Questo documento fa parte di una serie che fornisce informazioni e indicazioni chiave relative alla pianificazione ed esecuzione delle migrazioni dei database Oracle® 11g/12c a Cloud SQL per PostgreSQL versione 12. Oltre alla parte introduttiva sulla configurazione, la serie include le seguenti parti:
- Migrazione degli utenti Oracle a Cloud SQL per PostgreSQL: terminologia e funzionalità (questo documento)
- Migrazione degli utenti Oracle a Cloud SQL per PostgreSQL: tipi di dati, utenti e tabelle
- Migrazione degli utenti Oracle a Cloud SQL per PostgreSQL: query, stored procedure, funzioni e trigger
- Migrazione degli utenti Oracle a Cloud SQL per PostgreSQL: sicurezza, operazioni, monitoraggio e registrazione
- Migrazione di utenti e schemi di database Oracle a Cloud SQL per PostgreSQL
Terminologia
Questa sezione illustra le somiglianze e le differenze nella terminologia dei database tra Oracle e Cloud SQL per PostgreSQL. Esamina e confronta gli aspetti di base di ciascuna delle piattaforme di database. Il confronto distingue tra le versioni Oracle 11g e 12c a causa delle differenze di architettura (ad esempio, Oracle 12c introduce la funzionalità multi-tenant). La versione di Cloud SQL per PostgreSQL a cui si fa riferimento qui è 12.
Questa sezione mette in evidenza le principali differenze di terminologia tra Oracle e Cloud SQL per PostgreSQL. Una descrizione di basso livello è descritta più avanti in questo documento.
| Oracle 11g | Descrizione | Cloud SQL per PostgreSQL | Differenze principali |
|---|---|---|---|
| instance | Una singola istanza Oracle 11g può contenere un solo database. | instance | Un'istanza Cloud SQL per PostgreSQL contiene esattamente un cluster di database. Un cluster di database è una raccolta di database archiviati in un'area di dati comune. |
| database | Un database è considerato una singola istanza (il nome del database è identico al nome dell'istanza). | database | Uno o più database servono più applicazioni. |
| schema | Gli schemi e gli utenti sono identici perché entrambi sono considerati proprietari degli oggetti del database (un utente può essere creato senza specificare o essere allocato a uno schema). | schema | Un database contiene uno o più schemi. Oggetti come le tabelle sono contenuti negli schemi. Lo stesso nome dell'oggetto può essere utilizzato in schemi diversi all'interno dello stesso database senza conflitti. |
| user | Identità dello schema perché entrambi sono proprietari di oggetti database, ad esempio istanza → database → schemi/utenti → oggetti database. | role | Un ruolo può essere un utente del database o un gruppo di utenti del database,
a seconda di come è configurato. Può possedere oggetti di database come le tabelle.
I ruoli sono limitati a un intero cluster di database ed è possibile concedere l'appartenenza a un ruolo a un altro ruolo. |
| role | Set definito di autorizzazioni di database che possono essere collegate come gruppo e assegnate agli utenti del database | ||
| admin/ Utenti di SYSTEM |
Utenti amministratori Oracle con il massimo livello di accesso:SYS
|
cloudsqlsuperuser | Cloud SQL per PostgreSQL viene fornito con l'utente postgres
predefinito. Questo utente fa parte del ruolo cloudsqlsuperuser e ha
i seguenti attributi (privilegi): CREATEROLE,
CREATEDB e LOGIN. Dato che Cloud SQL per PostgreSQL è un servizio gestito, limita l'accesso ad alcune procedure e tabelle di sistema che richiedono privilegi avanzati. Pertanto, l'utente postgres non ha gli attributi SUPERUSER o REPLICATION. Non puoi
creare o avere accesso a utenti con attributi superuser. |
| dictionary/ metadata |
Oracle utilizza le seguenti tabelle di metadati:USER_TableName
|
dictionary/ metadata |
Cloud SQL per PostgreSQL utilizza lo standard ANSI
INFORMATION_SCHEMA per fornire informazioni su dizionario e metadati. |
| Visualizzazioni dinamiche del sistema | Visualizzazioni dinamiche Oracle:V$ViewName |
sistema visualizzazioni dinamiche |
Cloud SQL per PostgreSQL dispone delle seguenti visualizzazioni delle statistiche dinamiche:pg_stat_ViewNamepg_statio_ViewName |
| spazio_tabelle | Le strutture di archiviazione logiche principali dei database Oracle. Ogni tablespace può contenere uno o più file di dati. | spazio_tabelle | In Cloud SQL per PostgreSQL, i file di dati vengono archiviati insieme nella directory dei dati PGDATA di un cluster di database utilizzando una struttura di directory predefinita. Gli spazi tabella in Cloud SQL per PostgreSQL forniscono un meccanismo per definire posizioni personalizzate nel file system in cui possono essere archiviati i file di dati.Poiché Cloud SQL per PostgreSQL è un servizio gestito, Google Cloud gestisce per te il file system sottostante della macchina host. Non puoi creare nuovi spazi tabella su Cloud SQL per PostgreSQL. |
| file di dati | Gli elementi fisici di un database Oracle che contengono i dati e sono definiti in un tablespace specifico. Un singolo file di dati è definito dalle dimensioni iniziali e massime e può contenere dati per più tabelle. I file di dati Oracle utilizzano il suffisso .dbf (non obbligatorio). |
file di dati | Cloud SQL per PostgreSQL archivia ogni database in un cluster di database nella rispettiva sottodirectory. Ogni tabella e ogni indice all'interno di un database viene archiviato in un file separato in quella sottodirectory. |
| spazio tabella di sistema | Contiene gli oggetti delle tabelle e delle viste del dizionario di dati per l'intero database Oracle. | Non esiste | Gli oggetti delle tabelle e delle viste del dizionario dei dati vengono archiviati
INFORMATION_SCHEMA nella directory dei dati di un cluster di database
PGDATA utilizzando una struttura di directory predefinita. |
| spazio tabella temporaneo | Contiene oggetti dello schema validi per la durata di una sessione. Inoltre, supporta le operazioni in esecuzione che non possono essere inserite nella memoria del server. |
File temporanei | I file temporanei vengono utilizzati per archiviare le operazioni in esecuzione che non rientrano nella memoria del server. Questi file vengono memorizzati in una directory chiamatapgsql_tmp e vengono creati solo durante l'esecuzione dell'istruzione SQL. |
| Annullare il tablespace | Un tipo speciale di spazio tabella permanente di sistema utilizzato da Oracle per gestire le operazioni di rollback quando il database viene eseguito in modalità di gestione dell'annullamento automatico (predefinita). |
Non esiste | Per consentire le operazioni di rollback, Cloud SQL per PostgreSQL conserva le righe aggiornate o eliminate all'interno del file di dati della tabella stessa. La pulitura è il processo di recupero o riutilizzo dello spazio su disco occupato da righe aggiornate o eliminate. |
| ASM | Oracle Automatic Storage Management è un gestore di file system e dischi del database integrato e ad alte prestazioni, gestito automaticamente da un database Oracle configurato con ASM. | Non supportato | Cloud SQL per PostgreSQL si basa sul file system del sistema operativo per archiviare i file di dati e non ha un equivalente di Oracle ASM. Tuttavia, Cloud SQL per PostgreSQL supporta molte funzionalità che forniscono l'automazione dello spazio di archiviazione, come aumenti automatici dello spazio di archiviazione, prestazioni e scalabilità. |
| tables/views | Oggetti di database fondamentali creati dall'utente. | tables/views | Identico a Oracle. |
| Viste materializzate | Definiti con istruzioni SQL specifiche e possono essere aggiornati manualmente o automaticamente in base a configurazioni specifiche. |
Viste materializzate | Le viste materializzate funzionano in modo simile a Oracle. Vengono aggiornate manualmente
utilizzando le istruzioni REFRESH
MATERIALIZED VIEW. |
| sequenza | Generatore di valori univoci Oracle. | sequenza | Simile a Oracle. |
| synonym | Oggetti del database Oracle che fungono da identificatori alternativi per altri oggetti del database. | Non supportato | Cloud SQL per PostgreSQL non offre sinonimi. Come soluzione alternativa, le viste possono essere utilizzate impostando le autorizzazioni appropriate. |
| partizione | Oracle fornisce molte soluzioni di partizionamento per suddividere le tabelle di grandi dimensioni in parti gestite più piccole. | partizione | Cloud SQL per PostgreSQL supporta sia il partitioning declarative nello stile Oracle sia il partitioning tramite eredità, consentendo una maggiore flessibilità di partizionamento. |
| Database flashback | Funzionalità proprietaria di Oracle che può essere utilizzata per inizializzare un database Oracle a un momento definito in precedenza, consentendo di eseguire query o ripristinare i dati modificati o danneggiati per errore. | Non supportato | Per una soluzione alternativa, puoi utilizzare i backup di Cloud SQL e il recupero point-in-time per ripristinare un database a uno stato precedente (ad esempio, il ripristino prima dell'eliminazione di una tabella). |
| sqlplus | Interfaccia a riga di comando Oracle che consente di eseguire query e gestire l'istanza database. | psql | Interfaccia a riga di comando equivalente a Cloud SQL per PostgreSQL per query e gestione. Può essere connesso da qualsiasi client con le autorizzazioni appropriate a Cloud SQL. |
| PL/SQL | Oracle ha esteso il linguaggio procedurale a SQL ANSI. | PL/pgSQL | Cloud SQL per PostgreSQL ha un proprio linguaggio procedurale chiamato PL/pgSQL, che è simile a PL/SQL di Oracle sotto molti aspetti. Per un riepilogo delle principali differenze tra i due linguaggi, consulta Porting da Oracle PL/SQL. |
| package & package body | Funzionalità specifica di Oracle per raggruppare procedure e funzioni archiviate sotto lo stesso riferimento logico. | Non supportata | Cloud SQL per PostgreSQL organizza le funzioni utilizzando gli schemi. |
| Funzioni e stored procedure | Utilizza PL/SQL per implementare la funzionalità del codice. | Funzioni e stored procedure | Cloud SQL per PostgreSQL supporta l'implementazione di procedure e funzioni memorizzate utilizzando una serie di linguaggi di programmazione come PL/pgSQL e C. |
| trigger | Oggetto Oracle utilizzato per controllare l'implementazione di DML nelle tabelle. | trigger | Simile a Oracle. |
| PFILE/SPFILE | I parametri a livello di istanza e di database di Oracle vengono conservati in un file binario chiamato SPFILE (nelle versioni precedenti il file si chiamava PFILE), che può essere utilizzato come file di testo per impostare manualmente i parametri. |
Flag del database Cloud SQL per PostgreSQL | Puoi impostare o modificare i parametri di Cloud SQL per PostgreSQL tramite l'utilità database flags. |
| SGA/PGA/ AMM |
Parametri di memoria Oracle che controllano l'allocazione della memoria all'istanza database. | Una serie di parametri relativi alla memoria | Cloud SQL per PostgreSQL ha i propri parametri di memoria. Alcuni parametri simili sono shared_buffers, temp_buffers e
work_mem. In Cloud SQL per PostgreSQL, questi parametri
sono predefiniti dal tipo di istanza scelto e il valore cambia
di conseguenza. Puoi modificare alcuni di questi parametri utilizzando l'utilità di flag del database. |
| buffer cache | Riduce le operazioni di I/O SQL recuperando i dati memorizzati nella cache dalla cache del buffer. I parametri di memoria possono essere gestiti a livello di database e di sessione tramite gli indizi di query. | Funzionalità simili | La dimensione della cache del buffer di Cloud SQL per PostgreSQL è controllata dal parametro shared_buffer, che non è visibile in Cloud SQL. Cloud SQL fornisce una metrica sull'utilizzo della memoria, che viene utilizzata per determinare le dimensioni appropriate dell'istanza. |
| suggerimenti per il database | La capacità di Oracle di fornire un impatto controllato alle istruzioni SQL che influenzeranno il comportamento dell'ottimizzatore per ottenere un rendimento migliore. Oracle ha più di 50 diversi suggerimenti per i database. | Non supportato | Cloud SQL per PostgreSQL non supporta gli hint del database. In misura limitata, puoi controllare il pianificatore delle query di Cloud SQL per PostgreSQL utilizzando la sintassi JOIN esplicita. |
| RMAN | Utilità Oracle Recovery Manager. Utilizzato per eseguire il backup dei database con funzionalità estese per supportare più scenari di ripristino di emergenza e altro ancora (clonazione e così via). | Backup di Cloud SQL per PostgreSQL | Cloud SQL per PostgreSQL offre due metodi per applicare backup completi: backup automatici e on demand. |
| Data Pump (EXPDP/ IMPDP) |
Utilità per la generazione di dump Oracle che può essere utilizzata per molte funzionalità, come esportazione/importazione, backup del database (a livello di schema o oggetto), metadati dello schema, generazione di file SQL dello schema e altro ancora. | Esportazione/importazione di Cloud SQL per PostgreSQL | Cloud SQL per PostgreSQL offre due formati di esportazione/importazione
verso e da bucket Cloud Storage: SQL e CSV. In alternativa, puoi connetterti all'istanza del database utilizzando utilità di esportazione/importazione come pg_dump. |
| SQL*Loader | Strumento che consente di caricare dati da file esterni, come file di testo, file CSV e altro ancora. | psql \copy |
Il comando \copy
nel client psql ti consente di caricare file di testo, CSV o binari (Oracle supporta formati di file aggiuntivi) in una tabella di database con una struttura corrispondente. |
| Data Guard | Soluzione di disaster recovery di Oracle che utilizza un'istanza di standby, consentendo agli utenti di eseguire operazioni READ dall'istanza di standby. |
Elevata disponibilità e replica di Cloud SQL per PostgreSQL | Per eseguire il ripristino di emergenza o l'alta disponibilità,
Cloud SQL per PostgreSQL offre l'architettura della replica di failover
e per le operazioni di sola lettura (separazione READ/WRITE)
utilizzando la replica di lettura. |
| Active Data Guard/ GoldenGate |
Le principali soluzioni di replica di Oracle, che possono essere utilizzate per più scopi, ad esempio come standby (DR), istanze di sola lettura, replica bidirezionale (multi-master), data warehousing e altro ancora. | Replica di lettura Cloud SQL per PostgreSQL | Replica di lettura di Cloud SQL per PostgreSQL per implementare il clustering con separazione LETTURA/SCRITTURA. Al momento non è supportata la configurazione multimaster, ad esempio la replica bidirezionale GoldenGate o la replica eterogenea. |
| RAC | Oracle Real Application Cluster. Soluzione di clustering proprietaria di Oracle per fornire alta disponibilità tramite il deployment di più istanze di database con una singola unità di archiviazione. | Non supportato | Cloud SQL per PostgreSQL non supporta un'architettura multi-master. Cloud SQL per PostgreSQL offre alta disponibilità tramite un'istanza di standby e una maggiore scalabilità di lettura tramite le repliche di lettura. |
| Controllo della rete/del cloud (OEM) | Software Oracle per la gestione e il monitoraggio di database e altri servizi correlati in formato di applicazione web. Questo strumento è utile per l'analisi del database in tempo reale per comprendere i carichi di lavoro elevati. | Google Cloud console Cloud Monitoring |
Utilizza Cloud SQL per PostgreSQL per il monitoraggio, inclusi grafici dettagliati basati su tempo e risorse. Utilizza Cloud Monitoring anche per memorizzare metriche di monitoraggio e analisi dei log specifiche di Cloud SQL per PostgreSQL per funzionalità di monitoraggio avanzate. |
| Log REDO | Log delle transazioni Oracle costituiti da due o più file definiti preallocati che archiviano tutte le modifiche dei dati man mano che si verificano. Lo scopo principale del log di reimpostazione è proteggere il database in caso di errore dell'istanza. | Log WAL | Cloud SQL per PostgreSQL utilizza il log write-ahead (WAL) in modo che le modifiche ai file di dati vengano svuotate nell'archiviazione permanente per consentire il recupero in caso di arresto anomalo. |
| archiviazione dei log | I log archiviati forniscono supporto per le operazioni di backup e replica e altro ancora. Oracle scrive nei log di archivio (se abilitati) dopo ogni operazione di trasferimento del log di redo. | Archiviazione WAL | Implementazione della conservazione dei log WAL in Cloud SQL per PostgreSQL. L'archiviazione WAL viene utilizzata e abilitata con il recupero point-in-time. |
| file di controllo | Il file di controllo Oracle contiene informazioni sul database, ad esempio file di dati, nomi di log di ripetizione, posizioni, numero di sequenza del log corrente e informazioni sul checkpoint dell'istanza. | PGDATA and pg_control
|
L'architettura di Cloud SQL per PostgreSQL non condivide un concetto equivalente a un file di controllo Oracle. I file relativi al database sono organizzati
in una directory comunemente denominata PGDATA. Le informazioni WAL
relative a record e checkpoint vengono archiviate in
pg_control. |
| SCN (Numero della modifica di sistema) | L'SCN indica un punto in tempo specifico in un database Oracle. | Numero di sequenza di log (LSN) | L'equivalente di Cloud SQL per PostgreSQL è l'LSN. Come gli SCN, gli LSN aumentano in modo monotono nel tempo. |
| AWR | Oracle AWR (Automatic Workload Repository) è un report dettagliato che fornisce informazioni dettagliate sul rendimento dell'istanza del database Oracle ed è considerato uno strumento DBA per la diagnostica del rendimento. | Raccoglitore di statistiche | Cloud SQL per PostgreSQL non ha un report equivalente all'AWR di Oracle, ma PostgreSQL raccoglie i dati sulle prestazioni raccolti dal collector statistiche. Le statistiche raccolte vengono esposte tramite le visualizzazioni pg_stat_* e pg_statio_*. |
DBMS_SCHEDULER
|
Utilità Oracle utilizzata per impostare e temporizzare operazioni predefinite. | Non supportato | Cloud SQL per PostgreSQL non fornisce un'utilità di pianificazione integrata. Google Cloud fornisce Cloud Scheduler, che consente di pianificare attività di database come le esportazioni. |
| Crittografia trasparente dei dati | Cripta i dati archiviati sui dischi come protezione dei dati at-rest. | Advanced Encryption Standard di Cloud SQL | Cloud SQL per PostgreSQL utilizza l'Advanced Encryption Standard (AES-256) a 256 bit per proteggere i dati a riposo e in transito. |
| Compressione avanzata | Per migliorare l'impronta di archiviazione del database, ridurre i costi di archiviazione e migliorare le prestazioni del database, Oracle fornisce funzionalità di compressione avanzata dei dati (tabelle/indici). | TOAST | Sebbene non sia direttamente paragonabile alla compressione avanzata di Oracle, Cloud SQL per PostgreSQL utilizza un'infrastruttura chiamata TOAST per comprimere in modo automatico e trasparente i dati di lunghezza variabile che sono troppo grandi per essere inseriti in una singola pagina di dati. |
| SQL Developer | Interfaccia utente grafica SQL gratuita di Oracle per la gestione ed esecuzione di istruzioni SQL e PL/SQL. | pgAdmin | Interfaccia utente grafica SQL gratuita di Cloud SQL per PostgreSQL per gestire ed eseguire istruzioni di codice SQL e PostgreSQL. |
| Log degli avvisi | Il log principale di Oracle per le operazioni e gli errori generali del database. | Report e log degli errori PostgreSQL | Utilizza Logs Viewer di Cloud Logging per ispezionare i log degli errori di PostgreSQL. |
| Tabella DUAL | Tabella speciale Oracle per il recupero di valori di pseudocolonne come
SYSDATE o
USER. |
Non esiste | Cloud SQL per PostgreSQL consente di omettere le clausole FROM
dalle istruzioni SQL. Ad esempio:SELECT NOW();
è un'istruzione valida in PostgreSQL. |
| tabella esterna | Oracle consente agli utenti di creare tabelle esterne con i dati di origine in file al di fuori del database. | Non supportato | In quanto servizio gestito, Cloud SQL per PostgreSQL non espone il
sistema file sottostante dell'host che esegue l'istanza del database. Come soluzione alternativa, puoi importare i dati di origine in una tabella PostgreSQL per eseguire query sui dati. |
| Listener | Processo di rete Oracle incaricato di ascoltare le connessioni al database in arrivo. | Reti autorizzate Cloud SQL | Cloud SQL per PostgreSQL accetta le connessioni da origini remote se consentite nella pagina di configurazione delle reti autorizzate di Cloud SQL. |
| TNSNAMES | File di configurazione di rete Oracle che definisce gli indirizzi del database per stabilire connessioni utilizzando gli alias di connessione. | Non esiste | Cloud SQL per PostgreSQL accetta connessioni esterne utilizzando il nome della connessione dell'istanza Cloud SQL o l'indirizzo IP privato/pubblico. Cloud SQL Proxy è un metodo di accesso sicuro aggiuntivo per connettersi a Cloud SQL per PostgreSQL senza dover consentire indirizzi IP specifici o configurare SSL. |
| Porta predefinita dell'istanza | 1521 | Porta predefinita dell'istanza | 5432 |
| Link al database | Oggetti dello schema Oracle che possono essere utilizzati per interagire con gli oggetti del database locale/remoto. | Foreign Data Wrapper (FDW) | L'estensione postgres_fdw in Cloud SQL per PostgreSQL consente di esporre le tabelle di altri database PostgreSQL ("estranei") come tabelle "estranee" nel database corrente. Queste tabelle sono quindi disponibili per l'utilizzo, quasi come se fossero tabelle locali. |
Differenze nella terminologia tra Oracle 12c e Cloud SQL per PostgreSQL
| Oracle 12c | Descrizione | Cloud SQL per PostgreSQL | Differenze principali |
|---|---|---|---|
| Istanza | La funzionalità multi-tenant introdotta in Oracle 12c consente a un'istanza di contenere più database come database modulari (PDB), a differenza di Oracle 11g, in cui un'istanza Oracle può ospitare un singolo database. | Istanza | Un'istanza Cloud SQL per PostgreSQL contiene esattamente un cluster di database. Un cluster di database è una raccolta di database archiviati in un'area di dati comune. |
| CDB | Un database contenitore multitenant (CDB) può supportare uno o più PDB, mentre è possibile creare oggetti globali CDB (che interessano tutti i PDB), come i ruoli. | Istanza PostgreSQL | L'istanza Cloud SQL per PostgreSQL è paragonabile al CDB Oracle. Entrambi forniscono un livello di sistema per i database ospitati. |
| PDB | I database pluggable (PDB) possono essere utilizzati per isolare i servizi e le applicazioni tra loro e possono essere utilizzati come raccolta portatile di schemi. | Database/ schemi PostgreSQL |
Un database Cloud SQL per PostgreSQL può servire più servizi e applicazioni, nonché molti utenti di database. |
| Sequenze di sessioni | A partire da Oracle 12c, le sequenze possono essere create a livello di sessione (restituisce valori univoci solo all'interno di una sessione) o a livello globale (ad esempio, quando si utilizzano tabelle temporanee). | Sequenza temporanea | La sequenza temporanea viene creata per la sessione del database corrente e viene eliminata automaticamente all'uscita dalla sessione. |
| Colonne di identità | Il tipo IDENTITY di Oracle 12c genera una sequenza e la associa a una colonna della tabella senza dover creare manualmente un oggetto sequenza distinto. |
Colonna SERIAL | Se definisci il tipo di dati di una colonna come SERIAL, Cloud SQL per PostgreSQL
crea automaticamente una sequenza e compila il valore della colonna utilizzandola
quando vengono inserite nuove righe nella tabella. |
| Sharding | L'implementazione di sharding di Oracle è una soluzione in cui un database Oracle viene suddiviso in più database più piccoli (shard) per consentire scalabilità, disponibilità e distribuzione geografica per gli ambienti OLTP. | Non supportato (come funzionalità) | Cloud SQL per PostgreSQL non dispone di una funzionalità di suddivisione equivalente. Lo sharding può essere implementato utilizzando Cloud SQL per PostgreSQL (come piattaforma di dati) con un livello di applicazione di supporto. |
| Database in memoria | Oracle fornisce una suite di funzionalità che possono migliorare le prestazioni del database per OLTP e per carichi di lavoro misti. | Non supportato | Cloud SQL per PostgreSQL non ha una funzionalità equivalente integrata. Tuttavia, in alternativa puoi utilizzare il nostro servizio Redis gestito Memorystore. |
| Oscuramento | Nell'ambito delle funzionalità di sicurezza avanzate di Oracle, l'oscuramento può eseguire il mascheramento delle colonne per impedire il recupero di dati sensibili da parte di utenti e applicazioni. | Non supportato | Cloud SQL per PostgreSQL non ha una funzionalità equivalente integrata. Tuttavia, la protezione dei dati sensibili può essere utilizzata per anonimizzare i dati sensibili. |
Funzionalità
Sebbene i database Oracle 11g/12c e Cloud SQL per PostgreSQL siano basati su architetture diverse (infrastruttura e linguaggi procedurali estesi), entrambi condividono gli stessi aspetti fondamentali di un sistema di database relazionale. supportano oggetti database, carichi di lavoro di concorrenza multiutente e transazioni con proprietà ACID. Gestiscono inoltre i conflitti di blocco con più livelli di isolamento (in base alle esigenze dell'applicazione) e soddisfano i requisiti delle applicazioni sia per le operazioni di Online Transactional Processing (OLTP) sia per l'Online Analytical Processing (OLAP).
La sezione seguente fornisce una panoramica di alcune delle principali differenze funzionali tra Oracle e Cloud SQL per PostgreSQL. In alcuni casi, se è ritenuto necessario evidenziare le differenze, la sezione include confronti tecnici dettagliati.
Creazione e visualizzazione di database esistenti
| Oracle 11g/12c | Cloud SQL per PostgreSQL 12 |
|---|---|
In genere, per creare i database e visualizzare quelli esistenti, utilizzi l'utilità Oracle
Database
Creation Assistant (DBCA). I database o le istanze creati manualmente richiedono la specifica di parametri aggiuntivi:SQL> CREATE DATABASE ORADB
|
Utilizza un'istruzione del tipo CREATE DATABASE Name;, come показано в этом примере:postgres=> CREATE DATABASE PGSQLDB;
|
| Oracle 12c | Cloud SQL per PostgreSQL 12 |
In Oracle 12c, puoi creare PDB dal seed, da un modello di database di container (CDB) o clonando un PDB da un PDB esistente. Utilizza diversi parametri:SQL> CREATE PLUGGABLE DATABASE PDB
|
Utilizza un'istruzione del tipo CREATE DATABASE Name;, come показано в этом примере:postgres=> CREATE DATABASE PGSQLDB;
|
Elenca tutti i PDB:SQL> SHOW is PDBS; |
Elenca tutti i database esistenti:postgres=> \list |
Connettiti a un altro PDB:SQL> ALTER SESSION SET CONTAINER=pdb; |
Connettiti a un altro database:postgres=> \connect databaseName;
In alternativa: postgres=> \c databaseName |
Apri o chiudi un PDB specifico (aperto/sola lettura):SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
Non supportato per un singolo database. Tutti i database si trovano nella stessa istanza Cloud SQL per PostgreSQL, pertanto sono tutti attivi o tutti inattivi. |
Gestione di un database tramite la Google Cloud console
Nella Google Cloud console, vai a Database>SQL>Instance>(Seleziona la tua istanza PostgreSQL)>Database.
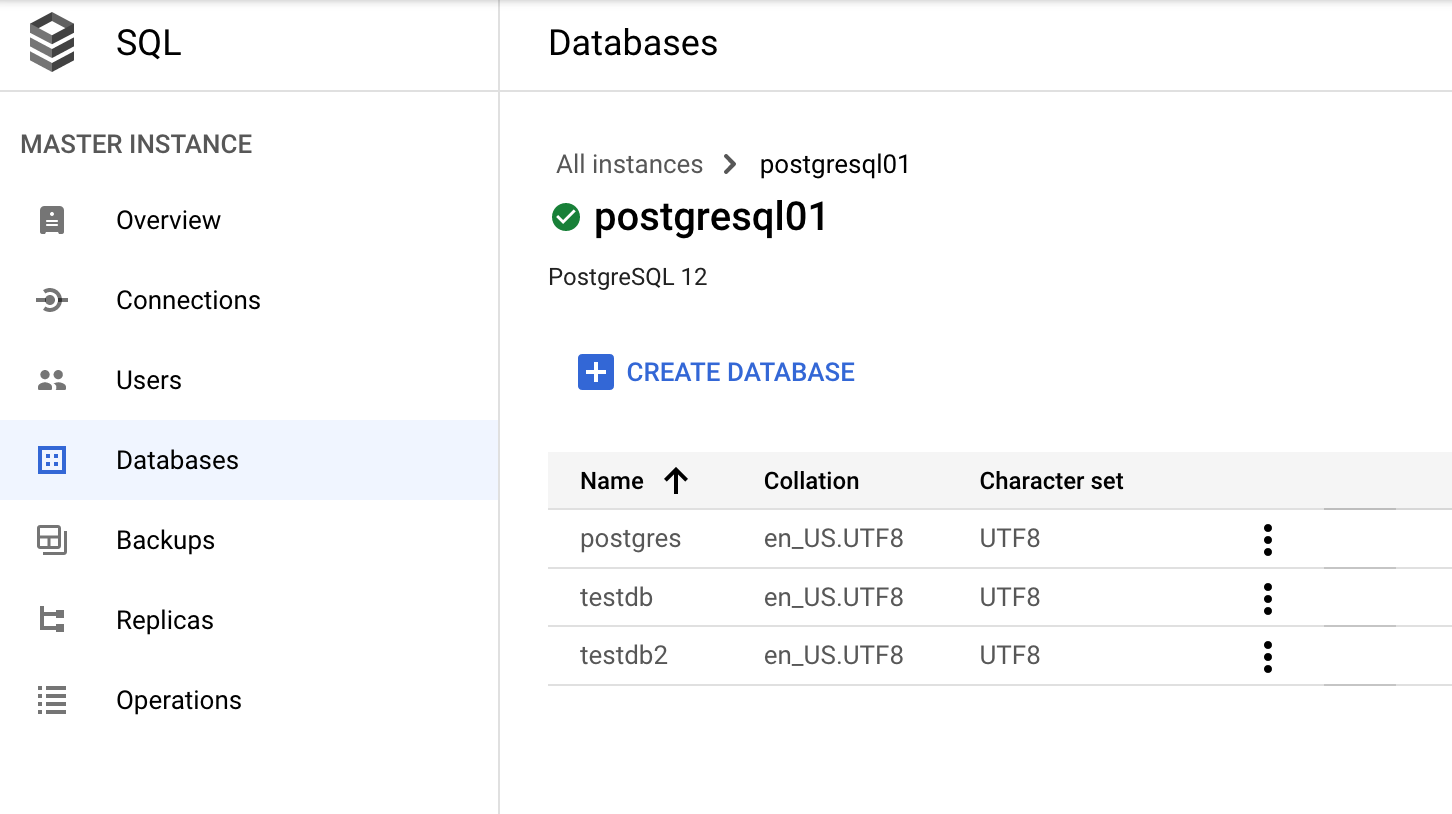
Dizionario di dati e visualizzazioni dinamiche
I database Oracle forniscono un dizionario di dati insieme a viste dinamiche sul rendimento
(V$ View) che facilitano una serie di attività di monitoraggio e manutenzione del database. Il dizionario dei dati memorizza tutte le informazioni utilizzate per gestire gli oggetti nel database, mentre le visualizzazioni del rendimento dinamico contengono molte informazioni relative al rendimento del database. Queste viste vengono aggiornate continuamente durante l'esecuzione del database.
Al contrario, PostgreSQL fornisce diversi cataloghi di metadati che hanno un scopo simile a quello del dizionario di dati e delle visualizzazioni del rendimento dinamiche di Oracle:
- Catalogo di sistema: metadati su tutti gli oggetti del database.
- Visualizzazioni della raccolta delle statistiche: generazione di report sulle attività di PostgreSQL.
- Visualizzazioni dello schema di informazioni: metadati su tutti gli oggetti del database registrati in base allo standard ANSI SQL.
Visualizzazione dei metadati e delle visualizzazioni dinamiche del sistema
Questa sezione fornisce una panoramica di alcune delle tabelle dei metadati più comuni e delle viste dinamiche di sistema utilizzate in Oracle e dei relativi oggetti database in Cloud SQL per PostgreSQL versione 12.
Oracle fornisce centinaia di tabelle e viste dei metadati di sistema (in determinati schemi di sistema, ad esempio SYS o SYSTEM), mentre PostgreSQL ne contiene solo alcune decine. Per ogni caso, può essere presente più di un oggetto database, ciascuno con uno scopo specifico.
Oracle fornisce diversi livelli di oggetti metadati, ognuno dei quali richiede diversi privilegi:
USER_TableName: visibile dall'utente.ALL_TableName: visibile a tutti gli utenti.DBA_TableName: visibile solo agli utenti con il privilegio DBA, comeSYSeSYSTEM.
Per le visualizzazioni del rendimento dinamico, Oracle utilizza i prefissi V$/GV$. Al contrario,
le visualizzazioni e i metadati di Cloud SQL per PostgreSQL si trovano negli schemi information_schema
e pg_catalog.
| Tipo di metadati | Tabella/visualizzazione Oracle | Tabella/vista/query Cloud SQL per PostgreSQL |
|---|---|---|
| Sessioni aperte | V$SESSION |
pg_catalog.pg_stat_activity |
| Transazioni in esecuzione | V$TRANSACTION |
Non supportati. Come soluzione alternativa, pg_locks fornisce un elenco di transazioni aperte che detengono uno o più blocchi. |
| Oggetti di database | DBA_OBJECTS |
pg_catalog.pg_class |
| Tabelle | DBA_TABLES |
pg_catalog.pg_tables |
| Colonne della tabella | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| Privilegi per tabelle e colonne | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| Partizioni | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| Visualizzazioni | DBA_VIEWS |
pg_catalog.pg_views |
| Vincoli | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| Indici | DBA_INDEXES |
pg_catalog.pg_index |
| Viste materializzate | DBA_MVIEWS |
pg_catalog.pg_matviews |
| Stored procedure | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Funzioni memorizzate | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Trigger | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| Utenti | DBA_USERS |
pg_catalog.pg_user |
| Privilegi utente | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| Job/ pianificazione |
DBA_JOBS |
Non supportati. |
| Spazi dati | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| File di dati | DBA_DATA_FILES |
Non supportati. |
| Sinonimi | DBA_SYNONYMS |
Non supportati. |
| Sequenze | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| Link ai database | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| Statistiche | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| Serrature | DBA_LOCK |
pg_catalog.pg_locks |
| Parametri del database | V$PARAMETER |
pg_catalog.pg_settings
show |
| Segmenti | DBA_SEGMENTS |
Non supportati. |
| Ruoli | DBA_ROLES |
pg_catalog.pg_roles |
| Cronologia sessioni | V$ACTIVE_SESSION_HISTORY |
Non supportati. |
| Versione | V$VERSION |
select version(); |
| Eventi di attesa | V$WAITCLASSMETRIC |
Non supportati. |
| Ottimizzazione e analisi di SQL |
V$SQL |
Non supportati. |
| Ottimizzazione della memoria dell'istanza |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
Non integrato in Cloud SQL per PostgreSQL. Utilizza l'estensione pg_buffercache per esaminare la cache del buffer condivisa in tempo reale. |
Parametri di sistema
Sia i database Oracle sia i database Cloud SQL per PostgreSQL possono essere configurati in modo specifico per ottenere determinate funzionalità oltre la configurazione predefinita. Per modificare i parametri di configurazione in Oracle, sono necessarie alcune autorizzazioni di amministrazione (principalmente le autorizzazioni utente SYS/SYSTEM).
Di seguito è riportato un esempio di modifica della configurazione di Oracle mediante l'istruzione
ALTER SYSTEM. In questo esempio, l'utente modifica il parametro "tentativi massimi per accessi non riusciti" solo a livello di configurazione spfile (con la modifica valida solo dopo un riavvio):
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
Nell'esempio seguente, l'utente richiede di visualizzare il valore del parametro Oracle:
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
L'output è simile al seguente:
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
La modifica del parametro Oracle funziona in tre ambiti:
- SPFILE: le modifiche ai parametri vengono scritte in
spfiledi Oracle, con un riavvio dell'istanza necessario per l'applicazione del parametro. - MEMORIA: le modifiche ai parametri vengono applicate solo nel livello di memoria, mentre non è consentita alcuna modifica dei parametri statici.
- ENTRAMBI: le modifiche ai parametri vengono applicate sia nel file del parametro del server sia nella memoria dell'istanza, dove non è consentita alcuna modifica dei parametri statici.
Flag di configurazione di Cloud SQL per PostgreSQL
Puoi modificare i parametri di sistema di Cloud SQL per PostgreSQL utilizzando i flag di configurazione nella Google Cloud console, in gcloud CLI o in CURL. Consulta l'elenco completo di tutti i parametri supportati da Cloud SQL per PostgreSQL che puoi modificare.
I parametri PostgreSQL possono essere suddivisi in diversi ambiti:
- Parametri dinamici:possono essere modificati in fase di esecuzione.
- Parametri del database:si applicano solo a un database specifico all'interno di un'istanza PostgreSQL.
- Parametri di ruolo:si applicano solo a un ruolo di database specifico.
- Parametri statici:richiedono il riavvio dell'istanza per essere applicati.
- Parametri sessione:possono essere modificati a livello di sessione solo per la durata della sessione corrente, in modo isolato dalle altre sessioni.
- Parametri globali:avranno un effetto globale su tutte le sessioni attuali e future.
Esempi di modifica dei parametri di Cloud SQL per PostgreSQL
Console
Utilizza la Google Cloud console per attivare il parametro log_connections.
Vai alla pagina Modifica istanza di Cloud Storage.
In Flag, fai clic su Aggiungi elemento e cerca
log_connectionscome показано во скриншоте ниже.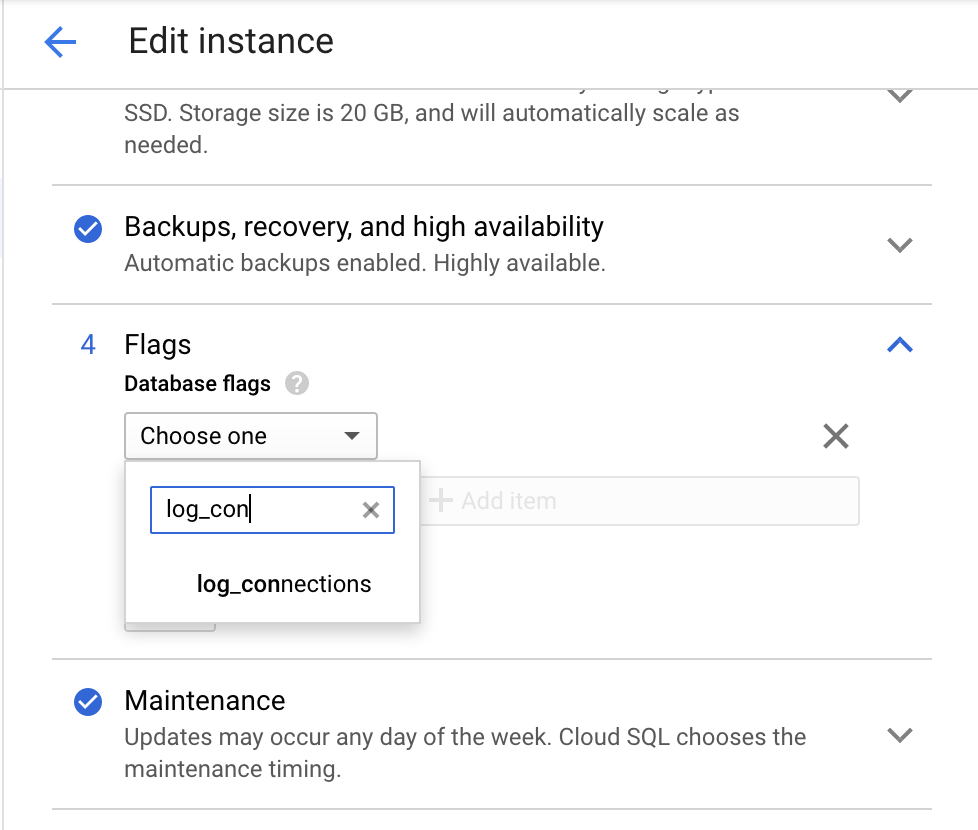
gcloud
- Utilizza gcloud CLI per attivare il parametro
log_connections:
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
L'output è il seguente:
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL per PostgreSQL
Imposta timezone a livello di sessione. Questa alterazione rimane in vigore per la sessione corrente e vale solo per la durata della sessione.
Mostra il parametro di configurazione
timezone:postgres=> SHOW timezone;Viene visualizzato il seguente output, dove
timezoneèset to UTC:TimeZone ---------- UTC (1 row)
Imposta
timezonesu UTC-9:postgres=> SET timezone='UTC-9';Mostra il parametro di configurazione
timezone:postgres> SHOW timezone;Viene visualizzato il seguente output, in cui
timezoneè impostato suUTC-9:TimeZone ---------- UTC-9 (1 row)
Transazioni e livelli di isolamento
Questa sezione descrive le principali differenze nell'esecuzione delle transazioni e nei livelli di isolamento tra Oracle e Cloud SQL per PostgreSQL.
Modalità di commit
Per impostazione predefinita, Oracle funziona in modalità di commit non automatico, in cui ogni transazione DML deve essere determinata con istruzioni COMMIT/ROLLBACK. Una delle differenze fondamentali tra Oracle e PostgreSQL è che PostgreSQL emette implicitamente un COMMIT dopo ogni comando che non segue START TRANSACTION (o BEGIN). Questo è noto anche in alcuni altri motori del database come commit automatico.
Sebbene l'commit automatico sia attivo per impostazione predefinita, può essere disattivato a livello di sessione utilizzando SET AUTOCOMMIT OFF.
Livelli di isolamento
Lo standard ANSI/ISO SQL (SQL:92) definisce quattro livelli di isolamento. Ogni livello offre un approccio diverso per la gestione dell'esecuzione simultanea delle transazioni del database:
- Lettura non confermata: una transazione attualmente in fase di elaborazione può vedere i dati non confermati creati dall'altra transazione. Se viene eseguito un rollback, tutti i dati vengono ripristinati allo stato precedente.
- Lettura confermata:una transazione vede solo le modifiche ai dati che sono state confermate, non sono possibili modifiche non confermate ("letture sporche").
- Lettura ripetibile:una transazione può visualizzare le modifiche apportate dall'altra transazione solo dopo che entrambe le transazioni hanno emesso un
COMMITo dopo che entrambe sono state annullate. - Serializable:il livello di isolamento più rigoroso/sicuro. Questo livello blocca tutti i record a cui viene eseguito l'accesso e la risorsa in modo che i record non possano essere aggiunti alla tabella.
I livelli di isolamento delle transazioni gestiscono la visibilità dei dati modificati come li vedono altre transazioni in esecuzione. Inoltre, quando più transazioni contemporaneamente accedono agli stessi dati, il livello di isolamento delle transazioni selezionato influisce sul modo in cui le diverse transazioni interagiscono.
Oracle supporta i seguenti livelli di isolamento:
- Lettura confermata (valore predefinito)
- Serializable
- In sola lettura (non fa parte dello standard SQL ANSI/ISO (SQL:92)
Controllo della concorrenza multiversione (MVCC) di Oracle:
- Oracle utilizza il meccanismo MVCC per fornire coerenza di lettura automatica in tutto il database e in tutte le sessioni.
- Oracle si basa sul numero di modifica di sistema (SCN) della transazione corrente per ottenere una vista coerente del database. Pertanto, tutte le query del database restituiscono solo i dati committati rispetto all'SCN al momento dell'esecuzione della query.
- I livelli di isolamento possono essere modificati a livello di transazione e sessione.
Ecco un esempio di impostazione dei livelli di isolamento:
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
Cloud SQL per PostgreSQL supporta i seguenti quattro livelli di isolamento delle transazioni specificati nello standard ANSI SQL:92:
- Lettura non confermata (equivalente a Lettura confermata)
- Lettura confermata (valore predefinito)
- Lettura ripetibile
- Serializable
Il livello di isolamento predefinito di Cloud SQL per PostgreSQL è READ COMMITTED.
Questi livelli di isolamento possono essere modificati a livello SESSION, TRANSACTION e INSTANCE.
Per verificare i livelli di isolamento attuali sia a livello di TRANSACTION sia a livello di SESSION,
utilizza la seguente istruzione:
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
L'output è il seguente:
current_setting ----------------- read committed (1 row)
Puoi modificare la sintassi del livello di isolamento nel seguente modo:
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
Puoi anche modificare il livello di isolamento a livello di SESSIONE:
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
L'output è il seguente:
current_setting ----------------- repeatable read (1 row)
Il livello di isolamento a livello di INSTANCE viene controllato utilizzando il
flag di database
default_transaction_isolation. Puoi verificare questo utilizzando la seguente dichiarazione:
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
L'output è il seguente:
default_transaction_isolation ------------------------------- repeatable read (1 row)
Passaggi successivi
- Scopri di più sugli account utente di Cloud SQL per PostgreSQL.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.