Para mejorar el uso de los recursos, puedes monitorizar las tasas de uso de la GPU de tus instancias de máquina virtual.
Cuando conozcas los porcentajes de uso de la GPU, podrás realizar tareas como configurar grupos de instancias gestionados que se pueden usar para autoescalar recursos.
Para revisar las métricas de GPU con Cloud Monitoring, sigue estos pasos:
- En cada VM, configure la secuencia de comandos de informes de métricas de GPU. Esta secuencia de comandos instala el agente de informes de métricas de GPU. Este agente se ejecuta a intervalos en la VM para recoger datos de la GPU y los envía a Cloud Monitoring.
- En cada VM, ejecuta la secuencia de comandos.
- En cada VM, configura el agente de informes de métricas de GPU para que se inicie automáticamente al arrancar.
- Consulta los registros en Google Cloud Cloud Monitoring.
Roles obligatorios
Para monitorizar el rendimiento de la GPU en máquinas virtuales de Windows, debes conceder los roles de Gestión de Identidades y Accesos (IAM) necesarios a los siguientes principales:
- La cuenta de servicio que usa la instancia de VM
- Tu cuenta de usuario
Para asegurarte de que tú y la cuenta de servicio de la VM tenéis los permisos necesarios para monitorizar el rendimiento de la GPU en las VMs de Windows, pide a tu administrador que os conceda a ti y a la cuenta de servicio de la VM los siguientes roles de gestión de identidades y accesos en el proyecto:
-
Administrador de instancias de Compute (v. 1) (
roles/compute.instanceAdmin.v1) -
Editor de las métricas de monitorización (
roles/monitoring.metricWriter)
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar el acceso a proyectos, carpetas y organizaciones.
Es posible que tu administrador también pueda concederte a ti y a la cuenta de servicio de la VM los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Configurar la secuencia de comandos de informes de métricas de GPU
Requisitos
En cada una de tus máquinas virtuales, comprueba que cumples los siguientes requisitos:
- Cada VM debe tener GPUs conectadas.
- Cada máquina virtual debe tener un controlador de GPU instalado.
Descargar la secuencia de comandos
Abre un terminal de PowerShell como administrador y usa el comando Invoke-WebRequest para descargar la secuencia de comandos.
Invoke-WebRequest está disponible en PowerShell 3.0 o versiones posteriores.
Google Cloud te recomienda que uses ctrl+v para pegar los bloques de código copiados.
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
Ejecutar la secuencia de comandos
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
Configurar el agente para que se inicie automáticamente al arrancar
Para asegurarse de que el agente de informes de métricas de GPU esté configurado para ejecutarse al iniciar el sistema, use el siguiente comando para añadir el agente al Programador de tareas de Windows.
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
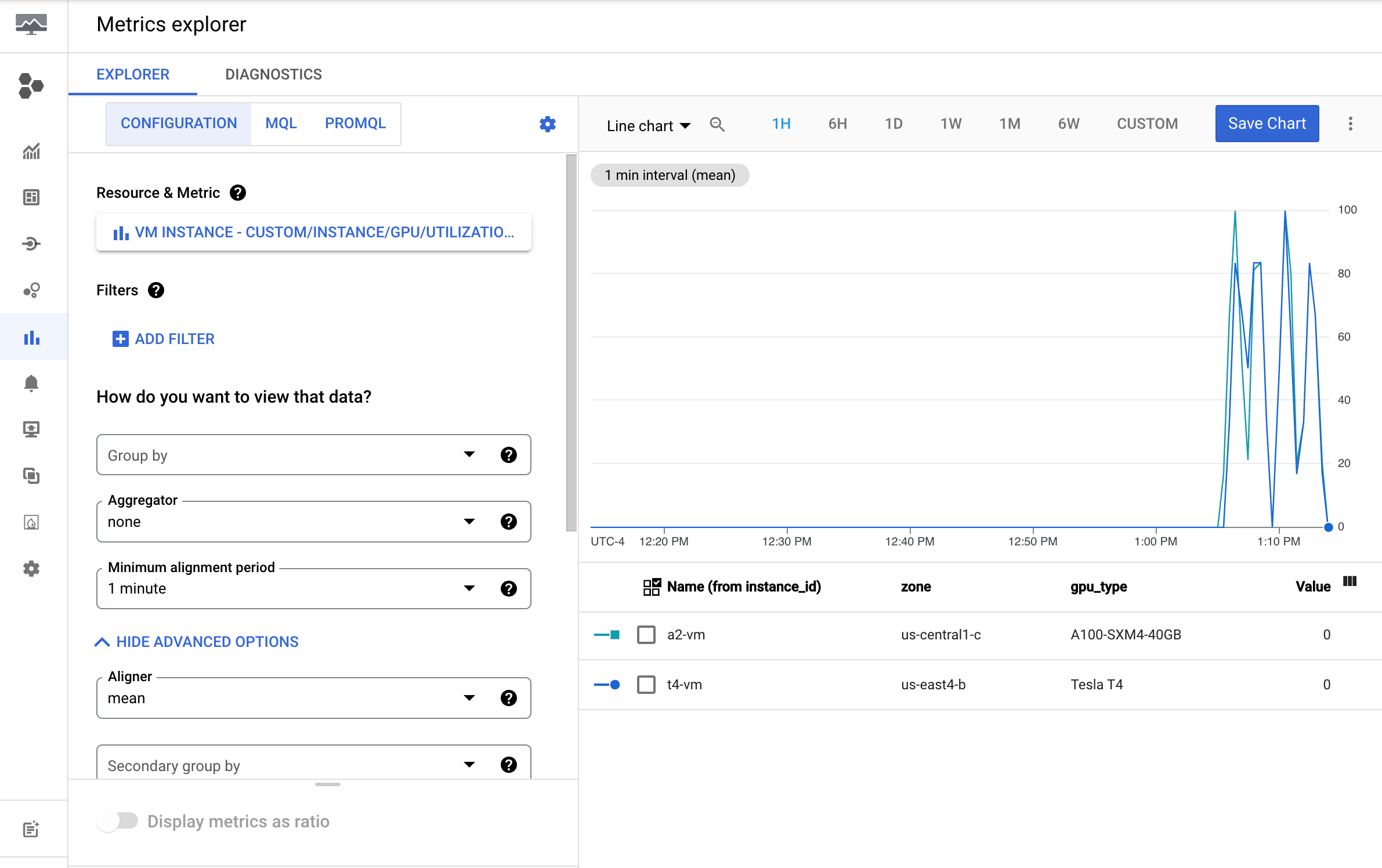
Consultar métricas en Cloud Monitoring
En la Google Cloud consola, ve a la página Explorador de métricas.
Despliega el menú Seleccionar una métrica.
En el menú Recurso, selecciona Instancia de VM.
En el menú Categoría de métrica, selecciona Personalizada.
En el menú Métrica, seleccione la métrica que quiera representar en el gráfico. Por ejemplo,
custom/instance/gpu/utilization.Haz clic en Aplicar.
La utilización de la GPU debería ser similar a la siguiente:
Métricas disponibles
| Nombre de la métrica | Descripción |
|---|---|
instance/gpu/utilization |
Porcentaje del tiempo durante el periodo de muestreo anterior en el que se ha ejecutado uno o varios kernels en la GPU. |
instance/gpu/memory_utilization |
Porcentaje del tiempo del periodo de muestreo anterior durante el cual se ha leído o escrito la memoria global (del dispositivo). |
instance/gpu/memory_total |
Memoria de GPU total instalada. |
instance/gpu/memory_used |
Memoria total asignada por los contextos activos. |
instance/gpu/memory_used_percent |
Porcentaje de la memoria total asignada por los contextos activos. El intervalo va de 0 a 100. |
instance/gpu/memory_free |
Memoria libre total. |
instance/gpu/temperature |
Temperatura de la GPU principal en grados Celsius (°C). |
Siguientes pasos
- Para gestionar el mantenimiento del host de GPU, consulta Gestionar eventos de mantenimiento de host de GPU.
- Para mejorar el rendimiento de la red, consulta Usar un ancho de banda de red mayor.