이 문서는 PostgreSQL용 Cloud SQL 버전 12로 Oracle® 11g/12c 데이터베이스 마이그레이션 계획 및 수행과 관련된 핵심 정보와 지침을 제공하는 시리즈의 일부입니다. 이 시리즈에는 소개 설정 부분 외에도 다음 부분이 포함됩니다.
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 용어 및 기능
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 데이터 유형, 사용자, 테이블
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 쿼리, 저장 프로시저, 함수, 트리거
- Oracle 사용자를 PostgreSQL용 Cloud SQL로 마이그레이션: 보안, 작업, 모니터링, 로깅(이 문서)
- Oracle 데이터베이스 사용자 및 스키마를 PostgreSQL용 Cloud SQL로 마이그레이션
보안
이 섹션에서는 암호화, 감사, 액세스 제어에 대한 안내를 제공합니다.
암호화
Oracle과 PostgreSQL용 Cloud SQL 모두 기본 사용자 인증과 사용자 권한 관리 이상으로 보호를 강화하는 데이터 암호화 메커니즘을 제공합니다.
저장 데이터 암호화
네트워크를 통해 이동하지 않는 데이터(저장됨)를 '저장 데이터'라고 합니다. Oracle은 운영체제 수준에서 암호화 계층을 추가하는 TDE(투명 데이터 암호화) 메커니즘을 제공합니다. Cloud SQL에서 데이터는 256비트 고급 암호화 표준(AES-256) 이상을 통해 암호화됩니다. 이러한 데이터 키는 보안 키 저장소에 저장된 마스터 키를 통해 암호화되고 정기적으로 변경됩니다. 저장 데이터 암호화에 대한 자세한 내용은 Google Cloud의 저장 데이터 암호화를 참조하세요.
전송 중인 데이터 암호화
Oracle은 네트워크를 통해 데이터 암호화를 처리하는 고급 보안을 제공합니다. 데이터가 Google이나 Google의 대리인이 통제하지 않는 물리적 경계 외부로 이동하면 Cloud SQL은 네트워크 계층 하나 이상에서 전송 중인 모든 데이터를 암호화하고 인증합니다. 일반적으로 Google이나 Google 대리인이 통제하는 물리적 경계 내에서 전송 중인 데이터는 인증되지만 기본적으로 암호화되지 않을 수 있습니다. 위협 모델에 따라 적용할 추가 보안 조치를 선택할 수 있습니다. 예를 들어 Cloud SQL로 영역 내 연결에 사용되는 SSL을 구성할 수 있습니다. 전송 중인 데이터 암호화에 대한 자세한 내용은 Google Cloud의 전송 중인 데이터 암호화를 참조하세요.
감사
Oracle은 감사(예: 표준 및 세분화된 감사)에 사용되는 여러 방법을 제공합니다. 반면 PostgreSQL용 Cloud SQL의 감사는 다음 방법으로 수행될 수 있습니다.
- pgAudit 확장 프로그램. 특정 데이터베이스 인스턴스에서 수행된 SQL 작업을 기록하고 추적합니다.
- Cloud 감사 로그. PostgreSQL용 Cloud SQL 인스턴스에서 수행된 관리 및 유지보수 작업을 감사합니다.
액세스 제어
사용자는 승인된 고정 IP 주소로 PostgreSQL 클라이언트를 사용하거나 다른 데이터베이스 연결과 같은 Cloud SQL 프록시를 사용하여 PostgreSQL용 Cloud SQL 인스턴스에 연결할 수 있습니다. App Engine 또는 Compute Engine과 같은 다른 연결 소스의 경우 사용자는 Cloud SQL 프록시 사용과 같은 몇 가지 옵션을 사용할 수 있습니다. 이러한 옵션에 대한 자세한 내용은 인스턴스 액세스 제어를 참조하세요.
PostgreSQL용 Cloud SQL은 Identity and Access Management(IAM)와 통합되며 Cloud SQL 리소스에 대한 액세스를 제어하는 데 도움이 되도록 설계된 사전 정의된 역할 집합을 제공합니다. 이러한 역할을 통해 IAM 사용자는 인스턴스 재시작, 백업, 장애 조치와 같은 다양한 관리 작업을 시작할 수 있습니다. 자세한 내용은 프로젝트 액세스 제어를 참조하세요.
운영
이 섹션에서는 내보내기 및 가져오기 작업, 인스턴스 수준 백업 및 복원, 읽기 전용 작업 및 재해 복구 구현에 사용되는 대기 인스턴스에 대한 지침을 제공합니다.
내보내기 및 가져오기
Oracle에서 논리적 내보내기 및 가져오기 작업을 수행하는 기본 방식은 EXPDP/IMPDP 명령어(exp/imp 명령어가 포함된 Oracle 내보내기/가져오기 기능의 이전 버전)를 사용하는 데이터 펌프 유틸리티입니다. 상응하는 PostgreSQL용 Cloud SQL 명령어는 덤프 파일을 생성한 후 데이터베이스나 객체 수준(메타데이터 내보내기 및 가져오기만 포함)에서 가져오는 pg_dump 및 pg_restore 유틸리티입니다.
Oracle DBMS_DATAPUMP 유틸리티(DBMS_DATAPUMP 패키지와 직접 상호작용하는 EXPDP/IMPDP 기능을 적용할 수 있는 Oracle 메서드)와 직접 상응되는 PostgreSQL용 Cloud SQL 솔루션은 없습니다. Oracle DBMS_DATAPUMP PL/SQL 코드에서 변환하려면 대체 코드(예: Bash 및 Python)를 사용하여 논리적 요소와 PostgreSQL용 Cloud SQL 프로그램 pg_dump 및 pg_restore를 구현해 내보내기/가져오기 작업을 실행합니다.
Oracle SQL*Loader를 사용하여 외부 파일을 데이터베이스 테이블에 로드할 수 있습니다. SQL*Loader는 데이터가 Oracle 데이터베이스로 파싱 및 로드되는 방법을 결정하는 데 SQL*Loader에서 사용하는 메타데이터가 저장된 구성 파일(제어 파일이라 함)을 사용할 수 있습니다. SQL*Loader는 고정 및 가변 소스 파일을 모두 지원합니다.
pg_dump 및 pg_restore 유틸리티는 클라이언트 수준에서 실행되며 PostgreSQL용 Cloud SQL 인스턴스에 원격으로 연결합니다. 덤프 파일은 클라이언트 측에서 생성됩니다. 외부 파일을 PostgreSQL용 Cloud SQL에 로드하려면 psql 클라이언트 인터페이스에서 COPY 명령어를 사용하거나 Dataflow 또는 Dataproc을 사용합니다. 이 섹션에서는 주로 Oracle의 SQL*Loader 유틸리티와 더욱 유사한 PostgreSQL용 Cloud SQL COPY 명령어를 사용합니다.
PostgreSQL용 Cloud SQL 데이터베이스에 더 복잡한 데이터를 로드하려면 ETL 프로세스 생성과 관련된 Dataflow 또는 Dataproc을 사용하는 것이 좋습니다.
Dataflow에 대한 자세한 내용은 Dataflow 문서를 참조하고 Dataproc에 대한 자세한 내용은 Dataproc 문서를 참조하세요.
pg_dump
pg_dump 클라이언트 유틸리티는 스크립트 또는 보관 파일 형식으로 일관된 백업과 출력을 수행합니다. 스크립트 덤프는 원본 데이터베이스 객체 정의와 테이블 데이터를 재현하기 위해 실행할 수 있는 SQL 문 집합입니다. 이러한 SQL 문은 복원에 사용되는 모든 PostgreSQL 클라이언트에 전달될 수 있습니다. 보관 파일 형식으로 백업은 복원 작업 시 pg_restore와 함께 사용되어야 합니다. 하지만 백업은 선택적 객체를 복원하도록 지원하며 아키텍처 간 이동이 가능하도록 설계되었습니다.
사용량:
-- Single database backup & specific tables backup # pg_dump database_name > outputfile.sql # pg_dump -t table_name database_name > outputfile.sql -- Dump all tables in a given schema with a prefix and ignore a given table # pg_dump -t 'schema_name.table_prefixvar>*' -T schema_name.ignore_table database_name > outputfile.sql -- Backup metadata only - Schema only # pg_dump -s database_name > metadata.sql -- Backup in custom-format archive pg_dump -Fc database_name > outputfile.dump
pg_restore
pg_restore 클라이언트 프로그램은 pg_dump에서 만든 보관 파일에서 PostgreSQL 데이터베이스를 복원합니다. 데이터베이스 이름이 지정되지 않으면 pg_restore는 pg_dump와 유사한 데이터베이스를 다시 빌드하는 데 필요한 SQL 명령어가 포함된 스크립트를 출력합니다.
사용량:
-- Connect to an existing database and restore the backup archive
pg_restore -d database_name outputfile.dump
-- Create and restore the database from the backup archive
pg_restore -C -d database_name outputfile.dump
psql COPY 명령어
psql은 PostgreSQL용 Cloud SQL에 대한 명령줄 클라이언트 인터페이스입니다. COPY 명령어를 사용하면 psql에서 명령어 인수에 지정된 파일을 읽고 데이터를 서버와 로컬 파일 시스템 간에 라우팅합니다.
사용량:
-- Connect to an existing database and restore the backup archive psql -p 5432 -U username -h cloud_sql_instance_ip -d database_name -c "\copy emps from '/opt/files/inputfile.csv' WITH csv;" -W
PostgreSQL용 Cloud SQL 내보내기/가져오기:
다음 문서 링크에서는 내보내기 및 가져오기 작업을 적용할 수 있도록 gcloud CLI를 사용하여 Cloud SQL 인스턴스 및 Cloud Storage와 상호작용하는 방법을 보여줍니다.
인스턴스 수준 백업 및 복원
Cloud SQL에서 백업 태스크와 복구 태스크는 자동 및 주문형 데이터베이스 백업을 통해 처리됩니다.
백업은 데이터가 손실되거나 인스턴스에 문제가 발생할 경우 Cloud SQL 인스턴스를 복원하는 방법을 제공합니다. 손실 또는 손상으로부터 보호하는 데 필요한 데이터가 포함된 인스턴스에 자동 백업을 사용 설정하는 것이 좋습니다.
언제든지 백업을 만들 수 있습니다. 데이터베이스에서 위험 부담이 있는 작업을 수행하려고 하거나 백업이 필요하지만 백업 기간을 기다리지 않으려는 경우에 유용합니다. 인스턴스에 자동 백업이 사용 설정되어 있는지 여부와 관계없이 모든 인스턴스에 주문형 백업을 만들 수 있습니다.
주문형 백업은 자동 백업과 달리 자동으로 삭제되지 않으며 사용자가 직접 삭제하거나 인스턴스가 삭제되기 전까지 유지됩니다. 주문형 백업은 자동으로 삭제되지 않으므로 이를 직접 삭제하지 않으면 비용이 계속 청구됩니다.
자동 백업을 사용 설정하면 백업 기간이 4시간으로 지정되고 이 기간 동안 백업이 시작됩니다. 가능하면 인스턴스 활동이 가장 적을 때 백업을 예약합니다. 마지막 백업 이후 데이터가 변경되지 않으면 백업이 실행되지 않습니다.
Cloud SQL은 인스턴스당 최대 7개의 자동 백업을 보유합니다. 백업에 사용되는 스토리지는 백업이 저장된 리전에 따라 할인된 가격으로 청구됩니다. 가격 책정 목록에 대한 자세한 내용은 PostgreSQL용 Cloud SQL 가격 책정을 참조하세요.
PostgreSQL용 Cloud SQL 데이터베이스 인스턴스 복원을 사용하여 동일한 인스턴스로 복원하거나 기존 데이터를 덮어쓰거나 다른 인스턴스로 복원할 수 있습니다. PostgreSQL용 Cloud SQL을 사용하면 사용 설정된 자동 백업 옵션으로 PostgreSQL 데이터베이스를 특정 시점으로 복원할 수 있습니다.
주문형 백업과 자동 백업을 만들거나 관리하는 방법에 대한 자세한 내용은 주문형 백업과 자동 백업 만들기 및 관리를 참조하세요.
다음 표에는 Oracle에 상응하는 PostgreSQL용 Cloud SQL의 공통 백업 및 복원 작업이 나와 있습니다.
| 설명 | Oracle(복구 관리자 - RMAN) |
PostgreSQL용 Cloud SQL |
|---|---|---|
| 예약된 자동 백업 | RMAN 스크립트를 예약된 일정에 실행하는 DBMS_SCHEDULER 작업을 만듭니다. |
gcloud sql instances patch INSTANCE_NAME --backup-start-time HH:MM
|
| 전체 데이터베이스 수동 백업 | BACKUP DATABASE PLUS ARCHIVELOG;
|
gcloud sql backups create --async --instance INSTANCE_NAME
|
| 데이터베이스 복원 | RUN
|
gcloud sql backups list --instance INSTANCE_NAME
|
| 증분차 | BACKUP INCREMENTAL LEVEL 0 DATABASE;
|
모든 백업은 증분 방식이므로 증분 유형을 선택하는 옵션이 없습니다. |
| 증분 누적 | BACKUP INCREMENTAL LEVEL 0 CUMULATIVE DATABASE;
|
모든 백업은 증분 방식이므로 증분 유형을 선택하는 옵션이 없습니다. |
| 특정 시점으로 데이터베이스 복원 | RUN
|
gcloud sql instances clone SOURCE_INSTANCE_NAME NEW_INSTANCE_NAME \
|
| 데이터베이스 보관 로그 백업 | BACKUP ARCHIVELOG ALL;
|
지원되지 않음 |
읽기 전용 작업 및 재해 복구 구현에 대한 대기 인스턴스
Oracle Active Data Guard를 사용하면 새 데이터가 재실행 및 보관 로그를 통해 계속 적용되는 동안 대기 인스턴스를 읽기 전용 엔드포인트로 제공할 수 있습니다. 또한 변경 데이터 캡처(CDC) 솔루션으로 제공되는 Oracle GoldenGate를 사용하여 데이터 수정사항이 실시간으로 적용되는 동안 추가 인스턴스를 읽기용으로 사용 설정할 수 있습니다.
PostgreSQL용 Cloud SQL에서는 고가용성을 위해 대기 인스턴스를 사용합니다. 이 인스턴스는 디스크 수준 복제를 통해 기본 인스턴스와 동기화된 상태로 유지됩니다. Active Data Guard와 달리 읽기 또는 쓰기에는 열리지 않습니다. 기본 인스턴스가 다운되거나 약 60초 동안 응답하지 않으면 대기 인스턴스로 자동 장애 조치됩니다. 몇 초 내에 역할이 전환되고 새 기본 역할이 인수됩니다.
PostgreSQL용 Cloud SQL은 읽기 요청을 확장할 수 있는 읽기 복제본도 제공합니다. 기본 인스턴스에서 읽기를 오프로드하도록 설계되어 있으므로 재해 복구용 대기 인스턴스로 제공되지 않습니다. 대기 인스턴스와 달리 읽기 복제본은 기본 인스턴스와 비동식으로 동기화된 상태로 유지됩니다. 인스턴스는 기본 인스턴스와 다른 영역과 다른 리전에 있을 수 있습니다. Google Cloud 콘솔 또는 gcloud CLI를 사용하여 읽기 복제본을 만들 수 있습니다. 일부 작업은 인스턴스를 재부팅해야 합니다(예: 기존 기본 인스턴스에 고가용성 추가).
로그 기록 및 모니터링
Oracle의 알림 로그 파일은 Oracle 데이터베이스 인스턴스 수명 주기(주로 문제 해결 실패 이벤트 및 오류 이벤트)를 이해하기 위해 일반적인 시스템 이벤트 및 오류 이벤트의 식별에 사용되는 기본 소스입니다.
Oracle 알림 로그에는 다음에 대한 정보가 표시됩니다.
- Oracle 데이터베이스 인스턴스 오류 및 경고(
ORA-+ 오류 번호) - Oracle 데이터베이스 인스턴스 시작 및 종료 이벤트
- 네트워크 및 연결 관련 문제
- 이벤트를 전환하는 데이터베이스 재실행 로그
- 특정 데이터베이스 이벤트에 대한 추가 세부정보의 링크에 언급될 수도 있는 Oracle 추적 파일
Oracle은 PostgreSQL용 Cloud SQL에 상응하는 구성요소가 없는 LISTENER, ASM, Enterprise Manager(OEM)와 같은 여러 서비스 전용 로그 파일을 제공합니다.
PostgreSQL용 Cloud SQL 작업 로그 보기
Cloud Logging은 postgres.log의 모든 로그 항목을 볼 수 있는 기본 플랫폼입니다(Oracle의 alert.log와 동일). 로그 이벤트 수준(예: 중요, 오류 또는 경고)별로 필터링할 수 있습니다. 이벤트 기간 및 무료 텍스트 필터링도 사용할 수 있습니다.
PostgreSQL용 Cloud SQL 데이터베이스 인스턴스 모니터링
Oracle의 기본 UI 모니터링 대시보드는 OEM 및 Grid/Cloud 제어 제품(예: 인기 활동 그래프)의 일부이며 세션 또는 SQL 문 수준에서의 실시간 데이터베이스 인스턴스 모니터링에 유용합니다. PostgreSQL용 Cloud SQL은 Google Cloud 콘솔을 사용하여 비슷한 모니터링 기능을 제공합니다. CPU 사용률, 스토리지 사용량, 메모리 사용량, 읽기/쓰기 작업, 인그레스/이그레스 바이트, 활성 연결 등과 같은 여러 모니터링 측정항목을 사용하여 PostgreSQL용 Cloud SQL 데이터베이스 인스턴스에 대한 요약 정보를 볼 수 있습니다.
Cloud Logging은 PostgreSQL용 Cloud SQL에 대한 추가 모니터링 측정항목을 지원합니다. 다음 스크린샷에서는 지난 12시간 동안의 PostgreSQL용 Cloud SQL 쿼리 그래프를 보여줍니다.
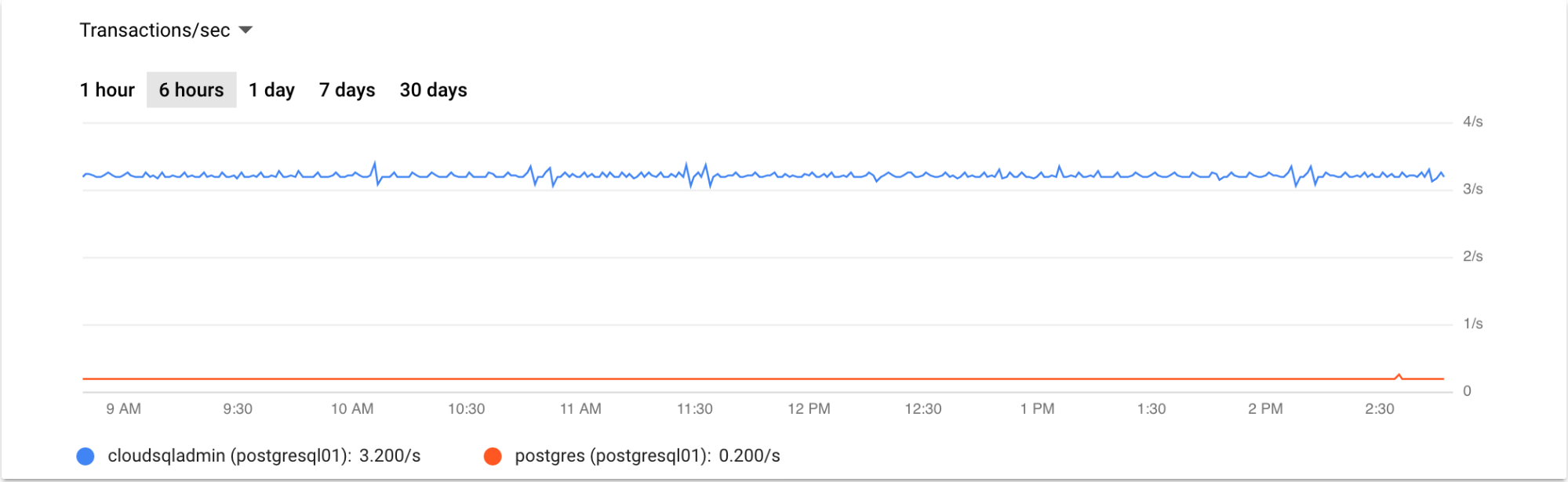
PostgreSQL용 Cloud SQL 읽기 복제본 모니터링
앞에서 설명한 대로 Google Cloud 콘솔 모니터링 측정항목을 사용하여 기본 인스턴스를 모니터링하는 방식과 동일한 방식으로 읽기 복제본을 모니터링할 수 있습니다. 또한 기본 인스턴스와 읽기 복제본 인스턴스 사이의 지연 시간(바이트 단위)을 확인하는 방식으로 복제 지연을 모니터링하기 위한 전용 모니터링 측정항목이 있습니다. 이러한 지연 시간은 Google Cloud 콘솔의 읽기 복제본 인스턴스 개요 탭에서 모니터링할 수 있습니다.
gcloud CLI를 사용하여 복제 상태를 가져올 수 있습니다.
gcloud sql instances describe REPLICA_NAME
또한 기본 데이터베이스와 대기 데이터베이스의 상태를 제공하는 PostgreSQL 클라이언트의 명령어를 사용하여 복제 모니터링을 수행할 수 있습니다.
다음 SQL 문을 사용하여 읽기 복제본 상태를 확인할 수 있습니다.
postgres=> select * from pg_stat_replication;
PostgreSQL용 Cloud SQL 모니터링
이 섹션에서는 Oracle 또는 PostgreSQL용 Cloud SQL과 같은 데이터베이스 관리자(DBA)가 수행하는 루틴 태스크로 간주되는 기본 PostgreSQL용 Cloud SQL 모니터링 방법을 설명합니다.
세션 모니터링
Oracle 세션 모니터링은 'V$' 뷰라고 하는 동적 성능 뷰를 쿼리하여 수행됩니다. V$SESSION 및 V$PROCESS 뷰는 일반적으로 SQL 문을 사용하여 현재 데이터베이스 활동에 대한 실시간 통계를 얻는 데 사용됩니다. pg_stat_activity 동적 뷰를 쿼리하여 세션 활동을 모니터링할 수 있습니다.
postgres=> select * from pg_stat_activity;
긴 트랜잭션 모니터링
pg_stat_activity 동적 뷰의 query_start 및 state와 같은 열에 적절한 필터를 적용하여 장기 실행 쿼리를 식별할 수 있습니다.
잠금 모니터링
성능 문제를 일으킬 수 있는 잠금 발생에 대한 실시간 정보를 제공하는 pg_locks 동적 뷰를 사용하여 데이터베이스 잠금을 모니터링할 수 있습니다.
다음 단계
- PostgreSQL용 Cloud SQL 사용자 자세히 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터를 살펴보세요.