Einführung in die Vektorsuche
Dieses Dokument bietet einen Überblick über die Vektorsuche in BigQuery. Die Vektorsuche ist ein Verfahren, mit dem ähnliche Objekte mithilfe von Einbettungen verglichen werden. Sie wird für Google-Produkte wie die Google Suche, YouTube und Google Play verwendet. Mit der Vektorsuche können Sie Suchanfragen im großen Maßstab ausführen. Wenn Sie Vektorindexe mit der Vektorsuche verwenden, können Sie grundlegende Technologien wie die Inverted File Indexing (IVF) und den ScaNN-Algorithmus nutzen.
Die Vektorsuche basiert auf Einbettungen. Einbettungen sind hochdimensionale numerische Vektoren, die eine bestimmte Entität darstellen, z. B. einen Text oder eine Audiodatei. Bei Modellen für maschinelles Lernen (ML) werden Embeddings verwendet, um die Semantik solcher Entitäten zu codieren, damit sie leichter analysiert und verglichen werden können. Ein gängiger Vorgang in Clustering-, Klassifizierungs- und Empfehlungsmodellen besteht beispielsweise darin, die Entfernung zwischen Vektoren in einem Embedding-Raum zu messen, um Elemente zu finden, die semantisch am ähnlichsten sind.
Dieses Konzept der semantischen Ähnlichkeit und Distanz in einem Einbettungsraum wird visuell veranschaulicht, wenn Sie sich überlegen, wie verschiedene Elemente dargestellt werden könnten. Begriffe wie Katze, Hund und Löwe, die alle Tierarten darstellen, werden in diesem Bereich aufgrund ihrer gemeinsamen semantischen Merkmale nah beieinander gruppiert. Ähnlich würden Begriffe wie Auto, Lkw und der allgemeinere Begriff Fahrzeug einen weiteren Cluster bilden. Das ist in der folgenden Abbildung dargestellt:
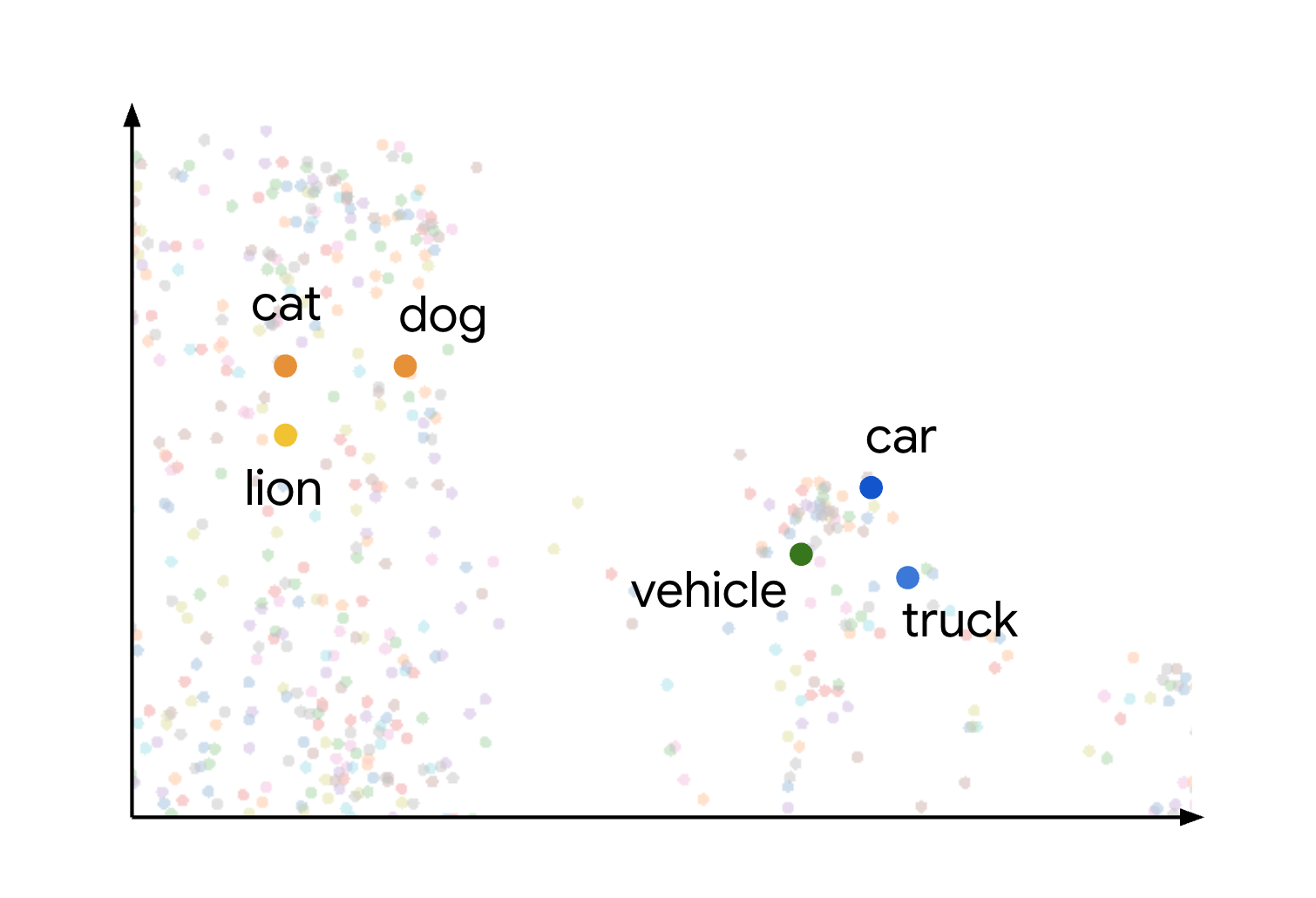
Sie sehen, dass die Cluster „Tier“ und „Fahrzeug“ weit voneinander entfernt sind. Die Trennung zwischen den Gruppen veranschaulicht das Prinzip, dass Objekte, die im Einbettungsraum näher beieinander liegen, semantisch ähnlicher sind, während größere Entfernungen auf eine größere semantische Abweichung hinweisen.
BigQuery bietet eine End-to-End-Lösung zum Generieren von Einbettungen, Indexieren von Inhalten und Durchführen von Vektorsuchen. Sie können jede dieser Aufgaben einzeln oder in einem einzigen Vorgang ausführen. Eine Anleitung dazu, wie Sie all diese Aufgaben ausführen, finden Sie unter Semantische Suche und Retrieval Augmented Generation durchführen.
Wenn Sie eine Vektorsuche mit SQL ausführen möchten, verwenden Sie die Funktion VECTOR_SEARCH.
Optional können Sie mit der Anweisung CREATE VECTOR INDEX einen Vektorindex erstellen.
Bei Verwendung eines Vektorindex nutzt VECTOR_SEARCH die Suchmethode Annäherung an den nächsten Nachbarn, um die Leistung der Vektorsuchleistung zu verbessern, mit dem Kompromiss: Reduzierung der Trefferquote und damit die Rückgabe von ungefähren Ergebnissen. Ohne Vektorindex verwendet VECTOR_SEARCH die Brute-Force-Suche, um die Entfernung für jeden Datensatz zu messen. Sie können auch die Brute-Force-Suche verwenden, um genaue Ergebnisse zu erhalten, auch wenn ein Vektorindex verfügbar ist.
In diesem Dokument liegt der Schwerpunkt auf dem SQL-Ansatz. Sie können aber auch Vektorsuchen mit BigQuery DataFrames in Python ausführen. Ein Notebook, das den Python-Ansatz veranschaulicht, finden Sie unter Vector Search-Anwendung mit BigQuery DataFrames erstellen.
Anwendungsfälle
Die Kombination aus Einbettungsgenerierung und Vektorsuche ermöglicht viele interessante Anwendungsfälle. Beispiele für Anwendungsfälle:
- Retrieval-Augmented Generation (RAG):Dokumenten werden in BigQuery geparst, Inhalte werden mithilfe von Vektorsuche durchsucht und zusammengefasste Antworten auf Fragen in natürlicher Sprache werden mit Gemini-Modellen generiert. Ein Notebook, das dieses Szenario veranschaulicht, finden Sie unter Eine Anwendung für die Vektorsuche mit BigQuery DataFrames erstellen.
- Empfehlung von Ersatz- oder ähnlichen Produkten:Optimieren Sie E-Commerce-Anwendungen, indem Sie Produktalternativen basierend auf dem Kundenverhalten und der Produktähnlichkeit vorschlagen.
- Log-Analysen: Teams können proaktiv Anomalien in Protokollen priorisieren und Untersuchungen beschleunigen. Sie können diese Funktion auch verwenden, um den Kontext für LLMs zu ergänzen, um die Bedrohungserkennung, Forensik und Fehlerbehebung zu verbessern. Ein Notebook, das dieses Szenario veranschaulicht, finden Sie unter Log-Anomalieerkennung und -untersuchung mit Text-Embeddings und BigQuery Vector Search.
- Clustering und Targeting:Zielgruppen präzise segmentieren. So kann beispielsweise eine Krankenhauskette Patienten anhand von Notizen in natürlicher Sprache und strukturierten Daten gruppieren oder ein Werbetreibender Anzeigen basierend auf der Suchanfrage ausrichten. Ein Notebook, das dieses Szenario veranschaulicht, finden Sie unter Create-Campaign-Customer-Segmentation.
- Entitätsauflösung und Deduplizierung: Bereinigen und konsolidieren von Daten. So kann beispielsweise ein Werbeunternehmen Datensätze mit personenidentifizierbaren Informationen (PII) deduplizieren oder ein Immobilienunternehmen übereinstimmende Postadressen ermitteln.
Preise
Für die Funktion VECTOR_SEARCH und die Anweisung CREATE VECTOR INDEX gelten die BigQuery-Computing-Preise.
VECTOR_SEARCH-Funktion: Die Ähnlichkeitssuche wird Ihnen zu On-Demand-Preisen oder Editionspreisen in Rechnung gestellt.- On-Demand: Sie werden für die Anzahl der in der Basistabelle, im Index und in der Suchanfrage gescannten Bytes in Rechnung gestellt.
Preis für Versionen: Ihnen werden die Slots in Rechnung gestellt, die für die Ausführung des Jobs in Ihrer Reservierungsversion erforderlich sind. Größere und komplexere Ähnlichkeitsberechnungen verursachen höhere Kosten.
CREATE VECTOR INDEXErläuterung: Die für den Aufbau und die Aktualisierung Ihrer Vektorindizes erforderliche Verarbeitung ist kostenlos, solange die Gesamtgröße der indexierten Tabellendaten unter dem Limit pro Organisation liegt. Wenn Sie die Indexierung über dieses Limit hinaus unterstützen möchten, müssen Sie eine eigene Reservierung für die Ausführung der Indexverwaltungsjobs bereitstellen.
Auch bei Einbettungen und Indexen ist der Speicherplatz ein wichtiger Faktor. Für die Anzahl der Byte, die als Einbettungen und Indexe gespeichert werden, fallen Kosten für aktiven Speicher an.
- Wenn Vektorindexe aktiv sind, verursachen sie Speicherkosten.
- Die Größe des Indexspeichers finden Sie in der
INFORMATION_SCHEMA.VECTOR_INDEXES-Ansicht. Wenn der Suchindex noch nicht zu 100% abgedeckt ist, wird Ihnen trotzdem der gesamte in der Ansicht gemeldete Indexspeicher in Rechnung gestellt. Sie können die Indexabdeckung in der AnsichtINFORMATION_SCHEMA.VECTOR_INDEXESprüfen.
Kontingente und Limits
Weitere Informationen finden Sie unter Limits für Vektorindexe.
Beschränkungen
Abfragen, die die Funktion VECTOR_SEARCH enthalten, werden von BigQuery BI Engine nicht beschleunigt.
Nächste Schritte
- Weitere Informationen zum Erstellen eines Vektorindex
- Informationen zum Ausführen einer Vektorsuche mit der Funktion
VECTOR_SEARCH - In der Anleitung Nach Einbettungen mit Vektorsuche suchen erfahren Sie, wie Sie einen Vektorindex erstellen und dann eine Vektorsuche nach Einbettungen sowohl mit als auch ohne Index durchführen.
In der Anleitung Semantische Suche und Retrieval Augmented Generation durchführen erfahren Sie, wie Sie die folgenden Aufgaben ausführen:
- Texteinbettungen generieren
- Erstellen Sie einen Vektorindex für die Einbettungen.
- Durch Vektorsuche mit den Einbettungen nach ähnlichem Text suchen
- Führen Sie RAG (Retrieval Augmented Generation) durch, indem Sie Vektorsuchergebnisse verwenden, um die Prompt-Eingabe zu erweitern und die Ergebnisse zu verbessern.
Im Tutorial PDFs in einer Retrieval-Augmented-Generation-Pipeline parsen erfahren Sie, wie Sie eine RAG-Pipeline auf der Grundlage von geparsten PDF-Inhalten erstellen.