En estas instrucciones, se muestra cómo configurar una solución para replicar datos de aplicaciones SAP, como SAP S/4HANA o SAP Business Suite, a BigQuery mediante SAP Landscape Transformation (LT) Replication Server y SAP Data Services (DS).
Puedes usar la replicación de datos para realizar copias de seguridad de tus datos de SAP en tiempo real o consolidar los datos de tus sistemas SAP con los datos de consumidor de otros sistemas en BigQuery a fin de obtener estadísticas de aprendizaje automático y análisis de datos a escala de petabytes.
Las instrucciones están destinadas a los administradores de sistemas SAP que tienen experiencia básica con la configuración de SAP Basis, SAP LT Replication Server, SAP DS y Google Cloud.
Arquitectura

SAP LT Replication Server puede actuar como proveedor de datos para el framework de aprovisionamiento de datos operativos (ODP) de SAP NetWeaver. SAP LT Replication Server recibe datos de sistemas SAP conectados y los almacena en el framework de ODP en una cola delta operativa (ODQ) del sistema SAP LT Replication Server. Por lo tanto, SAP LT Replication Server también actúa como destino de la configuración de SAP LT Replication Server. El framework de ODP hace que los datos estén disponibles como objetos de ODP que corresponden a las tablas del sistema de origen.
El framework de ODP admite situaciones de extracción y replicación para varias aplicaciones SAP de destino, conocidas como suscriptores. Los suscriptores recuperan los datos de la cola delta para su posterior procesamiento.
Los datos se replican en cuanto un suscriptor solicita datos de una fuente de datos a través de un contexto de ODP. Varios suscriptores pueden usar la misma ODQ como fuente.
SAP LT Replication Server aprovecha la compatibilidad con la captura de datos modificados (CDC) de SAP Data Services 4.2 SP1 o posterior, que incluye aprovisionamiento de datos en tiempo real y capacidades delta para todas las tablas de origen.
En el siguiente diagrama, se explica el flujo de datos a través de los sistemas:
- Las aplicaciones SAP actualizan los datos en el sistema de origen.
- SAP LT Replication Server replica los cambios de datos y los almacena en la cola delta operativa.
- SAP DS es un suscriptor de la cola delta operativa y, de forma periódica, consulta la cola para detectar cambios en los datos.
- SAP DS recupera los datos de la cola delta, los transforma para que sean compatibles con el formato de BigQuery y, luego, inicia el trabajo de carga que mueve los datos a BigQuery.
- Los datos están disponibles en BigQuery para su análisis.
En esta situación, el sistema de origen SAP, SAP LT Replication Server y SAP Data Services pueden ejecutarse dentro o fuera de Google Cloud. Para obtener más información de SAP, consulta Aprovisionamiento de datos operativos en tiempo real con SAP Landscape Transformation Replication Server.a

Componentes principales de la solución
Los siguientes componentes son necesarios para replicar los datos de las aplicaciones SAP a BigQuery mediante SAP Landscape Transformation Replication Server y SAP Data Services:
| Componente | Versiones requeridas | Notas |
|---|---|---|
| Pila del servidor de la aplicación SAP | Cualquier sistema SAP basado en ABAP a partir de R/3 4.6C SAP_Basis (requisito mínimo):
|
En esta guía, el servidor de aplicaciones y el servidor de la base de datos se denominan de forma colectiva sistema de origen, incluso si se ejecutan en máquinas diferentes. Define un usuario de RFC con la autorización adecuada. Opcional: Define un espacio de tabla diferente para las tablas de registro. |
| Sistema de base de datos (DB) | Cualquier versión de DB que aparezca como admitida en la matriz de la disponibilidad del producto (PAM) de SAP, sujeta a cualquier restricción de la pila de SAP NetWeaver que aparezca en la PAM. Consulta service.sap.com/pam. | |
| Sistema operativo (SO) | Cualquier versión de SO que aparezca como admitida en la PAM de SAP, sujeta a cualquier restricción de la pila de SAP NetWeaver que aparezca en la PAM. Consulta service.sap.com/pam. | |
| SAP Data Migration Server (DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 o posterior | Requiere una conexión RFC al sistema de origen. El tamaño del sistema SAP LT Replication Server depende en gran medida de la cantidad de datos que se almacenan en la ODQ y de los períodos de retención planificados. |
| SAP Data Services | SAP Data Services 4.2 SP1 o superior | |
| BigQuery | No disponible |
Costos
BigQuery es un componente facturable de Google Cloud.
Usa la calculadora de precios para generar una estimación de los costos según el uso previsto.
Requisitos
En estas instrucciones, se da por sentado que el servidor de aplicaciones SAP, el servidor de base de datos, SAP LT Replication Server y SAP Data Services ya están instalados y configurados para un funcionamiento normal.
Para poder usar BigQuery, necesitas un proyecto de Google Cloud.
Configura un proyecto de Google Cloud en Google Cloud
Debes habilitar la API de BigQuery y, si aún no creaste un proyecto de Google Cloud, debes hacerlo.
Crea un proyecto de Google Cloud
Ve a la consola de Google Cloud y regístrate siguiendo el asistente de configuración.
Junto al logotipo de Google Cloud en la esquina superior izquierda, haz clic en el menú desplegable y selecciona Crear proyecto.
Asigna un nombre al proyecto y haz clic en Crear.
Después de crear el proyecto (se muestra una notificación en la esquina superior derecha), actualiza la página.
Habilita las API
Habilita la API de BigQuery:
Cree una cuenta de servicio
Se usa la cuenta de servicio (en particular, su archivo de claves) para autenticar SAP DS en BigQuery. Usarás el archivo de claves más adelante cuando crees el almacén de datos de destino.
En la consola de Google Cloud, ve a la página Cuentas de servicio.
Selecciona tu proyecto de Google Cloud.
Haz clic en Crear cuenta de servicio.
Ingresa un nombre de cuenta de servicio.
Haz clic en Crear y continuar.
En la lista Seleccionar un rol, selecciona BigQuery > BigQuery Data Editor.
Haz clic en Agregar otra función.
En la lista Seleccionar un rol , selecciona BigQuery > BigQuery Job User.
Haga clic en Continuar.
Según corresponda, otorga otro acceso a los usuarios a la cuenta de servicio.
Haga clic en Listo.
En la página Cuentas de servicio de la consola de Google Cloud, haz clic en la dirección de correo electrónico de la cuenta de servicio que acabas de crear.
En el nombre de la cuenta de servicio, haz clic en la pestaña Claves.
Haz clic en el menú desplegable Agregar clave y, luego, selecciona Crear clave nueva.
Asegúrate de que esté especificado el tipo de clave JSON.
Haga clic en Crear.
Guarda el archivo de claves que se descarga automáticamente en una ubicación segura.
Configura la replicación entre las aplicaciones de SAP y BigQuery
La configuración de esta solución incluye los siguientes pasos de alto nivel:
- Configurar SAP LT Replication Server
- Configurar SAP Data Services
- Crear el flujo de datos entre SAP Data Services y BigQuery
Configuración de SAP Landscape Transformation Replication Server
Los siguientes pasos permiten configurar SAP LT Replication Server para que actúe como proveedor dentro del framework de aprovisionamiento de datos operativos y crear una cola delta operativa. En esta configuración, SAP LT Replication Server usa la replicación basada en activadores para copiar los datos del sistema SAP de origen a las tablas de la cola delta. SAP Data Services, que actúa como un suscriptor en el framework de ODP, recupera los datos de la cola delta, los transforma y los carga en BigQuery.
Configura la cola delta operativa (ODQ)
- En SAP LT Replication Server, usa la transacción
SM59a fin de crear un destino RFC para el sistema de aplicaciones SAP que es la fuente de datos. - En SAP LT Replication Server, usa la transacción
LTRCpara crear una configuración. En la configuración, define la fuente y el destino de SAP LT Replication Server. El destino para la transferencia de datos mediante ODP es SAP LT Replication Server.- A fin de especificar la fuente, ingresa el destino RFC para el sistema de aplicaciones SAP que se usará como fuente de datos.
- Para especificar el destino, sigue estos pasos:
- Ingresa NINGUNA como conexión RFC.
- Elige Situación de replicación de ODQ para la comunicación RFC. Con esta situación, se especifica que los datos se transfieran mediante la infraestructura de aprovisionamiento de datos operativos con colas delta operativas.
- Asigna un alias de cola.
El alias de cola se usa en SAP Data Services para la configuración del contexto de ODP de la fuente de datos.
Configuración de SAP Data Services
Crea un proyecto de servicios de datos
- Abre la aplicación SAP Data Services Designer.
- Ve a File > New > Project (Archivo > Nuevo > Proyecto).
- Especifica un nombre en el campo Project name (Nombre del proyecto).
- En Data Services Repository (Repositorio de servicios de datos), selecciona tu repositorio de servicios de datos.
- Haz clic en Finish (Finalizar). Tu proyecto aparecerá en el Explorador de proyectos a la izquierda.
SAP Data Services se conecta a los sistemas de origen para recopilar metadatos y, luego, al agente SAP Replication Server con el objetivo de recuperar la configuración y cambiar los datos.
Crea un almacén de datos de origen
Mediante los siguientes pasos, se crea una conexión con SAP LT Replication Server y se agregan las tablas de datos al nodo del almacén de datos correspondiente en la biblioteca de objetos de Designer.
A fin de usar SAP LT Replication Server con SAP Data Services, debes conectar SAP DataServices a la cola delta operativa correcta en el ODP mediante la conexión de un almacén de datos a la infraestructura de ODP.
- Abre la aplicación SAP Data Services Designer.
- Haz clic derecho en el nombre de tu proyecto de SAP Data Services en el Project Explorer (Explorador de proyectos).
- Selecciona New > Datastore (Nuevo > Almacén de datos).
- Completa el Datastore Name (Nombre del almacén de datos). Por ejemplo, DS_SLT.
- En el campo Tipo de almacén de datos, selecciona Aplicaciones SAP.
- En el campo Nombre del servidor de aplicaciones, ingresa el nombre de la instancia de SAP LT Replication Server.
- Especifica las credenciales de acceso de SAP LT Replication Server.
- Abra la pestaña Advanced.
- En ODP Context, ingresa SLT~ALIAS, en el que ALIAS es el alias de cola que especificaste en Configura la cola delta operativa (ODQ).
- Haz clic en Aceptar.
El almacén de datos nuevo aparecerá en la pestaña Almacén de datos en la biblioteca de objetos local en Designer.
Crea el almacén de datos de destino
Mediante estos pasos, se crea un almacén de datos de BigQuery que usa la cuenta de servicio que creaste antes en la sección Crea una cuenta de servicio. La cuenta de servicio permite que SAP Data Services acceda de forma segura a BigQuery.
Para obtener más información, consulta Obtain your Google service account email (Obtén el correo electrónico de la cuenta de servicio de Google) y Obtain a Google service account private key file (Obtén un archivo de claves privadas de la cuenta de servicio de Google) en la documentación de SAP Data Services.
- Abre la aplicación SAP Data Services Designer.
- Haz clic derecho en el nombre de tu proyecto de SAP Data Services en el Project Explorer (Explorador de proyectos).
- Selecciona New > Datastore (Nuevo > Almacén de datos).
- Completa el campo Name (Nombre). Por ejemplo, BQ_DS.
- Haz clic en Next (Siguiente).
- En el campo Datastore type (Tipo de almacén de datos), selecciona Google BigQuery.
- Aparecerá la opción Web Service URL. El software completa de forma automática la opción con la URL predeterminada del servicio web de BigQuery.
- Selecciona Configuración avanzada (Advanced).
- Completa las opciones avanzadas según Datastore option descriptions (Descripciones de las opciones del almacén de datos) para BigQuery en la documentación de SAP Data Services.
- Haz clic en OK.
El almacén de datos nuevo aparecerá en la pestaña Almacén de datos en la biblioteca de objetos local de Designer.
Importa los objetos de ODP de origen para la replicación
Mediante estos pasos, se importan objetos de ODP del almacén de datos de origen para las cargas iniciales y delta, y se ponen a disposición en SAP Data Services.
- Abre la aplicación SAP Data Services Designer.
- Expande el almacén de datos de origen para la carga de replicación en el Explorador de proyectos.
- Selecciona la opción Metadatos externos en la parte superior del panel derecho. Aparecerá la lista de nodos con las tablas y los objetos de ODP disponibles.
- Haz clic en el nodo de objetos de ODP para recuperar la lista de objetos de ODP disponibles. La lista puede tomar bastante tiempo en mostrarse.
- Haz clic en el botón Buscar.
- En el cuadro de diálogo, selecciona Datos externos en el menú Buscar en y Objeto de ODP en el menú Tipo de objeto.
- En el cuadro de diálogo Buscar, selecciona los criterios de búsqueda para filtrar la lista de objetos de ODP de origen.
- Selecciona de la lista el objeto de ODP para importar.
- Haz clic con el botón derecho y selecciona la opción Import (Importar).
- Completa el Name of Consumer (Nombre del consumidor).
- Completa el Name of project (Nombre del proyecto).
- Selecciona la opción Changed-data capture (CDC) (Captura de datos modificados [CDC]) en Extraction mode (Modo de extracción).
- Haz clic en Importar. Esto inicia la importación del objeto de ODP a Data Services. El objeto de ODP ahora está disponible en la biblioteca de objetos en el nodo DS_SLT.
Para obtener más información, consulta Importing ODP source metadata (Importa metadatos de origen de ODP) en la documentación de SAP Data Services.
Crea un archivo de esquema
Mediante estos pasos, se crea un flujo de datos en SAP Data Services para generar un archivo de esquema que refleje la estructura de las tablas de origen. Más adelante, usarás el archivo de esquema para crear una tabla de BigQuery.
El esquema garantiza que el flujo de datos del cargador de BigQuery propague de manera correcta la tabla de BigQuery nueva.
Crea un flujo de datos
- Abre la aplicación SAP Data Services Designer.
- Haz clic derecho en el nombre de tu proyecto de SAP Data Services en el Project Explorer (Explorador de proyectos).
- Selecciona Project > New > Data flow (Proyecto > Nuevo > Flujo de datos).
- Completa el campo Name (Nombre). Por ejemplo, DF_BQ.
- Haz clic en Finish (Finalizar).
Actualiza la biblioteca de objetos
- Haz clic con el botón derecho en el almacén de datos de origen para la carga inicial en el Explorador de proyectos y selecciona la opción Actualizar biblioteca de objetos. Esto actualiza la lista de tablas de bases de datos de fuentes de datos que puedes usar en tu flujo de datos.
Compila el flujo de datos
- Para compilar el flujo de datos, arrastra y suelta las tablas de origen en el lugar de trabajo del flujo de datos y elige Importar como origen cuando se te solicite.
- En la pestaña Transformaciones de la biblioteca de objetos, arrastra una Transformación XML_Map del nodo Plataforma al flujo de datos y elige Carga por lotes cuando se te solicite.
- Conecta todas las tablas de origen en el lugar de trabajo a la transformación XML Map.
- Abre la Transformación XML Map y completa las secciones del esquema de entrada y salida según los datos que incluyas en la tabla de BigQuery.
- Haz clic con el botón derecho en el nodo XML_Map en la columna Schema Out y selecciona Generate Google BigQuery Schema en el menú desplegable.
- Ingresa un nombre y una ubicación para el esquema.
- Haz clic en Save (Guardar).
- Haz clic derecho en el flujo de datos del Project Explorer (Explorador de proyectos) y selecciona Remove (Quitar).
SAP Data Services genera un archivo de esquema con la extensión de archivo .json.
Crea las tablas de BigQuery
Debes crear tablas en tu conjunto de datos de BigQuery en Google Cloud para la carga inicial y las cargas delta. Usarás los esquemas que creaste en SAP Data Services para crear las tablas.
La tabla de la carga inicial se usa para la replicación inicial de todo el conjunto de datos de origen. La tabla de las cargas delta se usa para la replicación de los cambios en el conjunto de datos de origen que se producen después de la carga inicial. Las tablas se basan en el esquema que generaste en el paso anterior. La tabla para las cargas delta incluye un campo adicional de marca de tiempo que identifica el horario de cada carga delta.
Crea una tabla de BigQuery para la carga inicial
Mediante estos pasos, se crea una tabla para la carga inicial en tu conjunto de datos de BigQuery.
- Accede a tu proyecto de Google Cloud en la consola de Google Cloud.
- Selecciona BigQuery.
- Haz clic en el conjunto de datos correspondiente.
- Haz clic en Crear tabla.
- Ingresa un nombre de tabla. Por ejemplo, BQ_INIT_LOAD.
- En Esquema, activa o desactiva la configuración para habilitar el modo Editar como texto.
- Para configurar el esquema de la tabla nueva en BigQuery, copia y pega el contenido del archivo de esquema que creaste en Crea un archivo de esquema.
- Haz clic en Crear tabla.
Crea una tabla de BigQuery para las cargas delta
Mediante estos pasos, se crea una tabla para las cargas delta de tu conjunto de datos de BigQuery.
- Accede a tu proyecto de Google Cloud en la consola de Google Cloud.
- Selecciona BigQuery.
- Haz clic en el conjunto de datos correspondiente.
- Haz clic en Crear tabla.
- Ingresa el nombre de la tabla. Por ejemplo, BQ_DELTA_LOAD.
- En Esquema, activa o desactiva la configuración para habilitar el modo Editar como texto.
- Para configurar el esquema de la tabla nueva en BigQuery, copia y pega el contenido del archivo de esquema que creaste en Crea un archivo de esquema.
En la lista JSON del archivo de esquema, justo antes de la definición de campo del campo DI_SEQUENCE_NUMBER, agrega la siguiente definición de campo DL_TIMESTAMP. Este campo almacena la marca de tiempo de cada ejecución de carga delta:
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },Haz clic en Crear tabla.
Configura el flujo de datos entre SAP Data Services y BigQuery
Para configurar el flujo de datos, debes importar las tablas de BigQuery a SAP Data Services como metadatos externos y crear el trabajo de replicación y el flujo de datos del cargador de BigQuery.
Importa las tablas de BigQuery
Mediante estos pasos, se importan las tablas de BigQuery que creaste en el paso anterior y se ponen a disposición en SAP Data Services.
- En la biblioteca de objetos de SAP Data Services Designer, abre el almacén de datos de BigQuery que creaste antes.
- En la parte superior del panel derecho, selecciona Metadatos externos. Aparecerán las tablas de BigQuery que creaste.
- Haz clic con el botón derecho en el nombre de la tabla de BigQuery correspondiente y selecciona Importar.
- Se iniciará la importación de la tabla seleccionada a SAP Data Services. Ahora, la tabla está disponible en la biblioteca de objetos en el nodo del almacén de datos de destino.
Crea un trabajo de replicación y el flujo de datos del cargador de BigQuery
Mediante estos pasos, se crea un trabajo de replicación y el flujo de datos en SAP Data Services que se usa para cargar los datos desde SAP LT Replication Server a la tabla de BigQuery.
El flujo de datos consta de dos partes. La primera ejecuta la carga inicial de datos desde los objetos de ODP de origen a la tabla de BigQuery, y la segunda habilita las cargas delta posteriores.
Crea una variable global
A fin de que el trabajo de replicación pueda determinar si ejecuta una carga inicial o una carga delta, debes crear una variable global para hacer el seguimiento del tipo de carga en la lógica de flujo de datos.
- En el menú de la aplicación SAP Data Services Designer, ve a Herramientas > Variables.
- Haz clic con el botón derecho en Variables globales y selecciona Insertar.
- Haz clic con el botón derecho en el Name (Nombre) de la variable y selecciona Properties (Propiedades).
- Ingresa $INITLOAD como Name (Nombre) de la variable.
- En Data Type (Tipo de datos), selecciona Int.
- Ingresa 0 en el campo Value (Valor).
- Haz clic en Aceptar.
Crea el trabajo de replicación
- Haz clic derecho en el nombre de tu proyecto en el Project Explorer (Explorador de proyectos).
- Selecciona New (Nuevo) > Batch Job (Trabajo por lotes).
- Completa el campo Name (Nombre). Por ejemplo, JOB_SRS_DS_BQ_REPLICATION.
- Haz clic en Finish (Finalizar).
Crea una lógica de flujo de datos para la carga inicial
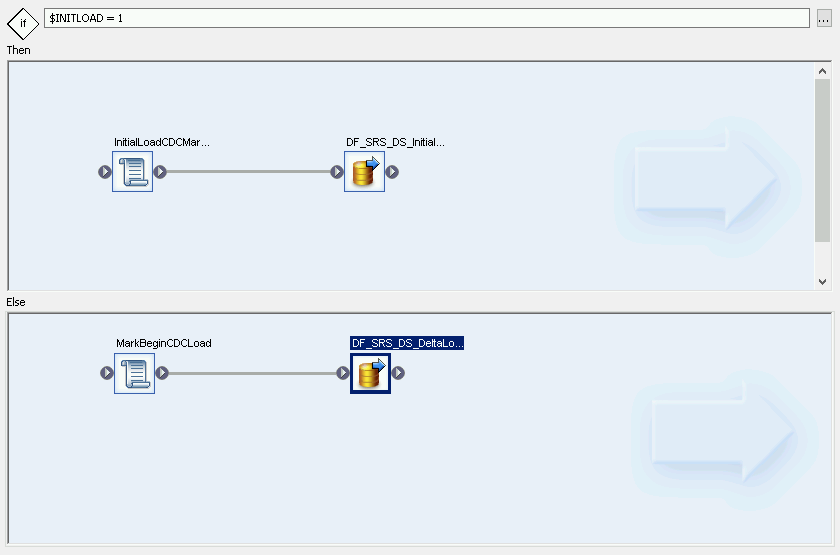
Crea una condicional
- Haz clic con el botón derecho en Nombre del trabajo y selecciona la opción Agregar nueva > Condicional.
- Haz clic con el botón derecho en el ícono de la condicional y selecciona Cambiar nombre.
Cambia el nombre a InitialOrDelta.

Abre el Editor de condicional; para ello, haz doble clic en el ícono de la condicional.
En el campo Instrucción if, ingresa $INITLOAD = 1, que establece la condición para ejecutar la carga inicial.
Haz clic con el botón derecho en el panel Then y selecciona Agregar nueva > Secuencia de comandos.
Haz clic con el botón derecho en el ícono Script (Secuencia de comandos) y selecciona Rename (Cambiar nombre).
Cambia el nombre. Por ejemplo, en estas instrucciones se usa InitialLoadCDCMarker.
Haz doble clic en el ícono Script (Secuencia de comandos) para abrir el editor de Funciones.
Ingresa
print('Beginning Initial Load');.Ingresa
begin_initial_load();.
Haz clic en el ícono Atrás en la barra de herramientas de la aplicación para salir del Function Editor (Editor de funciones).
Crea un flujo de datos para la carga inicial
- Haz clic con el botón derecho en el panel Then y selecciona Add New (Agregar nuevo) Data Flow (Flujo de datos).
- Cambia el nombre del flujo de datos. Por ejemplo, DF_SRS_DS_InitialLoad.
- Conecta InitialLoadCDCMarker con DF_SRS_DS_InitialLoad; para ello, haz clic en el ícono de salida de conexión de InitialLoadCDCMarker y, luego, arrastra la línea de conexión al ícono de entrada de DF_SRS_DS_InitialLoad.
- Haz doble clic en el flujo de datos de DF_SRS_DS_InitialLoad.
Importa y conecta el flujo de datos con los objetos del almacén de datos de origen
- Desde el almacén de datos, arrastra y suelta los objetos de ODP de origen en el lugar de trabajo del flujo de datos. En estas instrucciones, el almacén de datos se llama DS_SLT. El nombre del almacén de datos puede ser diferente.
- Arrastra la Transformación de Query del nodo Plataforma en la pestaña Transformaciones de la biblioteca de objetos al flujo de datos.
Haz doble clic en los objetos de ODP y, en la pestaña Source (Origen), configura la opción Initial Load (Carga inicial) en Yes (Sí).
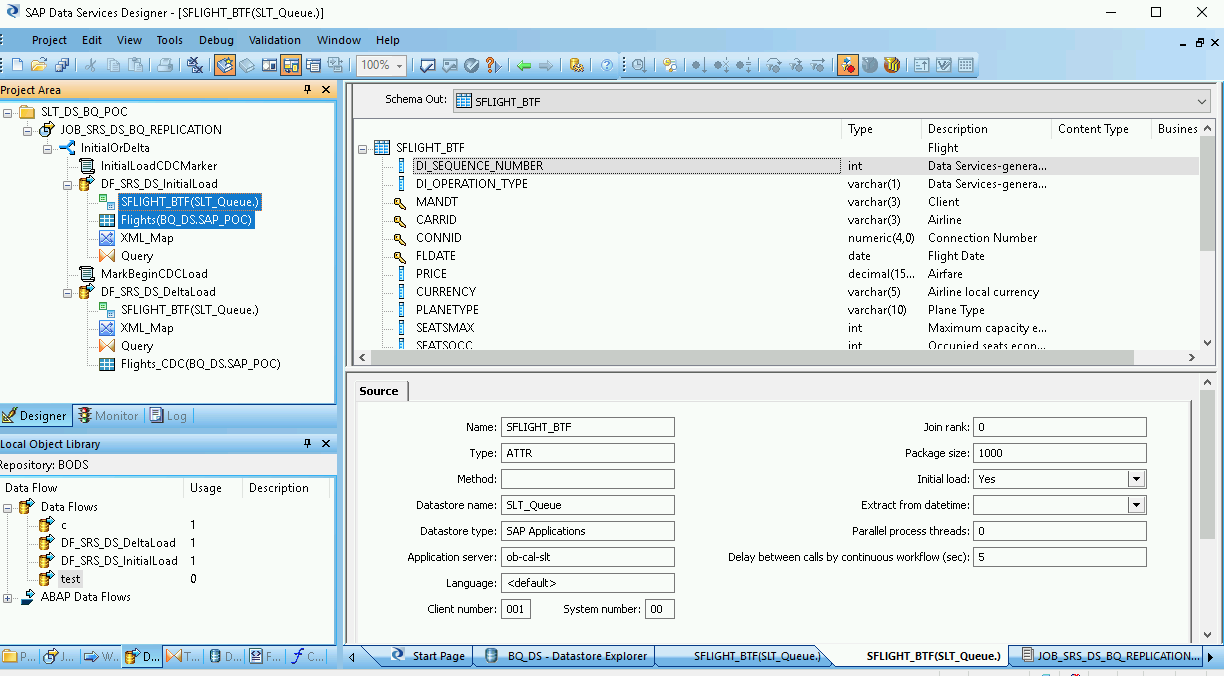
Conecta todos los objetos de ODP de origen en el lugar de trabajo a la Transformación de Query.
Haz doble clic en la Transformación de Query.
Selecciona todos los campos de la tabla en Schema In (Esquema de entrada) a la izquierda y arrástralos a Schema Out (Esquema de salida) a la derecha.
A fin de agregar una función de conversión para un campo de fecha y hora, sigue estos pasos:
- Selecciona el campo de fecha y hora en la lista Schema Out (Esquema de salida) a la derecha.
- Selecciona la pestaña Asignación (Mapping) debajo de las listas de esquemas.
Reemplaza el nombre del campo con la siguiente función:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')donde FIELDNAME es el nombre del campo que seleccionaste.
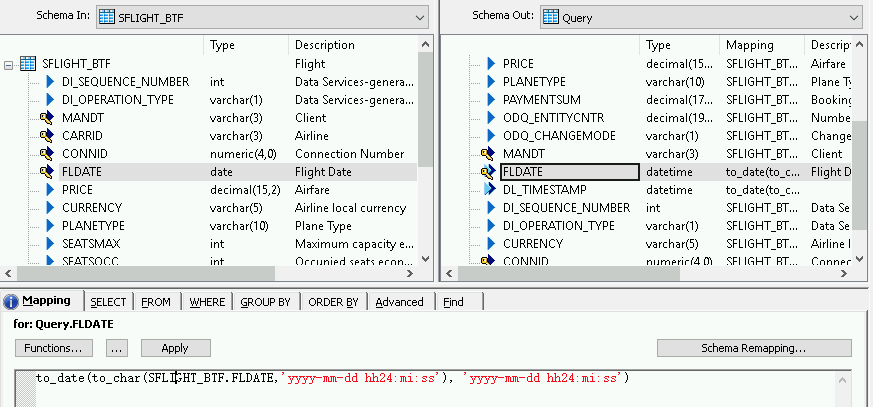
Haz clic en el ícono Back (Atrás) en la barra de herramientas de la aplicación para volver al flujo de datos.
Importa y conecta el flujo de datos con los objetos del almacén de datos de destino
- En el almacén de datos de la biblioteca de objetos, arrastra la tabla de BigQuery importada para Initial load (Carga inicial) al flujo de datos. El nombre del almacén de datos en estas instrucciones es BQ_DS. El nombre de tu almacén de datos puede ser diferente.
- Desde el nodo Plataforma en la pestaña Transformaciones de la biblioteca de objetos, arrastra una transformación XML_Map al flujo de datos.
- Selecciona Modo por lotes en el cuadro de diálogo.
- Conecta la transformación Query a la transformación XML_Map.
Conecta la transformación XML_Map a la tabla de BigQuery importada.
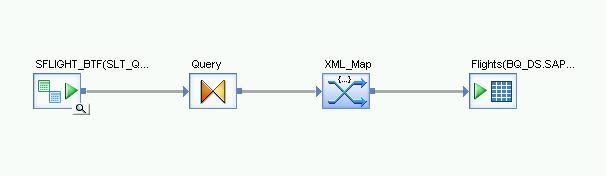
Abre la Transformación XML_Map y completa las secciones del esquema de entrada y salida según los datos que incluyas en la tabla de BigQuery.
Haz doble clic en la tabla de BigQuery en el lugar de trabajo para abrirla y completar las opciones en la pestaña Target, como se indica en la siguiente tabla:
| Opción | Descripción |
|---|---|
| Convertir en puerto (Make port) | Especifica No, que es la opción predeterminada. Si se especifica Sí, se convierte un archivo de origen o de destino en un puerto de flujo de datos incorporado. |
| Modo | Especifica Truncar para la carga inicial, que reemplaza los registros existentes en la tabla de BigQuery con los datos cargados por SAP Data Services. Truncar es el valor predeterminado. |
| Cantidad de cargadores | Especifica un número entero positivo para establecer la cantidad de cargadores (subprocesos) que se usarán en el procesamiento. El valor predeterminado es 4.
Cada cargador inicia un trabajo de carga reanudable en BigQuery. Puedes especificar cualquier cantidad de cargadores. Para obtener ayuda sobre cómo determinar una cantidad adecuada de cargadores, consulta la documentación de SAP, que incluye lo siguiente: |
| Cantidad máxima de registros con errores por cargador | Especifica 0 o un número entero positivo para establecer la cantidad máxima de registros que pueden fallar por trabajo de carga antes de que BigQuery deje de cargar registros. El valor predeterminado es cero (0). |
- Haz clic en el ícono Validar en la barra de herramientas superior.
- Haz clic en el ícono Atrás en la barra de herramientas de la aplicación para volver al Editor de condicional.
Crea un flujo de datos para la carga delta
Debes crear un flujo de datos para replicar los registros de captura de datos modificados que se acumulan después de la carga inicial.
Crea un flujo delta condicional:
- Haz doble clic en la condicional InitialOrDelta.
- Haz clic con el botón derecho en la sección Else y selecciona Add New (Agregar nueva) > Script (Secuencia de comandos).
- Cambia el nombre de la secuencia de comandos. Por ejemplo, MarkBeginCDCLoad.
- Haz doble clic en el ícono Script (Secuencia de comandos) para abrir el editor de Funciones.
Ingresa print('Beginning Delta Load');

Haz clic en el ícono Atrás en la barra de herramientas de la aplicación para volver al Editor de condicional.
Crea el flujo de datos para la carga delta
- En el Editor de condicional, haz clic con el botón derecho y selecciona Agregar nuevo > Flujo de datos.
- Cambia el nombre del flujo de datos. Por ejemplo, DF_SRS_DS_DeltaLoad.
- Conecta MarkBeginCDCLoad con DF_SRS_DS_DeltaLoad, como se muestra en el siguiente diagrama.
Haz doble clic en el flujo de datos DF_SRS_DS_DeltaLoad.
Importa y conecta el flujo de datos con los objetos del almacén de datos de origen
- Arrastra y suelta los objetos de ODP de origen del almacén de datos al lugar de trabajo del flujo de datos. El almacén de datos en estas instrucciones tiene el nombre DS_SLT. El nombre del almacén de datos puede ser diferente.
- Desde el nodo Plataforma en la pestaña Transformaciones de la biblioteca de objetos, arrastra la transformación de Query al flujo de datos.
- Haz doble clic en los objetos de ODP y, en la pestaña Origen, configura la opción Carga inicial en No.
- Conecta todos los objetos de ODP de origen en el lugar de trabajo a la Transformación de Query.
- Haz doble clic en la transformación Query.
- Selecciona todos los campos de la tabla en la lista Esquema de entrada de la izquierda y arrástralos a la lista Esquema de salida de la derecha.
Habilita la marca de tiempo para las cargas delta
Mediante los siguientes pasos, SAP Data Services puede registrar de manera automática la marca de tiempo de cada ejecución de carga delta en un campo de la tabla de carga delta.
- Haz clic con el botón derecho en el nodo Query en el panel Schema Out (Esquema de salida) a la derecha.
- Selecciona New Output Column (Nueva columna de resultados).
- Ingresa DL_TIMESTAMP en Name (Nombre).
- Selecciona fecha y hora en Data type (Tipo de datos).
- Haz clic en Aceptar.
- Haz clic en el campo DL_TIMESTAMP recién creado.
- Ve a la pestaña Mapping (Asignación) a continuación.
Ingresa la siguiente función:
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
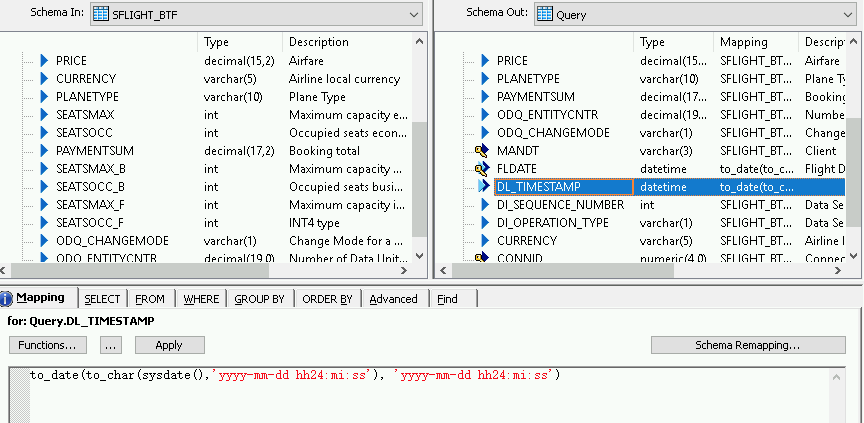
Importa y conecta el flujo de datos a los objetos del almacén de datos de destino
- Desde el almacén de datos en la biblioteca de objetos, arrastra la tabla de BigQuery importada para Carga delta al lugar de trabajo del flujo de datos después de la transformación XML_Map. Estas instrucciones usan el nombre del almacén de datos de ejemplo BQ_DS. El nombre de tu almacén de datos puede ser diferente.
- Desde el nodo Plataforma en la pestaña Transformaciones de la biblioteca de objetos, arrastra una transformación XML_Map al flujo de datos.
- Conecta la transformación Query a la transformación XML_Map.
Conecta la transformación XML_Map a la tabla de BigQuery importada.
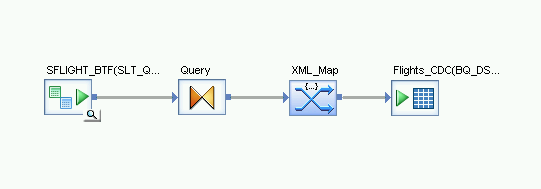
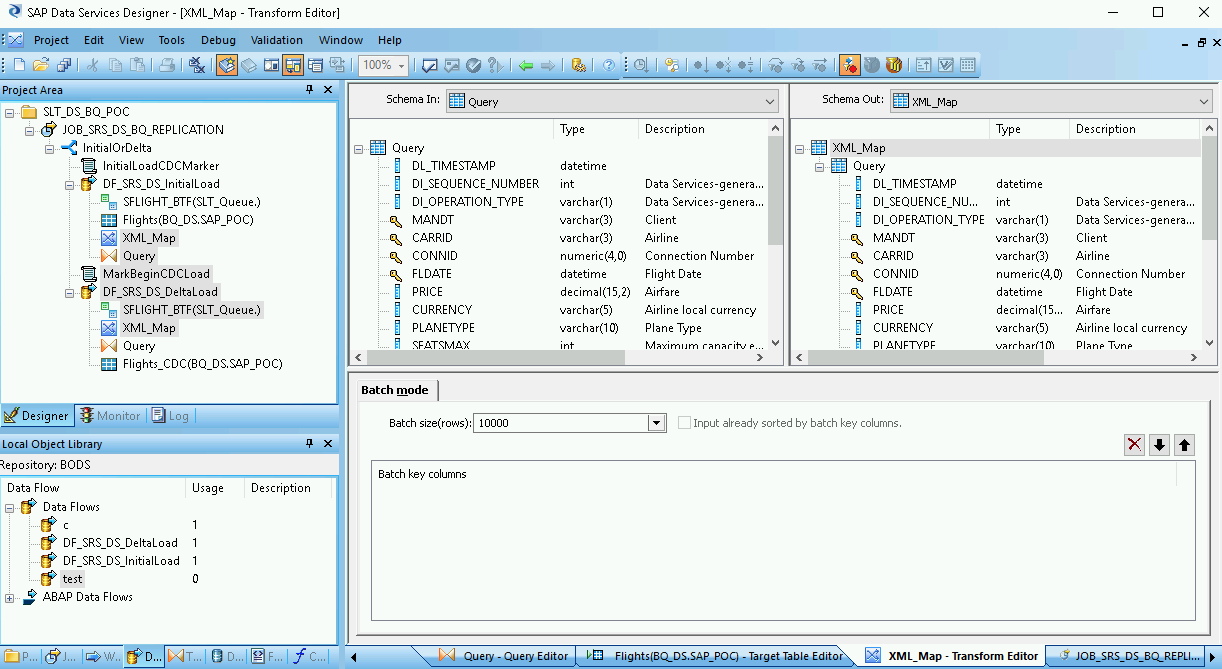
Abre la Transformación XML_Map y completa las secciones del esquema de entrada y salida según los datos que incluyas en la tabla de BigQuery.
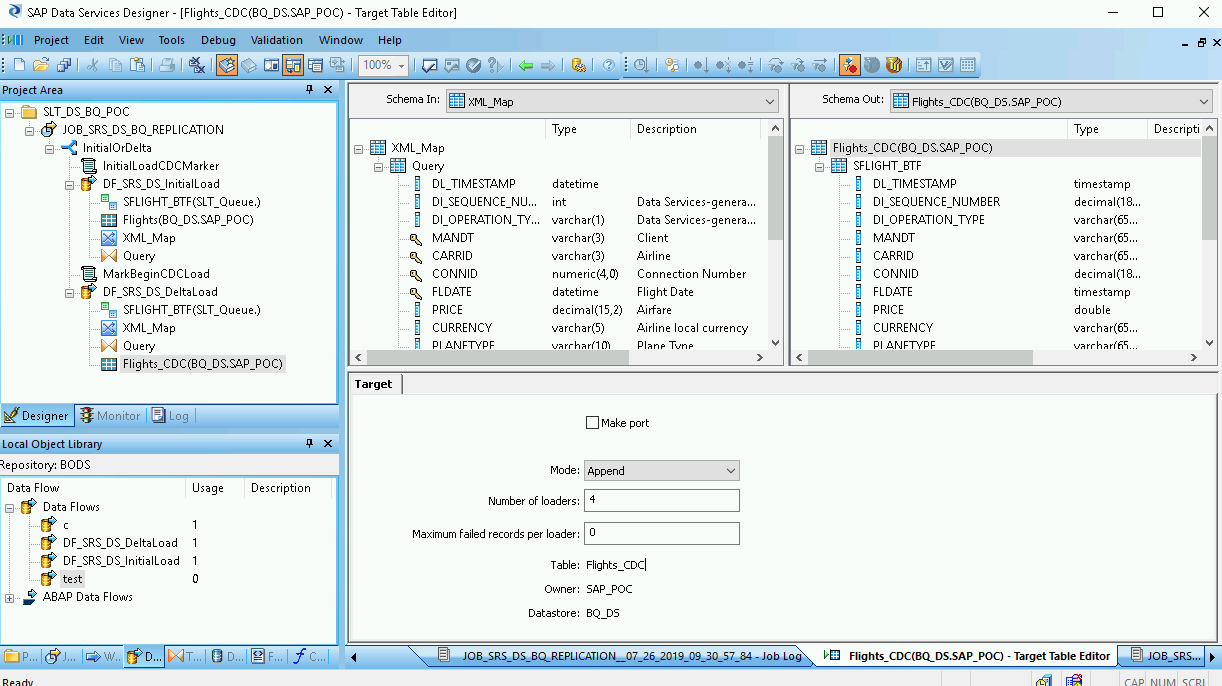
Haz doble clic en la tabla de BigQuery en el lugar de trabajo para abrirla y completar las opciones en la pestaña Destino según las siguientes descripciones:
| Opción | Descripción |
|---|---|
| Convertir en puerto (Make port) | Especifica No, que es la opción predeterminada. Si se especifica Sí, se convierte un archivo de origen o de destino en un puerto de flujo de datos incorporado. |
| Modo | Especifica Adjuntar para las cargas delta, que conserva los registros existentes en la tabla de BigQuery cuando se cargan registros nuevos desde SAP Data Services. |
| Cantidad de cargadores | Especifica un número entero positivo para establecer la cantidad de cargadores (subprocesos) que se usarán en el procesamiento.
Cada cargador inicia un trabajo de carga reanudable en BigQuery. Puedes especificar cualquier cantidad de cargadores. Por lo general, las cargas delta necesitan menos cargadores que la carga inicial. Para obtener ayuda sobre cómo determinar una cantidad adecuada de cargadores, consulta la documentación de SAP, que incluye lo siguiente: |
| Cantidad máxima de registros con errores por cargador | Especifica 0 o un número entero positivo para establecer la cantidad máxima de registros que pueden fallar por trabajo de carga antes de que BigQuery deje de cargar registros. El valor predeterminado es cero (0). |
- Haz clic en el ícono Validar en la barra de herramientas superior.
- Haz clic en el ícono Atrás en la barra de herramientas de la aplicación para volver al editor de Condicional.
Carga los datos en BigQuery
Los pasos para una carga inicial y una carga delta son similares. Para cada una, inicia el trabajo de replicación y ejecuta el flujo de datos en SAP Data Services a fin de cargar los datos de SAP LT Replication Server a BigQuery. Una diferencia importante entre los dos procedimientos de carga es el valor de la variable global $INITLOAD. Para una carga inicial, $INITLOAD debe establecerse en 1. Para una carga delta, $INITLOAD debe ser 0.
Ejecuta una carga inicial
Cuando ejecutas una carga inicial, todos los datos en el conjunto de datos de origen se replican en la tabla de BigQuery de destino que está conectada al flujo de datos de la carga inicial. Se reemplazarán todos los datos de la tabla de destino.
- En SAP Data Services Designer, abre el Explorador de proyectos.
- Haz clic con el botón derecho en el nombre del trabajo de replicación y selecciona Ejecutar. Aparecerá un cuadro de diálogo.
- En el cuadro de diálogo, ve a la pestaña Variable global y cambia el valor de $INITLOAD a 1 para que la carga inicial se ejecute primero.
- Haz clic en Aceptar. El proceso de carga se inicia y comienzan a aparecer los mensajes de depuración en el registro de SAP Data Services. Los datos se cargan en la tabla que creaste en BigQuery para las cargas iniciales. El nombre de la tabla de carga inicial en estas instrucciones es BQ_INIT_LOAD. El nombre de tu tabla puede ser diferente.
- Para saber si la carga se completó, ve a la consola de Google Cloud y abre el conjunto de datos de BigQuery que contiene la tabla. Si los datos aún se están cargando, aparecerá “Cargando” junto al nombre de la tabla.
Después de la carga, los datos estarán listos para procesarse en BigQuery.
A partir de ahora, todos los cambios en la tabla de origen se registrarán en la cola delta de SAP LT Replication Server. Para cargar los datos de la cola delta a BigQuery, ejecuta un trabajo de carga delta.
Ejecuta una carga delta
Cuando ejecutas una carga delta, solo los cambios que ocurrieron en el conjunto de datos de origen desde la última carga se replicarán en la tabla de destino de BigQuery conectada al flujo de datos de la carga delta.
- Haz clic con el botón derecho en el nombre del trabajo y selecciona Ejecutar.
- Haz clic en Aceptar. Se inicia el proceso de carga y comienzan a aparecer los mensajes de depuración en el registro de SAP Data Services. Los datos se cargan en la tabla que creaste en BigQuery para las cargas delta. En estas instrucciones, el nombre de la tabla de carga delta es BQ_DELTA_LOAD. El nombre de tu tabla puede ser diferente.
- Para saber si la carga se completó, ve a la consola de Google Cloud y abre el conjunto de datos de BigQuery que contiene la tabla. Si los datos aún se están cargando, aparecerá “Cargando” junto al nombre de la tabla.
- Después de la carga, los datos estarán listos para procesarse en BigQuery.
Para realizar un seguimiento de los cambios en los datos de origen, SAP LT Replication Server registra el orden de las operaciones de datos modificados en la columna DI_SEQUENCE_NUMBER y el tipo de operación de datos modificados en la columna DI_OPERATION_TYPE (D=borrar, U=actualizar, I=insertar). SAP LT Replication Server almacena los datos en las columnas de las tablas de cola delta, desde las cuales se replican a BigQuery.
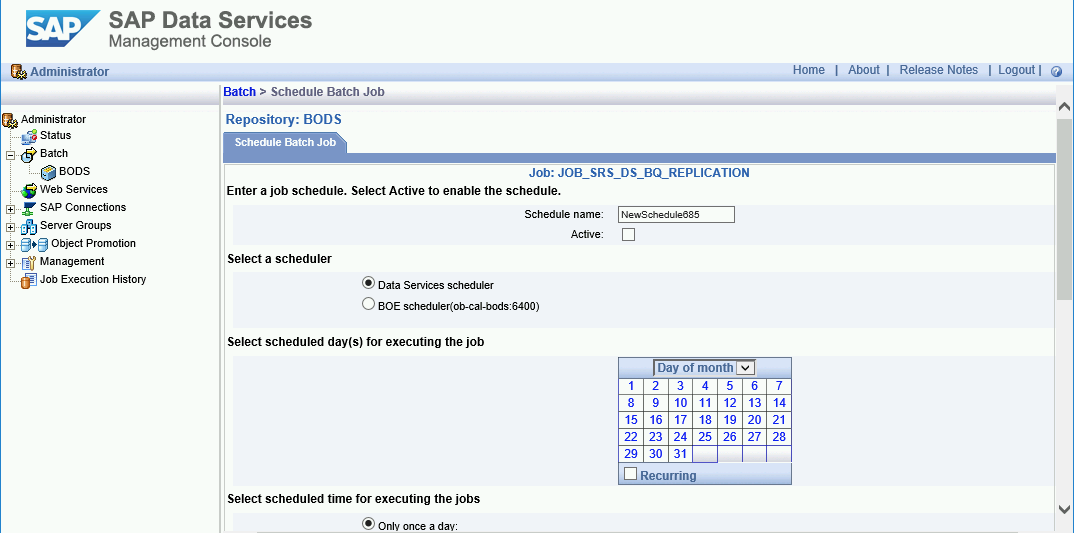
Programa cargas delta
Puedes programar un trabajo de carga delta para que se ejecute a intervalos regulares mediante SAP Data Services Management Console.
- Abre la aplicación SAP Data Services Management Console.
- Haz clic en Administrador (Administrator).
- Expande el nodo Lote (Batch) en el árbol del menú del lado izquierdo.
- Haz clic en el nombre del repositorio de SAP Data Services.
- Haz clic en la pestaña Configuración del trabajo por lotes (Batch Job Configuration).
- Haz clic en Agregar programa (Add Schedule).
- Completa el Schedule name (Nombre del programa).
- Marca Active.
- En la sección Select scheduled time for executing the jobs, especifica la frecuencia de la ejecución de carga delta.
- Importante: Google Cloud limita la cantidad de trabajos de carga de BigQuery que puedes ejecutar en un día. Asegúrate de que tu programa no supere el límite, que no se puede aumentar. Para obtener más información sobre el límite de trabajos de carga de BigQuery, consulta Cuotas y límites en la documentación de BigQuery.
- Expande las Variables globales y comprueba si $INITLOAD está establecido en 0.
- Haz clic en Aplicar (Apply).
Próximos pasos
Consulta y analiza datos replicados en BigQuery.
Para obtener más información sobre las consultas, revisa lo siguiente documentación:
- Descripción general de las consultas de datos de BigQuery en la documentación de BigQuery.
Para obtener algunas ideas sobre cómo consolidar los datos de carga inicial y delta en BigQuery a gran escala, consulta lo siguiente:
- Realiza mutaciones a gran escala en BigQuery, disponible en el blog de Google Cloud.
- Lenguaje de manipulación de datos en la documentación de BigQuery.
Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.