In diesem Dokument wird beschrieben, wie nichtflüchtige Speicher über VM-Instanzen aufgerufen werden können, und wie Sie die Replikation von nichtflüchtigen Speichern umsetzen. Außerdem wird die zentrale Infrastruktur der nichtflüchtigen Speicher beschrieben. Dieses Dokument richtet sich an Google Cloud-Entwickler und -Architekten, die nichtflüchtigen Speicher in ihren Systemen verwenden möchten.
Nichtflüchtige Speicher sind keine lokalen Laufwerke, die an die physischen Maschinen angehängt sind, sondern Netzwerkdienste, die als Netzwerkblockgeräte an VMs angehängt sind. Wenn Sie von einem nichtflüchtigen Speicher lesen oder schreiben, werden Daten über das Netzwerk übertragen. Nichtflüchtige Speicher sind ein Netzwerkspeichergerät, ermöglichen jedoch viele Anwendungsfälle und Funktionen in Bezug auf Kapazität, Flexibilität und Zuverlässigkeit, die herkömmliche Laufwerke nicht bieten können.
Nichtflüchtige Speicher und Colossus
Nichtflüchtige Speicher werden in Verbindung mit dem Dateisystem Colossus von Google ausgeführt, einem verteilten Blockspeichersystem. Treiber für nichtflüchtige Speicher verschlüsseln die Daten automatisch, bevor sie von der VM in das Netzwerk übertragen werden. Dann speichert Colossus die Daten. Wenn Colossus die Daten liest, entschlüsselt der Treiber die eingehenden Daten.
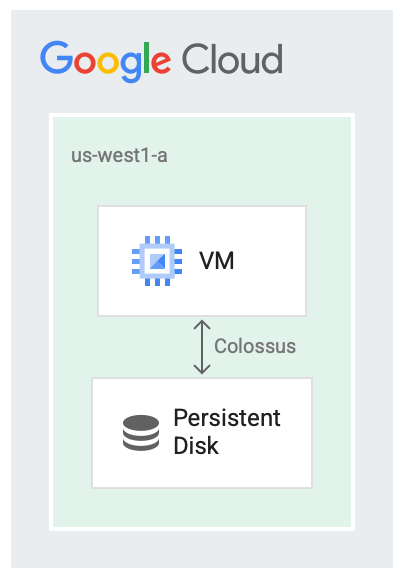
Nichtflüchtige Speicher verwenden Colossus als Speicher-Backend.
Das Bereitstellen von Laufwerken als Dienst ist in verschiedenen Fällen nützlich. Beispiele:
- Die Größenanpassung der Laufwerke während der Ausführung der VM ist einfacher. Die VM muss nicht zuerst beendet werden. Sie können die Laufwerkgröße erhöhen, ohne die VM zu beenden.
- Das Anhängen und Trennen von Laufwerken wird einfacher, wenn Laufwerke und VMs nicht denselben Lebenszyklus haben oder sich am gleichen Ort befinden müssen. Es ist möglich, eine VM zu beenden und deren nichtflüchtiges Bootlaufwerk zum Booten einer anderen VM zu verwenden.
- Hochverfügbarkeitsfeatures wie die Replikation werden einfacher, da der Laufwerktreiber Replikationsdetails ausblenden und eine automatische Schreibzeitreplikation ermöglichen kann.
Laufwerkslatenz
Es gibt verschiedene Benchmarking-Tools, mit denen Sie die Overhead-Latenz bei der Verwendung von Laufwerken als Netzwerkdienst überwachen können. Im folgenden Beispiel wird die SCSI-Laufwerksschnittstelle und nicht die NVMe-Schnittstelle verwendet und die Ausgabe der VM zeigt einige Lesevorgänge von 4-KiB-Blöcken von einem nichtflüchtigen Speicher. Das folgende Beispiel zeigt die Latenz, die in den Lesevorgängen angezeigt wird:
$ ioping -c 5 /dev/sda1
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=293.7 us (warmup)
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=330.0 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=278.1 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=307.7 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=310.1 us
--- /dev/sda1 (block device 10.00 GiB) ioping statistics ---
4 requests completed in 1.23 ms, 16 KiB read, 3.26 k iops, 12.7 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 278.1 us / 306.5 us / 330.0 us / 18.6 us
Compute Engine ermöglicht Ihnen außerdem, lokale SSDs an VMs anzuhängen, wenn der Prozess so schnell wie möglich laufen muss. Wenn Sie einen Cache-Server ausführen oder große Datenverarbeitungsjobs mit einer Zwischenausgabe ausführen, empfehlen wir die Verwendung lokaler SSDs. Im Gegensatz zu nichtflüchtigen Speichern sind Daten auf lokalen SSDs nicht persistent und die Daten werden bei jedem Neustart der virtuellen Maschine gelöscht. Lokale SSDs eignen sich nur für Optimierungsfälle.
Die folgende Ausgabe ist ein Beispiel für die Latenz von 4-KiB-Lesevorgängen von einer lokalen SSD über die NVMe-Laufwerksschnittstelle:
$ ioping -c 5 /dev/nvme0n1
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=245.3 us(warmup)
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=252.3 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=244.8 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=289.5 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=219.9 us
--- /dev/nvme0n1 (block device 375 GiB) ioping statistics ---
4 requests completed in 1.01 ms, 16 KiB read, 3.97 k iops, 15.5 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 219.9 us / 251.6 us / 289.5 us / 25.0 us
Replikation
Wenn Sie eine neue Persistent Disk erstellen, können Sie das Laufwerk entweder in einer Zone erstellen oder über zwei Zonen innerhalb derselben Region hinweg replizieren.
Wenn Sie beispielsweise ein Laufwerk in einer Zone erstellen, z. B. in us-west1-a, haben Sie eine Kopie des Laufwerks. Diese werden als zonale Laufwerke bezeichnet.
Sie können die Verfügbarkeit des Laufwerks erhöhen, indem Sie eine weitere Kopie des Laufwerks in einer anderen Zone innerhalb der Region speichern, z. B. in us-west1-b.
Laufwerke, die über zwei Zonen in derselben Region hinweg repliziert werden, werden als regionale Persistent Disks bezeichnet.
Es ist unwahrscheinlich, dass eine Region vollständig ausfällt, aber zonale Fehler können auftreten. Die Replikation innerhalb der Region in verschiedenen Zonen hilft, wie in der folgenden Abbildung dargestellt, bei der Verfügbarkeit und reduziert die Laufwerkslatenz. Wenn beide Replikationszonen fehlschlagen, wird sie als Ausfall in der gesamten Region betrachtet.
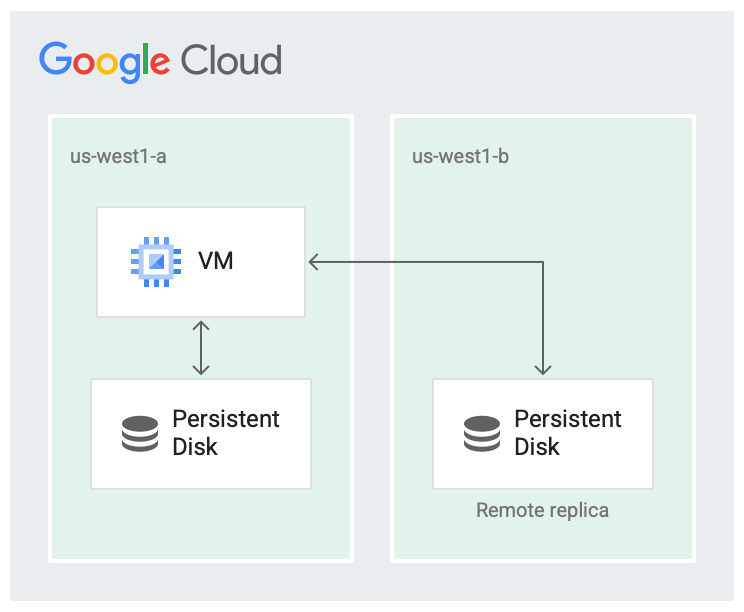
Das Laufwerk wird in zwei Zonen repliziert.
Im replizierten Szenario sind die Daten in der lokalen Zone (us-west1-a) verfügbar, in der die virtuelle Maschine ausgeführt wird. Anschließend werden die Daten in eine andere Colossus-Instanz in einer anderen Zone (us-west1-b) repliziert. Mindestens eine der Zonen sollte dieselbe Zone sein, in der die VM ausgeführt wird.
Beachten Sie, dass die Replikation von nichtflüchtigem Speicher nur für die Hochverfügbarkeit der Laufwerke vorgesehen ist. Zonale Ausfälle können auch die virtuellen Maschinen oder andere Komponenten beeinträchtigen, was ebenfalls zu Ausfällen führen kann.
Lese-/Schreibsequenzen
Beim Festlegen der Lese-/Schreibsequenzen oder der Reihenfolge, in der Daten von dem Laufwerk gelesen und auf das Laufwerk geschrieben werden, wird der Großteil der Arbeit vom Laufwerktreiber in der VM ausgeführt. Als Nutzer müssen Sie sich nicht mit der Replikationssemantik befassen und können wie gewohnt mit dem Dateisystem interagieren. Der zugrunde liegende Treiber übernimmt die Sequenz für Lese- und Schreibvorgänge.
Das System arbeitet standardmäßig im vollständigen Replikationsmodus, in dem Anfragen zum Lesen oder Schreiben von beiden Laufwerken an beide Replikate gesendet werden.
Im vollständigen Replikationsmodus geschieht Folgendes:
- Beim Schreiben versucht eine Schreibanfrage, in beide Replikate zu schreiben, und bestätigt, dass beide Schreibvorgänge erfolgreich sind.
- Beim Lesen sendet die VM eine Leseanfrage an beide Replikate und gibt die Ergebnisse von dem Replikat zurück, das erfolgreich ist. Wenn bei der Leseanfrage eine Zeitüberschreitung auftritt, wird eine weitere Leseanfrage gesendet.
Wenn ein Replikat zurückfällt und nicht bestätigt, dass die Lese- oder Schreibanfragen abgeschlossen wurden, werden die Lese- und Schreibvorgänge nicht mehr an das Replikat gesendet. Das Replikat muss einen Abgleichsprozess durchlaufen, damit es in einen aktuellen Zustand zurückversetzt wird, bevor die Replikation fortgesetzt werden kann.
Nächste Schritte
- Laufwerke entsprechend den Leistungsanforderungen konfigurieren
- Best Practices für Snapshots nichtflüchtiger Speicher