Neste documento, explicamos como configurar o Cloud SQL para PostgreSQL para uso na produção. O Cloud SQL para PostgreSQL é um serviço RDBMS totalmente gerenciado integrado ao ecossistema do Google Cloud. O Cloud SQL para PostgreSQL tem vários recursos e funcionalidades importantes:
- Ele veicula vários aplicativos e usuários globalmente por meio dos recursos de segurança gerenciados do Google Cloud, incluindo VPC e criptografia de dados automática em repouso e em trânsito.
- Compatível com arquitetura de alta disponibilidade usando instâncias principais e em espera e failover automático entre elas.
- Compatível com cargas de trabalho de banco de dados distribuídas ativando a leitura/gravação entre o nó principal e as réplicas de leitura no mesmo cluster.
- Compatível com backups automáticos integrados ao Cloud Storage e à manutenção automática do banco de dados.
- Compatível com diversas cargas de trabalho de processamento transacional on-line (OLTP, na sigla em inglês).
Como implantar uma instância do Cloud SQL para PostgreSQL
É possível configurar uma instância do Cloud SQL para PostgreSQL em algumas etapas usando o console do Google Cloud ou a Google Cloud CLI. Ambos os métodos são descritos aqui.
Console
No Console do Google Cloud, acesse a página SQL>Instâncias.
Clique em Criar instância e em Escolher PostgreSQL.
Na página Criar uma instância do PostgreSQL, forneça os seguintes detalhes:
- Código da instância: insira um nome para a instância. O nome da instância é permanente e não pode ser alterado posteriormente.
- Senha de usuário padrão: escolha a senha de usuário do postgres como a conta de administrador padrão. É possível criar outros usuários após a implantação da instância do PostgreSQL.
- Região e Zona: selecione uma região e uma zona. É uma prática recomendada implantar a instância do PostgreSQL na mesma região que os serviços do Google Cloud associados (por exemplo, aplicativos) ou em proximidade geográfica dos usuários, para reduzir a latência no processamento de dados. Depois de selecionar uma região, não é possível modificá-la.
- Versão do banco de dados: escolha a versão mais recente ou, se necessário, a versão mais recente disponível.
Clique em Criar para implantar a instância do PostgreSQL. Se preferir, clique em Mostrar opções de configuração para definir outras configurações.
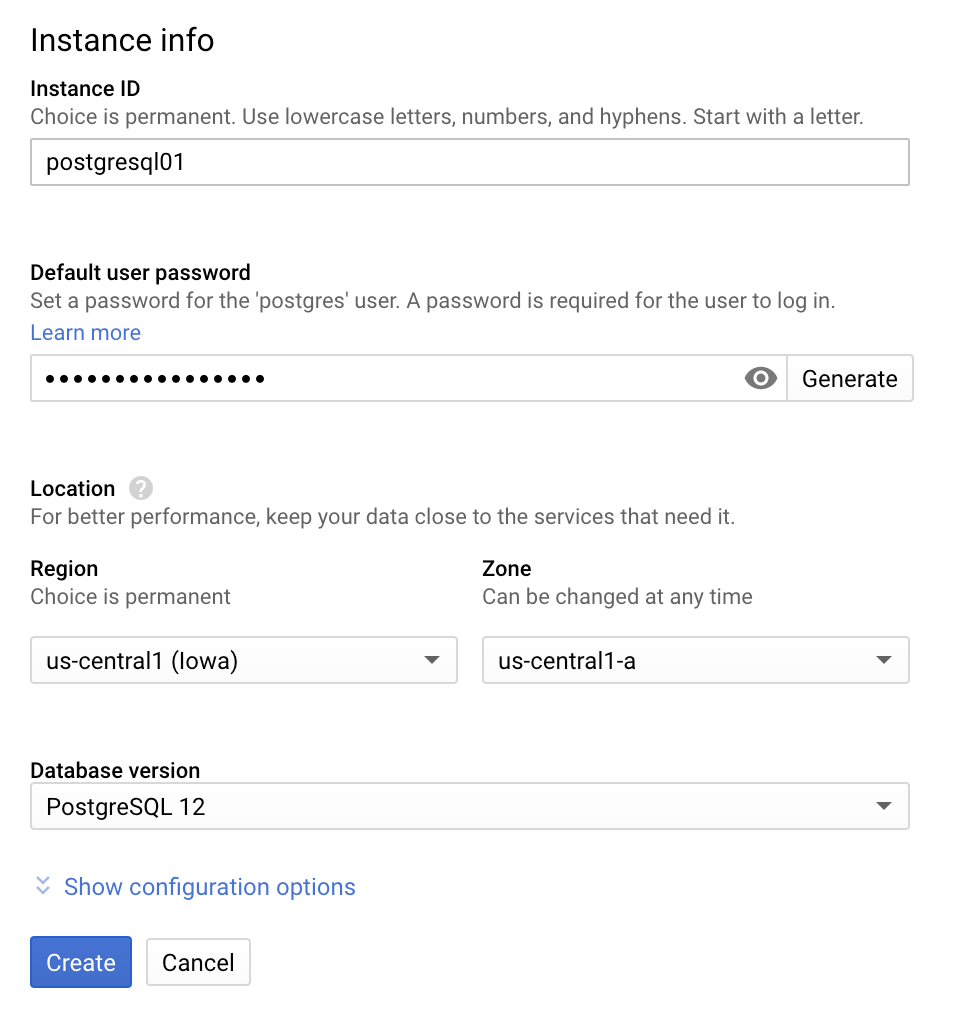
Outras opções de configuração:
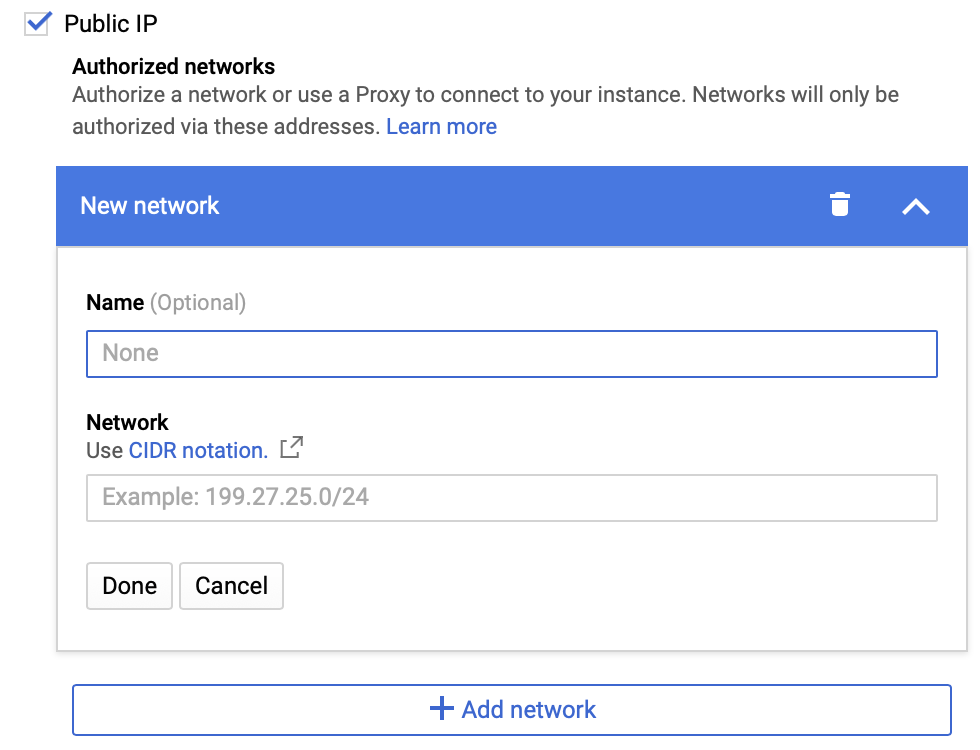
Conectividade: normalmente, você conecta a instância do PostgreSQL à rede por meio de um endereço IP público, um endereço IP particular e redes autorizadas. As redes autorizadas são conexões permitidas que podem ser definidas para estabelecer uma conexão remota, como, por exemplo, aprovar uma conexão de um endereço IP específico de um cliente.
Tipo de máquina e armazenamento: escolha o tipo de máquina por recursos alocados (vCPUs, RAM), tipo de armazenamento (SSD ou HDD) e capacidade de armazenamento. Aumentar a capacidade de armazenamento também aumenta a capacidade do disco compatível (MB/s) e as IOPs de leitura e gravação para seu banco de dados. Ajuste a capacidade de armazenamento com base na capacidade esperada de disco e nos requisitos de IOPS.


Backups automáticos e alta disponibilidade: use o recurso backups automatizados, que é ativado por padrão, para definir o período em que realizar backups automáticos. Além disso, a opção de recuperação pontual, que usa registros de gravação antecipada, também é necessária para criar uma réplica de leitura. Esses registros são atualizados regularmente e usam espaço de armazenamento. Para evitar problemas de armazenamento inesperados, recomendamos ativar os aumentos automáticos no armazenamento ao usar a recuperação pontual. A alta disponibilidade é desativada por padrão (várias zonas). Para ativar o failover automático, selecione a opção Alta disponibilidade (regional).
Sinalizações: essa configuração especifica o método do Cloud SQL para controlar configurações e parâmetros na instância. Isso é equivalente ao arquivo
postgresql.confde uma instância do PostgreSQL não gerenciada. Para ter uma lista completa, consulte a documentação do produto. Alterar o valor de uma sinalização ou definir uma nova sinalização pode exigir uma reinicialização da instância.Manutenção: esta seção especifica sua janela de tempo preferencial para tarefas de manutenção, incluindo correções de bugs e upgrades de versão secundária. Observe que as operações de manutenção geralmente exigem uma reinicialização da instância e podem causar uma breve interrupção do serviço. Inscreva-se para receber notificações por e-mail sobre eventos de manutenção futuros.
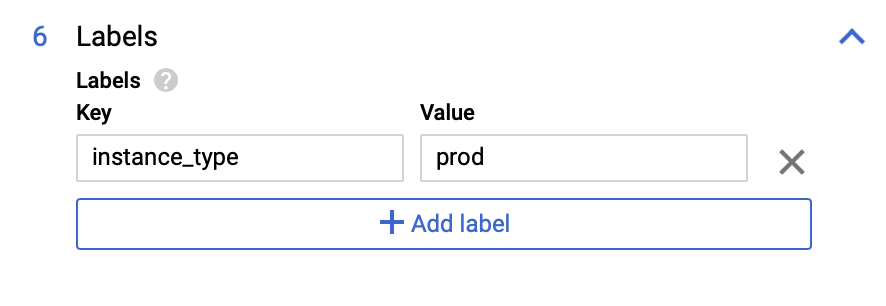
Rótulos: nesta seção, você define pares de chave-valor para categorizar sua instância do PostgreSQL, por exemplo:
gcloud
Crie a instância do PostgreSQL:
gcloud sql instances create postgresql01 \ --cpu=2 \ --memory=7680MB \ --region=us-central1 --zone=us-central1-aAtribua uma senha para o usuário padrão do PostgreSQL (exemplo de sintaxe):
gcloud sql users set-password postgres \ --instance INSTANCE_NAME \ --password PASSWORDÉ possível especificar estas opções:
- Versão do banco de dados: uma das versões do PostgreSQL compatíveis.
- Tipo de armazenamento: SSD ou HDD como o tipo de armazenamento.
- Capacidade de armazenamento: as configurações iniciais de armazenamento para a instância.
- Aumento automático de armazenamento: automação do Cloud SQL para adicionar armazenamento extra quando houver pouco espaço livre.
- Alta disponibilidade: alta disponibilidade do Cloud SQL.
- Backups automáticos: a janela de horário de início dos backups.
- Recuperação pontual: recuperação pontual e geração antecipadamente.
- Janela de manutenção: uma janela de uma hora em que o Cloud SQL pode executar a manutenção disruptiva.
- Hora da manutenção: o melhor horário para executar atualizações na instância do PostgreSQL. É possível especificar pré-lançamento para atualizações anteriores ou produção para atualizações posteriores.
- Sinalizações do banco de dados: as sinalizações do banco de dados PostgreSQL para controlar configurações e parâmetros.
O comando
gclouda seguir cria uma instância do Cloud SQL para PostgreSQL com algumas outras opções:gcloud sql instances create postgresql01 \ --cpu=2 \ --memory=7680MB \ --region=us-central1 \ --zone=us-central1-a \ --database-version=POSTGRES_12 \ --storage-type=SSD \ --storage-size=100 \ --storage-auto-increase \ --availability-type=regional \ --backup-start-time=23:30 \ --enable-point-in-time-recovery \ --maintenance-window-day=sun \ --maintenance-window-hour=11 \ --maintenance-release-channel=production \ --database-flags max_connections=100Para saber mais, consulte o artigo Criar instâncias.
Seleção de instâncias
A seleção ou o dimensionamento de instâncias envolve a seleção de um tipo de máquina que seja compatível com sua carga de trabalho Oracle no Cloud SQL para PostgreSQL. Os tipos de instância são divididos em dois grupos principais:
- Máquinas com núcleo compartilhado: econômicas.
- Instâncias de núcleo dedicado: compatíveis com várias vCPUs e proporções de memória.
Para mais informações sobre tipos de instância, consulte a página de preços do Cloud SQL.
Para dimensionar sua instância, comece analisando os recursos alocados e usados pelo banco de dados de origem. É possível acessar as configurações dos recursos
do banco de dados da Oracle na visualização do sistema
V$OSSTAT
ou em um relatório da Oracle AWR (consulte os exemplos a seguir):
Memória física (número de bytes da memória física no servidor de banco de dados):
SQL> SELECT ROUND(MAX(VALUE)/1024/1024/1024) AS MEM_SIZE_GB
FROM V$OSSTAT
WHERE STAT_NAME = 'PHYSICAL_MEMORY_BYTES';
Memória alocada:
SQL> SELECT NAME, VALUE, DISPLAY_VALUE FROM V$PARAMETER
WHERE NAME LIKE '%sga%' OR NAME LIKE '%memory%';
Núcleos de CPU (número de núcleos de CPU disponíveis):
SQL> SELECT VALUE FROM V$OSSTAT
WHERE STAT_NAME = 'NUM_CPU_CORES';
Núcleos de CPU (identificados por uma instância do Oracle usando a visualização V$LICENSE):
SQL> SELECT CPU_CORE_COUNT_CURRENT FROM V$LICENSE;
Exemplo de recurso de relatório do Oracle AWR (em inglês), que pode fornecer insights adicionais sobre as características de carga de trabalho específicas de uma instância do Oracle:

Quando você tiver as informações de recursos do seu banco de dados de origem, recomendamos escolher o tipo de instância do Cloud SQL mais próximo e executar alguns comparativos de mercado. Os resultados das comparações vão ajudar você a finalizar a seleção de instâncias.
Configuração de alta disponibilidade
Para implementar uma solução de recuperação de desastres, semelhante ao Data Guard do Oracle, o Cloud SQL para PostgreSQL oferece recursos de alta disponibilidade que oferecem failover automático da instância principal do cluster para a instância de espera. A instância de espera está localizada em uma zona diferente na mesma região da instância principal. A instância de espera é mantida em sincronia por meio da replicação síncrona entre os discos permanentes das instâncias principal e de espera. Esse método garante que todas as modificações de dados no primário também sejam aplicadas em espera.
No caso de uma falha principal, como uma instância que não responde ou a falha no nível da zona, o Cloud SQL realiza um failover automático. A instância primária é monitorada por sinais de funcionamento, que ocorrem em intervalos de um segundo, com um failover ativado após cerca de 60 segundos sem nenhum sinal de funcionamento recebido da instância principal. Nesse ponto, a instância principal faz o failover em espera, fornecendo acesso de dados a aplicativos ou clientes de forma transparente, enquanto as réplicas de leitura existentes permanecem operacionais. Diferentemente do Active Data Guard, a instância de espera não está aberta para leituras enquanto atua como uma espera. Com o Cloud SQL, somente as réplicas de leitura podem ser usadas para descarregar as leituras da instância primária.
Ative o recurso de alta disponibilidade (HA, na sigla em inglês) do Cloud SQL para PostgreSQL quando você criar a instância ou para uma instância atual do PostgreSQL. Estas são as etapas:
Console
- Na página de criação da instância, clique em Mostrar opções de configuração>Backups automáticos e disponibilidade>Disponibilidadee selecione a opção Alta disponibilidade (regional).
- Para uma instância existente do PostgreSQL, edite a instância do PostgreSQL seguindo a etapa anterior. Isso exige a reinicialização do banco de dados.
Para iniciar um failover para fins de teste, acesse a página do Cloud SQL e clique em Failover.

É possível ativar o failback da mesma maneira.
gcloud
Ative a HA definindo o parâmetro
availability-typecomoregional:gcloud sql instances create postgresql01 \ --cpu=2 \ --memory=7680MB \ --region=us-central1 \ --zone=us-central1-a \ --availability-type=regionalVerifique se uma instância existente do PostgreSQL tem a alta disponibilidade configurada:
gcloud sql instances describe INSTANCE_NAME
Se a saída deste comando incluir
availabilityType: REGIONAL, a HA já estará ativada. Se a saída incluiravailabilityType: ZONAL, a alta disponibilidade não será configurada e poderá ser ativada usando o comandopatch:gcloud sql instances patch INSTANCE_NAME --availability-type REGIONAL
Inicie um teste de failover do principal para o modo de espera:
gcloud sql instances failover PRIMARY_INSTANCE_NAME
Para falhar, execute o mesmo comando de failover no novo principal.
Usuários administradores e contas
Duas contas de usuário padrão do PostgreSQL vêm com qualquer instalação do Cloud SQL para PostgreSQL. Essas contas são postgres e cloudsqlimportexport.
Conta do postgres
A conta postgres é a conta de administrador equivalente aos usuários SYS ou SYSTEM do Oracle no Cloud PaaS. Como o Cloud SQL para PostgreSQL é um serviço gerenciado, o usuário postgres, ao contrário dos usuários SYS ou SYSTEM do Oracle, não pode acessar determinados procedimentos e tabelas do sistema que exigem privilégios avançados.
O usuário postgres faz parte do papel cloudsqlsuperuser e
tem estes atributos ou privilégios: CREATEROLE,
CREATEDB e LOGIN. Ele não tem os atributos SUPERUSER ou
REPLICATION.
Conta cloudsqlimportexport
A conta cloudsqlimportexport é criada com o conjunto mínimo de privilégios necessários para as operações de importação/exportação de CSV. É possível criar os próprios usuários para executar essas operações. No entanto, se você não fizer isso, o usuário padrão cloudsqlimportexport será usado. O usuário cloudsqlimportexport é
do sistema e não é possível usá-lo diretamente.
Gerenciamento de contas (adicionar, excluir ou alterar senha)
O gerenciamento de contas requer a criação de novas contas de usuário, a modificação da senha de uma conta existente e a exclusão de uma conta que não é mais necessária. É possível
executar essas operações da conta por meio do Console do Google Cloud, da ferramenta
gcloud
ou do cliente PostgreSQL.
Console
Liste as contas atuais no Console do Google Cloud: acesse Console do Cloud SQL>Selecionar instância do PostgreSQL>Usuários.
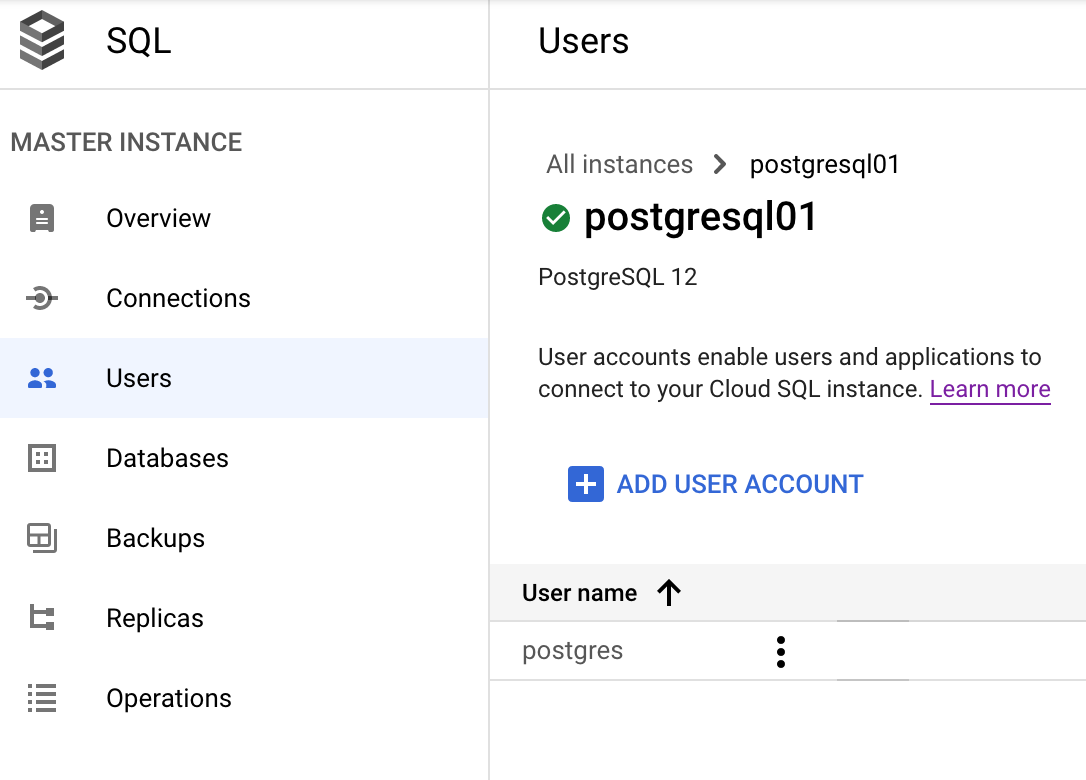
Modifique a senha ou exclua a conta completamente clicando no ícone de três pontos (Mais) ao lado da conta.
Nessa tela, clique em Criar conta de usuário para criar um novo usuário do PostgreSQL.
gcloud
Liste as contas de usuários existentes:
gcloud sql users list --instance=postgresql01A resposta será semelhante a:
NAME HOST PostgresCrie a conta de usuário
appuser, defina a senha e excluaappuser:gcloud sql users create appuser \ --instance=postgresql01 --password=PASSWORD gcloud sql users set-password appuser \ --host=% --instance=postgresql01 --prompt-for-password gcloud sql users delete appuser --instance=postgresql01
PostgreSQL
Execute essas mesmas ações diretamente de um cliente padrão do PostgreSQL, por exemplo:
postgres=> create user appuser with login password 'my_password'; postgres=> alter user appuser password 'my_password'; postgres=> drop user appuser;É possível configurar permissões no nível do banco de dados PostgreSQL (por exemplo, leitura de uma tabela ou visualização específica) usando os comandos
GRANT/REVOKEno cliente do PostgreSQL.
Monitoramento e alertas
O Cloud Logging é a principal ferramenta de geração de registros no Google Cloud. Ele é usado para coletar e visualizar vários registros de monitoramento de recursos, como o Cloud SQL para PostgreSQL.
O Cloud Logging permite que você veja os registros do Cloud SQL para PostgreSQL filtrados por nível de evento (por exemplo, crítico, erro ou aviso), período do evento e pesquisa de texto livre, como na captura de tela a seguir.
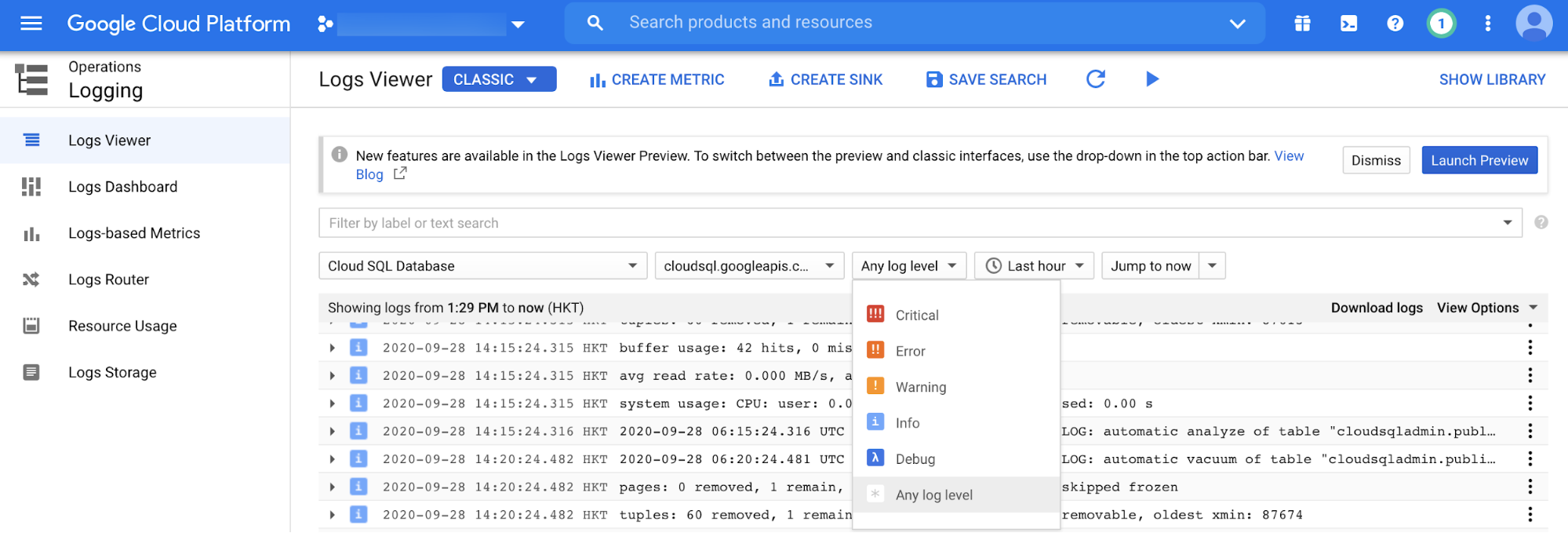
Monitoramento de instâncias de banco de dados PostgreSQL
As principais ferramentas de monitoramento da Oracle são Enterprise Manager e Grid/Cloud Control. Essas ferramentas permitem fazer o monitoramento de instâncias de banco de dados em tempo real em uma sessão do banco de dados e no nível de instrução SQL.
O Cloud SQL para PostgreSQL oferece recursos de monitoramento comparáveis por meio do Console do Google Cloud. A partir daí, você pode ter uma visão resumida das instâncias de seu banco de dados, incluindo a utilização da CPU, uso de armazenamento, uso de memória, operações de leitura/gravação, conexões ativas, transações por segundo e bytes de entrada/saída. A observabilidade do Google Cloud fornece outras métricas de monitoramento para o Cloud SQL para PostgreSQL, como solicitações de failover automático e atraso de replicação entre as réplicas primária e de leitura.
O gráfico de exemplo a seguir mostra um gráfico de transações por segundo nas últimas seis horas:
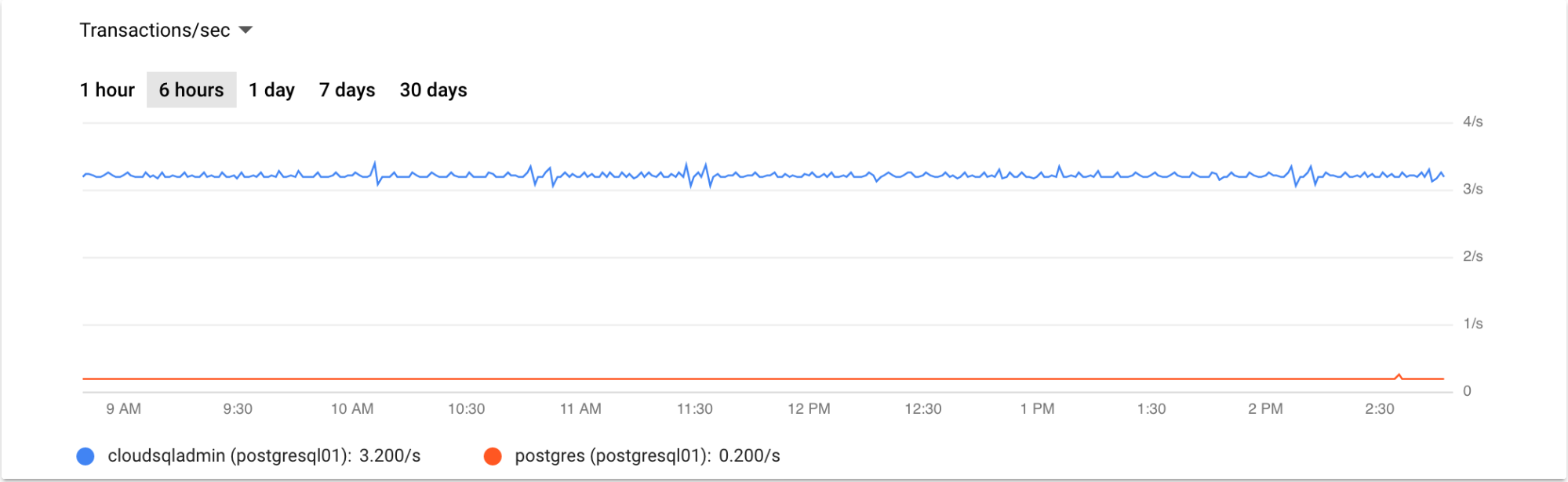
Como monitorar réplicas de leitura
É possível monitorar as réplicas de leitura por meio do Console do Google Cloud da mesma forma que você monitora a instância principal. Há métricas específicas para verificar o status da replicação entre as instâncias primária e de réplica de leitura. Essas métricas são usadas para preencher a página de visão geral da instância de réplica de leitura no Console do Google Cloud.
Também é possível verificar o status da replicação na linha de comando:
gcloud sql instances describe REPLICA_NAME
Uma terceira opção é verificar o status da replicação por meio de um cliente PostgreSQL. O comando PostgreSQL a seguir verifica o status da réplica de leitura:
postgres=> \x on Expanded display is on. postgres=> select * from pg_stat_replication; -[ RECORD 1 ]----+------------------------------------------- pid | 74733 usesysid | 16388 usename | cloudsqlreplica application_name | PROJECT_ID:REPLICA_NAME client_addr | REPLICA_IP client_hostname | client_port | 41660 backend_start | 2020-09-28 06:59:38.783981+00 backend_xmin | state | streaming sent_lsn | 0/2939FFA8 write_lsn | 0/2939FFA8 flush_lsn | 0/2939FFA8 replay_lsn | 0/2939FFA8 write_lag | flush_lag | replay_lag | sync_priority | 0 sync_state | async reply_time | 2020-09-28 07:17:52.714969+00 postgres=>
Monitoramento do banco de dados PostgreSQL
Nesta seção, você verá outras tarefas de monitoramento que são consideradas rotina para um DBA do PostgreSQL.
Monitoramento de sessão
As sessões do Oracle são monitoradas consultando as visualizações de desempenho dinâmico conhecidas como visualizações "V$". As visualizações V$SESSION e V$PROCESS costumam ser usadas para ver insights em tempo real sobre a atividade atual do banco de dados por meio de instruções SQL. É possível monitorar a atividade da sessão no PostgreSQL de maneira semelhante, por meio de comandos do PostgreSQL e instruções SQL.
A visualização dinâmica
pg_stat_activity
do PostgreSQL fornece informações detalhadas sobre a atividade da sessão atual do
banco de dados:
postgres=> \x on postgres=> select * from pg_stat_activity where backend_type = 'client backend' and usename != 'cloudsqladmin'; -[ RECORD 1 ]----+----------------------------------------------------------------------------------------------------- datid | 14052 datname | postgres pid | 74750 usesysid | 16389 usename | postgres application_name | psql client_addr | CLIENT_IP client_hostname | client_port | 51904 backend_start | 2020-09-28 07:01:30.214099+00 xact_start | 2020-09-28 07:28:48.982115+00 query_start | 2020-09-28 07:28:48.982115+00 state_change | 2020-09-28 07:28:48.982117+00 wait_event_type | wait_event | state | active backend_xid | backend_xmin | 88513 query | select * from pg_stat_activity where backend_type = 'client backend' and usename != 'cloudsqladmin'; backend_type | client backend postgres=>
Monitoramento de transações longas
Para identificar transações de longa duração que podem gerar problemas de desempenho, consulte a visualização dinâmica pg_stat_activity. É possível identificar consultas de longa duração aplicando filtros apropriados nas colunas, como query_start e state.
Monitoramento de bloqueios
É possível monitorar os bloqueios de banco de dados por meio da visualização dinâmica
pg_locks,
que fornece informações em tempo real sobre qualquer contenção
de bloqueio que possa levar a problemas de desempenho.
Alertas
É possível utilizar alertas além do monitoramento e da geração de registros. Também é possível criar alertas para as condições.
Escalonamento
O Cloud SQL para PostgreSQL é compatível com as opções de escalonamento vertical e horizontal.
Escalone verticalmente adicionando mais recursos à instância do Cloud SQL, como aumentando o número de CPUs e memória atribuídas a instâncias. A capacidade de rede da instância depende dos valores escolhidos para CPU e memória.
O Cloud SQL é compatível com até 30 TB de espaço de armazenamento. Adicionar a capacidade de armazenamento geralmente aumenta a capacidade e as IOPs de disco de uma instância. Observe que a capacidade de rede de uma instância do Cloud SQL inclui leituras/gravações dos seus dados (taxa de transferência do disco) e o conteúdo de consultas, cálculos e outros dados que não são armazenados no seu banco de dados. É importante considerar esses fatores ao escalonar verticalmente a instância do Cloud SQL.
Você faz o escalonamento horizontal criando réplicas de leitura. As réplicas de leitura permitem escalonar as cargas de trabalho de leitura em instâncias separadas do Cloud SQL sem afetar o desempenho e a disponibilidade da instância principal.
Backup e recuperação
Há dois métodos de backup de banco de dados para o Cloud SQL para PostgreSQL: sob demanda e automatizado. É possível fazer backups sob demanda a qualquer momento, e eles são mantidos até que você os exclua. Os backups automáticos usam o período de quatro horas de backup e são retidos por sete dias.
É possível restaurar backups do banco de dados do Cloud SQL para PostgreSQL para a mesma instância, substituindo os dados atuais ou para uma nova instância. Além disso, o Cloud SQL para PostgreSQL permite restaurar um banco de dados do PostgreSQL para um ponto determinado no tempo, desde que a recuperação pontual esteja ativada e a opção de backup automático esteja ativada.
O Cloud SQL para MySQL fornece recursos de clonagem de bancos de dados. É preciso criar o clone a partir da instância principal, ou seja, ele não pode ser criado a partir de uma réplica. É possível executar backups do banco de dados, restaurar e clonar no Console do Google Cloud ou na CLI gcloud.
Automação
É possível usar a API Cloud SQL Admin para automatizar completamente a administração de uma instância do Cloud SQL para PostgreSQL. A API Cloud SQL Admin é uma API REST que controla diferentes tipos de recursos, como instâncias, bancos de dados, usuários, sinalizações, operações, SslCerts, camadas e BackupRuns. Para saber mais informações, consulte a documentação da API.
A seguir
- Descubra mais sobre as contas de usuário do Cloud SQL para PostgreSQL.
- Saiba mais sobre o Cloud SQL para PostgreSQL para usuários do Oracle:
- Como migrar usuários do Oracle para o Cloud SQL para PostgreSQL: terminologia e funcionalidade
- Como migrar usuários do Oracle para o Cloud SQL para MySQL: tipos de dados, usuários e tabelas
- Como migrar usuários do Oracle para o Cloud SQL para PostgreSQL: consultas, procedimentos armazenados, funções e gatilhos
- Como migrar usuários da Oracle para o Cloud SQL para MySQL: segurança, operações, monitoramento e geração de registros
- Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.