Programar consultas
En esta página se describe cómo programar consultas periódicas en BigQuery.
Puedes programar consultas para que se ejecuten de forma periódica. Las consultas programadas deben escribirse en GoogleSQL, que puede incluir instrucciones de lenguaje de definición de datos (DDL) y de lenguaje de manipulación de datos (DML). Puede organizar los resultados de las consultas por fecha y hora parametrizando la cadena de consulta y la tabla de destino.
Cuando creas o actualizas la programación de una consulta, la hora programada de la consulta se convierte de tu hora local a UTC. La zona horaria UTC no se ve afectada por el horario de verano.
Antes de empezar
- Las consultas programadas utilizan funciones de BigQuery Data Transfer Service. Comprueba que has completado todas las acciones necesarias en Habilitar BigQuery Data Transfer Service.
- Concede roles de gestión de identidades y accesos (IAM) que proporcionen a los usuarios los permisos necesarios para realizar cada tarea de este documento.
- Si tienes previsto especificar una clave de cifrado gestionada por el cliente (CMEK), asegúrate de que tu cuenta de servicio tenga permisos para cifrar y descifrar y de que tengas el ID de recurso de clave de Cloud KMS necesario para usar la CMEK. Para obtener información sobre cómo funcionan las CMEKs con BigQuery Data Transfer Service, consulta Especificar una clave de cifrado con consultas programadas.
Permisos obligatorios
Para programar una consulta, necesitas los siguientes permisos de gestión de identidades y accesos:
Para crear la transferencia, debes tener los permisos
bigquery.transfers.updateybigquery.datasets.get, o los permisosbigquery.jobs.create,bigquery.transfers.getybigquery.datasets.get.Para ejecutar una consulta programada, debe tener lo siguiente:
- Permisos de
bigquery.datasets.geten el conjunto de datos de destino bigquery.jobs.create
- Permisos de
Para modificar o eliminar una consulta programada, debes tener los permisos bigquery.transfers.update y bigquery.transfers.get, o bien el permiso bigquery.jobs.create y ser el propietario de la consulta programada.
El rol de gestión de identidades y accesos predefinido Administrador de BigQuery (roles/bigquery.admin) incluye los permisos que necesitas para programar o modificar una consulta.
Para obtener más información sobre los roles de gestión de identidades y accesos en BigQuery, consulta el artículo sobre roles y permisos predefinidos.
Para crear o actualizar consultas programadas que ejecute una cuenta de servicio, debes tener acceso a esa cuenta de servicio. Para obtener más información sobre cómo asignar el rol de cuenta de servicio a los usuarios, consulta el artículo Rol Usuario de cuenta de servicio. Para seleccionar una cuenta de servicio en la interfaz de usuario de la consulta programada de laGoogle Cloud consola, necesitas los siguientes permisos de gestión de identidades y accesos:
iam.serviceAccounts.listpara mostrar tus cuentas de servicio.iam.serviceAccountUserpara asignar una cuenta de servicio a una consulta programada.
Opciones de configuración
En las siguientes secciones se describen las opciones de configuración.
Cadena de consulta
La cadena de consulta debe ser válida y estar escrita en GoogleSQL. Cada ejecución de una consulta programada puede recibir los siguientes parámetros de consulta.
Para probar manualmente una cadena de consulta con los parámetros @run_time y @run_date antes de programar una consulta, usa la herramienta de línea de comandos bq.
Parámetros disponibles
| Parámetro | Tipo de GoogleSQL | Valor |
|---|---|---|
@run_time |
TIMESTAMP |
Representado en la hora UTC. En el caso de las consultas programadas periódicamente, run_time representa la hora de ejecución prevista. Por ejemplo, si la consulta programada se establece en "cada 24 horas", la diferencia run_time entre dos consultas consecutivas es exactamente de 24 horas, aunque el tiempo de ejecución real puede variar ligeramente. |
@run_date |
DATE |
Representa una fecha de calendario lógica. |
Ejemplo
El parámetro @run_time forma parte de la cadena de consulta de este ejemplo, que consulta un conjunto de datos público llamado hacker_news.stories.
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
Tabla de destino
Si la tabla de destino de los resultados no existe cuando configuras la consulta programada, BigQuery intenta crearla.
Si usas una consulta DDL o DML, en la Google Cloud consola, elige la ubicación de procesamiento o la región. Es necesario indicar la ubicación de procesamiento para las consultas de DDL o DML que creen la tabla de destino.
Si la tabla de destino ya existe y usas la WRITE_APPEND
preferencia de escritura, BigQuery añade datos a la tabla de destino e intenta asignar el esquema.
BigQuery permite automáticamente añadir y reordenar campos, y se adapta a los campos opcionales que faltan. Si el esquema de la tabla cambia tanto entre ejecuciones que BigQuery no puede procesar los cambios automáticamente, la consulta programada falla.
Las consultas pueden hacer referencia a tablas de diferentes proyectos y conjuntos de datos. Al configurar la consulta programada, no es necesario que incluyas el conjunto de datos de destino en el nombre de la tabla. El conjunto de datos de destino se especifica por separado.
El conjunto de datos y la tabla de destino de una consulta programada deben estar en el mismo proyecto que la consulta programada.
Preferencia de escritura
La preferencia de escritura que selecciones determinará cómo se escriben los resultados de la consulta en una tabla de destino.
WRITE_TRUNCATE: Si la tabla ya existe, BigQuery sobrescribe los datos de la tabla.WRITE_APPEND: Si la tabla ya existe, BigQuery añade los datos a la tabla.
Si usas una consulta DDL o DML, no puedes usar la opción de preferencia de escritura.
La creación, truncado o anexión de una tabla de destino solo se produce si BigQuery puede completar la consulta correctamente. Las acciones de creación, truncamiento o anexión se producen como una actualización atómica al completar el trabajo.
Agrupamiento en clústeres
Las consultas programadas solo pueden crear clústeres en tablas nuevas cuando se crean con una instrucción DDL CREATE TABLE AS SELECT. Consulta la sección Crear una tabla agrupada en clústeres a partir de los resultados de una consulta de la página Usar instrucciones del lenguaje de definición de datos.
Opciones de partición
Las consultas programadas pueden crear tablas de destino con o sin particiones. La creación de particiones está disponible en la consola, en la herramienta de línea de comandos bq y en los métodos de configuración de la API. Google Cloud Si usas una consulta DDL o DML con particiones, deja en blanco el campo Campo de partición de la tabla de destino.
En BigQuery, puede usar los siguientes tipos de particiones de tablas:
- Particiones por intervalo de números enteros:
tablas con particiones basadas en intervalos de valores de una columna
INTEGERespecífica. - Partición por columnas de unidades de tiempo:
tablas con particiones basadas en una columna de
TIMESTAMP,DATEoDATETIME. - Particiones por hora de ingestión: tablas con particiones por hora de ingestión. BigQuery asigna automáticamente las filas a las particiones en función de la hora en la que BigQuery ingiere los datos.
Para crear una tabla con particiones mediante una consulta programada en la consola deGoogle Cloud , usa las siguientes opciones:
Para usar la partición por intervalo de números enteros, deje en blanco el campo Campo de partición de la tabla de destino.
Para usar la partición por columnas de unidades de tiempo, especifica el nombre de la columna en el campo Campo de partición de la tabla de destino cuando configures una consulta programada.
Para usar la partición por hora de ingestión, deje el campo Campo de partición de la tabla de destino en blanco e indique la partición por fecha en el nombre de la tabla de destino. Por ejemplo,
mytable${run_date}. Para obtener más información, consulta Sintaxis de las plantillas de parámetros.
Parámetros disponibles
Al configurar la consulta programada, puede especificar cómo quiere particionar la tabla de destino con parámetros de tiempo de ejecución.
| Parámetro | Tipo de plantilla | Valor |
|---|---|---|
run_time |
Marca de tiempo con formato | En hora UTC, según la programación. En el caso de las consultas programadas periódicamente, run_time representa la hora de ejecución prevista. Por ejemplo, si la consulta programada se establece en "cada 24 horas", la run_time diferencia entre dos consultas consecutivas es exactamente de 24 horas, aunque el tiempo de ejecución real puede variar ligeramente.Consulta TransferRun.runTime. |
run_date |
Cadena de fecha | La fecha del parámetro run_time en el siguiente formato: %Y-%m-%d. Por ejemplo, 2018-01-01. Este formato es compatible con las tablas con particiones por hora de ingestión. |
Sistema de plantillas
Las consultas programadas admiten parámetros de tiempo de ejecución en el nombre de la tabla de destino con una sintaxis de plantilla.
Sintaxis de las plantillas de parámetros
La sintaxis de las plantillas admite plantillas de cadenas básicas y desfases de tiempo. Los parámetros se hacen referencia en los siguientes formatos:
{run_date}{run_time[+\-offset]|"time_format"}
| Parámetro | Purpose |
|---|---|
run_date |
Este parámetro se sustituye por la fecha en formato YYYYMMDD. |
run_time |
Este parámetro admite las siguientes propiedades:
|
- No se permiten espacios en blanco entre run_time, offset y el formato de hora.
- Para incluir llaves literales en la cadena, puedes usar el carácter de escape
'\{' and '\}'. - Para incluir comillas literales o una barra vertical en time_format, como
"YYYY|MM|DD", puedes usar el carácter de escape en la cadena de formato:'\"'o'\|'.
Ejemplos de plantillas de parámetros
En estos ejemplos se muestra cómo especificar nombres de tabla de destino con diferentes formatos de hora y cómo compensar el tiempo de ejecución.| run_time (UTC) | Parámetro de plantilla | Nombre de la tabla de destino de salida |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}
o mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
Usar una cuenta de servicio
Puedes configurar una consulta programada para autenticarte como cuenta de servicio. Una cuenta de servicio es una cuenta especial asociada a tu proyecto de Google Cloud . La cuenta de servicio puede ejecutar trabajos, como consultas programadas o canalizaciones de procesamiento por lotes, con sus propias credenciales de servicio en lugar de con las credenciales de un usuario final.
Consulta más información sobre la autenticación con cuentas de servicio en el artículo Introducción a la autenticación.
Puedes configurar la consulta programada con una cuenta de servicio. Si has iniciado sesión con una identidad federada, debes tener una cuenta de servicio para crear una transferencia. Si has iniciado sesión con una cuenta de Google, no es obligatorio tener una cuenta de servicio para la transferencia.
Puedes actualizar una consulta programada con las credenciales de una cuenta de servicio mediante la herramienta de línea de comandos bq o la consola de Google Cloud . Para obtener más información, consulta Actualizar las credenciales de una consulta programada.
Especificar la clave de cifrado en consultas programadas
Puedes especificar claves de cifrado gestionadas por el cliente (CMEKs) para cifrar los datos de una ejecución de transferencia. Puedes usar una CMEK para admitir transferencias desde consultas programadas.Cuando especifica una CMEK con una transferencia, BigQuery Data Transfer Service aplica la CMEK a cualquier caché intermedio en disco de los datos ingeridos para que todo el flujo de trabajo de transferencia de datos cumpla los requisitos de la CMEK.
No puedes actualizar una transferencia para añadir una CMEK si no se creó originalmente con una CMEK. Por ejemplo, no puedes cambiar una tabla de destino que originalmente estaba cifrada de forma predeterminada para que ahora se cifre con CMEK. Del mismo modo, tampoco puedes cambiar el tipo de cifrado de una tabla de destino cifrada con CMEK.
Puedes actualizar una CMEK de una transferencia si la configuración de la transferencia se creó originalmente con un cifrado CMEK. Cuando actualizas una CMEK de una configuración de transferencia, BigQuery Data Transfer Service propaga la CMEK a las tablas de destino en la siguiente ejecución de la transferencia, donde BigQuery Data Transfer Service sustituye las CMEKs obsoletas por la nueva CMEK durante la ejecución de la transferencia. Para obtener más información, consulta Actualizar una transferencia.
También puedes usar las claves predeterminadas del proyecto. Cuando especifica una clave predeterminada de proyecto con una transferencia, BigQuery Data Transfer Service usa la clave predeterminada de proyecto como clave predeterminada para cualquier configuración de transferencia nueva.
Configurar consultas programadas
Para ver una descripción de la sintaxis de la programación, consulta Dar formato a la programación.
Para obtener información sobre la sintaxis de la programación, consulta Recurso: TransferConfig.
Consola
Abre la página de BigQuery en la Google Cloud consola.
Ejecuta la consulta que te interese. Cuando estés conforme con los resultados, haz clic en Programar.
Las opciones de la consulta programada se abren en el panel Nueva consulta programada.
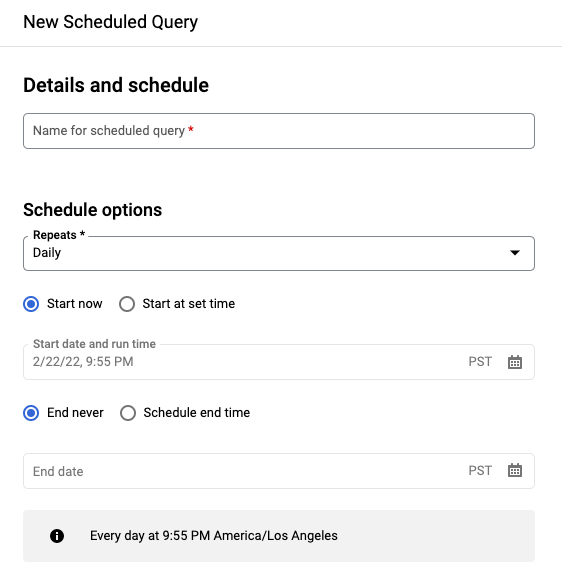
En el panel Nueva consulta programada:
- En Nombre de la consulta programada, escriba un nombre como
My scheduled query. El nombre de la consulta programada puede ser cualquier valor que puedas identificar más adelante si necesitas modificar la consulta. Opcional: De forma predeterminada, la consulta se programa para que se ejecute Diariamente. Para cambiar la programación predeterminada, selecciona una opción en el menú desplegable Se repite:
Para especificar una frecuencia personalizada, selecciona Personalizar y, a continuación, introduce una especificación de tiempo similar a Cron en el campo Programación personalizada. Por ejemplo,
every mon 23:30oevery 6 hours. Para obtener información sobre las programaciones válidas, incluidos los intervalos personalizados, consulta el camposcheduleen Recurso:TransferConfig.
Para cambiar la hora de inicio, selecciona la opción Empezar a una hora determinada. Introduce la fecha y la hora de inicio seleccionadas.
Para especificar una hora de finalización, selecciona la opción Programar hora de finalización e introduce la fecha y la hora de finalización que quieras.
Para guardar la consulta sin una programación y poder ejecutarla cuando quieras, selecciona Bajo demanda en el menú Se repite.
- En Nombre de la consulta programada, escriba un nombre como
En el caso de una consulta de GoogleSQL
SELECT, selecciona la opción Definir una tabla de destino para los resultados de la consulta y proporciona la siguiente información sobre el conjunto de datos de destino.- En Nombre del conjunto de datos, elige el conjunto de datos de destino adecuado.
- En Table name (Nombre de la tabla), introduce el nombre de la tabla de destino.
En Preferencia de escritura de la tabla de destino, elija una de las siguientes opciones: Añadir a la tabla para añadir datos a la tabla Sobrescribir tabla para sobrescribir la tabla de destino.

Elige el Tipo de ubicación.
Si ha habilitado la tabla de destino para los resultados de las consultas, puede seleccionar Selección automática de la ubicación para elegir automáticamente la ubicación en la que se encuentra la tabla de destino.
De lo contrario, elija la ubicación de los datos que se van a consultar.
Opciones avanzadas:
Opcional: CMEK Si usas claves de cifrado gestionadas por el cliente, puedes seleccionar Clave gestionada por el cliente en Opciones avanzadas. Aparecerá una lista de las CMEKs disponibles para que elijas la que quieras. Para obtener información sobre cómo funcionan las claves de cifrado gestionadas por el cliente (CMEKs) con BigQuery Data Transfer Service, consulta Especificar una clave de cifrado con consultas programadas.
Autenticarse como cuenta de servicio Si tienes una o varias cuentas de servicio asociadas a tu proyecto de Google Cloud , puedes asociar una cuenta de servicio a tu consulta programada en lugar de usar tus credenciales de usuario. En Credencial de consulta programada, haz clic en el menú para ver una lista de las cuentas de servicio disponibles. Se necesita una cuenta de servicio si has iniciado sesión como identidad federada.

Configuraciones adicionales:
Opcional: Marca Enviar notificaciones por correo para permitir que se envíen notificaciones por correo cuando se produzcan fallos en las transferencias.
Opcional: En Tema de Pub/Sub, introduce el nombre del tema de Pub/Sub. Por ejemplo:
projects/myproject/topics/mytopic.
Haz clic en Guardar.
bq
Opción 1: Usa el comando bq query.
Para crear una consulta programada, añade las opciones destination_table (o target_dataset), --schedule y --display_name al comando bq query.
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
Haz los cambios siguientes:
name. Nombre visible de la consulta programada. El nombre visible puede ser cualquier valor que puedas identificar más adelante si necesitas modificar la consulta.table. La tabla de destino de los resultados de la consulta.--target_datasetes una forma alternativa de asignar un nombre al conjunto de datos de destino de los resultados de la consulta cuando se usa con consultas de DDL y DML.- Usa
--destination_tableo--target_dataset, pero no ambos.
interval. Cuando se usa conbq query, convierte una consulta en una consulta programada periódica. Es necesario programar la frecuencia con la que se debe ejecutar la consulta. Para obtener información sobre las programaciones válidas, incluidos los intervalos personalizados, consulta el camposchedulede Recurso:TransferConfig. Ejemplos:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
Marcas posibles
--project_ides el ID del proyecto. Si no se especifica--project_id, se usa el proyecto predeterminado.--replacesobrescribe la tabla de destino con los resultados de la consulta después de cada ejecución de la consulta programada. Se borrarán todos los datos. En el caso de las tablas sin particiones, el esquema también se borra.--append_tableañade los resultados a la tabla de destino.En el caso de las consultas DDL y DML, también puedes proporcionar la marca
--locationpara especificar una región concreta para el procesamiento. Si no se especifica--location, se usa la ubicación Google Cloud más cercana.
Por ejemplo, el siguiente comando crea una consulta programada llamada My Scheduled Query con la consulta SELECT 1 from mydataset.test.
La tabla de destino es mytable en el conjunto de datos mydataset. La consulta programada se crea en el proyecto predeterminado:
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
Opción 2: Usa el comando bq mk.
Las consultas programadas son un tipo de transferencia. Para programar una consulta, puedes usar la herramienta de línea de comandos bq para crear una configuración de transferencia.
Las consultas deben estar en dialecto Standard SQL para poder programarse.
Introduce el comando bq mk y proporciona las siguientes marcas obligatorias:
--transfer_config--data_source--target_dataset(opcional para las consultas DDL y DML)--display_name--params
Marcas posibles
--project_ides el ID del proyecto. Si no se especifica--project_id, se usa el proyecto predeterminado.--schedulees la frecuencia con la que quieres que se ejecute la consulta. Si no se especifica--schedule, el valor predeterminado es "cada 24 horas" según la hora de creación.En el caso de las consultas DDL y DML, también puedes proporcionar la marca
--locationpara especificar una región concreta para el procesamiento. Si no se especifica--location, se usa la ubicación Google Cloud más cercana.--service_account_namese usa para autenticar tu consulta programada con una cuenta de servicio en lugar de con tu cuenta de usuario.--destination_kms_keyespecifica el ID de recurso de la clave de la clave si usas una clave de cifrado gestionada por el cliente (CMEK) para esta transferencia. Para obtener información sobre cómo funcionan las CMEKs con BigQuery Data Transfer Service, consulta Especificar una clave de cifrado con consultas programadas.
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
Haz los cambios siguientes:
dataset. El conjunto de datos de destino de la configuración de la transferencia.- Este parámetro es opcional para las consultas de DDL y DML. Es obligatorio para todas las demás consultas.
name. Nombre visible de la configuración de transferencia. El nombre visible puede ser cualquier valor que pueda identificar más adelante si necesita modificar la consulta.parameters. Contiene los parámetros de la configuración de transferencia creada en formato JSON. Por ejemplo:--params='{"param":"param_value"}'.- En el caso de las consultas programadas, debe proporcionar el parámetro
query. - El parámetro
destination_table_name_templatees el nombre de la tabla de destino.- Este parámetro es opcional para las consultas de DDL y DML. Es obligatorio para todas las demás consultas.
- En el parámetro
write_disposition, puede elegirWRITE_TRUNCATEpara truncar (sobrescribir) la tabla de destino oWRITE_APPENDpara añadir los resultados de la consulta a la tabla de destino.- Este parámetro es opcional para las consultas de DDL y DML. Es obligatorio para todas las demás consultas.
- En el caso de las consultas programadas, debe proporcionar el parámetro
data_source. La fuente de datos:scheduled_query.- Opcional: La marca
--service_account_namese usa para autenticar con una cuenta de servicio en lugar de con una cuenta de usuario individual. - Opcional:
--destination_kms_keyespecifica el ID de recurso de la clave de la clave de Cloud KMS. Por ejemplo,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.
Por ejemplo, el siguiente comando crea una configuración de transferencia de consulta programada llamada My Scheduled Query con la consulta SELECT 1
from mydataset.test. La tabla de destino mytable se trunca en cada escritura y el conjunto de datos de destino es mydataset. La consulta programada se crea en el proyecto predeterminado y se autentica como cuenta de servicio:
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.
La primera vez que ejecutes el comando, recibirás un mensaje como el siguiente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Sigue las instrucciones del mensaje y pega el código de autenticación en la línea de comandos.
API
Usa el método projects.locations.transferConfigs.create y proporciona una instancia del recurso TransferConfig.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Configurar consultas programadas con una cuenta de servicio
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Ver el estado de una consulta programada
Consola
Para ver el estado de las consultas programadas, en el menú de navegación, haga clic en Programación y filtre por Consulta programada. Haz clic en una consulta programada para obtener más información sobre ella.
bq
Las consultas programadas son un tipo de transferencia. Para ver los detalles de una consulta programada, primero puede usar la herramienta de línea de comandos bq para enumerar sus configuraciones de transferencia.
Introduce el comando bq ls y proporciona la marca de transferencia
--transfer_config. También se necesitan las siguientes marcas:
--transfer_location
Por ejemplo:
bq ls \
--transfer_config \
--transfer_location=us
Para mostrar los detalles de una sola consulta programada, introduce el comando bq show
y proporciona el transfer_path de esa consulta programada o configuración de transferencia.
Por ejemplo:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
Usa el método projects.locations.transferConfigs.list y proporciona una instancia del recurso TransferConfig.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Actualizar consultas programadas
Consola
Para actualizar una consulta programada, sigue estos pasos:
- En el menú de navegación, haga clic en Consultas programadas o en Programación.
- En la lista de consultas programadas, haga clic en el nombre de la consulta que quiera cambiar.
- En la página Detalles de la consulta programada que se abre, haga clic en Editar.
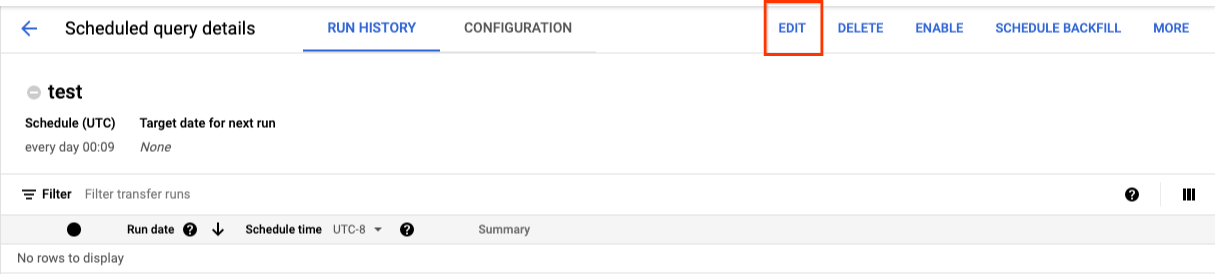
- Opcional: Cambia el texto de la consulta en el panel de edición de consultas.
- Haz clic en Programar consulta y, a continuación, selecciona Actualizar consulta programada.
- Opcional: Cambia cualquier otra opción de programación de la consulta.
- Haz clic en Actualizar.
bq
Las consultas programadas son un tipo de transferencia. Para actualizar una consulta programada, puedes usar la herramienta de línea de comandos bq para crear una configuración de transferencia.
Introduce el comando bq update con la marca --transfer_config
obligatoria.
Marcas posibles
--project_ides el ID del proyecto. Si no se especifica--project_id, se usa el proyecto predeterminado.--schedulees la frecuencia con la que quieres que se ejecute la consulta. Si no se especifica--schedule, el valor predeterminado es "cada 24 horas" según la hora de creación.--service_account_namesolo tiene efecto si también se define--update_credentials. Para obtener más información, consulta Actualizar las credenciales de una consulta programada.--target_dataset(opcional para las consultas DDL y DML) es una forma alternativa de asignar un nombre al conjunto de datos de destino de los resultados de la consulta cuando se usa con consultas DDL y DML.--display_namees el nombre de la consulta programada.--paramslos parámetros de la configuración de transferencia creada en formato JSON. Por ejemplo: --params='{"param":"param_value"}'.--destination_kms_keyespecifica el ID de recurso de la clave de Cloud KMS si usas una clave de cifrado gestionada por el cliente (CMEK) para esta transferencia. Para obtener información sobre cómo funcionan las claves de cifrado gestionadas por el cliente (CMEK) con BigQuery Data Transfer Service, consulta Especificar una clave de cifrado con consultas programadas.
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
Haz los cambios siguientes:
dataset. El conjunto de datos de destino de la configuración de la transferencia. Este parámetro es opcional para las consultas de DDL y DML. Es obligatorio para el resto de las consultas.name. Nombre visible de la configuración de transferencia. El nombre visible puede ser cualquier valor que pueda identificar más adelante si necesita modificar la consulta.parameters. Contiene los parámetros de la configuración de transferencia creada en formato JSON. Por ejemplo:--params='{"param":"param_value"}'.- En el caso de las consultas programadas, debe proporcionar el parámetro
query. - El parámetro
destination_table_name_templatees el nombre de la tabla de destino. Este parámetro es opcional para las consultas de DDL y DML. Es obligatorio para el resto de las consultas. - En el parámetro
write_disposition, puede elegirWRITE_TRUNCATEpara truncar (sobrescribir) la tabla de destino oWRITE_APPENDpara añadir los resultados de la consulta a la tabla de destino. Este parámetro es opcional para las consultas DDL y DML. Es obligatorio para el resto de las consultas.
- En el caso de las consultas programadas, debe proporcionar el parámetro
- Opcional:
--destination_kms_keyespecifica el ID de recurso de la clave de la clave de Cloud KMS. Por ejemplo,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. RESOURCE_NAME: El nombre de recurso de la transferencia (también denominado "configuración de transferencia"). Si no sabes el nombre del recurso de la transferencia, puedes encontrarlo con:bq ls --transfer_config --transfer_location=location.
Por ejemplo, el siguiente comando actualiza una configuración de transferencia de consulta programada llamada My Scheduled Query con la consulta SELECT 1
from mydataset.test. La tabla de destino mytable se trunca en cada escritura y el conjunto de datos de destino es mydataset:
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
Usa el método projects.transferConfigs.patch
y proporciona el nombre de recurso de la transferencia mediante el parámetro
transferConfig.name. Si no sabes el nombre de recurso de la transferencia, usa el comando bq ls --transfer_config --transfer_location=location para enumerar todas las transferencias o llama al método projects.locations.transferConfigs.list y proporciona el ID de proyecto mediante el parámetro parent.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Actualizar consultas programadas con restricciones de propiedad
Si intentas actualizar una consulta programada que no es tuya, es posible que la actualización falle y se muestre el siguiente mensaje de error:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
El propietario de la consulta programada es el usuario asociado a la consulta programada o el usuario que tiene acceso a la cuenta de servicio asociada a la consulta programada. El usuario asociado se puede ver en los detalles de configuración de la consulta programada. Para obtener información sobre cómo actualizar la consulta programada para tomar la propiedad, consulta Actualizar las credenciales de una consulta programada. Para conceder acceso a una cuenta de servicio a los usuarios, debes tener el rol Usuario de cuenta de servicio.
Los parámetros restringidos de las consultas programadas son los siguientes:
- El texto de la consulta
- El conjunto de datos de destino
- La plantilla de nombre de tabla de destino
Actualizar las credenciales de una consulta programada
Si vas a programar una consulta, es posible que tengas que actualizar las credenciales del usuario en la consulta. Las credenciales se actualizan automáticamente para las nuevas consultas programadas.
Estas son otras situaciones en las que podría ser necesario actualizar las credenciales:
- Quieres consultar datos de Google Drive en una consulta programada.
Recibes un error INVALID_USER cuando intentas programar la consulta:
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERIDRecibes el siguiente error de parámetros restringidos cuando intentas actualizar la consulta:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Consola
Para actualizar las credenciales de una consulta programada, sigue estos pasos:
Haz clic en el botón MÁS y selecciona Actualizar credenciales.
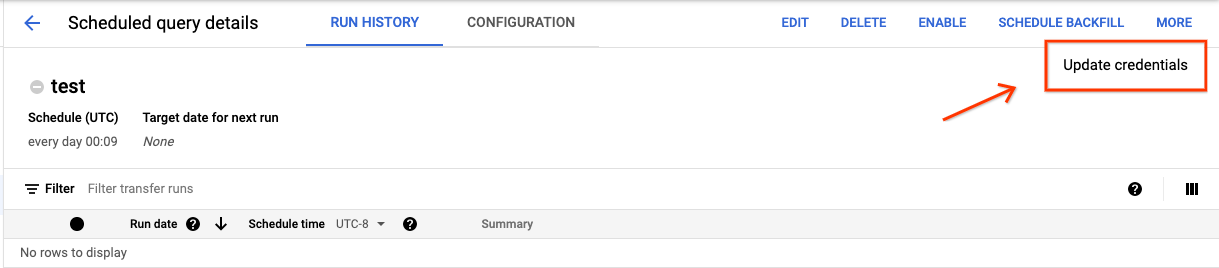
Espera entre 10 y 20 minutos para que el cambio se aplique. Es posible que tengas que borrar la caché del navegador.
bq
Las consultas programadas son un tipo de transferencia. Para actualizar las credenciales de una consulta programada, puedes usar la herramienta de línea de comandos bq para actualizar la configuración de la transferencia.
Introduce el comando bq update y proporciona la marca de transferencia
--transfer_config. También se necesitan las siguientes marcas:
--update_credentials
Marca opcional:
--service_account_namese usa para autenticar tu consulta programada con una cuenta de servicio en lugar de con tu cuenta de usuario.
Por ejemplo, el siguiente comando actualiza una configuración de transferencia de consulta programada para autenticarla como cuenta de servicio:
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test. \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Configurar una ejecución manual en fechas anteriores
Además de programar una consulta para que se ejecute en el futuro, también puedes activarla manualmente para que se ejecute de inmediato. Sería necesario activar una ejecución inmediata si tu consulta usa el parámetro run_date y ha habido problemas durante una ejecución anterior.
Por ejemplo, todos los días a las 09:00, consulta una tabla de origen para obtener las filas que coincidan con la fecha actual. Sin embargo, observa que no se han añadido datos a la tabla de origen en los últimos tres días. En esta situación, puedes configurar la consulta para que se ejecute en datos históricos dentro de un intervalo de fechas que especifiques. La consulta se ejecuta con combinaciones de parámetros run_date y run_time que corresponden a las fechas que has configurado en la consulta programada.
Una vez que hayas configurado una consulta programada, puedes ejecutarla con un periodo histórico de la siguiente manera:
Consola
Después de hacer clic en Programar para guardar la consulta programada, puedes hacer clic en el botón Consultas programadas para ver la lista de consultas programadas. Haz clic en cualquier nombre visible para ver los detalles de la programación de la consulta. En la parte superior derecha de la página, haz clic en Programar carga retroactiva para especificar un periodo anterior.
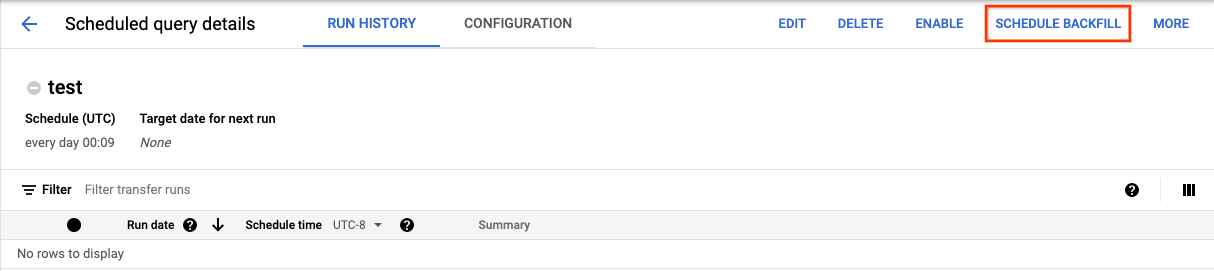
Todos los tiempos de ejecución elegidos están dentro del intervalo seleccionado, incluida la primera fecha y excluida la última.
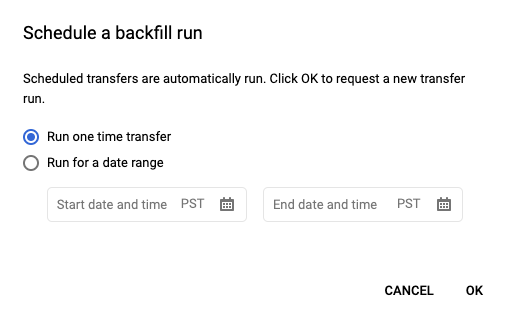
Ejemplo 1
La consulta programada se ejecutará a las every day 09:00 (hora del Pacífico). Te faltan datos del 1, el 2 y el 3 de enero. Elige el siguiente intervalo de fechas:
Start Time = 1/1/19
End Time = 1/4/19
La consulta se ejecuta con los parámetros run_date y run_time, que corresponden a las siguientes horas:
- 1/1/19 09:00 (hora del Pacífico)
- 2/1/19 09:00 (hora del Pacífico)
- 1/3/19 09:00 (hora del Pacífico)
Ejemplo 2
La consulta programada se ejecutará a las every day 23:00 (hora del Pacífico). Te faltan datos del 1, el 2 y el 3 de enero. Elige los siguientes periodos históricos (se eligen fechas posteriores porque la hora UTC tiene una fecha diferente a las 23:00 de la hora del Pacífico):
Start Time = 1/2/19
End Time = 1/5/19
La consulta se ejecuta con los parámetros run_date y run_time, que corresponden a las siguientes horas:
- 1/2/19 06:00 UTC o 1/1/2019 23:00 (hora del Pacífico)
- 1/3/19 06:00 UTC o 1/2/2019 23:00 (hora del Pacífico)
- 4/1/19 a las 06:00 (UTC) o 3/1/2019 a las 23:00 (hora del Pacífico)
Después de configurar las ejecuciones manuales, actualiza la página para verlas en la lista de ejecuciones.
bq
Para ejecutar manualmente la consulta en un periodo del historial, siga estos pasos:
Introduce el comando bq mk y proporciona la marca de ejecución de la transferencia
--transfer_run. También se necesitan las siguientes marcas:
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
Haz los cambios siguientes:
start_timeyend_time. Marcas de tiempo que terminan en Z o que contienen una diferencia horaria válida. Ejemplos:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name. Nombre de recurso de la consulta programada (o de la transferencia). El nombre de recurso también se conoce como configuración de transferencia.
Por ejemplo, el siguiente comando programa un relleno para el recurso de consulta programada (o configuración de transferencia):
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7.
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Para obtener más información, consulta bq mk --transfer_run.
API
Usa el método projects.locations.transferConfigs.scheduleRun y proporciona una ruta del recurso TransferConfig.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Configurar alertas para consultas programadas
Puede configurar políticas de alertas para consultas programadas basadas en métricas de recuento de filas. Para obtener más información, consulte Configurar alertas con consultas programadas.
Eliminar consultas programadas
Consola
Para eliminar una consulta programada en la página Consultas programadas de la Google Cloud consola, siga estos pasos:
- En el menú de navegación, haga clic en Consultas programadas.
- En la lista de consultas programadas, haga clic en el nombre de la consulta programada que quiera eliminar.
En la página Detalles de la consulta programada, haga clic en Eliminar.
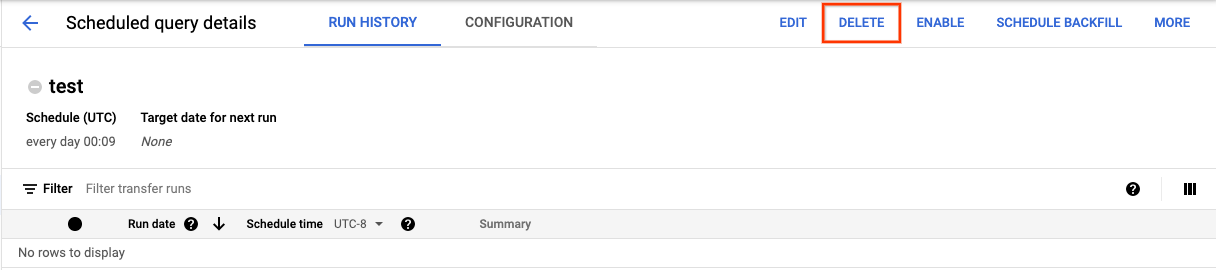
También puedes eliminar una consulta programada en la página Programación de la consola de Google Cloud :
- En el menú de navegación, haga clic en Programación.
- En la lista de consultas programadas, haga clic en el menú Acciones de la consulta programada que quiera eliminar.
Selecciona Eliminar.

Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Habilitar o inhabilitar consultas programadas
Para pausar las ejecuciones programadas de una consulta seleccionada sin eliminar la programación, puedes inhabilitarla.
Para inhabilitar una programación de una consulta seleccionada, sigue estos pasos:
- En el menú de navegación de la Google Cloud consola, haz clic en Programación.
- En la lista de consultas programadas, haz clic en el menú Acciones de la consulta programada que quieras inhabilitar.
Selecciona Disable (Inhabilitar).

Para habilitar una consulta programada inhabilitada, haga clic en el menú Acciones de la consulta programada que quiera habilitar y seleccione Habilitar.
Cuotas
Las consultas programadas siempre se ejecutan como tareas de consulta por lotes y están sujetas a las mismas cuotas y límites de BigQuery que las consultas manuales.
A pesar de que las consultas programadas utilizan funciones de BigQuery Data Transfer Service, no son transferencias ni están sujetas a las cuotas de las tareas de carga.
La identidad utilizada para ejecutar la consulta determina qué cuotas se aplican. Esto depende de la configuración de la consulta programada:
Credenciales del creador (predeterminadas): si no especificas una cuenta de servicio, la consulta programada se ejecuta con las credenciales del usuario que la creó. El trabajo de consulta se factura al proyecto del creador y está sujeto a las cuotas de ese usuario y proyecto.
Credenciales de cuenta de servicio: si configuras la consulta programada para que use una cuenta de servicio, se ejecutará con las credenciales de la cuenta de servicio. En este caso, el trabajo se sigue facturando al proyecto que contiene la consulta programada, pero la ejecución está sujeta a las cuotas de la cuenta de servicio especificada.
Precios
Las consultas programadas tienen el mismo precio que las consultas de BigQuery manuales.
Regiones disponibles
Las consultas programadas se admiten en las siguientes ubicaciones.
Regiones
En la siguiente tabla se indican las regiones de América en las que está disponible BigQuery.| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Columbus (Ohio) | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Las Vegas | us-west4 |
|
| Los Ángeles | us-west2 |
|
| México | northamerica-south1 |
|
| Montreal | northamerica-northeast1 |
|
| Norte de Virginia | us-east4 |
|
| Oregón | us-west1 |
|
| Salt Lake City | us-west3 |
|
| São Paulo | southamerica-east1 |
|
| Santiago | southamerica-west1 |
|
| Carolina del Sur | us-east1 |
|
| Toronto | northamerica-northeast2 |
|
| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Deli | asia-south2 |
|
| Hong Kong | asia-east2 |
|
| Yakarta | asia-southeast2 |
|
| Melbourne | australia-southeast2 |
|
| Bombay | asia-south1 |
|
| Osaka | asia-northeast2 |
|
| Seúl | asia-northeast3 |
|
| Singapur | asia-southeast1 |
|
| Sídney | australia-southeast1 |
|
| Taiwán | asia-east1 |
|
| Tokio | asia-northeast1 |
| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Bélgica | europe-west1 |
|
| Berlín | europe-west10 |
|
| Finlandia | europe-north1 |
|
| Fráncfort | europe-west3 |
|
| Londres | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Milán | europe-west8 |
|
| Países Bajos | europe-west4 |
|
| París | europe-west9 |
|
| Estocolmo | europe-north2 |
|
| Turín | europe-west12 |
|
| Varsovia | europe-central2 |
|
| Zúrich | europe-west6 |
|
| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Dammam | me-central2 |
|
| Doha | me-central1 |
|
| Tel Aviv | me-west1 |
| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Johannesburgo | africa-south1 |
Multirregional
En la siguiente tabla se indican las multirregiones en las que está disponible BigQuery.| Descripción multirregional | Nombre multirregional |
|---|---|
| Centros de datos en Estados miembros de la Unión Europea1 | EU |
| Centros de datos en Estados Unidos2 | US |
1 Los datos ubicados en la multirregión EU solo se almacenan en una de las siguientes ubicaciones: europe-west1 (Bélgica) o europe-west4 (Países Bajos).
BigQuery determina automáticamente la ubicación exacta en la que se almacenan y procesan los datos.
2 Los datos ubicados en la multirregión US solo se almacenan en una de las siguientes ubicaciones: us-central1 (Iowa), us-west1 (Oregón) o us-central2 (Oklahoma). BigQuery determina automáticamente la ubicación exacta en la que se almacenan y procesan los datos.
Siguientes pasos
- Para ver un ejemplo de una consulta programada que usa una cuenta de servicio e incluye los parámetros
@run_datey@run_time, consulta Crear copias de una tabla con una consulta programada.