Partitions- und Clusterempfehlungen verwalten
In diesem Dokument wird beschrieben, wie der Recommender für Partitionen und Cluster funktioniert, wie Sie Ihre Empfehlungen und Statistiken aufrufen und wie Sie Partitions- und Clusterempfehlungen anwenden.
Funktionsweise des Recommenders
Der BigQuery-Partitionierungs- und -Clustering-Recommender generiert Empfehlungen für Partitionen oder Cluster zur Optimierung Ihrer BigQuery-Tabellen. Der Recommender analysiert Workflows in Ihren BigQuery-Tabellen und gibt Empfehlungen zur besseren Optimierung Ihrer Workflows und Abfragekosten durch Tabellenpartitionierung oder Tabellen-Clustering.
Weitere Informationen zum Recommender-Dienst finden Sie in der Recommender-Übersicht.
Der Partitionierungs- und Clustering-Recommender verwendet die Arbeitslastausführungsdaten des Projekts der letzten 30 Tage, um jede BigQuery-Tabelle auf suboptimale Partitionierungs- und Clustering-Konfigurationen zu analysieren. Der Recommender verwendet auch maschinelles Lernen, um vorherzusagen, wie viel die Ausführung von Arbeitslasten mit verschiedenen Partitionierungs- oder Clustering-Konfigurationen optimiert werden könnte. Wenn der Recommender feststellt, dass Partitionierung oder Clustering einer Tabelle erhebliche Einsparungen ermöglicht, generiert der Recommender eine Empfehlung. Der Partitionierungs- und Clustering-Recommender generiert die folgenden Arten von Empfehlungen:
| Vorhandener Tabellentyp | Empfehlungsuntertyp | Empfehlungsbeispiel |
|---|---|---|
| Nicht partitioniert, nicht geclustert | Partition | „Sparen Sie etwa 64 Slot-Stunden pro Monat durch Partitionierung nach column_C nach DAY“ |
| Nicht partitioniert, nicht geclustert | Cluster | „Sparen Sie durch Clustering nach Spalte_C etwa 64 Slot-Stunden pro Monat“ |
| Partitioniert, nicht geclustert | Cluster | „Sparen Sie durch Clustering nach Spalte_C etwa 64 Slot-Stunden pro Monat“ |
Jede Empfehlung besteht aus drei Teilen:
- Anleitung zum Partitionieren oder Clustern einer bestimmten Tabelle
- Die spezifische Spalte in einer Tabelle, die partitioniert oder geclustert werden soll
- Geschätzte monatliche Einsparungen beim Anwenden der Empfehlung
Bei der Berechnung potenzieller Arbeitslasteinsparungen geht der Recommender davon aus, dass die Verlaufsdaten der Ausführungsarbeitslasten der letzten 30 Tage die zukünftige Arbeitslast darstellen.
Die Recommender API gibt auch Informationen zur Tabellenarbeitslast in Form von Statistiken zurück. Statistiken sind Erkenntnisse, mit denen Sie die Arbeitslast Ihres Projekts verstehen können. Sie erhalten dadurch mehr Kontext dazu, wie eine Partition oder Clusterempfehlung die Arbeitslastkosten verbessern kann.
Beschränkungen
Der Partitionierungs- und Clustering-Recommender unterstützt keine BigQuery-Tabellen mit Legacy-SQL. Beim Generieren einer Empfehlung schließt der Recommender alle Legacy-SQL-Abfragen in der Analyse aus. Darüber hinaus werden durch das Anwenden von Partitionsempfehlungen auf BigQuery-Tabellen mit Legacy-SQL alle Legacy-SQL-Workflows in dieser Tabelle beeinträchtigt.
Bevor Sie Partitionsempfehlungen anwenden, migrieren Sie Ihre Legacy-SQL-Workflows in Google SQL.
BigQuery unterstützt nicht das Ändern des Partitionierungsschemas einer vorhandenen Tabelle. Sie können die Partitionierung einer Tabelle nur in einer Kopie der Tabelle ändern. Weitere Informationen finden Sie unter Partitionsempfehlungen anwenden.
Standorte
Der Partitionierungs- und Clustering-Recommender ist an den folgenden Verarbeitungsorten verfügbar:
| Beschreibung der Region | Name der Region | Details | |
|---|---|---|---|
| Asiatisch-pazifischer Raum | |||
| Delhi | asia-south2 |
||
| Hongkong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seoul | asia-northeast3 |
||
| Singapur | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokio | asia-northeast1 |
||
| Europa | |||
| Belgien | europe-west1 |
|
|
| Berlin | europe-west10 |
|
|
| EU (mehrere Regionen) | eu |
||
| Frankfurt | europe-west3 |
|
|
| London | europe-west2 |
|
|
| Niederlande | europe-west4 |
|
|
| Zürich | europe-west6 |
|
|
| Amerika | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Montreal | northamerica-northeast1 |
|
|
| Northern Virginia | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| USA (mehrere Regionen) | us |
||
Hinweise
- Achten Sie darauf, dass Gemini in BigQuery für Ihr Google Cloud-Projekt aktiviert ist.
- Aktivieren Sie die Recommender API.
Erforderliche Berechtigungen
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle Betrachter von BigQuery-Partitionierungsclustering-Recommender (roles/recommender.bigqueryPartitionClusterViewer) zu gewähren, um die Berechtigungen zu erhalten, die Sie für den Zugriff auf Partitions- und Clusterempfehlungen benötigen.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierte Rolle enthält die Berechtigungen, die für den Zugriff auf Partitions- und Clusterempfehlungen erforderlich sind. Erweitern Sie den Abschnitt Erforderliche Berechtigungen, um die erforderlichen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Für den Zugriff auf Partitions- und Clusterempfehlungen sind die folgenden Berechtigungen erforderlich:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Empfehlungen aufrufen
In diesem Abschnitt wird beschrieben, wie Sie Empfehlungen zu Partitionen und Clustern mit der Google Cloud Console, der Google Cloud CLI oder der Recommender API aufrufen.
Wählen Sie eine der folgenden Optionen aus:
Console
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie zum Öffnen des Tabs „Empfehlungen“ auf Empfehlungen > Alle Empfehlungen ansehen.
Auf dem Tab „Empfehlungen“ werden alle Empfehlungen aufgelistet, die für Ihr Projekt verfügbar sind.
Klicken Sie im Bereich BigQuery-Arbeitslastkosten optimieren auf Alle ansehen.
In der Tabelle mit den Kostenempfehlungen werden alle Empfehlungen aufgeführt, die für das aktuelle Projekt generiert wurden. Der folgende Screenshot zeigt beispielsweise, dass der Recommender die Tabelle
example_tableanalysiert und dann das Clustering der Spalteexample_columnempfohlen hat, um eine ungefähre Menge von Byte und Slots zu sparen.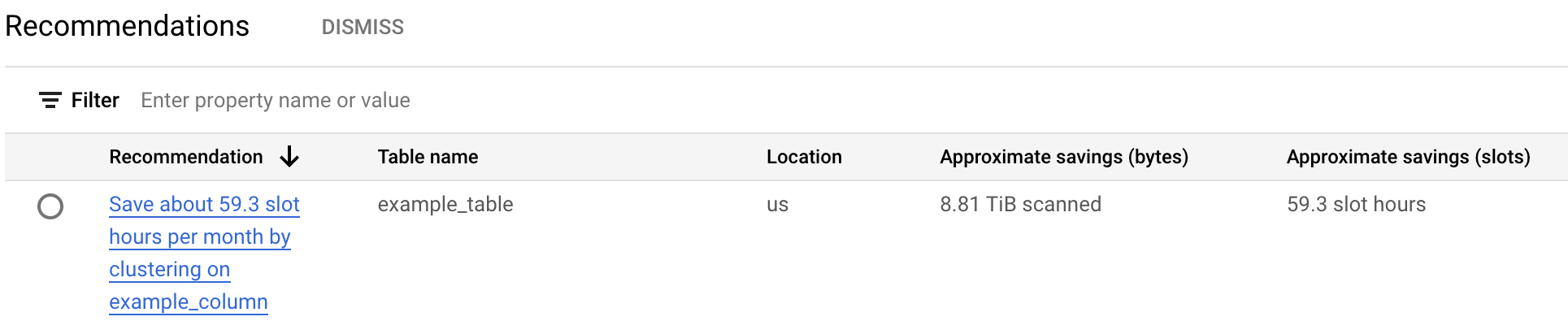
Klicken Sie auf eine Empfehlung, um weitere Informationen zu den Daten und Empfehlungen der Tabelle zu sehen.
gcloud
Verwenden Sie den Befehl gcloud recommender recommendations list, um Partitions- oder Clusterempfehlungen für ein bestimmtes Projekt aufzurufen:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Dabei gilt:
PROJECT_NAME: der Name des Projekts, das Ihre BigQuery-Tabelle enthältREGION_NAME: die Region, in der sich Ihr Projekt befindetFORMAT_TYPE: ein unterstütztes Ausgabeformat der gcloud CLI, z. B. JSON
| Attribut | Relevant für Untertyp | Beschreibung |
|---|---|---|
recommenderSubtype |
Partition oder Cluster | Gibt den Typ der Empfehlung an. |
content.overview.partitionColumn |
Partition | Empfohlener Name der Partitionierungsspalte. |
content.overview.partitionTimeUnit |
Partition | Empfohlene Partitionierungszeiteinheit. DAY bedeutet beispielsweise, dass Sie tägliche Partitionen in der empfohlenen Spalte haben sollten. |
content.overview.clusterColumns |
Cluster | Empfohlene Clustering-Spaltennamen. |
- Weitere Informationen zu anderen Feldern in der Recommender-Antwort finden Sie unter REST-Ressource:
projects.locations.recommendersrecommendation. - Weitere Informationen zur Verwendung der Recommender API finden Sie unter API verwenden – Empfehlungen.
Verwenden Sie den Befehl gcloud recommender insights list, um Tabellenstatistiken mit der gcloud CLI aufzurufen:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Dabei gilt:
PROJECT_NAME: der Name des Projekts, das Ihre BigQuery-Tabelle enthältREGION_NAME: die Region, in der sich Ihr Projekt befindetFORMAT_TYPE: ein unterstütztes Ausgabeformat der gcloud CLI, z. B. JSON
| Attribut | Relevant für Untertyp | Beschreibung |
|---|---|---|
content.existingPartitionColumn |
Cluster | Vorhandene Partitionierungsspalte, falls vorhanden |
content.tableSizeTb |
Alle | Größe der Tabelle in Terabyte |
content.bytesReadMonthly |
Alle | Monatliche Byte, die aus der Tabelle gelesen werden |
content.slotMsConsumedMonthly |
Alle | Monatliche Slot-Millisekunden, die von der auf der Tabelle ausgeführten Arbeitslast verbraucht werden |
content.queryJobsCountMonthly |
Alle | Monatliche Anzahl von Jobs, die in der Tabelle ausgeführt werden |
- Weitere Informationen zu anderen Feldern in der Statistikantwort finden Sie unter REST-Ressource:
projects.locations.insightTypes.insights. - Weitere Informationen zur Verwendung von Statistiken finden Sie unter API verwenden – Statistiken.
REST API
Verwenden Sie die REST API, um Partitions- oder Clusterempfehlungen für ein bestimmtes Projekt aufzurufen. Bei jedem Befehl müssen Sie ein Authentifizierungstoken angeben, das Sie mit der gcloud CLI abrufen können. Weitere Informationen zum Abrufen eines Authentifizierungstokens finden Sie unter Methoden zum Abrufen eines ID-Tokens.
Mit der curl list-Anfrage können Sie alle Empfehlungen für ein bestimmtes Projekt anzeigen:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Dabei gilt:
GCLOUD_AUTH_TOKEN: der Name eines gültigen gcloud CLI-ZugriffstokensPROJECT_NAME: der Name des Projekts, das Ihre BigQuery-Tabelle enthält
| Attribut | Relevant für Untertyp | Beschreibung |
|---|---|---|
recommenderSubtype |
Partition oder Cluster | Gibt den Typ der Empfehlung an. |
content.overview.partitionColumn |
Partition | Empfohlener Name der Partitionierungsspalte. |
content.overview.partitionTimeUnit |
Partition | Empfohlene Partitionierungszeiteinheit. DAY bedeutet beispielsweise, dass Sie tägliche Partitionen in der empfohlenen Spalte haben sollten. |
content.overview.clusterColumns |
Cluster | Empfohlene Clustering-Spaltennamen. |
- Weitere Informationen zu anderen Feldern in der Recommender-Antwort finden Sie unter REST-Ressource:
projects.locations.recommendersrecommendation. - Weitere Informationen zur Verwendung der Recommender API finden Sie unter API verwenden – Empfehlungen.
Führen Sie den folgenden Befehl aus, um Tabellenstatistiken mit der REST API aufzurufen:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Ersetzen Sie Folgendes:
GCLOUD_AUTH_TOKEN: der Name eines gültigen gcloud CLI-ZugriffstokensPROJECT_NAME: der Name des Projekts, das Ihre BigQuery-Tabelle enthält
| Attribut | Relevant für Untertyp | Beschreibung |
|---|---|---|
content.existingPartitionColumn |
Cluster | Vorhandene Partitionierungsspalte, falls vorhanden |
content.tableSizeTb |
Alle | Größe der Tabelle in Terabyte |
content.bytesReadMonthly |
Alle | Monatliche Byte, die aus der Tabelle gelesen werden |
content.slotMsConsumedMonthly |
Alle | Monatliche Slot-Millisekunden, die von der auf der Tabelle ausgeführten Arbeitslast verbraucht werden |
content.queryJobsCountMonthly |
Alle | Monatliche Anzahl von Jobs, die in der Tabelle ausgeführt werden |
- Weitere Informationen zu anderen Feldern in der Statistikantwort finden Sie unter REST-Ressource:
projects.locations.insightTypes.insights. - Weitere Informationen zur Verwendung von Statistiken finden Sie unter API verwenden – Statistiken.
Clusterempfehlungen anwenden
So wenden Sie Clusterempfehlungen an:
- Cluster direkt auf die ursprüngliche Tabelle anwenden
- Cluster auf eine kopierte Tabelle anwenden
- Cluster in einer materialisierten Ansicht anwenden
Cluster direkt auf die ursprüngliche Tabelle anwenden
Sie können Clusterempfehlungen direkt auf eine vorhandene BigQuery-Tabelle anwenden. Diese Methode ist schneller als das Anwenden von Empfehlungen auf eine kopierte Tabelle, aber eine Sicherungstabelle bleibt dabei nicht erhalten.
Führen Sie die folgenden Schritte aus, um eine neue Clustering-Spezifikation auf nicht partitionierte oder partitionierte Tabellen anzuwenden.
Aktualisieren Sie im bq-Tool die Clustering-Spezifikation Ihrer Tabelle, damit sie dem neuen Clustering entspricht:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Ersetzen Sie Folgendes:
CLUSTER_COLUMN: die Spalte, nach der Sie Cluster gruppieren, z. B.mycolumnDATASET: der Name des Datasets, das die Tabelle enthält, z. B.mydatasetORIGINAL_TABLE: der Name der ursprünglichen Tabelle, z. B.mytable
Sie können auch die API-Methode
tables.updateodertables.patchaufrufen, um die Clustering-Spezifikation zu ändern.Führen Sie die folgende
UPDATE-Anweisung aus, um alle Zeilen gemäß der neuen Clustering-Spezifikation zu clustern:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Cluster auf eine kopierte Tabelle anwenden
Wenn Sie Clusterempfehlungen auf eine BigQuery-Tabelle anwenden, können Sie zuerst die ursprüngliche Tabelle kopieren und dann die Empfehlung auf die kopierte Tabelle anwenden. So wird sichergestellt, dass Ihre ursprünglichen Daten erhalten bleiben, wenn Sie ein Rollback der Änderung auf die Clustering-Konfiguration durchführen müssen.
Sie können diese Methode verwenden, um Clusterempfehlungen sowohl auf nicht partitionierte als auch auf partitionierte Tabellen anzuwenden.
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Erstellen Sie im Abfrageeditor mit dem
LIKE-Operator eine leere Tabelle mit denselben Metadaten (einschließlich der Clustering-Spezifikationen) der ursprünglichen Tabelle:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Dabei gilt:
DATASET: der Name des Datasets, das die Tabelle enthält, z. B.mydatasetCOPIED_TABLE: der Name der kopierten Tabelle, z. B.copy_mytableORIGINAL_TABLE: der Name der ursprünglichen Tabelle, z. B.mytable
Öffnen Sie in der Google Cloud Console den Cloud Shell-Editor.
Aktualisieren Sie im Cloud Shell-Editor die Clustering-Spezifikation der kopierten Tabelle mit dem empfohlenen Clustering. Verwenden Sie dazu den Befehl
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Ersetzen Sie
CLUSTER_COLUMNdurch die Spalte, die Sie clustern, z. B.mycolumn.Sie können auch die API-Methode
tables.updateodertables.patchaufrufen, um die Clustering-Spezifikation zu ändern.Rufen Sie im Abfrageeditor das Tabellenschema mit der Partitionierungs- und Clustering-Konfiguration der ursprünglichen Tabelle ab, sofern eine Partitionierung oder ein Clustering vorhanden ist. Sie können das Schema abrufen, wenn Sie die Ansicht
INFORMATION_SCHEMA.TABLESder ursprünglichen Tabelle anzeigen:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
Die Ausgabe ist die vollständige DDL-Anweisung (Datendefinitionssprache) von ORIGINAL_TABLE, einschließlich der Klausel
PARTITION BY. Weitere Informationen zu den Argumenten in der DDL-Ausgabe finden Sie unterCREATE TABLE-Anweisung.Die DDL-Ausgabe gibt den Partitionierungstyp in der ursprünglichen Tabelle an:
Partitionierungstyp Ausgabebeispiel Nicht partitioniert Die PARTITION BY-Klausel fehlt.Nach Tabellenspalte partitioniert PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Nach Aufnahmezeit partitioniert PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Daten in die kopierte Tabelle aufnehmen. Der verwendete Prozess basiert auf dem Partitionstyp.
- Wenn die ursprüngliche Tabelle nicht partitioniert oder durch eine Tabellenspalte partitioniert ist, nehmen Sie die Daten aus der ursprünglichen Tabelle in die kopierte Tabelle auf:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
Wenn die ursprüngliche Tabelle nach Aufnahmezeit partitioniert ist, gehen Sie so vor:
Rufen Sie die Liste der Spalten ab, um den Datenaufnahmeausdruck mithilfe der Ansicht
INFORMATION_SCHEMA.COLUMNSzu bilden:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
Die Ausgabe ist eine durch Kommas getrennte Liste von Spaltennamen.
Nehmen Sie die Daten aus der ursprünglichen Tabelle in die kopierte Tabelle auf:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Ersetzen Sie
COLUMN_NAMESdurch die durch Kommas getrennte Liste der Spalten, die im vorherigen Schritt ausgegeben wurde. Beispiel:col1, col2, col3.
Sie haben jetzt eine geclusterte kopierte Tabelle mit denselben Daten wie die ursprüngliche Tabelle. In den nächsten Schritten ersetzen Sie die ursprüngliche Tabelle durch eine neu geclusterte Tabelle.
- Wenn die ursprüngliche Tabelle nicht partitioniert oder durch eine Tabellenspalte partitioniert ist, nehmen Sie die Daten aus der ursprünglichen Tabelle in die kopierte Tabelle auf:
Benennen Sie die ursprüngliche Tabelle in eine Sicherungstabelle um:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Ersetzen Sie
BACKUP_TABLEdurch einen Namen für die Sicherungstabelle, z. B.backup_mytable.Benennen Sie die kopierte Tabelle in die ursprüngliche Tabelle um:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Die ursprüngliche Tabelle wird jetzt gemäß der Clusterempfehlung geclustert.
- Zugriff und Berechtigungen, z. B. IAM-Berechtigungen, Zugriff auf Zeilenebene oder Zugriff auf Spaltenebene.
- Tabellenartefakte wie Tabellenklone, Tabellen-Snapshots oder Suchindexe.
- Der Status aller laufenden Tabellenprozesse, z. B. alle materialisierten Ansichten oder alle Jobs, die beim Kopieren der Tabelle ausgeführt wurden.
- Die Möglichkeit, mit Zeitreisen auf Verlaufsdaten aus Tabellen zuzugreifen.
- Alle Metadaten, die der ursprünglichen Tabelle zugeordnet sind, z. B.
table_option_listodercolumn_option_list. Weitere Informationen finden Sie unter Anweisungen der Datendefinitionssprache.
Wenn Probleme auftreten, müssen Sie die betroffenen Artefakte manuell in die neue Tabelle migrieren.
Nachdem Sie die geclusterte Tabelle geprüft haben, können Sie optional die Sicherungstabelle mit dem folgenden Befehl löschen:DROP TABLE DATASET.BACKUP_TABLE
Cluster in einer materialisierten Ansicht anwenden
Sie können eine materialisierte Ansicht der Tabelle erstellen, um Daten aus der ursprünglichen Tabelle mit der angewendeten Empfehlung zu speichern. Durch die Verwendung von materialisierten Ansichten zur Anwendung von Empfehlungen wird sichergestellt, dass die geclusterten Daten mithilfe von automatischen Aktualisierungen auf dem neuesten Stand bleiben. Beim Abfragen, Verwalten und Speichern von materialisierten Ansichten gibt es Überlegungen zur Preisgestaltung. Geclusterte materialisierte Ansichten erstellen.Partitionsempfehlungen anwenden
Sie müssen Partitionsempfehlungen auf eine Kopie der ursprünglichen Tabelle anwenden. BigQuery unterstützt nicht das Ändern eines Partitionierungsschemas einer vorhandenen Tabelle, z. B. das Ändern einer nicht partitionierten Tabelle in eine partitionierte Tabelle, das Ändern des Partitionierungsschemas einer Tabelle oder das Erstellen einer materialisierten Ansicht mit Ein anderes Partitionierungsschema als die Basistabelle. Sie können die Partitionierung einer Tabelle nur in einer Kopie der Tabelle ändern.
Partitionsempfehlungen auf eine kopierte Tabelle anwenden
Wenn Sie Partitionsempfehlungen auf eine BigQuery-Tabelle anwenden, müssen Sie zuerst die ursprüngliche Tabelle kopieren und dann die Empfehlung auf die kopierte Tabelle anwenden. So werden die ursprünglichen Daten beibehalten, falls Sie eine Partition zurücksetzen müssen.
Das folgende Verfahren verwendet eine Beispielempfehlung, um eine Tabelle nach der Partitionszeiteinheit DAY zu partitionieren.
Erstellen Sie eine kopierte Tabelle mit den Partitionsempfehlungen:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Dabei gilt:
DATASET: der Name des Datasets, das die Tabelle enthält, z. B.mydatasetCOPIED_TABLE: der Name der kopierten Tabelle, z. B.copy_mytablePARTITION_COLUMN: die Spalte, nach der Sie partitionieren, z. B.mycolumn
Weitere Informationen zum Erstellen von partitionierten Tabellen erhalten Sie unter Partitionierte Tabellen erstellen.
Benennen Sie die ursprüngliche Tabelle in eine Sicherungstabelle um:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Ersetzen Sie
BACKUP_TABLEdurch einen Namen für die Sicherungstabelle, z. B.backup_mytable.Benennen Sie die kopierte Tabelle in die ursprüngliche Tabelle um:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Die ursprüngliche Tabelle wird jetzt gemäß der Partitionsempfehlung partitioniert.
- Zugriff und Berechtigungen, z. B. IAM-Berechtigungen, Zugriff auf Zeilenebene oder Zugriff auf Spaltenebene.
- Tabellenartefakte wie Tabellenklone, Tabellen-Snapshots oder Suchindexe.
- Der Status aller laufenden Tabellenprozesse, z. B. alle materialisierten Ansichten oder alle Jobs, die beim Kopieren der Tabelle ausgeführt wurden.
- Die Möglichkeit, mit Zeitreisen auf Verlaufsdaten aus Tabellen zuzugreifen.
- Alle Metadaten, die der ursprünglichen Tabelle zugeordnet sind, z. B.
table_option_listodercolumn_option_list. Weitere Informationen finden Sie unter Anweisungen der Datendefinitionssprache. - Möglichkeit, Legacy-SQL zu verwenden, um Abfrageergebnisse in partitionierte Tabellen zu schreiben. Die Verwendung von Legacy-SQL wird in partitionierten Tabellen nicht vollständig unterstützt. Eine Lösung besteht darin, Ihre Legacy-SQL-Workflows zu Google SQL zu migrieren, bevor Sie eine Partitionsempfehlung anwenden.
Wenn Probleme auftreten, müssen Sie die betroffenen Artefakte manuell in die neue Tabelle migrieren.
Nachdem Sie die partitionierte Tabelle geprüft haben, können Sie optional die Sicherungstabelle mit dem folgenden Befehl löschen:DROP TABLE DATASET.BACKUP_TABLE
Preise
Weitere Informationen zu den Preisen für diese Funktion finden Sie unter Preisübersicht für Gemini in BigQuery.
Wenn Sie eine Empfehlung auf eine Tabelle anwenden, können folgende Kosten anfallen:- Verarbeitungskosten. Wenn Sie eine Empfehlung anwenden, führen Sie eine DDL-Abfrage (Datendefinitionssprache) oder eine DML-Abfrage (Datenbearbeitungssprache) für Ihr BigQuery-Projekt aus.
- Speicherkosten. Wenn Sie die Methode zum Kopieren einer Tabelle verwenden, verwenden Sie zusätzlichen Speicher für die kopierte (oder Sicherungs-)Tabelle.
Standardverarbeitungs- und Speichergebühren hängen vom Rechnungskonto ab, das dem Projekt zugeordnet ist. Weitere Informationen finden Sie unter BigQuery-Preise.
Kontingente und Limits
Informationen zu Kontingenten und Limits für dieses Feature finden Sie unter Kontingente für Gemini in BigQuery.
Fehlerbehebung
Problem: Für eine bestimmte Tabelle werden keine Empfehlungen angezeigt.
Partitions- und Clusterempfehlungen werden unter folgenden Umständen möglicherweise nicht angezeigt:
- Die Tabelle ist kleiner als 10 GB.
- Die Tabelle verursacht hohe Schreibkosten für Vorgänge zur Datenbearbeitungssprache (DML).
- Die Tabelle wurde in den letzten 30 Tagen nicht gelesen.
- Die geschätzten monatlichen Einsparungen sind zu unbedeutend (weniger als eine Slot-Stunde).
- Die Tabelle ist bereits geclustert.