Migración a BigQuery desde Amazon Redshift: descripción general
En este documento se ofrecen directrices para migrar de Amazon Redshift a BigQuery. Nos centraremos en los siguientes temas:
- Estrategias de migración
- Prácticas recomendadas para la optimización de consultas y el modelado de datos
- Consejos para solucionar problemas
- Guía de adopción por parte de los usuarios
Los objetivos de este documento son los siguientes:
- Ofrecer orientación general a las organizaciones que migran de Amazon Redshift a BigQuery, lo que incluye ayudarle a replantearse sus canalizaciones de datos para sacar el máximo partido a BigQuery.
- Te ayuda a comparar las arquitecturas de BigQuery y Amazon Redshift para que puedas determinar cómo implementar las funciones y las características durante la migración. El objetivo es mostrarte las nuevas funciones que tiene a tu disposición tu organización a través de BigQuery, no asignar funciones de forma individual con Amazon Redshift.
Este documento está dirigido a arquitectos empresariales, administradores de bases de datos, desarrolladores de aplicaciones y especialistas en seguridad informática. Se presupone que conoces Amazon Redshift.
También puedes usar la traducción de SQL por lotes para migrar tus secuencias de comandos SQL en bloque o la traducción de SQL interactiva para traducir consultas específicas. Los servicios de traducción de SQL admiten totalmente el SQL de Amazon Redshift.
Tareas previas a la migración
Para que la migración del almacén de datos se realice correctamente, empieza a planificar tu estrategia de migración al principio del proyecto. Este enfoque te permite evaluar las funciones que se adaptan a tus necesidades. Google Cloud
Planificación de la capacidad
BigQuery usa ranuras para medir el rendimiento de las analíticas. Las ranuras de BigQuery son las unidades de capacidad informática propias de Google que se necesitan para ejecutar consultas de SQL. BigQuery calcula continuamente cuántas ranuras necesitan las consultas a medida que se ejecutan, pero asigna ranuras a las consultas en función de un programador justo.
Puedes elegir entre los siguientes modelos de precios al planificar la capacidad de las ranuras de BigQuery:
- Precios bajo demanda: Con este modelo, BigQuery cobra por el número de bytes procesados (tamaño de los datos), por lo que solo pagas por las consultas que ejecutas. Para obtener más información sobre cómo determina BigQuery el tamaño de los datos, consulta la sección Cálculo del tamaño de los datos. Como las ranuras determinan la capacidad informática subyacente, puedes pagar por el uso de BigQuery en función del número de ranuras que necesites (en lugar de los bytes procesados). De forma predeterminada, todos losGoogle Cloud proyectos tienen un límite de 2000 ranuras. Para agilizar las consultas, BigQuery puede producir ráfagas que superen este límite, pero no se garantiza que se produzcan.
- Precios basados en la capacidad: con este modelo, compras reservas de ranuras de BigQuery (un mínimo de 100) en lugar de pagar por los bytes procesados por las consultas que ejecutas. Recomendamos la opción de precios basada en la capacidad para las cargas de trabajo de almacenes de datos empresariales, que suelen tener muchas consultas simultáneas de informes y de extracción, carga y transformación (ELT) con un consumo predecible.
Para ayudarte a estimar las ranuras, te recomendamos que configures la monitorización de BigQuery con Cloud Monitoring y que analices tus registros de auditoría con BigQuery. Puedes usar Looker Studio (aquí tienes un ejemplo de código abierto de un panel de control de Looker Studio) o Looker para visualizar los datos de registro de auditoría de BigQuery, concretamente el uso de ranuras en consultas y proyectos. También puedes usar los datos de las tablas de sistema de BigQuery para monitorizar la utilización de ranuras en las tareas y las reservas (aquí tienes un ejemplo de código abierto de un panel de Looker Studio). Monitorizar y analizar periódicamente el uso de las ranuras te ayuda a estimar cuántas ranuras necesita tu organización a medida que creces en Google Cloud.
Por ejemplo, supongamos que inicialmente reservas 4000 ranuras de BigQuery para ejecutar 100 consultas de complejidad media simultáneamente. Si observas tiempos de espera elevados en los planes de ejecución de tus consultas y tus paneles de control muestran una utilización de ranuras alta, puede que necesites más ranuras de BigQuery para admitir tus cargas de trabajo. Si quieres comprar slots por tu cuenta con compromisos anuales o trienales, puedes empezar a usar las reservas de BigQuery con laGoogle Cloud consola o la herramienta de línea de comandos bq. Para obtener más información sobre la gestión de cargas de trabajo, la ejecución de consultas y la arquitectura de BigQuery, consulta Migración a Google Cloud: análisis detallado.
Seguridad en Google Cloud
En las siguientes secciones se describen los controles de seguridad habituales de Amazon Redshift y cómo puedes asegurarte de que tu almacén de datos esté protegido en un entornoGoogle Cloud .
Gestión de identidades y accesos
Para configurar los controles de acceso en Amazon Redshift, debes escribir políticas de permisos de la API de Amazon Redshift y asociarlas a identidades de Gestión de Identidades y Accesos (IAM). Los permisos de la API de Amazon Redshift proporcionan acceso a nivel de clúster, pero no a niveles más granulares que el clúster. Si quiere tener un acceso más granular a recursos como tablas o vistas, puede usar cuentas de usuario en la base de datos de Amazon Redshift.
BigQuery usa la gestión de identidades y accesos para gestionar el acceso a los recursos de forma más granular. Los tipos de recursos disponibles en BigQuery son organizaciones, proyectos, conjuntos de datos, tablas, columnas y vistas. En la jerarquía de políticas de gestión de identidades y accesos, los conjuntos de datos son recursos secundarios de los proyectos. Una tabla hereda los permisos del conjunto de datos que la contiene.
Para conceder acceso a un recurso, asigna uno o varios roles de gestión de identidades y accesos a un usuario, un grupo o una cuenta de servicio. Los roles de organización y de proyecto afectan a la capacidad de ejecutar trabajos o gestionar el proyecto, mientras que los roles de conjunto de datos afectan a la capacidad de acceder a los datos de un proyecto o modificarlos.
IAM proporciona estos tipos de roles:
- Roles predefinidos: se han diseñado para admitir casos prácticos y patrones de control de acceso habituales.
- Roles personalizados: proporcionan acceso granular según una lista de permisos especificada por el usuario.
En Gestión de identidades y accesos, BigQuery ofrece control de acceso a nivel de tabla. Los permisos a nivel de tabla determinan los usuarios, grupos y cuentas de servicio que pueden acceder a una tabla o vista. Puedes dar acceso a un usuario a tablas o vistas específicas sin darle acceso al conjunto de datos completo. Para tener un acceso más granular, también puedes implementar uno o varios de los siguientes mecanismos de seguridad:
- El control de acceso a nivel de columna, que proporciona acceso pormenorizado a columnas sensibles mediante etiquetas de política o con una clasificación basada en tipos de datos.
- Máscara de datos dinámica a nivel de columna: te permite ocultar datos de las columnas a determinados grupos de usuarios, quienes podrán seguir accediendo a dichas columnas.
- La seguridad a nivel de fila, que le permite filtrar datos y acceder a filas específicas de una tabla en función de las condiciones de usuario que se cumplan.
Cifrado de disco completo
Además de la gestión de identidades y accesos, el cifrado de datos añade una capa adicional de defensa para proteger los datos. En caso de que los datos se expongan, los datos cifrados no se podrán leer.
En Amazon Redshift, el cifrado de los datos en reposo y en tránsito no está habilitado de forma predeterminada. El cifrado de los datos en reposo debe habilitarse explícitamente al iniciar un clúster o modificando un clúster para que use el cifrado del servicio de gestión de claves de AWS. El cifrado de los datos en tránsito también debe habilitarse explícitamente.
BigQuery cifra todos los datos en reposo y en tránsito de forma predeterminada, independientemente de la fuente o de cualquier otra condición, y esta opción no se puede desactivar. BigQuery también admite claves de cifrado gestionadas por el cliente (CMEK) si quieres controlar y gestionar las claves de cifrado de claves en Cloud Key Management Service.
Para obtener más información sobre el cifrado en Google Cloud, consulta los informes sobre el cifrado de datos en reposo y el cifrado de datos en tránsito.
En el caso de los datos en tránsito Google Cloud, estos se encriptan y autentican cuando salen de los límites físicos controlados por Google o en su nombre. Dentro de estos límites, los datos en tránsito suelen estar autenticados, pero no necesariamente encriptados.
Prevención de la pérdida de datos
Los requisitos de cumplimiento pueden limitar los datos que se pueden almacenar enGoogle Cloud. Puedes usar Protección de Datos Sensibles para analizar tus tablas de BigQuery y detectar y clasificar datos sensibles. Si se detectan datos sensibles, las transformaciones de desidentificación de Protección de Datos Sensibles pueden enmascarar, eliminar u ocultar de cualquier otra forma esos datos.
Migración a Google Cloud: conceptos básicos
En esta sección se explica cómo usar herramientas y pipelines para facilitar la migración.
Herramientas de migración
BigQuery Data Transfer Service proporciona una herramienta automatizada para migrar tanto el esquema como los datos de Amazon Redshift a BigQuery directamente. En la siguiente tabla se enumeran otras herramientas que pueden ayudarte a migrar de Amazon Redshift a BigQuery:
| Herramienta | Purpose |
|---|---|
| BigQuery Data Transfer Service | Realiza una transferencia por lotes automatizada de tus datos de Amazon Redshift a BigQuery con este servicio totalmente gestionado. |
| Servicio de transferencia de Storage | Importa rápidamente datos de Amazon S3 a Cloud Storage y configura una programación periódica para transferir datos con este servicio totalmente gestionado. |
gcloud |
Copia archivos de Amazon S3 en Cloud Storage con esta herramienta de línea de comandos. |
| Herramienta de línea de comandos bq | Interactúa con BigQuery mediante esta herramienta de línea de comandos. Entre las interacciones habituales se incluyen la creación de esquemas de tablas de BigQuery, la carga de datos de Cloud Storage en tablas y la ejecución de consultas. |
| Bibliotecas de cliente de Cloud Storage | Copia archivos de Amazon S3 en Cloud Storage con tu herramienta personalizada, creada a partir de la biblioteca de cliente de Cloud Storage. |
| Bibliotecas de cliente de BigQuery | Interactúa con BigQuery mediante tu herramienta personalizada, creada a partir de la biblioteca de cliente de BigQuery. |
| Programador de consultas de BigQuery | Programa consultas SQL periódicas con esta función integrada de BigQuery. |
| Cloud Composer | Orquesta las transformaciones y las tareas de carga de BigQuery con este entorno de Apache Airflow totalmente gestionado. |
| Apache Sqoop | Envía tareas de Hadoop mediante Sqoop y el controlador JDBC de Amazon Redshift para extraer datos de Amazon Redshift a HDFS o Cloud Storage. Sqoop se ejecuta en un entorno de Dataproc. |
Para obtener más información sobre cómo usar BigQuery Data Transfer Service, consulta el artículo Migrar el esquema y los datos de Amazon Redshift.
Migración mediante flujos de datos
La migración de datos de Amazon Redshift a BigQuery puede seguir diferentes rutas en función de las herramientas de migración disponibles. Aunque la lista de esta sección no es exhaustiva, sí ofrece una idea de los diferentes patrones de canalización de datos disponibles al mover los datos.
Para obtener información general sobre cómo migrar datos a BigQuery mediante flujos de procesamiento, consulta el artículo Migrar flujos de procesamiento de datos.
Extracción y carga (EL)
Puedes automatizar por completo una canalización EL con BigQuery Data Transfer Service, que puede copiar automáticamente los esquemas y los datos de tus tablas de tu clúster de Amazon Redshift a BigQuery. Si quieres tener más control sobre los pasos de tu canalización de datos, puedes crear una canalización con las opciones que se describen en las siguientes secciones.
Usar extractos de archivos de Amazon Redshift
- Exportar datos de Amazon Redshift a Amazon S3.
Copia datos de Amazon S3 a Cloud Storage con cualquiera de las siguientes opciones:
- Servicio de transferencia de Storage (opción recomendada)
- CLI de gcloud
- Bibliotecas de cliente de Cloud Storage
Para cargar datos de Cloud Storage en BigQuery, puede usar cualquiera de las siguientes opciones:
Usar una conexión JDBC de Amazon Redshift
Usa cualquiera de los siguientes productos de Google Cloud para exportar datos de Amazon Redshift con el controlador JDBC de Amazon Redshift:
-
- Plantilla proporcionada por Google: JDBC a BigQuery
-
Conectarse a Amazon Redshift a través de JDBC con Apache Spark
Usa Sqoop y el controlador JDBC de Amazon Redshift para extraer datos de Amazon Redshift a Cloud Storage
Extracción, transformación y carga (ETL)
Si quieres transformar algunos datos antes de cargarlos en BigQuery, sigue las mismas recomendaciones de la sección Extraer y cargar (EL) y añade un paso adicional para transformar los datos antes de cargarlos en BigQuery.
Usar extractos de archivos de Amazon Redshift
Copia datos de Amazon S3 a Cloud Storage con cualquiera de las siguientes opciones:
- Servicio de transferencia de Storage (opción recomendada)
- CLI de gcloud
- Bibliotecas de cliente de Cloud Storage
Transforma tus datos y, a continuación, cárgalos en BigQuery con cualquiera de las siguientes opciones:
-
- Leer desde Cloud Storage
- Escribir en BigQuery
- Plantilla proporcionada por Google: De archivos de texto de Cloud Storage a BigQuery
Usar una conexión JDBC de Amazon Redshift
Usa cualquiera de los productos descritos en la sección Extracción y carga (EL) y añade un paso adicional para transformar los datos antes de cargarlos en BigQuery. Modifica tu flujo de procesamiento para introducir uno o varios pasos que transformen tus datos antes de escribirlos en BigQuery.
-
- Clona el código de la plantilla JDBC a BigQuery y modifícalo para añadir transformaciones de Apache Beam.
-
- Transforma tus datos con cualquiera de los complementos de CDAP.
Proceso de extracción, carga y transformación (ELT)
Puedes transformar tus datos con BigQuery, usando cualquiera de las opciones de Extracción y carga (EL) para cargar tus datos en una tabla de almacenamiento provisional. Después, transforma los datos de esta tabla de almacenamiento provisional mediante consultas SQL que escriben su salida en la tabla de producción final.
Captura de datos de cambios (CDC)
La captura de cambios de datos es uno de los varios patrones de diseño de software que se usan para monitorizar los cambios en los datos. Se suele usar en el almacenamiento de datos, ya que el almacén de datos se utiliza para recopilar y monitorizar datos y sus cambios de varios sistemas de origen a lo largo del tiempo.
Herramientas de partners para la migración de datos
Hay varios proveedores en el espacio de extracción, transformación y carga (ETL). Consulta el sitio web de partners de BigQuery para ver una lista de los partners principales y las soluciones que ofrecen.
Migración a Google Cloud: análisis detallado
En esta sección se explica cómo influyen la arquitectura, el esquema y el dialecto SQL de su almacén de datos en la migración.
Comparación de arquitecturas
Tanto BigQuery como Amazon Redshift se basan en una arquitectura de procesamiento paralelo masivo (MPP). Las consultas se distribuyen en varios servidores para acelerar su ejecución. En cuanto a la arquitectura del sistema, Amazon Redshift y BigQuery se diferencian principalmente en la forma en que se almacenan los datos y en cómo se ejecutan las consultas. En BigQuery, el hardware y las configuraciones subyacentes se abstraen. Su almacenamiento y su computación permiten que tu almacén de datos crezca sin que tengas que hacer nada.
Computación, memoria y almacenamiento
En Amazon Redshift, la CPU, la memoria y el almacenamiento en disco están vinculados a través de los nodos de computación, tal como se muestra en este diagrama de la documentación de Amazon Redshift. El rendimiento del clúster y la capacidad de almacenamiento se determinan en función del tipo y la cantidad de nodos de computación, que deben configurarse. Para cambiar la capacidad de computación o de almacenamiento, debes cambiar el tamaño de tu clúster mediante un proceso (que puede durar un par de horas, hasta dos días o más) que crea un clúster nuevo y copia los datos. Amazon Redshift también ofrece nodos RA3 con almacenamiento gestionado que ayudan a separar la computación y el almacenamiento. El nodo más grande de la categoría RA3 tiene un límite de 64 TB de almacenamiento gestionado por nodo.
Desde el principio, BigQuery no vincula la computación, la memoria y el almacenamiento, sino que trata cada uno por separado.
La computación de BigQuery se define mediante ranuras, que son unidades de capacidad computacional necesarias para ejecutar consultas. Google gestiona toda la infraestructura que encapsula un slot, por lo que solo tienes que elegir la cantidad de slots adecuada para tus cargas de trabajo de BigQuery. Consulta la sección sobre planificación de la capacidad para decidir cuántos espacios vas a comprar para tu almacén de datos. La memoria de BigQuery se proporciona mediante un servicio distribuido remoto conectado a los slots de computación a través de la red de petabits de Google, todo ello gestionado por Google.
Tanto BigQuery como Amazon Redshift usan el almacenamiento en columnas, pero BigQuery usa variaciones y mejoras del almacenamiento en columnas. Mientras se codifican las columnas, se conservan varias estadísticas sobre los datos, que se usan más adelante durante la ejecución de las consultas para compilar planes óptimos y elegir el algoritmo de tiempo de ejecución más eficiente. BigQuery almacena tus datos en el sistema de archivos distribuidos de Google, donde se comprimen, cifran, replican y distribuyen automáticamente. Todo esto se consigue sin afectar a la potencia de cálculo disponible para tus consultas. Al separar el almacenamiento de la computación, puedes ampliar el almacenamiento hasta decenas de petabytes sin problemas, sin necesidad de recursos de computación adicionales y costosos. También hay otras ventajas de separar la computación y el almacenamiento.
Escalar hacia arriba o hacia abajo
Cuando el almacenamiento o la computación se ven limitados, los clústeres de Amazon Redshift deben cambiar de tamaño modificando la cantidad o los tipos de nodos del clúster.
Cuando cambias el tamaño de un clúster de Amazon Redshift, tienes dos opciones:
- Cambio de tamaño clásico: Amazon Redshift crea un clúster en el que se copian los datos. Este proceso puede tardar un par de horas o hasta dos días (o más) si se trata de grandes cantidades de datos.
- Cambio de tamaño elástico: si solo cambias el número de nodos, las consultas se pausan temporalmente y las conexiones se mantienen abiertas si es posible. Durante la operación de cambio de tamaño, el clúster es de solo lectura. El cambio de tamaño elástico suele tardar entre 10 y 15 minutos, pero puede que no esté disponible para todas las configuraciones.
Como BigQuery es una plataforma como servicio (PaaS), solo tienes que preocuparte por el número de ranuras de BigQuery que quieras reservar para tu organización. Reservas ranuras de BigQuery en reservas y, a continuación, asignas proyectos a esas reservas. Para saber cómo configurar estas reservas, consulta el artículo Planificación de la capacidad.
Ejecución de consultas
El motor de ejecución de BigQuery es similar al de Amazon Redshift, ya que ambos orquestan tu consulta dividiéndola en pasos (un plan de consulta), ejecutando los pasos (simultáneamente cuando sea posible) y, a continuación, volviendo a montar los resultados. Amazon Redshift genera un plan de consulta estático, pero BigQuery no lo hace porque optimiza dinámicamente los planes de consulta a medida que se ejecutan. BigQuery baraja los datos mediante su servicio de memoria remota, mientras que Amazon Redshift lo hace mediante la memoria del nodo de computación local. Para obtener más información sobre el almacenamiento de datos intermedios de BigQuery en varias fases de tu plan de consulta, consulta el artículo Ejecución de consultas en memoria en Google BigQuery.
Gestión de la carga de trabajo en BigQuery
BigQuery ofrece los siguientes controles para la gestión de la carga de trabajo (WLM):
- Consultas interactivas: se ejecutan lo antes posible (este es el ajuste predeterminado).
- Consultas por lotes: se ponen en cola en tu nombre y se inician en cuanto haya recursos inactivos disponibles en el grupo de recursos compartidos de BigQuery.
Reservas de slots con precios basados en la capacidad. En lugar de pagar por las consultas bajo demanda, puedes crear y gestionar dinámicamente contenedores de ranuras llamados reservas y asignar proyectos, carpetas u organizaciones a estas reservas. Puede comprar compromisos de ranuras de BigQuery (con un mínimo de 100) con compromisos flexibles, mensuales o anuales para minimizar los costes. De forma predeterminada, las consultas que se ejecutan en una reserva usan automáticamente las ranuras inactivas de otras reservas.
Como se muestra en el siguiente diagrama, supongamos que has comprado una capacidad total de compromiso de 1000 ranuras para compartir entre tres tipos de cargas de trabajo: ciencia de datos, ELT e inteligencia empresarial (BI). Para admitir estas cargas de trabajo, puedes crear las siguientes reservas:
- Puedes crear la reserva ds con 500 ranuras y asignar todos los proyectos de ciencia de datosGoogle Cloud a esa reserva.
- Puedes crear la reserva elt con 300 ranuras y asignar los proyectos que usas para las cargas de trabajo de ELT a esa reserva.
- Puedes crear la reserva bi con 200 espacios y asignar proyectos conectados a tus herramientas de BI a esa reserva.
Esta configuración se muestra en el siguiente gráfico:
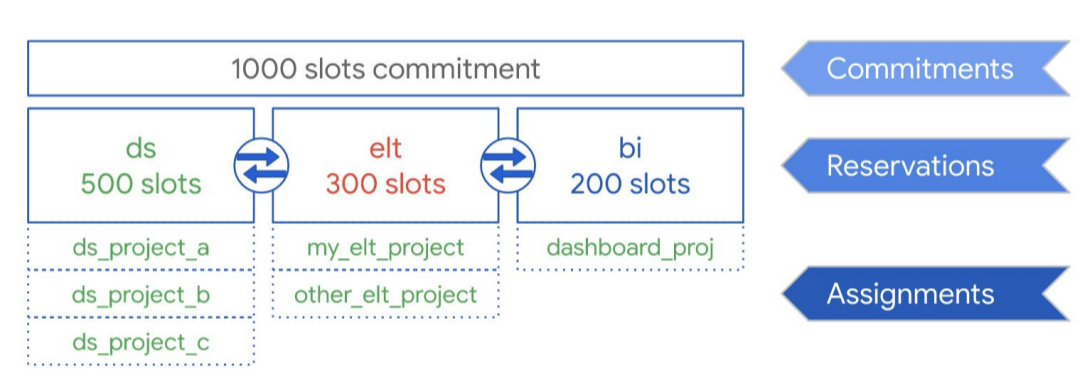
En lugar de distribuir las reservas a las cargas de trabajo de tu organización (por ejemplo, a producción y pruebas), puedes asignar reservas a equipos o departamentos concretos, en función de tu caso práctico.
Para obtener más información, consulta la página Gestión de cargas de trabajo mediante reservas.
Gestión de cargas de trabajo en Amazon Redshift
Amazon Redshift ofrece dos tipos de gestión de cargas de trabajo (WLM):
- Automático: Con la gestión de carga de trabajo automática, Amazon Redshift gestiona la simultaneidad de las consultas y la asignación de memoria. Se crean hasta ocho colas con los identificadores de clase de servicio del 100 al 107. La gestión de cargas de trabajo automática determina la cantidad de recursos que necesitan las consultas y ajusta la simultaneidad en función de la carga de trabajo. Para obtener más información, consulta Prioridad de las consultas.
- Manual: Por el contrario, la gestión de carga de trabajo manual requiere que especifiques valores para la simultaneidad de consultas y la asignación de memoria. El valor predeterminado de la gestión de carga de trabajo manual es una simultaneidad de cinco consultas, y la memoria se divide en partes iguales entre las cinco.
Cuando se habilita el escalado de la simultaneidad, Amazon Redshift añade automáticamente capacidad de clúster adicional cuando la necesitas para procesar un aumento de las consultas de lectura simultáneas. La escalabilidad de la simultaneidad tiene ciertas consideraciones regionales y de consulta. Para obtener más información, consulta Candidatos para el escalado de la simultaneidad.
Configuraciones de conjuntos de datos y tablas
BigQuery ofrece varias formas de configurar los datos y las tablas, como la creación de particiones, la agrupación en clústeres y la localidad de los datos. Estas configuraciones pueden ayudarte a mantener tablas grandes y a reducir la carga de datos general y el tiempo de respuesta de tus consultas, lo que aumenta la eficiencia operativa de tus cargas de trabajo de datos.
Particiones
Una tabla con particiones es una tabla que se divide en segmentos, llamados particiones, que facilitan la gestión y la consulta de los datos. Los usuarios suelen dividir las tablas grandes en muchas particiones más pequeñas, donde cada partición contiene los datos de un día. La gestión de particiones es un factor determinante del rendimiento y el coste de BigQuery al consultar un intervalo de fechas específico, ya que ayuda a BigQuery a analizar menos datos por consulta.
En BigQuery, hay tres tipos de particiones de tablas:
- Tablas con particiones por hora de ingestión: las tablas se particionan en función de la hora de ingestión de los datos.
- Tablas con particiones por columna:
Las tablas se dividen en particiones en función de una columna
TIMESTAMPoDATE. - Tablas con particiones de intervalos de números enteros: las tablas se dividen en particiones en función de una columna de números enteros.
Una tabla con particiones por hora basada en columnas evita tener que mantener la información de las particiones independientemente del filtrado de datos de la columna de límite. Los datos escritos en una tabla con particiones por hora basada en columnas se envían automáticamente a la partición adecuada en función del valor de los datos. Del mismo modo, las consultas que expresan filtros en la columna de partición pueden reducir el volumen total de datos analizados, lo que puede mejorar el rendimiento y reducir el coste de las consultas bajo demanda.
La partición basada en columnas de BigQuery es similar a la de Amazon Redshift, pero con una motivación ligeramente diferente. Amazon Redshift usa la distribución de claves basada en columnas para intentar que los datos relacionados se almacenen juntos en el mismo nodo de cálculo, lo que minimiza el movimiento de datos que se produce durante las combinaciones y las agregaciones. BigQuery separa el almacenamiento de los recursos de computación, por lo que utiliza particiones basadas en columnas para minimizar la cantidad de datos que leen los slots del disco.
Una vez que los trabajadores de los slots leen sus datos del disco, BigQuery puede determinar automáticamente una fragmentación de datos más óptima y volver a particionar los datos rápidamente mediante el servicio de aleatorización en memoria de BigQuery.
Para obtener más información, consulta el artículo sobre la introducción a las tablas con particiones.
Claves de ordenación y de clustering
Amazon Redshift permite especificar columnas de tabla como claves de ordenación compuestas o entrelazadas. En BigQuery, puedes especificar claves de ordenación compuestas agrupando en clústeres tu tabla. Las tablas agrupadas en clústeres de BigQuery mejoran el rendimiento de las consultas porque los datos de la tabla se ordenan automáticamente en función del contenido de hasta cuatro columnas especificadas en el esquema de la tabla. Estas columnas se usan para colocar datos relacionados en el mismo lugar. El orden de las columnas de agrupamiento que especifiques es importante porque determina el criterio de ordenación de los datos.
El agrupamiento en clústeres puede mejorar el rendimiento de determinados tipos de consultas, como las que usan cláusulas de filtro y las que agregan datos. Cuando una tarea de consulta o de carga escribe datos en una tabla agrupada en clústeres, BigQuery ordena automáticamente los datos mediante los valores de las columnas de este tipo de agrupamiento. Estos valores se usan para organizar los datos en varios bloques en el almacenamiento de BigQuery. Cuando envías una consulta que contiene una cláusula que filtra datos en función de las columnas de agrupamiento en clústeres, BigQuery usa los bloques ordenados para eliminar los análisis de datos innecesarios.
Del mismo modo, cuando envías una consulta que agrega datos en función de los valores de las columnas de agrupamiento en clústeres, el rendimiento mejora porque los bloques ordenados colocan las filas con valores similares en el mismo lugar.
Utiliza la agrupación en clústeres en las siguientes circunstancias:
- Las claves de ordenación compuestas se configuran en las tablas de Amazon Redshift.
- La filtración o la agregación se configuran en columnas concretas de tus consultas.
Si usas la creación de clústeres y las particiones juntas, tus datos se pueden particionar por una columna de fecha, marca de tiempo o número entero y, a continuación, se pueden agrupar en clústeres en otro conjunto de columnas (hasta cuatro columnas agrupadas en clústeres en total). En este caso, los datos de cada partición se agrupan en clústeres según los valores de las columnas de este tipo de agrupamiento.
Cuando especifica claves de ordenación en las tablas de Amazon Redshift, en función de la carga del sistema, Amazon Redshift inicia automáticamente la ordenación con la capacidad de computación de su propio clúster. Puede que incluso tengas que ejecutar manualmente el comando
VACUUM
si quieres ordenar completamente los datos de la tabla lo antes posible, por ejemplo, después de una gran carga de datos. BigQuery gestiona automáticamente esta ordenación y no utiliza las ranuras de BigQuery que tengas asignadas, por lo que no afecta al rendimiento de ninguna de tus consultas.
Para obtener más información sobre cómo trabajar con tablas agrupadas en clústeres, consulta la introducción a las tablas agrupadas en clústeres.
Claves de distribución
Amazon Redshift usa claves de distribución para optimizar la ubicación de los bloques de datos para ejecutar sus consultas. BigQuery no usa claves de distribución porque determina y añade automáticamente fases en un plan de consulta (mientras se ejecuta la consulta) para mejorar la distribución de datos entre los trabajadores de la consulta.
Fuentes externas
Si usas Amazon Redshift Spectrum para consultar datos en Amazon S3, puedes usar de forma similar la función de fuente de datos externa de BigQuery para consultar datos directamente desde archivos de Cloud Storage.
Además de consultar datos en Cloud Storage, BigQuery ofrece funciones de consulta federada para consultar directamente desde los siguientes productos:
- Cloud SQL (MySQL o PostgreSQL totalmente gestionados)
- Bigtable (NoSQL totalmente gestionado)
- Google Drive (CSV, JSON, Avro y Hojas de cálculo)
Localidad de los datos
Puedes crear tus conjuntos de datos de BigQuery en ubicaciones regionales y multirregionales, mientras que Amazon Redshift solo ofrece ubicaciones regionales. BigQuery determina la ubicación en la que se ejecutarán las tareas de carga, consulta o extracción en función de los conjuntos de datos a los que se haga referencia en la solicitud. Consulta las consideraciones sobre la ubicación de BigQuery para obtener consejos sobre cómo trabajar con conjuntos de datos regionales y multirregionales.
Asignación de tipos de datos en BigQuery
Los tipos de datos de Amazon Redshift son diferentes de los de BigQuery. Para obtener más información sobre los tipos de datos de BigQuery, consulta la documentación oficial.
BigQuery también admite los siguientes tipos de datos, que no tienen un análogo directo en Amazon Redshift:
Comparación de SQL
GoogleSQL cumple el estándar SQL 2011 y tiene extensiones que permiten consultar datos anidados y repetidos. El SQL de Amazon Redshift se basa en PostgreSQL, pero tiene varias diferencias que se detallan en la documentación de Amazon Redshift. Para ver una comparación detallada entre la sintaxis y las funciones de Amazon Redshift y GoogleSQL, consulta la guía de traducción de SQL de Amazon Redshift.
Puedes usar el traductor de SQL por lotes para convertir secuencias de comandos y otro código SQL de tu plataforma actual a BigQuery.
Después de la migración
Como has migrado secuencias de comandos que no se diseñaron para BigQuery, puedes implementar técnicas para optimizar el rendimiento de las consultas en BigQuery. Para obtener más información, consulta el artículo Introducción a la optimización del rendimiento de las consultas.
Siguientes pasos
- Consulta las instrucciones detalladas para migrar esquemas y datos desde Amazon Redshift.
- Consulta las instrucciones detalladas para migrar de Amazon Redshift a BigQuery con VPC.