Trasmetti in streaming gli aggiornamenti delle tabelle con Change Data Capture
BigQuery Change Data Capture (CDC) aggiorna le tabelle BigQuery elaborando e applicando le modifiche trasmesse in streaming ai dati esistenti. Questa sincronizzazione viene eseguita tramite operazioni di inserimento/aggiornamento ed eliminazione di righe che vengono trasmesse in streaming in tempo reale dall'API BigQuery Storage Write, che devi conoscere prima di procedere.
Prima di iniziare
Concedi i ruoli IAM (Identity and Access Management) che forniscono agli utenti le autorizzazioni necessarie per eseguire ogni attività descritta in questo documento e assicurati che il tuo flusso di lavoro soddisfi ogni prerequisito.
Autorizzazioni obbligatorie
Per ottenere l'autorizzazione
necessaria per utilizzare l'API Storage Write,
chiedi all'amministratore di concederti il
ruolo IAM Editor dati BigQuery (roles/bigquery.dataEditor).
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questo ruolo predefinito contiene l'autorizzazione
bigquery.tables.updateData
necessaria per
utilizzare l'API Storage Write.
Potresti anche ottenere questa autorizzazione con ruoli personalizzati o altri ruoli predefiniti.
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Prerequisiti
Per utilizzare BigQuery CDC, il flusso di lavoro deve soddisfare le seguenti condizioni:
- Devi utilizzare l'API Storage Write nello stream predefinito.
- Devi utilizzare il formato protobuf come formato di importazione. Il formato Apache Arrow non è supportato.
- Devi dichiarare le chiavi primarie per la tabella di destinazione in BigQuery. Sono supportate le chiavi primarie composite contenenti fino a 16 colonne.
- Devono essere disponibili risorse di calcolo BigQuery sufficienti per eseguire le operazioni sulle righe CDC. Tieni presente che se le operazioni di modifica delle righe CDC non riescono, potresti conservare involontariamente i dati che intendevi eliminare. Per ulteriori informazioni, consulta la sezione Considerazioni sui dati eliminati.
Specificare le modifiche ai record esistenti
In BigQuery CDC, la pseudocolonna _CHANGE_TYPE indica il
tipo di modifica da elaborare per ogni riga. Per utilizzare CDC, imposta _CHANGE_TYPE quando
trasmetti in streaming le modifiche alle righe utilizzando l'API Storage Write. La
pseudocolonna _CHANGE_TYPE accetta solo i valori UPSERT e DELETE.
Una tabella viene considerata abilitata per CDC mentre l'API Storage Write
trasmette in streaming le modifiche alle righe della tabella in questo modo.
Esempio con valori UPSERT e DELETE
Considera la seguente tabella in BigQuery:
| ID | Nome | Stipendio |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
Le seguenti modifiche alle righe vengono trasmesse in streaming dall'API Storage Write:
| ID | Nome | Stipendio | _CHANGE_TYPE |
|---|---|---|---|
| 100 | ELIMINA | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
La tabella aggiornata è ora la seguente:
| ID | Nome | Stipendio |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
Gestisci l'obsolescenza delle tabelle
Per impostazione predefinita, ogni volta che esegui una query, BigQuery restituisce i risultati più aggiornati. Per fornire i risultati più recenti quando esegui una query su una tabella abilitata per CDC, BigQuery deve applicare ogni modifica alla riga trasmessa in streaming fino all'ora di inizio della query, in modo che venga eseguita una query sulla versione più aggiornata della tabella. L'applicazione di queste modifiche alle righe in fase di esecuzione della query aumenta la latenza e il costo della query. Tuttavia, se non hai bisogno di risultati di query completamente aggiornati,
puoi ridurre i costi e la latenza delle query impostando l'opzione max_staleness
nella tabella. Quando questa opzione è impostata, BigQuery applica
le modifiche alle righe almeno una volta nell'intervallo definito dal valore
max_staleness, consentendoti di eseguire query senza attendere l'applicazione degli aggiornamenti, a costo di una certa inattività dei dati.
Questo comportamento è particolarmente utile per i dashboard e i report per i quali l'aggiornamento dei dati non è essenziale. È utile anche per la gestione dei costi, in quanto ti offre un maggiore controllo sulla frequenza con cui BigQuery applica le modifiche alle righe.
Esegui query sulle tabelle con l'opzione max_staleness impostata
Quando esegui una query su una tabella con l'opzione max_staleness impostata,
BigQuery restituisce il risultato in base al valore di max_staleness
e all'ora in cui è stato eseguito l'ultimo job di applicazione, rappresentata
dal timestamp upsert_stream_apply_watermark della tabella.
Considera il seguente esempio, in cui una tabella ha l'opzione max_staleness
impostata su 10 minuti e l'ultima applicazione del job è avvenuta alle ore 20:00:
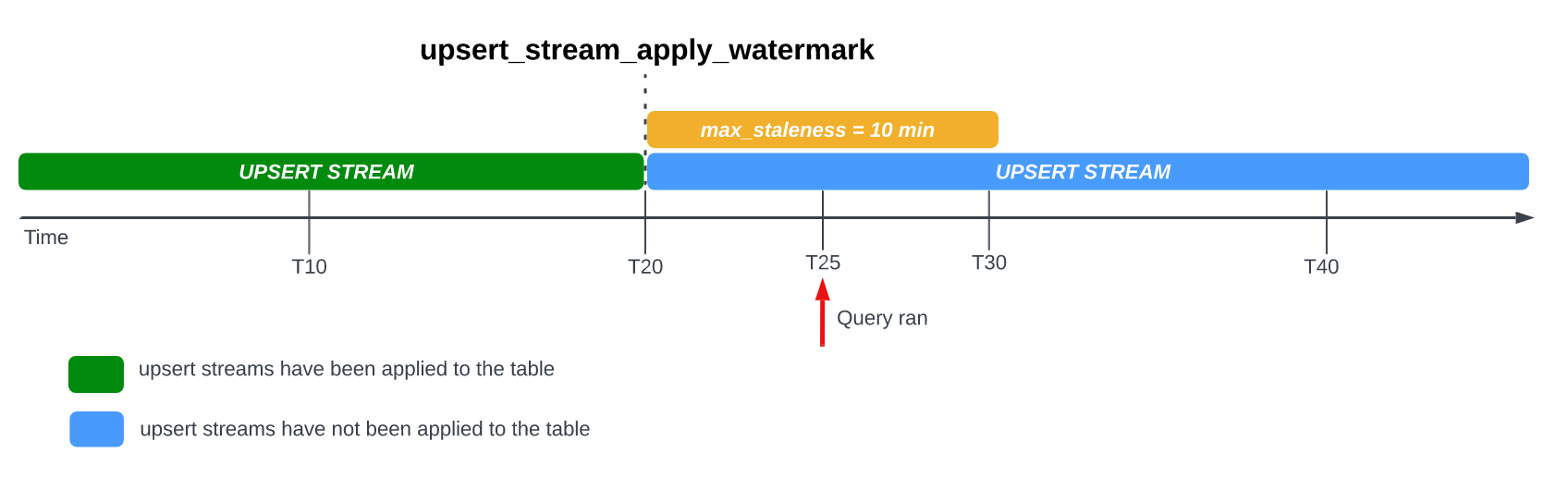
Se esegui una query sulla tabella a T25, la versione attuale della tabella è obsoleta di 5 minuti, ovvero meno dell'intervallo max_staleness di 10 minuti. In
questo caso, BigQuery restituisce la versione della tabella alle ore 20:00,
il che significa che i dati restituiti sono anche obsoleti di 5 minuti.
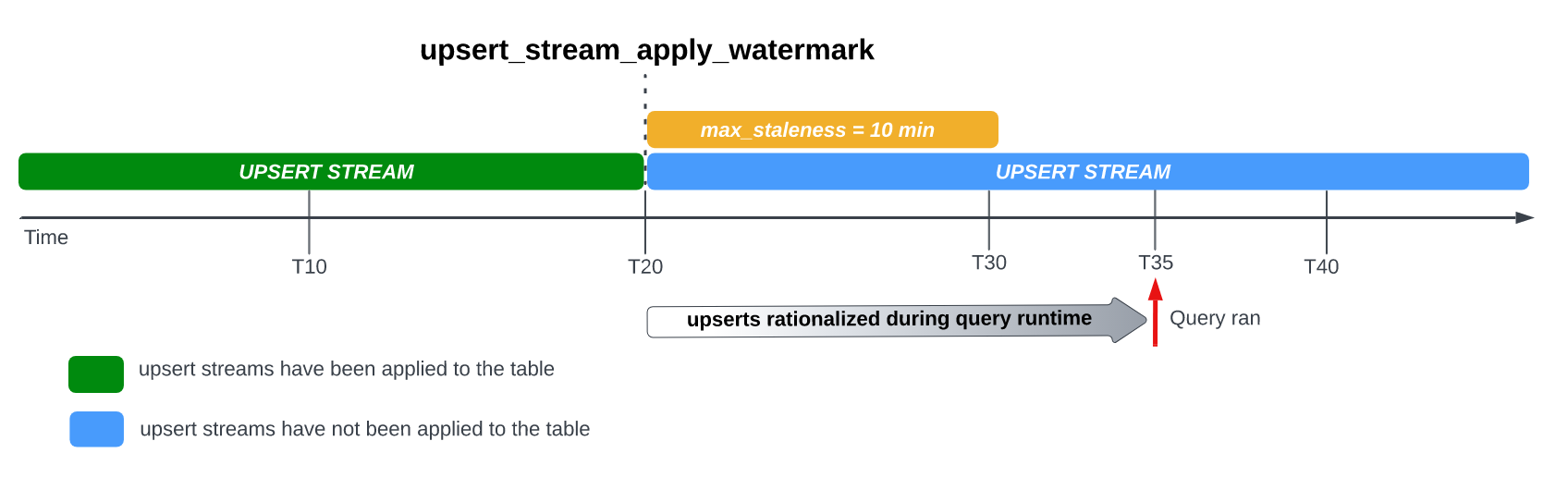
Quando imposti l'opzione max_staleness nella tabella, BigQuery
applica le modifiche alle righe in attesa almeno una volta nell'intervallo max_staleness. In alcuni casi, tuttavia, BigQuery potrebbe non completare
l'applicazione di queste modifiche alle righe in attesa entro l'intervallo.
Ad esempio, se esegui una query sulla tabella all'ora T35 e il processo di applicazione delle modifiche alle righe in attesa non è stato completato, la versione corrente della tabella è obsoleta di 15 minuti, ovvero un intervallo superiore a max_staleness di 10 minuti.
In questo caso, al momento dell'esecuzione della query, BigQuery applica tutte le modifiche alle righe tra T20 e T35 per la query corrente, il che significa che i dati sottoposti a query sono completamente aggiornati, a costo di una latenza aggiuntiva della query.
Questo è considerato un job di unione in fase di runtime.
Valore consigliato per table max_staleness
Il valore max_staleness di una tabella dovrebbe in genere essere il maggiore dei due valori seguenti:
- Il livello massimo di obsolescenza dei dati tollerabile per il flusso di lavoro.
- Il doppio del tempo massimo necessario per applicare le modifiche di upsert nella tabella, più un buffer aggiuntivo.
Per calcolare il tempo necessario per applicare le modifiche upsert a una tabella esistente, utilizza la seguente query SQL per determinare la durata del 95° percentile dei job di applicazione in background, più un buffer di sette minuti per consentire la conversione dell'archiviazione ottimizzata per la scrittura (buffer di streaming) di BigQuery.
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Sostituisci quanto segue:
REGION: il nome della regione in cui si trova il progetto. Ad esempio,us.PROJECT_ID: l'ID del progetto contenente le tabelle BigQuery che vengono modificate da BigQuery CDC.
La durata dei job di applicazione in background è influenzata da diversi fattori, tra cui il numero e la complessità delle operazioni CDC emesse nell'intervallo di non aggiornamento, le dimensioni della tabella e la disponibilità delle risorse BigQuery. Per ulteriori informazioni sulla disponibilità delle risorse, consulta Dimensiona e monitora le prenotazioni BACKGROUND.
Crea una tabella con l'opzione max_staleness
Per creare una tabella con l'opzione max_staleness, utilizza l'istruzione
CREATE TABLE.
L'esempio seguente crea la tabella employees con un limite max_staleness di 10 minuti:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
Modificare l'opzione max_staleness per una tabella esistente
Per aggiungere o modificare un limite max_staleness in una tabella esistente, utilizza l'istruzione
ALTER TABLE.
L'esempio seguente modifica il limite max_staleness della tabella employees
a 15 minuti:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Determinare il valore max_staleness attuale di una tabella
Per determinare il valore max_staleness attuale di una tabella, esegui una query sulla
vista INFORMATION_SCHEMA.TABLE_OPTIONS.
L'esempio seguente controlla il valore max_staleness corrente della tabella
mytable:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Sostituisci quanto segue:
DATASET_NAME: il nome del set di dati in cui risiede la tabella abilitata a CDC.TABLE_NAME: il nome della tabella abilitata per CDC.
I risultati mostrano che il valore di max_staleness è 10 minuti:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Monitorare l'avanzamento dell'operazione di upsert della tabella
Per monitorare lo stato di una tabella e controllare quando sono state applicate le ultime modifiche alle righe, esegui una query sulla vista INFORMATION_SCHEMA.TABLES per ottenere il timestamp upsert_stream_apply_watermark.
Il seguente esempio controlla il valore upsert_stream_apply_watermark della tabella mytable:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Sostituisci quanto segue:
DATASET_NAME: il nome del set di dati in cui risiede la tabella abilitata a CDC.TABLE_NAME: il nome della tabella abilitata per CDC.
Il risultato è simile al seguente:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
Le operazioni di upsert vengono eseguite dal account di servizio bigquery-adminbot@system.gserviceaccount.com e vengono visualizzate nella cronologia dei job del progetto contenente la tabella abilitata per CDC.
Gestire l'ordinamento personalizzato
Quando esegui l'upsert in streaming in BigQuery, il comportamento predefinito di ordinamento dei record con chiavi primarie identiche è determinato dall'ora di sistema di BigQuery in cui il record è stato importato in BigQuery. In altre parole, il record inserito più di recente con il timestamp più recente ha la precedenza sul record inserito in precedenza con un timestamp precedente. Per alcuni casi d'uso, ad esempio quelli in cui possono verificarsi upsert molto frequenti nella stessa chiave primaria in un intervallo di tempo molto breve o in cui l'ordine di upsert non è garantito, questo potrebbe non essere sufficiente. Per questi scenari, potrebbe essere necessaria una chiave di ordinamento fornita dall'utente.
Per configurare le chiavi di ordinamento fornite dall'utente, la pseudocolonna
_CHANGE_SEQUENCE_NUMBER viene utilizzata per indicare l'ordine in cui
BigQuery deve applicare i record, in base al valore
_CHANGE_SEQUENCE_NUMBER più grande tra due record corrispondenti con la stessa chiave
primaria. La pseudocolonna _CHANGE_SEQUENCE_NUMBER è una colonna facoltativa e accetta solo valori in un formato fisso STRING.
Formato _CHANGE_SEQUENCE_NUMBER
La pseudocolonna _CHANGE_SEQUENCE_NUMBER accetta solo valori STRING,
scritti in un formato fisso. Questo formato fisso utilizza valori STRING scritti in
esadecimale, separati in sezioni da una barra /. Ogni sezione può essere
espressa in un massimo di 16 caratteri esadecimali e sono consentite fino a quattro sezioni
per _CHANGE_SEQUENCE_NUMBER. L'intervallo consentito di
_CHANGE_SEQUENCE_NUMBER supporta valori compresi tra 0/0/0/0 e
FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
I valori _CHANGE_SEQUENCE_NUMBER supportano caratteri maiuscoli e minuscoli.
L'espressione delle chiavi di ordinamento di base può essere eseguita utilizzando una singola sezione. Ad esempio, per ordinare le chiavi in base al timestamp di elaborazione di un record da un server delle applicazioni, puoi utilizzare una sezione: '2024-04-30 11:19:44 UTC', espressa in esadecimale convertendo il timestamp in millisecondi dall'epoca, '18F2EBB6480' in questo caso. La logica per convertire i dati in esadecimale
è responsabilità del client che esegue la scrittura in BigQuery
utilizzando l'API Storage Write.
Il supporto di più sezioni consente di combinare diversi valori di logica di elaborazione
in un'unica chiave per casi d'uso più complessi. Ad esempio, per ordinare le chiavi in base al timestamp di elaborazione di un record da un server delle applicazioni, a un numero di sequenza di log e allo stato del record, puoi utilizzare tre sezioni: '2024-04-30 11:19:44 UTC' / '123' / 'complete', ciascuna espressa in formato esadecimale.
L'ordine delle sezioni è un aspetto importante da considerare per il ranking della logica di elaborazione. BigQuery confronta i valori _CHANGE_SEQUENCE_NUMBER
confrontando la prima sezione e poi confrontando la sezione successiva solo se
le sezioni precedenti erano uguali.
BigQuery utilizza _CHANGE_SEQUENCE_NUMBER per eseguire l'ordinamento
confrontando due o più campi _CHANGE_SEQUENCE_NUMBER come valori numerici
senza segno.
Considera i seguenti esempi di confronto _CHANGE_SEQUENCE_NUMBER e i relativi risultati di precedenza:
Esempio 1:
- Record n. 1:
_CHANGE_SEQUENCE_NUMBER= "77" - Record n. 2:
_CHANGE_SEQUENCE_NUMBER= "7B"
Risultato: il record n. 2 è considerato l'ultimo perché "7B" > "77" (ovvero "123" > "119")
- Record n. 1:
Esempio 2:
- Record n. 1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - Record n. 2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
Risultato: il record n. 2 è considerato l'ultimo perché "FFF/ABC" > "FFF/B" (ovvero "4095/2748" > "4095/11")
- Record n. 1:
Esempio 3:
- Record n° 1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - Record n. 2:
_CHANGE_SEQUENCE_NUMBER= "ABC"
Risultato: il record n. 2 è considerato l'ultimo record perché "ABC" > "BA/FFFFFFFF" (ovvero "2748" > "186/4294967295")
- Record n° 1:
Esempio 4:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - Record n. 2:
_CHANGE_SEQUENCE_NUMBER= "ABC"
Risultato: il record n. 1 è considerato l'ultimo perché "FFF/ABC" > "ABC" (ovvero "4095/2748" > "2748")
- Record #1:
Se due valori _CHANGE_SEQUENCE_NUMBER sono identici, il record con l'ora di importazione più recente nel sistema BigQuery ha la precedenza sui record importati in precedenza.
Quando viene utilizzato l'ordinamento personalizzato per una tabella, il valore _CHANGE_SEQUENCE_NUMBER
deve essere sempre fornito. Le richieste di scrittura che non specificano il valore di _CHANGE_SEQUENCE_NUMBER, con conseguente mix di righe con e senza valori di _CHANGE_SEQUENCE_NUMBER, comportano un ordinamento imprevedibile.
Configura una prenotazione BigQuery da utilizzare con CDC
Puoi utilizzare le prenotazioni BigQuery per allocare risorse di calcolo BigQuery dedicate per le operazioni di modifica delle righe CDC. Le prenotazioni ti consentono di impostare un limite per il costo dell'esecuzione di queste operazioni. Questo approccio è particolarmente utile per i workflow con operazioni CDC frequenti su tabelle di grandi dimensioni, che altrimenti avrebbero costi on demand elevati a causa del gran numero di byte elaborati durante l'esecuzione di ogni operazione.
I job BigQuery CDC che applicano le modifiche alle righe in attesa entro l'intervallo max_staleness sono considerati job in background e utilizzano il tipo di assegnazione BACKGROUND anziché il tipo di assegnazione QUERY.
Al contrario, le query al di fuori dell'intervallo max_staleness che richiedono l'applicazione di modifiche alle righe in fase di esecuzione della query utilizzano il tipo di assegnazione QUERY. Le tabelle senza un'impostazione max_staleness o le tabelle con max_staleness impostato su 0 utilizzano anche il tipo di assegnazione QUERY.
I job in background CDC di BigQuery eseguiti senza un'assegnazione BACKGROUND
utilizzano i prezzi on demand.
Questa considerazione è importante quando progetti la strategia di gestione dei carichi di lavoro per BigQuery CDC.
Per configurare una prenotazione BigQuery da utilizzare con CDC, inizia
configurando una prenotazione
nella regione in cui si trovano le tabelle BigQuery. Per indicazioni sulle dimensioni della prenotazione, consulta
Dimensioni e monitoraggio delle prenotazioni BACKGROUND.
Dopo aver creato una prenotazione,
assegna il progetto BigQuery
alla prenotazione e imposta l'opzione job_type su BACKGROUND eseguendo la seguente
istruzione CREATE ASSIGNMENT:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Sostituisci quanto segue:
ADMIN_PROJECT_ID: l'ID del progetto di amministrazione proprietario della prenotazione.REGION: il nome della regione in cui si trova il progetto. Ad esempio,us.RESERVATION_NAME: il nome della prenotazione.ASSIGNMENT_ID: l'ID dell'assegnazione. L'ID deve essere univoco per il progetto e la località, iniziare e terminare con una lettera minuscola o un numero e contenere solo lettere minuscole, numeri e trattini.PROJECT_ID: l'ID del progetto contenente le tabelle BigQuery modificate da BigQuery CDC. Questo progetto è assegnato alla prenotazione.
Dimensioni e monitoraggio delle prenotazioni di BACKGROUND
Le prenotazioni determinano la quantità di risorse di calcolo disponibili per eseguire le operazioni di calcolo BigQuery. La sottodimensionamento di una prenotazione può
aumentare il tempo di elaborazione delle operazioni di modifica delle righe CDC. Per dimensionare una
prenotazione in modo accurato, monitora il consumo storico di slot per il progetto che
esegue le operazioni CDC eseguendo query sulla
visualizzazione INFORMATION_SCHEMA.JOBS_TIMELINE:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Sostituisci REGION con il
nome della regione in cui si trova il tuo progetto. Ad
esempio, us.
Considerazioni sui dati eliminati
- Le operazioni CDC di BigQuery utilizzano risorse di calcolo BigQuery. Se le operazioni CDC sono configurate per utilizzare la fatturazione on demand, vengono eseguite regolarmente utilizzando le risorse BigQuery interne. Se le
operazioni CDC sono configurate con una prenotazione
BACKGROUND, le operazioni CDC sono invece soggette alla disponibilità delle risorse della prenotazione configurata. Se non sono disponibili risorse sufficienti all'interno della prenotazione configurata, l'elaborazione delle operazioni CDC, inclusa l'eliminazione, potrebbe richiedere più tempo del previsto. - Un'operazione CDC
DELETEviene considerata applicata solo quando il timestampupsert_stream_apply_watermarkha superato il timestamp in cui l'API Storage Write ha trasmesso in streaming l'operazione. Per saperne di più sul timestampupsert_stream_apply_watermark, vedi Monitorare l'avanzamento dell'operazione di upsert della tabella. - Per applicare le operazioni CDC
DELETEche arrivano in modo non sequenziale, BigQuery mantiene una finestra di conservazione delle eliminazioni di due giorni. Le operazioni sulla tabellaDELETEvengono memorizzate per questo periodo prima dell'inizio della procedura di eliminazione dei dati Google Cloud standard. Le operazioniDELETEall'interno della finestra di conservazione per l'eliminazione utilizzano i prezzi di archiviazione di BigQuery standard.
Limitazioni
- BigQuery CDC non applica le chiavi, quindi è essenziale che le chiavi primarie siano univoche.
- Le chiavi primarie non possono superare le 16 colonne.
- Le tabelle abilitate per la CDC non possono avere più di 2000 colonne di primo livello definite dallo schema della tabella.
- Le tabelle abilitate per la CDC non supportano:
- Istruzioni
Data Manipulation Language (DML)
di mutazione come
DELETE,UPDATEeMERGE - Esecuzione di query sulle tabelle con caratteri jolly
- Indici di ricerca
- Istruzioni
Data Manipulation Language (DML)
di mutazione come
- Le tabelle abilitate per CDC che eseguono job di unione in fase di runtime perché il valore
max_stalenessdella tabella è troppo basso non possono supportare quanto segue: - Le operazioni di esportazione di BigQuery sulle tabelle abilitate a CDC non esportano le modifiche alle righe trasmesse in streaming di recente che devono ancora essere applicate da un job in background. Per esportare l'intera tabella, utilizza un'istruzione
EXPORT DATA. - Se la query attiva un'unione in fase di runtime su una tabella partizionata, viene scansionata l'intera tabella, indipendentemente dal fatto che la query sia limitata a un sottoinsieme delle partizioni.
- Se utilizzi Standard Edition,
le prenotazioni
BACKGROUNDnon sono disponibili, pertanto l'applicazione delle modifiche alle righe in attesa utilizza il modello di prezzo on demand. Tuttavia, puoi eseguire query sulle tabelle abilitate per CDC indipendentemente dalla tua edizione. - Le pseudocolonne
_CHANGE_TYPEe_CHANGE_SEQUENCE_NUMBERnon sono colonne interrogabili quando viene eseguita una lettura della tabella. - La combinazione di righe con valori
UPSERToDELETEper_CHANGE_TYPEcon righe con valoriINSERTo non specificati per_CHANGE_TYPEnella stessa connessione non è supportata e genera il seguente errore di convalida:The given value is not a valid CHANGE_TYPE.
Prezzi di BigQuery CDC
BigQuery CDC utilizza l'API Storage Write per l'importazione dei dati, BigQuery Storage per l'archiviazione dei dati e BigQuery Compute per le operazioni di modifica delle righe, tutte operazioni che comportano costi. Per informazioni sui prezzi, consulta la pagina Prezzi di BigQuery.
Stima dei costi di BigQuery CDC
Oltre alle best practice generali per la stima dei costi di BigQuery, la stima dei costi di BigQuery CDC potrebbe essere importante per i flussi di lavoro con grandi quantità di dati, una configurazione max_staleness bassa o dati che cambiano frequentemente.
I prezzi di importazione dati BigQuery e i prezzi di archiviazione di BigQuery vengono calcolati direttamente in base alla quantità di dati importati e archiviati, incluse le pseudocolonne. Tuttavia, i prezzi di calcolo di BigQuery possono essere più difficili da stimare, in quanto si riferiscono al consumo di risorse di calcolo utilizzate per eseguire i job BigQuery CDC.
I job BigQuery CDC sono suddivisi in tre categorie:
- Job di applicazione in background:job eseguiti in background a intervalli regolari
definiti dal valore
max_stalenessdella tabella. Questi job applicano le modifiche alle righe trasmesse di recente alla tabella abilitata per CDC. - Query sui job: query GoogleSQL eseguite all'interno della finestra
max_stalenesse che leggono solo dalla tabella di base CDC. - Job di unione runtime:job attivati da query GoogleSQL ad hoc eseguite al di fuori della finestra
max_staleness. Questi job devono eseguire un'unione al volo della tabella di base CDC e delle modifiche alle righe trasmesse di recente in fase di runtime della query.
Solo i job di query sfruttano il partizionamento BigQuery. I job di applicazione in background e di unione in fase di runtime non possono utilizzare il partizionamento perché, quando vengono applicate le modifiche alle righe trasmesse in streaming di recente, non è garantito a quale partizione della tabella vengono applicati gli upsert trasmessi in streaming di recente. In altre parole, la tabella di base completa viene letta durante i job di applicazione in background e i job di unione in fase di runtime. Per lo stesso motivo, solo i job di query possono trarre vantaggio dai filtri sulle colonne di clustering BigQuery. Comprendere la quantità di dati letti per eseguire operazioni CDC è utile per stimare il costo totale.
Se la quantità di dati letti dalla baseline della tabella è elevata, valuta la possibilità di utilizzare il modello di prezzi basato sulla capacità di BigQuery, che non si basa sulla quantità di dati elaborati.
Best practice per i costi di BigQuery CDC
Oltre alle best practice generali per i costi di BigQuery, utilizza le seguenti tecniche per ottimizzare i costi delle operazioni CDC di BigQuery:
- Se non necessario, evita di configurare l'opzione
max_stalenessdi una tabella con un valore molto basso. Il valoremax_stalenesspuò aumentare la frequenza di job di applicazione in background e di unione in fase di runtime, che sono più costosi e più lenti rispetto ai job di query. Per indicazioni dettagliate, consulta Valoremax_stalenessdella tabella consigliata. - Valuta la possibilità di configurare una
prenotazione BigQuery da utilizzare con le tabelle CDC.
In caso contrario, i job di applicazione in background e di unione in fase di runtime utilizzano i prezzi on demand,
che possono essere più costosi a causa della maggiore elaborazione dei dati. Per maggiori dettagli, scopri di più sulle prenotazioni BigQuery e segui le indicazioni su come dimensionare e monitorare una prenotazione
BACKGROUNDper l'utilizzo con BigQuery CDC.
Passaggi successivi
- Scopri come implementare il flusso predefinito dell'API Storage Write.
- Scopri di più sulle best practice per l'API Storage Write.
- Scopri come utilizzare Datastream per replicare i database transazionali in BigQuery con BigQuery CDC.