이 문서는 PostgreSQL용 Cloud SQL 버전 12로 Oracle® 11g/12c 데이터베이스 마이그레이션 계획 및 수행과 관련된 핵심 정보와 지침을 제공하는 시리즈의 일부입니다. 이 시리즈에는 소개 설정 부분 외에도 다음 부분이 포함됩니다.
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 용어 및 기능(이 문서)
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 데이터 유형, 사용자, 테이블
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 쿼리, 저장 프로시저, 함수, 트리거
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 보안, 작업, 모니터링, 로깅
- Oracle 데이터베이스 사용자 및 스키마를 PostgreSQL용 Cloud SQL로 마이그레이션
용어
이 섹션에서는 Oracle과 PostgreSQL용 Cloud SQL 간 데이터베이스 용어의 유사점과 차이점을 자세히 설명합니다. 또한 각 데이터베이스 플랫폼의 핵심 요소를 검토하고 비교합니다. 아키텍처 차이에 따라 Oracle 버전 11g와 12c를 구분하여 비교했습니다. 예를 들어 Oracle 12c에는 멀티 테넌트 기능이 있습니다. 여기에서 참조된 PostgreSQL용 Cloud SQL 버전은 12입니다.
이 섹션에서는 Oracle과 PostgreSQL용 Cloud SQL의 주요 용어 차이점을 설명합니다. 하위 수준 설명은 이 문서의 뒷부분에서 설명합니다.
| Oracle 11g | 설명 | PostgreSQL용 Cloud SQL | 주요 차이점 |
|---|---|---|---|
| 인스턴스 | 하나의 Oracle 11g 인스턴스는 하나의 데이터베이스만 보유할 수 있습니다. | 인스턴스 | PostgreSQL용 Cloud SQL 인스턴스 하나에는 데이터베이스 클러스터 하나만 있습니다. 데이터베이스 클러스터는 공통 데이터 영역에 저장되는 데이터베이스 모음입니다. |
| 데이터베이스 | 하나의 데이터베이스는 단일 인스턴스에 해당합니다. 데이터베이스 이름은 인스턴스 이름과 동일합니다. | 데이터베이스 | 여러 데이터베이스 또는 단일 데이터베이스가 여러 애플리케이션을 제공합니다. |
| schema | 스키마와 사용자는 데이터베이스 객체의 소유자로 간주되므로 동일한 의미로 사용됩니다. 스키마를 지정하거나 스키마에 할당하지 않고 사용자를 만들 수 있습니다. | schema | 데이터베이스에는 스키마가 한 개 이상 포함됩니다. 테이블과 같은 객체는 스키마 내에 포함됩니다. 동일한 객체 이름을 충돌 없이 동일한 데이터베이스 내 다른 스키마에서 사용할 수 있습니다. |
| 사용자 | 스키마와 사용자는 데이터베이스 객체의 소유자로 간주되므로 동일한 의미로 사용됩니다(예: 인스턴스 → 데이터베이스 → 스키마/사용자 → 데이터베이스 객체). | 역할 | 역할은 설정 방법에 따라 데이터베이스 사용자나 데이터베이스 사용자 그룹일 수 있습니다. 테이블과 같은 데이터베이스 객체를 소유할 수 있습니다.
역할 범위는 전체 데이터베이스 클러스터로 지정되며 역할의 멤버십을 다른 역할에 부여할 수 있습니다. |
| 역할 | 그룹으로 연결할 수 있고 데이터베이스 사용자에게 할당할 수 있는 데이터베이스 권한 집합으로 정의됩니다. | ||
| 관리자/ 시스템 사용자 |
최고 수준의 액세스 권한을 갖는 Oracle 관리자입니다.SYS
|
cloudsqlsuperuser | PostgreSQL용 Cloud SQL은 기본 postgres 사용자와 함께 제공됩니다. 이 사용자는 cloudsqlsuperuser 역할의 일부이며 CREATEROLE, CREATEDB, LOGIN과 같은 속성(권한)을 가집니다. PostgreSQL용 Cloud SQL은 관리형 서비스이므로 고급 권한이 필요한 특정 시스템 프로시저와 테이블에 대한 액세스를 제한합니다. 따라서 postgres 사용자에게는 SUPERUSER 또는 REPLICATION 속성이 없습니다. superuser 속성이 있는 사용자를 만들거나 이 사용자에 액세스할 수 없습니다. |
| 사전/ 메타데이터 |
Oracle은 다음 메타데이터를 사용합니다.USER_TableName
|
사전/ 메타데이터 |
PostgreSQL용 Cloud SQL은 ANSI 표준 INFORMATION_SCHEMA를 사용하여 사전과 메타데이터 정보를 제공합니다. |
| 시스템 동적 뷰 | Oracle 동적 뷰입니다.V$ViewName |
시스템 동적 뷰 |
PostgreSQL용 Cloud SQL에는 다음과 같은 동적 통계 뷰가 있습니다.pg_stat_ViewNamepg_statio_ViewName |
| 테이블스페이스 | Oracle 데이터베이스의 기본 논리 스토리지 구조로, 각 테이블스페이스는 하나 이상의 데이터 파일을 보유할 수 있습니다. | 테이블스페이스 | PostgreSQL용 Cloud SQL에서 데이터 파일은 사전 정의된 디렉터리 구조를 통해 데이터베이스 클러스터의 데이터 디렉터리 PGDATA에 함께 저장됩니다. PostgreSQL용 Cloud SQL의 테이블스페이스는 데이터 파일을 저장할 수 있는 파일 시스템의 커스텀 위치를 정의하는 메커니즘을 제공합니다.PostgreSQL용 Cloud SQL은 관리형 서비스이므로 Google Cloud는 호스트 머신의 기본 파일 시스템을 자동으로 관리합니다. PostgreSQL용 Cloud SQL에서 새 테이블스페이스를 만들 수 없습니다. |
| 데이터 파일 | 데이터를 보유하고 있는 Oracle 데이터베이스의 물리적 요소는 특정 테이블스페이스에서 정의됩니다. 단일 데이터 파일은 초기 크기 및 최대 크기로 정의되며 여러 테이블의 데이터를 보유할 수 있습니다. Oracle 데이터 파일은 .dbf 서픽스를 사용합니다(필수 아님). |
데이터 파일 | PostgreSQL용 Cloud SQL은 각 데이터베이스를 자체 하위 디렉터리에 있는 데이터베이스 클러스터에 저장합니다. 데이터베이스에 있는 각 테이블과 색인은 하위 디렉터리의 개별 파일에 저장됩니다. |
| 시스템 테이블스페이스 | 전체 Oracle 데이터베이스의 데이터 사전 테이블 및 뷰 객체를 포함합니다. | 존재하지 않음 | 데이터 사전 테이블과 뷰 객체는 사전 정의된 디렉터리 구조를 통해 데이터베이스 클러스터의 데이터 디렉터리 PGDATA에 있는 INFORMATION_SCHEMA에 저장됩니다. |
| 임시 테이블스페이스 | 세션 기간 동안 유효한 스키마 객체를 포함합니다. 또한 서버 메모리에 맞지 않는 작업은 실행되지 않습니다. |
임시 파일 | 임시 파일은 서버 메모리에 맞지 않는 실행 중인 작업을 저장하는 데 사용됩니다. 이러한 파일은 pgsql_tmp 디렉터리에 저장되며 SQL 문이 실행되는 동안에만 생성됩니다. |
| 테이블스페이스 실행취소 | 자동 실행취소 관리 모드(기본값)에서 데이터베이스를 실행할 때 Oracle에서 롤백 작업을 관리하는 데 사용하는 특수 유형의 시스템 영구 테이블스페이스입니다. |
존재하지 않음 | 롤백 작업이 허용되도록 PostgreSQL용 Cloud SQL은 테이블의 데이터 파일 자체 내에서 업데이트되거나 삭제된 행을 보관합니다. 청소는 업데이트되거나 삭제된 행에서 사용하는 디스크 공간을 복구하거나 재사용하는 프로세스입니다. |
| ASM | Oracle Automatic Storage Management는 고성능의 통합 데이터베이스 파일 시스템 및 디스크 관리자이며, ASM으로 구성된 Oracle 데이터베이스에서 자동으로 실행됩니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL은 OS 파일 시스템을 사용하여 데이터 파일을 저장하며 Oracle ASM은 없습니다. 하지만 PostgreSQL용 Cloud SQL은 스토리지 자동 증가, 성능, 확장성과 같은 스토리지 자동화를 제공하는 다양한 기능을 지원합니다. |
| 테이블/뷰 | 사용자가 만든 기본 데이터베이스 객체입니다. | 테이블/뷰 | Oracle과 동일합니다. |
| 구체화된 뷰 | 특정 SQL 문으로 정의되며 특정 구성에 따라 수동이나 자동으로 새로 고칠 수 있습니다. |
구체화된 뷰 | 구체화된 뷰는 Oracle과 비슷하게 작동합니다. REFRESH
MATERIALIZED VIEW 문을 사용하여 수동으로 새로 고칩니다. |
| 시퀀스 | Oracle 고유 값 생성기입니다. | 시퀀스 | Oracle과 유사합니다. |
| 동의어 | 다른 데이터베이스 객체의 대체 식별자 역할을 하는 Oracle 데이터베이스 객체입니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL은 동의어를 제공하지 않습니다. 해결 방법으로, 적절한 권한으로 설정하는 동안 뷰를 사용할 수 있습니다. |
| 파티션 나누기 | Oracle은 대규모 테이블을 관리 가능한 작은 조각으로 분할하기 위한 여러 파티션 나누기 솔루션을 제공합니다. | 파티션 나누기 | PostgreSQL용 Cloud SQL에서는 Oracle 스타일의 선언적 파티션 나누기와 상속을 사용한 파티션 나누기를 모두 지원하므로 더욱 유연하게 파티션을 나눌 수 있습니다. |
| 플래시백 데이터베이스 | Oracle에서 독점 제공하는 기능으로, Oracle 데이터베이스를 이전 특정 시간으로 초기화하므로 실수에 의해 수정되거나 손상된 데이터를 쿼리하고 복원할 수 있습니다. | 지원되지 않음 | 대안으로 Cloud SQL 백업 및 point-in-time recovery를 사용하여 데이터베이스를 이전 상태로 복원할 수 있습니다(예: 테이블 삭제 전 복원). |
| sqlplus | 데이터베이스 인스턴스를 쿼리하고 관리하는 데 사용할 수 있는 Oracle 명령줄 인터페이스입니다. | psql | PostgreSQL용 Cloud SQL에 상응하는 쿼리 및 관리에 사용되는 명령줄 인터페이스입니다. 적절한 권한이 있는 모든 클라이언트에서 Cloud SQL에 연결할 수 있습니다. |
| PL/SQL | Oracle은 절차적 언어를 ANSI SQL로 확장했습니다. | PL/pgSQL | PostgreSQL용 Cloud SQL에는 많은 측면에서 Oracle의 PL/SQL과 비슷한 PL/pgSQL이라는 자체 절차 언어가 있습니다. 두 언어 간의 주요 차이점에 대한 요약은 Oracle PL/SQL에서 포팅을 참조하세요. |
| 패키지 및 패키지 본문 | 저장 프로시져와 함수를 동일한 논리 참조로 그룹화하는 Oracle 전용 기능입니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL은 스키마를 사용하여 함수를 구성합니다. |
| 저장 프로시져 및 함수 | PL/SQL을 사용하여 코드 기능을 구현합니다. | 저장 프로시져 및 함수 | PostgreSQL용 Cloud SQL은 PL/pgSQL 및 C와 같은 다양한 프로그래밍 언어를 사용하여 저장된 프로시저와 함수를 구현할 수 있습니다. |
| 트리거 | 테이블에서 DML 구현을 제어하는 데 사용되는 Oracle 객체입니다. | 트리거 | Oracle과 유사합니다. |
| PFILE/SPFILE | Oracle 인스턴스 수준 매개변수와 데이터베이스 수준 매개변수는 SPFILE(이전 버전에서는 PFILE)라는 바이너리 파일에 보관됩니다. 이 파일은 매개변수를 수동으로 설정할 수 있도록 텍스트 파일로 사용될 수 있습니다. |
PostgreSQL용 Cloud SQL 데이터베이스 플래그 | 데이터베이스 플래그 유틸리티를 통해 PostgreSQL용 Cloud SQL 매개변수를 설정하거나 수정할 수 있습니다. |
| SGA/PGA/ AMM |
데이터베이스 인스턴스에 할당되는 메모리를 제어하는 Oracle 메모리 파라미터입니다. | 다양한 메모리 관련 매개변수 | PostgreSQL용 Cloud SQL에는 고유한 메모리 매개변수가 있습니다. 유사한 매개변수로는 shared_buffers, temp_buffers, work_mem가 있습니다. PostgreSQL용 Cloud SQL에서 이러한 매개변수는 선택한 인스턴스 유형에 따라 사전 정의되어 있으며 이에 따라 값이 변경됩니다. 데이터베이스 플래그 유틸리티를 사용하여 일부 매개변수를 조정할 수 있습니다. |
| 버퍼 캐시 | 버퍼 캐시에서 캐시된 데이터를 검색하여 SQL I/O 작업을 줄입니다. 쿼리 힌트를 통해 데이터베이스 수준과 세션 수준에서 메모리 매개변수를 관리할 수 있습니다. | 유사한 기능 | PostgreSQL용 Cloud SQL의 버퍼 캐시 크기는 Cloud SQL에서 노출되지 않는 shared_buffer 매개변수로 제어됩니다. Cloud SQL은 인스턴스 크기를 조정하는 데 사용되는 메모리 사용량 측정항목을 제공합니다. |
| 데이터베이스 힌트 | 성능이 향상되도록 최적화 도구 동작에 영향을 주는 SQL 문에 대한 영향을 제어하는 Oracle 기능입니다. Oracle에는 50가지가 넘는 데이터베이스 힌트가 있습니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL에서는 데이터베이스 힌트를 지원하지 않습니다. 명시적 JOIN 구문을 사용하여 PostgreSQL용 Cloud SQL의 쿼리 플래너를 어느 정도 제어할 수 있습니다. |
| RMAN | Oracle 복구 관리자 유틸리티입니다. 재해 복구 등 여러 시나리오를 지원하기 위해 확장 기능으로 데이터베이스 백업을 수행하는 데 사용됩니다(클로닝 등). | PostgreSQL용 Cloud SQL 백업 | PostgreSQL용 Cloud SQL은 전체 백업을 적용하는 두 가지 방법(주문형 백업과 자동 백업)을 제공합니다. |
| 데이터 펌프 (EXPDP/ IMPDP) |
내보내기/가져오기, 데이터베이스 백업(스키마 또는 객체 수준), 스키마 메타데이터, 스키마 SQL 파일 생성 등 다양한 기능에 사용할 수 있는 Oracle 덤프 생성 유틸리티입니다. | PostgreSQL용 Cloud SQL 내보내기/가져오기 | PostgreSQL용 Cloud SQL은 Cloud Storage 버킷에서 내보내기/가져오기의 두 가지 형식(SQL 및 CSV)을 제공합니다. 또는 pg_dump와 같은 내보내기/가져오기 유틸리티를 사용하여 데이터베이스 인스턴스에 연결할 수 있습니다. |
| SQL*Loader | 텍스트 파일, CSV 파일 등과 같은 외부 파일에서 데이터를 업로드할 수 있는 도구입니다. | psql \copy |
psql 클라이언트에서 \copy 명령어를 사용하면 텍스트, CSV, 바이너리 파일(Oracle에서 추가 파일 형식 지원)을 해당 구조의 데이터베이스 테이블로 로드할 수 있습니다. |
| 데이터 가드 | 대기 인스턴스를 사용하는 Oracle 재해 복구 솔루션으로, 사용자가 대기 인스턴스에서 READ 작업을 수행할 수 있게 해줍니다. |
PostgreSQL용 Cloud SQL 고가용성 및 복제 | 재해 복구 또는 고가용성을 달성하기 위해 PostgreSQL용 Cloud SQL은 읽기 복제본을 사용하여 장애 조치 복제본 아키텍처와 읽기 전용 작업(READ/WRITE 분리)을 제공합니다. |
| 액티브 데이터 가드/ GoldenGate |
대기(DR), 읽기 전용 인스턴스, 양방향 복제(다중 마스터), 데이터 웨어하우징 등 여러 용도로 사용할 수 있는 Oracle의 기본 복제 솔루션입니다. | PostgreSQL용 Cloud SQL 읽기 복제본 | 읽기/쓰기 분리로 클러스터링을 구현하는 PostgreSQL용 Cloud SQL 읽기 복제본입니다. 현재 GoldenGate 양방향 복제 또는 이기종 복제와 같은 멀티 마스터 구성을 지원하지 않습니다. |
| RAC | Oracle Real Application Cluster를 나타냅니다. Oracle에서 독점 제공하는 클러스터링 솔루션으로, 단일 스토리지 단위로 여러 데이터베이스 인스턴스를 배포하여 고가용성을 제공합니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL은 멀티 마스터 아키텍처를 지원하지 않습니다. PostgreSQL용 Cloud SQL은 대기 인스턴스를 통해 고가용성을, 읽기 복제본을 통해 증가된 읽기 확장성을 제공합니다. |
| Grid/Cloud Control(OEM) | 데이터베이스 및 기타 관련 서비스를 웹 애플리케이션 형식으로 관리하고 모니터링하는 Oracle 소프트웨어입니다. 이 도구는 실시간 데이터베이스 분석을 통해 높은 워크로드를 파악하는 데 유용합니다. | Google Cloud 콘솔, Cloud Monitoring |
PostgreSQL용 Cloud SQL을 사용하여 시간 및 리소스 기반 그래프의 세부정보 등을 모니터링합니다. 또한 Cloud Monitoring을 사용하여 고급 모니터링 기능에 대한 특정 PostgreSQL용 Cloud SQL 모니터링 측정항목과 로그 분석을 보유합니다. |
| REDO 로그 | 데이터의 모든 변경사항을 저장하는 2개 이상의 사전 할당되고 정의된 파일로 구성된 Oracle 트랜잭션 로그입니다. redo 로그의 기본 목적은 인스턴스가 실패할 경우 데이터베이스를 보호하는 것입니다. | WAL 로그 | PostgreSQL용 Cloud SQL은 Write-Ahead Logging(WAL)을 사용하므로 데이터 파일 변경사항이 영구 스토리지로 플러시되어 장애 복구가 수행됩니다. |
| 보관처리 로그 | 보관처리 로그는 백업 및 복제 작업 등을 지원합니다. Oracle은 각 재실행 로그 전환 작업 후 보관처리 로그(사용 설정된 경우)에 씁니다. | WAL 보관처리 | PostgreSQL용 Cloud SQL는 WAL 로그를 보관합니다. WAL 보관처리는 point-in-time recovery와 함께 사용되고 사용 설정됩니다. |
| 제어 파일 | Oracle 제어 파일에는 데이터 파일, redo 로그 이름, 위치, 현재 로그 시퀀스 번호, 인스턴스 체크포인트 정보 등 데이터베이스에 대한 정보가 포함됩니다. | PGDATA and pg_control
|
PostgreSQL용 Cloud SQL 아키텍처는 Oracle 제어 파일과 동일한 개념을 공유하지 않습니다. 데이터베이스 관련 파일은 일반적으로 PGDATA라는 디렉터리에 구성됩니다. 레코드 및 체크포인트와 관련된 WAL 정보는 pg_control에 저장됩니다. |
| 시스템 변경 번호(SCN) | SCN은 Oracle 데이터베이스에서 특정 시점을 표시합니다. | 로그 시퀀스 번호(LSN) | PostgreSQL용 Cloud SQL에 상응하는 LSN입니다. SCN과 마찬가지로 LSN도 시간이 경과할수록 점차 증가합니다. |
| AWR | Oracle AWR(Automatic Workload Repository)은 Oracle 데이터베이스 인스턴스 성능에 대한 세부정보를 제공하는 상세 보고서이며 성능 진단에 사용되는 DBA 도구로 간주됩니다. | 통계 수집기 | PostgreSQL용 Cloud SQL에는 Oracle AWR에 상응하는 보고서가 없지만 PostgreSQL은 통계 수집기에서 수집된 성능 데이터를 수집합니다. 수집된 통계는 pg_stat_* 및 pg_statio_* 뷰를 통해 노출됩니다. |
DBMS_SCHEDULER
|
사전 정의된 작업을 설정하고 시간을 지정하는 데 사용되는 Oracle 유틸리티입니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL은 기본 제공 스케줄링 유틸리티를 제공하지 않습니다. Google Cloud 에서는 내보내기와 같은 데이터베이스 작업을 예약할 수 있는 Cloud Scheduler를 제공합니다. |
| 투명 데이터 암호화 | 디스크에 저장된 데이터를 저장 데이터 보호로 암호화합니다. | Cloud SQL 고급 암호화 표준 | PostgreSQL용 Cloud SQL은 저장 데이터와 전송 중 데이터를 보호할 수 있는 256비트 고급 암호화 표준(AES-256)을 사용합니다. |
| 고급 압축 | 데이터베이스 스토리지 사용 공간을 늘리고, 스토리지 비용을 줄이고, 데이터베이스 성능을 개선하기 위해 Oracle은 데이터(테이블/색인) 고급 압축 기능을 제공합니다. | 토스트 메시지 | Oracle 고급 압축과 직접 비교할 수 없지만 PostgreSQL용 Cloud SQL은 토스트 메시지라는 인프라를 사용하여 가변 길이가 너무 큰 데이터를 자동으로 투명하게 단일 데이터 페이지에 맞게 압축합니다. |
| SQL Developer | SQL과 PL/SQL 문을 관리하고 실행할 수 있는 Oracle의 무료 SQL GUI입니다. | pgAdmin | PostgreSQL용 Cloud SQL은 SQL과 PostgreSQL 코드 구문을 관리하고 실행할 수 있는 무료 SQL GUI입니다. |
| 알림 로그 | 일반적인 데이터베이스 작업과 오류에 대한 Oracle 기본 로그입니다. | PostgreSQL 오류 보고 및 로깅 | Cloud Logging의 로그 뷰어를 사용하여 PostgreSQL 오류 로그를 검사합니다. |
| DUAL 테이블 | SYSDATE 또는 USER와 같은 유사 열 값을 검색할 수 있는 Oracle 특수 테이블입니다. |
존재하지 않음 | PostgreSQL용 Cloud SQL을 사용하면 SQL 문에서 FROM 절을 생략할 수 있습니다. 예를 들면 다음과 같습니다.SELECT NOW();
는 PostgreSQL의 유효한 문입니다. |
| 외부 테이블 | Oracle을 사용하면 사용자가 데이터베이스 외부의 파일에 소스 데이터가 있는 외부 테이블을 만들 수 있습니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL은 관리형 서비스로, 데이터베이스 인스턴스를 실행하는 호스트의 기본 파일 시스템을 노출하지 않습니다. 해결 방법으로, 데이터를 쿼리할 수 있도록 소스 데이터를 PostgreSQL 테이블로 가져올 수 있습니다. |
| 리스너 | 수신 데이터베이스 연결을 리슨하는 태스크와 관련된 Oracle 네트워크 프로세스입니다. | Cloud SQL 승인 네트워크 | PostgreSQL용 Cloud SQL은 Cloud SQL 승인된 네트워크 구성 페이지에서 허용되면 원격 소스의 연결을 허용합니다. |
| TNSNAMES | 연결 별칭을 사용하여 연결을 설정하기 위한 데이터베이스 주소를 정의하는 Oracle 네트워크 구성 파일입니다. | 존재하지 않음 | PostgreSQL용 Cloud SQL은 Cloud SQL 인스턴스 연결 이름이나 비공개/공개 IP 주소를 사용하여 외부 연결을 허용합니다. Cloud SQL 프록시는 특정 IP 주소를 허용하거나 SSL을 구성하지 않고도 PostgreSQL용 Cloud SQL에 연결하는 추가 보안 액세스 방법입니다. |
| 인스턴스 기본 포트 | 1521 | 인스턴스 기본 포트 | 5432 |
| 데이터베이스 링크 | 로컬/원격 데이터베이스 객체와 상호작용하는 데 사용할 수 있는 Oracle 스키마 객체입니다. | Foreign Data Wrapper(FDW) | PostgreSQL용 Cloud SQL의 postgres_fdw 확장 프로그램을 사용하면 다른('외부') PostgreSQL 데이터베이스의 테이블을 현재 데이터베이스에서 '외부' 테이블로 노출할 수 있습니다. 이러한 테이블을 로컬 테이블과 거의 유사하게 사용할 수 있습니다. |
Oracle 12c와 PostgreSQL용 Cloud SQL의 용어 차이점
| Oracle 12c | 설명 | PostgreSQL용 Cloud SQL | 주요 차이점 |
|---|---|---|---|
| 인스턴스 | Oracle 인스턴스 하나가 단일 데이터베이스를 호스팅할 수 있는 Oracle 11g와 달리 Oracle 12c에 도입된 멀티 테넌트 기능을 사용하면 인스턴스에서 여러 데이터베이스를 플러그인 가능한 데이터베이스(PDB)로 보유할 수 있습니다. | 인스턴스 | PostgreSQL용 Cloud SQL 인스턴스 하나에는 데이터베이스 클러스터 하나만 있습니다. 데이터베이스 클러스터는 공통 데이터 영역에 저장되는 데이터베이스 모음입니다. |
| CDB | 멀티테넌트 컨테이너 데이터베이스(CDB)는 PDB 한 개 이상을 지원할 수 있으며 역할과 같이 모든 PDB에 영향을 주는 CDB 전역 객체를 만들 수 있습니다. | PostgreSQL 인스턴스 | PostgreSQL용 Cloud SQL 인스턴스는 Oracle CDB와 유사합니다. 둘 다 호스팅된 데이터베이스의 시스템 레이어를 제공합니다. |
| PDB | PDB(플러그인 가능한 데이터베이스)는 서비스와 애플리케이션을 서로 격리하는 데 사용되고 포팅 가능한 스키마 모음으로 사용할 수 있습니다. | PostgreSQL 데이터베이스/ 스키마 |
PostgreSQL용 Cloud SQL 데이터베이스는 여러 서비스와 애플리케이션뿐만 아니라 다수의 데이터베이스 사용자를 제공할 수 있습니다. |
| 세션 시퀀스 | Oracle 12c부터는 세션 수준(세션 내에서만 고유한 값 반환) 또는 전역 수준(예: 임시 테이블 사용)에서 시퀀스를 만들 수 있습니다. | 임시 시퀀스 | 현재 데이터베이스 세션에 임시 시퀀스가 생성되고 세션 종료 시에 자동으로 삭제됩니다. |
| ID 열 | Oracle 12c IDENTITY 유형은 수동으로 별도의 시퀀스 객체를 만들지 않고도 시퀀스를 생성하고 테이블 열에 연결합니다. |
직렬 열 | 열의 데이터 유형을 직렬로 정의하면 PostgreSQL용 Cloud SQL은 자동으로 시퀀스를 만들고 새 행이 테이블에 삽입될 때 이 시퀀스를 사용하여 열 값을 채웁니다. |
| 샤딩 | Oracle 샤딩은 하나의 Oracle 데이터베이스를 여러 개의 작은 데이터베이스(샤드)로 분할하여 OLTP 환경의 확장성, 가용성, 지리적 분산을 지원하는 솔루션입니다. | 지원되지 않음(기능) | PostgreSQL용 Cloud SQL에는 상응하는 샤딩 기능이 없습니다. 지원 애플리케이션 레이어와 함께 PostgreSQL용 Cloud SQL을 데이터 플랫폼으로 사용하면 샤딩을 구현할 수 있습니다. |
| 인메모리 데이터베이스 | Oracle은 OLTP뿐 아니라 혼합 워크로드의 데이터베이스 성능을 향상시킬 수 있는 기능 모음을 제공합니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL에는 상응하는 기능이 기본 제공되지 않습니다. 하지만 Google의 관리형 Redis 서비스인 Memorystore를 대안으로 사용할 수 있습니다. |
| 수정 | Oracle의 고급 보안 기능 중 하나인 수정을 통해 열을 마스킹하면 사용자와 애플리케이션에서 민감한 데이터를 검색하지 못하도록 할 수 있습니다. | 지원되지 않음 | PostgreSQL용 Cloud SQL에는 상응하는 기능이 기본 제공되지 않습니다. 하지만 Sensitive Data ProtectionLINK를 활용하여 민감한 정보를 익명화할 수 있습니다. |
기능
Oracle 11g/12c 및 PostgreSQL용 Cloud SQL 데이터베이스는 서로 다른 아키텍처(인프라 및 확장된 절차적 언어)에서 빌드되지만 관계형 데이터베이스의 동일한 기본 요소를 공유합니다. 데이터베이스 객체, 멀티사용자 동시 실행 워크로드, ACID 속성을 사용한 트랜잭션을 지원합니다. 또한 애플리케이션 니즈에 따라 여러 수준의 격리로 잠금 경합을 관리하고 온라인 트랜잭션 처리(OLTP) 작업과 온라인 분석 처리(OLAP)에 대한 지속적인 애플리케이션 요구사항을 제공합니다.
다음 섹션에서는 Oracle과 PostgreSQL용 Cloud SQL 간 주요 기능 차이를 간략하게 설명합니다. 차이를 강조하기 위해 필요하다고 간주되는 일부 경우에는 섹션에 세부 기술 비교가 포함됩니다.
기존 데이터베이스 만들기 및 보기
| Oracle 11g/12c | PostgreSQL용 Cloud SQL 12 |
|---|---|
일반적으로 Oracle Database Creation Assistant(DBCA) 유틸리티를 사용하여 데이터베이스를 만들고 기존 데이터베이스를 봅니다. 수동으로 생성된 데이터베이스나 인스턴스를 사용하려면 추가 매개변수를 지정해야 합니다.SQL> CREATE DATABASE ORADB
|
이 예시와 같이 CREATE DATABASE Name; 형식의 문을 사용합니다.postgres=> CREATE DATABASE PGSQLDB;
|
| Oracle 12c | PostgreSQL용 Cloud SQL 12 |
Oracle 12c에서는 컨테이너 데이터베이스(CDB) 템플릿에서 또는 기존 PDB에서 PDB를 클론하여 시드에서 PDB를 만들 수 있습니다. 여러 매개변수를 사용합니다.SQL> CREATE PLUGGABLE DATABASE PDB
|
이 예시와 같이 CREATE DATABASE Name; 형식의 문을 사용합니다.postgres=> CREATE DATABASE PGSQLDB;
|
모든 PDB를 나열합니다.SQL> SHOW is PDBS; |
모든 기존 데이터베이스를 나열합니다.postgres=> \list |
다른 PDB에 연결합니다.SQL> ALTER SESSION SET CONTAINER=pdb; |
다른 데이터베이스에 연결합니다.postgres=> \connect databaseName;
또는: postgres=> \c databaseName |
특정 PDB를 열거나 닫습니다(열기/읽기 전용).SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
단일 데이터베이스에서는 지원되지 않습니다. 모든 데이터베이스는 동일한 PostgreSQL용 Cloud SQL 인스턴스에 있습니다. 따라서 모든 데이터베이스가 상위이거나 하위가 됩니다. |
Google Cloud 콘솔을 통한 데이터베이스 관리
Google Cloud 콘솔에서 데이터베이스>SQL>인스턴스>(PostgreSQL 인스턴스 선택)>데이터베이스로 이동합니다.
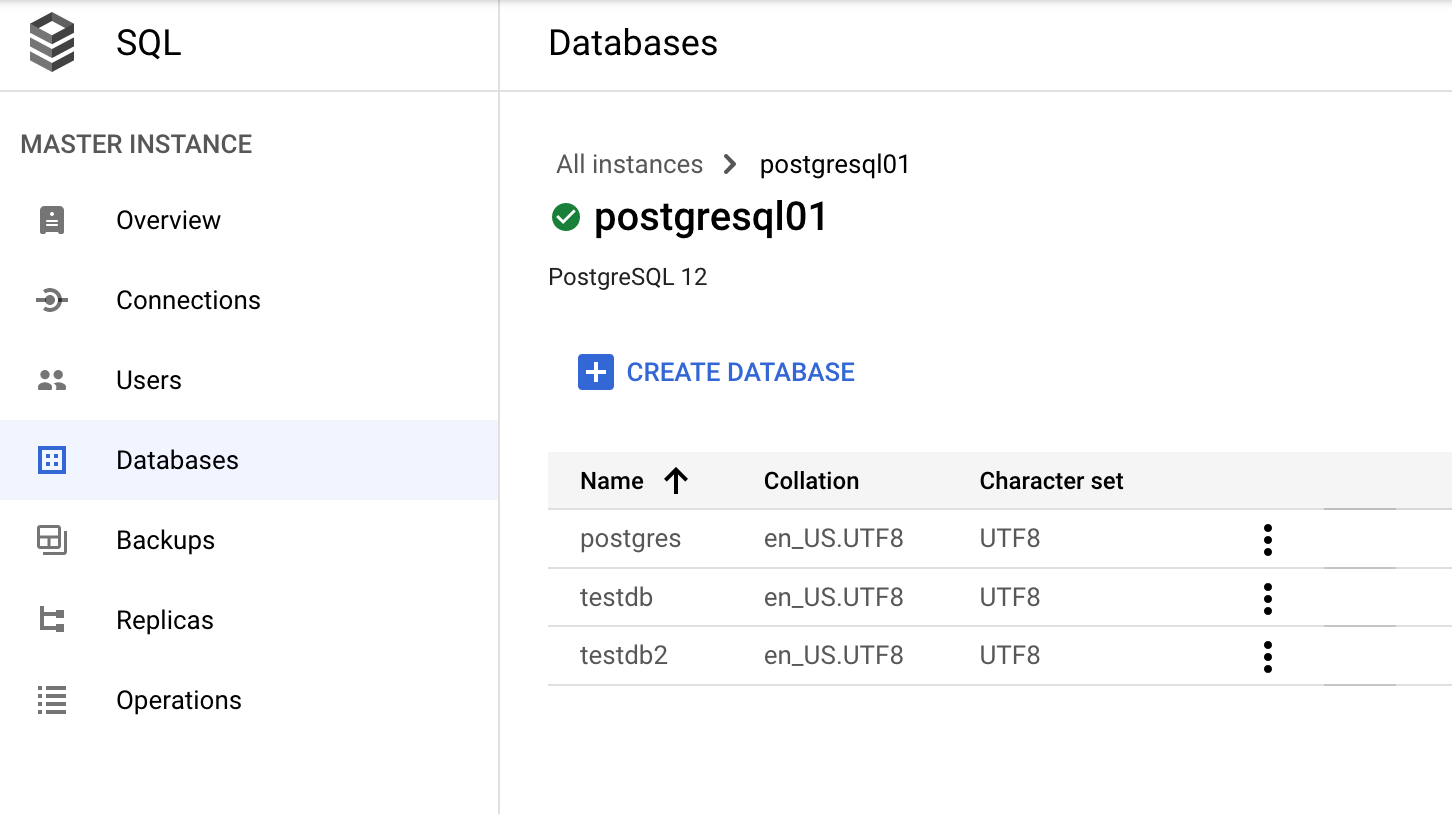
데이터 사전 및 동적 뷰
Oracle 데이터베이스는 다양한 데이터베이스 유지보수 및 모니터링 태스크를 용이하게 하는 동적 성능 뷰(V$ 뷰)와 함께 데이터 사전을 제공합니다. 데이터 사전에는 데이터베이스의 객체 관리에 사용되는 모든 정보가 저장되며 동적 성능 뷰에는 데이터베이스 성능과 관련된 많은 정보가 포함됩니다. 이러한 뷰는 데이터베이스가 실행되는 동안 지속적으로 업데이트됩니다.
반면 PostgreSQL은 Oracle의 데이터 사전 및 동적 성능 뷰와 비슷한 목적을 제공하는 여러 메타데이터 카탈로그를 제공합니다.
- 시스템 카탈로그: 모든 데이터베이스 객체에 대한 메타데이터입니다.
- 통계 모음 뷰: PostgreSQL 활동을 보고합니다.
- 정보 스키마 뷰: ANSI SQL 표준에 따라 보고된 모든 데이터베이스 객체에 대한 메타데이터입니다.
메타데이터 및 시스템 동적 뷰 보기
이 섹션에서는 Oracle에서 사용되는 가장 일반적인 메타데이터 테이블 및 시스템 동적 뷰와 PostgreSQL용 Cloud SQL 버전 12의 해당 데이터베이스 객체를 간략하게 설명합니다.
Oracle은 수백 개의 시스템 메타데이터 테이블과 뷰(예: 특정 시스템 스키마에서 SYS 또는 SYSTEM)를 제공하지만 PostgreSQL은 수십 개 정도만 보유합니다. 각 사례에서 특정 용도로 사용되는 데이터베이스 객체가 두 개 이상 있을 수 있습니다.
Oracle은 여러 수준의 메타데이터 객체를 제공하고 각 객체에는 서로 다른 권한이 필요합니다.
USER_TableName: 사용자가 볼 수 있습니다.ALL_TableName: 모든 사용자가 볼 수 있습니다.DBA_TableName:SYS및SYSTEM과 같은 DBA 권한이 있는 사용자만 볼 수 있습니다.
Oracle은 동적 성능 뷰에 V$/GV$ 프리픽스를 사용합니다. 반면 PostgreSQL용 Cloud SQL 메타데이터 및 뷰는 information_schema 및 pg_catalog 스키마에 있습니다.
| 메타데이터 유형 | Oracle 테이블/뷰 | PostgreSQL용 Cloud SQL 테이블/뷰/쿼리 |
|---|---|---|
| 개방형 세션 | V$SESSION |
pg_catalog.pg_stat_activity |
| 실행 트랜잭션 | V$TRANSACTION |
지원되지 않음 해결 방법으로, pg_locks는 잠금을 하나 이상 보유하는 열린 트랜잭션 목록을 제공합니다. |
| 데이터베이스 객체 | DBA_OBJECTS |
pg_catalog.pg_class |
| 테이블 | DBA_TABLES |
pg_catalog.pg_tables |
| 테이블 열 | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| 테이블 및 열 권한 | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| 파티션 | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| 뷰 | DBA_VIEWS |
pg_catalog.pg_views |
| 제약조건 | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| 색인 | DBA_INDEXES |
pg_catalog.pg_index |
| 구체화된 뷰 | DBA_MVIEWS |
pg_catalog.pg_matviews |
| 저장 프로시져 | DBA_PROCEDURES |
pg_catalog.pg_proc |
| 저장 함수 | DBA_PROCEDURES |
pg_catalog.pg_proc |
| 트리거 | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| 사용자 | DBA_USERS |
pg_catalog.pg_user |
| 사용자 권한 | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| 작업/ 스케줄러 |
DBA_JOBS |
지원되지 않음 |
| 테이블스페이스 | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| 데이터 파일 | DBA_DATA_FILES |
지원되지 않음 |
| 동의어 | DBA_SYNONYMS |
지원되지 않음 |
| 시퀀스 | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| 데이터베이스 링크 | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| 통계 | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| 잠금 | DBA_LOCK |
pg_catalog.pg_locks |
| 데이터베이스 매개변수 | V$PARAMETER |
pg_catalog.pg_settings
show |
| 부문 | DBA_SEGMENTS |
지원되지 않음 |
| 역할 | DBA_ROLES |
pg_catalog.pg_roles |
| 세션 기록 | V$ACTIVE_SESSION_HISTORY |
지원되지 않음 |
| 버전 | V$VERSION |
select version(); |
| 대기 이벤트 | V$WAITCLASSMETRIC |
지원되지 않음 |
| SQL 조정 및 분석 |
V$SQL |
지원되지 않음 |
| 인스턴스 메모리 조정 |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
PostgreSQL용 Cloud SQL에 기본 제공되지 않습니다. pg_buffercache 확장 프로그램을 사용하여 공유 버퍼 캐시를 실시간으로 검사할 수 있습니다. |
시스템 매개변수
Oracle과 PostgreSQL용 Cloud SQL 데이터베이스 모두 기본 구성 이외의 특정 기능을 제공하도록 구성할 수 있습니다. Oracle에서 구성 매개변수를 변경하려면 특정 관리 권한이 필요합니다(주로 SYS/SYSTEM 사용자 권한).
다음은 ALTER SYSTEM 문을 사용하여 Oracle 구성을 변경하는 예시입니다. 이 예시에서 사용자는 spfile 구성 수준에서만 '로그인 실패 시 최대 시도 횟수' 파라미터를 변경합니다(재부팅 후에만 수정 가능).
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
다음 예시에서는 사용자가 Oracle 매개변수 값 보기를 요청합니다.
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
출력은 다음과 비슷합니다.
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
Oracle 매개변수는 다음 세 가지 범위에서 수정할 수 있습니다.
- SPFILE: 파라미터 수정은 Oracle
spfile에 기록되고 파라미터를 적용하려면 인스턴스를 재부팅해야 합니다. - MEMORY: 매개변수 수정은 정적 매개변수 변경이 허용되지 않는 경우에만 메모리 레이어에 적용됩니다.
- BOTH: 파라미터 수정은 정적 파라미터 변경이 허용되지 않는 서버 파라미터 파일과 인스턴스 메모리 모두에 적용됩니다.
PostgreSQL용 Cloud SQL 구성 플래그
Google Cloud 콘솔, gcloud CLI 또는 CURL의 구성 플래그를 사용하여 PostgreSQL용 Cloud SQL 시스템 파라미터를 수정할 수 있습니다. PostgreSQL용 Cloud SQL에서 지원하는 변경 가능한 모든 파라미터의 전체 목록을 참조하세요.
PostgreSQL 매개변수를 여러 범위로 나눌 수 있습니다.
- 동적 매개변수: 런타임 시 변경할 수 있습니다.
- 데이터베이스 매개변수: PostgreSQL 인스턴스 내 특정 데이터베이스에만 적용됩니다.
- 역할 매개변수: 특정 데이터베이스 역할에만 적용됩니다.
- 정적 매개변수: 적용하려면 인스턴스를 재부팅해야 합니다.
- 세션 매개변수: 현재 세션 기간 동안에만 세션 수준에서 변경할 수 있으며 다른 세션과는 격리됩니다.
- 전역 매개변수: 모든 현재 및 향후 세션에 전역적으로 영향을 미칩니다.
PostgreSQL용 Cloud SQL 매개변수 변경 예시
콘솔
Google Cloud 콘솔을 사용하여 log_connections 파라미터를 사용 설정합니다.
Cloud Storage의 인스턴스 수정 페이지로 이동합니다.
플래그에서 항목 추가를 클릭하고 다음 스크린샷과 같이
log_connections를 검색합니다.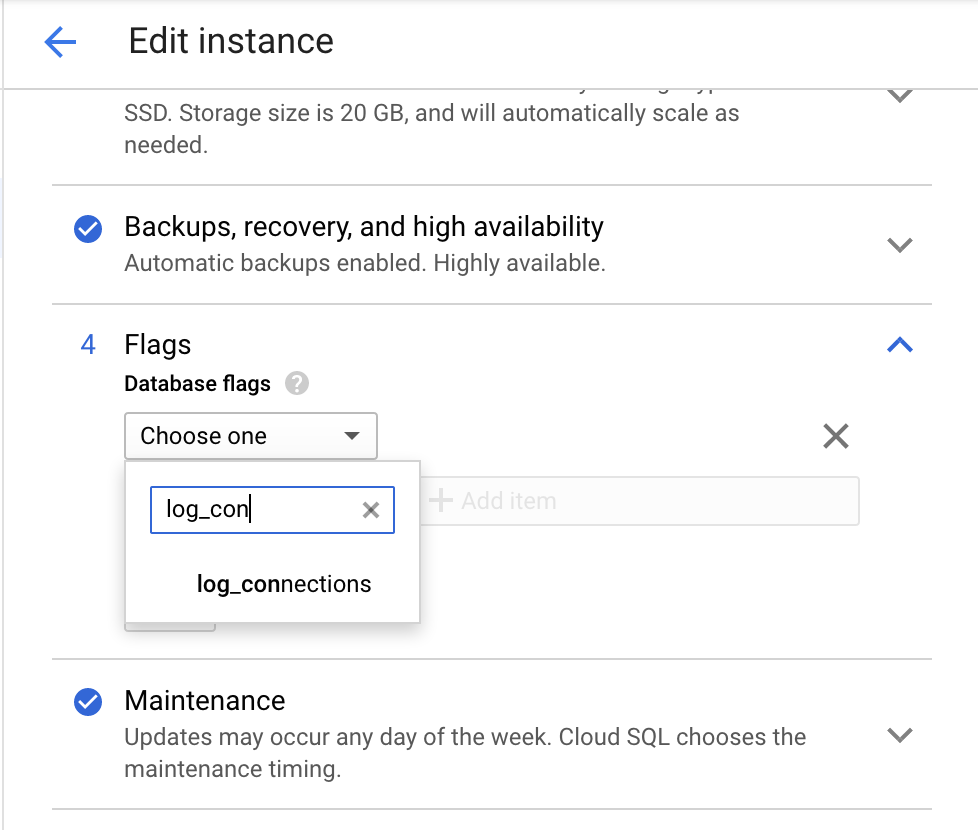
gcloud
- gcloud CLI를 사용하여
log_connections매개변수를 사용 설정합니다.
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
출력은 다음과 같습니다.
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
PostgreSQL용 Cloud SQL
세션 수준에서 timezone을 설정합니다. 이 변경사항은 현재 세션에 적용되며 세션 기간 동안만 유지됩니다.
timezone구성 매개변수를 표시합니다.postgres=> SHOW timezone;다음과 같은 출력이 표시됩니다. 여기서
timezone은set to UTC입니다.TimeZone ---------- UTC (1 row)
timezone을 UTC-9로 설정합니다.postgres=> SET timezone='UTC-9';timezone구성 매개변수를 표시합니다.postgres> SHOW timezone;다음 출력이 표시됩니다. 여기서
timezone은UTC-9로 설정됩니다.TimeZone ---------- UTC-9 (1 row)
트랜잭션 및 격리 수준
이 섹션에서는 트랜잭션 실행 및 격리 수준에서 Oracle과 PostgreSQL용 Cloud SQL의 주요 차이점을 설명합니다.
커밋 모드
Oracle은 기본적으로 자동 커밋 이외의 모드에서 작동하며 각 DML 트랜잭션은 COMMIT/ROLLBACK 문을 통해 결정해야 합니다. Oracle과 PostgreSQL의 기본 차이점 중 하나는 PostgreSQL이 START TRANSACTION(또는 BEGIN)을 따르지 않는 각 명령어 다음에 COMMIT을 암시적으로 실행한다는 점입니다. 다른 일부 데이터베이스 엔진에서도 자동 커밋으로 알려져 있습니다.
자동 커밋은 기본적으로 사용 설정되지만 SET AUTOCOMMIT OFF를 사용하여 세션 수준에서 중지할 수 있습니다.
격리 수준
ANSI/ISO SQL 표준(SQL:92)은 4가지 격리 수준을 정의합니다. 각 수준별로 데이터베이스 트랜잭션의 동시 실행을 처리하는 방법이 다릅니다.
- 커밋되지 않은 읽기: 현재 처리된 트랜잭션이 다른 트랜잭션에서 생성된 커밋되지 않은 데이터를 볼 수 있습니다. 롤백을 수행하면 모든 데이터가 이전 상태로 복원됩니다.
- 커밋된 읽기: 트랜잭션이 커밋된 데이터의 변경사항만 봅니다. 커밋되지 않은 변경('더티 읽기')은 불가능합니다.
- 반복 가능 읽기: 두 트랜잭션 모두
COMMIT을 실행했거나 둘 다 롤백한 후에만 트랜잭션에서 다른 트랜잭션에서 변경된 항목을 볼 수 있습니다. - 직렬화 가능: 가장 엄격하고 강력한 격리 수준입니다. 이 수준은 액세스되는 모든 레코드를 잠그고 레코드가 테이블에 추가되지 않도록 리소스를 잠급니다.
트랜잭션 격리 수준은 다른 실행 트랜잭션에서 보는 것과 같이 변경된 데이터의 공개 상태를 관리합니다. 또한 여러 동시 실행 트랜잭션에서 동일한 데이터에 액세스하면 선택한 트랜잭션 격리 수준에 따라 트랜잭션이 서로 상호작용하는 방식이 달라집니다.
Oracle은 다음과 같은 격리 수준을 지원합니다.
- 커밋된 읽기(기본값)
- Serializable
- 읽기 전용(ANSI/ISO SQL 표준(SQL:92)의 일부가 아님)
Oracle MVCC(다중 버전 동시 실행 제어):
- Oracle은 MVCC 메커니즘을 사용하여 전체 데이터베이스와 모든 세션에서 자동 읽기 일관성을 제공합니다.
- Oracle은 데이터베이스의 일관성 있는 뷰를 얻기 위해 현재 트랜잭션의 SCN(System Change Number)을 사용합니다. 따라서 모든 데이터베이스 쿼리는 쿼리 실행 시 SCN과 관련하여 커밋된 데이터만 반환합니다.
- 격리 수준은 트랜잭션 및 세션 수준에서 변경할 수 있습니다.
다음은 격리 수준 설정의 예시입니다.
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
PostgreSQL용 Cloud SQL은 ANSI SQL:92 표준에서 지정된 다음 4가지 트랜잭션 격리 수준을 지원합니다.
- 커밋되지 않은 읽기(커밋된 읽기와 동일)
- 커밋된 읽기(기본값)
- 반복 읽기
- Serializable
PostgreSQL용 Cloud SQL의 기본 격리 수준은 READ COMMITTED입니다.
이러한 격리 수준을 SESSION 수준, TRANSACTION 수준, INSTANCE 수준에서 변경할 수 있습니다.
TRANSACTION 및 SESSION 수준에서 현재 격리 수준을 확인하려면 다음 문을 사용하세요.
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
출력은 다음과 같습니다.
current_setting ----------------- read committed (1 row)
격리 수준 구문은 다음과 같이 수정할 수 있습니다.
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
또한 세션 수준에서 격리 수준을 수정할 수 있습니다.
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
출력은 다음과 같습니다.
current_setting ----------------- repeatable read (1 row)
INSTANCE 수준의 격리 수준은 데이터베이스 플래그 default_transaction_isolation을 통해 제어됩니다. 다음과 같은 문을 사용하여 이를 확인할 수 있습니다.
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
출력은 다음과 같습니다.
default_transaction_isolation ------------------------------- repeatable read (1 row)
다음 단계
- PostgreSQL용 Cloud SQL 사용자 자세히 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기