Introducción a las tablas con particiones
Una tabla con particiones se divide en segmentos, llamados particiones, que facilitan la gestión y la consulta de los datos. Al dividir una tabla grande en particiones más pequeñas, puedes mejorar el rendimiento de las consultas y controlar los costes reduciendo el número de bytes que lee una consulta. Para crear particiones en las tablas, especifica una columna de partición que se usa para segmentar la tabla.
Si una consulta usa un filtro calificador en el valor de la columna con particiones, BigQuery podrá analizar las particiones que coincidan con el filtro y omitir las demás. Este proceso se denomina poda.
En una tabla con particiones, los datos se almacenan en bloques físicos, cada uno de los cuales contiene una partición de datos. Cada tabla particionada mantiene varios metadatos sobre las propiedades de ordenación en todas las operaciones que la modifican. Los metadatos permiten a BigQuery estimar con mayor precisión el coste de una consulta antes de que se ejecute.
Cuándo usar las particiones
Considera la posibilidad de particionar una tabla en los siguientes casos:
- Quieres mejorar el rendimiento de las consultas escaneando solo una parte de una tabla.
- La operación de tabla supera una cuota de tabla estándar y puede limitar las operaciones de tabla a valores de columna de partición específicos para permitir cuotas de tabla con particiones más altas.
- Quieres determinar los costes de las consultas antes de que se ejecuten. BigQuery proporciona estimaciones del coste de las consultas antes de que se ejecuten en una tabla particionada. Para calcular una estimación del coste de una consulta, poda una tabla con particiones y, a continuación, ejecuta una prueba de consulta para estimar los costes de la consulta.
- Quieres usar alguna de las siguientes funciones de gestión a nivel de partición:
- Define una fecha de vencimiento de la partición para eliminar automáticamente particiones enteras después de un periodo determinado.
- Escribir datos en una partición específica mediante tareas de carga sin que afecte a otras particiones de la tabla.
- Eliminar particiones específicas sin analizar toda la tabla.
En las siguientes circunstancias, te recomendamos que clusters una tabla en lugar de particionarla:
- Necesitas más granularidad de la que ofrecen las particiones.
- Tus consultas suelen usar filtros o agregaciones en varias columnas.
- La cardinalidad del número de valores de una columna o un grupo de columnas es grande.
- No necesitas estimaciones de costes estrictas antes de ejecutar las consultas.
- La partición da como resultado una pequeña cantidad de datos por partición (aproximadamente menos de 10 GB). Si creas muchas particiones pequeñas, aumentarán los metadatos de la tabla y se puede ver afectado el tiempo de acceso a los metadatos al consultar la tabla.
- La creación de particiones da lugar a un gran número de particiones, lo que supera los límites de las tablas con particiones.
- Las operaciones de DML modifican con frecuencia (por ejemplo, cada pocos minutos) la mayoría de las particiones de la tabla.
En estos casos, el agrupamiento en clústeres de tablas te permite acelerar las consultas agrupando los datos de columnas específicas en función de las propiedades de orden definidas por el usuario.
También puedes combinar la agrupación en clústeres y la partición de tablas para conseguir una ordenación más precisa. Para obtener más información sobre este enfoque, consulta Combinar tablas con particiones y en clúster.
Tipos de particiones
En esta sección se describen las diferentes formas de particionar una tabla.
Particiones de intervalos de números enteros
Puedes particionar una tabla en función de los intervalos de valores de una columna INTEGER
específica. Para crear una tabla con particiones de rangos de números enteros, debes proporcionar lo siguiente:
- Columna de partición.
- Valor inicial de la partición por rango (inclusivo).
- Valor final del rango de partición (exclusivo).
- El intervalo de cada rango de la partición.
Por ejemplo, supongamos que crea una partición de intervalo de números enteros con la siguiente especificación:
| Argumento | Valor |
|---|---|
| nombre de la columna | customer_id |
| start | 0 |
| fin | 100 |
| intervalo | 10 |
La tabla tiene particiones en la columna customer_id en intervalos de 10.
Los valores del 0 al 9 se incluyen en una partición, los valores del 10 al 19 se incluyen en la siguiente partición, y así sucesivamente hasta el 99. Los valores que no estén incluidos en este intervalo se incluirán en una partición llamada __UNPARTITIONED__. Las filas en las que customer_id es NULL se incluyen en una partición llamada __NULL__.
Para obtener información sobre las tablas con particiones de rangos de números enteros, consulta el artículo Crear una tabla con particiones de rangos de números enteros.
Partición por columnas de unidades de tiempo
Puede crear particiones de una tabla en una columna DATE, TIMESTAMP o DATETIME de la tabla. Cuando escribes datos en la tabla, BigQuery los coloca automáticamente en la partición correcta en función de los valores de la columna.
En las columnas TIMESTAMP y DATETIME, las particiones pueden tener una granularidad horaria, diaria, mensual o anual. En el caso de las columnas DATE, las particiones pueden tener una granularidad diaria, mensual o anual. Los límites de las particiones se basan en la hora UTC.
Por ejemplo, supongamos que crea particiones en una tabla por la columna DATETIME con particiones mensuales. Si insertas los siguientes valores en la tabla, las filas se escribirán en las siguientes particiones:
| Valor de columna | Partición (mensual) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
Además, se crean dos particiones especiales:
__NULL__: contiene filas con valoresNULLen la columna de partición.__UNPARTITIONED__: contiene las filas en las que el valor de la columna de partición es anterior al 1 de enero de 1960 o posterior al 31 de diciembre del 2159.
Para obtener información sobre las tablas con particiones por columnas de unidades de tiempo, consulta Crear una tabla con particiones por columnas de unidades de tiempo.
Partición por tiempo de ingestión
Cuando creas una tabla con particiones por hora de ingestión, BigQuery asigna automáticamente las filas a las particiones en función de la hora en la que BigQuery ingiere los datos. Puedes elegir una granularidad por horas, diaria, mensual o anual para las particiones. Los límites de las particiones se basan en la hora UTC.
Si tus datos pueden alcanzar el número máximo de particiones por tabla al usar una granularidad temporal más precisa, usa una granularidad más gruesa. Por ejemplo, puedes crear particiones por mes en lugar de por día para reducir el número de particiones. También puedes agrupar la columna de partición para mejorar aún más el rendimiento.
Una tabla con particiones por hora de ingestión tiene una pseudocolumna llamada _PARTITIONTIME.
El valor de esta columna es la hora de ingestión de cada fila, truncada al límite de la partición (por ejemplo, por horas o por días). Por ejemplo, supongamos que crea una tabla con particiones por hora de ingestión y envía datos a las siguientes horas:
| Tiempo de ingestión | _PARTITIONTIME |
Partición (por horas) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
Como la tabla de este ejemplo usa particiones por horas, el valor de _PARTITIONTIME se trunca a un límite de una hora. BigQuery usa este valor para determinar la partición correcta de los datos.
También puedes escribir datos en una partición específica. Por ejemplo, puede que quieras cargar datos históricos o ajustar las zonas horarias. Puedes usar cualquier fecha válida entre el 01-01-0001 y el 31-12-9999. Sin embargo, las sentencias DML no pueden hacer referencia a fechas anteriores al 1 de enero de 1970 ni posteriores al 31 de diciembre del 2159. Para obtener más información, consulta Escribir datos en una partición específica.
En lugar de usar _PARTITIONTIME, también puedes usar _PARTITIONDATE.
La pseudocolumna _PARTITIONDATE contiene la fecha UTC correspondiente al valor de la pseudocolumna _PARTITIONTIME.
Seleccionar una partición diaria, por hora, mensual o anual
Cuando particiona una tabla por una columna de unidad de tiempo o por tiempo de ingestión, elige si las particiones tienen una granularidad diaria, por hora, mensual o anual.
La partición diaria es el tipo de partición predeterminado. La partición diaria es una buena opción cuando los datos se distribuyen en un amplio intervalo de fechas o si se añaden datos continuamente a lo largo del tiempo.
Elige la partición por horas si tus tablas tienen un gran volumen de datos que abarca un periodo corto, normalmente menos de seis meses de valores de marca de tiempo. Si eliges la partición por horas, asegúrate de que el número de particiones no supere los límites de partición.
Elige la partición mensual o anual si tus tablas tienen una cantidad de datos relativamente pequeña para cada día, pero abarcan un periodo amplio. También se recomienda esta opción si tu flujo de trabajo requiere actualizar o añadir con frecuencia filas que abarquen un intervalo de fechas amplio (por ejemplo, más de 500 fechas). En estos casos, usa el particionado mensual o anual junto con la agrupación en clústeres en la columna de partición para obtener el mejor rendimiento. Para obtener más información, consulta la sección Combinar tablas con particiones y en clúster de este documento.
Combinar tablas agrupadas en clústeres y con particiones
Puede combinar la partición de tablas con el agrupamiento en clústeres de tablas para conseguir una ordenación detallada y optimizar aún más las consultas.
Una tabla agrupada en clústeres contiene columnas de este tipo que ordenan los datos según las propiedades de ordenación definidas por el usuario. Los datos de estas columnas agrupadas en clústeres se ordenan en bloques de almacenamiento cuyo tamaño se adapta en función del tamaño de la tabla. Cuando ejecutas una consulta que filtra por la columna agrupada en clústeres, BigQuery solo analiza los bloques pertinentes en función de las columnas agrupadas en clústeres en lugar de toda la tabla o partición de la tabla. En un enfoque combinado que utiliza tanto el particionado como el agrupamiento en clústeres de tablas, primero segmentas los datos de la tabla en particiones y, a continuación, agrupas los datos de cada partición en clústeres por las columnas de agrupamiento en clústeres.
Si creas una tabla agrupada en clústeres y con particiones, puedes conseguir una ordenación más precisa, como se muestra en el siguiente diagrama:
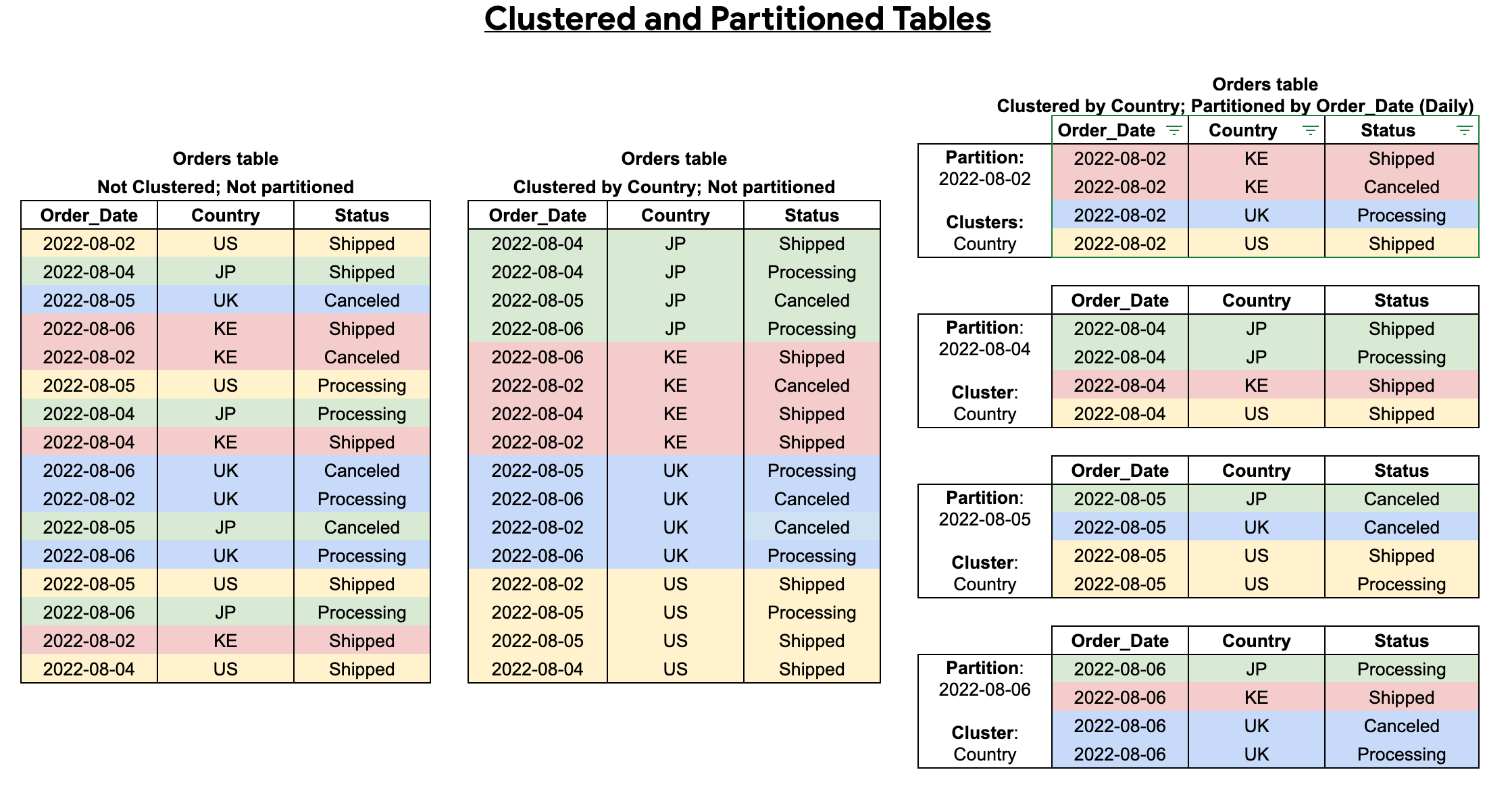
Particiones y fragmentación
La fragmentación de tablas es la práctica de almacenar datos en varias tablas mediante un prefijo de nombre, como [PREFIX]_YYYYMMDD.
Se recomienda usar particiones en lugar de fragmentación de tablas, ya que las tablas con particiones tienen un mejor rendimiento. Con las tablas fragmentadas, BigQuery debe mantener una copia del esquema y los metadatos de cada tabla. Es posible que BigQuery también tenga que verificar los permisos de cada tabla consultada. Esta práctica también añade una sobrecarga a las consultas y afecta al rendimiento de las consultas.
Si has creado tablas con particiones por fecha, puedes convertirlas en tablas con particiones por hora de ingestión. Para obtener más información, consulta Convertir tablas con particiones por fecha en tablas con particiones por tiempo de ingestión.
Decoradores de partición
Los decoradores de partición te permiten hacer referencia a una partición de una tabla. Por ejemplo, puede usarlos para escribir datos en una partición específica.
Un decorador de partición tiene el formato table_name$partition_id, donde el formato del segmento partition_id depende del tipo de partición:
| Tipo de partición | Formato | Ejemplo |
|---|---|---|
| Cada hora | yyyymmddhh |
my_table$2021071205 |
| Diarias | yyyymmdd |
my_table$20210712 |
| Mensual | yyyymm |
my_table$202107 |
| Cada año | yyyy |
my_table$2021 |
| Intervalo de números enteros | range_start |
my_table$40 |
Consultar los datos de una partición
Para consultar los datos de una partición específica, usa el comando
bq head con un decorador de partición.
Por ejemplo, el siguiente comando muestra todos los campos de las 10 primeras filas de my_dataset.my_table en la partición 2018-02-24:
bq head --max_rows=10 'my_dataset.my_table$20180224'
Exportar datos de una tabla
El proceso para exportar todos los datos de una tabla particionada es el mismo que para exportar datos de una tabla no particionada. Para obtener más información, consulta el artículo Exportar datos de una tabla.
Para exportar datos de una partición concreta, usa el comando bq extract y añade el decorador de partición al nombre de la tabla. Por ejemplo, my_table$20160201. También puede exportar datos de las particiones __NULL__ y __UNPARTITIONED__
añadiendo los nombres de las particiones al nombre de la tabla. Por ejemplo, my_table$__NULL__ o my_table$__UNPARTITIONED__.
Limitaciones
Las tablas con particiones tienen las siguientes limitaciones:
No puedes usar SQL antiguo para consultar tablas con particiones ni para escribir los resultados de las consultas en tablas con particiones.
BigQuery no admite la creación de particiones por varias columnas. Solo se puede usar una columna para crear particiones en una tabla.
No puedes convertir directamente una tabla sin particiones en una tabla con particiones. La estrategia de partición se define cuando se crea la tabla. En su lugar, usa la instrucción
CREATE TABLEpara crear una tabla con particiones consultando los datos de la tabla.Las tablas con particiones por columnas de unidades de tiempo están sujetas a las siguientes limitaciones:
- La columna de partición debe ser una columna escalar
DATE,TIMESTAMPoDATETIME. Aunque el modo de la columna puede serREQUIREDoNULLABLE, no puede serREPEATED(basado en una matriz). - La columna de partición debe ser un campo de nivel superior. No puedes usar un campo de hoja de un
RECORD(STRUCT) como columna de partición.
Para obtener información sobre las tablas con particiones por columnas de unidades de tiempo, consulta Crear una tabla con particiones por columnas de unidades de tiempo.
- La columna de partición debe ser una columna escalar
Las tablas con particiones de rangos de números enteros están sujetas a las siguientes limitaciones:
- La columna de partición debe ser una columna
INTEGER. Aunque el modo de la columna puede serREQUIREDoNULLABLE, no puede serREPEATED(basado en una matriz). - La columna de partición debe ser un campo de nivel superior. No puedes usar un campo de hoja de un
RECORD(STRUCT) como columna de partición.
Para obtener información sobre las tablas con particiones de rangos de números enteros, consulta el artículo Crear una tabla con particiones de rangos de números enteros.
- La columna de partición debe ser una columna
Cuotas y límites
Las tablas con particiones tienen límites definidos en BigQuery.
Las cuotas y los límites también se aplican a los distintos tipos de tareas que puede ejecutar en tablas con particiones, como las siguientes:
- Carga de datos (tareas de carga)
- Exportar datos (tareas de extracción)
- Consultar datos (tareas de consulta)
- Copiar tablas (tareas de copia)
Para obtener más información sobre todas las cuotas y los límites, consulta Cuotas y límites.
Precios de las tablas
Si creas tablas con particiones para usarlas en BigQuery, los cargos se basan en la cantidad de datos almacenados en las particiones y en las consultas que realizas en los datos:
- Para obtener información sobre los precios del almacenamiento, consulta la página Precios del almacenamiento.
- Para obtener información sobre los precios de las consultas, consulta Precios de las consultas.
Muchas operaciones de tablas particionadas son gratuitas, como cargar datos en particiones, copiar particiones y exportar datos de particiones. Aunque son gratuitas, estas operaciones están sujetas a las cuotas y límites de BigQuery. Para obtener información sobre todas las operaciones gratuitas, consulta la sección Operaciones gratuitas de la página de precios.
Para consultar las prácticas recomendadas para controlar los costes en BigQuery, consulta el artículo Controlar los costes en BigQuery.
Seguridad de las tablas
El control de acceso de las tablas con particiones es el mismo que el de las tablas estándar. Para obtener más información, consulta Introducción a los controles de acceso a tablas.
Siguientes pasos
- Para saber cómo crear tablas con particiones, consulta Crear tablas con particiones.
- Para saber cómo gestionar y actualizar tablas con particiones, consulta Gestionar tablas con particiones.
- Para obtener información sobre cómo consultar tablas con particiones, consulta Consultar tablas con particiones.