En esta guía, se proporciona una descripción general de las opciones, las recomendaciones y los conceptos generales que debes conocer antes de implementar un sistema SAP HANA con alta disponibilidad (HA) en Google Cloud.
En esta guía, se da por sentado que ya conoces las prácticas y los conceptos generales necesarios para implementar un sistema SAP HANA con alta disponibilidad. Por lo tanto, la guía se centra sobre todo en lo que necesitas saber para implementar este sistema en Google Cloud.
Si necesitas saber más sobre los conceptos y las prácticas generales que se requieren para implementar un sistema SAP HANA con alta disponibilidad, consulta:
- El documento de prácticas recomendadas de SAP Compilación de alta disponibilidad para SAP NetWeaver y SAP HANA en Linux
- La documentación de SAP HANA
Esta guía de planificación se centra solo en la HA para SAP HANA y no abarca la HA para los sistemas de aplicaciones. Si deseas obtener información sobre la HA para SAP NetWeaver, consulta la Guía de planificación de alta disponibilidad para SAP NetWeaver en Google Cloud.
Esta guía no reemplaza ninguna documentación proporcionada por SAP.
Opciones de alta disponibilidad para SAP HANA en Google Cloud
Puedes usar una combinación de funciones de Google Cloud y SAP en el diseño de una configuración de alta disponibilidad para SAP HANA que puede manejar fallas en los niveles de infraestructura y de software. En la siguiente tabla, se describen las funciones de SAP y Google Cloud que se usan para proporcionar alta disponibilidad.
| Atributo | Descripción |
|---|---|
| Migración en vivo de Compute Engine |
Compute Engine supervisa el estado de la infraestructura subyacente y, automáticamente, migra la instancia lejos de un evento de mantenimiento de infraestructura. La intervención del usuario no es obligatoria. Compute Engine mantiene la instancia en ejecución durante la migración, si es posible. En el caso de interrupciones importantes, puede haber una pequeña demora entre el momento en que la instancia falla y el momento en que vuelve a estar disponible. En los sistemas de varios hosts, los volúmenes compartidos, como el volumen “/hana/shared” usado en la guía de implementación, son discos persistentes conectados a la VM que aloja el host principal y se activan por NFS en los hosts de trabajador. Durante la migración en vivo del host principal, no se puede acceder al volumen de NFS durante algunos segundos. Cuando se reinicia el host principal, el volumen de NFS vuelve a funcionar en todos los hosts y la operación normal se reanuda automáticamente. Una instancia recuperada es idéntica a la instancia original, incluidos el ID de la instancia, la dirección IP privada y todos los metadatos y el almacenamiento de la instancia. De forma predeterminada, las instancias estándar están configuradas para migrar en vivo. Te recomendamos que no cambies esta configuración. Para obtener más información, consulta Migración en vivo. |
| Reinicio automático de Compute Engine |
Si la instancia está configurada para finalizar cuando hay un evento de mantenimiento o si falla debido a un problema del hardware subyacente, puedes configurar Compute Engine a fin de reiniciar la instancia automáticamente. De forma predeterminada, las instancias se configuran para que se reinicien automáticamente. Te recomendamos que no cambies esta configuración. |
| Reinicio automático del servicio de SAP HANA |
El reinicio automático del servicio de SAP HANA es una solución de recuperación ante fallas que proporciona SAP. SAP HANA tiene muchos servicios configurados que se ejecutan todo el tiempo para varias actividades. Cuando alguno de estos servicios se inhabilita debido a un error de software o un error humano, la función controladora de reinicio automático del servicio de SAP HANA la reinicia automáticamente. Cuando se reinicia el servicio, se vuelven a cargar todos los datos necesarios en la memoria y se reanuda su funcionamiento. |
| Copias de seguridad de SAP HANA |
Las copias de seguridad de SAP HANA crean copias de los datos de la base de datos que se pueden usar para reconstruir la base de datos en un momento determinado. Para obtener más información sobre el uso de las copias de seguridad de SAP HANA en Google Cloud, consulta la guía de operaciones de SAP HANA. |
| Replicación de almacenamiento de SAP HANA |
La replicación del almacenamiento de SAP HANA proporciona asistencia de recuperación ante desastres a nivel de almacenamiento a través de ciertos socios de hardware. La replicación del almacenamiento de SAP HANA no es compatible con Google Cloud. En su lugar, puedes considerar usar instantáneas de discos persistentes de Compute Engine. A fin de obtener más información sobre el uso de instantáneas de discos persistentes para crear copias de seguridad de los sistemas SAP HANA en Google Cloud, consulta la guía de operaciones de SAP HANA. |
| Conmutación por error automática del host de SAP HANA |
La conmutación por error automática del host de SAP HANA es una solución de recuperación ante fallas local que requiere uno o más hosts de SAP HANA en espera en un sistema de escalamiento horizontal. Si uno de los hosts principales falla, la conmutación por error automática del host activa el host en línea de reserva y reinicia el host con errores como host de reserva. Para obtener más información, consulte:
|
| Replicación del sistema SAP HANA |
La replicación del sistema SAP HANA te permite configurar uno o más sistemas para que reemplacen el sistema principal en situaciones de alta disponibilidad o recuperación ante desastres. Puedes ajustar la replicación para satisfacer tus necesidades en términos de rendimiento y tiempo de conmutación por error. |
| Opción de SAP HANA Fast Restart (recomendada) |
SAP HANA Fast Restart reduce los tiempos de reinicio en caso de que SAP HANA finalice, pero el sistema operativo permanezca en ejecución. SAP HANA reduce el tiempo de reinicio, ya que aprovecha la funcionalidad de la memoria persistente de SAP HANA para preservar los fragmentos de datos MAIN de las tablas del almacenamiento de columnas en DRAM que se asignan al sistema de archivos Para obtener más información sobre el uso de la opción de SAP HANA Fast Restart, consulta las guías de implementación de alta disponibilidad: |
| Hooks de proveedor de HA/DR de SAP HANA (recomendada) |
Los hooks del proveedor de HA/DR de SAP HANA permiten que SAP HANA envíe notificaciones para ciertos eventos al clúster de Pacemaker, lo que mejora la detección de fallas. Los hooks del proveedor de HA/DR de SAP HANA requieren Para obtener más información sobre el uso de los hooks del proveedor de HA/DR de SAP HANA, consulta las guías de implementación de alta disponibilidad: |
Clústeres con alta disponibilidad nativos del SO para SAP HANA en Google Cloud
El agrupamiento en clústeres del sistema operativo Linux proporciona conocimiento de la aplicación y del invitado para el estado de la aplicación y automatiza las acciones de recuperación en caso de que se genere una falla.
Aunque por lo general los principios de los clústeres con alta disponibilidad que se aplican en entornos que no son de nube se aplican en Google Cloud, hay algunas diferencias en la forma de implementar, por ejemplo, las IP virtuales y la protección.
Puedes usar distribuciones de Linux de alta disponibilidad de Red Hat o SUSE para tu clúster con alta disponibilidad para SAP HANA en Google Cloud.
A fin de obtener instrucciones para implementar y configurar de forma manual un clúster con alta disponibilidad en Google Cloud para SAP HANA, consulta:
- Configuración manual de clústeres de escalamiento vertical de alta disponibilidad en RHEL
- Configuración manual de clústeres con alta disponibilidad en SLES:
Para ver las opciones de implementación automatizada que proporciona Google Cloud, consulta Opciones de implementación automatizada para las configuraciones de alta disponibilidad de SAP HANA.
Agentes de recursos del clúster
Red Hat y SUSE proporcionan agentes de recursos para Google Cloud con sus implementaciones con alta disponibilidad del software del clúster de Pacemaker. Los agentes de recursos para Google Cloud administran la protección, las VIP que se implementan con rutas o IP de alias, y las acciones de almacenamiento.
Para entregar actualizaciones que aún no están incluidas en los agentes de recursos básicos del SO, Google Cloud proporciona de manera periódica agentes de recursos complementarios para clústeres con alta disponibilidad de SAP. Cuando se requieren estos agentes de recursos complementarios, los procedimientos de implementación de Google Cloud incluyen un paso para descargarlos.
Agentes de protección
Protección, en el contexto del agrupamiento en clústeres del SO de Google Cloud Compute Engine, adopta el formato de STONITH, que proporciona a cada miembro de un clúster de dos nodos la capacidad de reiniciar el otro nodo.
Google Cloud proporciona dos agentes de protección para usar con SAP en sistemas operativos Linux: el agente fence_gce, que se incluye en distribuciones más recientes de Red Hat y SUSE Linux, y el agente heredado gcpstonith, que también puedes descargar para usar con distribuciones de Linux que no incluyen el agente fence_gce.
Permisos de IAM obligatorios para los agentes de protección
Los agentes de protección reinician las VM mediante una llamada de restablecimiento a la API de Compute Engine. Para la autenticación y la autorización a fin de acceder a la API, los agentes de protección usan la cuenta de servicio de la VM. La cuenta de servicio que use un agente de protección debe tener una función que incluya los siguientes permisos:
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
La función predefinida de administrador de instancias de Compute contiene todos los permisos necesarios.
Para limitar el alcance del permiso de reinicio del agente al nodo de destino, puedes configurar el acceso basado en recursos. Para obtener más información, consulta Configura el acceso basado en recursos.
Dirección IP virtual
Los clústeres con alta disponibilidad para SAP en Google Cloud usan una dirección IP (VIP) virtual o flotante para redireccionar el tráfico de red de un host a otro en caso de que se genere una conmutación por error.
Las implementaciones que no suelen ser de nube usan una solicitud injustificada de protocolo de resolución de direcciones (ARP) para anunciar el movimiento y la reasignación de una VIP a una dirección MAC nueva.
En Google Cloud, en lugar de usar solicitudes ARP injustificadas, se usa uno de los varios métodos para mover y reasignar una VIP en un clúster con alta disponibilidad. El método recomendado es usar un balanceador de cargas de TCP/UDP interno, pero, según tus necesidades, también puedes usar una implementación VIP basada en rutas o basada en IP de alias.
Para obtener más información sobre la implementación de VIP en Google Cloud, consulta Implementación de IP virtual en Google Cloud.
Almacenamiento y replicación
Una configuración de clúster con alta disponibilidad de SAP HANA usa la replicación síncrona de su sistema para mantener sincronizadas las bases de datos principales y secundarias de SAP HANA. Los agentes de recursos estándar que proporciona el SO para SAP HANA administran la replicación del sistema durante una conmutación por error. Para hacerlo, inician y detienen la replicación, y cambian las instancias que actúan como instancias activas y las que actúan como instancias en espera durante el proceso de replicación.
Si necesitas almacenamiento de archivos compartido, los archivadores basados en NFS o SMB pueden proporcionar la funcionalidad requerida.
Para una solución de almacenamiento compartido con alta disponibilidad, puedes usar lo siguiente:Filestore o una solución de uso compartido de archivos de terceros, comoCloud Volumes Service para Google Cloud de NetApp. El nivel empresarial de Filestore se puede usar para implementaciones de varias zonas y el nivel Básico para implementaciones de zona única.
Los discos persistentes regionales de Compute Engine ofrecen almacenamiento en bloque replicado de forma síncrona en distintas zonas. Aunque los discos persistentes regionales no son compatibles con el almacenamiento de la base de datos en los sistemas SAP con alta disponibilidad, puedes usarlos con los servidores de archivos NFS.
Para obtener más información sobre las opciones de almacenamiento en Google Cloud:
Opciones de configuración para clústeres de alta disponibilidad alojados en Google Cloud
Google Cloud recomienda cambiar los valores predeterminados de ciertos parámetros de configuración del clúster a valores que sean más adecuados para sistemas SAP en el entorno de Google Cloud. Si usas las secuencias de comandos de automatización que proporciona Google Cloud, los valores recomendados se configuran automáticamente.
Considera los valores recomendados como un punto de partida para ajustar la configuración de Corosync en tu clúster de alta disponibilidad. Debes confirmar que la sensibilidad de la detección de fallas y la activación de conmutación por error sean apropiadas para tus sistemas y cargas de trabajo en el entorno de Google Cloud.
Valores de los parámetros de configuración de Corosync
En las guías de configuración de clústeres de alta disponibilidad para SAP HANA, Google Cloud recomienda valores para numerosos parámetros en la sección totem del archivo de configuración corosync.conf que son distintos de los valores predeterminados establecidos por Corosync o la distribución de Linux.
totem para los que Google Cloud recomienda valores, junto con el impacto de cambiar los valores. Para conocer los valores predeterminados de estos parámetros, que pueden diferir entre distribuciones de Linux, consulta la documentación de tu distribución de Linux.
| Parámetro | Valor recomendado | Impacto del cambio de valor |
|---|---|---|
secauth |
off |
Inhabilita la autenticación y encriptación de todos los mensajes totem |
join |
60 (ms) | Aumenta el tiempo de espera del nodo para recibir mensajes join en el protocolo de membresía. |
max_messages |
20 | Aumenta la cantidad máxima de mensajes que puede enviar el nodo después de recibir el token. |
token |
20000 (ms) |
Aumenta el tiempo de espera del nodo para obtener un token de protocolo
Aumentar el valor del parámetro El valor del parámetro |
consensus |
No disponible | Especifica en milisegundos cuánto tiempo se debe esperar para que se logre el consenso antes de comenzar una nueva ronda de configuración de membresía.
Te recomendamos omitir este parámetro. Cuando no se especifica el parámetro consensus, asegúrate de que el valor sea 24000 o 1.2*token, lo que sea mayor.
|
token_retransmits_before_loss_const |
10 | Aumenta la cantidad de retransmisiones del token que intenta realizar el nodo antes de suponer que ocurrió una falla en el nodo receptor y comenzar a tomar medidas. |
transport |
|
Especifica el mecanismo de transporte que usa corosync. |
Si necesitas más información para configurar el archivo corosync.conf, consulta la guía de configuración de tu distribución de Linux:
- RHEL: Edita la configuración predeterminada de corosync.conf
- SLES: Crea los archivos de configuración de Corosync
Configuración del tiempo de espera y del intervalo para los recursos del clúster
Cuando defines un recurso de clúster, estableces valores interval y timeout, en segundos, para diversas operaciones de recursos (op). Por ejemplo:
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
Los valores timeout afectan cada una de las operaciones de recursos de manera diferente, como se explica en la siguiente tabla.
| Recurso Operation | Acción de tiempo de espera |
|---|---|
monitor |
Si se excede el tiempo de espera, el estado de supervisión suele informar que falló y el recurso asociado se considera en estado de error. El clúster intenta usar opciones de recuperación, que pueden incluir una conmutación por error. El clúster no vuelve a intentar una operación de supervisión con errores. |
start |
Si un recurso no se inicia antes de que se agote el tiempo de espera, el clúster intenta reiniciar el recurso. El comportamiento se determina según la acción en caso de error que se asocia con un recurso. |
stop |
Si un recurso no responde a una operación de detención antes de que se agote el tiempo de espera, se activa un evento de protección. |
Junto con otras opciones de configuración del clúster, interval y timeout afectan la rapidez con la que el software del clúster detecta una falla y activa una conmutación por error.
Los valores timeout y interval que sugiere Google Cloud en las guías de configuración de clústeres para SAP HANA toman en consideración los eventos de mantenimiento de la Migración en vivo de Compute Engine.
Sin importar qué valores de timeout y interval uses, debes evaluar los valores cuando pruebes tu clúster, especialmente durante las pruebas de migración en vivo, ya que la duración de los eventos de migración en vivo puede variar un poco según el tipo de máquina que uses y otros factores, como el uso del sistema.
Configuración de recursos de protección
En las guías de configuración de clústeres de alta disponibilidad para SAP HANA, Google Cloud recomienda varios parámetros mientras configura los recursos de protección del clúster de alta disponibilidad. Los valores recomendados son diferentes de los valores predeterminados que establece Corosync o tu distribuidor de Linux.
En la siguiente tabla, se muestran los parámetros de protección que recomienda Google Cloud junto con los valores recomendados y los detalles de los parámetros. Para conocer los valores predeterminados de los parámetros, que pueden diferir entre distribuciones de Linux, consulta la documentación de tu distribución de Linux.
| Parámetro | Valor recomendado | Detalles |
|---|---|---|
pcmk_reboot_timeout |
300 (segundos) | Especifica el valor del tiempo de espera para usar en las acciones de reinicio.
El valor de
|
pcmk_monitor_retries |
4 | Especifica la cantidad máxima de veces que se puede reintentar el comando monitor dentro del tiempo de espera. |
pcmk_delay_max |
30 (segundos) | Especifica un retraso aleatorio para las acciones de protección para evitar que los nodos del clúster se protejan entre sí al mismo tiempo. Para evitar una carrera de protección, ya que garantiza que solo a una instancia se le asigne un retraso aleatorio, este parámetro solo se debe habilitar en uno de los recursos de protección en un clúster de dos nodos de alta disponibilidad de HANA (escalamiento vertical). En un clúster de alta disponibilidad de HANA de escalamiento horizontal, este parámetro debe estar habilitado en todos los nodos que forman parte de un sitio (ya sea primario o secundario). |
Prueba tu clúster de alta disponibilidad en Google Cloud
Después de configurar el clúster e implementar en el entorno de prueba tanto el clúster como los sistemas de SAP HANA, debes probar el clúster para confirmar que el sistema de alta disponibilidad esté configurado correctamente y funcione como se espera.
Para confirmar que la conmutación por error funciona como se espera, simula varias situaciones de falla con las siguientes acciones:
- Apaga la VM.
- Genera un kernel panic.
- Cierra la aplicación.
- Interrumpe la red entre las instancias.
Además, simula un evento de migración en vivo de Compute Engine en el host principal para confirmar que no se activa una conmutación por error. Puedes simular un evento de mantenimiento con el comando gcloud compute instances
simulate-maintenance-event de Google Cloud CLI.
Registro y supervisión
Los agentes de recursos pueden incluir capacidades de registro que propagan registros a Google Cloud Observability para el análisis. Cada agente de recursos incluye información de configuración que identifica cualquier opción de registro. En el caso de las implementaciones de Bash, la opción de registro es gcloud logging.
También puedes instalar el agente de Cloud Logging para capturar resultados de registro a partir de procesos del sistema operativo y correlacionar el uso de recursos con eventos del sistema. El agente de Logging captura los registros del sistema predeterminados, que incluyen los datos de registro de Pacemaker y los servicios de agrupamiento en clústeres. Para obtener más información, consulta Acerca del agente de Logging.
Si deseas obtener información sobre el uso de Cloud Monitoring para configurar las verificaciones de servicio que supervisan la disponibilidad de los extremos del servicio, consulta Administra las verificaciones de tiempo de actividad.
Cuentas de servicio y clústeres con alta disponibilidad
Las acciones que el software del clúster puede realizar en el entorno de Google Cloud están protegidas por los permisos otorgados a la cuenta de servicio de cada VM del host. Para entornos de alta seguridad, puedes limitar los permisos en las cuentas de servicio de las VM del host a fin de cumplir con el principio de privilegio mínimo.
Cuando limites los permisos de una cuenta de servicio, ten en cuenta que tu sistema puede interactuar con los servicios de Google Cloud, como Cloud Storage, por lo que es posible que debas incluir permisos para esas interacciones de servicio en la cuenta de servicio de la VM del host.
Para los permisos más restrictivos, crea una función personalizada con los permisos mínimos necesarios. Para obtener información sobre las funciones personalizadas, consulta Crea y administra funciones personalizadas. Puedes restringir aún más los permisos si los limitas a solo instancias específicas de un recurso, como las instancias de VM en el clúster con alta disponibilidad, si agregas condiciones en las vinculaciones de la función de la política de IAM de un recurso.
Los permisos mínimos que tus sistemas necesitan dependen de los recursos de Google Cloud a los que acceden tus sistemas y de las acciones que realizan. En consecuencia, determinar los permisos mínimos requeridos para las VM del host en el clúster con alta disponibilidad puede requerir que investigues con exactitud qué recursos acceden a los sistemas en la VM del host y las acciones que esos sistemas realizan con esos recursos.
Como punto de partida, en la siguiente lista se muestran algunos recursos del clúster con alta disponibilidad y los permisos asociados que requieren:
- Protección
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- VIP implementada mediante un alias de IP
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- VIP implementada mediante rutas estáticas
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- VIP implementada mediante un balanceador de cargas interno
- No se requieren permisos específicos: el balanceador de cargas opera en las condiciones de la verificación de estado que no requieren que el clúster interactúe con recursos ni los cambie en Google Cloud.
Implementación de IP virtual en Google Cloud
Un clúster con alta disponibilidad usa una dirección IP (VIP) virtual o flotante para mover su carga de trabajo de un nodo del clúster a otro en caso de que se genere una falla inesperada o si se realiza mantenimiento programado. La dirección IP de la VIP no cambia, por lo que las aplicaciones cliente no saben que el trabajo se entrega mediante un nodo diferente.
Las VIP también se conocen como direcciones IP flotantes.
En Google Cloud, las VIP se implementan de una manera un poco diferente que en las instalaciones locales, ya que cuando se produce una conmutación por error, no se pueden usar las solicitudes ARP injustificadas para anunciar el cambio. En cambio, puedes implementar una dirección VIP para un clúster de SAP con alta disponibilidad mediante uno de los siguientes métodos:
- Compatibilidad con la conmutación por error del Balanceador de cargas de red de transferencia interno (recomendado)
- Rutas estáticas de Google Cloud
- Direcciones IP de alias de Google Cloud
Implementaciones de VIP del balanceador de cargas de red de transferencia interno
Por lo general, un balanceador de cargas distribuye el tráfico del usuario entre varias instancias de las aplicaciones a fin de distribuir la carga de trabajo entre varios sistemas activos y ofrecer protección frente a una demora en el procesamiento o una falla en cualquier instancia.
El balanceador de cargas de red de transferencia interno también proporciona asistencia de conmutación por error que puedes usar con las verificaciones de estado de Compute Engine para detectar fallas, activar la conmutación por error y redirigir el tráfico a un nuevo sistema SAP principal en un clúster con alta disponibilidad nativo del SO.
La asistencia de conmutación por error es la implementación de VIP recomendada por diversos motivos, incluidos los siguientes:
- El balanceo de cargas en Compute Engine ofrece un ANS del 99.99% de disponibilidad.
- El balanceo de cargas admite clústeres con alta disponibilidad en varias zonas, que protegen contra fallas de la zona con tiempos de conmutación por error entre zonas predecibles.
- El uso del balanceo de cargas reduce el tiempo necesario para detectar y activar una conmutación por error, que suele ser unos segundos después de la falla. Los tiempos de la conmutación por error promedio dependen de los tiempos de la conmutación por error de cada componente del sistema con alta disponibilidad, que puede incluir hosts, sistemas de base de datos, sistemas de aplicaciones y más.
- Usar el balanceo de cargas simplifica la configuración del clúster y reduce las dependencias.
- A diferencia de una implementación de VIP en la que se usan rutas, con los balanceos de cargas, puedes usar rangos de IP de tu propia red de VPC, lo que te permite reservarlos y configurarlos según sea necesario.
- El balanceo de cargas se puede usar con facilidad para redirigir el tráfico a un sistema secundario en caso de que se generen interrupciones por mantenimiento planificadas.
Cuando creas una verificación de estado para una implementación del balanceador de cargas de una VIP, debes especificar el puerto del host que la verificación de estado prueba para determinar el estado del host. Para un clúster de SAP con alta disponibilidad, especifica un puerto de host de destino que esté en el rango privado 49152-65535 para evitar conflictos con otros servicios. En la VM del host, configura el puerto de destino con un servicio de asistencia secundario, como la utilidad socat o HAProxy.
Para los clústeres de bases de datos en los que el sistema en espera secundario permanece en línea, la verificación de estado y el servicio de asistencia permiten que el balanceo de cargas dirija el tráfico al sistema en línea que en ese momento funciona como sistema principal en el clúster.
Mediante el servicio de asistencia y la redirección de puertos, puedes activar una conmutación por error para el mantenimiento de software planificado en tus sistemas SAP.
Para obtener más información sobre la compatibilidad con la conmutación por error, consulta Configura la conmutación por error para balanceadores de cargas de red de transferencia internos.
Para implementar un clúster con alta disponibilidad mediante la implementación de la VIP del balanceador de cargas, consulta:
- Terraform: Guía de configuración de clústeres de alta disponibilidad de SAP HANA
- Guía de configuración del clúster de HA para SAP HANA en RHEL
- Guía de configuración de clústeres de alta disponibilidad para SAP HANA en SLES
Implementaciones de VIP de la ruta estática
La implementación de la ruta estática también proporciona protección contra fallas zonales, pero requiere que uses una VIP por fuera de los rangos de IP de tus subredes de VPC existentes en las que residen las VM. Por lo tanto, también debes asegurarte de que la VIP no entre en conflicto con ninguna dirección IP externa en tu red ampliada.
Las implementaciones de rutas estáticas también pueden generar cierta complejidad cuando se usan con configuraciones de VPC compartidas, que están destinadas a segregar la configuración de red a un proyecto host.
Si usas una implementación de ruta estática para la VIP, consulta con tu administrador de red a fin de definir una dirección IP adecuada para una implementación de ruta estática.
Implementaciones de VIP de IP de alias
Estas no se recomiendan para implementaciones con alta disponibilidad multizonal porque, si una zona falla, la reasignación de la IP de alias para un nodo en una zona diferente se puede demorar. En cambio, puedes implementar la VIP con un balanceador de cargas de red de transferencia interno compatible con la conmutación por error.
Si implementas todos los nodos del clúster con alta disponibilidad de SAP en la misma zona, puedes usar una IP de alias a fin de implementar una VIP para el clúster con alta disponibilidad.
Si tienes clústeres de SAP con alta disponibilidad de múltiples zonas existentes que usan una implementación de IP de alias para la VIP, puedes migrar a una implementación de balanceador de cargas de red de transferencia interno sin cambiar tu dirección VIP. Los alias de direcciones IP y los balanceadores de cargas de red de transferencia interno usan rangos de IP de tu red de VPC.
Si bien las direcciones IP de alias no se recomiendan para implementaciones VIP en clústeres con alta disponibilidad multizonales, tienen otros casos de uso en implementaciones de SAP. Por ejemplo, se pueden usar a fin de proporcionar un nombre de host lógico y asignaciones de IP para implementaciones flexibles de SAP, como las que administra SAP Landscape Management.
Prácticas recomendadas generales para las VIP en Google Cloud
A fin de obtener más información sobre las VIP en Google Cloud, consulta Prácticas recomendadas para las direcciones IP flotantes.
Conmutación por error automática del host de SAP HANA en Google Cloud
Google Cloud es compatible con la conmutación por error automática del host de SAP HANA, la solución local de recuperación de fallas que proporciona SAP HANA. La solución de conmutación por error automática del host usa uno o más hosts de reserva que se mantienen en reserva para tomar el trabajo del host principal o de trabajador en caso de que el host falle. Los hosts de reserva no contienen datos ni procesan ningún trabajo.
Una vez que se completa una conmutación por error, el host con errores se reinicia como un host de reserva.
SAP admite hasta tres hosts de reserva en sistemas de escalamiento horizontal en Google Cloud. Los hosts de reserva no cuentan para el máximo de 16 hosts activos que SAP admite en sistemas de escalamiento horizontal en Google Cloud.
Para obtener más información de SAP sobre la solución de conmutación por error automática del host, consulta Conmutación por error automática del host.
Cuándo usar la conmutación por error automática del host de SAP HANA en Google Cloud
La conmutación por error automática del host de SAP HANA protege contra las fallas que afectan un solo nodo en un sistema de escalamiento horizontal de SAP HANA, incluidas las fallas de los siguientes:
- La instancia de SAP HANA
- El sistema operativo del host
- La VM del host
Con respecto a las fallas de la VM del host, en Google Cloud, el reinicio automático, que suele restablecer la VM del host de SAP HANA más rápido que la conmutación por error automática del host, y la migración en vivo protegen contra interrupciones planificadas y no planificadas de la VM. Por lo tanto, para la protección de la VM, no se necesita la solución de conmutación por error automática del host de SAP HANA.
La conmutación por error automática del host de SAP HANA no protege contra fallas zonales porque todos los nodos de un sistema de escalamiento horizontal de SAP HANA se implementan en una sola zona.
La conmutación por error automática del host de SAP HANA no precarga los datos de SAP HANA en la memoria de los nodos en espera, por lo que, cuando se ejecuta un nodo en espera, el tiempo de recuperación de un nodo general se determina principalmente por el tiempo que lleva cargar los datos en la memoria del nodo en espera.
Considera usar la conmutación por error automática del host de SAP HANA para los siguientes casos:
- Fallas en el software o sistema operativo del host de un nodo de SAP HANA que Google Cloud no puede detectar.
- Migraciones lift-and-shift, en las que necesitas reproducir tu configuración local de SAP HANA hasta que puedas optimizar SAP HANA para Google Cloud.
- Cuando una configuración de alta disponibilidad completamente replicada y multizona es costosa y tu empresa puede tolerar lo siguiente:
- Un tiempo de recuperación de nodo más largo debido a la necesidad de cargar datos de SAP HANA en la memoria de un nodo en espera.
- El riesgo de que se produzcan fallas zonales.
El administrador de almacenamiento de SAP HANA
Los volúmenes /hana/data y /hana/log se activan solo en los hosts principales y de trabajador. Cuando se produce una toma de control, la solución de conmutación por error automática del host usa la API de Storage Connector de SAP HANA y el administrador de almacenamiento de Google Cloud para los nodos en espera de SAP HANA a fin de mover las activaciones de volumen del host con errores al host de reserva.
En Google Cloud, el administrador de almacenamiento de SAP HANA es necesario para los sistemas SAP HANA que usan la conmutación por error automática del host de SAP HANA.
Versiones compatibles del administrador de almacenamiento para SAP HANA
Se admiten las versiones 2.0 y posteriores del administrador de almacenamiento de SAP HANA. Todas las versiones anteriores a la 2.0 están obsoletas y no son compatibles. Si usas una versión anterior, actualiza el sistema SAP HANA a fin de usar la última versión del administrador de almacenamiento para SAP HANA. Consulta Actualiza el administrador de almacenamiento para SAP HANA.
Para determinar si tu versión es obsoleta, abre el archivo gceStorageClient.py.
El directorio de la instalación predeterminado es /hana/shared/gceStorageClient.
A partir de la versión 2.0, el número de versión aparece en los comentarios de la parte superior del archivo gceStorageClient.py, como se muestra en el siguiente ejemplo. Si falta el número de versión, estás viendo una versión obsoleta del administrador de almacenamiento para SAP HANA.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Instala el administrador de almacenamiento para SAP HANA
El método recomendado a fin de instalar el administrador de almacenamiento para SAP HANA es usar un método de implementación automatizado a fin de implementar un sistema SAP HANA de escalamiento horizontal que incluya el administrador de almacenamiento más reciente para SAP HANA.
Si necesitas agregar la conmutación por error automática del host de SAP HANA a un sistema de escalamiento horizontal de SAP HANA existente en Google Cloud, el enfoque recomendado es similar: usa la plantilla de Deployment Manager que proporciona Google Cloud para implementar un nuevo sistema de escalamiento horizontal de SAP HANA y, luego, cargar los datos en el sistema nuevo desde el sistema existente. Para cargar los datos, puedes usar procedimientos de copia de seguridad y restablecimiento estándar de SAP HANA, o la replicación del sistema SAP HANA, que puede reducir el tiempo de inactividad. Para obtener más información sobre la replicación del sistema, consulta Nota 2473002 de SAP: Uso de la replicación del sistema HANA para migrar el sistema de escalamiento horizontal..
Si no puedes usar un método de implementación automatizado, considera comunicarte con un asesor de soluciones de SAP, como el que se puede encontrar a través de los servicios de asesoría de Google Cloud, para obtener ayuda sobre cómo instalar de forma manual el administrador de almacenamiento para SAP HANA.
Por el momento, no se documenta la instalación manual del administrador de almacenamiento de SAP HANA en un sistema SAP HANA de escalabilidad nueva o existente.
Si deseas obtener más información sobre las opciones de implementación automatizadas para la conmutación por error automática del host de SAP HANA, consulta Implementación automatizada de sistemas de escalamiento horizontal de SAP HANA con conmutación por error automática del host de SAP HANA.
Actualiza el administrador de almacenamiento de SAP HANA
Actualiza el administrador de almacenamiento para SAP HANA; para ello, descarga primero el paquete de instalación y, luego, ejecuta una secuencia de comandos de instalación, que actualiza el administrador de almacenamiento para el archivo ejecutable de SAP HANA en la unidad /shared de SAP HANA.
El siguiente procedimiento es solo para la versión 2 del administrador de almacenamiento de SAP HANA. Si usas una versión del administrador de almacenamiento de SAP HANA que se descargó antes del 1 de febrero de 2021, instala la versión 2 antes de intentar actualizar el administrador de almacenamiento de SAP HANA.
Para actualizar el administrador de almacenamiento de SAP HANA, sigue estos pasos:
Verifica la versión de tu administrador de almacenamiento actual para SAP HANA:
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
Si existe, instala la actualización:
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
El administrador de almacenamiento actualizado para SAP HANA se instala en
/usr/sap/google-sapgcestorageclient/gceStorageClient.py.Reemplaza el
gceStorageClient.pyexistente por el archivogceStorageClient.pyactualizado:Si tu archivo
gceStorageClient.pyexistente se encuentra en/hana/shared/gceStorageClient, la ubicación de instalación predeterminada, usa la secuencia de comandos de instalación para actualizar el archivo:sudo /usr/sap/google-sapgcestorageclient/install.sh
Si tu archivo
gceStorageClient.pyexistente no está en/hana/shared/gceStorageClient, copia el archivo actualizado en la misma ubicación que tu archivo existente y reemplázalo.
Parámetros de configuración en el archivo global.ini
Ciertos parámetros de configuración para el administrador de almacenamiento de SAP HANA, incluso si la protección está habilitada o inhabilitada, se almacenan en la sección de almacenamiento del archivo global.ini de SAP HANA. Cuando usas el archivo de configuración de Terraform o la plantilla de Deployment Manager que proporciona Google Cloud para implementar un sistema SAP HANA con la función de conmutación por error automática del host, el proceso de implementación agrega los parámetros de configuración al archivo global.ini por ti.
En el siguiente ejemplo, se muestra el contenido de un global.ini que se crea para el administrador de almacenamiento de SAP HANA:
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Acceso sudo para el administrador de almacenamiento de SAP HANA
Para administrar los servicios y el almacenamiento de SAP HANA, el administrador de almacenamiento de SAP HANA usa la cuenta de usuario SID_LCadm y requiere acceso sudo a ciertos objetos binarios del sistema.
Si usas las secuencias de comandos de automatización que proporciona Google Cloud para implementar SAP HANA con conmutación por error automática del host, el acceso sudo necesario se configura por ti.
Si instalas el administrador de almacenamiento para SAP HANA de forma manual, usa el comando visudo a fin de editar el archivo /etc/sudoers y, así otorgar a la cuenta de usuario SID_LCadm acceso sudo a los siguientes objetos binarios requeridos.
Haz clic en la pestaña de tu sistema operativo:
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
En el siguiente ejemplo, se muestra una entrada en el archivo /etc/sudoers. En el ejemplo, el ID del sistema para el sistema SAP HANA asociado se reemplaza por SID_LC. La entrada de ejemplo la creo la plantilla de Deployment Manager que proporcionó la entrada de ejemplo lo proporcionó Google Cloud para el escalamiento horizontal de SAP HANA con conmutación por error automática del host.
La entrada que crea la plantilla de Deployment Manager incluye objetos binarios que ya no son necesarios, pero que se conservan para la retrocompatibilidad. Solo debes incluir los objetos binarios que aparecen en la lista anterior.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Almacenamiento NFS para conmutación por error automática del host de SAP HANA
Un sistema de escalamiento horizontal de SAP HANA con conmutación por error automática del host requiere una solución NFS, como Filestore, para compartir los volúmenes /hana/shared y /hanabackup entre todos los hosts. Debes configurar la solución NFS por tu cuenta.
Cuando usas un método de implementación automatizado, proporcionas información sobre el servidor NFS en el archivo de implementación para activar los directorios NFS durante la implementación.
El volumen de NFS que uses debe estar vacío. Cualquier archivo existente puede entrar en conflicto con el proceso de implementación, especialmente si los archivos o las carpetas hacen referencia al ID del sistema SAP (SID). El proceso de implementación no puede determinar si los archivos se pueden reemplazar.
El proceso de implementación almacena los volúmenes /hana/shared y /hanabackup en el servidor NFS y activa el servidor NFS en todos los hosts, incluidos los hosts de reserva. Luego, el host principal administra el servidor NFS.
Si implementas una solución de copia de seguridad, como el agente de Backint de Cloud Storage para SAP HANA, puedes quitar el volumen /hanabackup del servidor NFS después de que se complete la implementación.
Si deseas obtener más información sobre las soluciones de archivos compartidos disponibles que están disponibles en Google Cloud, consulta Soluciones de uso compartido de archivos para SAP en Google Cloud.
Compatibilidad con el sistema operativo
Google Cloud admite la conmutación por error automática del host de SAP HANA solo en los siguientes sistemas operativos:
- RHEL para SAP 7.7 o posterior
- RHEL para SAP 8.1 o posterior
- RHEL para SAP 9.0 o posterior
-
Antes de instalar cualquier software de SAP en RHEL para SAP 9.x, se deben instalar paquetes adicionales en tus máquinas anfitrión, en especial
chkconfigycompat-openssl11. Si usas una imagen proporcionada por Compute Engine, estos paquetes se instalarán de forma automática. Para obtener más información de SAP, consulta la Nota 3108316 de SAP: Red Hat Enterprise Linux 9.x: Instalación y configuración.
-
Antes de instalar cualquier software de SAP en RHEL para SAP 9.x, se deben instalar paquetes adicionales en tus máquinas anfitrión, en especial
- SLES para SAP 12 SP5
- SLES para SAP 15 SP1 o posterior
Para ver las imágenes públicas disponibles en Compute Engine, consulta Imágenes.
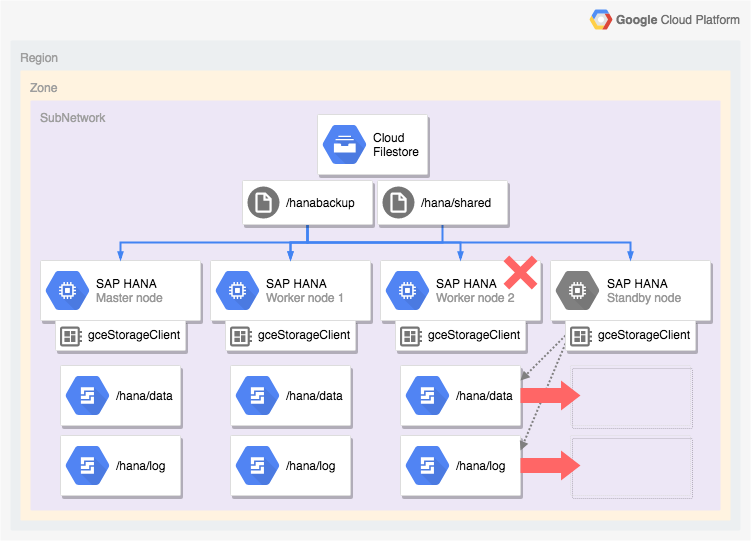
Arquitectura de un sistema SAP HANA con conmutación por error automática del host
En el siguiente diagrama, se muestra una arquitectura de escalamiento horizontal en Google Cloud que incluye la característica de conmutación por error automática del host de SAP HANA. En el diagrama, el administrador de almacenamiento para SAP HANA se representa con el nombre de su ejecutable, gceStorageClient.
En el diagrama, se muestra que el nodo trabajador 2 falla y el nodo de reserva toma el control.
El administrador de almacenamiento para SAP HANA funciona con la API de Storage Connector de SAP (no mostrado) para desconectar los discos que contienen los volúmenes /hana/data y /hana/logs del nodo trabajador con errores y volver a activarlos en el nodo de reserva, que luego se convierte en el nodo trabajador 2 mientras que el nodo con errores se convierte en el nodo de reserva.
Opciones de implementación automatizada para configuraciones con alta disponibilidad de SAP HANA
Google Cloud proporciona archivos de implementación que puedes usar para automatizar la implementación de sistemas SAP HANA con alta disponibilidad o puedes implementar y configurar tus sistemas de SAP HANA con alta disponibilidad de forma manual.
Para la implementación automatizada de sistemas con alta disponibilidad de SAP HANA, puedes usar Terraform o Deployment Manager.
Google Cloud proporciona archivos de configuración de Terraform específicos de la implementación que debes completar. Usa los comandos estándar de Terraform a fin de inicializar tu directorio de trabajo actual y descargar los archivos del módulo y el complemento del proveedor de Terraform para Google Cloud, y aplica la configuración a fin de implementar un sistema SAP HANA.
Las plantillas de Deployment Manager que proporciona Google Cloud incluyen un archivo de configuración template.yaml que debes completar. Deployment Manager lee el archivo de configuración y, luego, implementa un sistema SAP HANA.
Estos métodos de implementación automatizada implementan un sistema SAP HANA que es completamente compatible con SAP y que cumple las prácticas recomendadas de SAP y Google Cloud.
Implementación automatizada de los clústeres con alta disponibilidad de Linux para SAP HANA
Para SAP HANA, los métodos de implementación automatizada implementan un clúster de Linux de alta disponibilidad optimizado para el rendimiento que incluye las siguientes funciones:
- Conmutación por error automática
- Reinicio automático
- Una reserva de la dirección IP virtual (VIP) que especificas
- Compatibilidad con la conmutación por error proporcionada por el balanceo de cargas TCP/UDP interno, que administra el enrutamiento desde la dirección IP virtual (VIP) a los nodos del clúster de alta disponibilidad
- Una regla de firewall que permita que las verificaciones de estado de Compute Engine supervisen las instancias de VM del clúster
- El administrador de recursos del clúster de alta disponibilidad de Pacemaker
- Un mecanismo de protección de Google Cloud
- Una VM con los discos persistentes necesarios para cada instancia de SAP HANA
- Instancias de SAP HANA configuradas para la replicación síncrona y la carga previa de la memoria
Puedes usar uno de los siguientes métodos de implementación a fin de implementar un clúster de alta disponibilidad para SAP HANA:
Si deseas usar Terraform a fin de automatizar la implementación de un clúster de alta disponibilidad para SAP HANA, consulta los siguientes vínculos:
Si deseas usar Deployment Manager a fin de automatizar la implementación de un clúster de alta disponibilidad para SAP HANA, consulta la Guía de configuración de clústeres de alta disponibilidad de escalamiento vertical de SAP HANA.
Implementación automatizada de sistemas de escalamiento horizontal de SAP HANA con conmutación por error automática del host de SAP HANA
Puedes usar uno de los siguientes métodos de implementación para implementar sistemas de escalamiento horizontal de SAP HANA con conmutación por error automática del host:
Si deseas usar Terraform para automatizar la implementación de un sistema de escalamiento horizontal con hosts en espera, consulta Terraform: guía de implementación del sistema de escalamiento horizontal de SAP HANA con conmutación por error automática de host.
Para usar Deployment Manager a fin de automatizar la implementación de un sistema de escalamiento horizontal con hosts en espera, consulta Sistema de escalamiento horizontal de SAP HANA con guía de implementación de conmutación por error automática de host.
Para un sistema de escalamiento horizontal de SAP HANA que incluye la función de conmutación por error automática de host de SAP HANA, el método de implementación automatizada implementa lo siguiente:
- Una instancia principal de SAP HANA
- Entre 1 y 15 hosts trabajadores
- Entre 1 y 3 hosts de reserva
- Una VM para cada host de SAP HANA
- Discos persistentes para los hosts principales y trabajadores
- El administrador de almacenamiento de Google Cloud para nodos en espera de SAP HANA
Un sistema de escalamiento horizontal de SAP HANA con conmutación por error automática del host requiere una solución NFS, como Filestore, para compartir los volúmenes /hana/shared y /hanabackup entre todos los hosts. Para que Terraform o Deployment Manager pueda activar los directorios NFS durante la implementación, debes configurar la solución NFS tú mismo antes de implementar el sistema SAP HANA.
Puedes configurar las instancias del servidor NFS de Filestore con rapidez y facilidad si sigues las instrucciones en Crea instancias.
Opción activa/activa (lectura habilitada) para SAP HANA
A partir de SAP HANA 2.0 SPS1, SAP proporciona la configuración Activa/Activa (lectura habilitada) para situaciones de replicación del sistema SAP HANA. En un sistema de replicación que está configurado para Active/Active (Read Enabled), los puertos SQL en el sistema secundario están abiertos para el acceso de lectura. Esto te permite usar el sistema secundario para tareas de lectura intrínseca y tener un mejor equilibrio de cargas de trabajo en los recursos de procesamiento, lo que mejora el rendimiento general de tu base de datos de SAP HANA. Para obtener más información sobre la función activa/activa (habilitada para lectura), consulta la Guía de administración de SAP HANA específica para tu versión de SAP HANA y la Nota de SAP 1999880.
Para configurar una replicación del sistema que habilite el acceso de lectura en tu sistema secundario, debes usar el modo de operación logreplay_readaccess. Sin embargo, para usar este modo de operación, los sistemas principales y secundarios deben ejecutar la misma versión de SAP HANA. En consecuencia, el acceso de solo lectura al sistema secundario no es posible durante una actualización progresiva hasta que ambos sistemas ejecuten la misma versión de SAP HANA.
Para conectarse a un sistema secundario de Active/Active (read enabled), SAP admite las siguientes opciones:
- Conectarse directamente abriendo una conexión explícita con el sistema secundario.
- Conectarse de forma indirecta mediante la ejecución de una instrucción de SQL en el sistema principal con una sugerencia, que durante la evaluación redirige la consulta al sistema secundario.
En el siguiente diagrama, se muestra la primera opción, en la que las aplicaciones acceden al sistema secundario directamente en un clúster de Pacemaker implementado en Google Cloud. Se usa una dirección IP flotante o VIP adicional (VIP) para orientar la instancia de VM que funciona como el sistema secundario como parte del clúster de Pacemaker de SAP HANA. La VIP sigue el sistema secundario y puede mover su carga de trabajo de lectura de un nodo del clúster a otro en caso de que se genere una falla inesperada o si se realiza mantenimiento programado. Para obtener información sobre los métodos disponibles de implementación de VIP, consulta Implementación de IP virtual en Google Cloud.

Si deseas obtener instrucciones para configurar la replicación del sistema SAP HANA con activo/activo (lectura habilitada), en un clúster de Pacemaker:
- Configura HANA activo/activo (lectura habilitada) en un clúster de SUSE Pamaker
- Configura HANA activo/activo (lectura habilitada) en un clúster de Red Hat Pamaker
¿Qué sigue?
Google Cloud y SAP proporcionan más información sobre la alta disponibilidad.
Más información de Google Cloud sobre la alta disponibilidad
Para obtener más información sobre la alta disponibilidad de SAP HANA en Google Cloud, consulta la guía de operaciones de SAP HANA.
Para obtener información general sobre la protección de sistemas en Google Cloud contra diversas situaciones de falla, consulta Diseña sistemas sólidos.
Más información de SAP sobre sus funciones de alta disponibilidad
Para obtener más información de SAP acerca de las funciones de alta disponibilidad de SAP HANA, consulta los siguientes vínculos:
- Alta disponibilidad para SAP HANA
- Nota de SAP 2057595: Preguntas frecuentes: Alta disponibilidad de SAP HANA
- Cómo realizar la replicación del sistema para SAP HANA 2.0
- Network Recommendations for SAP HANA System Replication (Recomendaciones de redes para la replicación del sistema de SAP HANA)