Gérer les recommandations de partition et de cluster
Ce document décrit le fonctionnement de l'outil de recommandation de partition et de cluster, les méthodes pour afficher vos recommandations et insights, ainsi que la manière d'appliquer les recommandations de partition et de cluster.
Fonctionnement de l'outil de recommandation
L'outil de recommandation de partitionnement et de clustering génère des recommandations de partition ou de cluster pour optimiser vos tables BigQuery. L'outil de recommandation analyse les workflows sur vos tables BigQuery et propose des recommandations pour mieux optimiser vos workflows et coûts de requêtes à l'aide du partitionnement ou du clustering de tables.
Pour en savoir plus sur l'outil de recommandation, consultez la page Présentation de l'outil de recommandation.
L'outil de recommandation de partitionnement et de clustering utilise les données d'exécution de charge de travail du projet au cours des 30 derniers jours pour analyser chaque table BigQuery afin d'identifier les configurations de partitionnement et de clustering non optimales. L'outil de recommandation utilise également le machine learning pour prédire dans quelle mesure l'exécution de la charge de travail pourrait être optimisée avec différentes configurations de partitionnement ou de clustering. Si l'outil de recommandation constate que le partitionnement ou le clustering d'une table permet de réaliser des économies significatives, il génère une recommandation. L'outil de recommandation de partitionnement et de clustering génère les types de recommandations suivants :
| Type de table existant | Sous-type de recommandation | Exemple de recommandation |
|---|---|---|
| Non partitionnée, hors cluster | Partition | "Économisez environ 64 heures d'utilisation des emplacement par mois en partitionnant la colonne_C par JOUR". |
| Non partitionnée, hors cluster | Cluster | "Économisez environ 64 heures d'utilisation des emplacement par mois en regroupant les lignes en fonction de la colonne_C" |
| Partitionnée, hors cluster | Cluster | "Économisez environ 64 heures d'utilisation des emplacement par mois en regroupant les lignes en fonction de la colonne_C" |
Chaque recommandation comprend trois parties :
- L'orientation vers le partitionnement ou la mise en cluster d'une table spécifique
- La colonne spécifique d'une table à partitionner ou à mettre en cluster
- L'estimation des économies mensuelles réalisées grâce à l'application de la recommandation
Pour calculer les économies de charges de travail potentielles, l'outil de recommandation suppose que les données d'historique de charge de travail d'exécution des 30 derniers jours représentent la charge de travail future.
L'API de l'outil de recommandation renvoie également des informations sur les charges de travail de table sous la forme d'insights. Les insights sont des résultats qui vous aident à comprendre la charge de travail de votre projet, en fournissant plus de contexte sur la façon dont une recommandation de partitionnement ou de clustering peut améliorer les coûts des charges de travail.
Limites
L'outil de recommandation de partitionnement et de clustering n'est pas compatible avec les tables BigQuery utilisant l'ancien SQL. Lors de la génération d'une recommandation, l'outil de recommandation exclut toutes les requêtes en ancien SQL de son analyse. En outre, l'application de recommandations de partition sur les tables BigQuery avec l'ancien SQL interrompt tous les workflows en ancien SQL de cette table.
Avant d'appliquer des recommandations de partition, migrez vos workflows en ancien SQL vers GoogleSQL.
BigQuery ne permet pas de modifier le schéma de partitionnement d'une table en place. Vous ne pouvez modifier le partitionnement d'une table que sur une copie de la table. Pour en savoir plus, consultez la section Appliquer des recommandations de partition.
Emplacements
L'outil de recommandation de partitionnement et de clustering est disponible dans les emplacements de traitement suivants :
| Description de la région | Nom de la région | Détail | |
|---|---|---|---|
| Asie-Pacifique | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Séoul | asia-northeast3 |
||
| Singapour | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taïwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europe | |||
| Belgique | europe-west1 |
|
|
| Berlin | europe-west10 |
|
|
| UE (multirégional) | eu |
||
| Francfort | europe-west3 |
|
|
| Londres | europe-west2 |
|
|
| Pays-Bas | europe-west4 |
|
|
| Zurich | europe-west6 |
|
|
| Amériques | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Montréal | northamerica-northeast1 |
|
|
| Virginie du Nord | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| États-Unis (multirégional) | us |
||
Avant de commencer
- Assurez-vous que Gemini dans BigQuery est activé pour votre projet Google Cloud.
- Activez l'API Recommender.
Autorisations requises
Pour obtenir les autorisations nécessaires pour accéder aux recommandations de partition et de cluster, demandez à votre administrateur de vous accorder le rôle IAM Lecteur de l'outil de recommandation de partitionnement et de clustering BigQuery (roles/recommender.bigqueryPartitionClusterViewer).
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Ce rôle prédéfini contient les autorisations requises pour accéder aux recommandations de partition et de cluster. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Vous devez disposer des autorisations suivantes pour accéder aux recommandations de partition et de cluster :
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour plus d'informations sur les rôles et les autorisations IAM dans BigQuery, consultez la page Présentation d'IAM.
Afficher les recommandations
Cette section explique comment afficher les recommandations et les insights de partition et de cluster à l'aide de la console Google Cloud, de Google Cloud CLI ou de l'API Recommender.
Sélectionnez l'une des options suivantes :
Dans la console Google Cloud, accédez à la page BigQuery.
Pour ouvrir l'onglet "Recommandations", cliquez sur Recommandations > Afficher toutes les recommandations.
L'onglet "Recommandations" répertorie toutes les recommandations disponibles pour votre projet.
Dans le panneau Optimiser le coût des charges de travail BigQuery, cliquez sur Tout afficher.
La table des recommandations de coûts répertorie toutes les recommandations générées pour le projet en cours. Par exemple, la capture d'écran suivante montre que l'outil de recommandation a analysé la table
example_table, puis qu'il a recommandé de mettre en cluster la colonneexample_columnpour économiser une quantité approximative d'octets et d'emplacements.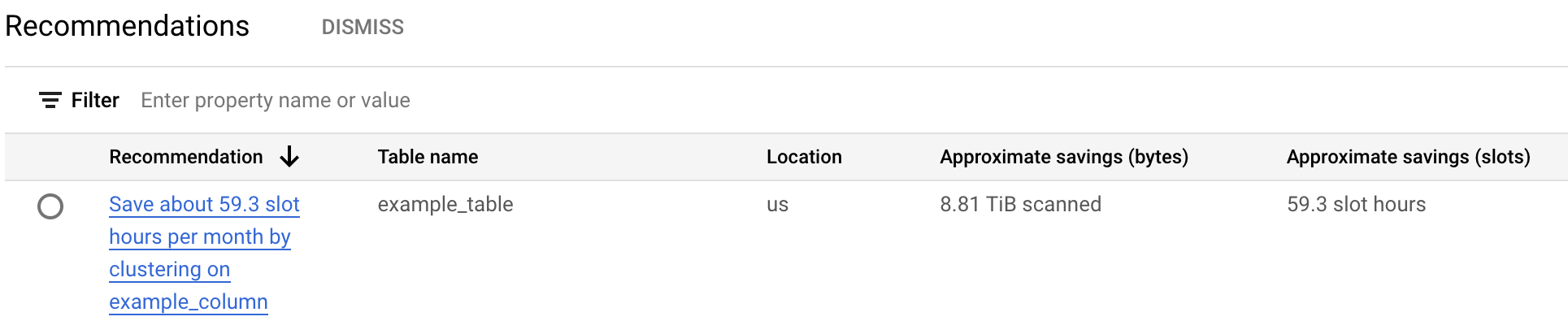
Pour afficher plus d'informations sur les recommandations et insights de la table, cliquez sur une recommandation.
Pour afficher les recommandations de partition ou de cluster pour un projet spécifique, utilisez la commande gcloud recommender recommendations list :
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Remplacez les éléments suivants :
PROJECT_NAME: nom du projet contenant votre table BigQuery.REGION_NAME: région dans laquelle se trouve votre projetFORMAT_TYPE: format de sortie gcloud CLI compatible (par exemple, JSON)
| Propriété | Pertinent pour le sous-type | Description |
|---|---|---|
recommenderSubtype |
Partition ou cluster | Indique le type de recommandation. |
content.overview.partitionColumn |
Partition | Nom de colonne de partitionnement recommandé. |
content.overview.partitionTimeUnit |
Partition | Unité de temps de partitionnement recommandée. Par exemple, DAY signifie que la recommandation consiste à avoir des partitions quotidiennes sur la colonne recommandée. |
content.overview.clusterColumns |
Cluster | Noms de colonnes de clustering recommandés. |
- Pour en savoir plus sur les autres champs dans la réponse de l'outil de recommandation, consultez la section Ressource REST :
projects.locations.recommendersrecommendation. - Pour en savoir plus sur l'utilisation de l'API Recommender, consultez la section Utiliser l'API - Recommandations.
Pour afficher les insights de tables à l'aide de gcloud CLI, exécutez la commande gcloud recommender insights list :
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Remplacez les éléments suivants :
PROJECT_NAME: nom du projet contenant votre table BigQuery.REGION_NAME: région dans laquelle se trouve votre projetFORMAT_TYPE: format de sortie gcloud CLI compatible (par exemple, JSON)
| Propriété | Pertinent pour le sous-type | Description |
|---|---|---|
content.existingPartitionColumn |
Cluster | Colonne de partitionnement existante, le cas échéant |
content.tableSizeTb |
Tout | Taille de la table en téraoctets |
content.bytesReadMonthly |
Tout | Octets lus depuis la table par mois |
content.slotMsConsumedMonthly |
Tout | Millisecondes d'emplacement consommées par la charge de travail exécutée sur la table par mois |
content.queryJobsCountMonthly |
Tout | Nombre de jobs exécutés sur la table par mois |
- Pour en savoir plus sur les autres champs dans la réponse des insights, consultez la section Ressource REST :
projects.locations.insightTypes.insights. - Pour en savoir plus sur l'utilisation des insights, consultez la section Utiliser l'API - Insights.
Pour afficher les recommandations de partition ou de cluster pour un projet spécifique, utilisez l'API REST. Avec chaque commande, vous devez fournir un jeton d'authentification, que vous pouvez obtenir à l'aide de gcloud CLI. Pour en savoir plus sur l'obtention d'un jeton d'authentification, consultez la section Méthodes d'obtention d'un jeton d'ID.
Vous pouvez utiliser la requête curl list pour afficher toutes les recommandations pour un projet spécifique :
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN "
-H "x-goog-user-project: PROJECT_NAME " https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Remplacez les éléments suivants :
GCLOUD_AUTH_TOKEN: nom d'un jeton d'accès gcloud CLI validePROJECT_NAME: nom du projet contenant votre table BigQuery
| Propriété | Pertinent pour le sous-type | Description |
|---|---|---|
recommenderSubtype |
Partition ou cluster | Indique le type de recommandation. |
content.overview.partitionColumn |
Partition | Nom de colonne de partitionnement recommandé. |
content.overview.partitionTimeUnit |
Partition | Unité de temps de partitionnement recommandée. Par exemple, DAY signifie que la recommandation consiste à avoir des partitions quotidiennes sur la colonne recommandée. |
content.overview.clusterColumns |
Cluster | Noms de colonnes de clustering recommandés. |
- Pour en savoir plus sur les autres champs dans la réponse de l'outil de recommandation, consultez la section Ressource REST :
projects.locations.recommendersrecommendation. - Pour en savoir plus sur l'utilisation de l'API Recommender, consultez la section Utiliser l'API - Recommandations.
Pour afficher les insights de la table à l'aide de l'API REST, exécutez la commande suivante :
curl -H "Authorization: Bearer$GCLOUD_AUTH_TOKEN " -H "x-goog-user-project:PROJECT_NAME " https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Remplacez les éléments suivants :
GCLOUD_AUTH_TOKEN: nom d'un jeton d'accès gcloud CLI validePROJECT_NAME: nom du projet contenant votre table BigQuery
| Propriété | Pertinent pour le sous-type | Description |
|---|---|---|
content.existingPartitionColumn |
Cluster | Colonne de partitionnement existante, le cas échéant |
content.tableSizeTb |
Tout | Taille de la table en téraoctets |
content.bytesReadMonthly |
Tout | Octets lus depuis la table par mois |
content.slotMsConsumedMonthly |
Tout | Millisecondes d'emplacement consommées par la charge de travail exécutée sur la table par mois |
content.queryJobsCountMonthly |
Tout | Nombre de jobs exécutés sur la table par mois |
- Pour en savoir plus sur les autres champs dans la réponse des insights, consultez la section Ressource REST :
projects.locations.insightTypes.insights. - Pour en savoir plus sur l'utilisation des insights, consultez la section Utiliser l'API - Insights.
Appliquer des recommandations de cluster
Pour appliquer des recommandations de cluster, procédez comme suit :
- Appliquer des clusters directement à la table d'origine
- Appliquer des clusters à une table copiée
- Appliquer des clusters dans une vue matérialisée
Appliquer des clusters directement à la table d'origine
Vous pouvez directement appliquer des recommandations de cluster à une table BigQuery existante. Cette méthode est plus rapide que d'appliquer des recommandations à une table copiée, mais elle ne conserve pas de table de sauvegarde.
Suivez ces étapes pour appliquer une nouvelle spécification de clustering à des tables non partitionnées ou partitionnées.
Dans l'outil bq, mettez à jour la spécification de clustering de votre table pour qu'elle corresponde au nouveau clustering :
bq update --clustering_fields=
CLUSTER_COLUMN DATASET .ORIGINAL_TABLE Remplacez les éléments suivants :
CLUSTER_COLUMN: colonne sur laquelle vous effectuez le clustering, par exemplemycolumnDATASET: nom de l'ensemble de données contenant la table, par exemplemydatasetORIGINAL_TABLE: nom de votre table d'origine, par exemplemytable
Vous pouvez également appeler la méthode API
tables.updateoutables.patchpour modifier la spécification du clustering.Pour mettre en cluster toutes les lignes conformément à la nouvelle spécification de clustering, exécutez l'instruction
UPDATEsuivante :UPDATE
DATASET .ORIGINAL_TABLE SETCLUSTER_COLUMN =CLUSTER_COLUMN WHERE true
Appliquer des clusters à une table copiée
Lorsque vous appliquez des recommandations de cluster à une table BigQuery, vous pouvez d'abord copier la table d'origine, puis appliquer la recommandation à la table copiée. Cette méthode garantit que vos données d'origine sont conservées si vous devez annuler la modification de la configuration de clustering.
Cette méthode vous permet d'appliquer des recommandations de cluster aux tables non partitionnées et aux tables partitionnées.
Dans la console Google Cloud, accédez à la page "BigQuery".
Dans l'éditeur de requête, créez une table vide avec les mêmes métadonnées (y compris les spécifications de clustering) de la table d'origine à l'aide de l'opérateur
LIKE:CREATE TABLE
DATASET .COPIED_TABLE LIKEDATASET .ORIGINAL_TABLE Remplacez les éléments suivants :
DATASET: nom de l'ensemble de données contenant la table, par exemplemydatasetCOPIED_TABLE: nom de votre table copiée, par exemplecopy_mytableORIGINAL_TABLE: nom de votre table d'origine, par exemplemytable
Dans la console Google Cloud, ouvrez l'éditeur Cloud Shell.
Dans l'éditeur Cloud Shell, mettez à jour la spécification de clustering de la table copiée pour qu'elle corresponde au clustering recommandé à l'aide de la commande
bq update:bq update --clustering_fields=
CLUSTER_COLUMN DATASET .COPIED_TABLE Remplacez
CLUSTER_COLUMNpar la colonne sur laquelle vous effectuez le clustering, par exemplemycolumn.Vous pouvez également appeler la méthode API
tables.updateoutables.patchpour modifier la spécification du clustering.Dans l'éditeur de requête, récupérez le schéma de table avec la configuration de partitionnement et de clustering de la table d'origine, si un partitionnement ou un clustering existe. Vous pouvez récupérer le schéma en affichant la vue
INFORMATION_SCHEMA.TABLESde la table d'origine :SELECT ddl FROM
DATASET .INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET .ORIGINAL_TABLE ;'Le résultat est l'instruction LDD (langage de définition de données) complète de ORIGINAL_TABLE, y compris la clause
PARTITION BY. Pour en savoir plus sur les arguments de votre sortie LDD, consultez la section InstructionCREATE TABLE.Le résultat LDD indique le type de partitionnement dans la table d'origine :
Type de partitionnement Exemple de sortie Non partitionnée La clause PARTITION BYest absente.Partitionnée par colonne de table PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Partitionnée par date d'ingestion PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Ingérez les données dans la table copiée. Le processus à utiliser dépend du type de partition.
- Si la table d'origine n'est pas partitionnée ou partitionnée par une colonne de table, ingérez les données de la table d'origine dans la table copiée :
INSERT INTO
DATASET .COPIED_TABLE SELECT * FROMDATASET .ORIGINAL_TABLE Si la table d'origine est partitionnée par date d'ingestion, procédez comme suit :
Récupérez la liste des colonnes pour former l'expression d'ingestion de données à l'aide de la vue
INFORMATION_SCHEMA.COLUMNS:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM
DATASET .INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE ')), ", ")La sortie est une liste de noms de colonnes séparés par une virgule.
Ingérez les données de la table d'origine dans la table de copie :
INSERT
DATASET .COPIED_TABLE (COLUMN_NAMES , _PARTITIONTIME) SELECT *, _PARTITIONTIME FROMDATASET .ORIGINAL_TABLE Remplacez
COLUMN_NAMESpar la liste des colonnes en sortie de l'étape précédente, séparées par une virgule (par exemple,col1, col2, col3).
Vous disposez maintenant d'une table de copie en cluster avec les mêmes données que la table d'origine. Dans les étapes suivantes, vous allez remplacer votre table d'origine par une nouvelle table en cluster.
- Si la table d'origine n'est pas partitionnée ou partitionnée par une colonne de table, ingérez les données de la table d'origine dans la table copiée :
Renommez la table d'origine en table de sauvegarde :
ALTER TABLE
DATASET .ORIGINAL_TABLE RENAME TODATASET .BACKUP_TABLE Remplacez
BACKUP_TABLEpar le nom de votre table de sauvegarde, par exemplebackup_mytable.Renommez la table de copie en table d'origine :
ALTER TABLE
DATASET .COPIED_TABLE RENAME TODATASET .ORIGINAL_TABLE Votre table d'origine est maintenant mise en cluster conformément à la recommandation de cluster.
- Les accès et autorisations, tels que les autorisations IAM, l'accès au niveau des lignes ou l'accès au niveau des colonnes.
- Les artefacts de table, tels que les clones de table, les instantanés de table ou les index de recherche.
- L'état de tous les processus de table en cours, tels que les vues matérialisées ou les jobs exécutés lors de la copie de la table.
- La possibilité d'accéder aux données historiques des tables à l'aide des fonctionnalités temporelles.
- Toutes les métadonnées associées à la table d'origine, par exemple
table_option_listoucolumn_option_list. Pour en savoir plus, consultez la section Instructions de langage de définition des données.
Si des problèmes surviennent, vous devez migrer manuellement les artefacts concernés vers la nouvelle table.
Après avoir examiné la table en cluster, vous pouvez éventuellement supprimer la table de sauvegarde à l'aide de la commande suivante :DROP TABLEDATASET .BACKUP_TABLE
Appliquer des clusters dans une vue matérialisée
Vous pouvez créer une vue matérialisée de la table pour stocker les données de la table d'origine avec la recommandation appliquée. L'utilisation de vues matérialisées pour appliquer des recommandations garantit la tenue à jour des données en cluster à l'aide d'actualisations automatiques. Lorsque vous interrogez, gérez et stockez des vues matérialisées, il existe des considérations tarifaires à prendre en compte. Pour savoir comment créer une vue matérialisée en cluster, consultez la section Vues matérialisées en cluster.Appliquer des recommandations de partition
Pour appliquer des recommandations de partition, vous devez les appliquer à une copie de la table d'origine. BigQuery ne permet pas de modifier le schéma de partitionnement d'une table en place, par exemple en convertissant une table non partitionnée en table partitionnée, en modifiant le schéma de partitionnement d'une table ou en créant une vue matérialisée avec un schéma de partitionnement différent de celui de la table de base. Vous ne pouvez modifier le partitionnement d'une table que sur une copie de la table.
Appliquer des recommandations de partition à une table copiée
Lorsque vous appliquez des recommandations de partition à une table BigQuery, vous pouvez d'abord copier la table d'origine, puis appliquer la recommandation à la table copiée. Cette approche garantit que vos données d'origine sont conservées si vous devez effectuer un rollback d'une partition.
La procédure suivante utilise un exemple de recommandation pour partitionner une table en fonction de l'unité de temps DAY.
Créez une table copiée à l'aide des recommandations de partition :
CREATE TABLE
DATASET .COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN , DAY) AS SELECT * FROMDATASET .ORIGINAL_TABLE Remplacez les éléments suivants :
DATASET: nom de l'ensemble de données contenant la table, par exemplemydatasetCOPIED_TABLE: nom de votre table copiée, par exemplecopy_mytablePARTITION_COLUMN: colonne sur laquelle vous effectuez le partitionnement, par exemplemycolumn.
Pour plus d'informations sur la création de tables partitionnées, consultez la section Créer des tables partitionnées.
Renommez la table d'origine en table de sauvegarde :
ALTER TABLE
DATASET .ORIGINAL_TABLE RENAME TODATASET .BACKUP_TABLE Remplacez
BACKUP_TABLEpar le nom de votre table de sauvegarde, par exemplebackup_mytable.Renommez la table de copie en table d'origine :
ALTER TABLE
DATASET .COPIED_TABLE RENAME TODATASET .ORIGINAL_TABLE Votre table d'origine est maintenant partitionnée conformément à la recommandation de partition.
- Les accès et autorisations, tels que les autorisations IAM, l'accès au niveau des lignes ou l'accès au niveau des colonnes.
- Les artefacts de table, tels que les clones de table, les instantanés de table ou les index de recherche.
- L'état de tous les processus de table en cours, tels que les vues matérialisées ou les jobs exécutés lors de la copie de la table.
- La possibilité d'accéder aux données historiques des tables à l'aide des fonctionnalités temporelles.
- Toutes les métadonnées associées à la table d'origine, par exemple
table_option_listoucolumn_option_list. Pour en savoir plus, consultez la section Instructions de langage de définition des données. - La possibilité d'utiliser l'ancien SQL pour écrire des résultats de requête dans des tables partitionnées. L'utilisation de l'ancien SQL n'est pas totalement compatible avec les tables partitionnées. Une solution consiste à migrer vos workflows en l'ancien SQL vers GoogleSQL avant d'appliquer une recommandation de partition.
Si des problèmes surviennent, vous devez migrer manuellement les artefacts concernés vers la nouvelle table.
Après avoir examiné la table partitionnée, vous pouvez éventuellement supprimer la table de sauvegarde à l'aide de la commande suivante :DROP TABLEDATASET .BACKUP_TABLE
Tarifs
Pour en savoir plus sur les tarifs de cette fonctionnalité, consultez la section Présentation des tarifs de Gemini dans BigQuery.
L'application d'une recommandation à une table peut entraîner les coûts suivants :- Coûts de traitement. Lorsque vous appliquez une recommandation, vous exécutez une requête LDD (langage de définition de données) ou LMD (langage de manipulation de données) sur votre projet BigQuery.
- Coûts de stockage. Si vous utilisez la méthode de copie d'une table, vous utilisez de l'espace de stockage supplémentaire pour la table copiée (ou de sauvegarde).
Les frais de traitement et de stockage standards s'appliquent en fonction du compte de facturation associé au projet. Pour en savoir plus, consultez la page relative aux tarifs de BigQuery.
Quotas et limites
Pour en savoir plus sur les quotas et les limites de cette fonctionnalité, consultez la page Quotas pour Gemini dans BigQuery.
Dépannage
Problème : aucune recommandation n'apparaît pour une table spécifique.
Les recommandations de partitionnement peuvent ne pas s'afficher pour les tables qui répondent aux critères suivants:
- La table est inférieure à 100 Go.
- La table est déjà partitionnée ou mise en cluster.
Les recommandations de clusters peuvent ne pas s'afficher pour les tableaux qui répondent aux critères suivants:
- La taille de la table est inférieure à 10 Go.
- La table est déjà en cluster.
Les recommandations de partitionnement et de clustering peuvent être supprimées dans les cas suivants:
- La table présente un coût d'écriture élevé pour les opérations du langage de manipulation de données (LMD).
- La table n'a pas été lue au cours des 30 derniers jours.
- Les économies mensuelles estimées sont trop faibles (moins d'une heure d'économies par emplacement).