이 튜토리얼에서는 리전 간 읽기 복제본을 사용한 MySQL용 Cloud SQL의 전체 재해 복구(DR) 장애 조치 및 대체 프로세스를 설명합니다.
이 튜토리얼에서는 DR 시 고가용성(HA) MySQL용 Cloud SQL 인스턴스를 설정하고 서비스 중단을 시뮬레이션합니다. 그런 다음 DR 프로세스를 단계별로 진행하여 서비스 중단이 해결되면 초기 배포를 복구합니다.
이 튜토리얼은 데이터베이스 설계자, 관리자, 엔지니어를 대상으로 합니다.
SQL 재해 복구 작동 방법에 대한 개요를 보려면 Cloud SQL의 재해 복구 정보를 참조하세요.
목표
- HA MySQL용 Cloud SQL 인스턴스를 만듭니다.
- MySQL용 Cloud SQL을 사용하여 Google Cloud 에 리전 간 읽기 복제본을 배포합니다.
- MySQL용 Cloud SQL을 사용하여 재해 및 장애 조치를 시뮬레이션합니다.
- MySQL용 Cloud SQL에서 대체를 사용하여 초기 배포를 복구하는 단계를 이해합니다.
이 문서에서는 리전 간 DR 장애 조치 및 대체 프로세스에만 중점을 둡니다. 단일 리전 HA 장애 조치 프로세스에 대한 자세한 내용은 고가용성 구성 개요를 참조하세요.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
1단계: DR용 HA 데이터베이스 인스턴스 설정
다음 단계(1-3)는 전체 장애 조치 및 대체 프로세스를 안내합니다. Cloud Shell에서
gcloud명령어를 사용하여 모든 명령어를 실행합니다. 이 프로세스를 단순화하기 위해 이 튜토리얼에서는 가능하면 기본 설정(예: 기본 Cloud SQL 버전)을 사용합니다. 프로덕션 환경에서는 다른 구성을 추가할 수 있습니다.환경 변수 설정
이 섹션에서는 이 튜토리얼에서 실행하는 명령어에 필요한 다양한 이름과 리전을 정의하는 환경 변수의 예시를 제공합니다. 필요에 따라 다음 예제 변수를 조정할 수 있습니다.
다음 표에서는 이 튜토리얼의 DR 및 대체 프로세스의 각 단계에 대한 인스턴스 이름, 역할, 배포 리전을 설명합니다. 고유한 이름과 리전을 제공할 수도 있습니다.
초기 단계 인스턴스 이름 역할 리전 instance-1기본 us-west1instance-2대기 us-west1instance-3리전 간 읽기 복제본 us-west2재해 단계 인스턴스 이름 역할 리전 instance-3기본 us-west2instance-4대기 us-west2instance-5리전 간 읽기 복제본 us-west3instance-6리전 간 읽기 복제본 us-west1대체(최종) 단계 인스턴스 이름 역할 리전 instance-6기본 us-west1instance-7대기 us-west1instance-8리전 간 읽기 복제본 us-west2위 표의 인스턴스 이름은 역할로 인코딩되지 않습니다. DR 상황에서는 인스턴스의 함수가 변경될 수 있습니다. 예를 들어 복제본이 기본 인스턴스가 될 수 있습니다. 새 기본 인스턴스의 이름에
replica라는 단어가 포함된 경우 혼동 및 충돌이 발생할 수 있습니다. 따라서 수행하는 기능 또는 역할로 인스턴스 이름을 인코딩하지 않는 것이 좋습니다.위의 표에는 대기 인스턴스의 이름이 나열됩니다. 이 튜토리얼에서는 HA 장애 조치를 수행하지 않지만 튜토리얼에는 완성도를 위해 대기 인스턴스의 이름이 포함되어 있습니다.
대체 단계는 동일한 원래 리전에 초기 단계의 원래 배포를 다시 만듭니다. 하지만 대체 단계에서는 원래 인스턴스가 삭제된 후에도 원래 이름을 바로 사용할 수 없으므로 인스턴스 이름을 변경해야 합니다. 대체 단계에서 빠르게 인스턴스를 만들려면 초기 단계에서 사용한 이름과 일치하지 않는 인스턴스 이름을 사용해야 합니다.
Cloud Shell에서 이전 표의 사양에 따라 환경 변수를 설정합니다.
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2기본 인스턴스에 다른 등급을 사용하려면 사용할 수 있는 등급을 나열한 다음 primary_tier에 다른 값을 할당합니다.
gcloud sql tiers listCloud SQL을 배포할 수 있는 리전 목록은 인스턴스 설정을 참조하세요.
기본 데이터베이스 인스턴스 만들기
Cloud Shell에서 Cloud SQL의 단일 인스턴스를 만듭니다.
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regiongcloud명령어는 인스턴스가 생성될 때까지 일시중지됩니다.루트 비밀번호를 설정합니다.
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
기본 데이터베이스 만들기
Cloud Shell에서 MySQL 셸에 로그인하고 프롬프트에 루트 비밀번호를 입력합니다.
gcloud sql connect $primary_name --user=rootMySQL 프롬프트에서 데이터베이스를 만들고 테스트 데이터를 업로드합니다.
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");데이터가 성공적으로 커밋되었는지 확인합니다.
SELECT * FROM entries;2행의 데이터가 반환되는지 확인합니다.
MySQL 셸을 종료합니다.
exit;
이제 테이블과 일부 테스트 데이터가 포함된 단일 데이터베이스가 있습니다.
기본 인스턴스를 HA 데이터베이스 인스턴스로 변경
Cloud SQL은 리전 간 시스템이 아닌 리전별 HA 시스템으로만 구성할 수 있습니다. (리전 간 읽기 복제본을 설정하는 것은 Cloud SQL을 리전 간 시스템으로 구성하는 것과 다릅니다.) 자세한 내용은 인스턴스에서 고가용성 사용 설정 및 중지를 참조하세요.
Cloud Shell에서 HA 지원 Cloud SQL 인스턴스를 만듭니다.
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
자동 업데이트로 DR용 리전 간 읽기 복제본 추가
이 튜토리얼을 위한 리전 간 읽기 복제본은 다음 단계를 통해 충분히 만들 수 있습니다.
Cloud Shell에서 리전 간 읽기 복제본을 설정합니다.
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(선택사항) 데이터베이스가 복제되었는지 확인하려면Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
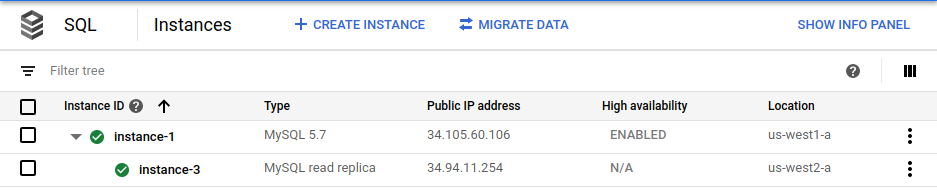
Google Cloud 콘솔에 기본 인스턴스(
instance-1)가 HA에 사용 설정되어 있고 리전 간 읽기 복제본(instance-3)이 있음이 표시됩니다.기본 인스턴스에 동일한 루트 비밀번호를 사용하여 리전 간 읽기 복제본에 로그인합니다.
gcloud sql connect $cross_region_replica_name --user=rootMySQL 프롬프트에서 데이터를 선택하여 복제가 제대로 작동하고 있는지 확인합니다.
USE guestbook; SELECT * FROM entries;MySQL 셸을 종료합니다.
exit;
전체 리전 간 읽기 복제본을 설정하는 방법에 대한 자세한 내용은 Cloud SQL 문서를 참조하세요.
프로덕션 환경에 있는 대규모 데이터베이스의 경우 기본 데이터베이스를 백업하고 백업에서 리전 간 읽기 복제본을 만드는 것이 좋습니다. 이 단계는 읽기 복제본이 기본 데이터베이스와 동기화되는 데 걸리는 시간을 줄여줍니다. 다음 섹션에서 이 절차를 설명합니다. 하지만 이 단계를 건너뛰고 2단계로 진행할 수도 있습니다.
덤프 파일을 기반으로 리전 간 읽기 복제본 추가
리전 간 읽기 복제본 생성을 최적화하는 방법 중 하나는 새로운 기본 인스턴스에 액세스하는 지점에서 복제본을 동기화하는 대신 이전의 일관된 기본 데이터베이스 상태에서 동기화하는 것입니다. 이 최적화를 하려면 복제본이 시작 상태로 사용하는 덤프 파일을 만들어야 합니다.
덤프 파일을 기반으로 복제본을 만드는 단계는 외부 서버에서 Cloud SQL(v1.1)로 복제를 참조하세요. 이 방식은 대규모 프로덕션 데이터베이스에 유용할 수 있습니다. 하지만 이 튜토리얼에서는 테스트 데이터 세트가 완전히 복제될 만큼 작아서 이 단계를 건너뜁니다.
2단계: 재해 시뮬레이션(리전 서비스 중단)
이 단계에서는 기본 데이터베이스를 사용할 수 없도록 설정하여 프로덕션 설정에서 기본 리전의 서비스 중단을 시뮬레이션합니다.
리전 간 읽기 복제본 지연 확인
다음 단계에서는 리전 간 읽기 복제본의 복제 지연을 결정합니다.
Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
읽기 복제본(instance-3)을 클릭합니다.
측정항목 드롭다운 목록에서 복제 지연을 클릭합니다.
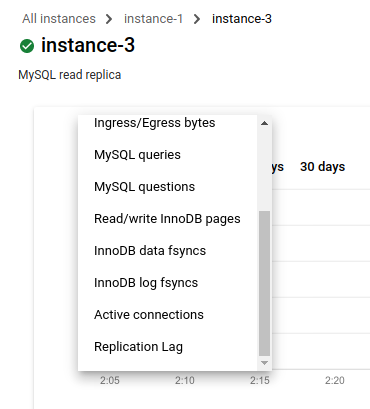
측정항목이 복제 지연으로 변경됩니다. 그래프에 지연 시간이 표시되지 않는 경우는 다음과 같습니다.
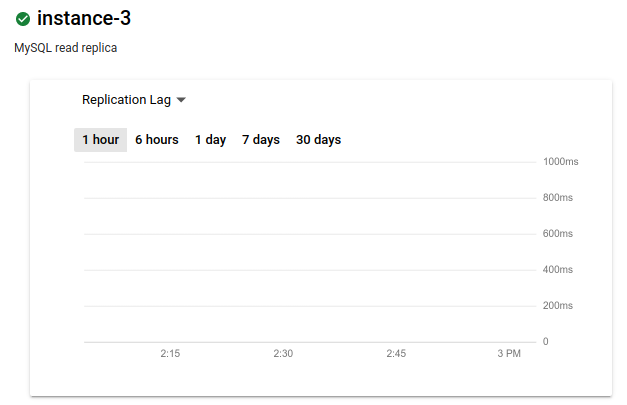
지연 시간이 0이면 모든 트랜잭션이 복제되므로 기본 리전 서비스 중단이 발생하는 경우 복제 지연 시간이 0인 경우가 가장 좋습니다. 0이 아니면 일부 트랜잭션이 복제되지 않을 수 있습니다. 이 경우 리전 간 읽기 복제본에는 기본 인스턴스에서 커밋된 모든 트랜잭션이 포함되지 않습니다.
기본 인스턴스를 사용할 수 없도록 설정
다음 단계에서는 기본 인스턴스를 중지하여 재해를 시뮬레이션합니다. 리전 간 읽기 복제본이 기본 인스턴스에 연결되어 있는 경우 먼저 복제본을 분리해야 합니다. 그렇지 않으면 Cloud SQL 인스턴스를 중지할 수 없습니다.
Cloud Shell에서 기본 인스턴스로의 리전 간 읽기 복제본을 삭제합니다.
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replication메시지가 표시되면 계속 진행하는 옵션을 수락합니다.
기본 데이터베이스 인스턴스를 중지합니다.
gcloud sql instances patch $primary_name --activation-policy NEVER
DR 구현
Cloud Shell에서 리전 간 읽기 복제본을 독립형 인스턴스로 승격합니다.
gcloud sql instances promote-replica $cross_region_replica_name메시지가 표시되면 계속 진행하는 옵션을 수락합니다. Cloud SQL 인스턴스 페이지에는 이전 리전 간 읽기 복제본(
instance-3)이 새 기본 인스턴스로, 이전 기본 인스턴스(instance-1)가 중지된 인스턴스로 표시됩니다.
리전 간 읽기 복제본을 새 기본 인스턴스로 승격한 후에는 HA에 이를 사용 설정합니다. 환경 변수를 적절한 이름으로 지정하는 것이 좋습니다.
환경 변수를 업데이트합니다.
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3새 기본 인스턴스를 시작합니다.
gcloud sql instances patch $primary_name --activation-policy ALWAYS새 기본 인스턴스를 HA 리전 인스턴스로 사용 설정합니다.
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_time세 번째 리전에 리전 간 읽기 복제본을 만듭니다.
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region이전 단계에서는
cross_region_replica_region환경 변수를us-west3로 설정합니다.장애 조치가 완료되면 Google Cloud 콘솔의 Cloud SQL 인스턴스 페이지에 새 기본 인스턴스(
instance-3)가 HA로 사용 설정되어 있고 리전 간 읽기 복제본(instance-5)이 있음이 표시됩니다.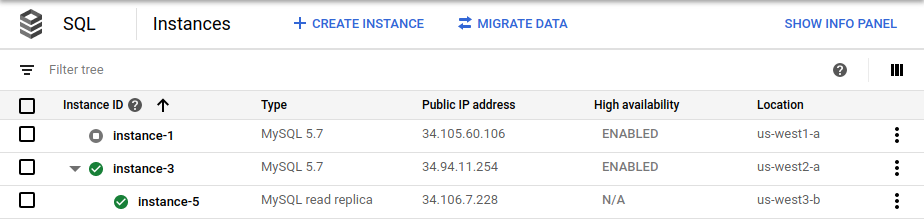
(선택사항) 정기적인 백업이 있는 경우 앞에서 설명한 프로세스를 따라 새 기본 버전을 최신 백업 버전과 동기화합니다.
(선택사항) Cloud SQL 프록시를 사용하는 경우 애플리케이션 처리를 다시 시작하려면 새 기본 인스턴스를 사용하도록 프록시를 구성합니다.
단기 리전 서비스 중단 처리
장애 조치가 완료되기 전에 장애 조치를 트리거하는 서비스 중단이 해결될 수 있습니다. 이 경우 장애 조치 프로세스를 취소하고 서비스 중단이 발생한 리전에서 원래 기본 Cloud SQL 인스턴스를 계속 사용하는 것이 좋습니다.
장애 조치 프로세스의 특정 상태에 따라 리전 간 읽기 복제본이 이미 승격되었을 수 있습니다. 이 경우에는 리전 간 읽기 복제본을 삭제하고 다시 만들어야 합니다.
분할 브레인 상황을 방지하기 위해 원래 기본 인스턴스를 삭제합니다.
분할 브레인 상황을 방지하려면 원래 기본 인스턴스를 삭제하거나 데이터베이스 클라이언트에서 액세스할 수 없도록 해야 합니다.
장애 조치 후 클라이언트가 원본 기본 데이터베이스와 새 기본 데이터베이스에 동시에 쓰기 작업을 수행하면 분할 브레인 상황이 발생할 수 있습니다. 이 경우 두 데이터베이스의 콘텐츠가 일관되지 않습니다. 장애 조치 후 원래 기본 데이터베이스는 오래되어 읽기 또는 쓰기 트래픽을 수신해서는 안 됩니다.
Cloud Shell에서 원래 기본 인스턴스를 삭제합니다.
gcloud sql instances delete $former_primary_name메시지가 표시되면 계속 진행하는 옵션을 수락합니다.
Google Cloud 콘솔의 Cloud SQL 인스턴스 페이지에 더 이상 원래 기본 인스턴스(
instance-1)가 배포의 일부로 표시되지 않습니다.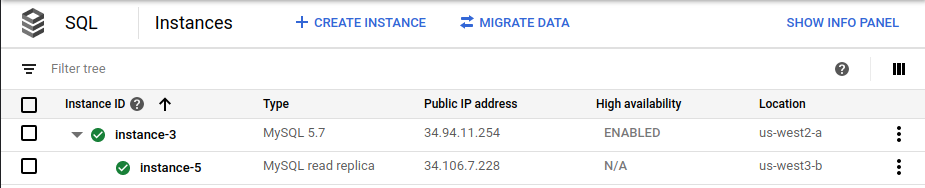
3단계: 대체 수행
원래 리전(R1)을 사용할 수 있게 된 후 대체를 수행하려면 2단계에서 설명한 것과 동일한 프로세스를 따릅니다. 이 프로세스는 다음과 같이 요약됩니다.
원래 리전(R1)에서 두 번째 리전 간 읽기 복제본을 만듭니다. 이 시점에서 기본 인스턴스에는 리전 간 읽기 복제본 2개가 하나는 리전 R3에, 나머지 하나는 리전 R1에 있습니다.
R1의 리전 간 읽기 복제본을 최종 기본 인스턴스로 승격합니다.
최종 기본 인스턴스에 HA를 사용 설정합니다.
us-west2에서 최종 기본 인스턴스의 리전 간 읽기 복제본을 만듭니다.분할 브레인 상황을 방지하려면 더 이상 필요하지 않은 모든 인스턴스(R3의 원본 기본 인스턴스 및 교차 리전 읽기 복제본)를 삭제합니다.
앞에서 설명한 것처럼 새 기본 데이터베이스의 정의된 시작 상태가 포함된 초기 백업을 만드는 것이 좋습니다.
이제 최종 배포에는 HA 기본(이름:
instance-6)과 리전 간 읽기 복제본(이름:instance-8)이 있습니다.수동 DR과 자동 DR의 장단점 비교
다음 표에서는 DR 프로세스를 수동으로 또는 자동으로 수행할 때의 장단점에 대해 설명합니다. 목표는 올바른 접근 방식과 잘못된 접근 방식을 판단하는 것이 아니라, 필요에 가장 적합한 접근 방식을 결정하는 데 도움이 되는 기준을 제공하는 것입니다.
수동 실행 자동 실행 장점:
- 모든 단계를 완벽히 제어할 수 있습니다.
- 프로세스의 모든 문제를 즉시 확인, 처리, 문서화할 수 있습니다.
- 장애 조치 중에 모든 프로세스 단계를 보고 검토할 수 있습니다.
장점:
- 장애 조치 프로세스를 수행하고 테스트할 수 있습니다.
- 자동화는 가장 빠른 수행을 제공하고 지연을 최소화합니다.
- 수행은 운영자, 운영자의 지식, 존재 여부와 무관합니다.
단점:
- 프로세스 단계를 수동으로 수행하면 프로세스 속도가 느려집니다.
- 사용자의 입력 오류가 있으면 문제가 발생할 수 있습니다.
- 프로세스 테스트에는 일반적으로 여러 역할과 시간이 수반되므로 정기적인 테스트가 어렵습니다.
단점:
- 예기치 않은 오류가 발생하는 경우에는 프로덕션 장애 조치 중에 디버그해야 합니다.
- 프로세스 중에 오류가 발생하면 프로세스를 중단했던 상태에서 스크립트를 재개(복구)해야 합니다.
- 특히 오류 상황에서 스크립트 동작을 이해하려면 스크립트와 그 구현에 대한 지식이 필요합니다.
먼저 수동 구현으로 시작하는 것이 좋습니다. 그런 다음 가능하면 프로덕션에서 정기적으로 구현을 실행하여 수동 프로세스가 작동하고 모든 팀 구성원이 각자의 역할과 책임을 알 수 있도록 합니다. 단계별 프로세스 문서에서 수동 프로세스를 정의하는 것이 좋습니다. 모든 구현 후에는 프로세스 문서를 확인하거나 수정해야 합니다.
프로세스를 세부 조정하고 신뢰성을 확인한 후 프로세스 자동화 여부를 결정합니다. 자동화된 프로세스를 선택하고 수행하는 경우 프로덕션 환경에서 프로세스를 정기적으로 테스트하여 안정적으로 수행할 수 있는지 확인해야 합니다.
삭제
이 튜토리얼에서 사용된 리소스에 대한 비용이 Google Cloud 계정에 청구되지 않게 하려면 이 튜토리얼에서 만든 Google Cloud 프로젝트를 삭제하면 됩니다.
프로젝트 삭제
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- Cloud SQL 재해 복구에 대해 알아보기
- Compute Engine에서 MySQL의 재해 복구에 대해 읽어보기
- 클라우드 인프라 서비스 중단 시 재해 복구 아키텍처에 대해 알아봅니다.
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 살펴봅니다. Cloud 아키텍처 센터 살펴보기