Wenn Sie beispielbasierte Erläuterungen verwenden möchten, müssen Sie diese so konfigurieren: Geben Sie eine explanationSpec an, wenn Sie die Ressource Model in die Modell-Registry importieren oder hochladen möchten.
Wenn Sie dann Online-Erläuterungen anfordern, können Sie einige dieser Konfigurationswerte überschreiben. Geben Sie dazu eine ExplanationSpecOverride in der Anfrage an. Sie können keine Batcherläuterungen anfordern; diese werden nicht unterstützt.
Auf dieser Seite wird beschrieben, wie Sie diese Optionen konfigurieren und aktualisieren.
Erläuterungen beim Importieren oder Hochladen des Modells konfigurieren
Folgende Voraussetzungen müssen erfüllt sein:
Ein Cloud Storage-Speicherort, der Ihre Modellartefakte enthält. Ihr Modell muss entweder ein DNN-Modell (neuronales Deep-Learning-Netzwerk) sein, bei dem Sie den Namen einer Ebene oder eine Signatur angeben, deren Ausgabe als latenter Bereich verwendet werden kann. Sie können aber auch ein Modell angeben, das Einbettungen direkt ausgibt (latente Bereichsdarstellung). In diesem latenten Bereich werden die Beispieldarstellungen erfasst, die zum Generieren von Erläuterungen verwendet werden.
Ein Cloud Storage-Speicherort, der die zu indexierenden Instanzen für die Suche nach dem ungefähren nächsten Nachbarn enthält. Weitere Informationen finden Sie unter Anforderungen an Eingabedaten.
Console
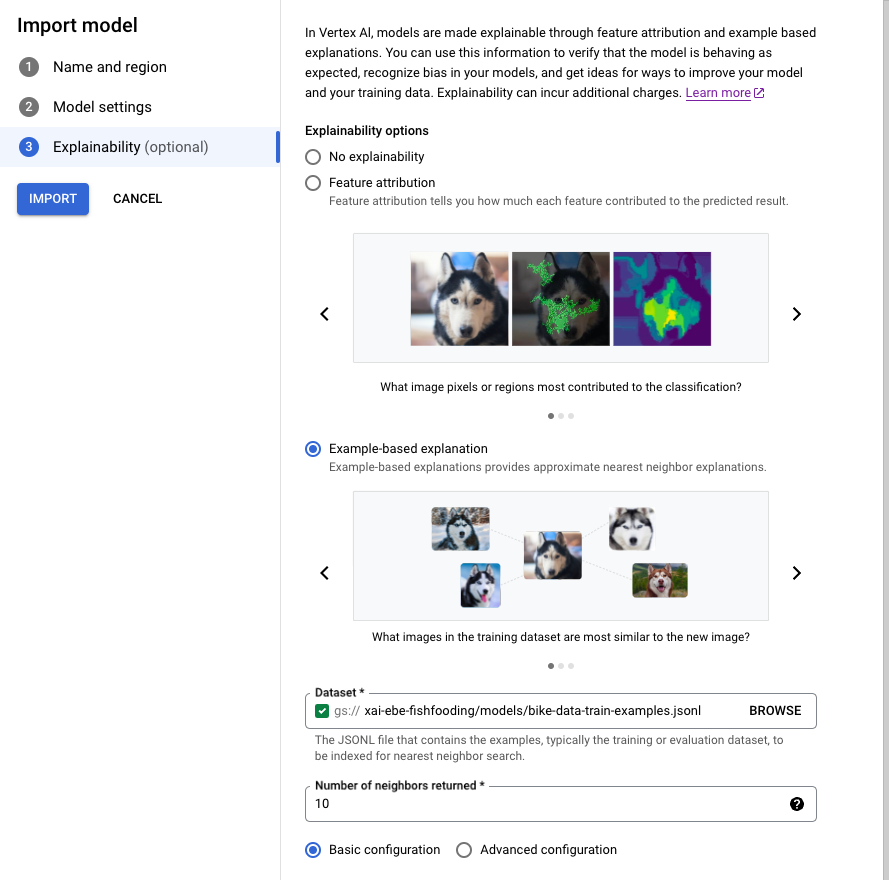
Folgen Sie der Anleitung zum Importieren eines Modells mit der Google Cloud -Konsole.
Wählen Sie auf dem Tab Erläuterbarkeit die Option Beispielbasierte Erläuterung aus und füllen Sie die Felder aus.
Informationen zu den einzelnen Feldern finden Sie in den Tipps in der Google Cloud -Konsole (siehe unten) sowie in der Referenzdokumentation zu Example und ExplanationMetadata.
gcloud-CLI
- Schreiben Sie die folgenden
ExplanationMetadatain eine JSON-Datei in Ihrer lokalen Umgebung. Der Dateiname spielt keine Rolle, aber in diesem Beispiel wird die Dateiexplanation-metadata.jsonaufgerufen:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (Optional) Wenn Sie die vollständige
NearestNeighborSearchConfigangeben, schreiben Sie Folgendes in eine JSON-Datei in Ihrer lokalen Umgebung. Der Dateiname spielt keine Rolle, aber in diesem Beispiel wird die Dateisearch_config.jsonaufgerufen:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- Führen Sie den folgenden Befehl aus, um Ihr
Modelhochzuladen.
Wenn Sie eine Preset-Suchkonfiguration verwenden, entfernen Sie das Flag --explanation-nearest-neighbor-search-config-file. Wenn Sie NearestNeighborSearchConfig angeben, entfernen Sie die Flags --explanation-modality und --explanation-query.
Die Flags, die für beispielbasierte Erläuterungen am relevantesten sind, werden fett formatiert.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
Weitere Informationen finden Sie unter gcloud ai models upload.
-
Die Upload-Aktion gibt eine
OPERATION_IDzurück, mit der geprüft werden kann, ob der Vorgang abgeschlossen ist. Sie können den Status des Vorgangs abfragen, bis in der Antwort"done": trueangegeben wird. Verwenden Sie den Befehl gcloud ai operations describe, um den Status abzufragen. Beispiel:gcloud ai operations describe <operation-id>Sie können erst Erläuterungen anfordern, wenn der Vorgang abgeschlossen ist. Je nach Größe der Dataset- und Modellarchitektur kann dieser Schritt mehrere Stunden dauern, um den Index für die Abfrage von Beispielen zu erstellen.
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT
- LOCATION
Weitere Informationen zu den anderen Platzhaltern finden Sie unter Model, explanationSpec und Examples.
Weitere Informationen zum Hochladen von Modellen finden Sie unter der Methode upload und Modelle importieren.
Im folgenden JSON-Text der Anfrage wird eine Preset-Suchkonfiguration angegeben. Alternativ können Sie die vollständige NearestNeighborSearchConfig angeben.
HTTP-Methode und URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
JSON-Text anfordern:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
Die Upload-Aktion gibt eine OPERATION_ID zurück, mit der geprüft werden kann, ob der Vorgang abgeschlossen ist. Sie können den Status des Vorgangs abfragen, bis in der Antwort "done": true angegeben wird. Verwenden Sie den Befehl gcloud ai operations describe, um den Status abzufragen. Beispiel:
gcloud ai operations describe <operation-id>
Sie können erst Erläuterungen anfordern, wenn der Vorgang abgeschlossen ist. Je nach Größe der Dataset- und Modellarchitektur kann dieser Schritt mehrere Stunden dauern, um den Index für die Abfrage von Beispielen zu erstellen.
Python
Weitere Informationen finden Sie im Abschnitt Modell hochladen im Notebook zur Bildklassifizierung mit beispielbasierten Erklärungen.
NearestNeighborSearchConfig
Der folgende JSON-Anfragetext zeigt, wie die vollständige NearestNeighborSearchConfig (anstelle von Voreinstellungen) in einer upload-Anfrage angegeben wird.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
In diesen Tabellen sind die Felder für NearestNeighborSearchConfig aufgeführt.
| Felder | |
|---|---|
dimensions |
Erforderlich. Die Anzahl der Dimensionen der Eingabevektoren. Wird nur für dichte Einbettungen verwendet. |
approximateNeighborsCount |
Erforderlich, wenn der tree-AH-Algorithmus verwendet wird. Die Standardanzahl der Nachbarn, die über die ungefähre Suche gefunden werden sollen, bevor die genaue Neusortierung ausgeführt wird. Bei der genauen Neusortierung werden Ergebnisse, die von einem ungefähren Suchalgorithmus zurückgegeben werden, über eine aufwändigere Entfernungsberechnung neu angeordnet. |
ShardSize |
ShardSize
Die Größe jedes Shards. Wenn ein Index groß ist, wird er basierend auf der angegebenen Shard-Größe fragmentiert. Während der Bereitstellung wird jeder Shard auf einem separaten Knoten bereitgestellt und unabhängig skaliert. |
distanceMeasureType |
Die bei der Suche nach dem nächsten Nachbarn verwendete Distanzmessung. |
featureNormType |
Art der Normalisierung, die für jeden Vektor ausgeführt werden soll. |
algorithmConfig |
oneOf:
Die Konfiguration für die Algorithmen, die die Vektorsuche für eine effiziente Suche verwendet. Wird nur für dichte Einbettungen verwendet.
|
DistanceMeasureType
| Enums | |
|---|---|
SQUARED_L2_DISTANCE |
Euklidische (L2)-Distanz |
L1_DISTANCE |
Manhattan (L1)-Distanz |
DOT_PRODUCT_DISTANCE |
Standardwert. Definiert als negativer Wert des Skalarprodukts. |
COSINE_DISTANCE |
Kosinus-Entfernung. Wir empfehlen dringend, anstelle der KOSINUS-Distanz DOT_PRODUCT_DISTANCE + UNIT_L2_NORM zu verwenden. Unsere Algorithmen wurden für die DOT_PRODUCT-Distanz optimiert. In Kombination mit UNIT_L2_NORM bietet sie dieselbe Rangfolge und mathematische Äquivalenz wie die KOSINUS-Distanz. |
FeatureNormType
| Enums | |
|---|---|
UNIT_L2_NORM |
Einheit-L2-Normalisierungstyp. |
NONE |
Standardwert. Es ist kein Normalisierungstyp angegeben. |
TreeAhConfig
Dies sind die Felder, die für den tree-AH-Algorithmus ausgewählt werden (Flacher Baum + Asymmetrisches Hashing).
| Felder | |
|---|---|
fractionLeafNodesToSearch |
double |
| Der Standardanteil an Blattknoten, die bei einer beliebigen Abfrage durchsucht werden können. Muss zwischen 0,0 bis 1,0 (ausschließlich) liegen. Der Standardwert ist 0.05, wenn nicht festgelegt. | |
leafNodeEmbeddingCount |
int32 |
| Anzahl der Einbettungen auf jedem Blattknoten. Der Standardwert ist 1.000, wenn nicht festgelegt. | |
leafNodesToSearchPercent |
int32 |
Verworfen, verwenden Sie fractionLeafNodesToSearch.Der Standardprozentsatz von Blattknoten, die bei einer beliebigen Abfrage durchsucht werden können. Muss zwischen 1 und 100 liegen. Der Standardwert ist 10 (also 10 %), wenn nichts festgelegt ist. |
|
BruteForceConfig
Mit dieser Option wird die standardmäßige lineare Suche in der Datenbank für jede Abfrage implementiert. Es gibt keine Felder, die für eine Brute-Force-Suche konfiguriert werden müssen. Zum Auswählen dieses Algorithmus übergeben Sie ein leeres Objekt für BruteForceConfig an algorithmConfig.
Anforderungen an Eingabedaten
Laden Sie das Dataset in einen Cloud Storage-Speicherort hoch. Achten Sie darauf, dass die Dateien im JSON Lines-Format vorliegen.
Die Dateien müssen im JSON Lines-Format vorliegen. Das folgende Beispiel stammt aus dem Notebook zur Bildklassifizierung mit beispielbasierten Erläuterungen:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
Index oder Konfiguration aktualisieren
Mit Vertex AI können Sie den Index des nächsten Nachbarns oder der Example-Konfiguration eines Modells aktualisieren. Dies ist nützlich, wenn Sie Ihr Modell aktualisieren möchten, ohne das zugehörige Dataset neu zu indexieren. Wenn der Index Ihres Modells beispielsweise 1.000 Instanzen enthält und Sie 500 weitere Instanzen hinzufügen möchten, können Sie UpdateExplanationDataset aufrufen, um den Index hinzuzufügen, ohne die ursprünglichen 1.000 Instanzen neu zu verarbeiten.
So aktualisieren Sie das Erläuterungs-Dataset:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
Verwendungshinweise:
model_idbleibt nach dem VorgangUpdateExplanationDatasetunverändert.Der Vorgang
UpdateExplanationDatasetbetrifft nur die RessourceModel. Es wird kein zugehörigesDeployedModelaktualisiert. Dies bedeutet, dass der Index einesdeployedModels das Dataset zum bei der Bereitstellung enthält. Zum Aktualisieren des Index einesdeployedModels müssen Sie das aktualisierte Modell noch einmal auf einem Endpunkt bereitstellen.
Konfiguration beim Abrufen von Online-Erläuterungen überschreiben
Wenn Sie eine Erläuterung anfordern, können Sie einige der Parameter direkt überschreiben, indem Sie das Feld ExplanationSpecOverride angeben.
Abhängig von der Anwendung sind einige Einschränkungen möglicherweise in Bezug auf die Art der zurückgegebenen Informationen wünschenswert. Um beispielsweise die Vielfalt zu erläutern, kann ein Nutzer einen Crowding-Parameter angeben, der festlegt, dass kein einzelner Beispieltyp in den Erläuterungen überrepräsentiert ist. Konkret: Wenn ein Nutzer versucht zu verstehen, warum ein Vogel von seinem Modell als Flugzeug eingestuft wurde, ist er vielleicht nicht daran interessiert, zu viele Vogelbeispiele als Erläuterungen zu sehen, um die Ursache besser untersuchen zu können.
In der folgenden Tabelle sind die Parameter zusammengefasst, die für eine Anfrage mit beispielbasierter Erläuterung überschrieben werden können:
| Property-Name | Attributwert | Beschreibung |
|---|---|---|
| neighborCount | int32 |
Die Anzahl der Beispiele, die als Erläuterung zurückgegeben werden sollen |
| crowdingCount | int32 |
Maximale Anzahl von Beispielen, die mit demselben Crowding-Tag zurückgegeben werden sollen |
| Zulassen | String Array |
Die Tags, die für Erläuterung zulässig sind |
| Ablehnen | String Array |
Die Tags, die für Erläuterungen nicht zulässig sind |
Unter Vektorsuche – Filterung werden diese Parameter ausführlicher beschrieben.
Das folgende Beispiel zeigt einen JSON-Anfragetext mit Überschreibungen:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
Nächste Schritte
Hier ein Beispiel für die Antwort auf eine beispielbasierte explain-Anfrage:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
Preise
Weitere Informationen finden Sie auf der Seite „Preise“ im Abschnitt zu beispielbasierten Erklärungen.