En este documento, se proporciona información general sobre la privacidad diferencial para BigQuery. Para obtener información sobre la sintaxis, consulta la cláusula de privacidad diferencial. Para obtener una lista de funciones que puedes usar con esta sintaxis, consulta funciones de agregación privada diferencial.
¿Qué es la privacidad diferencial?
La privacidad diferencial es un estándar para los cálculos de datos que limitan la información personal que revela un resultado. La privacidad diferencial suele utilizarse para compartir datos y permitir inferencias sobre grupos de personas, a la vez que evita que alguien conozca información sobre un individuo.
La privacidad diferencial es útil:
- Cuando existe un riesgo de reidentificación.
- Para cuantificar la compensación entre riesgo y utilidad analítica.
Para comprender mejor la privacidad diferencial, veamos un ejemplo simple.
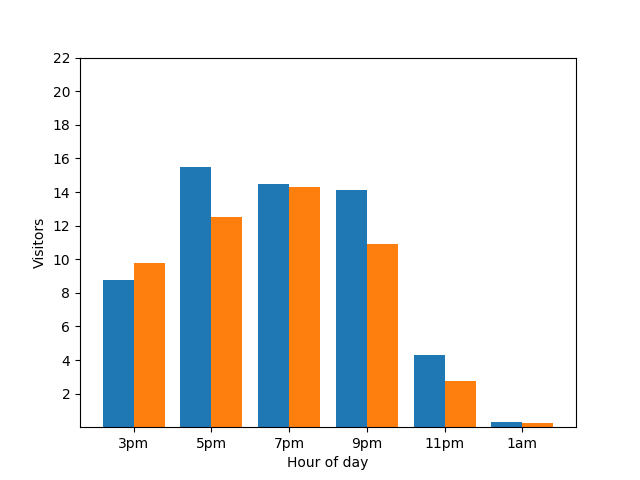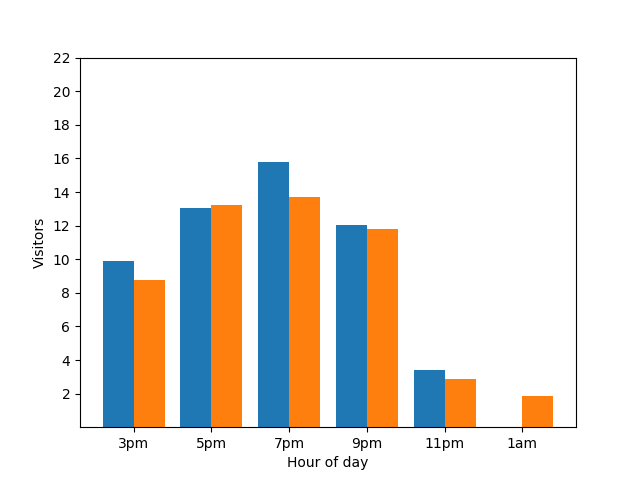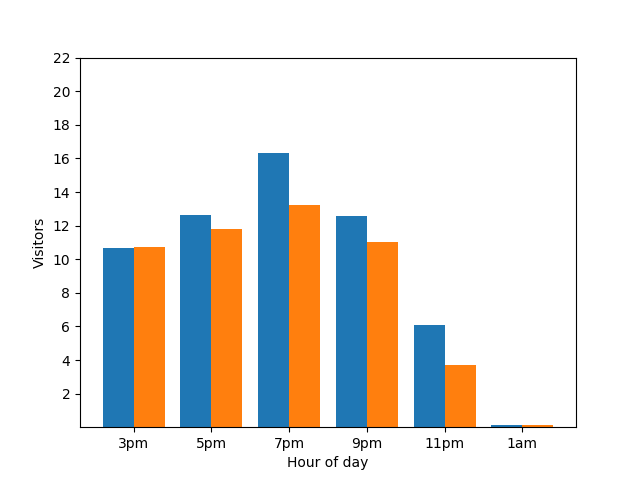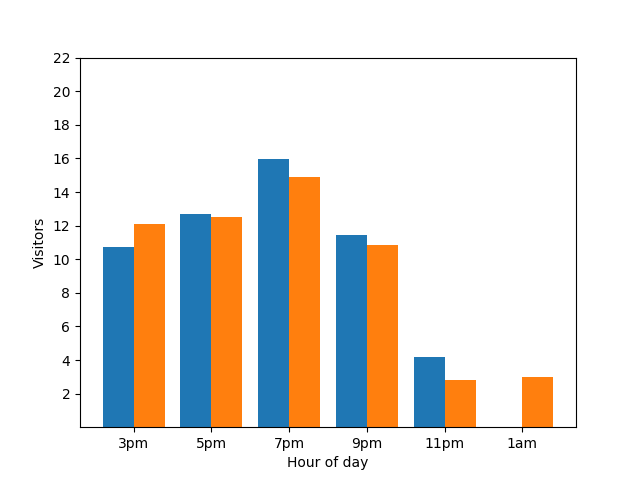
El gráfico de barras muestra el nivel de actividad de un restaurante pequeño durante una noche particular. Muchos clientes llegan a las 7 p.m. y el restaurante está completamente vacío a la 1 a.m.:
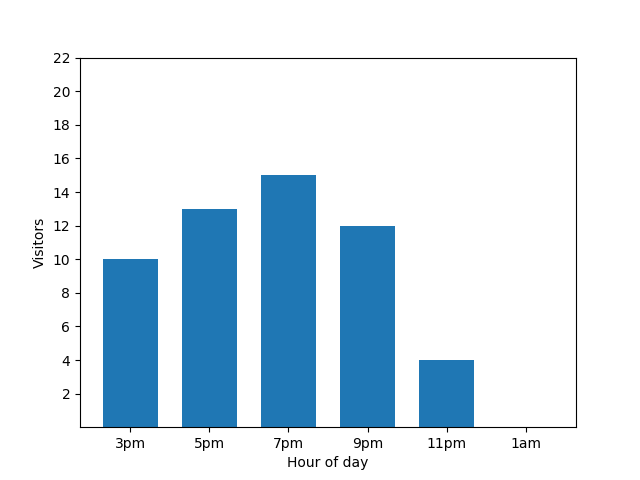
Este gráfico parece útil, pero hay una desventaja. Cuando llega un nuevo cliente, el gráfico de barras lo revela de inmediato. En el siguiente gráfico, está claro que hay un invitado nuevo y que este llegó aproximadamente a la 1 a.m.:
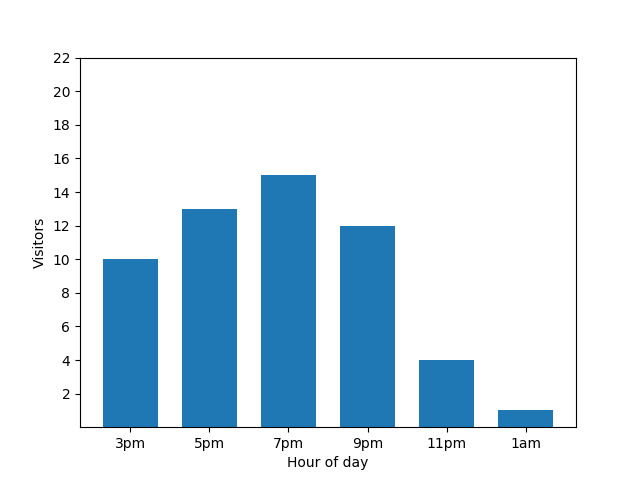
Mostrar este detalle no es bueno desde la perspectiva de la privacidad, ya que las estadísticas anónimas no deberían revelar las contribuciones individuales. Si colocas esos dos gráficos en paralelo, se hace más evidente: el gráfico de barras naranja tiene un invitado adicional que llegó alrededor de la 1 a.m.:
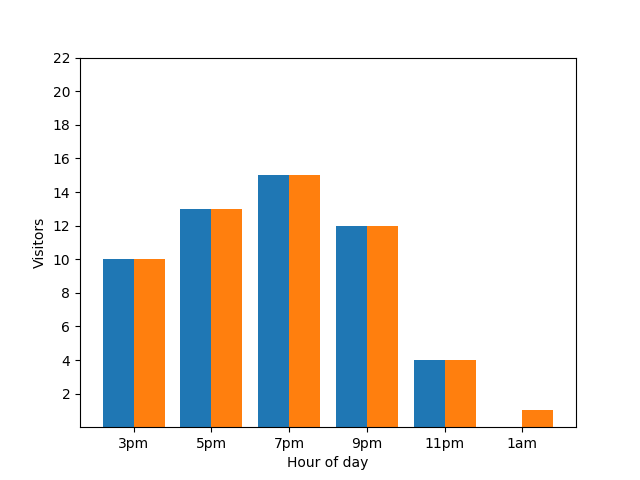
Una vez más, eso no es lo mejor. Para evitar este problema de privacidad, puedes agregar ruido aleatorio a los gráficos de barras con la privacidad diferencial. En el siguiente gráfico de comparación, los resultados son anónimos y ya no revelan contribuciones individuales.
Cómo funciona la privacidad diferencial en las consultas
El objetivo de la privacidad diferencial es mitigar el riesgo de divulgación: el riesgo de que alguien pueda obtener información sobre una entidad en un conjunto de datos. La privacidad diferencial equilibra la necesidad de proteger la privacidad con la necesidad de utilidad analítica estadística. A medida que aumenta la privacidad, la utilidad analítica estadística disminuye y viceversa.
Con GoogleSQL para BigQuery, puedes transformar los resultados de una consulta con agregaciones privadas diferenciales. Cuando se ejecuta la consulta, realiza lo siguiente:
- Calcula las agregaciones por entidad para cada grupo si los grupos se especifican con una cláusula
GROUP BY. Limita la cantidad de grupos a los que puede contribuir cada entidad, según el parámetro de privacidad diferencialmax_groups_contributed. - Restringe cada contribución agregada por entidad para que se encuentre dentro de los límites de restricción. Si no se especifican los límites de restricción, se calculan de manera implícita y privada diferencial.
- Agrega las contribuciones restringidas por entidad para cada grupo.
- Agrega ruido al valor agregado final para cada grupo. La escala del ruido aleatorio es una función de todos los límites y parámetros de privacidad restringidos.
- Calcula un recuento de entidades ruidosas para cada grupo y elimina los grupos con pocas entidades. Un recuento de entidades ruidosas ayuda a eliminar un conjunto no determinista de grupos.
El resultado final es un conjunto de datos en el que cada grupo tiene resultados agregados ruidosos y se borraron grupos pequeños.
Para obtener más información sobre qué es la privacidad diferencial y sus casos de uso, consulta los siguientes artículos:
- Una introducción amigable y no técnica a la privacidad diferencial
- SQL privado diferencial con una contribución de usuario limitada
- Privacidad diferencial en Wikipedia
Genera una consulta privada diferencial válida
Para que la consulta privada diferencial sea válida, se deben cumplir las siguientes reglas:
- Se define una columna de unidades de privacidad.
- La lista
SELECTcontiene una cláusula privada diferencial. - Solo las funciones de agregación privada diferencial se encuentran en la lista
SELECTcon la cláusula privada diferencial.
Define una columna de unidades de privacidad
Una unidad de privacidad es la entidad en un conjunto de datos que se protege con la privacidad diferencial. Una entidad puede ser una persona, una empresa, una ubicación o cualquier columna que elijas.
Una consulta privada diferencial debe incluir una sola columna de unidades de privacidad. Una columna de unidades de privacidad es un identificador único para una unidad de privacidad y puede existir dentro de varios grupos. Debido a que se admiten varios grupos, el tipo de datos para la columna de unidades de privacidad debe ser agrupable.
Puedes definir una columna de unidades de privacidad en la cláusula OPTIONS de una cláusula de privacidad diferencial con el identificador único privacy_unit_column.
En los siguientes ejemplos, se agrega una columna de unidades de privacidad a una cláusula de privacidad diferencial. id representa una columna que se origina en una tabla llamada students.
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
Quita el ruido de una consulta privada diferencial
En la referencia "Sintaxis de consulta", consulta Quita ruido.
Agrega ruido a una consulta privada diferencial
En la referencia "Sintaxis de consulta", consulta Agrega ruido.
Limita los grupos en los que puede existir un ID de unidad de privacidad
En la referencia "Sintaxis de consulta", consulta Limita los grupos en los que puede existir un ID de unidad de privacidad.
Limitaciones
En esta sección, se describen las limitaciones de la privacidad diferencial.
Implicaciones de rendimiento de la privacidad diferencial
Las consultas privadas diferenciales se ejecutan más lento que las consultas estándar porque se realiza la agregación por entidad y se aplica la limitación max_groups_contributed. Limitar los límites de contribución puede ayudar a mejorar el rendimiento de tus consultas privadas diferenciales.
Los perfiles de rendimiento de las siguientes consultas no son similares:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
La diferencia de rendimiento se debe a que se aplica un nivel de detalle mayor adicional de la agrupación para las consultas privadas diferenciales, ya que también se debe realizar la agregación por entidad.
Los perfiles de rendimiento de las siguientes consultas deberían ser similares, aunque la consulta privada diferencial es un poco más lenta:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
La consulta privada diferencial funciona más lento porque tiene una gran cantidad de valores distintos para la columna de unidades de privacidad.
Limitaciones implícitas de límites para conjuntos de datos pequeños
El límite implícito funciona mejor cuando se procesa mediante conjuntos de datos grandes. El límite implícito puede fallar con conjuntos de datos que contienen una cantidad baja de unidades de privacidad y no muestran resultados. Además, el límite implícito en un conjunto de datos con una cantidad baja de unidades de privacidad puede restringir una gran parte de los valores no atípicos, lo que da como resultado agregaciones y resultados que no se consideran adecuados y que se alteran más con una restricción que con el ruido agregado. Los conjuntos de datos que tienen una cantidad baja de unidades de privacidad o que están poco particionados deben usar una restricción explícita en lugar de una restricción implícita.
Vulnerabilidades de privacidad
Cualquier algoritmo de privacidad diferencial, incluido este, genera el riesgo de una filtración de datos privados cuando un analista actúa de mala fe, en especial cuando se calculan estadísticas básicas como sumas, debido a limitaciones aritméticas.
Limitaciones de las garantías de privacidad
Si bien la privacidad diferencial de BigQuery aplica el algoritmo de privacidad diferencial, no garantiza la propiedad de privacidad del conjunto de datos resultante.
Errores de entorno de ejecución
Un analista que actúa de mala fe con la capacidad de escribir consultas o controlar los datos de entrada podría activar un error de entorno de ejecución en los datos privados.
Ruido de punto flotante
Se deben tener en cuenta las vulnerabilidades relacionadas con los ataques de redondeo, redondeo repetido y reordenamiento antes de usar la privacidad diferencial. Estas vulnerabilidades son particularmente preocupantes cuando un atacante puede controlar parte del contenido de un conjunto de datos o el orden del contenido en un conjunto de datos.
Las adiciones de ruido privadas diferenciales en tipos de datos de punto flotante están sujetas a las vulnerabilidades descritas en Subestimación generalizada de la sensibilidad en bibliotecas privadas diferenciales y cómo solucionarla. Las adiciones de ruido en los tipos de datos de números enteros no están sujetas a las vulnerabilidades que se describen en el documento.
Riesgos de ataque de tiempo
Un analista que actúa de mala fe podría ejecutar una consulta lo suficientemente compleja para hacer una inferencia sobre los datos de entrada según la duración de ejecución de una consulta.
Clasificación errónea
Crear una consulta privada diferencial supone que tus datos están en una estructura conocida y comprensible. Si aplicas la privacidad diferencial en los identificadores incorrectos, como uno que representa un ID de transacción en lugar del ID de una persona, puedes exponer datos sensibles.
Si necesitas ayuda para comprender tus datos, considera usar servicios y herramientas como los siguientes:
Precios
No se aplican costos adicionales por usar la privacidad diferencial, pero se aplican precios de BigQuery estándar para el análisis.