Présentation des tables en cluster
Les tables en cluster dans BigQuery sont des tables dont l'ordre de tri est défini par l'utilisateur à l'aide de colonnes en cluster. Les tables en cluster peuvent améliorer les performances des requêtes et réduire leurs coûts.
Dans BigQuery, une colonne groupée est une propriété de table définie par l'utilisateur qui trie les blocs de stockage en fonction des valeurs des colonnes en cluster. Les blocs de stockage sont dimensionnés de manière adaptative en fonction de la taille de la table. La colocation se produit au niveau des blocs de stockage, et non au niveau des lignes individuelles. Pour en savoir plus sur la colocation dans ce contexte, consultez la section Clustering (Clustering).
Une table en cluster conserve les propriétés de tri dans le contexte de chaque opération qui la modifie. Les requêtes qui filtrent ou agrégent les colonnes en cluster analysent uniquement les blocs pertinents en fonction des colonnes en cluster, et non l'intégralité de la table ou de la partition de la table. Par conséquent, BigQuery risque de ne pas pouvoir estimer avec précision les octets à traiter par la requête ni les coûts de la requête, mais il tente de réduire le nombre total d'octets lors de l'exécution.
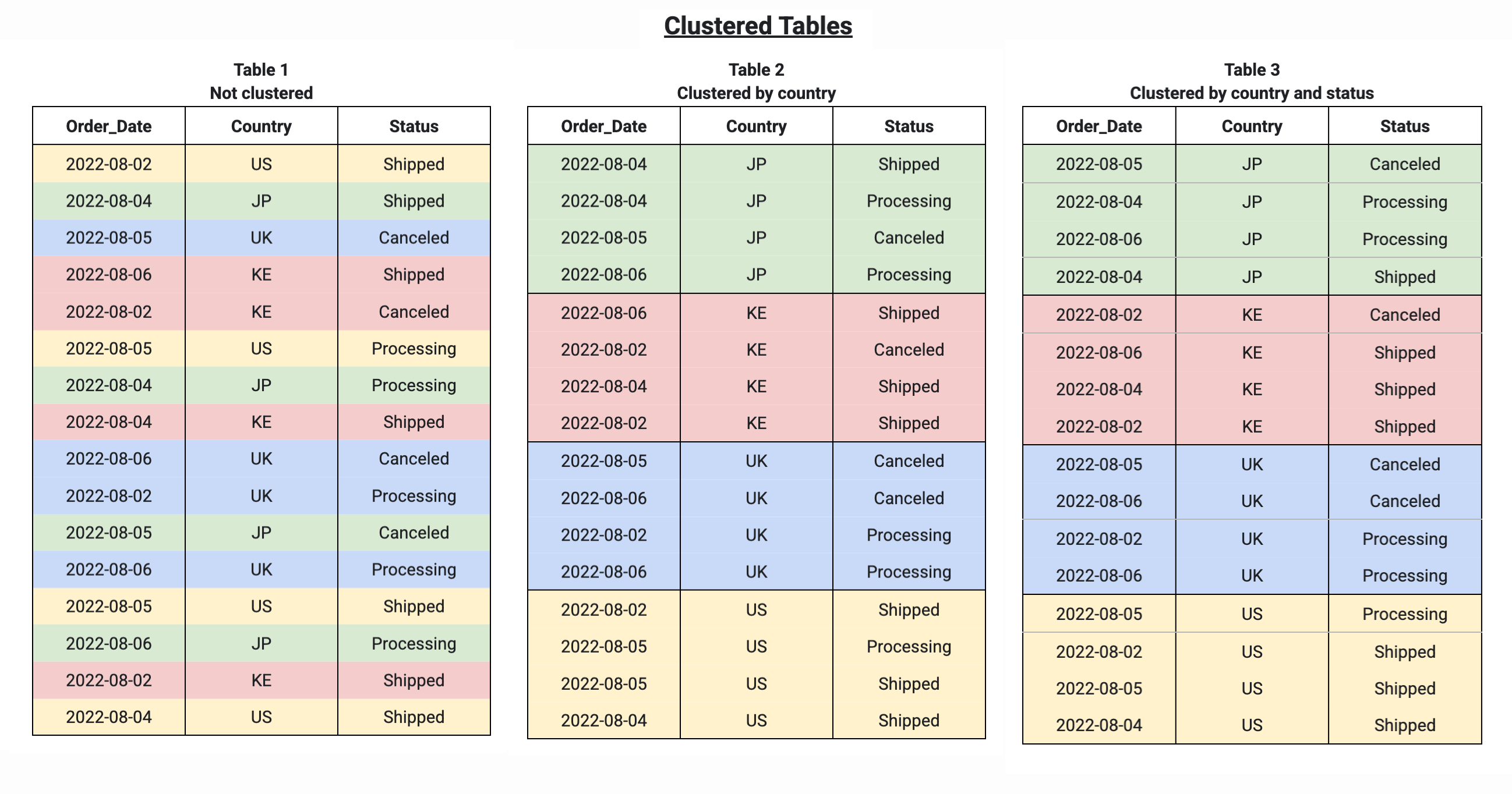
Lorsque vous mettez une table en cluster à l'aide de plusieurs colonnes, l'ordre des colonnes détermine lesquelles sont prioritaires lorsque BigQuery trie et regroupe les données dans des blocs de stockage, comme illustré dans l'exemple suivant. Le tableau 1 présente la disposition des blocs de stockage logiques d'une table non clustée. En comparaison, la table 2 n'est mise en cluster que par la colonne Country, tandis que la table 3 est mise en cluster par plusieurs colonnes, Country et Status.
Lorsque vous interrogez une table en cluster, vous ne recevez pas d'estimation précise du coût de la requête avant son exécution, car le nombre de blocs de stockage à analyser n'est pas connu avant l'exécution de la requête. Le coût final est déterminé une fois l'exécution de la requête terminée et est basé sur les blocs de stockage spécifiques qui ont été analysés.
Quand utiliser le clustering
Étant donné que le clustering traite le stockage d'une table, il s'agit généralement d'une bonne option pour améliorer les performances des requêtes. Par conséquent, vous devez toujours envisager de procéder au clustering en raison des avantages suivants :
- Les tables non partitionnées de plus de 64 Mo sont susceptibles de bénéficier du clustering. De même, les partitions de tables de plus de 64 Mo sont également susceptibles de bénéficier du clustering. Il est possible de mettre en cluster de petites tables ou partitions, mais l'amélioration des performances est généralement négligeable.
- Si vos requêtes filtrent couramment sur des colonnes particulières, le clustering accélère les requêtes, car celles-ci n'analysent que les blocs correspondant au filtre.
- Si vos requêtes filtrent des colonnes ayant de nombreuses valeurs distinctes (cardinalité élevée), le clustering accélère ces requêtes en fournissant à BigQuery des métadonnées détaillées permettant d'obtenir les données d'entrée.
- Le clustering permet de dimensionner de manière adaptative les blocs de stockage sous-jacents de votre table en fonction de sa taille.
Vous pouvez envisager de partitionner votre table en plus du clustering. Dans cette approche, vous segmentez d'abord les données en partitions, puis vous regroupez les données de chaque partition en fonction des colonnes de clustering. Envisagez cette approche dans les cas suivants :
- Vous avez besoin d'une estimation stricte du coût des requêtes avant de les exécuter. Le coût des requêtes sur les tables en cluster ne peut être déterminé qu'après l'exécution de la requête. Le partitionnement fournit des estimations précises du coût des requêtes avant leur exécution.
- Le partitionnement de votre table entraîne une taille de partition moyenne d'au moins 10 Go par partition. La création de nombreuses petites partitions augmente les métadonnées de la table et peut affecter les temps d'accès aux métadonnées lors de l'interrogation de la table.
- Vous devez mettre à jour votre table en permanence, mais vous souhaitez tout de même profiter des tarifs de stockage à long terme. Le partitionnement permet de prendre en compte chaque partition individuellement pour l'éligibilité à une tarification à long terme. Si votre table n'est pas partitionnée, votre table entière ne doit pas être modifiée pendant 90 jours consécutifs pour être prise en compte pour les tarifs à long terme.
Pour en savoir plus, consultez la section Combiner des tables partitionnées et en cluster.
Types et ordre des colonnes en cluster
Cette section décrit les types de colonnes et le fonctionnement de l'ordre des colonnes dans le clustering de tables.
Types de colonnes en cluster
Les colonnes de cluster doivent être des colonnes uniques de premier niveau, de l'un des types suivants :
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
Pour en savoir plus sur les types de données, consultez la section Types de données GoogleSQL.
Ordre des colonnes du cluster
L'ordre des colonnes en cluster affecte les performances des requêtes. Pour bénéficier du clustering, l'ordre des filtres de requête doit correspondre à l'ordre des colonnes groupées et inclure au moins la première colonne en cluster.
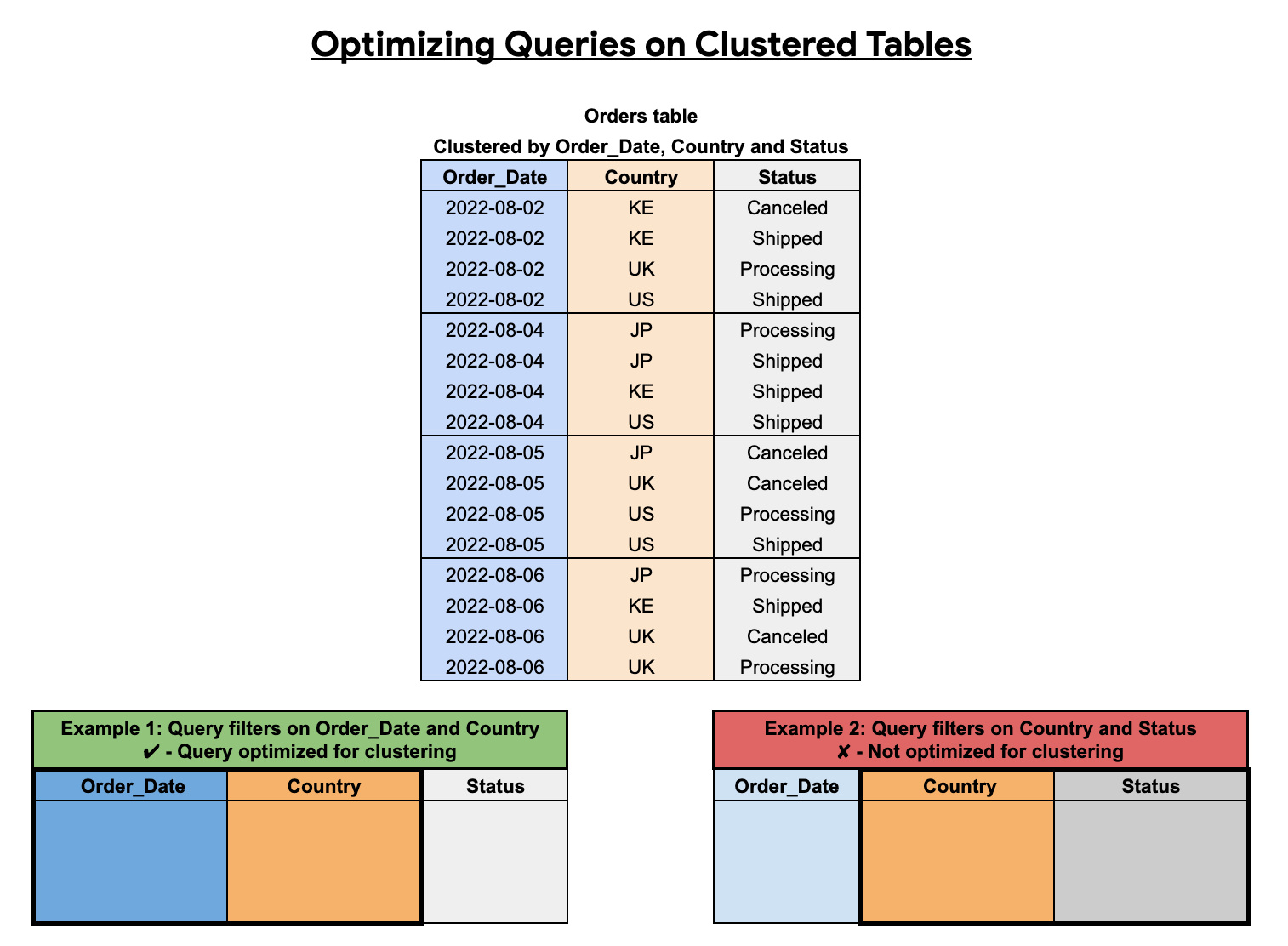
Dans l'exemple suivant, la table "Orders" est mise en cluster à l'aide d'un ordre de tri de colonne Order_Date, Country et Status. La première colonne en cluster de cet exemple est Order_Date. Par conséquent, une requête qui filtre sur Order_Date et Country est optimisée pour le clustering, tandis qu'une requête qui ne filtre que sur Country et Status n'est pas optimisée. Pour optimiser les résultats du clustering, vous devez filtrer les colonnes groupées dans l'ordre en commençant par la première.
Élimination en bloc
Pour vous aider à réduire le coût des requêtes, les tables en cluster éliminent des données de façon qu'elles ne soient pas traitées par les requêtes. Ce processus est appelé "élimination en bloc". BigQuery trie les données d'une table groupée en fonction des valeurs des colonnes de clustering, puis les organise en blocs.
Lorsque vous exécutez une requête sur une table groupée et qu'elle inclut un filtre sur les colonnes groupées, BigQuery utilise l'expression de filtre et les métadonnées de bloc pour restreindre le nombre de blocs analysés par la requête. Cela permet à BigQuery d'analyser uniquement les blocs pertinents.
Lorsqu'un bloc est éliminé, il n'est pas analysé. Seuls les blocs analysés sont pris en compte pour calculer les octets de données traités par la requête. Le nombre d'octets traités par une requête sur une table en cluster est égal à la somme des octets lus dans chaque colonne référencée par la requête dans les blocs analysés.
Si une table en cluster est référencée à de multiples reprises dans une requête qui utilise plusieurs filtres, BigQuery facture l'analyse des colonnes des blocs appropriés de chacun des filtres respectifs. Pour voir un exemple de fonctionnement de l'élagage de blocs, consultez la section Exemple.
Combiner des tables en cluster et partitionnées
Vous pouvez combiner le clustering et le partitionnement de table pour effectuer un tri précis afin d'optimiser davantage les requêtes.
Dans une table partitionnée, les données sont stockées dans des blocs physiques, chacun contenant une partition de données. Chaque table partitionnée conserve diverses métadonnées relatives aux propriétés de tri pour toutes les opérations qui la modifient. Les métadonnées permettent à BigQuery d'estimer plus précisément le coût d'une requête avant son exécution. Cependant, le partitionnement nécessite que BigQuery gère plus de métadonnées qu'avec une table non partitionnée. À mesure que le nombre de partitions augmente, la quantité de métadonnées à maintenir augmente.
Lorsque vous créez une table en cluster et partitionnée, vous pouvez effectuer un tri plus précis, comme le montre le schéma suivant :

Exemple
Vous disposez d'une table groupée nommée ClusteredSalesData. La table est partitionnée en fonction de la colonne timestamp. Elle est par ailleurs mise en clusters par la colonne customer_id. Les données sont organisées dans l'ensemble de blocs suivant :
| Identifiant de partition | ID de bloc | Valeur minimale pour customer_id dans le bloc | Valeur maximale pour customer_id dans le bloc |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
Vous exécutez la requête suivante sur la table. La requête contient un filtre sur la colonne customer_id.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
La requête précédente implique les étapes suivantes:
- analyse les colonnes
timestamp,customer_idettotalSaledans les blocs B2 et B4 ; - élimine le bloc B3 en raison du prédicat de filtre
DATE(timestamp) = "2016-05-01"sur la colonne de partitionnementtimestamp; - élimine le bloc B1 en raison du prédicat de filtre
customer_id BETWEEN 20000 AND 23000sur la colonne de clusteringcustomer_id.
Reclustering automatique
Lorsque des données sont ajoutées à une table groupée, les nouvelles données sont organisées en blocs, ce qui peut créer des blocs de stockage ou modifier des blocs existants. L'optimisation des blocs est requise pour des performances de requête et de stockage optimales, car les nouvelles données peuvent ne pas être regroupées avec des données existantes ayant les mêmes valeurs de cluster.
Pour conserver les caractéristiques de performance d'une table groupée, BigQuery effectue un reclustering automatique en arrière-plan. Pour les tables partitionnées, le clustering est maintenu pour les données comprises dans le champ d'application de chaque partition.
Limites
- Seul le langage GoogleSQL est compatible avec l'interrogation de tables en cluster et avec l'écriture des résultats de requête dans des tables en cluster.
- Un maximum de quatre colonnes de clustering peut être spécifié. Si vous avez besoin de colonnes supplémentaires, envisagez de combiner le clustering avec le partitionnement.
- Lorsque vous utilisez des colonnes de type
STRINGpour le clustering, BigQuery n'utilise que les 1 024 premiers caractères pour mettre en cluster les données. Les valeurs des colonnes peuvent elles-mêmes être supérieures à 1 024. - Si vous modifiez une table hors cluster existante pour la mise en cluster, les données existantes ne sont pas automatiquement mises en cluster. Seules les nouvelles données stockées à l'aide des colonnes en cluster sont soumises au reclustering automatique. Pour en savoir plus sur le reclustering de données existantes à l'aide d'une instruction
UPDATE, consultez la page Modifier la spécification du clustering.
Quotas et limites des tables en cluster
BigQuery limite l'utilisation des Google Cloud ressources partagées avec des quotas et limites, y compris des limites sur certaines opérations de table ou le nombre de jobs exécutés dans une journée.
Lorsque vous utilisez la fonctionnalité de table en cluster avec une table partitionnée, vous êtes soumis aux limites imposées sur les tables partitionnées.
Les quotas et les limites s'appliquent également aux différents types de jobs que vous pouvez exécuter sur des tables en cluster. Pour plus d'informations sur les quotas de jobs qui s'appliquent à vos tables, consultez la section Jobs de la page "Quotas et limites".
Tarifs des tables groupées
Lorsque vous créez et utilisez des tables en cluster dans BigQuery, les frais sont basés sur le volume de données stockées dans les tables et sur les requêtes que vous exécutez sur les données. Pour en savoir plus, consultez les sections Tarifs du stockage et Tarifs des requêtes.
Comme les autres opérations de table BigQuery, les opérations de table en cluster tirent parti des opérations gratuites de BigQuery telles que le chargement par lot, la copie de table, le reclustering automatique et l'exportation de données. Ces opérations sont toutefois soumises aux quotas et limites BigQuery. Pour plus d'informations sur les opérations gratuites, consultez la section Opérations gratuites.
Pour obtenir un exemple détaillé de tarif de tables groupées, consultez la section Estimer les coûts du stockage et des requêtes.
Sécurité des tables
Pour savoir comment contrôler l'accès aux tables dans BigQuery, consultez la page Présentation des contrôles d'accès aux tables.
Étapes suivantes
- Pour apprendre à créer et à utiliser des tables en cluster, consultez la page Créer et utiliser des tables en cluster.
- Pour en savoir plus sur l'interrogation de tables en cluster, consultez la page Interroger des tables en cluster.