パーティション分割テーブルの概要
パーティション分割テーブルはパーティションと呼ばれるセグメントに分割されるため、データの管理や照会が簡単になります。大きなテーブルを小さなパーティションに分割することで、クエリのパフォーマンスを高めたり、クエリによって読み取られるバイト数を減らしてコストを抑えたりすることができます。テーブルを分割するには、テーブルの分割に使用するパーティション列を指定します。
クエリで、パーティショニング列の値に対する限定フィルタを使用すると、BigQuery では、フィルタに一致するパーティションがスキャンされ、残りのパーティションはスキップされます。このプロセスは「プルーニング」と呼ばれます。
パーティション分割テーブルでは、データが物理ブロックに保存され、各ブロックに 1 つのデータ パーティションが保持されます。各パーティション分割テーブルには、そのテーブルを変更するすべてのオペレーションについて、並べ替えプロパティに関するさまざまなメタデータが保持されます。メタデータを使用すると、BigQuery でクエリを実行する前にクエリの費用をより正確に見積もることができます。
パーティショニングを使用するタイミング
次のシナリオでは、テーブルのパーティショニングを検討してください。
- テーブルの一部のみをスキャンすることで、クエリのパフォーマンスを改善したい。
- テーブル オペレーションが標準のテーブル割り当てを超えており、テーブル オペレーションのスコープを特定のパーティション列の値に制限することで、パーティション分割テーブルの割り当てを増やすことができる。
- クエリを実行する前にクエリ費用を把握したい。BigQuery では、パーティション分割テーブルにクエリを実行する前にクエリ費用の見積もりが提供されます。パーティション分割テーブルをプルーニングすることでクエリ費用を見積もり、続いてクエリ ドライランを発行してクエリ費用を見積もります。
- 次のいずれかのパーティション レベルの管理機能が必要な場合。
- パーティションの有効期限を設定して、指定した期間の経過後にパーティション全体を自動的に削除する。
- テーブル内の他のパーティションに影響を与えることなく、読み込みジョブを使用して特定のパーティションにデータを書き込む。
- テーブル全体をスキャンせずに、特定のパーティションを削除する。
次のような状況では、テーブルをパーティショニングするのではなく、テーブルをクラスタリングすることを検討してください。
- パーティショニングで許容されるよりも細かい粒度が必要。
- 通常、クエリによって、複数列に対するフィルタまたは集計が使用される。
- 1 つの列または列グループの値のカーディナリティが大きい。
- クエリを実行する前に、厳密な費用見積もりを行う必要がない。
- パーティショニングにより、パーティションごとに少量のデータ(約 10 GB 未満)が生成される。小さなパーティションを多数作成すると、テーブルのメタデータが増加し、テーブルをクエリする際のメタデータ アクセス時間に影響する可能性があります。
- パーティショニングにより、パーティション分割テーブルの上限を超える多数のパーティションが生成される。
- DML オペレーションを行うと、テーブル内のほとんどのパーティションが頻繁に(たとえば数分ごとに)変更されます。
このような場合、テーブルのクラスタリングにより、ユーザー定義の並べ替えプロパティに基づいて特定の列のデータをクラスタリングすることで、クエリを高速化できます。
クラスタリングとテーブル パーティショニングを組み合わせて、より細かい並べ替えを行うこともできます。このアプローチの詳細については、クラスタ化テーブルとパーティション分割テーブルを組み合わせるをご覧ください。
パーティショニングのタイプ
このセクションでは、テーブルをパーティショニングするさまざまな方法について説明します。
整数範囲パーティショニング
特定の INTEGER 列の値の範囲に基づいてテーブルを分割できます。整数範囲パーティション分割テーブルを作成する方法は次のとおりです。
- パーティショニング列。
- 範囲パーティショニングの開始値(この値を含む)。
- 範囲パーティショニングの終了値(この値を含まない)。
- パーティション内の各範囲の間隔。
たとえば、次の仕様で整数範囲パーティションを作成するとします。
| 引数 | 値 |
|---|---|
| 列名 | customer_id |
| 開始 | 0 |
| 終了 | 100 |
| 間隔 | 10 |
テーブルは、customer_id 列において、10 の間隔の範囲にパーティション分割されます。0 から 9 の値は 1 つのパーティションに入り、10 から 19 は次のパーティションに入ります。この処理が 99 まで続きます。この範囲外の値は、__UNPARTITIONED__ という名前のパーティションに入ります。customer_id が NULL である行は、__NULL__ という名前のパーティションに入ります。
整数範囲パーティション分割テーブルについては、整数範囲パーティション分割テーブルを作成するをご覧ください。
時間単位列パーティショニング
テーブルのパーティションは、テーブルの DATE、TIMESTAMP または DATETIME 列で分割できます。テーブルにデータを書き込むと、BigQuery は列の値に基づいて、自動的に正しいパーティションにデータを入力します。
TIMESTAMP 列と DATETIME 列では、パーティションを時間単位、日単位、月単位、年単位のいずれで作成できます。DATE 列の場合、パーティションは日単位、月単位、年単位で作成できます。パーティションの境界は UTC 時間に基づきます。
たとえば、月別パーティショニングで DATETIME 列にテーブルを分割するとします。テーブルに次の値を挿入すると、行は次のパーティションに書き込まれます。
| 列の値 | パーティション(月単位) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
さらに、次の 2 つの特殊パーティションが作成されます。
__NULL__: パーティショニングする列でNULL値を持つ行が含まれます。__UNPARTITIONED__: パーティショニングする列の値が 1960-01-01 より前、または 2159-12-31 より後の行を含みます。
時間単位の列パーティション分割テーブルについては、時間単位の列パーティション分割テーブルを作成するをご覧ください。
取り込み時間パーティショニング
取り込み時間でパーティション分割されたテーブルを作成すると、BigQuery はデータを取り込む時間に基づいて、パーティションに自動的に行を割り当てます。パーティションは、時間単位、日単位、月単位、年単位から選択できます。パーティションの境界は UTC 時間に基づきます。
細かい時間粒度を使用しており、データがテーブルあたりのパーティション数の上限に達する可能性がある場合は、より粗い粒度を使用してください。たとえば、日単位ではなく月単位でパーティション分割して、パーティション数を減らすことができます。また、パーティション列をクラスタ化して、パフォーマンスをさらに向上させることもできます。
取り込み時間パーティション分割テーブルには、_PARTITIONTIME という名前の疑似列があります。この列の値は、パーティションの境界(時間単位や日単位など)で切り捨てられた各行の取り込み時間です。たとえば、時間単位のパーティショニングで取り込み時間パーティション分割テーブルを作成し、次の時点でデータを送信するとします。
| 取り込み時間 | _PARTITIONTIME |
パーティション(時間単位) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
この例のテーブルは時間単位のパーティショニングを使用しているため、_PARTITIONTIME の値は 1 時間の境界で切り捨てられます。BigQuery はこの値を使用して、データの正しいパーティションを決定します。
特定のパーティションにデータを書き込むこともできます。たとえば、過去のデータの読み込みやタイムゾーンの調整ができます。0001-01-01 から 9999-12-31 までの有効な日付を使用できます。ただし、DML ステートメントは、1970-01-01 より前、および 2159-12-31 より後の日付を参照できません。詳細については、特定のパーティションにデータを書き込むをご覧ください。
_PARTITIONTIME の代わりに _PARTITIONDATE を使用することもできます。_PARTITIONDATE 擬似列には、_PARTITIONTIME 擬似列の値に対応する UTC の日付が格納されます。
日別、時間別、月別、年別のいずれかのパーティショニングを選択する
時間単位列または取り込み時間でテーブルをパーティション分割する場合、日別、時間別、月別、年別のいずれかのパーティションを選択します。
日別のパーティショニングはデフォルトのパーティショニング タイプです。データが長期間にわたって分散している場合や、データが継続的に追加される場合は、日別パーティショニングが適しています。
大量のデータが短期間(通常は 6 か月未満のタイムスタンプ値)のデータ範囲にある場合は、時間別パーティショニングを選択します。時間別のパーティショニングを選択する場合、パーティションの数がパーティションの制限を超えないようにしてください。
テーブルの 1 日あたりのデータ量は比較的少ないものの、長い期間にわたる場合は、月別または年別パーティショニングを選択します。このオプションは、ワークフローで長い期間(例: 500 日超)にわたる行の更新または追加を頻繁に行う必要がある場合にも推奨されます。これらのシナリオでは、パーティショニング列で月別または年別のパーティショニングをクラスタリングと併用すると、最適なパフォーマンスを実現します。詳細については、このドキュメントのクラスタ化テーブルとパーティション分割テーブルを組み合わせるをご覧ください。
クラスタ化テーブルとパーティション分割テーブルを組み合わせる
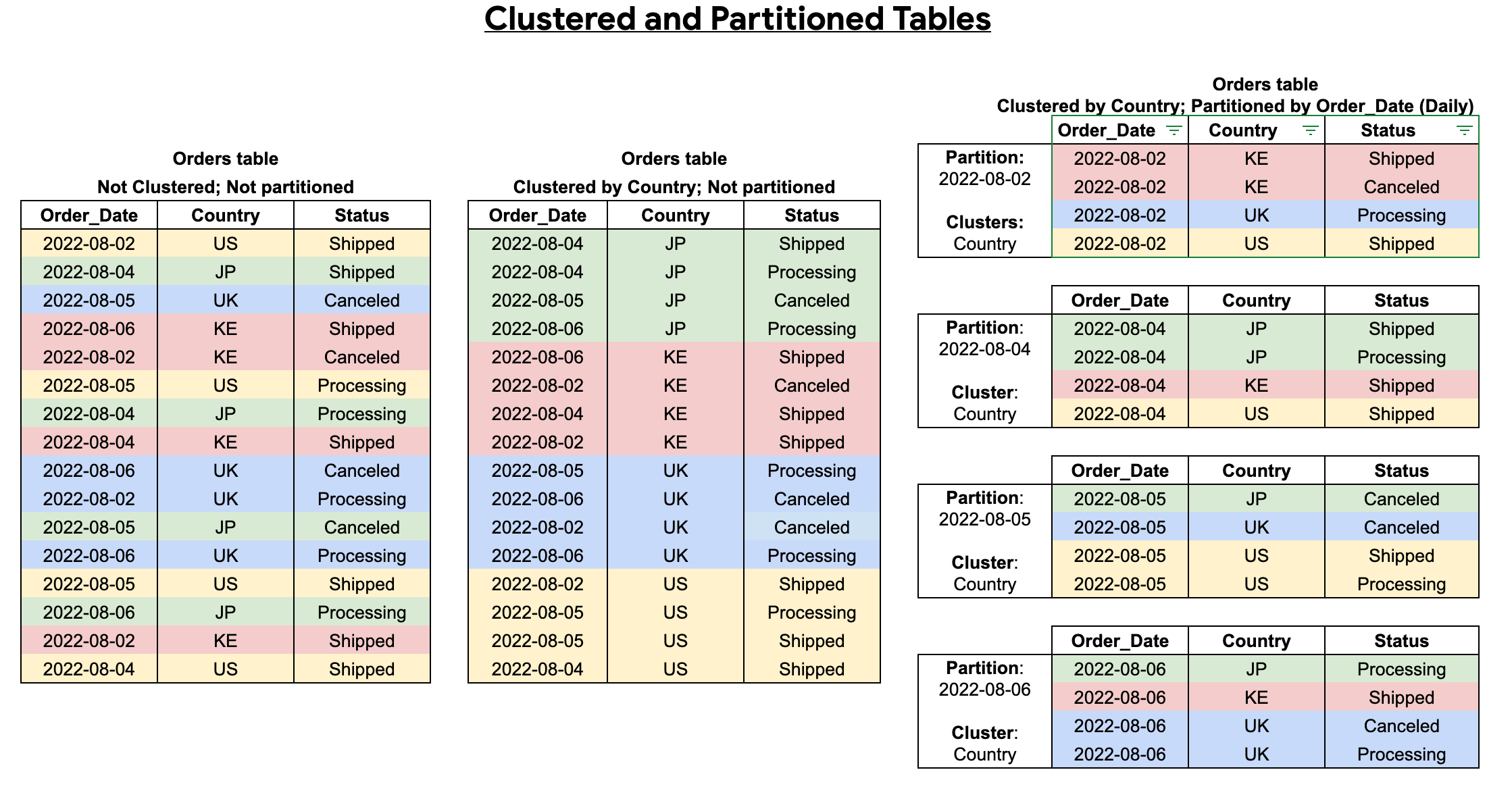
テーブルのパーティショニングとテーブルのクラスタリングを組み合わせると、クエリをさらに最適化するためのきめ細かい並べ替えを行うことができます。
クラスタ化テーブルには、ユーザー定義の並べ替えプロパティに基づいてデータを並べ替えるクラスタ化列が含まれます。クラスタ化列内のデータは、テーブルのサイズに基づいて適応的にサイズが変わるストレージ ブロックに振り分けられます。クラスタ列でフィルタリングするクエリを実行すると、BigQuery はテーブル全体やテーブル パーティションではなく、クラスタ列に基づいて関連するブロックのみをスキャンします。テーブルのパーティショニングとクラスタリングの両方を使用する方法では、最初にテーブルのデータをパーティションに分割し、クラスタリング列で各パーティション内のデータをクラスタ化します。
クラスタ化およびパーティション分割されたテーブルを作成すると、次の図に示すように、より細かい並べ替えを行うことができます。
パーティショニングとシャーディング
テーブル シャーディングは、[PREFIX]_YYYYMMDD などの名前の接頭辞を使用して複数のテーブルにデータを格納する方法です。
パーティション分割テーブルのほうがパフォーマンスが向上するため、テーブルのシャーディングよりもパーティショニングをおすすめします。シャーディングされたテーブルでは、BigQuery は各テーブルのスキーマとメタデータのコピーを保持する必要があります。BigQuery では、クエリされた各テーブルの権限の検証も必要になる場合があります。この方法はさらに、クエリのオーバーヘッドを増やし、クエリのパフォーマンスを低下させます。
以前に日付別テーブルを作成している場合は、取り込み時間パーティション分割テーブルに変換できます。詳細については、日付別テーブルを取り込み時間パーティション分割テーブルへ変換するをご覧ください。
パーティション デコレータ
パーティション デコレータを使用すると、テーブル内のパーティションを参照できます。たとえば、特定のパーティションにデータを書き込むことができます。
パーティション デコレータの形式は table_name$partition_id で、partition_id セグメントの形式はパーティショニングのタイプによって異なります。
| パーティショニング タイプ | 形式 | 例 |
|---|---|---|
| 毎時 | yyyymmddhh |
my_table$2021071205 |
| 毎日 | yyyymmdd |
my_table$20210712 |
| 月別 | yyyymm |
my_table$202107 |
| 毎年 | yyyy |
my_table$2021 |
| 整数の範囲 | range_start |
my_table$40 |
パーティション内のデータを参照する
指定したパーティションのデータを参照するには、bq head コマンドでパーティション デコレータを使用します。
たとえば、次のコマンドは、2018-02-24 パーティションの my_dataset.my_table にある最初の 10 行のすべてのフィールドを一覧表示します。
bq head --max_rows=10 'my_dataset.my_table$20180224'
テーブルデータをエクスポートする
パーティション分割テーブルからすべてのデータをエクスポートする処理は、分割されていないテーブルからデータをエクスポートする処理と同じプロセスです。詳細については、テーブルデータのエクスポートをご覧ください。
個々のパーティションからデータをエクスポートするには、bq extract コマンドを使用して、テーブル名にパーティション デコレータを追加します。たとえば、my_table$20160201 のようにします。テーブル名にパーティション名を追加して、__NULL__ と __UNPARTITIONED__ のパーティションからデータをエクスポートすることもできます。例: my_table$__NULL__、my_table$__UNPARTITIONED__
制限事項
レガシー SQL を使用して、パーティション分割テーブルをクエリすることや、クエリ結果をパーティション分割テーブルに書き込むことはできません。
BigQuery は、複数の列によるパーティショニングをサポートしていません。テーブルのパーティショニングに使用できる列は 1 つだけです。
時間単位の列パーティション分割テーブルには次の制限があります。
- パーティショニング列は、スカラー
DATE列、TIMESTAMP列、DATETIME列のいずれかであることが必要です。列のモードはREQUIREDまたはNULLABLEにできますが、REPEATED(配列ベース)にすることはできません。 - パーティショニング列はトップレベル フィールドであることが必要です。パーティショニングする列として
RECORD(STRUCT)のリーフ フィールドは使用できません。
時間単位の列パーティション分割テーブルについては、時間単位の列パーティション分割テーブルを作成するをご覧ください。
整数範囲パーティション分割テーブルには次の制限があります。
- 分割する列は
INTEGER列である必要があります。列のモードはREQUIREDまたはNULLABLEにできますが、REPEATED(配列ベース)にすることはできません。 - パーティショニング列はトップレベル フィールドであることが必要です。パーティショニングする列として
RECORD(STRUCT)のリーフ フィールドは使用できません。
整数範囲パーティション分割テーブルについては、整数範囲パーティション分割テーブルを作成するをご覧ください。
割り当てと上限
パーティション分割テーブルには BigQuery で上限が定義されています。
割り当てと上限は、パーティション分割テーブルに対して実行できる次のようなさまざまな種類のジョブにも適用されます。
- データの読み込み(読み込みジョブ)
- データのエクスポート(エクスポート ジョブ)
- データのクエリ(クエリジョブ)
- テーブルのコピー(コピージョブ)
すべての割り当てと制限の詳細については、割り当てと制限をご覧ください。
テーブルの料金
BigQuery でパーティション分割テーブルを作成して使用する場合、パーティションに格納されているデータの量とデータに対して実行するクエリに基づいて料金が発生します。
パーティションへのデータの読み込み、パーティションのコピー、パーティションからのデータのエクスポートなど、パーティション分割テーブルのオペレーションの多くは無料です。これらのオペレーションは無料ですが、BigQuery の割り当てと制限が適用されます。すべての無料オペレーションについては、料金ページの無料のオペレーションをご覧ください。
BigQuery で費用を抑えるためのベスト プラクティスについては、BigQuery で費用を抑えるをご覧ください。
テーブルのセキュリティ
パーティション分割テーブルのアクセス制御は、標準テーブルのアクセス制御と同じです。さらに詳しい内容については、テーブル アクセス制御の概要をご覧ください。
次のステップ
- パーティション分割テーブルの作成方法については、パーティション分割テーブルの作成をご覧ください。
- パーティション分割テーブルの管理方法と更新方法については、パーティション分割テーブルの管理をご覧ください。
- パーティション分割テーブルをクエリする方法については、パーティション分割テーブルのクエリをご覧ください。