Descripción general de la IA generativa
En este documento, se describen las funciones de inteligencia artificial (IA) generativas que admite BigQuery ML. Estos atributos te permiten realizar tareas de IA en BigQuery ML con modelos de Vertex AI previamente entrenados y modelos integrados de BigQuery ML.
Entre las tareas admitidas, se incluyen las siguientes:
- Generar texto
- Genera datos estructurados
- Genera valores de un tipo específico por fila
- Genera embeddings
- Previsión de series temporales
Accede a un modelo de Vertex AI para realizar una de estas funciones mediante la creación de un modelo remoto en BigQuery ML que representa el extremo del modelo de Vertex AI. Una vez que hayas creado un modelo remoto sobre el modelo de Vertex AI que deseas usar, debes acceder a las capacidades de ese modelo mediante la ejecución de una función de BigQuery ML en el modelo remoto.
Este enfoque te permite usar las capacidades de estos modelos de Vertex AI en consultas de SQL para analizar datos de BigQuery.
Flujo de trabajo
Puedes usar modelos remotos en modelos de Vertex AI y modelos remotos en servicios de Cloud AI junto con BigQuery. funciones de AA para realizar tareas de IA generativa y análisis de datos complejas.
En el siguiente diagrama, se muestran algunos flujos de trabajo típicos en los que puedes usar estas capacidades juntas:
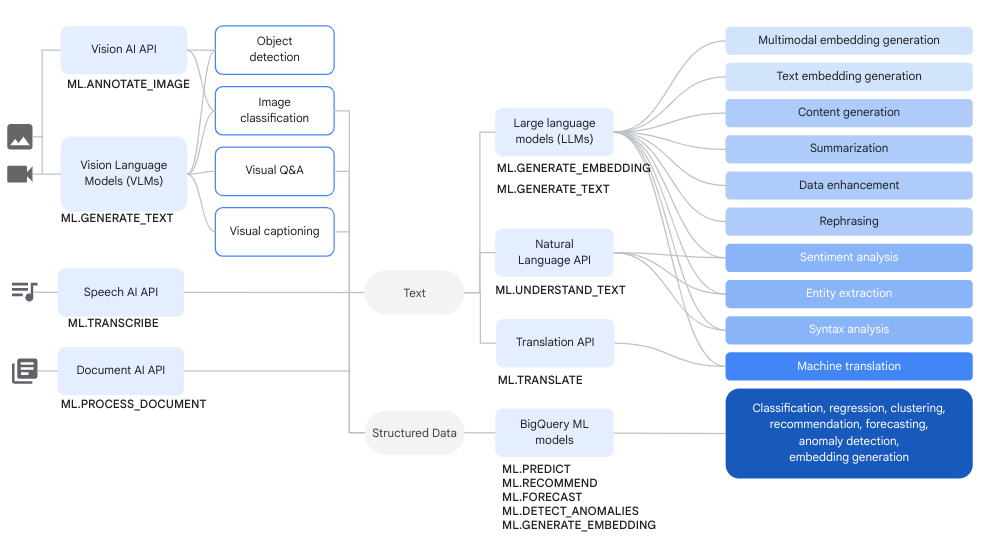
Generar texto
La generación de texto es una forma de IA generativa en la que se genera texto en función de una instrucción o del análisis de datos. Puedes generar texto con datos de texto y multimodales.
Estos son algunos casos de uso comunes de la generación de texto:
- Generar contenido creativo
- Se está generando el código.
- Generar respuestas de chat o correo electrónico
- Lluvia de ideas, como sugerir vías para futuros productos o servicios
- Personalización del contenido, como sugerencias de productos
- Clasificar los datos aplicando una o más etiquetas al contenido para ordenarlo en categorías
- Identificar las opiniones clave que se expresan en el contenido
- Resumir las ideas o impresiones clave que transmite el contenido
- Identificar una o más entidades destacadas en datos visuales o de texto
- Traducir el contenido de datos de texto o audio a otro idioma
- Generar texto que coincida con el contenido verbal de los datos de audio
- Generar subtítulos o realizar preguntas y respuestas sobre datos visuales
El enriquecimiento de datos es un paso siguiente común después de la generación de texto, en el que se enriquecen las estadísticas del análisis inicial combinándolas con datos adicionales. Por ejemplo, puedes analizar imágenes de muebles para el hogar y generar texto para una columna design_type, de modo que el SKU de los muebles tenga una descripción asociada, como mid-century modern o farmhouse.
Modelos compatibles
Para realizar tareas de IA generativa, puedes usar modelos remotos en BigQuery ML para hacer referencia a modelos implementados o alojados en Vertex AI. Puedes crear los siguientes tipos de modelos remotos:
- Modelos remotos sobre cualquiera de los modelos de Gemini disponibles de forma general o de vista previa
Modelos remotos sobre los siguientes modelos de socios:
Cómo usar modelos de generación de texto
Después de crear un modelo remoto, puedes usar la función ML.GENERATE_TEXT para interactuar con ese modelo:
En el caso de los modelos remotos basados en modelos de Gemini, puedes hacer lo siguiente:
Usa la función
ML.GENERATE_TEXTpara generar texto a partir de una instrucción que especifiques en una consulta o que extraigas de una columna en una tabla estándar. Cuando especificas la instrucción en una consulta, puedes hacer referencia a los siguientes tipos de columnas de tabla en la instrucción:- Columnas
STRINGpara proporcionar datos de texto - Columnas
STRUCTque usan el formatoObjectRefpara proporcionar datos no estructurados Debes usar la funciónOBJ.GET_ACCESS_URLdentro de la instrucción para convertir los valoresObjectRefen valoresObjectRefRuntime.
- Columnas
Usa la función
ML.GENERATE_TEXTpara analizar contenido de texto, imagen, audio, video o PDF a partir de una tabla de objetos con una instrucción que proporcionas como argumento de una función.
Para todos los demás tipos de modelos remotos, puedes usar la función
ML.GENERATE_TEXTcon una instrucción que proporciones en una consulta o desde una columna en una tabla estándar.
Usa los siguientes temas para probar la generación de texto en BigQuery ML:
- Genera texto con un modelo de Gemini y la función
ML.GENERATE_TEXT. - Genera texto con un modelo de Gemma y la función
ML.GENERATE_TEXT. - Analiza imágenes con un modelo de Gemini.
- Para generar texto, usa la función
ML.GENERATE_TEXTcon tus datos. - Ajusta un modelo con tus datos.
Atributos de fundamentación y seguridad
Puedes usar fundamentación y atributos de seguridad cuando uses modelos de Gemini con la función ML.GENERATE_TEXT, siempre y cuando uses una tabla estándar como entrada. Grounding lets the
Gemini model use additional information from the internet to
generate more specific and factual responses. Safety attributes let the
Gemini model filter the responses it returns based on the
attributes you specify.
Ajuste supervisado
Cuando creas un modelo remoto que hace referencia a cualquiera de los siguientes modelos, puedes optar por configurar el ajuste supervisado al mismo tiempo:
gemini-2.5-progemini-2.5-flash-litegemini-2.0-flash-001gemini-2.0-flash-lite-001gemini-1.5-pro-002gemini-1.5-flash-002
Todas las inferencias se producen en Vertex AI. Los resultados se almacenan en BigQuery.
Capacidad de procesamiento aprovisionada de Vertex AI
En el caso de los modelos de Gemini compatibles, puedes usar Vertex AI Provisioned Throughput con la función ML.GENERATE_TEXT para proporcionar una capacidad de procesamiento alta y coherente para las solicitudes. Para obtener más información, consulta Cómo usar la capacidad de procesamiento aprovisionada de Vertex AI.
Genera datos estructurados
La generación de datos estructurados es muy similar a la generación de texto, excepto que también puedes especificar un esquema SQL para dar formato a la respuesta del modelo.
Para generar datos estructurados, crea un modelo remoto sobre cualquiera de los modelos de Gemini que estén disponibles de forma general o en versión preliminar. Luego, puedes usar la función AI.GENERATE_TABLE para interactuar con ese modelo. Para intentar crear datos estructurados, consulta Genera datos estructurados con la función AI.GENERATE_TABLE.
Puedes especificar atributos de seguridad cuando usas los modelos de Gemini con la función AI.GENERATE_TABLE para filtrar las respuestas del modelo.
Genera valores de un tipo específico por fila
Puedes usar funciones de IA generativa escalar con modelos de Gemini para analizar datos en tablas estándar de BigQuery. Los datos incluyen datos de texto y datos no estructurados de columnas que contienen valores ObjectRef.
Para cada fila de la tabla, estas funciones generan un resultado que contiene un tipo específico.
Están disponibles las siguientes funciones basadas en IA:
AI.GENERATE, que genera un valorSTRINGAI.GENERATE_BOOLAI.GENERATE_DOUBLEAI.GENERATE_INT
Cuando usas la función AI.GENERATE con modelos de Gemini compatibles, puedes usar Vertex AI Provisioned Throughput para proporcionar un alto rendimiento constante para las solicitudes. Para obtener más información, consulta Cómo usar la capacidad de procesamiento aprovisionada de Vertex AI.
Genera embeddings
Una incorporación es un vector numérico de alta dimensión que representa una entidad determinada, como un fragmento de texto o un archivo de audio. Generar incorporaciones te permite capturar la semántica de tus datos de una manera que facilita el razonamiento y la comparación de los datos.
Estos son algunos casos de uso comunes para la generación de incorporaciones:
- Usar la generación mejorada por recuperación (RAG) para aumentar las respuestas del modelo a las preguntas de los usuarios haciendo referencia a datos adicionales de una fuente confiable La RAG proporciona una mejor exactitud fáctica y coherencia en las respuestas, y también brinda acceso a datos más recientes que los datos de entrenamiento del modelo.
- Realizar búsquedas multimodales Por ejemplo, usar la entrada de texto para buscar imágenes.
- Realizar búsquedas semánticas para encontrar elementos similares para recomendaciones, sustituciones y deduplicación de registros
- Crear embeddings para usar con un modelo de k-means para el agrupamiento en clústeres
Modelos compatibles
Se admiten los siguientes modelos:
Para crear incorporaciones de texto, puedes usar los siguientes modelos de Vertex AI:
gemini-embedding-001(vista previa)text-embeddingtext-multilingual-embedding- Modelos abiertos compatibles (Vista previa)
Para crear incorporaciones multimodales, que pueden incorporar texto, imágenes y videos en el mismo espacio semántico, puedes usar el modelo
multimodalembeddingde Vertex AI.Para crear incorporaciones para datos estructurados de variables aleatorias independientes (IID) y estructuradas, puedes usar un modelo de análisis de componentes principales (PCA) de BigQuery ML o un modelo de codificador automático.
Si deseas crear incorporaciones para datos de usuarios o elementos, puedes usar un modelo de factorización de matrices de BigQuery ML.
Para una incorporación de texto más ligera y pequeña, prueba usar un modelo previamente entrenado de TensorFlow, como NNLM, SWIVEL o BERT.
Usa modelos de generación de embeddings
Después de crear el modelo, puedes usar la función ML.GENERATE_EMBEDDING para interactuar con él. Para todos los tipos de modelos compatibles, ML.GENERATE_EMBEDDING funciona con datos estructurados en tablas estándar. En el caso de los modelos de incorporación multimodales, ML.GENERATE_EMBEDDING también funciona con el contenido visual de las columnas de tablas estándar que contienen valores ObjectRef o de las tablas de objetos.
En los modelos remotos, toda la inferencia se produce en Vertex AI. Para otros tipos de modelos, toda la inferencia se produce en BigQuery. Los resultados se almacenan en BigQuery.
Usa los siguientes temas para probar la generación de texto en BigQuery ML:
- Genera embeddings de texto con la función
ML.GENERATE_EMBEDDING - Genera embeddings de imágenes con la función
ML.GENERATE_EMBEDDING - Genera embeddings de video con la función
ML.GENERATE_EMBEDDING - Genera y busca incorporaciones multimodales
- Realiza búsquedas semánticas y generación mejorada de recuperación
Previsión
La previsión es una técnica que te permite analizar datos históricos de series temporales para realizar una predicción fundamentada sobre tendencias futuras. Puedes usar el modelo de series temporales TimesFM (versión preliminar) integrado de BigQuery ML para realizar previsiones sin tener que crear tu propio modelo. El modelo integrado TimesFM funciona con la función AI.FORECAST para generar previsiones basadas en tus datos.
Ubicaciones
Las ubicaciones admitidas para los modelos de generación y de incorporación de texto varían según el tipo y la versión del modelo que uses. Para obtener más información, consulta Ubicaciones. A diferencia de otros modelos de IA generativa, la compatibilidad con la ubicación no se aplica al modelo de series temporales integrado TimesFM. El modelo TimesFM está disponible en todas las regiones compatibles con BigQuery.
Precios
Se te cobra por los recursos de procesamiento que usas para ejecutar consultas en los modelos. Los modelos remotos realizan llamadas a los modelos de Vertex AI, por lo que las consultas a los modelos remotos también generan cargos de Vertex AI.
Para obtener más información, consulta los precios de BigQuery ML.
¿Qué sigue?
- Para obtener una introducción a la IA y el AA en BigQuery, consulta Introducción a la IA y el AA en BigQuery.
- Para obtener más información sobre la realización de inferencias sobre los modelos de aprendizaje automático, consulta Descripción general de la inferencia de modelo.
- Para obtener más información sobre las instrucciones y funciones de SQL compatibles con los modelos de IA generativa, consulta Recorridos del usuario de extremo a extremo para modelos de IA generativa.