Einführung: Tabellenklone
Dieses Dokument bietet einen Überblick über Tabellenklone in BigQuery. Es richtet sich an Nutzer, die mit BigQuery und BigQuery-Tabellen vertraut sind.
Ein Tabellenklon ist eine einfache, beschreibbare Kopie einer anderen Tabelle (der Basistabelle). Ihnen werden nur Kosten für die Speicherung von Daten im Tabellenklon in Rechnung gestellt, wenn diese sich von den Daten in der Basistabelle unterscheiden. Für Tabellenklone fallen anfangs also keine Speicherkosten an. Abgesehen vom Abrechnungsmodell für den Speicher und einigen zusätzlichen Metadaten für die Basistabelle ähnelt ein Tabellenklon einer Standardtabelle. Sie können ihn abfragen, erstellen, kopieren usw.
Gängige Anwendungsfälle für Tabellenklone:
- Kopien von Produktionstabellen erstellen, die Sie für die Entwicklung und Tests verwenden können
- Sandboxes für Nutzer erstellen, um ihre eigenen Analysen und Datenmanipulationen zu generieren, ohne alle Produktionsdaten physisch zu kopieren Nur die geänderten Daten werden in Rechnung gestellt.
Nachdem Sie einen Tabellenklon erstellt haben, ist er von der Basistabelle unabhängig. Änderungen, die an der Basistabelle oder dem Tabellenklon vorgenommen werden, sind im jeweils anderen Element nicht enthalten.
Wenn Sie schreibgeschützte, einfache Kopien Ihrer Tabellen benötigen, können Sie Tabellen-Snapshots verwenden.
Tabellenklon-Metadaten
Ein Tabellenklon hat dieselben Metadaten wie eine Standardtabelle sowie folgende Daten:
- Projekt, Dataset und Name der Basistabelle des Tabellenklons.
- Die Zeit des Tabellenklonvorgangs. Wenn Zeitreise zur Erstellung des Tabellenklons verwendet wurde, ist dies der Zeitstempel der Zeitreise.
Weitere Informationen finden Sie unter INFORMATION_SCHEMA.TABLES.
Tabellenklonvorgänge
Im Allgemeinen werden Tabellenklone genauso wie Standardtabellen genutzt, einschließlich folgender Vorgänge:
- Abfragen
- Zugriffssteuerung
- Metadaten aufrufen
- Partitionierung und Clustering
- Mit Schemas arbeiten
- Wird gelöscht
Allerdings unterscheidet sich die Erstellung eines Tabellenklons von der Erstellung einer Standardtabelle. Weitere Informationen finden Sie unter Tabellenklon erstellen.
Speicherkosten
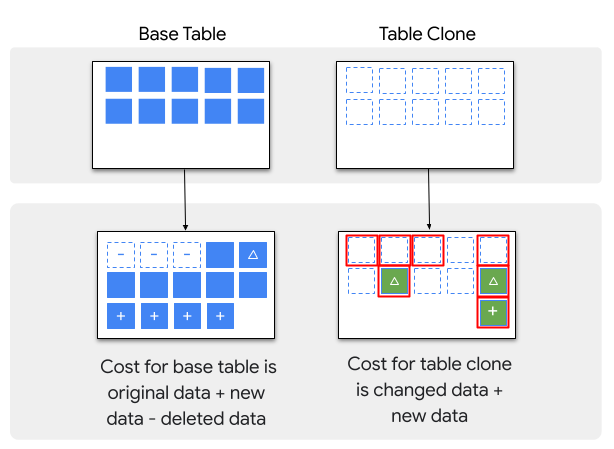
Speicherkosten gelten für Tabellenklone. BigQuery berechnet jedoch nur die Daten in einem Tabellenklon, die nicht bereits für eine andere Tabelle berechnet werden:
Wenn ein Tabellenklon erstellt wird, fallen zuerst keine Speicherkosten an.
Werden Daten einem Tabellenklon hinzugefügt oder in ihm geändert, wird Ihnen die Speicherung der hinzugefügten oder aktualisierten Daten in Rechnung gestellt.
Wenn Daten in einem Tabellenklon gelöscht werden, fallen keine Kosten für die Speicherung der gelöschten Daten an.
Werden Daten in der Basistabelle geändert oder gelöscht, die auch in einem Tabellenklon vorhanden sind, wird Ihnen der Tabellenklonspeicher der geänderten oder gelöschten Daten in Rechnung gestellt. Wenn mehrere Klone die geänderten oder gelöschten Daten enthalten, wird Ihnen nur der Speicherplatz berechnet, der vom ältesten Klon verwendet wurde.
Wenn der Basistabelle nach dem Erstellen des Tabellenklons Daten hinzugefügt werden, fallen keine Kosten für die Speicherung dieser Daten im Tabellenklon an, aber in der Basistabelle.
Die Unterschiede zwischen den Speicherkosten für Basistabellen und Tabellenklone sind im folgenden Bild dargestellt:
Weitere Informationen finden Sie unter BigQuery-Speicherpreise.
Beschränkungen
- Sie können eine Tabelle zwischen Datasets im selben Projekt und zwischen Datasets in verschiedenen Projekten klonen. Das Zieldataset für den Tabellenklon muss sich jedoch in der gleichen Region und unter der gleichen Organisation befinden wie die zu klonende Tabelle. Beispielsweise ist es nicht möglich, eine Tabelle aus einem Dataset in der EU in ein Dataset in den USA zu klonen.
- Sie können keine Daten einer Tabelle klonen, die älter sind als der Zeitraum des Zeitreisefensters für das Dataset der Tabelle.
- Sie können weder Ansichten noch materialisierte Ansichten klonen.
- Sie können externe Tabellen nicht klonen.
- Wenn Sie eine Tabelle mit Daten im schreiboptimierten Speicher klonen (der Zwischenspeicher für kürzlich gestreamte Zeilen), sind die Daten im schreiboptimierten Speicher nicht im Tabellenklon enthalten.
- Wenn Sie eine Tabelle mit Daten in Zeitreisen klonen, werden die Daten in Zeitreisen nicht in den Tabellenklon aufgenommen.
- Tabellenklone können nicht im Bereich Explorer von Standardtabellen unterschieden werden. Sie können einen Tabellenklon jedoch von einer Standardtabelle unterscheiden, indem Sie sich die Tabellendetails ansehen. Tabellenklondetails haben den Abschnitt Basistabelleninformationen, den Standardtabellen nicht haben.
- Sie können mit einem Klonvorgang keine Daten an eine vorhandene Tabelle anhängen. Sie können beispielsweise die Flag-Einstellungen
--append_table=trueund--clone=truenicht im selbenbq cp-Befehl verwenden. Wenn Sie beim Duplizieren einer Tabelle Daten anhängen möchten, verwenden Sie stattdessen einen Kopiervorgang. - Wenn Sie einen Tabellenklone erstellen, muss dessen Name denselben Namensregeln wie beim Erstellen einer Tabelle entsprechen.
- Das Erstellen von Tabellenklones unterliegt den Limits für BigQuery-Kopierjobs.
- Die Zeit, die BigQuery zum Erstellen von Tabellenklones benötigt, kann in verschiedenen Ausführungen erheblich variieren, da der zugrunde liegende Speicher dynamisch verwaltet wird.
Kontingente und Limits
Für Tabellenklone gelten die gleichen Kontingente und Limits wie für Standardtabellen. Weitere Informationen finden Sie unter Tabellenkontingente und Beschränkungen. Außerdem gelten Limits für Tabellenklone.