BigLake-Tabellen für Apache Iceberg in BigQuery
BigLake-Tabellen für Apache Iceberg in BigQuery (im Folgenden BigLake Iceberg-Tabellen in BigQuery) bilden die Grundlage für die Erstellung von Lakehouses im offenen Format auf Google Cloud. BigLake-Iceberg-Tabellen in BigQuery bieten dieselbe vollständig verwaltete Umgebung wie Standard-BigQuery-Tabellen, speichern Daten jedoch in kundeneigenen Speicher-Buckets. BigLake-Iceberg-Tabellen in BigQuery unterstützen das offene Iceberg-Tabellenformat für eine bessere Interoperabilität mit Open-Source- und Drittanbieter-Compute-Engines für eine einzelne Kopie von Daten.
BigLake-Tabellen für Apache Iceberg in BigQuery unterscheiden sich von externen Apache Iceberg-Tabellen. BigLake-Tabellen für Apache Iceberg in BigQuery sind vollständig verwaltete Tabellen, die direkt in BigQuery geändert werden können. Externe Apache Iceberg-Tabellen werden vom Kunden verwaltet und bieten schreibgeschützten Zugriff über BigQuery.
BigLake Iceberg-Tabellen in BigQuery unterstützen die folgenden Funktionen:
- Tabellenänderungen mit der Datenbearbeitungssprache (Data Manipulation Language, DML) von GoogleSQL.
- Einheitliches Batch-Streaming und Streaming mit hoher Durchsatzleistung mit der Storage Write API über BigLake-Connectors wie Spark, Dataflow und andere Engines.
- Iceberg V2-Snapshot-Export und automatisches Aktualisieren bei jeder Tabellenänderung für den direkten Abfragezugriff mit Open-Source- und Drittanbieter-Abfrage-Engines.
- Schemaentwicklung: Sie können Spalten hinzufügen, entfernen und umbenennen, um sie an Ihre Anforderungen anzupassen. Mit dieser Funktion können Sie auch den Datentyp einer vorhandenen Spalte und den Spaltenmodus ändern. Weitere Informationen finden Sie unter Regeln für die Typkonvertierung.
- Automatische Speicheroptimierung, einschließlich adaptiver Dateigrößenanpassung, automatischem Clustering, automatischer Speicherbereinigung und Metadatenoptimierung.
- Zeitreisen für den Zugriff auf Verlaufsdaten in BigQuery.
- Sicherheit auf Spaltenebene und Datenmaskierung.
- Transaktionen mit mehreren Anweisungen (in der Vorschau).
Architektur
Mit BigLake Iceberg-Tabellen in BigQuery können Sie die Ressourcenverwaltung von BigQuery auch für Tabellen in Ihren eigenen Cloud-Buckets nutzen. Sie können BigQuery und Open-Source-Compute-Engines für diese Tabellen verwenden, ohne die Daten aus den von Ihnen verwalteten Buckets zu verschieben. Sie müssen einen Cloud Storage-Bucket konfigurieren, bevor Sie BigLake Iceberg-Tabellen in BigQuery verwenden können.
BigLake Iceberg-Tabellen in BigQuery verwenden den BigLake Metastore als einheitlichen Runtime-Metastore für alle Iceberg-Daten. BigLake Metastore bietet eine zentrale Quelle für die Verwaltung von Metadaten aus mehreren Engines und ermöglicht die Interoperabilität von Engines.
Das folgende Diagramm zeigt die Architektur verwalteter Tabellen im Überblick:
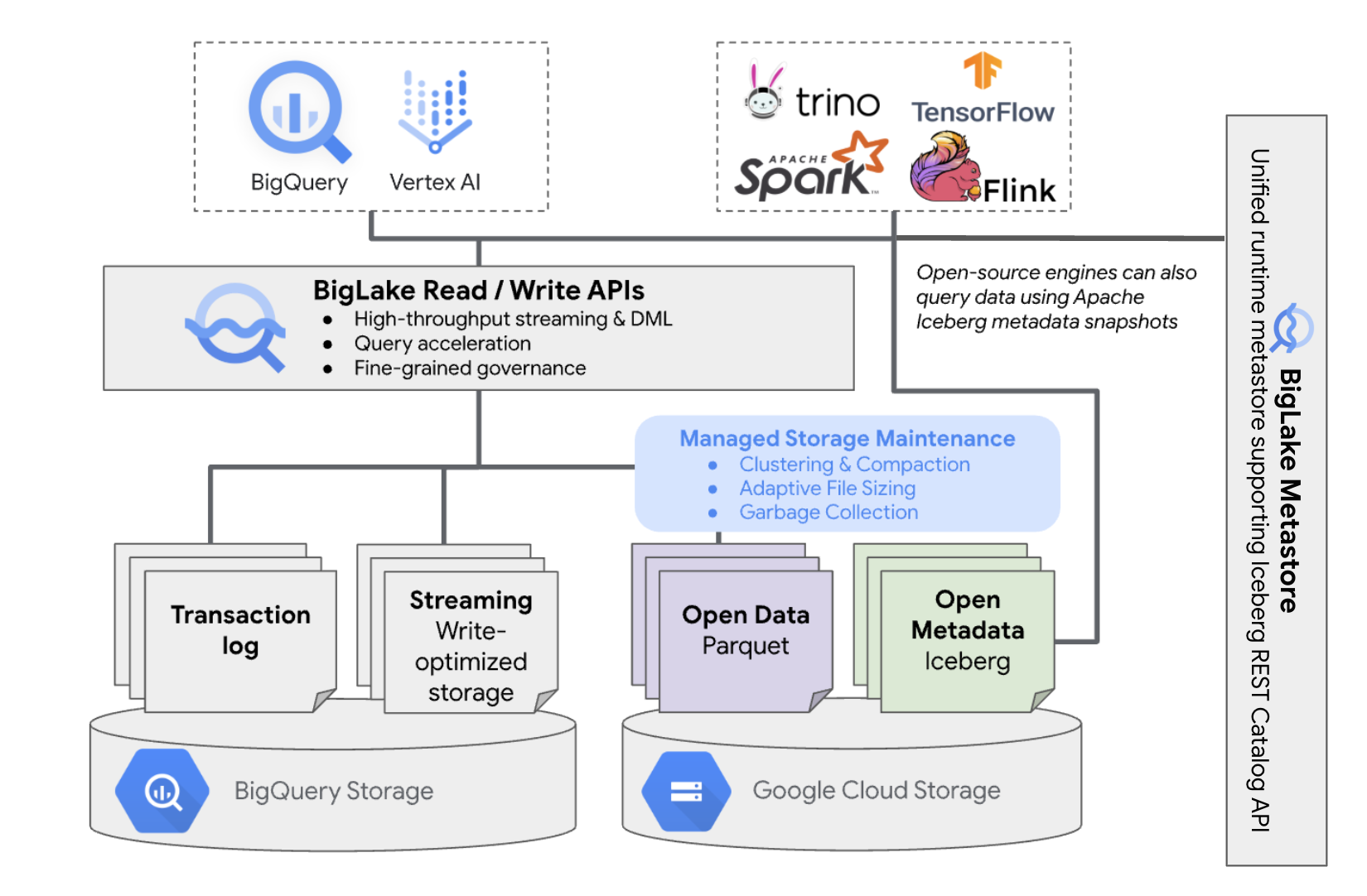
Die Tabellenverwaltung hat folgende Auswirkungen auf Ihren Bucket:
- BigQuery erstellt neue Datendateien im Bucket als Reaktion auf Schreibanfragen und Hintergrundoptimierungen des Speichers, z. B. DML-Anweisungen und Streaming.
- Wenn Sie eine verwaltete Tabelle in BigQuery löschen, werden die zugehörigen Datendateien in Cloud Storage nach Ablauf des Zeitreisezeitraums von BigQuery gelöscht.
Das Erstellen einer BigLake Iceberg-Tabelle in BigQuery ähnelt dem Erstellen von BigQuery-Tabellen. Da Daten in offenen Formaten in Cloud Storage gespeichert werden, müssen Sie Folgendes tun:
- Geben Sie die Cloud-Ressourcenverbindung mit
WITH CONNECTIONan, um die Anmeldedaten für die Verbindung von BigLake mit Cloud Storage zu konfigurieren. - Geben Sie das Dateiformat des Datenspeichers als
PARQUETmit der Anweisungfile_format = PARQUETan. - Geben Sie das Format der Open-Source-Metadatentabelle als
ICEBERGmit dertable_format = ICEBERG-Anweisung an.
Best Practices
Wenn Sie Dateien direkt im Bucket außerhalb von BigQuery ändern oder hinzufügen, kann dies zu Datenverlust oder nicht behebaren Fehlern führen. In der folgenden Tabelle werden mögliche Szenarien beschrieben:
| Vorgang | Auswirkungen | vermeiden |
|---|---|---|
| Fügen Sie dem Bucket außerhalb von BigQuery neue Dateien hinzu. | Datenverlust:Neue Dateien oder Objekte, die außerhalb von BigQuery hinzugefügt werden, werden von BigQuery nicht erfasst. Nicht verfolgte Dateien werden durch Hintergrundprozesse zur automatischen Speicherbereinigung gelöscht. | Daten ausschließlich über BigQuery hinzufügen So kann BigQuery die Dateien verfolgen und verhindern, dass sie als Garbage gesammelt werden. Um versehentliche Ergänzungen und Datenverluste zu vermeiden, empfehlen wir außerdem, die Schreibberechtigungen für externe Tools für Buckets mit BigLake Iceberg-Tabellen in BigQuery einzuschränken. |
| Erstellen Sie eine neue BigLake Iceberg-Tabelle in BigQuery in einem nicht leeren Präfix. | Datenverlust:Vorhandene Daten werden nicht von BigQuery erfasst. Diese Dateien gelten daher als nicht erfasst und werden durch Hintergrundprozesse zur automatischen Speicherbereinigung gelöscht. | Erstellen Sie neue BigLake Iceberg-Tabellen in BigQuery nur in leeren Präfixen. |
| BigLake Iceberg-Tabelle in BigQuery-Datendateien ändern oder ersetzen | Datenverlust:Bei externer Änderung oder Ersetzung besteht die Tabelle den Konsistenzcheck nicht und wird unlesbar. Abfragen für die Tabelle schlagen fehl. Es gibt keine Selfservice-Möglichkeit, um die Situation zu beheben. Wenden Sie sich an den Support, um Unterstützung bei der Datenwiederherstellung zu erhalten. |
Daten ausschließlich über BigQuery ändern So kann BigQuery die Dateien verfolgen und verhindern, dass sie als Garbage gesammelt werden. Um versehentliche Ergänzungen und Datenverluste zu vermeiden, empfehlen wir außerdem, die Schreibberechtigungen für externe Tools für Buckets mit BigLake Iceberg-Tabellen in BigQuery einzuschränken. |
| Erstellen Sie zwei BigLake Iceberg-Tabellen in BigQuery mit denselben oder sich überschneidenden URIs. | Datenverlust:BigQuery überbrückt keine identischen URI-Instanzen von BigLake-Iceberg-Tabellen in BigQuery. Bei der automatischen Speicherbereinigung im Hintergrund für jede Tabelle werden die Dateien der gegenüberliegenden Tabelle als nicht verfolgt betrachtet und gelöscht, was zu Datenverlust führt. | Verwenden Sie eindeutige URIs für jede BigLake Iceberg-Tabelle in BigQuery. |
Best Practices für die Konfiguration von Cloud Storage-Bucket
Die Konfiguration Ihres Cloud Storage-Bucket und seiner Verbindung mit BigLake hat direkten Einfluss auf die Leistung, Kosten, Datenintegrität, Sicherheit und Governance Ihrer BigLake Iceberg-Tabellen in BigQuery. Im Folgenden finden Sie Best Practices für diese Konfiguration:
Wählen Sie einen Namen aus, der deutlich darauf hinweist, dass der Bucket nur für BigLake Iceberg-Tabellen in BigQuery vorgesehen ist.
Wählen Sie Cloud Storage-Buckets mit einzelner Region aus, die sich in derselben Region wie Ihr BigQuery-Dataset befinden. Diese Koordination verbessert die Leistung und senkt die Kosten, da keine Gebühren für die Datenübertragung anfallen.
Standardmäßig werden Daten in Cloud Storage in der Speicherklasse „Standard“ gespeichert, die eine ausreichende Leistung bietet. Zur Optimierung der Datenspeicherkosten können Sie Autoclass aktivieren, um die Umstellung der Speicherklasse automatisch zu verwalten. Autoclass beginnt mit der Speicherklasse „Standard“ und verschiebt Objekte, auf die nicht zugegriffen wird, in immer niedrigere Klassen, um die Speicherkosten zu senken. Wenn das Objekt wieder gelesen wird, wird es zurück in die Standard-Klasse verschoben.
Aktivieren Sie den einheitlichen Zugriff auf Bucket-Ebene und die Verhinderung des öffentlichen Zugriffs.
Prüfen Sie, ob die erforderlichen Rollen den richtigen Nutzern und Dienstkonten zugewiesen sind.
Um ein versehentliches Löschen oder Beschädigen von Iceberg-Daten in Ihrem Cloud Storage-Bucket zu verhindern, sollten Sie die Schreib- und Löschberechtigungen für die meisten Nutzer in Ihrer Organisation einschränken. Dazu können Sie eine Bucket-Berechtigungsrichtlinie mit Bedingungen festlegen, die
PUT- undDELETE-Anfragen für alle Nutzer mit Ausnahme der von Ihnen angegebenen Nutzer ablehnen.Wenden Sie von Google verwaltete oder vom Kunden verwaltete Verschlüsselungsschlüssel an, um sensible Daten zusätzlich zu schützen.
Aktivieren Sie das Audit-Logging für betriebliche Transparenz, Fehlerbehebung und Überwachung des Datenzugriffs.
Behalten Sie die Standardrichtlinie für vorläufiges Löschen (7‑tägige Aufbewahrung) bei, um sich vor versehentlichem Löschen zu schützen. Wenn Sie jedoch feststellen, dass Iceberg-Daten gelöscht wurden, wenden Sie sich an den Support, anstatt Objekte manuell wiederherzustellen. Objekte, die außerhalb von BigQuery hinzugefügt oder geändert werden, werden nicht von BigQuery-Metadaten erfasst.
Die adaptive Dateigrößenanpassung, das automatische Clustering und die automatische Speicherbereinigung sind automatisch aktiviert und tragen zur Optimierung der Dateileistung und der Kosten bei.
Vermeiden Sie die folgenden Cloud Storage-Funktionen, da sie für BigLake-Iceberg-Tabellen in BigQuery nicht unterstützt werden:
- Hierarchische Namespaces
- Dual-Regionen und Multiregionen
- Objekt-ACLs (Access Control Lists)
- Vom Kunden bereitgestellte Verschlüsselungsschlüssel
- Objektversionsverwaltung
- Objektsperre
- Bucket-Sperre
- Wiederherstellen von vorläufig gelöschten Objekten mit der BigQuery API oder dem bq-Befehlszeilentool
Sie können diese Best Practices umsetzen, indem Sie Ihren Bucket mit dem folgenden Befehl erstellen:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Ersetzen Sie Folgendes:
BUCKET_NAME: der Name des neuen BucketsPROJECT_ID: die Projekt-IDLOCATION: der Speicherort für Ihren neuen Bucket
BigLake Iceberg-Tabellen in BigQuery-Workflows
In den folgenden Abschnitten wird beschrieben, wie Sie verwaltete Tabellen erstellen, laden, verwalten und abfragen.
Hinweise
Bevor Sie BigLake Iceberg-Tabellen in BigQuery erstellen und verwenden, müssen Sie eine Cloud-Ressourcenverbindung zu einem Speicher-Bucket einrichten. Ihre Verbindung benötigt Schreibberechtigungen für den Speicher-Bucket, wie im folgenden Abschnitt Erforderliche Rollen beschrieben. Weitere Informationen zu den erforderlichen Rollen und Berechtigungen für Verbindungen finden Sie unter Verbindungen verwalten.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie benötigen, damit BigQuery Tabellen in Ihrem Projekt verwalten kann:
-
So erstellen Sie BigLake-Iceberg-Tabellen in BigQuery:
-
BigQuery-Dateninhaber (
roles/bigquery.dataOwner) für Ihr Projekt -
BigQuery-Verbindungsadministrator (
roles/bigquery.connectionAdmin) für Ihr Projekt
-
BigQuery-Dateninhaber (
-
So fragen Sie BigLake Iceberg-Tabellen in BigQuery ab:
-
BigQuery-Datenbetrachter (
roles/bigquery.dataViewer) für Ihr Projekt -
BigQuery-Nutzer (
roles/bigquery.user) für Ihr Projekt
-
BigQuery-Datenbetrachter (
-
Weisen Sie dem Dienstkonto der Verbindung die folgenden Rollen zu, damit es Daten in Cloud Storage lesen und schreiben kann:
-
Storage Object User (
roles/storage.objectUser) für den Bucket -
Leser von Legacy-Storage-Buckets (
roles/storage.legacyBucketReader) für den Bucket
-
Storage Object User (
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierten Rollen enthalten die Berechtigungen, die erforderlich sind, damit BigQuery Tabellen in Ihrem Projekt verwalten kann. Erweitern Sie den Abschnitt Erforderliche Berechtigungen, um die erforderlichen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind erforderlich, damit BigQuery Tabellen in Ihrem Projekt verwalten kann:
-
bigquery.connections.delegatefür Ihr Projekt -
bigquery.jobs.createfür Ihr Projekt -
bigquery.readsessions.createfür Ihr Projekt -
bigquery.tables.createfür Ihr Projekt -
bigquery.tables.getfür Ihr Projekt -
bigquery.tables.getDatafür Ihr Projekt -
storage.buckets.getfür Ihren Bucket -
storage.objects.createfür Ihren Bucket -
storage.objects.deletefür Ihren Bucket -
storage.objects.getfür Ihren Bucket -
storage.objects.listfür Ihren Bucket
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
BigLake Iceberg-Tabellen in BigQuery erstellen
Wählen Sie eine der folgenden Methoden aus, um eine BigLake Iceberg-Tabelle in BigQuery zu erstellen:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Ersetzen Sie Folgendes:
- PROJECT_ID: Das Projekt, das das Dataset enthält. Wenn nicht definiert, wird vom Befehl das Standardprojekt angenommen.
- DATASET_ID: ein vorhandenes Dataset.
- TABLE_NAME: Der Name der Tabelle, die Sie erstellen.
- DATA_TYPE: der Datentyp der Informationen, die in der Spalte enthalten sind.
- CLUSTER_COLUMN_LIST (optional): Eine durch Kommas getrennte Liste mit bis zu vier Spalten. Sie müssen Spalten der obersten Ebene sein, die nicht wiederholt werden.
CONNECTION_NAME: der Name der Verbindung. Beispiel:
myproject.us.myconnectionWenn Sie eine Standardverbindung verwenden möchten, geben Sie
DEFAULTanstelle des Verbindungs-Strings mit PROJECT_ID.REGION.CONNECTION_ID an.STORAGE_URI: ein vollständig qualifizierter Cloud Storage-URI. Beispiel:
gs://mybucket/table
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Ersetzen Sie Folgendes:
- PROJECT_ID: Das Projekt, das das Dataset enthält. Wenn nicht definiert, wird vom Befehl das Standardprojekt angenommen.
- CONNECTION_NAME: der Name der Verbindung. Beispiel:
myproject.us.myconnection - STORAGE_URI: ein vollständig qualifizierter Cloud Storage-URI.
Beispiel:
gs://mybucket/table - COLUMN_NAME: Der Name der Spalte.
- DATA_TYPE: Der Datentyp der Informationen in der Spalte.
- CLUSTER_COLUMN_LIST (optional): Eine durch Kommas getrennte Liste mit bis zu vier Spalten. Sie müssen Spalten der obersten Ebene sein, die nicht wiederholt werden.
- DATASET_ID: Die ID eines vorhandenen Datasets.
- MANAGED_TABLE_NAME: Der Name der Tabelle, die Sie erstellen.
API
Rufen Sie die Methode tables.insert mit einer definierten Tabellenressource auf, wie im folgenden Beispiel:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Ersetzen Sie Folgendes:
- TABLE_NAME: Der Name der Tabelle, die Sie erstellen.
- CONNECTION_NAME: der Name der Verbindung. Beispiel:
myproject.us.myconnection - STORAGE_URI: ein vollständig qualifizierter Cloud Storage-URI.
Platzhalter werden ebenfalls unterstützt. Beispiel:
gs://mybucket/table. - COLUMN_NAME: Der Name der Spalte.
- DATA_TYPE: Der Datentyp der Informationen in der Spalte.
Daten in BigLake Iceberg-Tabellen in BigQuery importieren
In den folgenden Abschnitten wird beschrieben, wie Sie Daten aus verschiedenen Tabellenformaten in BigLake Iceberg-Tabellen in BigQuery importieren.
Standard-Ladevorgang für Daten aus Flatfiles
Für BigLake Iceberg-Tabellen in BigQuery werden BigQuery-Ladejobs verwendet, um externe Dateien in BigLake Iceberg-Tabellen in BigQuery zu laden. Wenn Sie bereits eine BigLake Iceberg-Tabelle in BigQuery haben, folgen Sie dem bq loadLeitfaden für die Befehlszeile oder dem LOAD SQL-Leitfaden, um externe Daten zu laden. Nach dem Laden der Daten werden neue Parquet-Dateien in den Ordner STORAGE_URI/data geschrieben.
Wenn die vorherigen Anleitungen ohne eine vorhandene BigLake Iceberg-Tabelle in BigQuery verwendet werden, wird stattdessen eine BigQuery-Tabelle erstellt.
Hier finden Sie toolspezifische Beispiele für Batch-Ladevorgänge in verwaltete Tabellen:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Ersetzen Sie Folgendes:
- MANAGED_TABLE_NAME: Der Name einer vorhandenen BigLake-Iceberg-Tabelle in BigQuery.
- STORAGE_URI: ein vollständig qualifizierter Cloud Storage-URI oder eine durch Kommas getrennte Liste von URIs.
Platzhalter werden ebenfalls unterstützt. Beispiel:
gs://mybucket/table. - FILE_FORMAT: das Format der Quelltabelle. Informationen zu unterstützten Formaten finden Sie in der
format-Zeile vonload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Ersetzen Sie Folgendes:
- FILE_FORMAT: das Format der Quelltabelle. Informationen zu unterstützten Formaten finden Sie in der
format-Zeile vonload_option_list. - MANAGED_TABLE_NAME: Der Name einer vorhandenen BigLake-Iceberg-Tabelle in BigQuery.
- STORAGE_URI: ein vollständig qualifizierter Cloud Storage-URI oder eine durch Kommas getrennte Liste von URIs.
Platzhalter werden ebenfalls unterstützt. Beispiel:
gs://mybucket/table.
Standard-Ladevorgang aus Hive-partitionierten Dateien
Sie können Hive-partitionierte Dateien mit standardmäßigen BigQuery-Ladejobs in BigLake Iceberg-Tabellen in BigQuery laden. Weitere Informationen finden Sie unter Extern partitionierte Daten laden.
Streamingdaten aus Pub/Sub laden
Sie können Streamingdaten in BigLake-Iceberg-Tabellen in BigQuery laden, indem Sie ein Pub/Sub-BigQuery-Abo verwenden.
Daten aus BigLake Iceberg-Tabellen in BigQuery exportieren
In den folgenden Abschnitten wird beschrieben, wie Sie Daten aus BigLake Iceberg-Tabellen in BigQuery in verschiedene Tabellenformate exportieren.
Daten in flache Formate exportieren
Wenn Sie eine BigLake-Iceberg-Tabelle in BigQuery in ein flaches Format exportieren möchten, verwenden Sie die Anweisung EXPORT DATA und wählen Sie ein Zielformat aus. Weitere Informationen finden Sie unter Daten exportieren.
BigLake Iceberg-Tabelle in BigQuery-Metadaten-Snapshots erstellen
So erstellen Sie eine BigLake Iceberg-Tabelle in einem BigQuery-Metadaten-Snapshot:
Exportieren Sie die Metadaten mit der SQL-Anweisung
EXPORT TABLE METADATAin das Iceberg V2-Format.Optional: Aktualisierung von Iceberg-Metadaten-Snapshots planen. Wenn Sie einen Iceberg-Metadatensnapshot in einem bestimmten Zeitintervall aktualisieren möchten, verwenden Sie eine geplante Abfrage.
Optional: Aktivieren Sie die automatische Aktualisierung von Metadaten für Ihr Projekt, um den Metadaten-Snapshot Ihrer Iceberg-Tabelle bei jeder Tabellenänderung automatisch zu aktualisieren. Wenn Sie die automatische Aktualisierung von Metadaten aktivieren möchten, wenden Sie sich an bigquery-tables-for-apache-iceberg-help@google.com. Bei jedem Aktualisierungsvorgang fallen
EXPORT METADATA-Kosten an.
Im folgenden Beispiel wird eine geplante Abfrage mit dem Namen My Scheduled Snapshot Refresh Query mithilfe der DDL-Anweisung EXPORT TABLE METADATA FROM mydataset.test erstellt. Die DDL-Anweisung wird alle 24 Stunden ausgeführt.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
BigLake Iceberg-Tabelle im BigQuery-Metadatensnapshot ansehen
Nachdem Sie den BigQuery-Metadaten-Snapshot der BigLake Iceberg-Tabelle aktualisiert haben, finden Sie den Snapshot im Cloud Storage-URI, in dem die BigLake Iceberg-Tabelle in BigQuery ursprünglich erstellt wurde. Der Ordner /data enthält die Parquet-Dateidaten-Shards und der Ordner /metadata den BigLake Iceberg-Tabellen-Metadaten-Snapshot in BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
mydataset und table_name sind Platzhalter für Ihr tatsächliches Dataset und Ihre tatsächliche Tabelle.
BigLake Iceberg-Tabellen in BigQuery mit Apache Spark lesen
Im folgenden Beispiel wird Ihre Umgebung für die Verwendung von Spark SQL mit Apache Iceberg eingerichtet. Anschließend wird eine Abfrage ausgeführt, um Daten aus einer angegebenen BigLake Iceberg-Tabelle in BigQuery abzurufen.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Ersetzen Sie Folgendes:
- ICEBERG_VERSION_NUMBER: die aktuelle Version der Apache Spark Iceberg-Laufzeit. Laden Sie die neueste Version von Spark Releases herunter.
- CATALOG_NAME: Der Katalog, der auf Ihre BigLake Iceberg-Tabelle in BigQuery verweist.
- BUCKET_PATH: Der Pfad zum Bucket mit den Tabellendateien. Beispiel:
gs://mybucket/. - FOLDER_NAME: der Ordner, der die Tabellendateien enthält.
Beispiel:
myfolder.
BigLake Iceberg-Tabellen in BigQuery ändern
Wenn Sie eine BigLake-Iceberg-Tabelle in BigQuery ändern möchten, folgen Sie der Anleitung unter Tabellenschemas ändern.
Transaktionen mit mehreren Anweisungen verwenden
Wenn Sie Zugriff auf Transaktionen mit mehreren Anweisungen für BigLake Iceberg-Tabellen in BigQuery erhalten möchten, füllen Sie das Anmeldeformular aus.
Preise
Die Preise für BigLake Iceberg-Tabellen in BigQuery setzen sich aus Speicher, Speicheroptimierung sowie Abfragen und Jobs zusammen.
Speicher
In BigLake Iceberg-Tabellen in BigQuery werden alle Daten in Cloud Storage gespeichert. Ihnen werden alle gespeicherten Daten in Rechnung gestellt, einschließlich der Daten aus dem Tabellenverlauf. Möglicherweise fallen auch Gebühren für die Cloud Storage-Datenverarbeitung und Übertragungsgebühren an. Für Vorgänge, die über BigQuery oder die BigQuery Storage API verarbeitet werden, fallen möglicherweise keine Gebühren für bestimmte Cloud Storage-Vorgänge an. Es fallen keine BigQuery-spezifischen Speichergebühren an. Weitere Informationen finden Sie unter Cloud Storage – Preise.
Speicheroptimierung
BigLake Iceberg-Tabellen in BigQuery führen eine automatische Tabellenverwaltung durch, einschließlich Verdichtung, Clustering, Garbage Collection und Generierung/Aktualisierung von BigQuery-Metadaten, um die Abfrageleistung zu optimieren und die Speicherkosten zu senken. Die Nutzung von Rechenressourcen für die BigLake-Tabellenverwaltung wird im Zeitverlauf in Data Compute Units (DCUs) in sekundengenauen Schritten abgerechnet. Weitere Informationen finden Sie unter BigLake Iceberg-Tabellen in BigQuery – Preise.
Datenexportvorgänge, die während des Streamings über die BigQuery Storage Write API stattfinden, sind in der Preisgestaltung der Storage Write API enthalten und werden nicht als Hintergrundwartung in Rechnung gestellt. Weitere Informationen finden Sie unter Datenaufnahme – Preise.
Die Speicheroptimierung und die Nutzung von EXPORT TABLE METADATA sind in der Ansicht INFORMATION_SCHEMA.JOBS sichtbar.
Abfragen und Jobs
Ähnlich wie bei BigQuery-Tabellen werden Ihnen Abfragen und gelesene Byte (pro TiB) in Rechnung gestellt, wenn Sie die On-Demand-Preise von BigQuery verwenden, oder der Slot-Verbrauch (pro Slotstunde), wenn Sie die Preise für BigQuery-Kapazitäts-Computing verwenden.
Die BigQuery-Preise gelten auch für die BigQuery Storage Read API und die BigQuery Storage Write API.
Für Lade- und Exportvorgänge (z. B. EXPORT METADATA) werden Pay-as-you-go-Slots der Enterprise-Version verwendet.
Bei BigQuery-Tabellen werden diese Vorgänge nicht in Rechnung gestellt. Wenn PIPELINE-Reservierungen mit Enterprise- oder Enterprise Plus-Slots verfügbar sind, werden diese Reservierungsslots bevorzugt für Lade- und Exportvorgänge verwendet.
Beschränkungen
Für BigLake-Iceberg-Tabellen in BigQuery gelten die folgenden Einschränkungen:
- BigLake-Iceberg-Tabellen in BigQuery unterstützen keine Umbenennungsvorgänge oder
ALTER TABLE RENAME TO-Anweisungen. - BigLake-Iceberg-Tabellen in BigQuery unterstützen keine Tabellenkopien oder
CREATE TABLE COPY-Anweisungen. - BigLake Iceberg-Tabellen in BigQuery unterstützen keine Tabellenklone oder
CREATE TABLE CLONE-Anweisungen. - BigLake Iceberg-Tabellen in BigQuery unterstützen keine Tabellen-Snapshots oder
CREATE SNAPSHOT TABLE-Anweisungen. - Die folgenden Tabellenschemas werden für BigLake Iceberg-Tabellen in BigQuery nicht unterstützt:
- Leeres Schema
- Schema mit den Datentypen
BIGNUMERIC,INTERVAL,JSON,RANGEoderGEOGRAPHY. - Schema mit Feldkollationen.
- Schema mit Standardwertausdrücken.
- Die folgenden Fälle der Schemaentwicklung werden für BigLake-Iceberg-Tabellen in BigQuery nicht unterstützt:
NUMERIC-zu-FLOAT-TypkoersionenINT-zu-FLOAT-Typkoersionen- Neue verschachtelte Felder in vorhandene
RECORD-Spalten einfügen
- Für BigLake Iceberg-Tabellen in BigQuery wird eine Speichergröße von 0 Byte angezeigt, wenn sie über die Konsole oder APIs abgefragt werden.
- Materialisierte Ansichten werden für BigLake-Iceberg-Tabellen in BigQuery nicht unterstützt.
- BigLake Iceberg-Tabellen in BigQuery unterstützen keine autorisierten Ansichten, aber die Zugriffssteuerung auf Spaltenebene wird unterstützt.
- BigLake Iceberg-Tabellen in BigQuery unterstützen keine Change Data Capture (CDC)-Aktualisierungen.
- BigLake Iceberg-Tabellen in BigQuery unterstützen keine verwaltete Notfallwiederherstellung.
- BigLake-Iceberg-Tabellen in BigQuery unterstützen keine Partitionierung. Erwägen Sie stattdessen Clustering.
- BigLake Iceberg-Tabellen in BigQuery unterstützen keine Sicherheit auf Zeilenebene.
- BigLake-Iceberg-Tabellen in BigQuery unterstützen keine Fail-Safe-Zeiträume.
- Für BigLake Iceberg-Tabellen in BigQuery werden keine Extraktionsjobs unterstützt.
- Die Ansicht
INFORMATION_SCHEMA.TABLE_STORAGEenthält keine BigLake Iceberg-Tabellen in BigQuery. - BigLake Iceberg-Tabellen in BigQuery werden nicht als Ziele für Abfrageergebnisse unterstützt. Stattdessen können Sie die
CREATE TABLE-Anweisung mit dem ArgumentAS query_statementverwenden, um eine Tabelle als Ziel für das Abfrageergebnis zu erstellen. CREATE OR REPLACEunterstützt nicht das Ersetzen von Standardtabellen durch BigLake Iceberg-Tabellen in BigQuery oder von BigLake Iceberg-Tabellen in BigQuery durch Standardtabellen.- Beim Batch-Laden und mit
LOAD DATA-Anweisungen können Daten nur an vorhandene BigLake Iceberg-Tabellen in BigQuery angehängt werden. - Batch-Ladevorgänge und
LOAD DATA-Anweisungen unterstützen keine Schemaaktualisierungen. TRUNCATE TABLEunterstützt keine BigLake-Iceberg-Tabellen in BigQuery. Dafür gibt allerdings es zwei Alternativen:CREATE OR REPLACE TABLEmit denselben Optionen zum Erstellen von Tabellen.DELETE FROMtableWHEREtrue
- Die Tabellenwertfunktion
APPENDS(Table-valued function, TVF) unterstützt keine BigLake Iceberg-Tabellen in BigQuery. - Iceberg-Metadaten enthalten möglicherweise keine Daten, die in den letzten 90 Minuten mit der Storage Write API in BigQuery gestreamt wurden.
- Der seitenweise Zugriff auf Datensätze mit
tabledata.listwird für BigLake-Iceberg-Tabellen in BigQuery nicht unterstützt. - Verknüpfte Datasets werden für BigLake Iceberg-Tabellen in BigQuery nicht unterstützt.
- Für jede BigLake-Iceberg-Tabelle in BigQuery wird nur eine mutierende DML-Anweisung (
UPDATE,DELETEundMERGE) gleichzeitig ausgeführt. Zusätzliche mutierende DML-Anweisungen werden in die Warteschlange gestellt.