このドキュメントでは、仮想マシン(VM)の指標にアクセスして表示する方法について説明します。また、VM の指標を確認して VM の詳細を確認する方法や、VM の特定の問題のトラブルシューティング方法についても説明します。
仮想マシン(VM)インスタンスのモニタリングは、VM リソースのメンテナンスに不可欠です。Compute Engine は、 Google Cloud コンソールの [オブザーバビリティ] タブを使用して、VM 指標の概要を提供します。このタブには、テレメトリー データを使用する事前定義されたダッシュボードが表示されます。これにより、VM をモニタリングし、Compute Engine リソースに関して情報に基づいた意思決定を行うことができます。事前定義されたダッシュボードをカスタマイズして、必要な特定の指標のみを表示することもできます。
すべての VM の作成時に、基本的なプロセス使用率データを使用できます。しかし、Ops エージェントをインストールすると、VM の動作をより深く分析できます。
モニタリング アラート ポリシーの作成、Metrics Explorer の使用方法、 Google Cloudでのモニタリングと指標の仕組みに関する一般的な情報については、Cloud Monitoring のドキュメントをご覧ください。
始める前に
省略可: Ops エージェントをインストールして、Compute Engine インスタンスから詳細なデータを収集します。
Ops エージェントがインストールされている VM インスタンスを確認するには、次の操作を行います。
Google Cloud コンソールで、[モニタリング ダッシュボード] に移動します。
ダッシュボード リストから [VM インスタンス] を選択します。
[リスト] をクリックして、VM をリストとして表示します。
プロジェクト内のすべての VM が表示されます。[エージェント] 列に、Ops エージェントのインストール ステータスが表示されます。このページから、Ops エージェントをインストールまたは更新できます。
省略可: イベント(マネージド インスタンス グループの更新を示すイベントなど)を表示するように事前定義ダッシュボードを更新するには、event_available [イベントを選択] をクリックして、ダイアログを完了します。
イベントの詳細については、イベントタイプをご覧ください。
VM オブザーバビリティ指標にアクセスする
Google Cloud コンソールの [オブザーバビリティ] タブを使用して、1 つまたは複数の VM の情報にアクセスします。デフォルトでは、事前定義されたダッシュボードに VM 指標が表示されます。必要な特定の指標のみを表示するには、カスタマイズされたダッシュボードを作成します。
単一の VM のオブザーバビリティ指標を表示する
VM 作成時、CPU 使用率やネットワーク トラフィックなどの基本的な VM 指標を使用できます。メモリとプロセス使用率の指標は、Ops エージェントがインストールされている場合にのみ利用できます。このエージェントは、Compute Engine インスタンスからテレメトリーを収集するための主要エージェントです。
単一の VM の指標を表示するには、次の操作を行います。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
VM を選択して [詳細] ページを開きます。
[オブザーバビリティ] タブをクリックして、VM に関する情報を表示します。
省略可: デフォルトの 1 時間をモニタリング対象の期間に再設定します。
省略可: イベント(マネージド インスタンス グループの更新を示すイベントなど)を表示するように事前定義ダッシュボードを更新するには、event_available [イベントを選択] をクリックして、ダイアログを完了します。
イベントの詳細については、イベントタイプをご覧ください。
図 1 の情報には、VM に Ops エージェントがインストールされていない VM の詳細が示されています。[メモリ使用率] グラフと [ディスク容量使用率] グラフにはデータがないことに注意してください。
![Ops エージェントがインストールされていない 1 つの VM の [オブザーバビリティ] タブ。](https://cloud.google.com/static/compute/images/monitoring/a-demo.jpg?authuser=4&hl=ja)
複数の VM のオブザーバビリティ指標を表示する
フリートレベルのオブザーバビリティでは、プロセス使用率が最も高い上位 5 つの VM の指標が表示されます。表示されている上位 5 つの VM は指標によって異なります。各プロセスに同じ 5 つの VM が表示されない場合があります。単一の VM で使用可能なデータの量と比べて、Ops エージェントをインストールしていないフリートレベルで利用できるより多くのデータがありますが、エージェントをインストールすると、将来のトラブルシューティングのためにより多くのデータが提供されます。
複数の VM の指標を表示するには、次の操作を行います。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
[オブザーバビリティ] タブをクリックします。
省略可: デフォルトの 1 時間をモニタリング対象の期間に再設定します。
結果を次のオプション(複数可)でフィルタします。
- ID
- 名前
- マシンタイプ
- ゾーン
- リージョン
- インスタンス グループ
- ラベル
- 状態
図 2 の情報は、プロジェクト内の複数の VM に Ops エージェントがインストールされている場合の [オブザーバビリティ] タブの例を示しています。これらの VM については、さらに多くの利用可能な指標があることに留意してください。
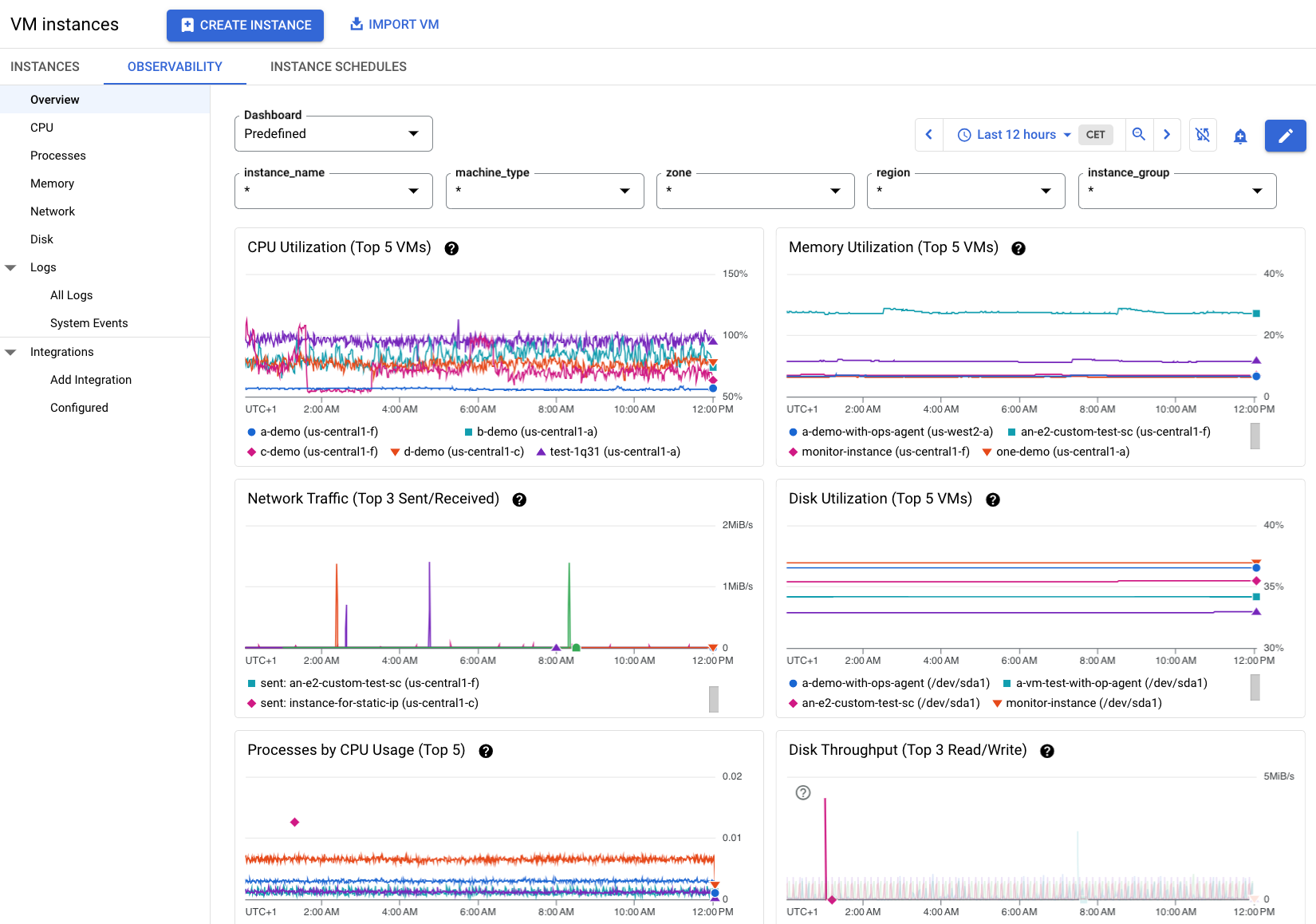
VM の詳細な指標を表示する
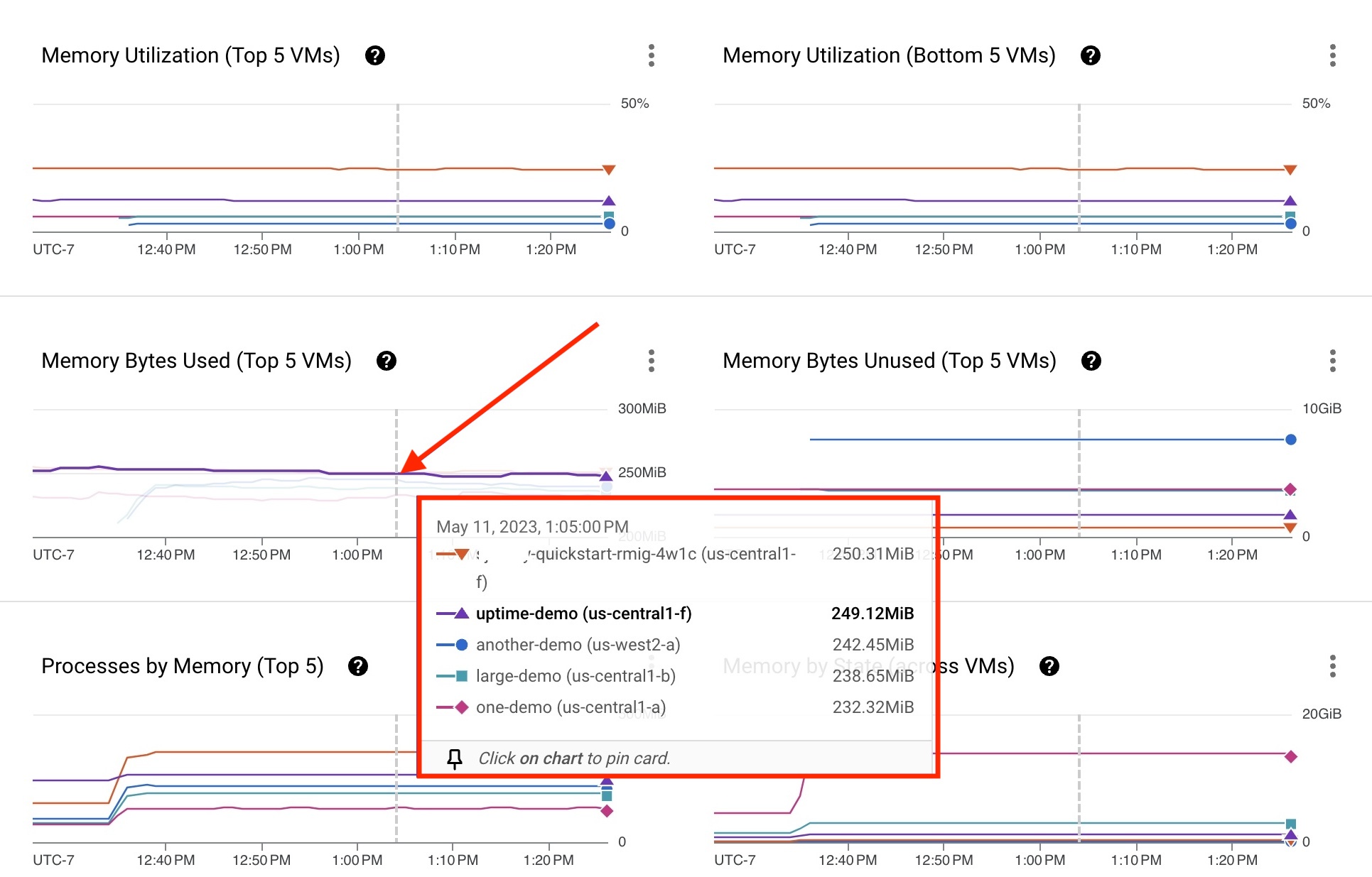
各 VM プロセスの指標は、グラフ上の線で表されます。次の例では、uptime-demo VM に Ops エージェントがインストールされています。メモリ使用率のデータはトラブルシューティングに使用できます。VM がカードに表示されない場合は、VM 名でフィルタして特定の VM を探します。
[オブザーバビリティ] タブからこの VM または上位 5 つの VM に関する情報を取得するには、次を行います。
- VM のグラフ線上にポインタを置きます。表示されたカードに、プロセスを使用した上位 5 つの VM のリストとそれぞれの指標が表示されます。
- VM の動作の詳細を確認するには、VM のグラフ線またはリスト上の特定の VM 名をクリックします。
図 3 のカードに表示された uptime-demo VM には、確認が必要な指標がいくつかあります。
uptime-demo VM をクリックして、図 4 の [VM の詳細] ページを開くと、次の情報が表示されます。
- Ops エージェントのステータス。
- コンテキスト内のオプション(アラートの作成、イベントのチェック、稼働時間チェックの作成)。
- VM の構成、指標、ログの詳細を表示するオプション。
![[VM の詳細] ページには、特定の VM に関する情報が表示されます。](https://cloud.google.com/static/compute/images/monitoring/uptime-demo-vm-details.jpg?authuser=4&hl=ja)
カスタマイズされたダッシュボードを作成して特定の指標を表示する
デフォルトでは、Compute Engine の [オブザーバビリティ] タブには、基本的な VM 指標を表示する事前定義されたダッシュボードが用意されています。確認したい特定の指標のみを表示するには、事前定義されたダッシュボードを変更し、カスタマイズされたダッシュボードとして保存します。ダッシュボードは適したものにさらにカスタマイズできます。
カスタマイズされたダッシュボードを作成する方法は次のとおりです。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
次のように [オブザーバビリティ] タブに移動します。
- 単一の VM の場合: [VM インスタンス] ページで、VM 名をクリックして [詳細] ページを開き、その VM の [オブザーバビリティ] タブをクリックします。
- 複数の VM の場合: [VM インスタンス] ページで、[オブザーバビリティ] タブをクリックします。
[ダッシュボード] プルダウンが有効になっている場合、カスタマイズされたダッシュボードを使用できます。カスタムビューを変更するには、プルダウンからカスタムビューを選択し、ダッシュボード ツールバーで をクリックします。
事前定義されたダッシュボードをカスタマイズするには、ダッシュボードのツールバーで をクリックします。
Compute Engine は、事前定義されたダッシュボードのコピーを作成し、そのコピーを編集モードで開きます。
エディタでは、ダッシュボードで可視化の追加、変更、削除、再配置、サイズ変更を行うことができます。可視化は、まとめてウィジェットと呼ばれます。さまざまなウィジェット タイプの詳細については、ダッシュボードの概要をご覧ください。
ウィジェットを追加するには、ダッシュボードのツールバーで [ウィジェットを追加] をクリックし、構成を完了します。
たとえば、指標データを含むログを表示するには、[ウィジェットを追加] をクリックし、[ログ] を選択して [適用] をクリックします。
ウィジェットを変更するには、ウィジェットの上にポインタを置いてツールバーを有効にし、 [ウィジェットを編集] をクリックして、[ウィジェットを構成する] ダイアログを使用します。変更をダッシュボードに適用するには、ツールバーで [適用] をクリックします。変更を破棄するには、[キャンセル] をクリックします。
ウィジェットを削除するには、ウィジェットにポインタを置いてツールバーを有効にし、[その他のグラフ オプション] をクリックして [削除] を選択してください。
ウィジェットの位置を変更するには、ポインタを使用してウィジェットのヘッダーを新しい場所にドラッグします。
ウィジェットのサイズを変更するには、ポインタを使用してウィジェットの右端の位置を変更します。
ダッシュボードの変更が完了したら、[保存] をクリックします。
変更を確認するダイアログで、[カスタマイズしたダッシュボードを表示] をクリックして、カスタマイズされたビューに移動します。
事前定義ビューに戻すには、[ダッシュボード] プルダウンから [事前定義] を選択します。
リソース指標を確認する
各リソース指標の詳細については、[オブザーバビリティ] タブメニュー内の各プロセスをクリックします。
- CPU、プロセス、メモリの使用率、ネットワークのトラフィック、ディスクの使用率について調べます。
- [ログ] を検索してログデータを表示し、システム イベントを特定して表示します。
- サードパーティの統合を追加したり、構成済みの既存の統合があるかどうかを確認したりします。
このセクションの残りの部分では、一部のプロセスがワークロードに与える影響の例について説明します。この情報は、Ops エージェントが VM にインストールされていることを前提としています。
CPU 使用率
極端な CPU 使用率の例として、ウェブサイトのトラフィックが急増した場合や、大規模なデータ処理タスクが実行中の場合など、サーバーが予期せず高い負荷を負っている場合があります。このような状況では、CPU が 100% の容量で長時間動作している場合があり、サーバーの速度が低下したり応答しなくなったりする可能性があります。
この例では、飽和度が懸念事項です。CPU 使用率が 100% の場合、現在のワークロードには問題ないかもしれませんが、他の指標を調べて介入が必要かどうかを確認することをおすすめします。この場合、VM の CPU 使用率が急増したときに通知されるように、アラート ポリシーの作成をおすすめします。
適切な権限があれば、SSH を使用して VM に接続し、問題を調査できます。しかし、Ops エージェントがインストールされていれば、誰でもトラブルシューティングに役立つ過去のデータを確認できます。
プロセス使用率
プロセスの極端な動作例としては、パフォーマンスの低下を引き起こしたり、さらに VM をクラッシュさせたりするまで、プロセスが CPU、メモリ、ディスク I/O などのリソースを過剰に消費する場合があります。
たとえば、VM で実行されているプロセスでメモリリークが発生している場合、時間の経過とともに大量のメモリを次第に消費し始め、最終的に VM のメモリ不足やクラッシュを引き起こす可能性があります。同様に、特定のプロセスがディスクを大量に使用すると、VM のディスク I/O が飽和状態になり、他のプロセスのレスポンス時間が遅くなる可能性があります。
メモリ使用率
テーブルのインデックス作成、並べ替え、結合などの操作を行うには、データベースに大量のメモリが必要です。
VM のメモリ使用率が高いのは、大規模なデータセットで Cloud SQL for MySQL や Cloud SQL for PostgreSQL などのデータベース サーバーを実行している場合です。VM の使用可能なメモリが小さすぎる場合、データセットをメモリに再読み込みすると、データベースの実行が遅くなったり、クラッシュしたりすることがあります。
ネットワーク パフォーマンス
ネットワーク パフォーマンスの問題は、輻輳、帯域幅の制限、ハードウェアまたはソフトウェアの問題、レイテンシなど、さまざまな要因が原因で発生します。問題を診断するには、ネットワーク パフォーマンス指標をモニタリングし、ハードウェアとソフトウェアの問題のトラブルシューティングを行い、ネットワーク トラフィック パターンを分析して問題の根本原因を特定し、解決します。
ディスク使用率
仮想ディスクの読み書きデータ量が多い場合、VM のディスク使用率が高くなり、その結果、ディスク アクセスに遅延が発生し、VM のパフォーマンスに影響が生じる可能性があります。
1 秒あたりのディスク I/O オペレーション数(IOPS)、ディスクキューの長さ、平均ディスク レスポンス時間などのディスク使用率の指標をモニタリングすると、VM のディスク使用率が高い問題を特定して診断できます。
ログとシステム イベントを確認する
[すべてのログ] ページには、リソースに関するログデータが表示されます。重大度で並べ替えると、問題を特定し、ペイロードを検査できます。
監査ログには、リソースで発生した管理イベントが記録されます。このログでは、何がこのイベントをトリガーしたかがわかります。複数のログが同じ行に記録、管理されるため、たとえば同じログが 20 個ある場合、情報は 20 行別々ではなく 1 行に保存されます。
システム イベントは、上位レベルで発生するが Compute Engine リソースに影響する可能性のあるイベントの総称と考えることができます。システム イベントは、計画されたイベントとは無関係なエラーが発生すると、発生します。システム イベントは、フリートレベルでログに記録されます。
サードパーティ統合を使用する
Monitoring では、サードパーティ アプリケーションとの統合が提供されます。これらの統合により、Apache ウェブサーバー、Cloud SQL for MySQL、Memorystore for Redis などのアプリケーションから、Compute Engine と GKE で実行されているデプロイのテレメトリーを収集できます。Compute Engine を使用している場合、サードパーティのテレメトリーは Ops エージェントによって収集されます。