Wenn Sie Ihren VMs Laufwerke hinzufügen möchten, wählen Sie eine der Blockspeicheroptionen aus, die die Compute Engine bietet. Jede der folgenden Speicheroptionen hat eigene Preis- und Leistungsmerkmale:
- Google Cloud Hyperdisk-Volumes sind Netzwerkspeicher für die Compute Engine mit konfigurierbarer Leistung und konfigurierbaren Volumes, deren Größe dynamisch angepasst werden kann. Sie bieten im Vergleich zu Persistent Disk eine deutlich höhere Leistung, Flexibilität und Effizienz. Mit Hyperdisk mit ausgeglichener Hochverfügbarkeit können Daten synchron zwischen Laufwerken in zwei Zonen repliziert werden, um Schutz zu bieten, wenn eine Zone nicht mehr verfügbar ist.
- Mit Hyperdisk Storage Pools können Sie Hyperdisk-Kapazität und ‑Leistung insgesamt erwerben und dann aus diesem Speicherpool Laufwerke für Ihre VMs erstellen.
- Persistent Disk-Volumes bieten einen leistungsstarken und redundanten Netzwerkspeicher. Jedes Persistent Disk-Volume wird über Hunderte von physischen Laufwerken „gestriped”.
- Standardmäßig verwenden VMs zonale Persistent Disk und speichern Ihre Daten auf Volumes, die sich innerhalb einer einzelnen Zone befinden, z. B.
us-west1-c. - Sie können auch regionale Persistent Disk-Volumes erstellen, die Daten synchron zwischen Laufwerken replizieren, die sich in zwei Zonen befinden, und Schutz bieten, wenn eine Zone nicht mehr verfügbar ist.
- Standardmäßig verwenden VMs zonale Persistent Disk und speichern Ihre Daten auf Volumes, die sich innerhalb einer einzelnen Zone befinden, z. B.
- Lokale SSDs sind physische Laufwerke, die direkt mit demselben Server wie Ihre VM verbunden sind. Sie bieten eine bessere Leistung, sind jedoch sitzungsspezifisch.
Kostenvergleiche finden Sie unter Laufwerkspreise. Wenn Sie sich nicht sicher sind,welche Option Sie verwenden sollen, ist die häufigste Lösung für Maschinenreihen der älteren Generation,Ihrer VM ein Balanced Persistent Disk-Volume hinzuzufügen. Bei den neuesten Maschinenreihen fügen Sie Ihrer Compute-Instanz ein Hyperdisk-Volume hinzu.
Neben Blockspeicher bietet die Compute Engine auch Datei- und Objektspeicheroptionen. Informationen zum Prüfen und Vergleichen der Speicheroptionen finden Sie unter Speicheroptionen prüfen.
Einführung
Standardmäßig hat jede Compute Engine-VM ein einzelnes Bootlaufwerk, auf dem sich das Betriebssystem befindet. Die Bootlaufwerksdaten werden in der Regel auf einem Persistent Disk- oderHyperdisk Balanced-Volume gespeichert. Wenn Ihre Anwendungen zusätzlichen Speicherplatz benötigen, können Sie ein oder mehrere der folgenden Speicher-Volumes für Ihre VM bereitstellen.
Weitere Informationen zu den einzelnen Speicheroptionen finden Sie in der folgenden Tabelle:
| Abgestimmte Persistent Disk |
SSD- Persistent Disk |
Standard- Persistent Disk |
Extrem- Persistent Disk |
Hyperdisk Balanced | Hyperdisk ML | Hyperdisk Extrem | Hyperdisk Durchsatz | Lokale SSDs | |
|---|---|---|---|---|---|---|---|---|---|
| Speichertyp | Kostengünstiger und zuverlässiger Blockspeicher | Schneller, zuverlässiger Blockspeicher | Effizienter, zuverlässiger Blockspeicher | Höchste Leistung von Persistent Disk-Blockspeicher mit anpassbaren IOPS | Hohe Leistung für anspruchsvolle Arbeitslasten zu geringeren Kosten | Speicher mit dem höchsten Durchsatz, optimiert für Arbeitslasten für maschinelles Lernen. | Schnellste Blockspeicheroption mit anpassbaren IOPS | Kostengünstiger und durchsatzorientierter Blockspeicher mit anpassbarem Durchsatz | Lokaler Hochleistungs-Blockspeicher |
| Mindestkapazität pro Laufwerk | Zonal: 10 GiB Regional: 10 GiB |
Zonal: 10 GiB Regional: 10 GiB |
Zonal: 10 GiB Regional: 200 GiB |
500 GiB | Zonal und regional: 4 GiB | 4 GiB | 64 GiB | 2 TiB | 375 GiB, 3 TiB mit Z3 |
| Maximale Kapazität pro Laufwerk | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 32 TiB | 375 GiB, 3 TiB mit Z3 |
| Kapazitätserhöhung | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | Je nach Maschinentyp† |
| Maximale Kapazität pro VM | 257 TiB* | 257 TiB* | 257 TiB* | 257 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 36 TiB |
| Umfang des Zugriffs | Zone | Zone | Zone | Zone | Zone | Zone | Zone | Zone | Instanz |
| Datenredundanz | Zonal und multizonal | Zonal und multizonal | Zonal und multizonal | Zonal | Zonal und multizonal | Zonal | Zonal | Zonal | Keine |
| Verschlüsselung inaktiver Daten | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
| Benutzerdefinierte Verschlüsselungsschlüssel | Ja | Ja | Ja | Ja | Ja‡ | Ja | Ja | Ja | Nein |
| Anleitung | Extreme Persistent Disk hinzufügen | Lokale SSD hinzufügen | |||||||
Zusätzlich zu den Speicheroptionen von Google Cloud können Sie auf Ihren VMs alternative Speicherlösungen implementieren.
- Erstellen eines Dateiservers oder verteilten Dateisystems auf Compute Engine zur Verwendung als Netzwerkdateisystem mit NFSv3- und SMB3-Funktionen.
- Bereitstellen eines RAM-Laufwerks im VM-Speicher, um ein Blockspeichervolumen mit hohem Durchsatz und niedriger Latenz zu erstellen.
Blockspeicherressourcen haben unterschiedliche Leistungsmerkmale. Berücksichtigen Sie Ihre Anforderungen an Speichergröße und Leistung, wenn Sie den geeigneten Blockspeichertyp für Ihre VMs auswählen.
Informationen zu den Leistungsgrenzen finden Sie unter:
Persistent Disk
Persistent Disk-Volumes sind langlebige Netzwerkspeichergeräte, auf die VM-Instanzen wie auf physische Laufwerke auf einem Desktop-Computer oder einem Server zugreifen können. Die Daten auf einem Persistent Disk-Volume sind auf mehrere physische Laufwerke verteilt. Compute Engine verwaltet die physischen Laufwerke und die Datenverteilung und sorgt damit automatisch für Redundanz und optimale Leistung.
Persistent Disk-Volumes sind unabhängig von Ihrer VM. Sie können sie deshalb trennen oder verschieben, wenn Sie Daten aufbewahren möchten, auch nachdem Sie die VMs gelöscht haben. Die Leistung von Persistent Disk hängt von der Volume-Größe ab. Sie können bestehende Persistent Disk-Volumes jederzeit ändern oder einer VM weitere Persistent Disk-Volumes hinzufügen, um die Leistungs- und Speicherplatzanforderungen zu erfüllen.
Persistent Disk-Typen
Wenn Sie einen nichtflüchtigen Speicher konfigurieren, können Sie einen der folgenden Laufwerkstypen auswählen.
- Abgestimmter nichtflüchtiger Speicher (
pd-balanced)- Eine Alternative zu leistungsstarkem nichtflüchtigem Speicher (pd-ssd)
- Kompromiss zwischen Leistung und Kosten. Bei den meisten VM-Typen mit Ausnahme großer Datenmengen haben diese Laufwerke die gleiche maximale IOPS-Anzahl wie nichtflüchtige SSD-Speicher und eine niedrigere IOPS pro GiB. Dieser Laufwerkstyp bietet Leistungsebenen, die für die meisten allgemeinen Anwendungen geeignet sind. Die Kosten liegen dabei zwischen dem standardmäßigen nichtflüchtigen Standardspeicher und dem leistungsstarken nichtflüchtigen Speicher (pd-ssd).
- Gesichert durch Solid-State-Laufwerke (SSD)
- Leistungsstarker nichtflüchtiger SSD-Speicher (
pd-ssd)- Geeignet für Unternehmensanwendungen und Hochleistungsdatenbanken, die eine geringere Latenz und mehr IOPS als nichtflüchtige Standardspeicher erfordern.
- Gesichert durch Solid-State-Laufwerke (SSD)
- Nichtflüchtige Standardspeicher (
pd-standard)- Geeignet für große Datenverarbeitungsarbeitslasten, die hauptsächlich sequenzielle E/A-Vorgänge verwenden.
- Gesichert durch Standardfestplattenlaufwerke (HDD)
- Extrem nichtflüchtiger Speicher (
pd-extreme)- Einheitliche hohe Leistung sowohl für Arbeitslasten mit zufälligen Zugriffen als auch für Bulk-Durchsätze
- Für High-End-Datenbankarbeitslasten konzipiert
- Ermöglicht es, Ziel-IOPS bereitzustellen
- Gesichert durch Solid-State-Laufwerke (SSD)
- Verfügbar für eine begrenzte Anzahl von Maschinentypen.
Wenn Sie ein Laufwerk in der Google Cloud Console erstellen, ist der Standard-Laufwerktyp pd-balanced. Wenn Sie ein Laufwerk mit der gcloud CLI oder der Compute Engine API erstellen, ist der Standardlaufwerkstyp pd-standard.
Informationen zur Unterstützung von Maschinentypen finden Sie hier:
Langlebigkeit von Persistent Disk
Die Langlebigkeit des Laufwerks stellt die Wahrscheinlichkeit eines Datenverlusts für ein typisches Laufwerk in einem typischen Jahr unter Verwendung einer Reihe von Annahmen zu Hardwarefehlern, der Wahrscheinlichkeit katastrophaler Ereignisse, der Isolierungspraktiken und der Entwicklungsprozesse in Google-Rechenzentren und den internen Codierungen dar, die von den einzelnen Laufwerktypen verwendet werden. Datenverlustereignisse bei Persistent Disk sind extrem selten und waren in der Vergangenheit das Ergebnis koordinierter Hardwarefehler, Softwarefehler oder einer Kombination aus beidem. Google unternimmt außerdem zahlreiche Schritte, um das branchenweite Risiko der schleichenden Datenbeschädigung zu minimieren. Menschliche Fehler eines Google Cloud-Kunden, z. B. wenn ein Kunde versehentlich ein Laufwerk löscht, fallen nicht unter die Langlebigkeit von Persistent Disk.
Es besteht ein sehr geringes Risiko eines Datenverlusts bei einem regionalen nichtflüchtigen Speicher aufgrund der internen Datencodierungen und der Replikation. Regionale nichtflüchtige Speicher stellen doppelt so viele Replikate bereit wie zonale Persistent Disks, wobei ihre Replikate auf zwei Zonen in derselben Region verteilt sind. Dadurch bieten sie hohe Verfügbarkeit und können zur Notfallwiederherstellung verwendet werden, wenn ein ganzes Rechenzentrum verloren geht und nicht wiederhergestellt werden kann. Dies ist bisher jedoch noch nicht passiert. Auf die zusätzlichen Replikate in einer zweiten Zone kann sofort zugegriffen werden, wenn eine primäre Zone während eines langen Ausfalls nicht mehr verfügbar ist.
Die folgende Tabelle zeigt die Langlebigkeit für die einzelnen Laufwerkstypen. Eine Langlebigkeit von 99,999 % bedeutet, dass bei 1.000 Laufwerken wahrscheinlich 100 Jahre vergehen, ohne dass ein einzelnes Laufwerk verloren geht.
| Zonale Standard-Persistent Disk | Abgestimmte zonale Persistent Disk | Zonale SSD-Persistent Disk | Zonale extreme Persistent Disk | Regionale Standard-Persistent Disk | Regionale abgestimmte Persistent Disk | Regionale SSD-Persistent Disk |
|---|---|---|---|---|---|---|
| Besser als 99,99 % | Besser als 99,999 % | Besser als 99,999 % | Besser als Besser als 99,9999 % | Besser als 99,999 % | Besser als Besser als 99,9999 % | Besser als Besser als 99,9999 % |
Zonale Persistent Disk
Nutzerfreundlichkeit
Compute Engine übernimmt fast alle Laufwerksverwaltungsaufgaben, damit Sie sich nicht um Dinge wie Partitionierung, redundante Laufwerksarrays oder Subvolume-Verwaltung kümmern müssen. Es ist im Allgemeinen nicht notwendig, größere logische Volumes zu erstellen. Sie können aber die Kapazität der sekundären angehängten Persistent Disk auf 257 TB pro VM erhöhen und diese Vorgehensweisen für die Persistent Disk-Volumes anwenden. Sie sparen Zeit und erhalten eine optimale Leistung, wenn Sie die Persistent Disk-Volumes mit einem einzigen Dateisystem und ohne Partitionstabellen formatieren.
Falls Sie Ihre Daten auf mehrere Volumes aufteilen möchten, fügen Sie weitere Laufwerke hinzu, anstatt die vorhandenen in mehrere Partitionen zu unterteilen.
Wenn Sie zusätzlichen Speicherplatz für die Persistent Disk-Volumes benötigen, können Sie die Größe des Speichers anpassen und nicht neu partitionieren und formatieren.
Leistung
Die Leistung von Persistent Disk ist vorhersehbar und wird mit der bereitgestellten Kapazität linear skaliert, bis die Grenzen der bereitgestellten vCPUs einer VM erreicht sind. Weitere Informationen zu den Grenzen der Leistungsskalierung und zur Leistungsoptimierung finden Sie unter Laufwerke so konfigurieren, dass sie die Leistungsanforderungen erfüllen.
Standard-Persistent Disks bewältigen sequenzielle Lese-/Schreibvorgänge effizient und kostengünstig, eignen sich aber nicht für große Mengen zufälliger Ein-/Ausgabevorgänge pro Sekunde (Input/Output Operations Per Second, IOPS). Wenn Ihre Anwendungen zufällige IOPS in hoher Zahl erfordern, verwenden Sie nichtflüchtige SSD- oder extreme Persistent Disk. SSD-Persistent Disk ist für Latenzen im einstelligen Millisekundenbereich ausgelegt. Die beobachtete Latenz ist anwendungsspezifisch.
Compute Engine optimiert die Leistung und Skalierung von Persistent Disk-Volumes automatisch. Ein Striping mehrerer Laufwerke oder das Vorwärmen von Laufwerken ist nicht erforderlich. Wenn Sie mehr Speicherplatz oder eine bessere Leistung benötigen, passen Sie die Größe Ihrer Laufwerke an. Sie können auch weitere vCPUs hinzufügen, um mehr Speicherplatz, Durchsatz und IOPS zu erzielen. Die Leistung der Persistent Disk basiert auf der Gesamtkapazität für Persistent Disk, die einer Instanz zugewiesen ist, und auf der Anzahl der vCPUs, die die VM aufweist.
Bei Bootgeräten können Sie die Kosten senken, wenn Sie eine Standard-Persistent Disk verwenden. Kleine Persistent Disk-Volumes mit 10 GiB eignen sich für einfache Bootvorgänge und Anwendungsfälle in Verbindung mit der Paketverwaltung. Wenn Sie aber bei der allgemeineren Verwendung des Bootgeräts eine konsistente Leistung gewährleisten möchten, verwenden Sie eine abgestimmte Persistent Disk als Bootlaufwerk.
Jeder Persistent Disk-Schreibvorgang zählt zum kumulativen ausgehenden Netzwerk-Traffic der jeweiligen VM. Daher gilt für Persistent Disk-Schreibvorgänge eine Obergrenze für den ausgehenden Netzwerk-Traffic Ihrer VM.
Zuverlässigkeit
Persistent Disk ist von Haus aus redundant, um Ihre Daten vor Geräteausfällen zu schützen und ihre Verfügbarkeit auch bei Wartungsarbeiten im Rechenzentrum sicherzustellen. Für alle Vorgänge der Persistent Disk werden Prüfsummen berechnet, um sicherzustellen, dass die gelesenen Daten mit den geschriebenen übereinstimmen.
Außerdem können Sie Snapshots von Persistent Disk erstellen, um Datenverluste aufgrund von Nutzerfehlern zu verhindern. Snapshots werden inkrementell angelegt und dauern nur wenige Minuten, selbst wenn sie von Laufwerken erstellt werden, die an laufende VMs angehängt sind.
Modus für mehrere Autoren
Sie können eine SSD-Persistent Disk im Modus für mehrere Autoren gleichzeitig an zwei N2-VMs anhängen, damit beide VMs auf dem Laufwerk lesen und schreiben können.
Persistent Disk im Modus für mehrere Autoren bietet eine gemeinsame Blockspeicherfunktion und stellt eine infrastrukturelle Grundlage für das Erstellen hochverfügbarer freigegebener Dateisysteme und Datenbanken dar. Diese speziellen Dateisysteme und Datenbanken sollten für die Verwendung mit gemeinsam genutztem Blockspeicher entwickelt werden und die Cache-Kohäsion zwischen VMs mithilfe von Tools wie nichtflüchtigen SCSI-Reservierungen verarbeiten.
Persistent Disk mit einem Modus für mehrere Autoren sollte jedoch im Allgemeinen nicht direkt verwendet werden. Beachten Sie, dass viele Dateisysteme wie EXT4, XFS und NTFS nicht für die gemeinsame Nutzung von Blockspeicher ausgelegt sind. Weitere Informationen zu den Best Practices für die gemeinsame Nutzung von Persistent Disk zwischen VMs finden Sie unter Best Practices.
Wenn Sie einen vollständig verwalteten Dateispeicher benötigen, können Sie eine Filestore-Dateifreigabe auf Ihren Compute Engine-VMs bereitstellen.
Wenn Sie den Schreibmodus für mehrere Autoren für neue Persistent Disk-Volumes aktivieren möchten, erstellen Sie eine neue Persistent Disk und geben Sie das Flag --multi-writer in der gcloud-Befehlszeile oder das Attribut multiWriter in der Compute Engine-API an. Weitere Informationen finden Sie unter Volumes für Persistent Disk zwischen VMs freigeben.
Verschlüsselung von Persistent Disk
Compute Engine verschlüsselt Ihre Daten automatisch, bevor diese von der VM an Persistent Disk übertragen werden. Jede Persistent Disk wird entweder mit vom System definierten oder mit vom Kunden bereitgestellten Schlüsseln verschlüsselt. Nutzer haben keinen Einfluss auf die Art und Weise, in der Google die Persistent Disk-Daten über mehrere physische Laufwerke verteilt.
Wenn Sie eine Persistent Disk löschen, verwirft Google die Codierschlüssel und die Daten werden unwiederbringlich gelöscht. Dieser Vorgang kann nicht rückgängig gemacht werden.
Sie können aber Laufwerke mit eigenen Verschlüsselungsschlüsseln erstellen, um die Kontrolle über die Datenverschlüsselung zu behalten.
Beschränkungen
Sie können ein Persistent Disk-Volume nicht an eine VM in einem anderen Projekt anhängen.
Sie können eine abgestimmte Persistent Disk an maximal 10 VMs im schreibgeschützten Modus anhängen.
Wenn Sie benutzerdefinierte Maschinentypen oder vordefinierte Maschinentypen mit mindestens einer vCPU verwenden, können Sie bis zu 128 Persistent Disk-Volumes anhängen.
Jedes Persistent Disk-Volume kann bis zu 64 TiB groß sein. Es ist daher nicht nötig, aus Festplatten-Arrays große logische Volumes zu erstellen. Jede VM kann nur einen begrenzten Persistent Disk-Speicher und eine gewisse Anzahl Persistent Disk-Volumes haben. Für vordefinierte Maschinentypen und benutzerdefinierte Maschinentypen gelten dieselben Persistent Disk-Beschränkungen.
Die meisten VMs können bis zu 128 Persistent Disk-Volumes und bis zu 257 TiB Gesamtspeicherplatz haben. Der Gesamtspeicherplatz für eine VM enthält die Größe des Bootlaufwerks.
Maschinentypen mit gemeinsam genutztem Kern sind auf 16 Persistent Disk-Volumes und 3 TiB Persistent Disk-Speicher insgesamt beschränkt.
Wenn Sie logische Volumes mit einer Kapazität von mehr als 64 TiB erstellen möchten, ist unter Umständen besondere Aufmerksamkeit erforderlich. Weitere Informationen zur Leistung logischer Volumes finden Sie unter Logische Volume-Größe.
Regionaler nichtflüchtiger Speicher
Regionale Persistent Disk-Volumes haben Speicherqualitäten, die denen von zonalen Persistent Disks ähneln. Regionale Persistent Disk-Volumes bieten jedoch eine dauerhafte Speicherung und Replikation von Daten zwischen zwei Zonen in derselben Region.
Synchrone Laufwerksreplikation
Wenn Sie eine neue Persistent Disk erstellen, können Sie das Laufwerk entweder in einer Zone erstellen oder über zwei Zonen innerhalb derselben Region hinweg replizieren.
Wenn Sie beispielsweise ein Laufwerk in einer Zone wie us-west1-a erstellen, haben Sie eine Kopie des Laufwerks. Dies wird als zonales Laufwerk bezeichnet.
Sie können die Verfügbarkeit des Laufwerks erhöhen, indem Sie eine weitere Kopie des Laufwerks in einer anderen Zone innerhalb der Region speichern, z. B. in us-west1-b.
Nichtflüchtige Speicher, die über zwei Zonen in derselben Region hinweg repliziert werden, werden als regionale nichtflüchtige Speicher bezeichnet. Sie können Hyperdisk Balanced High Availability auch für die zonenübergreifende synchrone Replikation von Google Cloud Hyperdisk verwenden.
Es ist unwahrscheinlich, dass eine Region vollständig ausfällt, aber zonale Fehler können auftreten. Die Replikation innerhalb der Region in verschiedenen Zonen hilft, wie in der folgenden Abbildung dargestellt, bei der Verfügbarkeit und reduziert die Laufwerkslatenz. Wenn beide Replikationszonen fehlschlagen, wird sie als Ausfall in der gesamten Region betrachtet.
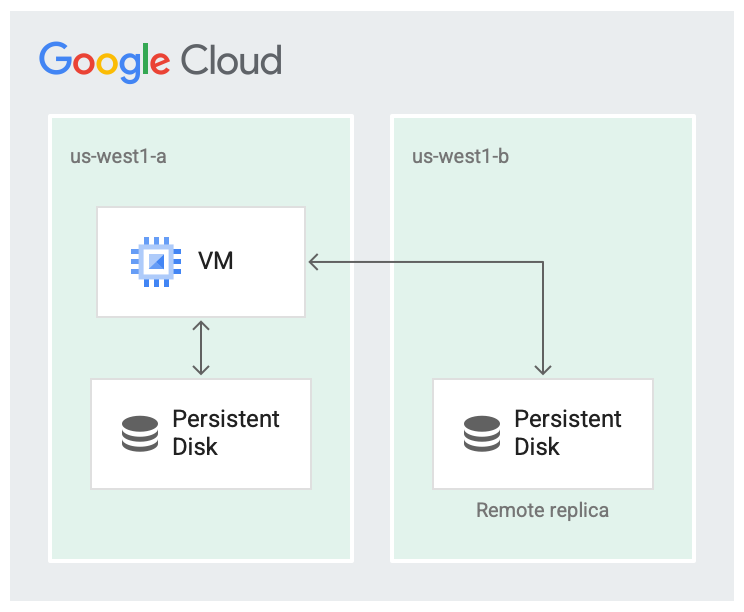
Das Laufwerk wird in zwei Zonen repliziert.
Im replizierten Szenario sind die Daten in der lokalen Zone (us-west1-a) verfügbar, in der die virtuelle Maschine (VM) ausgeführt wird. Anschließend werden die Daten in eine andere Zone (us-west1-b) repliziert. Eine der Zonen muss dieselbe Zone sein, in der die VM ausgeführt wird.
Bei einem zonalen Ausfall können Sie für Ihre Arbeitslast, die auf regionalem nichtflüchtigem Speicher ausgeführt wird, in der Regel einen Failover in eine andere Zone durchführen. Weitere Informationen finden Sie unter Failover für regionale Persistent Disk.
Designüberlegungen für regionalen nichtflüchtigen Speicher
Wenn Sie robuste Systeme oder Hochverfügbarkeitsdienste für Compute Engine konzipieren, sollten Sie regionale Persistent Disks mit anderen Best Practices kombinieren, z. B. mit der Sicherung Ihrer Daten mit Snapshots. Regionale Persistent Disk-Volumes funktionieren auch mit regional verwalteten Instanzgruppen.
Leistung
Regionale Persistent Disk-Volumes sind für Arbeitslasten vorgesehen, die im Vergleich zur Verwendung von Persistent Disk-Snapshots ein niedrigeres Recovery Point Objective (RPO) und ein niedrigeres Recovery Time Objective (RTO) erfordern.
Regionale Persistent Disk ist eine Option, wenn die Schreibleistung weniger kritisch ist als die Datenredundanz über mehrere Zonen hinweg.
Wie zonale Persistent Disk kann regionale Persistent Disk bei VMs mit einer größeren Anzahl von vCPUs eine höhere IOPS- und Durchsatzleistung erzielen. Weitere Informationen zu diesen und anderen Einschränkungen finden Sie unter Laufwerke so konfigurieren, dass sie die Leistungsanforderungen erfüllen.
Wenn Sie mehr Speicherplatz oder eine bessere Leistung benötigen, können Sie die Größe Ihrer regionalen Festplatten ändern, um mehr Speicherplatz, Durchsatz und IOPS hinzuzufügen.
Zuverlässigkeit
Compute Engine repliziert Daten Ihrer regionalen Persistent Disk in die Zonen, die Sie beim Erstellen Ihrer Festplatten ausgewählt haben. Die Daten jedes Replikats sind auf mehrere physische Maschinen innerhalb der Zone verteilt, um Redundanz zu gewährleisten.
Ähnlich wie bei zonaler Persistent Disk können Sie Persistent Disk-Snapshots erstellen, um Datenverluste aufgrund von Nutzerfehlern zu verhindern. Snapshots werden inkrementell angelegt und dauern nur wenige Minuten, selbst wenn sie von Laufwerken erstellt werden, die an laufende VMs angehängt sind.
Beschränkungen
- Mexiko, Osaka und Montreal haben drei Zonen, die sich in einem oder zwei physischen Rechenzentren befinden. In diesen Regionen gespeicherte Daten können bei einem Rechenzentrumsausfall verloren gehen. Daher sollten Sie für einen erhöhten Datenschutz in Erwägung ziehen, geschäftskritische Daten in einer zweiten Region zu sichern.
- Sie können regionalen nichtflüchtigen Speicher nur an VMs anhängen, die den Maschinentyp E2, N1, N2 oder N2D verwenden.
- Sie können Hyperdisk mit ausgeglichener Hochverfügbarkeit nur an unterstützte Maschinentypen anhängen.
- Sie können keinen regionalen nichtflüchtigen Speicher aus einem Image oder aus einem Laufwerk erstellen, das aus einem Image erstellt wurde.
- Im schreibgeschützten Modus können Sie einen regionalen abgestimmten nichtflüchtigen Speicher an maximal 10 VM-Instanzen anhängen.
- Die Mindestgröße eines regionalen nichtflüchtigen Standardspeichers beträgt 200 GiB.
- Sie können nur die Größe eines regionalen nichtflüchtigen Speichers oderHyperdisk mit ausgeglichenem Hochverfügbarkeits-Volume erhöhen. Sie können die Größe nicht verringern.
- Regionale nichtflüchtige Speicher- und Hyperdisk mit ausgeglichener Hochverfügbarkeits-Volumes haben unterschiedliche Leistungsmerkmale als die entsprechenden zonalen Laufwerke. Weitere Informationen finden Sie unter Blockspeicherleistung.
- Sie können ein Hyperdisk Balanced High Availability-Volume, das sich im Modus für mehrere Autoren befindet, nicht als Bootlaufwerk verwenden.
- Wenn Sie einen replizierten Speicher durch Klonen eines zonalen Laufwerks erstellen, sind die beiden zonalen Replikate zum Zeitpunkt der Erstellung nicht komplett synchron. Nach der Erstellung können Sie den regionalen Laufwerkklon innerhalb von durchschnittlich 3 Minuten verwenden. Sie müssen jedoch möglicherweise einige Minuten warten, bevor das Laufwerk einen vollständig replizierten Zustand erreicht und das Recovery Point Objective (RPO) fast null ist. Informationen zum Prüfen, ob Ihr repliziertes Laufwerk vollständig repliziert wurde
Google Cloud-Hyperdisk
Google Cloud Hyperdisk ist der Blockspeicher der nächsten Generation von Google. Durch die Auslagerung und dynamische Skalierung der Speicherverarbeitung wird die Speicherleistung vom VM-Typ und der Größe entkoppelt. Hyperdisk bietet im Vergleich zu Persistent Disk eine deutlich höhere Leistung, Flexibilität und Effizienz.
Hyperdisk abgestimmt
Hyperdisk Balanced für die Compute Engine eignet sich für eine Vielzahl von Anwendungsfällen, z. B. für LOB-Anwendungen (Line of Business), Webanwendungen und Datenbanken der mittleren Stufe, die nicht die Leistung von Hyperdisk Extreme erfordern. Sie können Hyperdisk Balanced auch für Anwendungen verwenden, bei denen mehrere VMs in derselben Zone gleichzeitig Schreibzugriff auf dasselbe Laufwerk benötigen.
Mit Hyperdisk Balanced-Volumes können Sie die Kapazität, die IOPS und den Durchsatz für Ihre Arbeitslasten dynamisch optimieren.
Hyperdisk ML
Für Arbeitslasten, bei denen Accelerators zum Trainieren oder Bereitstellen von Modellen für maschinelles Lernen verwendet werden, sollte Hyperdisk ML verwendet werden. Hyperdisk ML-Volumes bieten den schnellsten anpassbaren Durchsatz und eignen sich am besten für Modelle mit mehr als 20 GiB. Hyperdisk ML unterstützt auch den gleichzeitigen Lesezugriff auf dasselbe Volume von mehreren VMs.
Sie können die Kapazität und den Durchsatz eines Hyperdisk ML-Volumes dynamisch anpassen.
Hyperdisk Extrem
Hyperdisk Extreme bietet den schnellsten verfügbaren Blockspeicher. Sie eignet sich für High-End-Arbeitslasten, die den höchsten Durchsatz und die höchsten IOPS benötigen.
Mit Hyperdisk Extreme-Volumes können Sie die Kapazität und IOPS für Ihre Arbeitslasten dynamisch optimieren.
Hyperdisk Durchsatz
Hyperdisk Throughput eignet sich gut für Analysen mit horizontaler Skalierung, einschließlich Hadoop und Kafka, Datenlaufwerke für kostenempfindliche Anwendungen und kalter Speicher.
Mit Hyperdisk Throughput-Volumes können Sie die Kapazität und den Durchsatz für Ihre Arbeitslasten dynamisch optimieren. Sie können das bereitgestellte Durchsatzniveau ohne Ausfallzeiten oder Unterbrechung Ihrer Arbeitslasten ändern.
Hyperdisk mit ausgeglichener Hochverfügbarkeit
Mit Hyperdisk mit ausgeglichener Hochverfügbarkeit ist die synchrone Replikation auf Maschinenreihen der dritten Generation oder höher möglich. Hyperdisk mit ausgeglichener Hochverfügbarkeit ermöglicht eine Datenausfallsicherheit mit einer Replikation mit RPO=0 über zwei Zonen hinweg, ähnlich wie bei einem regionalen nichtflüchtigen Speicher.
Mit Hyperdisk Balanced High Availability-Volumes können Sie die Kapazität, die IOPS und den Durchsatz für Ihre Arbeitslasten dynamisch optimieren. Sie können die bereitgestellte Leistung und Kapazität ohne Ausfallzeiten oder Unterbrechung Ihrer Arbeitslasten ändern. Verwenden Sie Hyperdisk Balanced High Availability, wenn verschiedene VMs in derselben Region gleichzeitig Schreibzugriff auf dasselbe Laufwerk benötigen.
Hyperdisk-Volumes werden wie Persistent Disk erstellt und verwaltet. Sie haben jedoch die Möglichkeit, die bereitgestellte IOPS oder den Durchsatz festzulegen und diesen Wert jederzeit zu ändern. Es gibt keinen direkten Migrationspfad von Persistent Disk zu Hyperdisk. Stattdessen können Sie einen Snapshot erstellen und den Snapshot auf einem neuen Hyperdisk-Volume wiederherstellen.
Weitere Informationen zu Hyperdisk finden Sie unter Informationen zu Hyperdisks.
Langlebigkeit von Hyperdisk
Die Langlebigkeit des Laufwerks stellt die Wahrscheinlichkeit eines Datenverlusts für ein typisches Laufwerk in einem typischen Jahr dar. Die Zuverlässigkeit wird anhand einer Reihe von Annahmen zu Hardwareausfällen berechnet, z. B.:
- Die Wahrscheinlichkeit von Katastrophen
- Isolationspraktiken
- Engineering-Prozesse in Google-Rechenzentren
- Die internen Codierungen, die von den einzelnen Laufwerkstypen verwendet werden
Hyperdisk-Datenverlustereignisse sind extrem selten. Google unternimmt außerdem zahlreiche Schritte, um das branchenweite Risiko der schleichenden Datenbeschädigung zu minimieren.
Menschliche Fehler eines Google Cloud-Kunden, z. B. wenn ein Kunde versehentlich ein Laufwerk löscht, fallen nicht unter die Langlebigkeit von Hyperdisk.
Die folgende Tabelle zeigt die Langlebigkeit für die einzelnen Laufwerkstypen. Eine Langlebigkeit von 99,999 % bedeutet, dass bei 1.000 Laufwerken wahrscheinlich 100 Jahre vergehen, ohne dass ein einzelnes Laufwerk verloren geht.
| Hyperdisk Balanced | Hyperdisk Extrem | Hyperdisk ML | Hyperdisk Durchsatz |
|---|---|---|---|
| Besser als 99,999 % | Besser als Besser als 99,9999 % | Besser als 99,999 % | Besser als 99,999 % |
Hyperdisk-Verschlüsselung
Compute Engine verschlüsselt Ihre Daten automatisch, wenn auf ein Hyperdisk-Volume geschrieben wird. Sie können die Verschlüsselung auch mit vom Kunden verwalteten Verschlüsselungsschlüsseln anpassen.
Hyperdisk mit ausgeglichener Hochverfügbarkeit
Hyperdisk-Laufwerke mit ausgeglichener Hochverfügbarkeit bieten eine dauerhafte Speicherung und Replikation von Daten zwischen zwei Zonen in derselben Region. Für Hyperdisk Balanced High Availability-Volumes gelten Speicherlimits, die denen nicht replizierter Hyperdisk Balanced-Laufwerke ähneln.
Wenn Sie robuste Systeme oder Hochverfügbarkeitsdienste für Compute Engine konzipieren, sollten Sie Hyperdisk Balanced High Availability-Speicher mit anderen Best Practices kombinieren, z. B. mit der Sicherung Ihrer Daten mit Snapshots. Hyperdisk-Scheiben mit ausgeglichener Hochverfügbarkeit funktionieren auch mit regional verwalteten Instanzgruppen.
Im unwahrscheinlichen Fall eines zonalen Ausfalls können Sie für Ihre Arbeitslast, die auf Hyperdisk Balanced High Availability-Laufwerken ausgeführt wird, mit dem Flag --force-attach einen Failover zu einer anderen Zone durchführen. Mit dem Flag --force-attach können Sie das Hyperdisk Balanced High Availability-Laufwerk an eine Standby-Instanz anhängen, auch wenn das Laufwerk aufgrund der Nichtverfügbarkeit der ursprünglichen Compute-Instanz nicht von dieser getrennt werden kann. Weitere Informationen finden Sie unter Regionales Laufwerk-Failover.
Leistung
Hyperdisk mit ausgeglichenen Hochverfügbarkeits-Speichern wurden für Arbeitslasten entwickelt, die im Vergleich zur Verwendung von Hyperdisk-Snapshots für die Wiederherstellung ein niedrigeres Recovery Point Objective (RPO) und ein niedrigeres Recovery Time Objective (RTO) erfordern.
Hyperdisk Balanced High Availability-Laufwerke sind eine Option, wenn die Schreibleistung weniger kritisch ist als die Datenredundanz über mehrere Zonen hinweg.
Hyperdisk Balanced High Availability-Laufwerke haben anpassbare IOPS und Durchsatzleistung. Weitere Informationen zur Leistung und zu den Einschränkungen von Hyperdisk Balanced High Availability finden Sie unter Informationen zu Hyperdisk.
Wenn Sie mehr Speicherplatz oder eine bessere Leistung benötigen, können Sie die Hyperdisk-Volumes mit ausgeglichenen Hochverfügbarkeits-Volumes ändern, um mehr Speicherplatz, Durchsatz und IOPS hinzuzufügen.
Zuverlässigkeit
Compute Engine repliziert Daten Ihrer Hyperdisk-Hochverfügbarkeits-Laufwerke in die Zonen, die Sie beim Erstellen der Laufwerke angegeben haben. Die Daten jedes Replikats sind auf mehrere physische Maschinen innerhalb der Zone verteilt, um Redundanz zu gewährleisten.
Ähnlich wie bei Hyperdisk können Sie Snapshots von Hyperdisk-Balanced-Hochverfügbarkeitslaufwerken erstellen, um Datenverluste aufgrund von Nutzerfehlern zu verhindern. Snapshots werden inkrementell angelegt und dauern nur wenige Minuten, selbst wenn sie von Laufwerken erstellt werden, die an laufende VMs angehängt sind.
Hyperdisk-Volumes zwischen VMs freigeben
Bei bestimmten Hyperdisk-Volumes können Sie den gleichzeitigen Zugriff auf das Volume von mehreren VMs aktivieren, indem Sie die Laufwerkfreigabe aktivieren. Die Laufwerkfreigabe ist für eine Vielzahl von Anwendungsfällen nützlich, z. B. für die Entwicklung hochverfügbarer Anwendungen oder großer Arbeitslasten für maschinelles Lernen, bei denen mehrere VMs auf dasselbe Modell oder Trainingsdaten zugreifen müssen.
Weitere Informationen finden Sie unter Laufwerk zwischen VMs freigeben.
Hyperdisk Storage Pools
Mit Hyperdisk Storage Pools lassen sich die Gesamtbetriebskosten (TCO) für Blockspeicher leichter senken und die Blockspeicherverwaltung vereinfachen. Mit Hyperdisk Storage Pools können Sie einen Pool von Kapazität und Leistung auf maximal 1.000 Laufwerke in einem einzelnen Projekt teilen. Da Speicherpools eine schlanke Bereitstellung und Datenreduzierung bieten, können Sie eine höhere Effizienz erzielen. Speicherpools vereinfachen die Migration Ihres lokalen SAN in die Cloud und erleichtern es, Ihren Arbeitslasten die erforderliche Kapazität und Leistung zur Verfügung zu stellen.
Sie erstellen einen Speicherpool mit der geschätzten Kapazität und Leistung für alle Arbeitslasten in einem Projekt in einer bestimmten Zone. Anschließend erstellen Sie Laufwerke in diesem Speicherpool und hängen sie an vorhandene VMs an. Sie können auch ein Laufwerk im Speicherpool erstellen, wenn Sie eine neue VM erstellen. Jeder Speicherpool enthält einen Laufwerktyp, z. B. Hyperdisk Throughput. Es gibt zwei Arten von Hyperdisk Storage Pools:
- Ausgeglichener Hyperdisk-Speicherpool: für allgemeine Arbeitslasten, die am besten mit Hyperdisk Balanced-Laufwerken ausgeführt werden
- Hyperdisk Throughput Storage Pool: für Streaming, kalte Daten und Analysearbeitslasten, die sich am besten mit Hyperdisk Throughput-Laufwerken bedienen lassen
Optionen für die Kapazitätsbereitstellung
Die Kapazität von Hyperdisk Storage Pools kann auf zwei Arten bereitgestellt werden:
- Standardkapazitätsbereitstellung
- Bei der Standardbereitstellung für Kapazitäten erstellen Sie Laufwerke im Speicherpool, bis die Gesamtgröße aller Laufwerke die bereitgestellte Kapazität des Speicherpools erreicht. Die Laufwerke in einem Speicherpool mit Standardbereitstellung für Kapazitäten verbrauchen ähnlich wie Nicht-Pool-Laufwerke Kapazitäten, bei denen beim Erstellen der Laufwerke Kapazität verbraucht wird.
- Erweiterte Kapazitätsbereitstellung
Mit der erweiterten Kapazitätsbereitstellung können Sie einen Pool mit Thin-Provisioning und datenreduzierter Speicherkapazität auf alle Laufwerke in einem Speicherpool teilen. Ihnen wird die bereitgestellte Kapazität des Speicherpools in Rechnung gestellt.
Sie können Laufwerke in einem Speicherpool mit erweiterter Kapazität mit bis zu 500% der bereitgestellten Kapazität des Speicherpools bereitstellen. Nur die Datenmenge, die auf ein Laufwerk im Speicherpool geschrieben wird, beansprucht die Speicherpoolkapazität. Durch die automatische Datenreduzierung lässt sich die Auslastung der Speicherpoolkapazität noch weiter reduzieren.
Wenn die Kapazitätsauslastung eines Speicherpools mit erweiterter Kapazität 80% der bereitgestellten Kapazität erreicht, versucht Hyperdisk Storage Pools, dem Speicherpool automatisch Kapazität hinzuzufügen, um Fehler im Zusammenhang mit unzureichender Kapazität zu vermeiden.
Beispiel
Angenommen, Sie haben einen Speicherpool mit 10 TiB bereitgestellter Kapazität.
Bei der Standardkapazitätsbereitstellung gilt Folgendes:
- Sie können beim Erstellen von Laufwerken im Speicherpool eine Hyperdisk-Gesamtkapazität von bis zu 10 TiB bereitstellen. Ihnen werden die 10 TiB bereitgestellte Kapazität des Speicherpools in Rechnung gestellt.
- Wenn Sie im Speicherpool ein einzelnes Laufwerk mit einer Größe von 5 TiB erstellen und 2 TiB auf das Laufwerk schreiben, beträgt die verwendete Kapazität des Speicherpools 5 TiB.
Bei der erweiterten Kapazitätsbereitstellung gilt Folgendes:
- Sie können beim Erstellen von Laufwerken im Speicherpool eine Hyperdisk-Gesamtkapazität von bis zu 50 TiB bereitstellen. Ihnen werden die 10 TiB bereitgestellte Kapazität des Speicherpools in Rechnung gestellt.
- Wenn Sie im Speicherpool ein einzelnes Laufwerk mit einer Größe von 5 TiB erstellen, schreiben Sie 3 TiB Daten auf das Laufwerk. Die Datenreduzierung reduziert die Menge der geschriebenen Daten auf 2 TiB, die verwendete Kapazität des Speicherpools beträgt 2 TiB.
Optionen für die Leistungsbereitstellung
Die Leistung von Hyperdisk Storage Pools kann auf zwei Arten bereitgestellt werden:
- Standardleistung
Die Standardleistung ist die beste Option für die folgenden Arten von Arbeitslasten:
- Arbeitslasten, die nicht ausgeführt werden können, wenn die Leistung durch Ressourcen des Speicherpools begrenzt ist
- Arbeitslasten, bei denen die Laufwerke im Speicherpool wahrscheinlich zu korrelierten Leistungsspitzen führen, z. B. Datenlaufwerke für Datenbanken, die jeden Morgen eine Auslastungsspitze erreichen.
Standard-Speicherpools mit hoher Leistung profitieren nicht von der Thin-Provisioning-Technologie und senken die TCO für die Leistung nicht wesentlich. Bei der Bereitstellung mit Standardleistung erstellen Sie Laufwerke im Speicherpool, bis die Gesamtzahl der bereitgestellten IOPS oder der Durchsatz aller Laufwerke den bereitgestellten Wert des Speicherpools erreicht. Die Laufwerke in einem Speicherpool mit Standardbereitstellung für die Leistung verbrauchen IOPS und Durchsatz ähnlich wie Nicht-Pool-Laufwerke, bei denen Sie die Anzahl der IOPS und den Durchsatz beim Erstellen der Laufwerke bereitstellen. Ihnen werden die Gesamtzahl der IOPS und der Durchsatz in Rechnung gestellt, die für den Speicherpool bereitgestellt werden.
In einem abgestimmten Hyperdisk-Speicherpool mit Standardleistung werden die ersten 3.000 IOPS und 140 MiBps Durchsatz jedes Laufwerks im Speicherpool (die Baseline) nicht auf die Speicherpool-Ressourcen angerechnet. Wenn Sie Laufwerke im Speicherpool erstellen, werden alle IOPS und der gesamte Durchsatz, die über den Grundwert hinausgehen, dem Speicherpool entnommen.
Laufwerke, die in einem Speicherpool mit Standardleistung erstellt wurden, teilen sich keine Leistungsressourcen mit dem Rest des Speicherpools. Die Gesamtleistung aller Laufwerke im Speicherpool darf die insgesamt bereitgestellten IOPS oder den Durchsatz des Speicherpools nicht überschreiten.
- Erweiterte Leistungsbereitstellung
Bei Storage Pools mit erweiterter Leistungsbereitstellung wird die schlanke Bereitstellung genutzt, um die Leistungseffizienz zu erhöhen und die TCO für die Blockspeicherleistung zu senken. Mit der erweiterten Leistungsbereitstellung können Sie einen Pool bereitgestellter Leistung auf alle Laufwerke in einem Speicherpool verteilen. Der Speicherpool weist dynamisch Leistungsressourcen zu, wenn die Laufwerke im Speicherpool Daten lesen und schreiben. Nur die Anzahl der IOPS und der Durchsatz, die von einem Laufwerk im Speicherpool verwendet werden, beanspruchen die IOPS und den Durchsatz des Speicherpools. Da Speicherpools mit erweiterter Leistung mit Thin Provisioning bereitgestellt werden, können Sie den Laufwerken im Speicherpool mehr IOPS oder Durchsatz zuweisen, als Sie für den Speicherpool bereitgestellt haben – bis zu 500% der für den Speicherpool bereitgestellten IOPS oder des für den Speicherpool bereitgestellten Durchsatzes. Ähnlich wie bei der Standardleistung werden Ihnen die für den Speicherpool bereitgestellten IOPS und der Durchsatz in Rechnung gestellt.
In einem Hyperdisk Balanced Storage Pool mit erweiterter Leistungsbereitstellung haben die Laufwerke keine Baseline-Leistung. Jeder Lese- und Schreibvorgang eines Hyperdisk Balanced-Laufwerks im Speicherpool verbraucht Poolressourcen.
Wenn die Gesamtleistung aller Laufwerke im Speicherpool die für den Speicherpool bereitgestellte Gesamtleistung erreicht, kann es zu Leistungsengpässen kommen. Daher eignet sich die erweiterte Leistungsbereitstellung am besten für Arbeitslasten, bei denen die Spitzennutzung nicht stark korreliert ist. Wenn alle Ihre Arbeitslasten gleichzeitig Spitzenlast erreichen, kann der Storage Pool mit erweiterter Leistung die Leistungslimits des Storage Pools erreichen, was zu Konflikten bei den Leistungsressourcen führt.
Wenn in einem Speicherpool mit erweiterter Leistung für Laufwerke im Pool eine Beanspruchung von Leistungsressourcen erkannt wird, versucht die Funktion „Automatisch wachsen lassen“, die für die Laufwerke im Speicherpool verfügbaren IOPS oder den Durchsatz automatisch zu erhöhen, um Leistungsprobleme zu vermeiden.
Beispiel
Angenommen,Sie haben einen Hyperdisk Balanced Storage Pool mit 100.000 bereitgestellten IOPS.
Bei der Standardleistung gilt Folgendes:
- Sie können bis zu 100.000 IOPS bereitstellen,wenn Sie Hyperdisk Balanced-Laufwerke im Speicherpool erstellen.
- Ihnen werden die 100.000 IOPS der bereitgestellten Leistung des Hyperdisk Balanced-Speicherpools in Rechnung gestellt.
Wie Laufwerke, die außerhalb eines Speicherpools erstellt wurden,werden Hyperdisk Balanced-Laufwerke in Speicherpools mit Standardleistung automatisch mit bis zu 3.000 Baseline-IOPS und 140 MiB/s Baseline-Durchsatz bereitgestellt. Diese Basisleistung wird nicht auf die bereitgestellte Leistung für den Speicherpool angerechnet. Nur wenn Sie dem Speicherpool Laufwerke mit einer bereitgestellten Leistung hinzufügen, die über der Baseline liegt, wird dies auf die bereitgestellte Leistung für den Speicherpool angerechnet. Beispiele:
- Ein Laufwerk mit 3.000 IOPS nutzt keine Pool-IOPS und der Pool hat noch 100.000 bereitgestellte IOPS für andere Laufwerke verfügbar.
- Ein Laufwerk mit 13.000 IOPS belegt 10.000 Pool-IOPS. Im Pool sind noch 90.000 bereitgestellte IOPS verfügbar, die Sie anderen Laufwerken im Speicherpool zuweisen können.
Bei der erweiterten Leistungsbereitstellung gilt Folgendes:
- Sie können beim Erstellen von Laufwerken im Speicherpool eine Hyperdisk-Gesamtleistung von bis zu 500.000 IOPS bereitstellen.
- Ihnen werden 100.000 IOPS in Rechnung gestellt,die vom Speicherpool bereitgestellt werden.
- Wenn Sie ein einzelnes Laufwerk (
Disk1) mit 5.000 IOPS im Speicherpool erstellen, werden keine IOPS aus den bereitgestellten IOPS des Speicherpools verbraucht. Die Anzahl der IOPS, die Sie für neue Laufwerke bereitstellen können, die im Speicherpool erstellt wurden, beträgt jetzt 495.000. - Wenn
Disk1damit beginnt, Daten zu lesen und zu schreiben, und dabei in einer bestimmten Minute maximal 5.000 IOPS nutzt, werden 5.000 IOPS aus den bereitgestellten IOPS des Speicherpools verbraucht. Alle anderen Laufwerke, die Sie im selben Speicherpool erstellt haben, können in derselben Minute insgesamt maximal 95.000 IOPS nutzen, ohne dass es zu Konflikten kommt.
Bereitgestellte Kapazität und Leistung von Hyperdisk Storage Pools ändern
Sie können die bereitgestellte Kapazität, die IOPS und den Durchsatz für Ihren Speicherpool erhöhen oder verringern, wenn Ihre Arbeitslasten skaliert werden. Bei einem Speicherpool mit erweiterter Kapazität oder erweiterter Leistung steht zusätzliche Kapazität oder Leistung allen vorhandenen und neuen Laufwerken im Speicherpool zur Verfügung. Außerdem versucht Compute Engine, den Speicherpool automatisch so zu ändern:
- Erweiterte Kapazität: Wenn der Speicherpool 80% der bereitgestellten Kapazität erreicht, versucht die Compute Engine, dem Speicherpool automatisch mehr Kapazität hinzuzufügen.
- Erweiterte Leistung: Wenn es aufgrund von Überlastung zu längeren Zugriffskonflikten im Speicherpool kommt, versucht die Compute Engine, die IOPS oder den Durchsatz des Speicherpools zu erhöhen.
Weitere Informationen zu Hyperdisk Storage Pools
Unter den folgenden Links finden Sie Informationen zur Verwendung von Hyperdisk Storage Pools:
- Speicherpools
- Speicherpools erstellen
- Laufwerke mit einem Speicherpool zu VMs hinzufügen
- Speicherpools verwalten
- Messwerte für Speicherpools prüfen
Lokale SSDs
Lokale SSDs sind physisch mit dem Server verbunden, auf dem Ihre VM gehostet wird. Sie haben einen höheren Durchsatz und eine geringere Latenz als Standard-Persistent Disk oder SSD-Persistent Disk. Die auf einer lokalen SSD abgelegten Daten sind nicht länger zugänglich, wenn die VM angehalten oder gelöscht wird. Sie können je nach Anzahl der vCPUs mehrere lokale SSDs an Ihre VM anhängen.
Die Größe jedes lokalen SSD-Laufwerks beträgt unveränderlich 375 GiB, mit Ausnahme von Z3-VMs, die ein lokales SSD-Laufwerk mit einer Größe von 3 TiB verwenden. Wenn Sie mehr Speicherplatz benötigen, fügen Sie Ihrer VM beim Erstellen mehrere lokale SSD-Laufwerke hinzu. Die maximale Anzahl lokaler SSDs, die Sie an eine VM anhängen können, hängt vom Maschinentyp und der Anzahl der verwendeten vCPUs ab.
Datenpersistenz auf lokalen SSDs
Lesen Sie Persistenz lokaler SSD-Daten, um zu erfahren, welche Ereignisse dafür sorgen, dass Ihre Daten auf der lokalen SSD erhalten bleiben, und welche zur Folge haben, dass diese Daten unwiederbringlich verloren gehen.
Lokale SSDs und Maschinentypen
Sie können lokale SSDs an die meisten in Compute Engine verfügbaren Maschinentypen anhängen, wie in der Vergleichstabelle für Maschinenserien gezeigt. Je nach Maschinentyp bestehen jedoch Einschränkungen hinsichtlich der Anzahl der lokalen SSDs, die zugeordnet werden können. Weitere Informationen finden Sie unter Gültige Anzahl lokaler SSD-Laufwerke auswählen.
Kapazitätslimits bei lokalen SSD-Laufwerken
Die maximale Kapazität von lokalen SSD-Laufwerken, die für eine VM verfügbar ist, ist:
| Maschinentyp | Größe des lokalen SSD | Anzahl der Laufwerke | Maximale Kapazität |
|---|---|---|---|
| Z3 | 3 TiB | 12 | 36 TiB |
c3d-standard-360-lssd |
375 GiB | 32 | 12 TiB |
c3d-highmem-360-lssd |
375 GiB | 32 | 12 TiB |
c3-standard-176-lssd |
375 GiB | 32 | 12 TiB |
| N1, N2 und N2D | 375 GiB | 24 | 9 TiB |
| N1, N2 und N2D | 375 GiB | 16 | 6 TiB |
| A3 | 375 GiB | 16 | 6 TiB |
| C2, C2D, A2 Standard, M1 und M3 | 375 GiB | 8 | 3 TiB |
| A2-Ultra | 375 GiB | 8 | 3 TiB |
Einschränkungen lokaler SSDs
Für lokale SSDs gelten die folgenden Einschränkungen:
- Verwenden Sie eine VM-Instanz mit 32 oder mehr vCPUs, um maximale IOPS-Werte zu erreichen.
- Lokale SSD-Laufwerke können nicht an VMs mit Maschinentypen mit gemeinsam genutztem Kern angehängt werden.
- Sie können keine lokalen SSD-Laufwerke an N4-, H3-, M2-E2- und Tau-T2A-Maschinentypen anhängen.
- Sie können keine vom Kunden bereitgestellten Verschlüsselungsschlüssel mit einem lokalen SSD-Laufwerk verwenden. Compute Engine verschlüsselt Ihre Daten automatisch, wenn diese auf eine lokale SSD geschrieben werden.
Leistung
Lokale SSDs bieten sehr hohe IOPS und eine geringe Latenz. Im Gegensatz zu Persistent Disk müssen Sie das Striping auf lokalen SSD-Laufwerken selbst verwalten.
Die Leistung lokaler SSDs hängt von mehreren Faktoren ab. Weitere Informationen finden Sie unter Leistung lokaler SSDs und Leistung lokaler SSDs optimieren.
Cloud Storage-Buckets
Cloud Storage-Buckets sind die flexibelste, skalierbarste und langlebigste Speicheroption für VMs. Wenn Ihre Anwendungen die geringere Latenz von Hyperdisk, nichtflüchtigem Speicher, und lokalen SSDs, nicht benötigen, können Sie Ihre Daten in einem Cloud Storage-Bucket speichern.
Verbinden Sie Ihre VM mit einem Cloud Storage-Bucket, wenn Latenz und Durchsatz keine hohe Priorität haben und es darum geht, Daten ohne viel Aufwand zwischen mehreren VMs oder Zonen freizugeben.
Eigenschaften von Cloud Storage-Buckets
In den folgenden Abschnitten erhalten Sie Informationen zum Verhalten und zu den Eigenschaften von Cloud Storage-Buckets.
Leistung
Die Leistung der Cloud Storage-Buckets hängt von der gewählten Speicherklasse und der Zone des Buckets im Verhältnis zur VM ab.
Die Nutzung der Standard Storage-Klasse von Cloud Storage am selben Standort wie die VM erzielt eine Leistung, die mit Hyperdisk oder Persistent Disks vergleichbar ist, jedoch mit höherer Latenz und weniger konsistenten Durchsatzmerkmalen. Mit der Standard Storage-Klasse in einer Dual-Region werden Ihre Daten redundant in zwei Regionen gespeichert. Für eine optimale Leistung bei Verwendung einer Dual-Region sollten sich Ihre VMs in einer der Regionen befinden, die Teil der Dual-Region ist.
Die Klassen Nearline Storage, Coldline Storage und Archive Storage eignen sich vor allem für die langfristige Datenarchivierung. Im Gegensatz zur Standard Storage-Klasse haben diese Klassen eine Mindestspeicherdauer und es fallen Kosten für den Datenabruf an. Daher sind sie für die langfristige Speicherung selten abgerufener Daten geeignet.
Zuverlässigkeit
Alle Cloud Storage-Buckets haben eine integrierte Redundanz, um ihre Daten vor Geräteausfällen zu schützen und die Verfügbarkeit der Daten während Wartungsarbeiten im Rechenzentrum aufrechtzuerhalten. Für alle Cloud Storage-Vorgänge werden Prüfsummen berechnet, um dafür zu sorgen, dass die gelesenen Daten mit den geschriebenen Daten übereinstimmen.
Flexibilität
Im Gegensatz zu Hyperdisk oder nichtflüchtigen Speichernsind Cloud Storage-Buckets nicht auf die Zone beschränkt, in der sich Ihre VM befindet. Außerdem können Daten von mehreren VMs gleichzeitig auf einem Bucket gelesen und geschrieben werden. Sie können beispielsweise VMs in mehreren Zonen so konfigurieren, dass sie Daten im selben Bucket lesen und schreiben, anstatt diese auf ein Hyperdisk - oder Persistent Disk -Volume in mehreren Zonen zu replizieren.
Cloud Storage-Verschlüsselung
Compute Engine verschlüsselt Ihre Daten automatisch, bevor diese von der VM an Cloud Storage-Buckets übertragen werden. Sie müssen Dateien auf Ihren VMs nicht verschlüsseln, bevor Sie sie in einen Bucket schreiben.
Buckets können Sie genauso wie Persistent Disk-Volumes mit eigenen Verschlüsselungsschlüsseln verschlüsseln.Daten in Google Cloud Storage-Buckets schreiben und daraus lesen
Verwenden Sie zum Schreiben und Lesen von Dateien aus Cloud Storage-Buckets das gcloud storage-Befehlszeilentool oder eine Cloud Storage-Clientbibliothek.
gcloud-Speicher
Das gcloud storage-Befehlszeilentool ist standardmäßig auf den meisten VMs installiert, die öffentliche Images verwenden.
Wenn Ihre VM nicht das gcloud storage-Befehlszeilentool hat, können Sie es installieren.
Stellen Sie eine Verbindung zu Ihren Linux-VMs her oder stellen Sie eine Verbindung zu Ihren Windows-VMs her oder verwenden Sie SSH oder eine andere Verbindungsmethode.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

Wenn Sie auf dieser VM noch nie
gcloud storagegenutzt haben, verwenden Sie die gcloud CLI, um die Anmeldedaten einzurichten.gcloud init
Wenn die VM für die Verwendung eines Dienstkontos mit einem Cloud Storage-Bereich konfiguriert ist, können Sie diesen Schritt auch überspringen.
Mit dem
gcloud storage-Tool können Sie einen Bucket erstellen, Daten in Buckets schreiben und Daten aus diesen Buckets lesen. Wenn Sie Daten in einen bestimmten Bucket schreiben oder daraus lesen möchten, müssen Sie Zugriff auf den Bucket haben. Sie können Daten aus öffentlich zugänglichen Buckets lesen.Optional können Sie Daten auch zu Cloud Storage streamen.
Clientbibliothek
Wenn die VM für die Verwendung eines Dienstkontos mit einem Cloud Storage-Bereich konfiguriert ist, können Sie zum Lesen und Schreiben von Daten in Cloud Storage-Buckets die Cloud Storage API verwenden.
Stellen Sie eine Verbindung zu einer VM her.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
Installieren und konfigurieren Sie eine Clientbibliothek für Ihre bevorzugte Sprache.
Folgen Sie bei Bedarf den Codebeispielen, um auf der VM einen Cloud Storage-Bucket zu erstellen.
Verwenden Sie die Codebeispiele zum Schreiben von Daten und zum Lesen von Daten und fügen Sie Code in die Anwendung ein, mit dem eine Datei in einen Cloud Storage-Bucket geschrieben oder daraus gelesen wird.
Nächste Schritte
- Hyperdisk-Volume zu Ihrer VM hinzufügen.
- Persistent DiskVolume zu Ihrer VM hinzufügen.
- Fügen Sie Ihrer VM ein regionales Laufwerk hinzu.
- Erstellen Sie eine VM mit lokalen SSDs.
- Dateiserver oder ein verteiltes Dateisystem erstellen
- Kontingente für Laufwerke prüfen
- Speicherinterne RAM-Disks auf Ihrer VM bereitstellen