Dokumen ini menjelaskan cara persistent disk dapat diakses dari instance mesin virtual (VM) dan proses replikasi persistent disk. Bagian ini juga menjelaskan infrastruktur inti persistent disk. Dokumen ini ditujukan untuk engineer dan arsitek Google Cloud yang ingin menggunakan persistent disk di sistem mereka.
Persistent disk bukanlah disk lokal yang terpasang pada mesin fisik, melainkan layanan jaringan yang dipasang ke VM sebagai perangkat blok jaringan. Saat Anda membaca atau menulis dari persistent disk, data akan ditransmisikan melalui jaringan. Persistent disk adalah perangkat penyimpanan jaringan, tetapi memungkinkan banyak kasus penggunaan dan fungsi dalam hal kapasitas, fleksibilitas, dan keandalan, yang tidak dapat disediakan oleh disk konvensional.
Persistent disk dan Colossus
Persistent disk dirancang untuk berjalan bersama sistem file Google, Colossus, yang merupakan sistem block storage terdistribusi. Driver persistent disk secara otomatis mengenkripsi data di VM sebelum dikirim dari VM ke jaringan. Lalu, Colossus mempertahankan data tersebut. Saat Colossus membaca data, driver membongkar enkripsi data yang masuk.
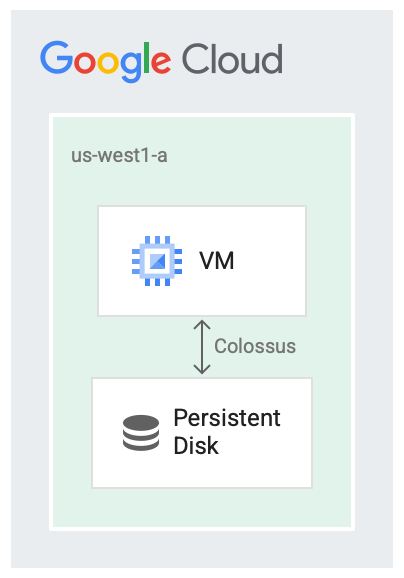
Persistent disk menggunakan Colossus untuk backend penyimpanan.
Memiliki disk sebagai layanan (disk as services) berguna dalam sejumlah kasus, misalnya:
- Mengubah ukuran disk saat VM berjalan menjadi lebih mudah daripada menghentikan VM terlebih dahulu. Anda dapat meningkatkan ukuran disk tanpa menghentikan VM.
- Memasang dan melepas disk menjadi lebih mudah jika disk dan VM tidak harus berbagi siklus proses yang sama atau ditempatkan bersama. Anda dapat menghentikan VM dan menggunakan persistent boot disk untuk mem-booting VM lain.
- Fitur ketersediaan tinggi seperti replikasi menjadi lebih mudah karena driver disk dapat menyembunyikan detail replikasi dan menyediakan replikasi waktu tulis otomatis.
Latensi disk
Ada berbagai alat tolok ukur yang dapat Anda gunakan untuk memantau latensi overhead dari penggunaan disk sebagai layanan jaringan. Contoh berikut menggunakan antarmuka disk SCSI, bukan antarmuka NVMe, dan menampilkan output VM yang melakukan beberapa pembacaan blok 4 KiB dari persistent disk. Berikut ini contoh latensi yang Anda lihat dalam pembacaan:
$ ioping -c 5 /dev/sda1
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=293.7 us (warmup)
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=330.0 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=278.1 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=307.7 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=310.1 us
--- /dev/sda1 (block device 10.00 GiB) ioping statistics ---
4 requests completed in 1.23 ms, 16 KiB read, 3.26 k iops, 12.7 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 278.1 us / 306.5 us / 330.0 us / 18.6 us
Compute Engine juga memungkinkan Anda memasang SSD lokal ke virtual machine jika Anda memerlukan prosesnya secepat mungkin. Saat menjalankan server cache atau menjalankan tugas pemrosesan data besar di mana ada output menengah, sebaiknya pilih SSD lokal. Tidak seperti persistent disk, data di SSD lokal tidak persisten dan, akibatnya, VM menghapus data setiap kali mesin virtual dimulai ulang. SSD lokal hanya cocok untuk kasus pengoptimalan.
Output berikut adalah contoh latensi yang Anda lihat dengan 4 KiB pembacaan dari SSD lokal menggunakan antarmuka disk NVMe:
$ ioping -c 5 /dev/nvme0n1
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=245.3 us(warmup)
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=252.3 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=244.8 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=289.5 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=219.9 us
--- /dev/nvme0n1 (block device 375 GiB) ioping statistics ---
4 requests completed in 1.01 ms, 16 KiB read, 3.97 k iops, 15.5 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 219.9 us / 251.6 us / 289.5 us / 25.0 us
Replikasi
Saat membuat Persistent Disk baru, Anda dapat membuat disk di satu zona, atau mereplikasinya di dua zona dalam region yang sama.
Misalnya, jika Anda membuat satu disk di zona, seperti di us-west1-a, Anda akan memiliki
satu salinan disk. Ini disebut sebagai disk zona.
Anda dapat meningkatkan ketersediaan disk dengan menyimpan
salinan disk lainnya di zona berbeda dalam region, seperti di
us-west1-b.
Disk yang direplikasi di dua zona di region yang sama disebut Persistent Disk regional.
Region tidak mungkin gagal sepenuhnya, tetapi kegagalan zona dapat terjadi. Mereplikasi dalam region di zona yang berbeda, seperti yang ditunjukkan pada gambar berikut, membantu meningkatkan ketersediaan dan mengurangi latensi disk. Jika kedua zona replikasi gagal, hal ini dianggap sebagai kegagalan seluruh region.
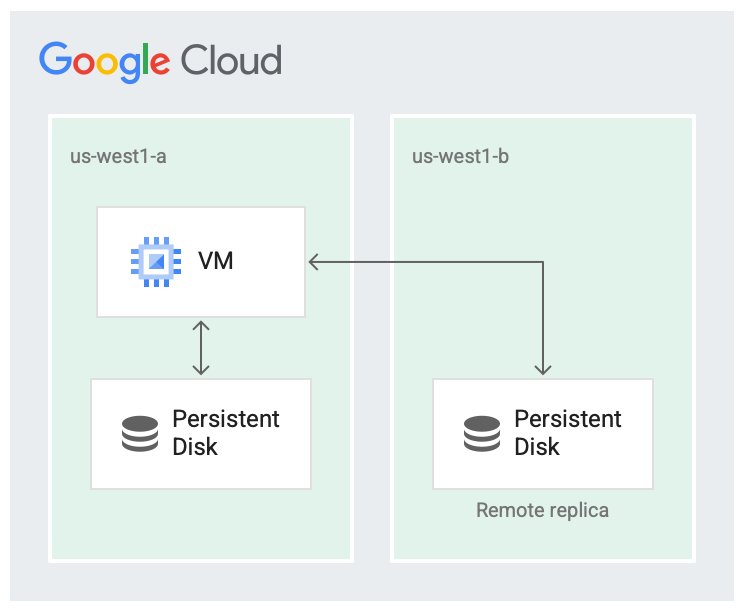
Disk direplikasi dalam dua zona.
Dalam skenario yang direplikasi, data tersedia di zona lokal (us-west1-a) yang merupakan zona tempat mesin virtual berjalan. Kemudian, data direplikasi ke contoh Colossus lain di zona lain (us-west1-b). Setidaknya salah satu zona harus berada di zona yang sama dengan tempat VM berjalan.
Perlu diperhatikan bahwa replikasi persistent disk hanya untuk ketersediaan tinggi disk. Pemadaman layanan zonal juga dapat memengaruhi mesin virtual atau komponen lainnya, yang juga dapat menyebabkan pemadaman layanan.
Urutan baca/tulis
Dalam menentukan urutan baca/tulis, atau urutan pembacaan dan penulisan data ke disk, sebagian besar pekerjaan dilakukan oleh driver disk di VM Anda. Sebagai pengguna, Anda tidak perlu berurusan dengan semantik replikasi, dan dapat berinteraksi dengan sistem file seperti biasa. Driver yang mendasarinya menangani urutan untuk membaca dan menulis.
Secara default, sistem beroperasi dalam mode replikasi penuh, dengan permintaan untuk membaca atau menulis dari disk akan dikirim ke kedua replika.
Dalam mode replikasi penuh, hal berikut akan terjadi:
- Saat menulis, permintaan tulis mencoba menulis ke kedua replika dan mengonfirmasi saat kedua penulisan berhasil.
- Saat membaca, VM akan mengirimkan permintaan baca ke kedua replika, dan menampilkan hasil dari replika yang berhasil. Jika waktu permintaan baca habis, permintaan baca lainnya akan dikirim.
Jika replika tertinggal dan gagal mengonfirmasi bahwa permintaan baca atau tulis telah selesai, maka pembacaan dan penulisan tidak akan lagi dikirim ke replika. Replika harus melalui proses rekonsiliasi untuk mengembalikannya ke status saat ini sebelum replikasi dapat dilanjutkan.
Langkah selanjutnya
- Pelajari cara mengonfigurasi disk untuk memenuhi persyaratan performa.
- Lihat praktik terbaik untuk snapshot persistent disk.