Diese Referenzarchitektur bietet Ihnen eine Methode und anfängliche Infrastruktur, um ein modernes CI/CD-System (Continuous Integration/Continuous Delivery) mithilfe von Tools wie
Google Kubernetes Engine,
Cloud Build,
Skaffold,
kustomize,
Config Sync,
Policy Controller,
Artifact Registry,
und
Cloud Deploy.
Dieses Dokument ist Teil der folgenden Reihe:
- Moderne CI/CD mit GKE: Ein Softwarebereitstellungs-Framework
- Moderne CI/CD mit GKE: CI/CD-System erstellen (dieses Dokument)
- Moderne CI/CD mit GKE: Entwickler-Workflow anwenden
Dieses Dokument richtet sich an Unternehmensarchitekten und Anwendungsentwickler sowie für IT-, DevOps- und Site Reliability Engineering-Teams. Erfahrung mit automatisierten Bereitstellungstools und -prozessen ist hilfreich, um die Konzepte in diesem Dokument zu verstehen.
CI/CD-Workflow
Wenn Sie ein modernes CI/CD-System aufbauen möchten, müssen Sie zuerst Tools und Dienste auswählen, die die Hauptfunktionen des Systems ausführen. Diese Referenzarchitektur konzentriert sich auf die Implementierung der Kernfunktionen eines CI/CD-Systems, die im folgenden Diagramm dargestellt sind:

In dieser Referenzimplementierung werden für jede Komponente die folgenden Tools verwendet:
- Für die Quellcodeverwaltung: GitHub
- Speichert den Anwendungs- und Konfigurationscode.
- Hier können Sie Änderungen prüfen.
- Für die Anwendungskonfiguration:
kustomize- Definiert die gewünschte Konfiguration einer Anwendung.
- Ermöglicht die Wiederverwendung und Erweiterung von Konfigurationsprimitiven oder -entwürfen.
- Für Continuous Integration: Cloud Build
- Testet und validiert den Quellcode.
- Erstellt Artefakte, die in der Bereitstellungsumgebung verbraucht werden.
- Für Continuous Delivery: Cloud Deploy
- Definiert den Rollout-Prozess des Codes in allen Umgebungen.
- Bietet Rollback für fehlgeschlagene Änderungen.
- Für die Infrastrukturkonfiguration: Config Sync
- Cluster- und Richtlinienkonfiguration werden konsistent angewendet.
- Für die Durchsetzung von Richtlinien: Policy Controller
- Stellt einen Mechanismus bereit, mit dem Sie anhand der Richtlinien der Organisation definieren können, was in einer bestimmten Umgebung ausgeführt werden darf.
- Für die Containerorchestrierung: Google Kubernetes Engine
- Führt die in CI erstellten Artefakte aus.
- Bietet Skalierungs-, Systemdiagnose- und Rollout-Methoden für Arbeitslasten.
- Für Containerartefakte: Artifact Registry
- Speichert die Artefakte (Container-Images), die während der CI erstellt wurden.
Architektur
In diesem Abschnitt werden die CI/CD-Komponenten beschrieben, die Sie mithilfe dieser Referenzarchitektur implementieren: Infrastruktur, Pipelines, Code-Repositories und Landing-Zones.
Allgemeine Informationen zu diesen Aspekten des CI/CD-Systems finden Sie unter Moderne CI/CD mit GKE: Ein Softwarebereitstellungs-Framework.
Referenzarchitekturvarianten
Die Referenzarchitektur hat zwei Bereitstellungsmodelle:
- Eine Variante mit mehreren Projekten, ähnlich einer Produktionsbereitstellung mit verbesserten Isolationsgrenzen
- Eine Variante mit einem einzelnen Projekt für Demonstrationszwecke
Referenzarchitektur für mehrere Projekte
Die multi-project-Version der Referenzarchitektur simuliert produktionsähnliche Szenarien. In diesen Szenarien erstellen verschiedene Personen Infrastrukturen, CI/CD-Pipelines und Anwendungen mit ordnungsgemäßen Isolationsgrenzen. Diese Personen oder Teams können nur auf die erforderlichen Ressourcen zugreifen.
Weitere Informationen finden Sie unter Moderne CI/CD mit GKE: Ein Softwarebereitstellungs-Framework.
Weitere Informationen zum Installieren und Anwenden dieser Version der Referenzarchitektur finden Sie im Softwarebereitstellungs-Blueprint.
Referenzarchitektur für ein einzelnes Projekt
In der single-project-Version der Referenzarchitektur wird gezeigt, wie Sie die gesamte Softwarebereitstellungsplattform in einem einzigen Google Cloud-Projekt einrichten. Diese Version kann allen Nutzern ohne erhöhte IAM-Rollen dabei helfen, die Referenzarchitektur mit der Inhaberrolle für ein Projekt zu installieren und auszuprobieren. In diesem Dokument wird die Einzelprojektversion der Referenzarchitektur demonstriert.
Plattforminfrastruktur
Die Infrastruktur für diese Referenzarchitektur besteht aus Kubernetes-Clustern zur Unterstützung der Entwicklungs-, Staging- und Produktionsanwendungsumgebungen. Das folgende Diagramm zeigt das logische Layout der Cluster:

Code-Repositories
Mit dieser Referenzarchitektur richten Sie Repositories für Operatoren, Entwickler, Plattform und Sicherheitsentwickler ein.
Das folgende Diagramm zeigt die Implementierung der Referenzarchitektur der verschiedenen Code-Repositories und die Interaktion der Betriebs-, Entwicklungs- und Sicherheitsteams mit den Repositories:

In diesem Workflow können Ihre Operatoren Best Practices für CI/CD und die Anwendungskonfiguration im Operator-Repository verwalten. Wenn Ihre Entwickler Anwendungen im Entwicklungs-Repository einrichten, erhalten sie automatisch Best Practices, Geschäftslogik für die Anwendung und alle speziellen Konfigurationen, die für den ordnungsgemäßen Betrieb ihrer Anwendung erforderlich sind. Das Betriebs- und Sicherheitsteam kann die Konsistenz und Sicherheit der Plattform in den Konfigurations- und Richtlinien-Repositories verwalten.
Anwendungs-Landing-Zones
In dieser Referenzarchitektur wird die Landing-Zone für eine Anwendung erstellt, wenn die Anwendung bereitgestellt wird. Im nächsten Dokument dieser Reihe, Moderne CI/CD mit GKE: Entwickler-Workflow anwenden, stellen Sie eine neue Anwendung bereit, die ihre eigene Landing-Zone erstellt. Das folgende Diagramm zeigt die wichtigsten Komponenten der in dieser Referenzarchitektur verwendeten Landing-Zones:

Jeder Namespace enthält ein Dienstkonto, mit dem Workload Identity-Föderation für GKE auf Dienste außerhalb des Kubernetes-Containers zugreifen kann, z. B. Cloud Storage oder Cloud Spanner. Der Namespace enthält auch andere Ressourcen wie Netzwerkrichtlinien, um Grenzen für andere Namespaces oder Anwendungen zu isolieren oder freizugeben.
Der Namespace wird vom CD-Ausführungsdienstkonto erstellt. Wir empfehlen, dass Teams den Grundsatz der geringsten Berechtigung befolgen, damit ein CD-Ausführungsdienstkonto nur auf erforderliche Namespaces zugreifen kann.
Sie können den Zugriff auf Dienstkonten in Config Sync definieren und mithilfe der rollenbasierten Zugriffssteuerungsrollen (RBAC) und Rollenbindungen von Kubernetes implementieren. Mit diesem Modell können Teams alle Ressourcen direkt in den von ihnen verwalteten Namespaces bereitstellen, können jedoch keine Ressourcen aus anderen Namespaces überschreiben oder löschen.
Ziele
- Referenzarchitektur für ein einzelnes Projekt bereitstellen
- Code-Repositories untersuchen
- Pipeline und Infrastruktur kennenlernen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Google Kubernetes Engine (GKE)
- Google Kubernetes Engine (GKE) Enterprise edition for Config Sync and Policy Controller
- Cloud Build
- Artifact Registry
- Cloud Deploy
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Vorbereitung
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Referenzarchitektur bereitstellen
Legen Sie in Cloud Shell das Projekt fest:
gcloud config set core/project PROJECT_ID
Ersetzen Sie
PROJECT_IDdurch Ihre Google Cloud-Projekt-ID.Klonen Sie in Cloud Shell das Git-Repository:
git clone https://github.com/GoogleCloudPlatform/software-delivery-blueprint.git cd software-delivery-blueprint/launch-scripts git checkout single-project-blueprintErstellen Sie in GitHub ein persönliches Zugriffstoken mit den folgenden Bereichen:
repodelete_repoadmin:orgadmin:repo_hook
Im Ordner
software-delivery-bluprint/launch-scriptsbefindet sich eine leere Datei mit dem Namenvars.sh. Fügen Sie der Datei den folgenden Inhalt hinzu.cat << EOF >vars.sh export INFRA_SETUP_REPO="gke-infrastructure-repo" export APP_SETUP_REPO="application-factory-repo" export GITHUB_USER=GITHUB_USER export TOKEN=TOKEN export GITHUB_ORG=GITHUB_ORG export REGION="us-central1" export SEC_REGION="us-west1" export TRIGGER_TYPE="webhook" EOF
Ersetzen Sie
GITHUB_USERdurch den GitHub-Nutzernamen.Ersetzen Sie
TOKENdurch das persönliche GitHub-Zugriffstoken.Ersetzen Sie
GITHUB_ORGdurch den Namen der GitHub-Organisation.Führen Sie das Skript
bootstrap.shaus: Wenn Sie von Cloud Shell zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren:./bootstrap.shDas Skript bootet die Softwarebereitstellungsplattform.
Code-Repositories entdecken
In diesem Abschnitt machen Sie sich mit den Code-Repositories vertraut.
Bei GitHub anmelden
- Rufen Sie in einem Webbrowser github.com auf und melden Sie sich in Ihrem Konto an.
- Klicken Sie oben auf der Benutzeroberfläche auf das Bildsymbol.
- Klicken Sie auf Meine Organisationen.
- Wählen Sie die Organisation aus, die Sie als Eingabe in der Datei
vars.shangegeben haben. - Klicken Sie auf den Tab Repositories.
Starter-, Operator-, Konfigurations- und Infrastruktur-Repositories entdecken
In den Starter-, Operator-, Konfigurations- und Infrastruktur-Repositories definieren Operatoren und Plattformadministratoren die gängigsten Best Practices für das Erstellen und Betreiben der Plattform. Diese Repositories werden beim Bootstrapping der Referenzarchitektur unter der GitHub-Organisation erstellt.
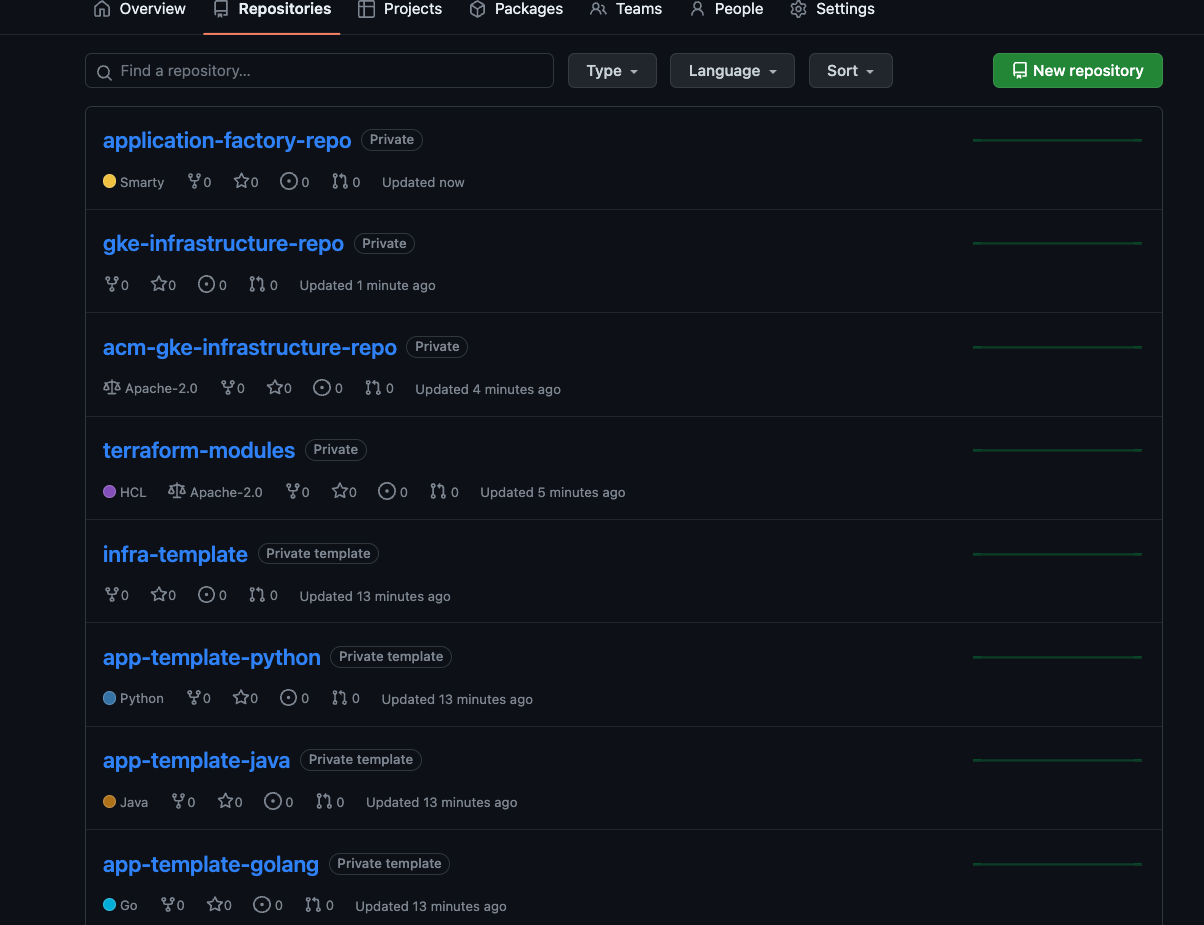
Starter-Repositories
Starter-Repositories unterstützen die Akzeptanz von CI/CD, Infrastruktur und Best Practices für die Entwicklung auf der gesamten Plattform. Weitere Informationen finden Sie unter Moderne CI/CD mit GKE: Ein Softwarebereitstellungs-Framework.
Starter-Repositories für Anwendungen
In den Repositories der Anwendung können Ihre Operatoren Best Practices wie CI/CD, Messwerterfassung, Logging, Containerschritte und Sicherheit für Anwendungen kodieren und dokumentieren. Die Referenzarchitektur enthält Beispiele für Starter-Repositories für Go-, Python- und Java-Anwendungen.
Die Starter-Repositories app-template-python und app-template-java und app-template-golang enthalten Boilerplate-Code, mit dem Sie neue Anwendungen erstellen können. Sie können nicht nur neue Anwendungen erstellen, sondern auch neue Vorlagen anhand der Anwendungsanforderungen. Die von der Referenzarchitektur bereitgestellten Starter-Repositories für Anwendungen enthalten Folgendes:
kustomize-Basis und Patches im Ordnerk8sQuellcode der Anwendung
Ein
Dockerfilemit einer Beschreibung zum Erstellen und Ausführen der AnwendungEine
cloudbuild.yaml-Datei mit den Best Practices für CI-SchritteEine
skaffold.yaml-Datei mit einer Beschreibung der Bereitstellungsschritte
Im nächsten Dokument dieser Reihe, Moderne CI/CD mit GKE: Entwickler-Workflow anwenden, verwenden Sie das Repository app-template-python, um eine neue Anwendung zu erstellen.
Infrastruktur-Starter-Repositories
In den Repositories der Infrastruktur-Starter können Ihre Operatoren und Infrastrukturadministratoren Best Practices wie CI/CD-Pipelines, IaC, Messwerterfassung, Logging und Sicherheit für Infrastruktur kodieren und dokumentieren. Die Referenzarchitektur enthält Beispiele für Infrastruktur-Starter-Repositories mit Terraform. Das Infrastruktur-Starter-Repository infra-template enthält Boilerplate-Code für Terraform, mit dem Sie die für eine Anwendung erforderlichen Infrastrukturressourcen erstellen können, z. B. Cloud Storage-Buckets oder Spanner-Datenbank.
Freigegebene Vorlagen-Repositories
In gemeinsam genutzten Vorlagen-Repositories stellen Infrastrukturadministratoren und Operatoren Standardvorlagen für Aufgaben bereit. Die Referenzarchitektur enthält ein Repository mit dem Namen terraform-modules. Das Repository enthält Terraform-Vorlagencode zum Erstellen verschiedener Infrastrukturressourcen.
Operator-Repositories
In der Referenzarchitektur sind die Operator-Repositories mit den Anwendungs-Starter-Repositories identisch. Die Operatoren verwalten die Dateien, die für CI und CD in den Starter-Repositories der Anwendung erforderlich sind.
Die Referenzarchitektur umfasst die Repositories app-template-python, app-template-java und app-template-golang.
- Dies sind Starter-Vorlagen, und sie enthalten die Kubernetes-Basismanifeste für die Anwendungen, die in Kubernetes auf der Plattform ausgeführt werden. Operatoren können die Manifeste in den Starter-Vorlagen nach Bedarf aktualisieren. Aktualisierungen werden beim Erstellen einer Anwendung übernommen.
- Die Dateien
cloudbuild.yamlundskaffold.yamlin diesen Repositories speichern die Best Practices für die Ausführung von CI bzw. CD auf der Plattform. Ähnlich wie bei den Anwendungskonfigurationen können Operatoren die Best Practices aktualisieren und zu den Best Practices hinzufügen. Einzelne Anwendungspipelines werden mit den neuesten Schritten erstellt.
In dieser Referenzimplementierung verwenden Operatoren kustomize, um Basiskonfigurationen im Ordner k8s der Starter-Repositories zu verwalten.
Anschließend können Entwickler die Manifeste mit anwendungsspezifischen Änderungen wie Ressourcennamen und Konfigurationsdateien erweitern. Das kustomize-Tool unterstützt die Konfiguration als Daten. Bei dieser Methode sind kustomize-Eingaben und -Ausgaben Kubernetes-Ressourcen. Sie können die Ausgaben einer Modifikation der Manifeste für eine andere Modifikation verwenden.
Das folgende Diagramm veranschaulicht eine Basiskonfiguration für eine Spring Boot-Anwendung:

Die Konfiguration als Datenmodell in kustomize bietet einen großen Vorteil: Wenn Operatoren die Basiskonfiguration aktualisieren, werden die Aktualisierungen automatisch von der Bereitstellungspipeline des Entwicklers bei der nächsten Ausführung übernommen. Entwickler müssen dabei keine Änderungen vornehmen.
Weitere Informationen zur Verwendung von kustomize für die Verwaltung von Kubernetes-Manifesten finden Sie in der Dokumentation zu kustomize.
Konfigurations- und Richtlinien-Repositories
Die Referenzarchitektur umfasst eine Implementierung eines Konfigurations- und Richtlinien-Repositorys, das Config Sync und Policy Controller verwendet. Das acm-gke-infrastructure-repo-Repository enthält die Konfiguration und die Richtlinien, die Sie in den Clustern der Anwendungsumgebung bereitstellen. Die von Plattformadministratoren in diesen Repositories definierte und gespeicherte Konfiguration ist wichtig, damit die Plattform ein konsistentes Erscheinungsbild für die Betriebs- und Entwicklungsteams hat.
In den folgenden Abschnitten wird detailliert erläutert, wie die Referenzarchitektur Konfigurations- und Richtlinien-Repositories implementiert.
Konfiguration
In dieser Referenzimplementierung verwenden Sie Config Sync, um die Konfiguration von Clustern auf der Plattform zentral zu verwalten und Richtlinien durchzusetzen. Mit der zentralisierten Verwaltung können Sie Konfigurationsänderungen im gesamten System verteilen.
Mit Config Sync kann Ihre Organisation ihre Cluster registrieren, um ihre Konfiguration aus einem Git-Repository zu synchronisieren. Dieser Vorgang wird als GitOps bezeichnet. Wenn Sie neue Cluster hinzufügen, werden die Cluster automatisch mit der neuesten Konfiguration synchronisiert und der Status des Clusters wird dynamisch mit der Konfiguration abgeglichen, falls Änderungen „out of band“ vorgenommen werden.
Weitere Informationen zu Config Sync finden Sie in der entsprechenden Dokumentation.
Richtlinie
In dieser Referenzimplementierung verwenden Sie den Policy Controller, der auf Open Policy Agent basiert, um jede Anfrage an die Kubernetes-Cluster auf der Plattform zu erfassen und zu validieren. Sie können Richtlinien mithilfe der Rego-Richtliniensprache erstellen, mit der Sie nicht nur die Ressourcentypen, die an den Cluster gesendet werden, sondern auch deren Konfiguration steuern können.
Die Architektur im folgenden Diagramm zeigt einen Anfragefluss zur Erstellung einer Ressource mithilfe von Policy Controller:

Sie erstellen und definieren Regeln im Config Sync-Repository. Diese Änderungen werden auf den Cluster angewendet. Anschließend werden neue Ressourcenanfragen von der Befehlszeile oder von API-Clients anhand der Einschränkungen des Policy Controllers validiert.
Weitere Informationen zum Verwalten von Richtlinien finden Sie unter Policy Controller – Übersicht.
Infrastruktur-Repositories
Die Referenz umfasst eine Implementierung des Infrastruktur-Repositorys mithilfe von Terraform. Das gke-infrastructure-repo-Repository enthält die Infrastruktur als Code, um GKE-Cluster für Entwicklungs-, Staging- und Produktionsumgebungen zu erstellen und Config Sync mithilfe des Repositorys acm-gke-infrastructure-repo auf ihnen zu konfigurieren. gke-infrastructure-repo enthält drei Zweige, einen für jede Entwicklungs-, Staging- und Produktionsumgebung. Darüber hinaus sind in jedem Zweig Entwicklungs-, Staging- und Produktionsordner enthalten.
Pipeline und Infrastruktur kennenlernen
Die Referenzarchitektur erstellt eine Pipeline im Google Cloud-Projekt. Diese Pipeline ist für die Erstellung der gemeinsam genutzten Infrastruktur verantwortlich.
Pipeline
In diesem Abschnitt machen Sie sich mit der Infrastruktur als Code-Pipeline vertraut und führen sie aus, um die freigegebene Infrastruktur einschließlich GKE-Cluster zu erstellen. Die Pipeline ist ein Cloud Build-Trigger namens create-infra im Google Cloud-Projekt, das mit dem Infrastruktur-Repository gke-infrastructure-repo verknüpft ist. Sie folgen der GitOps-Methode, um eine Infrastruktur zu erstellen, wie im Video zu wiederholbaren GCP-Umgebungen mit Cloud Build-Infra-As-Code-Pipelines erläutert.
gke-infrastructure-repo hat Entwicklungs-, Staging- und Produktionszweige. Im Repository gibt es auch Entwicklungs-, Staging- und Produktionsordner, die diesen Zweigen entsprechen. Es gibt Zweigschutzregeln für das Repository, die dafür sorgen, dass der Code nur an den Entwicklungszweig übertragen werden kann. Um den Code in die Staging- und Produktionszweige zu übertragen, müssen Sie eine Pull-Anfrage erstellen.
In der Regel prüft jemand, der Zugriff auf das Repository hat, die Änderungen und führt dann die Pull-Anfrage zusammen, um sicherzustellen, dass nur die beabsichtigten Änderungen zum höheren Zweig hochgestuft werden. Damit die Personen den Blueprint ausprobieren können, wurden die Zweigschutzregeln in der Referenzarchitektur gelockert, sodass der Repository-Administrator die Prüfung umgehen und die Pull-Anfrage zusammenführen kann.
Wenn ein Push an gke-infrastructure-repo gesendet wird, ruft er den Trigger create-infra auf. Dieser Trigger identifiziert den Zweig, in dem der Push erfolgt ist, und geht zum entsprechenden Ordner im Repository in diesem Zweig. Wenn der Ordner gefunden wurde, wird Terraform mit den darin enthaltenen Dateien ausgeführt. Wenn der Code beispielsweise in den Entwicklungszweig übertragen wird, führt der Trigger Terraform im Entwicklungsordner des Entwicklungszweigs aus, um einen GKE-Cluster zu erstellen. Wenn ein Push-Vorgang an den Zweig staging gesendet wird, führt der Trigger Terraform im Staging-Ordner des Staging-Zweigs aus, um einen GKE-Staging-Cluster zu erstellen.
Führen Sie die Pipeline aus, um GKE-Cluster zu erstellen:
Wechseln Sie in der Google Cloud Console zur Seite "Cloud Build".
- Es gibt fünf Cloud Build-Webhook-Trigger. Suchen Sie nach dem Trigger mit dem Namen
create-infra. Dieser Trigger erstellt die freigegebene Infrastruktur, einschließlich GKE-Clustern.
- Es gibt fünf Cloud Build-Webhook-Trigger. Suchen Sie nach dem Trigger mit dem Namen
Klicken Sie auf den Triggernamen. Die Triggerdefinition wird geöffnet.
Klicken Sie auf Bearbeiten öffnen, um die Schritte aufzurufen, die der Trigger ausführt.
Die anderen Trigger werden verwendet, wenn Sie eine Anwendung in Moderne CI/CD mit GKE: Entwickler-Workflow anwenden einrichten.
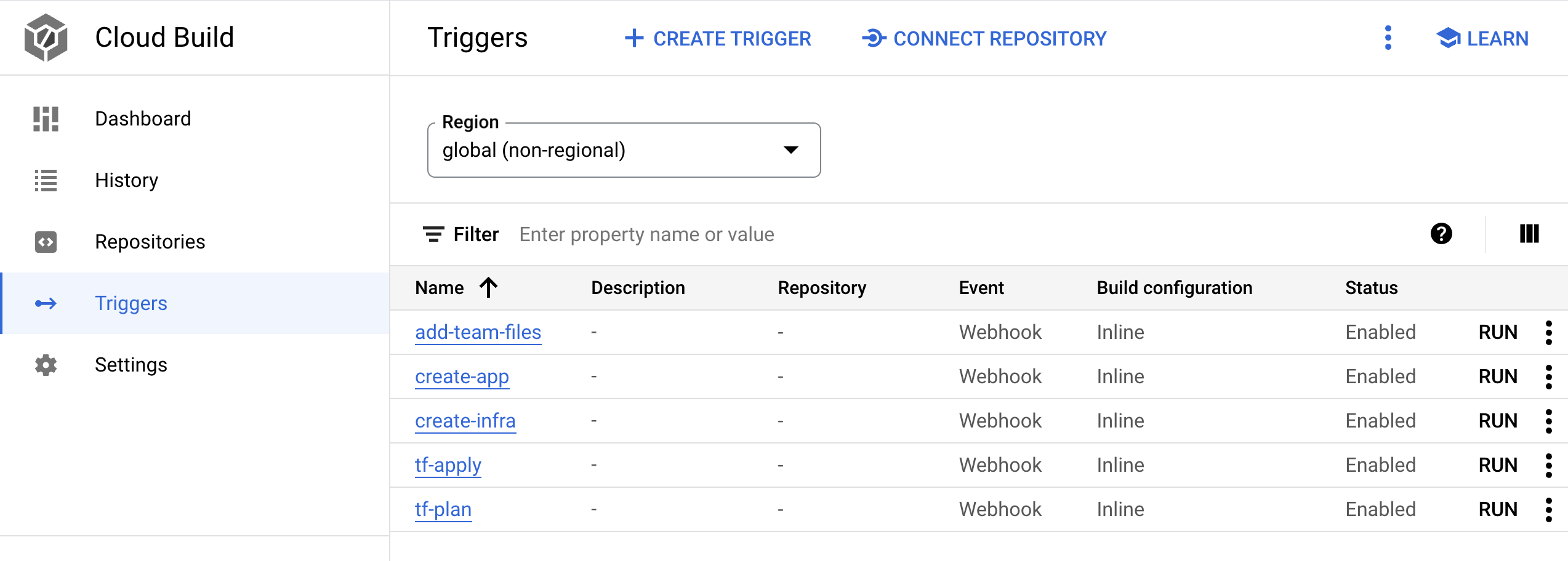
Wechseln Sie in der Google Cloud Console zur Seite "Cloud Build".
Zur Verlaufsseite „Cloud Build“
Prüfen Sie die auf der Verlaufsseite vorhandene Pipeline. Wenn Sie die Softwarebereitstellungsplattform mit
bootstrap.shbereitgestellt haben, hat das Skript den Code an den Entwicklungszweig des Repositorysgke-infrastructure-repoübertragen, das diese Pipeline gestartet und den GKE-Cluster für die Entwicklung erstellt hat.Senden Sie zum Erstellen eines GKE-Staging-Clusters eine Pull-Anfrage vom Entwicklungszweig an den Staging-Zweig:
Rufen Sie GitHub auf und wechseln Sie zum Repository
gke-infrastructure-repo.Klicken Sie auf Pull requests und dann auf New pull request.
Wählen Sie im Menü Basis die Option Staging und im Menü Compare die Option dev aus.
Klicken Sie auf Create pull request.
Wenn Sie ein Administrator für das Repository sind, führen Sie die Pull-Anfrage zusammen. Andernfalls bitten Sie den Administrator, die Pull-Anfrage zusammenzuführen.
Wechseln Sie in der Google Cloud Console zur Verlaufsseite „Cloud Build“.
Zur Verlaufsseite „Cloud Build“
Eine zweite Cloud Build-Pipeline startet im Projekt. Diese Pipeline erstellt den GKE-Staging-Cluster.
Senden Sie zum Erstellen von GKE-Produktionsclustern eine
pull requestvom Staging an den Produktionszweig:Rufen Sie GitHub auf und wechseln Sie zum Repository
gke-infrastructure-repo.Klicken Sie auf Pull requests und dann auf New pull request.
Wählen Sie im Menü Basis die Option prod und im Menü Compare die Option Staging aus.
Klicken Sie auf Create pull request.
Wenn Sie ein Administrator für das Repository sind, führen Sie die Pull-Anfrage zusammen. Andernfalls bitten Sie den Administrator, die Pull-Anfrage zusammenzuführen.
Wechseln Sie in der Google Cloud Console zur Verlaufsseite „Cloud Build“.
Zur Verlaufsseite „Cloud Build“
Eine dritte Cloud Build-Pipeline startet im Projekt. Diese Pipeline erstellt den GKE-Produktionscluster.
Infrastruktur
In diesem Abschnitt machen Sie sich mit der von den Pipelines erstellten Infrastruktur vertraut.
Rufen Sie in der Google Cloud Console die Seite mit den Kubernetes-Clustern auf.
Zur Seite "Kubernetes-Cluster"
Auf dieser Seite werden die Cluster für die Entwicklung (
gke-dev-us-central1), das Staging (gke-staging-us-central1) und die Produktion (gke-prod-us-central1,gke-prod-us-west1) aufgelistet: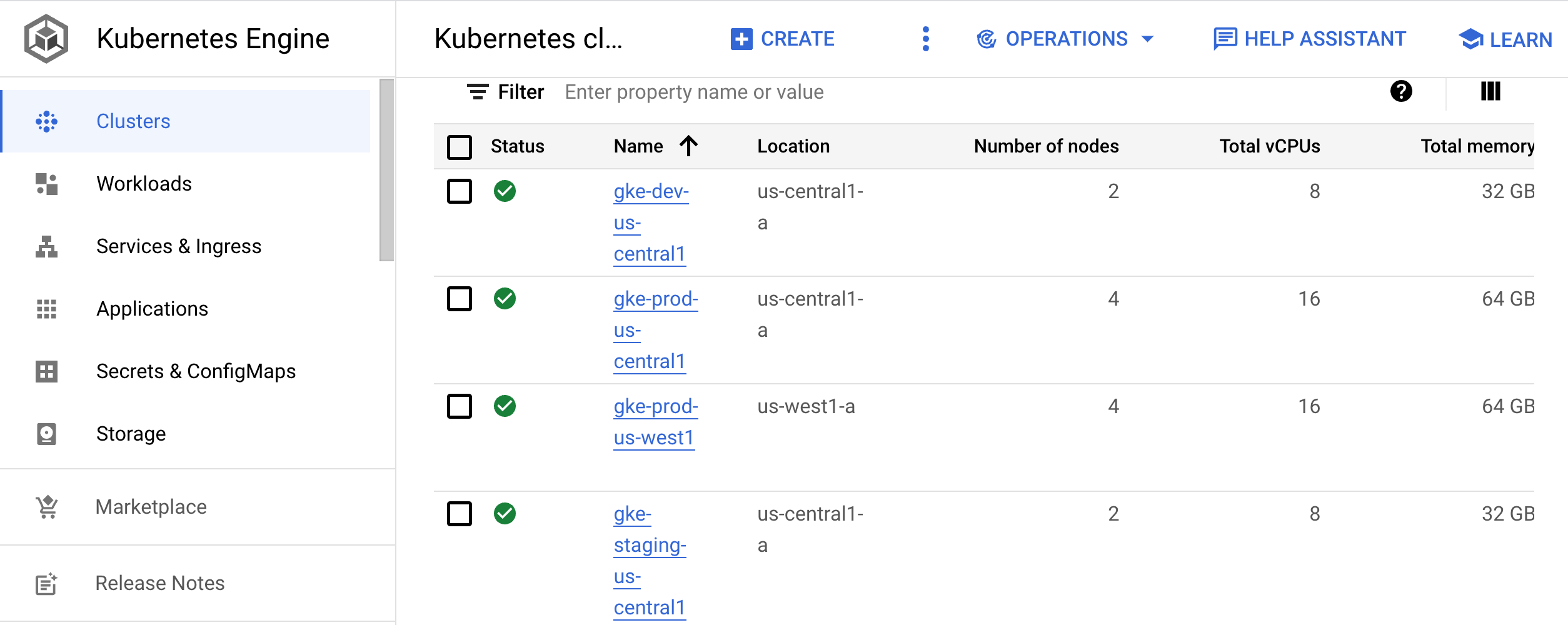
Entwicklungscluster
Der Entwicklungscluster (gke-dev-us-central1) gewährt Entwicklern Zugriff auf einen Namespace, mit dem sie ihre Anwendungen iterieren können. Wir empfehlen Teams, Skaffold zu verwenden, die einen iterativen Workflow bereitstellen. Dazu muss der in der Entwicklung befindliche Code im Blick behalten werden und bei Änderungen noch einmal auf die Entwicklungsumgebungen angewendet werden. Diese Iterationsschleife ähnelt dem Hot Reload.
Statt jedoch sprachspezifisch zu sein, funktioniert die Schleife mit jeder Anwendung, die Sie mit einem Docker-Image erstellen können. Sie können die Schleife in einem Kubernetes-Cluster ausführen.
Alternativ können Ihre Entwickler der CI/CD-Schleife für eine Entwicklungsumgebung folgen. Durch diese Schleife werden die Codeänderungen für das Hochstufen in höheren Umgebungen vorbereitet.
Im nächsten Dokument dieser Reihe, Moderne CI/CD mit GKE: Entwickler-Workflow anwenden, verwenden Sie sowohl Skaffold als auch CI/CD, um die Entwicklungsschleife zu erstellen.
Staging-Cluster
In diesem Cluster wird die Staging-Umgebung Ihrer Anwendungen ausgeführt. In dieser Referenzarchitektur erstellen Sie einen GKE-Cluster für das Staging. In der Regel ist eine Staging-Umgebung ein genaues Replikat der Produktionsumgebung.
Produktionscluster
In der Referenzarchitektur haben Sie zwei GKE-Cluster für Ihre Produktionsumgebungen. Bei Georedundanz- oder Hochverfügbarkeitssystemen (HA) empfehlen wir, jeder Umgebung mehrere Cluster hinzuzufügen. Für alle Cluster, in denen Anwendungen bereitgestellt werden, empfiehlt es sich, regionale Cluster zu verwenden. Dieser Ansatz schützt Ihre Anwendungen vor Fehlern auf Zonenebene und vor Unterbrechungen, die durch Cluster- oder Knotenpool-Upgrades verursacht werden.
Zum Synchronisieren der Konfiguration von Clusterressourcen wie Namespaces, Kontingenten und RBAC empfehlen wir die Verwendung von Config Sync. Weitere Informationen zum Verwalten dieser Ressourcen finden Sie unter Konfigurations- und Richtlinien-Repositories.
Referenzarchitektur anwenden
Nachdem Sie sich mit der Referenzarchitektur vertraut gemacht haben, können Sie sich einen Entwickler-Workflow ansehen, der auf dieser Implementierung basiert. Im nächsten Dokument dieser Reihe, Moderne CI/CD mit GKE: Entwickler-Workflow anwenden, erstellen Sie eine neue Anwendung, fügen ein Feature hinzu und stellen die Anwendung in der Staging- und Produktionsumgebung bereit.
Bereinigen
Wenn Sie sich das nächste Dokument dieser Reihe ansehen möchten, Moderne CI/CD mit GKE: Entwickler-Workflow anwenden löschen Sie nicht das mit dieser Referenzarchitektur verknüpfte Projekt oder Ressourcen. Um zu vermeiden, dass Ihrem Google Cloud-Konto die in der Referenzarchitektur verwendeten Ressourcen in Rechnung gestellt werden, können Sie das Projekt andernfalls löschen oder die Ressourcen manuell entfernen.
Projekt löschen
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Ressourcen manuell entfernen
Entfernen Sie in Cloud Shell die Infrastruktur:
gcloud container clusters delete gke-dev-us-central1 gcloud container clusters delete gke-staging-us-central1 gcloud container clusters delete gke-prod-us-central1 gcloud container clusters delete gke-prod-us-west1 gcloud beta builds triggers delete create-infra gcloud beta builds triggers delete add-team-files gcloud beta builds triggers delete create-app gcloud beta builds triggers delete tf-plan gcloud beta builds triggers delete tf-apply
Nächste Schritte
- Neue Anwendung durch Ausführen der Schritte unter Moderne CI/CD mit GKE: Entwickler-Workflow anwenden erstellen
- Best Practices zum Einrichten der Identity-Föderation
Weitere Informationen zu Kubernetes und den Herausforderungen der kontinuierlichen Softwarebereitstellung
Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center