Abfrage ausführen
In diesem Dokument wird beschrieben, wie Sie eine Abfrage in BigQuery ausführen und wie Sie vor der Ausführung durch einen Probelauf (Dry Run) ermitteln können, wie viele Daten durch die Abfrage verarbeitet werden.
Arten von Abfragen
Sie können BigQuery-Daten abfragen, indem Sie einen der folgenden Abfragejobtypen verwenden:
Interaktive Abfragejobs: Standardmäßig führt BigQuery Abfragen als interaktive Abfragejobs aus, die so schnell wie möglich ausgeführt werden sollen.
Batch-Abfragejobs. Batchabfragen haben eine geringere Priorität als interaktive Abfragen. Wenn in einem Projekt oder einer Reservierung alle verfügbaren Rechenressourcen genutzt werden, werden Batchabfragen mit höherer Wahrscheinlichkeit in die Warteschlange gestellt und bleiben dort. Nachdem eine Batch-Abfrage gestartet wurde, wird sie genauso ausgeführt wie eine interaktive Abfrage. Weitere Informationen finden Sie unter Abfragewarteschlangen.
Jobs vom Typ „Kontinuierliche Abfrage“ Bei diesen Jobs wird die Abfrage kontinuierlich ausgeführt. So können Sie eingehende Daten in BigQuery in Echtzeit analysieren und die Ergebnisse dann in eine BigQuery-Tabelle schreiben oder in Bigtable oder Pub/Sub exportieren. Mit dieser Funktion können Sie zeitkritische Aufgaben ausführen, z. B. Erkenntnisse erstellen und sofort darauf reagieren, Echtzeit-Inferenzen für maschinelles Lernen (ML) anwenden und ereignisgesteuerte Datenpipelines erstellen.
Sie können Abfragejobs mit den folgenden Methoden ausführen:
- Erstellen Sie eine Abfrage in der Google Cloud -Konsole und führen Sie sie aus.
- Führen Sie den Befehl
bq queryim bq-Befehlszeilentool aus. - Rufen Sie programmatisch eine der Methoden
jobs.queryoderjobs.insertin der BigQuery REST API auf. - Verwenden Sie die BigQuery-Clientbibliotheken.
In BigQuery werden Abfrageergebnisse entweder in einer temporären Tabelle (Standard) oder in einer permanenten Tabelle gespeichert. Wenn Sie eine permanente Tabelle als Zieltabelle für die Ergebnisse angeben, können Sie auswählen, ob eine vorhandene Tabelle angefügt oder überschrieben werden soll, oder eine neue Tabelle mit einem eindeutigen Namen erstellt werden soll.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Ausführen eines Abfragejobs benötigen:
-
BigQuery-Jobnutzer (
roles/bigquery.jobUser) für das Projekt. -
BigQuery-Datenbetrachter (
roles/bigquery.dataViewer) für alle Tabellen und Ansichten, auf die Ihre Abfrage verweist. Zum Abfragen von Ansichten benötigen Sie diese Rolle auch für alle zugrunde liegenden Tabellen und Ansichten. Wenn Sie autorisierte Ansichten oder autorisierte Datasets verwenden, benötigen Sie keinen Zugriff auf die zugrunde liegenden Quelldaten.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierten Rollen enthalten die Berechtigungen, die zum Ausführen eines Abfragejobs erforderlich sind. Erweitern Sie den Abschnitt Erforderliche Berechtigungen, um die erforderlichen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind zum Ausführen eines Abfragejobs erforderlich:
-
bigquery.jobs.createdes Projekts, in dem die Abfrage ausgeführt wird, unabhängig davon, wo die Daten gespeichert sind. -
bigquery.tables.getDatafür alle Tabellen und Ansichten, auf die Ihre Abfrage verweist. Zum Abfragen von Ansichten benötigen Sie diese Berechtigung auch für alle zugrunde liegenden Tabellen und Ansichten. Wenn Sie autorisierte Ansichten oder autorisierte Datasets verwenden, benötigen Sie keinen Zugriff auf die zugrunde liegenden Quelldaten.
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Fehlerbehebung
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
Dieser Fehler tritt auf, wenn ein Nutzer keine Berechtigung zum Erstellen von Abfragejobs im Projekt hat.
Lösung: Ein Administrator muss Ihnen die Berechtigung bigquery.jobs.create für das Projekt erteilen, das Sie abfragen. Diese Berechtigung ist zusätzlich zu allen Berechtigungen erforderlich, die für den Zugriff auf die abgefragten Daten erforderlich sind.
Weitere Informationen zu BigQuery-Berechtigungen finden Sie unter Zugriffssteuerung mit IAM.
Interaktive Abfrage ausführen
Wählen Sie eine der folgenden Optionen aus, um eine interaktive Abfrage auszuführen:
Console
Rufen Sie die Seite BigQuery auf.
Klicken Sie auf SQL-Abfrage.
Geben Sie im Abfrageeditor eine gültige GoogleSQL-Abfrage ein.
Fragen Sie beispielsweise das öffentliche BigQuery-Dataset
usa_namesab, um die häufigsten Namen in den USA zwischen den Jahren 1910 und 2013 zu ermitteln:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Alternativ können Sie auch das Feld „Referenz“ verwenden, um neue Abfragen zu erstellen.
Optional: Wenn Sie möchten, dass Codevorschläge automatisch angezeigt werden, wenn Sie eine Anfrage eingeben, klicken Sie auf Mehr und wählen Sie dann SQL-Autovervollständigung aus. Wenn Sie keine Vorschläge zur automatischen Vervollständigung benötigen, deaktivieren Sie SQL-Vervollständigung. Dadurch werden auch die Vorschläge für das automatische Ausfüllen des Projektnamens deaktiviert.
Optional: Wenn Sie zusätzliche Abfrageeinstellungen auswählen möchten, klicken Sie auf Mehr und dann auf Abfrageeinstellungen.
Klicken Sie auf Ausführen.
Wenn Sie keine Zieltabelle angeben, schreibt der Abfragejob die Ausgabe in eine temporäre (Cache-)Tabelle.
Sie können die Abfrageergebnisse jetzt auf dem Tab Ergebnisse im Bereich Abfrageergebnisse ansehen.
Optional: Klicken Sie zum Sortieren der Abfrageergebnisse (Vorschau) nach Spalten neben dem Spaltennamen auf Sortiermenü öffnen und wählen Sie eine Sortierreihenfolge aus. Wenn die geschätzten Byte, die für die Sortierung verarbeitet wurden, größer als null sind, wird die Anzahl der Byte oben im Menü angezeigt.
Optional: Öffnen Sie den Tab Visualisierung, um Ihre Abfrageergebnisse darzustellen. Sie können das Diagramm vergrößern oder verkleinern, das Diagramm als PNG-Datei herunterladen oder die Sichtbarkeit der Legende umschalten.
Im Bereich Visualisierungskonfiguration können Sie den Visualisierungstyp ändern und die Messwerte und Dimensionen der Visualisierung konfigurieren. Die Felder in diesem Bereich werden mit der Anfangskonfiguration vorausgefüllt, die aus dem Zieltabellenschema der Abfrage abgeleitet wurde. Die Konfiguration wird zwischen folgenden Abfrageausführungen im selben Abfrageeditor beibehalten.
Für Linien-, Balken- oder Streudiagramme sind die unterstützten Dimensionen die Datentypen
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIMEundSTRING, während die unterstützten Messwerte die DatentypenINT64,FLOAT64,NUMERICundBIGNUMERICsind.Wenn Ihre Suchergebnisse den Typ
GEOGRAPHYenthalten, ist Karte der Standardvisualisierungstyp. Damit können Sie Ihre Ergebnisse auf einer interaktiven Karte visualisieren.Optional: Auf dem Tab JSON können Sie die Abfrageergebnisse im JSON-Format ansehen. Der Schlüssel ist der Spaltenname und der Wert das Ergebnis für diese Spalte.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Führen Sie den Befehl
bq queryaus. Im folgenden Beispiel können Sie mit dem Flag--use_legacy_sql=falsedie GoogleSQL-Syntax verwenden.bq query \ --use_legacy_sql=false \ 'QUERY'
Ersetzen Sie QUERY durch eine gültige GoogleSQL-Abfrage. Fragen Sie beispielsweise das öffentliche BigQuery-Dataset
usa_namesab, um die häufigsten Namen in den USA zwischen den Jahren 1910 und 2013 zu ermitteln:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Der Abfragejob schreibt die Ausgabe in eine temporäre (Cache-)Tabelle.
Optional können Sie die Zieltabelle und den Speicherort für die Abfrageergebnisse angeben. Wenn Sie die Ergebnisse in eine vorhandene Tabelle schreiben möchten, fügen Sie das entsprechende Flag zum Anfügen (
--append_table=true) oder Überschreiben (--replace=true) der Tabelle ein.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Dabei gilt:
LOCATION: die Region oder Multiregion für die Zieltabelle, z. B.
USIn diesem Beispiel wird das Dataset
usa_namesam multiregionalen Standort „US“ gespeichert. Wenn Sie für diese Abfrage eine Zieltabelle angeben, muss sich das Dataset, das die Zieltabelle enthält, ebenfalls am multiregionalen Standort „US“ befinden. Es ist nicht möglich, ein Dataset an einem Standort abzufragen und die Ergebnisse in eine Zieltabelle an einem anderen Standort zu schreiben.Mit der Datei ".bigqueryrc" können Sie einen Standardwert für den Standort festlegen.
TABLE: der Name der Zieltabelle, z. B.
myDataset.myTableWenn die Zieltabelle eine neue Tabelle ist, erstellt BigQuery die Tabelle, wenn Sie Ihre Abfrage ausführen. Sie müssen jedoch ein vorhandenes Dataset angeben.
Wenn sich die Tabelle nicht in Ihrem aktuellen Projekt befindet, fügen Sie die Projekt-IDGoogle Cloud im Format
PROJECT_ID:DATASET.TABLEhinzu, z. B.myProject:myDataset.myTable. Wenn--destination_tablenicht angegeben ist, wird ein Abfragejob generiert, der die Ausgabe in eine temporäre Tabelle schreibt.
API
Sie können die API zum Ausführen einer Abfrage verwenden. Dazu fügen Sie einen neuen Job ein und füllen das Jobkonfigurationsattribut query mit Daten. Optional: Geben Sie Ihren Standort im Attribut location im Abschnitt jobReference der Jobressource an.
Rufen Sie getQueryResults auf, um die Ergebnisse abzufragen.
Führen Sie die Abfrage so lange aus, bis jobComplete gleich true ist. In der Liste errors werden Fehler und Warnungen angezeigt.
C#
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der C#-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery C# API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Informationen zum Ausführen einer Abfrage mit einem Proxy finden Sie unter Proxy konfigurieren.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
PHP
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von PHP in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery PHP API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Ruby
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Ruby in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Ruby API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Batch-Abfrage ausführen
Wählen Sie eine der folgenden Optionen aus, um eine Batch-Abfrage auszuführen:
Console
Rufen Sie die Seite BigQuery auf.
Klicken Sie auf SQL-Abfrage.
Geben Sie im Abfrageeditor eine gültige GoogleSQL-Abfrage ein.
Fragen Sie beispielsweise das öffentliche BigQuery-Dataset
usa_namesab, um die häufigsten Namen in den USA zwischen den Jahren 1910 und 2013 zu ermitteln:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Klicken Sie auf Mehr und dann auf Abfrageeinstellungen.
Wählen Sie im Abschnitt Ressourcenverwaltung die Option Batch aus.
Optional: Passen Sie die Abfrageeinstellungen an.
Klicken Sie auf Speichern.
Klicken Sie auf Ausführen.
Wenn Sie keine Zieltabelle angeben, schreibt der Abfragejob die Ausgabe in eine temporäre (Cache-)Tabelle.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq queryund geben Sie das Flag--batchan. Im folgenden Beispiel können Sie mit dem Flag--use_legacy_sql=falsedie GoogleSQL-Syntax verwenden.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
Ersetzen Sie QUERY durch eine gültige GoogleSQL-Abfrage. Fragen Sie beispielsweise das öffentliche BigQuery-Dataset
usa_namesab, um die häufigsten Namen in den USA zwischen den Jahren 1910 und 2013 zu ermitteln:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Der Abfragejob schreibt die Ausgabe in eine temporäre (Cache-)Tabelle.
Optional können Sie die Zieltabelle und den Speicherort für die Abfrageergebnisse angeben. Wenn Sie die Ergebnisse in eine vorhandene Tabelle schreiben möchten, fügen Sie das entsprechende Flag zum Anfügen (
--append_table=true) oder Überschreiben (--replace=true) der Tabelle ein.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Dabei gilt:
LOCATION: die Region oder Multiregion für die Zieltabelle, z. B.
USIn diesem Beispiel wird das Dataset
usa_namesam multiregionalen Standort „US“ gespeichert. Wenn Sie für diese Abfrage eine Zieltabelle angeben, muss sich das Dataset, das die Zieltabelle enthält, ebenfalls am multiregionalen Standort „US“ befinden. Es ist nicht möglich, ein Dataset an einem Standort abzufragen und die Ergebnisse in eine Zieltabelle an einem anderen Standort zu schreiben.Mit der Datei ".bigqueryrc" können Sie einen Standardwert für den Standort festlegen.
TABLE: der Name der Zieltabelle, z. B.
myDataset.myTableWenn die Zieltabelle eine neue Tabelle ist, erstellt BigQuery die Tabelle, wenn Sie Ihre Abfrage ausführen. Sie müssen jedoch ein vorhandenes Dataset angeben.
Wenn sich die Tabelle nicht in Ihrem aktuellen Projekt befindet, fügen Sie die Projekt-IDGoogle Cloud im Format
PROJECT_ID:DATASET.TABLEhinzu, z. B.myProject:myDataset.myTable. Wenn--destination_tablenicht angegeben ist, wird ein Abfragejob generiert, der die Ausgabe in eine temporäre Tabelle schreibt.
API
Sie können die API zum Ausführen einer Abfrage verwenden. Dazu fügen Sie einen neuen Job ein und füllen das Jobkonfigurationsattribut query mit Daten. Optional: Geben Sie Ihren Standort im Attribut location im Abschnitt jobReference der Jobressource an.
Wenn Sie die Attribute des Abfragejobs angeben, nehmen Sie das Attribut configuration.query.priority mit dem Wert BATCH auf.
Rufen Sie getQueryResults auf, um die Ergebnisse abzufragen.
Führen Sie die Abfrage so lange aus, bis jobComplete gleich true ist. In der Liste errors werden Fehler und Warnungen angezeigt.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Zum Ausführen einer Batch-Abfrage legen Sie die Abfragepriorität fest, und zwar auf QueryJobConfiguration.Priority.BATCH, wenn Sie eine QueryJobConfiguration erstellen.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Java-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Kontinuierliche Abfrage ausführen
Für das Ausführen eines kontinuierlichen Abfragejobs ist eine zusätzliche Konfiguration erforderlich. Weitere Informationen finden Sie unter Kontinuierliche Abfragen erstellen.
Bereich Referenz verwenden
Im Abfrageeditor werden im Bereich Referenz dynamisch kontextsensitive Informationen zu Tabellen, Snapshots, Ansichten und materialisierten Ansichten angezeigt. In diesem Bereich können Sie sich die Schemadetails dieser Ressourcen ansehen oder sie auf einem neuen Tab öffnen. Sie können auch den Bereich Referenz verwenden, um neue Abfragen zu erstellen oder vorhandene Abfragen zu bearbeiten, indem Sie Abfrage-Snippets oder Feldnamen einfügen.
So erstellen Sie eine neue Abfrage mit dem Bereich Referenz:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie auf SQL-Abfrage.
Klicken Sie auf quick_reference_all Referenz.
Klicken Sie auf eine Tabelle oder Ansicht, die Sie vor Kurzem verwendet oder mit einem Sternchen markiert haben. Sie können auch die Suchleiste verwenden, um Tabellen und Ansichten zu finden.
Klicken Sie auf Aktionen ansehen und dann auf Abfrage-Snippet einfügen.
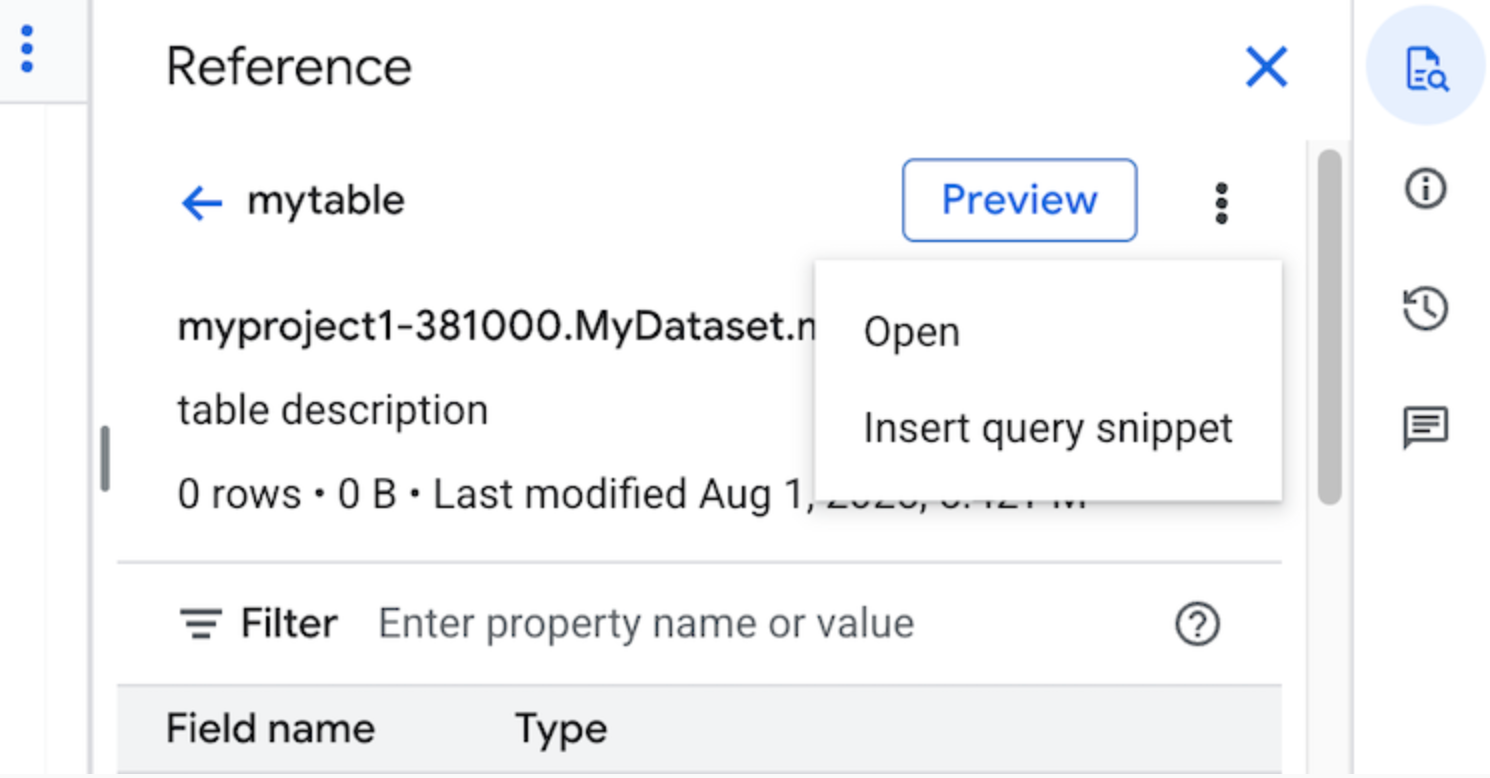
Optional: Sie können sich die Schemadetails der Tabelle oder Ansicht ansehen oder sie in einem neuen Tab öffnen.
Sie können die Abfrage jetzt entweder manuell bearbeiten oder Feldnamen direkt in die Abfrage einfügen. Wenn Sie einen Feldnamen einfügen möchten, klicken Sie im Abfrageeditor auf die Stelle, an der Sie den Feldnamen einfügen möchten, und klicken Sie dann im Bereich Referenz auf den Feldnamen.
Abfrageeinstellungen
Wenn Sie eine Abfrage ausführen, können Sie die folgenden Einstellungen angeben:
Eine Zieltabelle für die Abfrageergebnisse.
Die Priorität des Jobs.
Gibt an, ob im Cache gespeicherte Abfrageergebnisse verwendet werden sollen.
Das Zeitlimit des Jobs in Millisekunden.
Gibt an, ob der Sitzungsmodus verwendet werden soll.
Der zu verwendende Verschlüsselungstyp.
Die maximale Anzahl von Byte, die für die Abfrage in Rechnung gestellt werden.
Der zu verwendende SQL-Dialekt.
Der Standort, an dem die Abfrage ausgeführt werden soll. Die Abfrage muss am selben Standort wie alle in der Abfrage referenzierten Tabellen ausgeführt werden.
Die Reservierung zum Ausführen der Abfrage in der Vorschau.
Optionaler Modus zur Joberstellung
Der optionale Modus zur Joberstellung kann die Gesamtlatenz von Abfragen verbessern, die nur kurz ausgeführt werden, z. B. Abfragen aus Dashboards oder Arbeitslasten zur Datenexploration. In diesem Modus wird die Abfrage ausgeführt und die Ergebnisse werden inline für SELECT-Anweisungen zurückgegeben, ohne dass jobs.getQueryResults zum Abrufen der Ergebnisse verwendet werden muss. Bei Abfragen, die den optionalen Joberstellungsmodus verwenden, wird bei der Ausführung kein Job erstellt, es sei denn, BigQuery stellt fest, dass ein Job erstellt werden muss, um die Abfrage abzuschließen.
Wenn Sie den optionalen Modus zur Joberstellung aktivieren möchten, setzen Sie das Feld jobCreationMode der QueryRequest-Instanz im Anfragetext jobs.query auf JOB_CREATION_OPTIONAL.
Wenn der Wert dieses Felds auf JOB_CREATION_OPTIONAL festgelegt ist, ermittelt BigQuery, ob für die Abfrage der optionale Modus zum Erstellen von Jobs verwendet werden kann. Wenn ja, führt BigQuery die Abfrage aus und gibt alle Ergebnisse im Feld rows der Antwort zurück. Da für diese Abfrage kein Job erstellt wird, gibt BigQuery keine jobReference im Antworttext zurück. Stattdessen wird das Feld queryId zurückgegeben, mit dem Sie mithilfe der Ansicht INFORMATION_SCHEMA.JOBS Statistiken zur Abfrage abrufen können. Da kein Job erstellt wird, gibt es keine jobReference, die an die APIs jobs.get und jobs.getQueryResults übergeben werden kann, um diese Anfragen zu suchen.
Wenn BigQuery feststellt, dass ein Job zum Ausführen der Abfrage erforderlich ist, wird jobReference zurückgegeben. Sie können das Feld job_creation_reason in der INFORMATION_SCHEMA.JOBS-Ansicht prüfen, um den Grund für die Erstellung eines Jobs für die Anfrage zu ermitteln. In diesem Fall sollten Sie jobs.getQueryResults verwenden, um die Ergebnisse abzurufen, wenn die Abfrage abgeschlossen ist.
Wenn Sie den Wert JOB_CREATION_OPTIONAL verwenden, ist das Feld jobReference möglicherweise nicht in der Antwort enthalten. Prüfen Sie, ob das Feld vorhanden ist, bevor Sie darauf zugreifen.
Wenn JOB_CREATION_OPTIONAL für Abfragen mit mehreren Anweisungen (Skripts) angegeben wird, kann BigQuery den Ausführungsprozess optimieren. Im Rahmen dieser Optimierung kann BigQuery feststellen, dass das Skript mit weniger Jobressourcen als die Anzahl der einzelnen Anweisungen ausgeführt werden kann. Möglicherweise wird das gesamte Skript sogar ohne Erstellung eines Jobs ausgeführt.
Diese Optimierung hängt von der Bewertung des Skripts durch BigQuery ab und wird möglicherweise nicht in jedem Fall angewendet. Die Optimierung erfolgt vollständig automatisch. Es sind keine Nutzersteuerungen oder ‑aktionen erforderlich.
Wählen Sie eine der folgenden Optionen aus, um eine Abfrage im optionalen Modus für die Job-Erstellung auszuführen:
Console
Rufen Sie die Seite BigQuery auf.
Klicken Sie auf SQL-Abfrage.
Geben Sie im Abfrageeditor eine gültige GoogleSQL-Abfrage ein.
Fragen Sie beispielsweise das öffentliche BigQuery-Dataset
usa_namesab, um die häufigsten Namen in den USA zwischen den Jahren 1910 und 2013 zu ermitteln:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Klicken Sie auf Mehr und wählen Sie dann den Abfragemodus Optionale Joberstellung aus. Klicken Sie auf Bestätigen, um diese Auswahl zu bestätigen.
Klicken Sie auf Ausführen.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Verwenden Sie den Befehl
bq queryund geben Sie das Flag--job_creation_mode=JOB_CREATION_OPTIONALan. Im folgenden Beispiel können Sie mit dem Flag--use_legacy_sql=falsedie GoogleSQL-Syntax verwenden.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
Ersetzen Sie QUERY durch eine gültige GoogleSQL-Abfrage und LOCATION durch eine gültige Region, in der sich das Dataset befindet. Fragen Sie beispielsweise das öffentliche BigQuery-Dataset
usa_namesab, um die häufigsten Namen in den USA zwischen den Jahren 1910 und 2013 zu ermitteln:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Der Abfragejob gibt die Ausgabe inline in der Antwort zurück.
API
Wenn Sie eine Abfrage im optionalen Job-Erstellungsmodus über die API ausführen möchten, führen Sie eine Abfrage synchron aus und füllen Sie das Attribut QueryRequest aus. Fügen Sie das Attribut jobCreationMode hinzu und legen Sie als Wert JOB_CREATION_OPTIONAL fest.
Prüfen Sie die Antwort. Wenn jobComplete gleich true ist und jobReference leer ist, lesen Sie die Ergebnisse aus dem Feld rows. Sie können den queryId auch aus der Antwort abrufen.
Wenn jobReference vorhanden ist, können Sie in jobCreationReason nachsehen, warum ein Job von BigQuery erstellt wurde. Rufen Sie getQueryResults auf, um die Ergebnisse abzufragen.
Führen Sie die Abfrage so lange aus, bis jobComplete gleich true ist. In der Liste errors werden Fehler und Warnungen angezeigt.
Java
Verfügbare Version: 2.51.0 und höher
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Java-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Informationen zum Ausführen einer Abfrage mit einem Proxy finden Sie unter Proxy konfigurieren.
Python
Verfügbare Version: 3.34.0 und höher
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Python-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Knoten
Verfügbare Version: 8.1.0 und höher
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Node.js-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Go
Verfügbare Version: 1.69.0 und höher
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Go-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
JDBC-Treiber
Verfügbare Version: JDBC v1.6.1 und höher
Dazu muss JobCreationMode=2 im Verbindungsstring festgelegt werden.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
ODBC-Treiber
Verfügbare Version: ODBC v3.0.7.1016 und höher
Erfordert die Einstellung JobCreationMode=2 in der Datei .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
Kontingente
Informationen zu Kontingenten für interaktive Abfragen und Batch-Abfragen finden Sie unter Abfragejobs.
Abfragen beobachten
Informationen zu Abfragen während der Ausführung erhalten Sie über den Job-Explorer oder durch Abfragen der Ansicht INFORMATION_SCHEMA.JOBS_BY_PROJECT.
Probelauf
Ein Probelauf in BigQuery liefert die folgenden Informationen:
- Schätzung der Gebühren im On-Demand-Modus
- Validierung Ihrer Anfrage
- Ungefähre Anzahl der von Ihrer Abfrage verarbeiteten Byte im Kapazitätsmodus
Bei Probeläufen werden keine Abfrage-Slots verwendet. Für einen Probelauf fallen keine Kosten an. Verwenden Sie den Schätzungswert, der vom Probelauf zurückgegeben wird, um die Abfragekosten mit dem Preisrechner zu ermitteln.
Probelauf durchführen
So führen Sie einen Probelauf aus:
Console
Wechseln Sie zur BigQuery-Seite.
Geben Sie Ihre Abfrage in den Abfrageeditor ein.
Wenn die Abfrage gültig ist, wird automatisch ein Häkchen zusammen mit der Datenmenge angezeigt, die durch die Abfrage verarbeitet wird. Wenn die Abfrage ungültig ist, wird ein Ausrufezeichen mit einer Fehlermeldung angezeigt.
bq
Geben Sie eine Abfrage wie die folgende zusammen mit dem Flag --dry_run ein:
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
Bei einer gültigen Abfrage gibt der Befehl die folgende Antwort zurück:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
Für einen Probelauf über die API übergeben Sie einen Abfragejob, bei dem im JobConfiguration-Typ dryRun auf true gesetzt ist.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
PHP
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von PHP in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery PHP API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Setzen Sie das Attribut QueryJobConfig.dry_run auf True.
Client.query() gibt immer einen abgeschlossenen QueryJob zurück, wenn die Abfrage für einen Probelauf konfiguriert ist.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Python-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Nächste Schritte
- Weitere Informationen zum Verwalten von Abfragejobs.
- Weitere Informationen zum Aufrufen des Abfrageverlaufs.
- Abfragen speichern und freigeben.
- Weitere Informationen zu Abfragewarteschlangen
- Informationen zum Schreiben von Abfrageergebnissen