在表架构中指定嵌套和重复的列
本页面介绍如何在 BigQuery 中定义具有嵌套和重复列的表架构。如需大致了解表架构,请参阅指定架构。
定义嵌套和重复的列
要创建包含嵌套数据的列,请在架构中将列的数据类型设置为 RECORD。RECORD 可以在 GoogleSQL 中作为 STRUCT 类型进行访问。STRUCT 存储有序字段。
要创建包含重复数据的列,请在架构中将列的模式设置为 REPEATED。重复字段可以在 GoogleSQL 中作为 ARRAY 类型进行访问。
RECORD 列可以使用 REPEATED 模式,该模式表示为 STRUCT 类型的数组。此外,记录中的字段可以重复,表示为包含 ARRAY 的 STRUCT。数组不能直接包含另一个数组。如需了解详情,请参阅声明 ARRAY 类型。
限制
嵌套和重复的架构存在以下限制:
- 一个架构最多支持 15 层嵌套的
RECORD类型。 RECORD类型的列可以包含嵌套的RECORD类型(也称为子记录)。嵌套深度上限为 15 层。此限制与RECORD是基于标量还是基于数组(重复)无关。
RECORD 类型与 UNION、INTERSECT、EXCEPT DISTINCT 和 SELECT DISTINCT 不兼容。
示例架构
以下显示了嵌套和重复数据的示例。此表包含有关人员的信息。其中包含以下字段:
idfirst_namelast_namedob(出生日期)addresses(嵌套和重复的字段)addresses.status(目前或之前的状态)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(在此地址居住的年数)
JSON 数据文件如下所示。请注意,addresses 列包含一个值数组(以 [ ] 表示)。该数组中的多个地址是重复数据。各地址中的多个字段是嵌套数据。
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
此表的架构如下所示:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
在示例中指定嵌套和重复的列
如需使用先前嵌套和重复的列创建新表,请选择以下选项之一:
控制台
指定嵌套和重复的 addresses 列:
在 Google Cloud 控制台中,打开 BigQuery 页面。
在左侧窗格中,点击 Explorer:

如果您没有看到左侧窗格,请点击 展开左侧窗格以打开该窗格。
在浏览器窗格中,展开您的项目,点击数据集,然后选择一个数据集。
在“详细信息”窗格中,点击 创建表。
在创建表页面上,指定以下详细信息:
- 对于来源,在基于以下数据创建表字段中,选择空表。
在目标位置部分中,指定以下字段:
- 在数据集部分中,选择要在其中创建表的数据集。
- 在表部分中,输入您要创建的表的名称。
在架构部分中,点击 添加字段并输入以下表架构:
- 对于字段名称,输入
addresses。 - 对于类型,选择记录。
- 在模式部分中,选择重复。
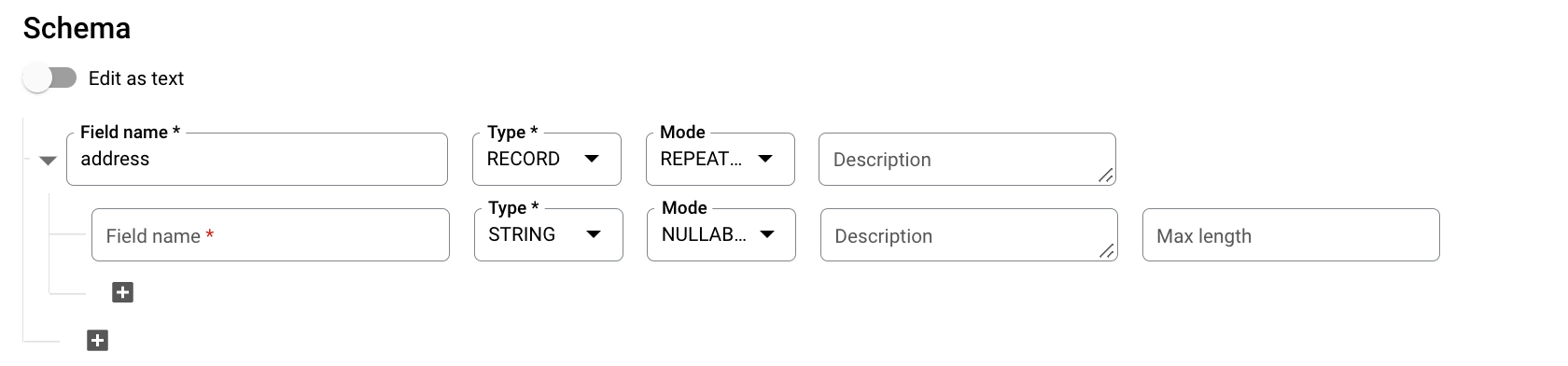
对于嵌套的字段,指定以下字段:
- 在字段名称字段中,输入
status。 - 在类型部分中,选择字符串。
- 在模式部分中,让保留设置的值可以为 Null。
点击 添加字段以添加以下字段:
字段名称 类型 模式 addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
您还可以点击以文本形式修改,并以 JSON 数组形式指定架构。
- 在字段名称字段中,输入
- 对于字段名称,输入
SQL
使用 CREATE TABLE 语句。使用列选项指定架构:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
bq
要在 JSON 架构文件中指定嵌套和重复的 addresses 列,请使用文本编辑器创建新文件。粘贴上述示例架构定义。
创建 JSON 架构文件后,您可以通过 bq 命令行工具提供此文件。如需了解详情,请参阅使用 JSON 架构文件。
Go
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Go 设置说明进行操作。 如需了解详情,请参阅 BigQuery Go API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Node.js
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Node.js 设置说明进行操作。 如需了解详情,请参阅 BigQuery Node.js API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
将数据插入示例中的嵌套列
使用以下查询将嵌套数据记录插入具有 RECORD 数据类型列的表中。
示例 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
示例 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
查询嵌套和重复的列
如需选择特定位置的 ARRAY 值,请使用数组子脚本运算符。如需访问 STRUCT 中的元素,请使用点运算符。以下示例选择名字、姓氏和 addresses 字段中列出的第一个地址:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
结果如下:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
如需提取 ARRAY 的所有元素,请将 UNNEST 运算符与 CROSS JOIN 搭配使用。以下示例为非纽约所有地址选择名字、姓氏、地址和州:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
结果如下:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
修改嵌套和重复的列
将嵌套列或嵌套和重复的列添加到表的架构定义后,您可以像修改其他任何类型的列一样修改此类列。BigQuery 本身支持多种架构更改,例如向记录添加新的嵌套字段或放宽嵌套字段的模式。如需了解详情,请参阅修改表架构。
何时使用嵌套和重复的列
在数据经过反规范化处理后,BigQuery 的执行效果最佳。与其保留星型或雪花型架构等关系型架构,不如对数据进行反规范化并利用嵌套和重复的字段。嵌套和重复的列可以维持关系,而不会由于保留关系型(标准化)架构产生性能影响。
例如,用于跟踪图书馆书籍的关系型数据库可能会将所有作者信息保存在单独的表中。您可以使用 author_id 之类的键将图书与作者关联起来。
在 BigQuery 中,您可以保留图书与作者之间的关系,而无需创建单独的作者表。您可以创建一个作者列,并将各种字段嵌套在其中,例如作者的名字、姓氏、出生日期等。如果一本书由多名作者合著,您可以使用重复的嵌套作者列。
假设您有下表 mydataset.books:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
此外您还有下表 mydataset.authors,其中包含每个作者 ID 的完整信息:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
如果这些表很大,定期联接这些表可能会占用大量资源。根据您的具体情况,创建包含所有信息的单个表可能会有所帮助:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
生成的表如下所示:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery 支持从支持基于对象的架构的源格式加载嵌套重复数据,例如 JSON 文件、Avro 文件、Firestore 导出文件和 Datastore 导出文件。
删除表中的重复记录
以下查询使用 row_number() 函数来识别示例中 last_name 和 first_name 值相同的重复记录,并按 dob 将其排序:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
表安全性
如需控制对 BigQuery 中的表的访问权限,请参阅使用 IAM 控制对资源的访问权限。
后续步骤
- 如需插入和更新具有嵌套和重复列的行,请参阅数据操纵语言语法。