instruções SQL específicas, podendo ser atualizadas de forma manual ou automática com base em configurações específicas. |
visualizações materializadas | As visualizações materializadas funcionam de maneira semelhante ao Oracle. Elas são atualizadas manualmente usando instruções REFRESH
MATERIALIZED VIEW. |
| sequência | Gerador de valor exclusivo do Oracle. | sequência | Semelhante ao Oracle. |
| sinônimo | Objetos de banco de dados Oracle que funcionam como identificadores alternativos de outros objetos de banco de dados. | incompatível | O Cloud SQL para PostgreSQL não oferece sinônimos. Como solução alternativa, use visualizações ao definir as permissões apropriadas. |
| particionamento | O Oracle fornece muitas soluções de particionamento para dividir tabelas grandes em partes gerenciadas menores. | particionamento | O Cloud SQL para PostgreSQL é compatível com o particionamento declarativo do estilo Oracle e com o particionamento usando herança. Isso permite mais flexibilidade de particionamento. |
| banco de dados flashback | Recurso reservado do Oracle que pode ser usado para inicializar um banco de dados Oracle em um horário predefinido, permitindo consultar ou restaurar dados que foram modificados ou corrompidos por engano. | incompatível | Como solução alternativa, use os backups e a recuperação pontual do Cloud SQL para restaurar um banco de dados a um estado anterior (por exemplo, restaurar antes de uma queda de tabela). |
| sqlplus | Interface de linha de comando do Oracle que permite consultar e gerenciar a instância do banco de dados. | psql | Cloud SQL para PostgreSQL: equivalente da interface de linha de comando para consultar e gerenciar. Pode ser conectado de qualquer cliente com as devidas permissões ao Cloud SQL. |
| PL/SQL | Linguagem de procedimentos estendida para ANSI SQL. | PL/pgSQL | O Cloud SQL para PostgreSQL tem sua própria linguagem processual chamada PL/pgSQL, que é semelhante ao PL/SQL da Oracle em muitos aspectos. Para ver um resumo das principais diferenças entre as duas linguagens, consulte Portabilidade do Oracle PL/SQL. |
| pacote e corpo do pacote | Funcionalidade específica do Oracle para agrupar procedimentos e funções armazenados na mesma referência lógica. | Sem suporte | O Cloud SQL para PostgreSQL organiza funções usando esquemas. |
| funções e procedimentos armazenados | Usa PL/SQL para implementar a funcionalidade de código. | funções e procedimentos armazenados | O Cloud SQL para PostgreSQL é compatível com a implementação de procedimentos e funções armazenados usando várias linguagens de programação, como PL/pgSQL e C. |
| gatilho | Objeto Oracle usado para controlar a implementação de DML em tabelas. | gatilho | Semelhante ao Oracle. |
| PFILE/SPFILE | Os parâmetros em nível de instância e banco de dados do Oracle são mantidos em um arquivo binário conhecido como SPFILE (nas versões anteriores, o arquivo era chamado PFILE), que pode ser usado como arquivo de texto para definir parâmetros manualmente. |
Sinalizações do banco de dados do Cloud SQL para PostgreSQL | Defina ou modifique parâmetros do Cloud SQL para PostgreSQL por meio do utilitário sinalizações do banco de dados. |
| SGA/PGA/ AMM |
Parâmetros de memória do Oracle que controlam a alocação de memória para a instância de banco de dados. | Variedade de parâmetros relacionados à memória | O Cloud SQL para PostgreSQL tem seus próprios parâmetros de memória. Alguns parâmetros semelhantes são shared_buffers, temp_buffers e work_mem. No Cloud SQL para PostgreSQL, esses parâmetros são predefinidos pelo tipo de instância escolhido e o valor é alterado de acordo. É possível ajustar alguns desses parâmetros usando o utilitário de sinalizações do banco de dados. |
| cache de buffer | Reduz as operações de E/S do SQL recuperando dados armazenados em cache de buffer. Os parâmetros de memória podem ser gerenciados no nível do banco de dados e no nível da sessão por meio de dicas de consulta. | Funcionalidade semelhante | O tamanho do cache de buffer do Cloud SQL para PostgreSQL é controlado pelo parâmetro shared_buffer, que não é exposto no Cloud SQL. O Cloud SQL fornece uma métrica de uso de memória, que é usada para dimensionar a instância. |
| dicas de banco de dados | Capacidade do Oracle de oferecer impacto controlado às instruções SQL que influenciarão o comportamento do otimizador para ter melhor desempenho. O Oracle tem mais de 50 dicas de banco de dados. | incompatível | O Cloud SQL para PostgreSQL não é compatível com dicas de banco de dados. A um nível limitado, é possível controlar o planejador de consultas do Cloud SQL para PostgreSQL usando a sintaxe JOIN explícita. |
| RMAN | Utilitário Recovery Manager do Oracle. Usado para fazer backups de banco de dados com funcionalidade estendida visando a compatibilidade com vários cenários de recuperação de desastres e muito mais (clonagem etc.). | Backup do Cloud SQL para PostgreSQL | O Cloud SQL para PostgreSQL oferece dois métodos para aplicar backups completos: backups sob demanda e automatizados. |
| Data Pump (EXPDP/ IMPDP) |
Utilitário de geração de despejo do Oracle que pode ser usado para muitos recursos, como exportação/importação, backup de banco de dados (em nível de esquema ou objeto), metadados de esquema, geração de arquivos SQL de esquema e muito mais. | Exportação/importação do Cloud SQL para PostgreSQL | O Cloud SQL para PostgreSQL oferece dois formatos de exportação/importação para e de buckets do Cloud Storage: SQL e CSV. Se preferir, conecte-se à instância do banco de dados usando utilitários de exportação/importação, como pg_dump. |
| SQL*Loader | Ferramenta que permite fazer upload de dados de arquivos externos, como arquivos de texto, arquivos CSV etc. | psql \copy |
O comando \copy no cliente psql permite carregar arquivos de texto, CSV ou binários (o Oracle é compatível com outros formatos de arquivo) em uma tabela de banco de dados com uma estrutura correspondente. |
| Data Guard | Solução de recuperação de desastres do Oracle que usa uma instância de espera, permitindo que os usuários executem operações READ da instância de espera. |
Alta disponibilidade e replicação do Cloud SQL para PostgreSQL | Para conseguir recuperação de desastres ou alta disponibilidade, o Cloud SQL para PostgreSQL oferece a réplica de failover arquitetura e para operações somente leitura (separação READ/WRITE) usando a réplica de leitura. |
| Active Data Guard/ GoldenGate |
As principais soluções de replicação do Oracle, que podem atender a várias finalidades, como espera (DR), instância somente leitura, replicação bidirecional (vários mestres), armazenamento de dados e muito mais. | Réplica de leitura do Cloud SQL para PostgreSQL | Réplica de leitura do Cloud SQL para PostgreSQL para implementar clustering com separação READ/WRITE. No momento, não há compatibilidade com a configuração de vários mestres, como replicação bidirecional do GoldenGate ou replicação heterogênea. |
| RAC | Oracle Real Application Cluster. Solução de clustering proprietária da Oracle para fornecer alta disponibilidade implantando várias instâncias de banco de dados em uma única unidade de armazenamento. | incompatível | O Cloud SQL para PostgreSQL não é compatível com uma arquitetura de vários mestres. O Cloud SQL para PostgreSQL oferece alta disponibilidade por meio de uma instância de espera e aumento da escalonabilidade de leitura por meio de réplicas de leitura. |
| Grid/Cloud Control (OEM) | Software Oracle para gerenciar e monitorar bancos de dados e outros serviços relacionados em um formato de aplicativo da Web. Esta ferramenta é útil para análise de banco de dados em tempo real para entender cargas de trabalho altas. | Console do Google Cloud, Cloud Monitoring |
Use o Cloud SQL para PostgreSQL para monitoramento, incluindo gráficos detalhados com base em tempo e recursos. Use também o Cloud Monitoring para armazenar métricas de monitoramento específicas do Cloud SQL para PostgreSQL e a análise de registros para recursos de monitoramento avançados. |
| registros REDO | Registros de transações do Oracle que consistem em dois (ou mais) arquivos definidos pré-alocados para armazenar todas as modificações de dados à medida que ocorrem. A finalidade principal do redo log é proteger o banco de dados em caso de falha da instância. | Registros WAL | O Cloud SQL para PostgreSQL usa o Write-Ahead Logging (WAL) para que as alterações nos arquivos de dados sejam removidas para armazenamento permanente para permitir a recuperação de falhas. |
| registros Archive | Os registros Archive são compatíveis com operações de backup e replicação e muito mais. O Oracle grava em registros Archive (se ativados) após cada operação de chave de redo log. | Arquivamento de WAL | Implementação do Cloud SQL para PostgreSQL da retenção de registros WAL. O arquivamento de WAL é usado e ativado com a recuperação pontual. |
| arquivo de controle | O arquivo de controle do Oracle contém informações sobre o banco de dados, como arquivos de dados, nomes de registros redo e locais, o número sequencial do registro atual e informações sobre o checkpoint da instância. | PGDATA and pg_control
|
A arquitetura do Cloud SQL para PostgreSQL não compartilha um conceito equivalente a um arquivo de controle do Oracle. Os arquivos relacionados ao banco de dados são organizados em um diretório comumente chamado de PGDATA. As informações WAL relacionadas a registros e checkpoints são armazenadas em pg_control. |
| Número de alteração do sistema (SCN, na sigla em inglês) | O SCN marca um ponto específico no tempo de um banco de dados Oracle. | Número de sequência do registro (LSN, na sigla em inglês) | O Cloud SQL para PostgreSQL equivalente é o LSN. Assim como SCNs, os NSNs aumentam monotonicamente ao longo do tempo. |
| AWR | O repositório automático de carga de trabalho (AWR, na sigla em inglês) do Oracle é um relatório detalhado que fornece informações detalhadas sobre o desempenho da instância do banco de dados Oracle, sendo considerado uma ferramenta de DBA para diagnósticos de desempenho. | coletor de estatísticas | O Cloud SQL para PostgreSQL não tem um relatório equivalente ao Oracle AWR, mas o PostgreSQL reúne dados de desempenho coletados pelo coletor de estatísticas. As estatísticas coletadas são expostas por meio de visualizações pg_stat_* e pg_statio_*. |
DBMS_SCHEDULER
|
Utilitário do Oracle usado para definir e cronometrar operações predefinidas. | incompatível | O Cloud SQL para PostgreSQL não fornece um utilitário de programação integrado. O Google Cloud oferece o Cloud Scheduler, que permite programar tarefas de banco de dados, como exportações. |
| criptografia de dados transparente | Criptografa dados armazenados em discos como proteção de dados em repouso. | padrão de criptografia avançada do Cloud SQL | O Cloud SQL para PostgreSQL usa o Padrão de criptografia avançada de 256 bits (AES-256, na sigla em inglês) para proteger dados em repouso e em trânsito. |
| compactação avançada | Para melhorar o tamanho do armazenamento do banco de dados, reduzir os custos de armazenamento e melhorar o desempenho do banco de dados, o Oracle fornece recursos avançados de compactação de dados (tabelas/índices). | TOAST | Embora não seja diretamente comparável à compactação avançada do Oracle, o Cloud SQL para PostgreSQL usa uma infraestrutura chamada TOAST para compactar de maneira automática e transparente os dados de tamanho variável que são muito grandes para caber em uma única página de dados. |
| SQL Developer | GUI de SQL gratuita da Oracle para gerenciar e executar instruções SQL e PL/SQL. | pgAdmin | GUI de SQL gratuita do Cloud SQL para PostgreSQL para gerenciar e executar instruções de código SQL e PostgreSQL. |
| Registro de alertas | Registro principal do Oracle para operações e erros gerais do banco de dados. | Relatórios e geração de registros de erros do PostgreSQL | Use o Visualizador de registros do Cloud Logging para inspecionar os registros de erro do PostgreSQL. |
| tabela DUAL | Tabela especial do Oracle para recuperar valores de pseudocoluna, como SYSDATE ou USER. |
não existe | O Cloud SQL para PostgreSQL permite que as cláusulas FROM sejam omitidas das instruções SQL. Por exemplo:SELECT NOW();
é uma instrução válida no PostgreSQL. |
| tabela externa | O Oracle permite que os usuários criem tabelas externas com os dados de origem em arquivos fora do banco de dados. | incompatível | Por ser um serviço gerenciado, o Cloud SQL para PostgreSQL não expõe o sistema de arquivos subjacente do host que executa a instância do banco de dados. Como solução alternativa, é possível importar os dados de origem para uma tabela do PostgreSQL para consultá-los. |
| Listener | Processo de rede do Oracle com a tarefa de escutar conexões de banco de dados recebidas. | redes autorizadas do Cloud SQL | O Cloud SQL para PostgreSQL aceita conexões de origens remotas quando permitido na página de configuração das redes autorizadas do Cloud SQL. |
| TNSNAMES | Arquivo de configuração de rede do Oracle que define endereços de banco de dados para estabelecer conexões usando aliases de conexão. | não existe | O Cloud SQL para PostgreSQL aceita conexões externas com o nome da conexão de instância do Cloud SQL ou o endereço IP particular/público. O Cloud SQL Proxy é um método de acesso seguro adicional para se conectar ao Cloud SQL para PostgreSQL sem ter que permitir endereços IP específicos ou configurar SSL. |
| porta padrão da instância | 1521 | porta padrão da instância | 5432 |
| link do banco de dados | Objetos de esquema do Oracle que podem ser usados para interagir com objetos de banco de dados locais/remotos. | Foreign Data Wrapper (FDW) | A extensão postgres_fdw no Cloud SQL para PostgreSQL permite que tabelas de outros bancos de dados PostgreSQL ("estrangeiras") sejam expostas como tabelas "estrangeiras" no banco de dados atual. Essas tabelas estão disponíveis para uso, quase como se fossem tabelas locais. |
Diferenças de terminologia entre o Oracle 12c e o Cloud SQL para PostgreSQL
| Oracle 12c | Descrição | Cloud SQL para PostgreSQL | Principais diferenças |
|---|---|---|---|
| instância | A capacidade de vários locatários introduzida no Oracle 12c permite que uma instância mantenha vários bancos de dados como bancos de dados conectáveis (PDBs, na sigla em inglês), ao contrário do Oracle 11g, em que uma instância do Oracle pode hospedar um único banco de dados. | instância | Uma instância do Cloud SQL para PostgreSQL contém exatamente um cluster de banco de dados. Um cluster de banco de dados é um conjunto de bancos de dados armazenado em uma área de dados comum. |
| CDB | Um banco de dados de contêiner de vários locatários (CDB, na sigla em inglês) é compatível com um ou mais PDBs, sendo possível criar objetos globais de CDB (o que afeta todos os PDBs), como papéis. | Instância do PostgreSQL | A instância do Cloud SQL para PostgreSQL é comparável ao Oracle CDB. Ambos fornecem uma camada de sistema para os bancos de dados hospedados. |
| PDB | É possível usar os bancos de dados plugáveis (PDBs) para isolar serviços de aplicativos e como uma coleção portátil de esquemas. | Bancos de dados PostgreSQL/ esquemas |
Um banco de dados do Cloud SQL para PostgreSQL pode exibir vários serviços e aplicativos, bem como muitos usuários de banco de dados. |
| sequências de sessão | Com o Oracle 12c, é possível criar sequências no nível da sessão (retornam valores exclusivos somente dentro de uma sessão) ou no nível global (por exemplo, ao usar tabelas temporárias). | Sequência temporária | A sequência temporária é criada para a sessão atual do banco de dados e é automaticamente descartada ao sair da sessão. |
| colunas de identidade | O tipo IDENTITY do Oracle 12c gera uma sequência e a associa a uma coluna de tabela sem a necessidade de criar manualmente um outro objeto de sequência. |
Coluna SERIAL | Quando você define o tipo de dados de uma coluna como SERIAL, o Cloud SQL para PostgreSQL cria automaticamente uma sequência e preenche o valor da coluna usando essa sequência quando novas linhas são inseridas na tabela. |
| fragmentação | A fragmentação do Oracle é uma solução em que um banco de dados Oracle é particionado em vários bancos de dados menores (fragmentos) para permitir escalonabilidade, disponibilidade e distribuição geográfica para ambientes OLTP. | incompatível (como recurso) | O Cloud SQL para PostgreSQL não tem um recurso de fragmentação equivalente. A fragmentação pode ser implementada usando o Cloud SQL para PostgreSQL (como a plataforma de dados) com uma camada de aplicativo de suporte. |
| banco de dados na memória | O Oracle fornece um pacote de recursos capazes de melhorar o desempenho do banco de dados para OLTP, bem como cargas de trabalho mistas. | incompatível | O Cloud SQL para PostgreSQL não tem um recurso equivalente integrado. No entanto, é possível usar nosso serviço gerenciado do Redis, o Memorystore, como alternativa. |
| edição | Como parte dos recursos avançados de segurança do Oracle, a edição pode mascarar colunas para impedir a recuperação de dados confidenciais por usuários e aplicativos. | incompatível | O Cloud SQL para PostgreSQL não tem um recurso equivalente integrado. No entanto, a Proteção de dados sensíveis pode ser aproveitada para desidentificar dados sensíveis. |
Funcionalidade
Ainda que os bancos de dados Oracle 11g/12c e Cloud SQL para PostgreSQL tenham sido criados em diferentes arquiteturas (infraestrutura e linguagens procedurais estendidas), ambos compartilham os mesmos aspectos fundamentais de um sistema de banco de dados relacional. Eles são compatíveis com objetos de banco de dados, cargas de trabalho de simultaneidade de vários usuários e transações com propriedades ACID. Eles também gerenciam as contenções de bloqueio com vários níveis de isolamento (com base nas necessidades do aplicativo) e atendem aos requisitos contínuos do aplicativo para operações de processamento transacional on-line (OLTP, na sigla em inglês) e processamento analítico on-line (OLAP, na sigla em inglês).
Na seção a seguir, fornecemos uma visão geral de algumas das principais diferenças funcionais entre Oracle e Cloud SQL para PostgreSQL. Em alguns casos, em que é considerada uma necessidade de destacar as diferenças, a seção inclui comparações técnicas detalhadas.
Como criar e visualizar bancos de dados atuais
| Oracle 11g/12c | Cloud SQL para PostgreSQL 12 |
|---|---|
Geralmente, você cria bancos de dados e visualiza os atuais usando o utilitário Database Creation Assistant (DBCA) do Oracle. Bancos de dados ou instâncias criados manualmente exigem que você especifique mais parâmetros:SQL> CREATE DATABASE ORADB
|
Use uma instrução no formato CREATE DATABASE Name;, como neste exemplo:postgres=> CREATE DATABASE PGSQLDB;
|
| Oracle 12c | Cloud SQL para PostgreSQL 12 |
No Oracle 12c, é possível criar PDBs da semente, de um modelo de banco de dados de contêiner (CDB) ou clonando um PDB de um PDB atual. Você usa vários parâmetros:SQL> CREATE PLUGGABLE DATABASE PDB
|
Use uma instrução no formato CREATE DATABASE Name;, como neste exemplo:postgres=> CREATE DATABASE PGSQLDB;
|
Listar todos os PDBs:SQL> SHOW is PDBS; |
Listar todos os bancos de dados atuais:postgres=> \list |
Conectar-se a um PDB diferente:SQL> ALTER SESSION SET CONTAINER=pdb; |
Conecte-se a um banco de dados diferente:postgres=> \connect databaseName;
Ou: postgres=> \c databaseName |
Abrir ou fechar um PDB específico (aberto/somente leitura):SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
Incompatível com um único banco de dados. Todos os bancos de dados estão na mesma instância do Cloud SQL para PostgreSQL. Portanto, todos os bancos de dados estão ativos ou inativos. |
Como gerenciar um banco de dados no Console do Google Cloud
No Console do Google Cloud, acesse Bancos de dados>SQL>Instância>(selecione a instância do PostgreSQL)>Bancos de dados.
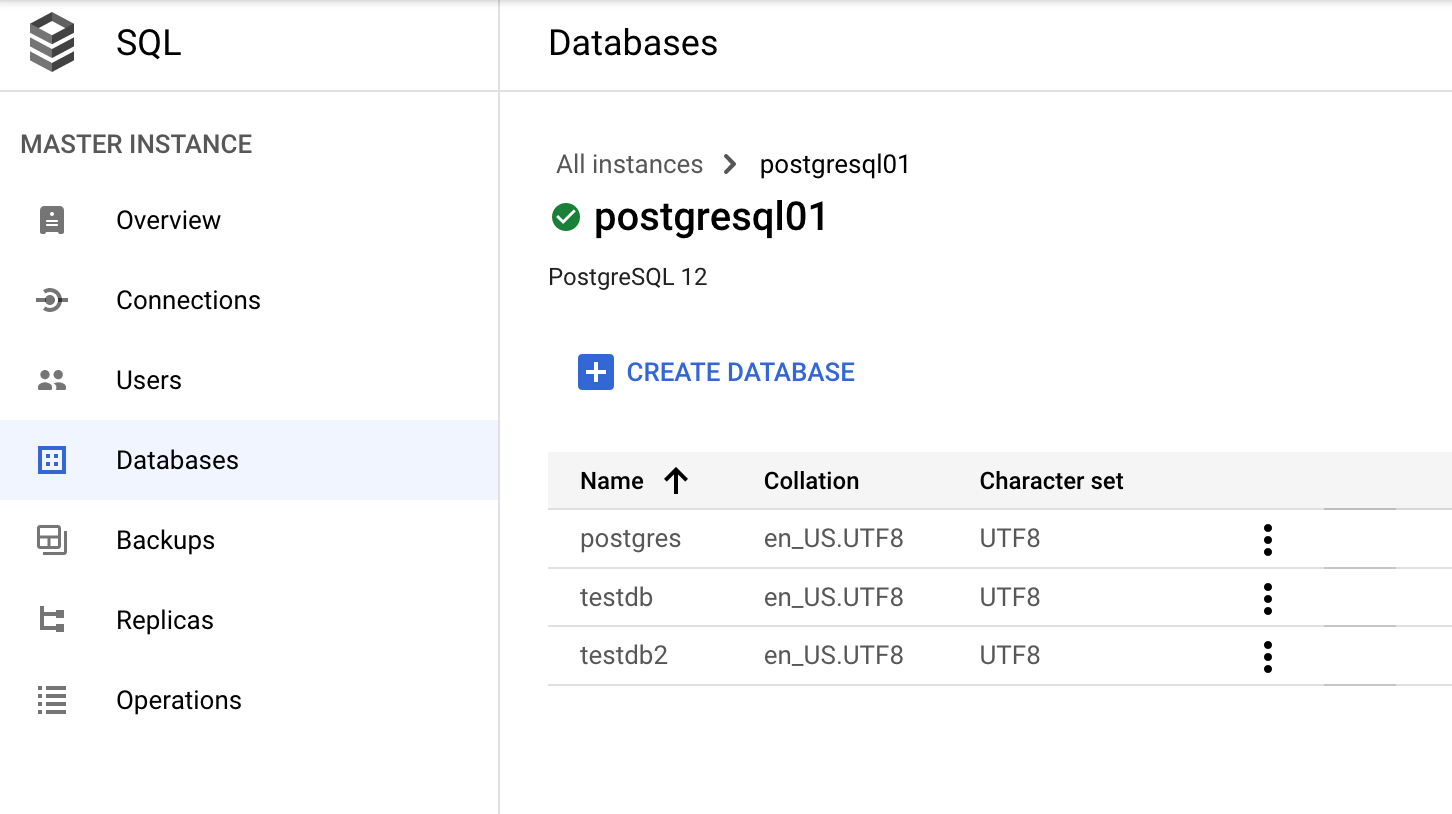
Dicionário de dados e visualizações dinâmicas
Os bancos de dados Oracle fornecem um dicionário de dados com visualizações dinâmicas de desempenho (V$ visualizações) que facilitam várias tarefas de manutenção e monitoramento de banco de dados. O dicionário de dados armazena todas as informações usadas para gerenciar os objetos no banco de dados. Já as visualizações de desempenho dinâmico contêm muitas informações relacionadas ao desempenho do banco de dados. Essas visualizações são atualizadas continuamente enquanto o banco de dados está em execução.
Em contrapartida, o PostgreSQL fornece vários catálogos de metadados que atendem a uma finalidade semelhante à do dicionário de dados e às visualizações dinâmicas de desempenho do Oracle:
- Catálogo do sistema: metadados sobre todos os objetos do banco de dados.
- Visualizações de coleta estatística: relatórios sobre as atividades do PostgreSQL.
- Visualizações de esquema de informações: metadados sobre todos os objetos de banco de dados relatados de acordo com o padrão ANSI SQL.
Como visualizar metadados e visualizações dinâmicas do sistema
Nesta seção, fornecemos uma visão geral de algumas das tabelas de metadados mais comuns e visualizações dinâmicas do sistema usadas no Oracle e os respectivos objetos de banco de dados correspondentes no Cloud SQL para PostgreSQL versão 12.
O Oracle fornece centenas de tabelas e visualizações de metadados do sistema (em alguns esquemas do sistema, por exemplo, SYS ou SYSTEM), enquanto o PostgreSQL contém apenas algumas dezenas. Para cada caso, pode haver mais de um objeto de banco de dados, atendendo a uma finalidade específica.
O Oracle oferece vários níveis de objetos de metadados, cada um exigindo privilégios diferentes:
USER_TableName: visível para o usuário.ALL_TableName: visível para todos os usuários.DBA_TableName: visível apenas para usuários com o privilégio de DBA, comoSYSeSYSTEM.
Para visualizações de desempenho dinâmico, o Oracle usa os prefixos V$/GV$. Por outro lado, os metadados e as visualizações do Cloud SQL para PostgreSQL residem nos esquemas information_schema e pg_catalog.
| Tipo de metadados | Tabela/visualização do Oracle | Tabela/visualização/consulta do Cloud SQL para PostgreSQL |
|---|---|---|
| sessões abertas | V$SESSION |
pg_catalog.pg_stat_activity |
| transações em execução | V$TRANSACTION |
Incompatível. Como solução alternativa, pg_locks fornece uma lista de transações abertas que contêm um ou mais bloqueios. |
| objetos de banco de dados | DBA_OBJECTS |
pg_catalog.pg_class |
| Tabelas | DBA_TABLES |
pg_catalog.pg_tables |
| colunas de tabela | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| privilégios de tabela e coluna | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| partições | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| visualizações | DBA_VIEWS |
pg_catalog.pg_views |
| Restrições | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| índices | DBA_INDEXES |
pg_catalog.pg_index |
| visualizações materializadas | DBA_MVIEWS |
pg_catalog.pg_matviews |
| procedimentos armazenados | DBA_PROCEDURES |
pg_catalog.pg_proc |
| funções armazenadas | DBA_PROCEDURES |
pg_catalog.pg_proc |
| gatilhos | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| Usuários | DBA_USERS |
pg_catalog.pg_user |
| privilégios de usuário | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| jobs/ programador |
DBA_JOBS |
Incompatível. |
| tablespaces | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| arquivos de dados | DBA_DATA_FILES |
Incompatível. |
| sinônimos | DBA_SYNONYMS |
Incompatível. |
| sequências | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| links de banco de dados | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| Estatísticas | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| bloqueios | DBA_LOCK |
pg_catalog.pg_locks |
| parâmetros de banco de dados | V$PARAMETER |
pg_catalog.pg_settings
show |
| segmentos | DBA_SEGMENTS |
Incompatível. |
| Papéis | DBA_ROLES |
pg_catalog.pg_roles |
| histórico da sessão | V$ACTIVE_SESSION_HISTORY |
Incompatível. |
| Versão | V$VERSION |
select version(); |
| eventos de espera | V$WAITCLASSMETRIC |
Incompatível. |
| ajuste e análise SQL |
V$SQL |
Incompatível. |
| ajuste de memória da instância |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
Não incorporado ao Cloud SQL para PostgreSQL. Use a extensão pg_buffercache para examinar o cache de buffer compartilhado em tempo real. |
Parâmetros do sistema
Os bancos de dados Oracle e Cloud SQL para PostgreSQL podem ser configurados especificamente para alcançar determinadas funcionalidades além da configuração padrão. Para alterar os parâmetros de configuração no Oracle, algumas permissões de administração são necessárias (principalmente as permissões do usuário SYS/SYSTEM).
Veja a seguir um exemplo de como alterar a configuração do Oracle usando a instrução ALTER SYSTEM. Nele, o usuário altera o parâmetro "máximo de tentativas para logins com falha" somente no nível da configuração spfile (modificação válida somente após uma reinicialização):
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
No próximo exemplo, o usuário solicita visualizar o valor do parâmetro do Oracle:
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
A resposta será semelhante a:
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
A modificação do parâmetro do Oracle funciona em três escopos:
- SPFILE: as modificações de parâmetro são gravadas no
spfiledo Oracle. Requer uma reinicialização da instância para entrar em vigor. - MEMORY: as modificações de parâmetro são aplicadas à camada de memória somente enquanto nenhuma alteração de parâmetro estático é permitida.
- AMBOS: as modificações de parâmetro são aplicadas ao arquivo de parâmetros do servidor e à memória da instância, em que nenhuma alteração de parâmetro estático é permitida.
Sinalizações de configuração do Cloud SQL para PostgreSQL
É possível modificar os parâmetros de sistema do Cloud SQL para PostgreSQL usando as flags de configuração no console do Google Cloud, na gcloud CLI ou no CURL. Consulte a lista completa de todos os parâmetros compatíveis com o Cloud SQL para PostgreSQL que podem ser alterados.
Os parâmetros do PostgreSQL podem ser divididos em vários escopos:
- Parâmetros dinâmicos: podem ser alterados no momento da execução.
- Parâmetros do banco de dados: aplicam-se a um banco de dados específico em uma instância do PostgreSQL.
- Parâmetros de papel: aplicam-se apenas a um papel de banco de dados específico.
- Parâmetros estáticos: exigem uma reinicialização da instância para entrar em vigor.
- Parâmetros de sessão: podem ser alterados no nível da sessão apenas durante a vida útil da sessão atual, isolada de outras sessões.
- Parâmetros globais: terão efeito global em todas as sessões atuais e futuras.
Exemplos de alteração de parâmetros do Cloud SQL para PostgreSQL
Console
Use o console do Google Cloud para ativar o parâmetro log_connections.
Acesse a página Editar instância do Cloud Storage.
Em Sinalizações, clique em Adicionar item e procure
log_connections, como na captura de tela a seguir.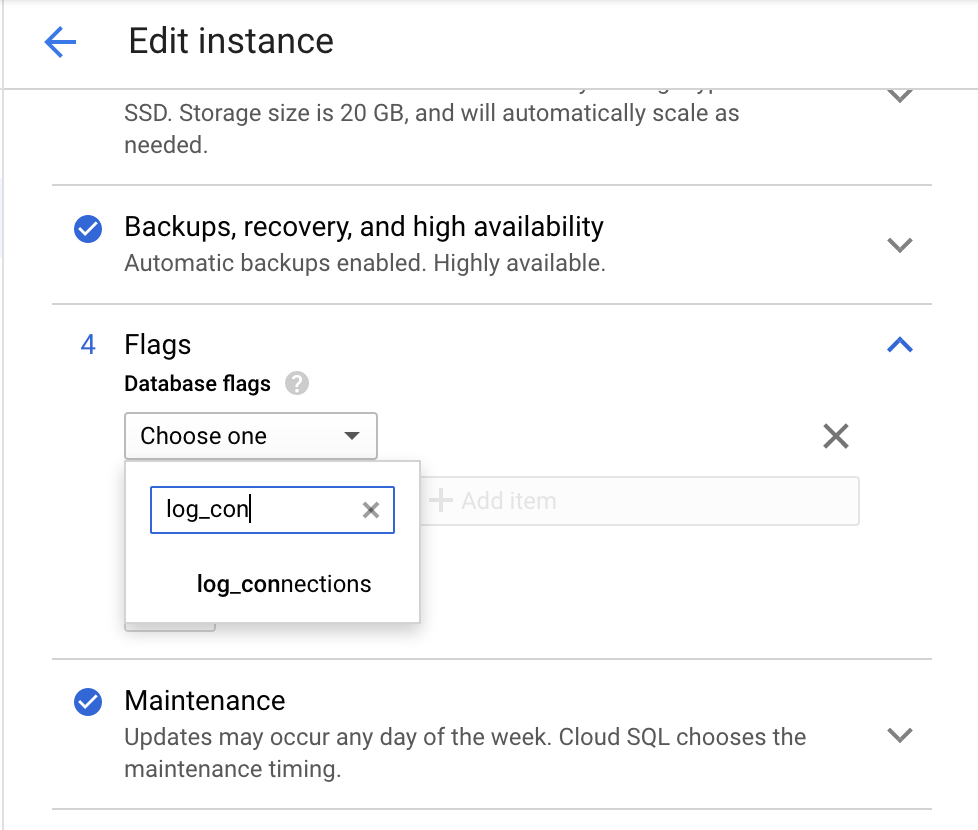
gcloud
- Use a CLI gcloud para ativar o parâmetro
log_connections:
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
A saída é esta:
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL para PostgreSQL
Defina timezone no nível da sessão. Essa alteração é válida para a sessão atual e só permanece em vigor durante o ciclo de vida dela.
Mostrar parâmetro de configuração
timezone:postgres=> SHOW timezone;Aparecerá esta saída, em que
timezoneéset to UTC:TimeZone ---------- UTC (1 row)
Defina
timezonecomo UTC-9.postgres=> SET timezone='UTC-9';Mostrar parâmetro de configuração
timezone:postgres> SHOW timezone;Você verá a seguinte saída, em que
timezoneestá definido comoUTC-9:TimeZone ---------- UTC-9 (1 row)
Transações e níveis de isolamento
Nesta seção, descrevemos as principais diferenças nos níveis de execução e isolamento de transações entre Oracle e Cloud SQL para PostgreSQL.
Modo de confirmação
Por padrão, o Oracle funciona no modo sem confirmação automática, em que é preciso determinar cada transação DML com instruções COMMIT/ROLLBACK. Uma das diferenças fundamentais entre o Oracle e o PostgreSQL é que o PostgreSQL emite implicitamente um COMMIT após cada comando que não segue START TRANSACTION (ou BEGIN). Isso também é conhecido por outros mecanismos de banco de dados como confirmação automática.
Embora a confirmação automática esteja ativada por padrão, ela pode ser desativada no nível da sessão usando SET AUTOCOMMIT OFF.
Níveis de isolamento
O padrão ANSI/ISO SQL (SQL:92) define quatro níveis de isolamento. Cada nível fornece uma abordagem diferente para manipular a execução simultânea de transações de banco de dados:
- Leitura não confirmada: uma transação processada atualmente pode ver dados não confirmados gerados pela outra transação. Se uma reversão for realizada, todos os dados serão restaurados ao estado anterior.
- Leitura confirmada: uma transação só vê alterações de dados que foram confirmadas. Alterações não confirmadas ("leituras sujas") não são possíveis.
- Leitura repetível: uma transação só pode ver as alterações feitas pela outra transação depois que ambas emitirem um
COMMITou ambas forem revertidas. - Serializável: o nível de isolamento mais rigoroso/forte. Esse nível bloqueia todos os registros acessados e bloqueia o recurso para impedir que os registros sejam anexados à tabela.
Os níveis de isolamento de transação gerenciam a visibilidade dos dados alterados, como ocorre para outras transações em execução. Além disso, quando os mesmos dados são acessados por várias transações simultâneas, o nível selecionado de isolamento de transação afeta a interação de diferentes transações.
O Oracle é compatível com os níveis de isolamento a seguir:
- leitura confirmada (padrão);
- Serializable
- Somente leitura (não faz parte do padrão ANSI/ISO SQL - SQL92)
Controle de simultaneidade de várias versões (MVCC, na sigla em inglês) do Oracle:
- O Oracle usa o mecanismo MVCC para fornecer consistência de leitura automática em todo o banco de dados e em todas as sessões.
- O Oracle depende do número de alteração do sistema (SCN, na sigla em inglês) da transação atual para ter uma visualização consistente do banco de dados. Portanto, todas as consultas de banco de dados só retornam dados confirmados em relação ao SCN no momento da execução.
- Os níveis de isolamento podem ser alterados nos níveis de transação e sessão.
Veja um exemplo de definição de níveis de isolamento:
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
O Cloud SQL para PostgreSQL é compatível com estes quatro níveis de isolamento da transação especificados no padrão ANSI SQL:92:
- Leitura não confirmada (equivalente à leitura confirmada)
- leitura confirmada (padrão);
- Leitura repetível
- Serializable
O nível de isolamento padrão do Cloud SQL para PostgreSQL é READ COMMITTED.
Esses níveis de isolamento podem ser alterados no nível SESSION, TRANSACTION e INSTANCE.
Para verificar os níveis de isolamento atuais nos níveis TRANSACTION e SESSION, use a instrução a seguir:
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
A saída é esta:
current_setting ----------------- read committed (1 row)
É possível modificar a sintaxe do nível de isolamento da seguinte maneira:
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
Também é possível modificar o nível de isolamento no nível:
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
A saída é esta:
current_setting ----------------- repeatable read (1 row)
O nível de isolamento em INSTANCE é controlado usando a
sinalização do banco de dados
default_transaction_isolation. Para confirmar isso, use a seguinte instrução:
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
A saída é esta:
default_transaction_isolation ------------------------------- repeatable read (1 row)
A seguir
- Descubra mais sobre as contas de usuário do Cloud SQL para PostgreSQL.
- Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.