Présentation de BigQuery Omni
Avec BigQuery Omni, vous pouvez exécuter des analyses BigQuery sur les données stockées dans Amazon Simple Storage Service (Amazon S3) ou Azure Blob Storage à l'aide de tables BigLake.
De nombreuses organisations stockent des données dans plusieurs clouds publics. Ces données finissent souvent par être cloisonnées, car il est difficile d'obtenir des insights sur toutes les données. Vous souhaitez pouvoir analyser des données avec un outil de données multicloud qui est économique et rapide, et ne génère pas de frais généraux supplémentaire liée à la gouvernance des données décentralisée. En utilisant BigQuery Omni, nous atténuons ces frictions grâce à une interface unifiée.
Pour exécuter des analyses BigQuery sur vos données externes, vous devez d'abord vous connecter à Amazon S3 ou Blob Storage. Si vous souhaitez interroger des données externes, vous devez créer une table BigLake faisant référence aux données Amazon S3 ou Blob Storage.
Outils BigQuery Omni
Vous pouvez utiliser les outils BigQuery Omni suivants pour exécuter des analyses BigQuery sur vos données externes :
- Jointures multicloud : exécutez une requête directement à partir d'une région BigQuery pouvant joindre des données provenant d'une région BigQuery Omni.
- Vues matérialisées multicloud : utilisez des répliques de vues matérialisées pour répliquer en continu les données des régions BigQuery Omni. Compatible avec le filtrage des données.
- Transfert multicloud à l'aide de
SELECT: exécutez une requête à l'aide de l'instructionCREATE TABLE AS SELECTouINSERT INTO SELECTdans une région BigQuery Omni, puis déplacez le résultat vers une région BigQuery. - Transfert multicloud à l'aide de
LOAD: Utilisez des instructionsLOAD DATApour charger des données directement depuis Amazon Simple Storage Service (Amazon S3) ou Azure Blob Storage dans BigQuery.
Le tableau suivant décrit les principales fonctionnalités de chaque outil multicloud :
| Jointures multi-cloud | Vue matérialisée multicloud | Transfert de cloud à cloud à l'aide de SELECT |
Transfert de cloud à cloud à l'aide de LOAD |
|
|---|---|---|---|---|
| Utilisation suggérée | Interrogez des données externes pour un usage unique, où vous pouvez les joindre à des tables locales ou joindre des données entre deux régions BigQuery Omni différentes (par exemple, entre les régions AWS et Azure Blob Storage). Utilisez des jointures inter-cloud si les données ne sont pas volumineuses et si la mise en cache n'est pas une exigence clé. | Configurez des requêtes répétées ou programmées pour transférer en continu des données externes de manière incrémentielle, où la mise en cache est une exigence clé. Par exemple, pour gérer un tableau de bord | Interrogez des données externes pour un usage unique, d'une région BigQuery Omni vers une région BigQuery, lorsque des contrôles manuels tels que la mise en cache et l'optimisation des requêtes sont essentiels, et si vous utilisez des requêtes complexes qui ne sont pas compatibles avec les jointures ou les vues matérialisées multicloud. | Migrer des ensembles de données volumineux tels quels, sans avoir à les filtrer, à l'aide de requêtes planifiées pour déplacer les données brutes |
| Filtrage des données avant leur transfert | Oui. Des limites s'appliquent à certains opérateurs de requête. Pour en savoir plus, consultez Limites des jointures inter-cloud. | Oui. Des limites s'appliquent à certains opérateurs de requête, tels que les fonctions d'agrégation et l'opérateur UNION. |
Oui. Aucune limite sur les opérateurs de requête | Non |
| Limites de taille des transferts | 60 Go par transfert (chaque sous-requête vers une région distante génère un transfert) | Aucune limite | 60 Go par transfert (chaque sous-requête vers une région distante génère un transfert) | Aucune limite |
| Compression du transfert de données | Compression des câbles | En colonnes | Compression des câbles | Compression des câbles |
| Mise en cache | Non compatible | Compatible avec les tables compatibles avec le cache avec vues matérialisées | Non compatible | Non compatible |
| Tarifs de sortie | Coût de sortie et intercontinental AWS | Coût de sortie et intercontinental AWS | Coût de sortie et intercontinental AWS | Coût de sortie et intercontinental AWS |
| Utilisation du calcul pour le transfert de données | Utilise des emplacements dans la région AWS ou Azure Blob Storage source (réservation ou à la demande) | Non utilisée | Utilise des emplacements dans la région AWS ou Azure Blob Storage source (réservation ou à la demande) | Non utilisée |
| Utilisation du calcul pour le filtrage | Utilise des emplacements dans la région AWS ou Azure Blob Storage source (réservation ou à la demande) | Utilise des emplacements dans la région AWS ou Azure Blob Storage source (réservation ou à la demande) pour calculer les vues matérialisées et les métadonnées locales | Utilise des emplacements dans la région AWS ou Azure Blob Storage source (réservation ou à la demande) | Non utilisée |
| Transfert incrémentiel | Non compatible | Compatible avec les vues matérialisées non agrégées | Non compatible | Non compatible |
Vous pouvez également envisager les alternatives suivantes pour transférer des données depuis Amazon Simple Storage Service (Amazon S3) ou Azure Blob Storage vers Google Cloud :
- Service de transfert de stockage : transférez des données entre le stockage d'objets et de fichiers dans Google Cloud , Amazon Simple Storage Service (Amazon S3) ou Azure Blob Storage.
- Service de transfert de données BigQuery : configurez le transfert automatisé de données vers BigQuery de manière programmée et gérée. Il est compatible avec une grande variété de sources et convient à la migration de données. Le service de transfert de données BigQuery n'est pas compatible avec le filtrage.
Architecture
L'architecture de BigQuery sépare le calcul du stockage, ce qui permet à BigQuery d'effectuer un scaling horizontal si nécessaire pour gérer des charges de travail très volumineuses. BigQuery Omni étend cette architecture en exécutant le moteur de requêtes BigQuery dans d'autres clouds. De ce fait, vous n'avez pas besoin de déplacer physiquement les données dans l'espace de stockage BigQuery. Le traitement des données se déroule là où ces données sont déjà stockées.
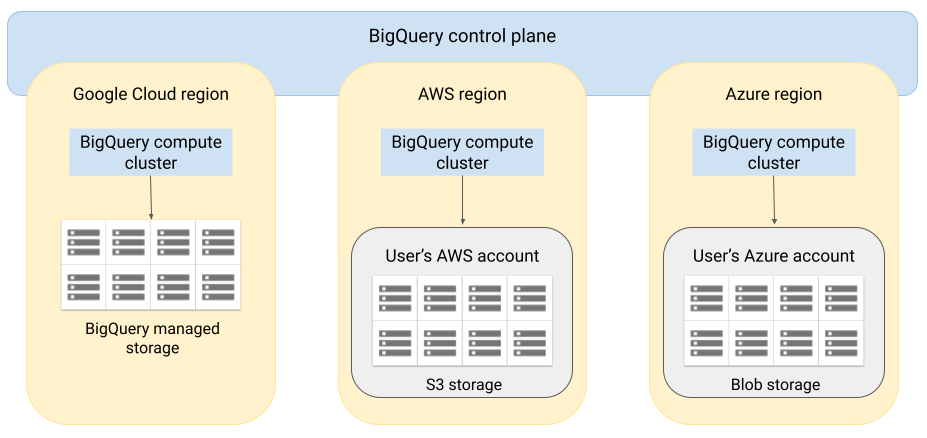
Les résultats de la requête peuvent être renvoyés à Google Cloud via une connexion sécurisée, par exemple pour s'afficher dans la console Google Cloud . Vous pouvez également écrire les résultats directement dans l'espace de stockage Amazon S3 ou Blob Storage. Dans ce cas, les résultats de la requête ne sont pas déplacés entre plusieurs clouds.
BigQuery Omni utilise les rôles AWS IAM standards ou les principes Azure Active Directory pour accéder aux données de votre abonnement. Vous déléguez l'accès en lecture ou en écriture à BigQuery Omni, et vous pouvez révoquer cet accès à tout moment.
Flux de données lors de l'interrogation de données
L'image suivante décrit la manière dont les données sont déplacées entre Google Cloud et AWS ou Azure pour les requêtes suivantes :
- Instruction
SELECT - Instruction
CREATE EXTERNAL TABLE

- Le plan de contrôle BigQuery reçoit des jobs de requête de votre part via la consoleGoogle Cloud , l'outil de ligne de commande bq, une méthode API ou une bibliothèque cliente.
- Le plan de contrôle BigQuery envoie des tâches de requête à traiter dans le plan de données BigQuery (sur AWS ou Azure).
- Le plan de données BigQuery reçoit une requête du plan de contrôle via une connexion VPN.
- Le plan de données BigQuery lit les données de table de votre bucket Amazon S3 ou Blob Storage.
- Le plan de données BigQuery exécute la tâche de requête sur les données de table. Le traitement des données de la table s'effectue dans la région AWS ou Azure sélectionnée.
- Le résultat de la requête est transmis du plan de données au plan de contrôle via la connexion VPN.
- Le plan de contrôle BigQuery reçoit les résultats du job de requête à afficher en réponse au job de requête. Ces données sont stockées pendant 24 heures au maximum.
- Le résultat de la requête vous est renvoyé.
Pour en savoir plus, consultez Interroger les données Amazon S3 et Données Blob Storage.
Flux de données lors de l'exportation de données
L'image suivante décrit la façon dont les données sont déplacées entre Google Cloud et AWS ou Azure lorsqu'une instruction EXPORT DATAest utilisée.

- Le plan de contrôle BigQuery reçoit des tâches de requête d'exportation de votre part via la console Google Cloud , l'outil de ligne de commande bq, une méthode API ou une bibliothèque cliente. La requête contient le chemin de destination du résultat de la requête dans votre bucket Amazon S3 ou Blob Storage.
- Le plan de contrôle BigQuery envoie des tâches de requête d'exportation pour traitement au plan de données BigQuery (sur AWS ou Azure).
- Le plan de données BigQuery reçoit la requête d'exportation provenant du plan de contrôle via la connexion VPN.
- Le plan de données BigQuery lit les données de table de votre bucket Amazon S3 ou Blob Storage.
- Le plan de données BigQuery exécute la tâche de requête sur les données de table. Le traitement des données de la table s'effectue dans la région AWS ou Azure sélectionnée.
- BigQuery écrit le résultat de la requête dans le chemin de destination spécifié dans votre bucket Amazon S3 ou Blob Storage.
Pour en savoir plus, consultez Exporter des résultats de requête vers Amazon S3 et Blob Storage.
Avantages
Performances Vous pouvez obtenir des insights plus rapidement, car les données ne sont pas copiées entre les différents clouds, et les requêtes s'exécutent dans la même région que celle où sont stockées vos données.
Coût Vous réduisez les coûts associés aux transferts de données sortantes, car les données ne sont pas déplacées. Aucuns frais supplémentaires ne sont facturés pour votre compte AWS ou Azure lié à l'analyse BigQuery Omni, car les requêtes s'exécutent sur des clusters gérés par Google. Vous n'êtes facturé que pour l'exécution des requêtes, selon le modèle de tarification BigQuery.
Sécurité et gouvernance des données. Vous devez gérer les données dans votre propre abonnement AWS ou Azure. Vous n'avez pas besoin de transférer ni de copier les données brutes depuis votre cloud public. Tous les calculs sont effectués dans le service mutualisé BigQuery qui s'exécute dans la même région que vos données.
Architecture sans serveur Comme le reste de BigQuery, BigQuery Omni est une offre sans serveur. Google déploie et gère les clusters qui exécutent BigQuery Omni. Vous n'avez pas besoin de provisionner de ressources ni de gérer de clusters.
Gestion simplifiée BigQuery Omni fournit une interface de gestion unifiée via Google Cloud. BigQuery Omni peut utiliser votre compte Google Cloud et vos projets BigQuery existants. Vous pouvez écrire une requête GoogleSQL dans la console Google Cloud pour interroger des données dans AWS ou Azure, et voir les résultats affichés dans la console Google Cloud .
Transfert de cloud à cloud Vous pouvez charger des données dans des tables BigQuery standards à partir de buckets S3 et de Blob Storage. Pour en savoir plus, consultez Transférer des données Amazon S3 et Données Blob Storage vers BigQuery.
Mise en cache des métadonnées pour améliorer les performances
Vous pouvez utiliser les métadonnées mises en cache pour améliorer les performances des requêtes sur les tables BigLake faisant référence à des données Amazon S3. Ceci est particulièrement utile lorsque vous travaillez avec un grand nombre de fichiers ou lorsque les données sont partitionnées avec Apache Hive.
BigQuery utilise CMETA comme système de métadonnées distribué pour gérer efficacement les grandes tables. CMETA fournit des métadonnées précises au niveau des colonnes et des blocs, accessibles via les tables système. Ce système permet d'améliorer les performances des requêtes en optimisant l'accès aux données et leur traitement. Pour accélérer davantage les performances des requêtes sur les grandes tables, BigQuery gère un cache de métadonnées. Les jobs d'actualisation CMETA permettent de maintenir ce cache à jour.Les métadonnées incluent les noms de fichiers, les informations de partitionnement et les métadonnées physiques des fichiers, telles que le nombre de lignes. Vous pouvez choisir d'activer ou non la mise en cache des métadonnées sur une table. Les requêtes comportant un grand nombre de fichiers et des filtres de partitionnement Apache Hive tirent le meilleur parti de la mise en cache des métadonnées.
Si vous n'activez pas la mise en cache des métadonnées, les requêtes effectuées sur la table doivent lire la source de données externe pour obtenir les métadonnées d'objet. La lecture de ces données augmente la latence des requêtes. Répertorier des millions de fichiers depuis la source de données externe peut prendre plusieurs minutes. Si vous activez la mise en cache des métadonnées, les requêtes peuvent éviter de répertorier les fichiers de la source de données externe et ainsi partitionner et supprimer les fichiers plus rapidement.
La mise en cache des métadonnées s'intègre également à la gestion des versions des objets Cloud Storage. Lorsque le cache est rempli ou actualisé, il capture les métadonnées en fonction de la version active des objets Cloud Storage à ce moment-là. Par conséquent, les requêtes pour lesquelles la mise en cache des métadonnées est activée lisent les données correspondant à la version spécifique de l'objet mis en cache, même si des versions plus récentes deviennent actives dans Cloud Storage. Pour accéder aux données de toutes les versions d'objet mises à jour ultérieurement dans Cloud Storage, vous devez actualiser le cache de métadonnées.
Deux propriétés contrôlent cette fonctionnalité :
- L'obsolescence maximale spécifie le moment auquel les requêtes utilisent des métadonnées mises en cache..
- Le mode de cache des métadonnées spécifie la manière dont les métadonnées sont collectées.
Lorsque la mise en cache des métadonnées est activée, vous spécifiez l'intervalle maximal d'obsolescence des métadonnées acceptable pour les opérations sur la table. Par exemple, si vous spécifiez un intervalle d'une heure, les opérations sur la table utilisent les métadonnées mises en cache si celles-ci ont été actualisées au cours de la dernière heure. Si les métadonnées mises en cache sont plus anciennes, l'opération extrait les métadonnées depuis Amazon S3. Vous pouvez spécifier un intervalle d'obsolescence compris entre 30 minutes et sept jours.
Lorsque vous activez la mise en cache des métadonnées pour les tables BigLake ou d'objets, BigQuery déclenche des tâches d'actualisation de la génération de métadonnées. Vous pouvez choisir d'actualiser le cache automatiquement ou manuellement :
- Pour les actualisations automatiques, le cache est actualisé à un intervalle défini par le système, généralement compris entre 30 et 60 minutes. L'actualisation automatique du cache est une bonne approche si les fichiers dans Amazon S3 sont ajoutés, supprimés ou modifiés à intervalles irréguliers. Si vous devez contrôler le moment de l'actualisation, par exemple pour déclencher l'actualisation à la fin d'un job d'extraction, de transformation et de chargement, utilisez l'actualisation manuelle.
Pour les actualisations manuelles, exécutez la procédure système
BQ.REFRESH_EXTERNAL_METADATA_CACHEafin d'actualiser le cache de métadonnées selon une programmation répondant à vos besoins. L'actualisation manuelle du cache est une bonne approche si les fichiers dans Amazon S3 sont ajoutés, supprimés ou modifiés à des intervalles connus, par exemple en tant que sortie d'un pipeline.Si vous émettez plusieurs actualisations manuelles simultanées, une seule réussira.
Le cache des métadonnées expire au bout de sept jours s'il n'est pas actualisé.
Les actualisations manuelles et automatiques du cache sont exécutées avec la priorité de requête INTERACTIVE.
Utiliser les réservations BACKGROUND
Si vous choisissez d'utiliser les actualisations automatiques, nous vous recommandons de créer une réservation, puis de créer une attribution avec un type de job BACKGROUND pour le projet qui exécute les jobs d'actualisation du cache de métadonnées. Avec les réservations BACKGROUND, les jobs d'actualisation utilisent un pool de ressources dédié, ce qui les empêche d'être en concurrence avec les requêtes utilisateur et d'échouer potentiellement si les ressources sont insuffisantes.
L'utilisation d'un pool d'emplacements partagés n'entraîne aucun coût supplémentaire. Toutefois, l'utilisation de réservations BACKGROUND offre des performances plus cohérentes en allouant un pool de ressources dédié. Elle améliore également la fiabilité des jobs d'actualisation et l'efficacité globale des requêtes dans BigQuery.
Réfléchissez à la manière dont l'intervalle d'obsolescence et les valeurs du mode de mise en cache des métadonnées interagissent avant de les définir. Prenons les exemples suivants :
- Si vous actualisez manuellement le cache de métadonnées d'une table et que vous définissez l'intervalle d'obsolescence sur deux jours, vous devez exécuter la procédure système
BQ.REFRESH_EXTERNAL_METADATA_CACHEtous les deux jours ou moins si vous souhaitez effectuer des opérations sur la table pour utiliser les métadonnées mises en cache. - Si vous actualisez automatiquement le cache de métadonnées d'une table et que vous définissez l'intervalle d'obsolescence sur 30 minutes, il est possible que certaines de vos opérations sur la table lisent les données d'Amazon S3 si l'actualisation du cache de métadonnées s'approche de la durée maximum de la fenêtre habituelle de 30 à 60 minutes.
Pour trouver des informations sur les jobs d'actualisation des métadonnées, interrogez la vue INFORMATION_SCHEMA.JOBS, comme illustré dans l'exemple suivant :
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Pour en savoir plus, consultez la section Mise en cache des métadonnées.
Tables compatibles avec le cache avec vues matérialisées
Vous pouvez utiliser des vues matérialisées sur des tables compatibles avec le cache des métadonnées Amazon Simple Storage Service (Amazon S3) pour améliorer les performances et l'efficacité lors de l'interrogation de données structurées stockées dans Amazon S3. Ces vues matérialisées fonctionnent comme les vues matérialisées sur des tables de stockage gérées par BigQuery, ce qui inclut les avantages de l'actualisation automatique et du réglage intelligent.
Pour rendre les données Amazon S3 dans une vue matérialisée disponibles dans une région BigQuery compatible à des fins de jointure, créez une instance dupliquée de la vue matérialisée. Vous ne pouvez créer des instances répliquées de vues matérialisées que pour les vues matérialisées autorisées.
Limites
En plus des limitations pour les tables BigLake, les limitations suivantes s'appliquent à BigQuery Omni, qui inclut des tables BigLake basées sur des données Amazon S3 et Blob Storage :
- L'utilisation de données dans l'une des régions BigQuery Omni n'est pas compatible avec les éditions Standard et Enterprise Plus. Pour en savoir plus sur les éditions, consultez la page Présentation des éditions BigQuery.
- Les vues
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGE,PARTITIONSetINFORMATION_SCHEMAne sont pas disponibles pour les tables BigLake basées sur Amazon S3 et Blob Storage. - Les vues matérialisées ne sont pas compatibles avec Blob Storage.
- Les fonctions JavaScript définies par l'utilisateur ne sont pas acceptées.
Les instructions SQL suivantes ne sont pas acceptées :
- Instructions BigQuery ML.
- Instructions LDD (langage de définition de données) nécessitant des données gérées dans BigQuery. Par exemple,
CREATE EXTERNAL TABLE,CREATE SCHEMAouCREATE RESERVATIONsont acceptés, maisCREATE TABLEne l'est pas. - Instructions du langage de manipulation de données (LMD).
Les limites suivantes s'appliquent à l'interrogation et à la lecture des tables temporaires de destination :
- Il n'est pas possible d'interroger des tables temporaires de destination à l'aide de l'instruction
SELECT.
- Il n'est pas possible d'interroger des tables temporaires de destination à l'aide de l'instruction
Les requêtes programmées ne sont disponibles que via la méthode API ou CLI. L'option de table de destination est désactivée pour les requêtes. Seules les requêtes
EXPORT DATAsont autorisées.L'API BigQuery Storage n'est pas disponible dans les régions BigQuery Omni.
Si votre requête utilise la clause
ORDER BYet que sa taille de résultat est supérieure à 256 Mo, votre requête échoue. Pour résoudre ce problème, réduisez la taille du résultat ou supprimez la clauseORDER BYde la requête. Pour en savoir plus sur les quotas BigQuery Omni, consultez la page Quotas et limites.Utiliser des clés de chiffrement gérées par le client (CMEK) avec des ensembles de données et des tables externes n'est pas pris en charge.
Tarifs
Pour en savoir plus sur les tarifs et les offres à durée limitée dans BigQuery Omni, consultez la page Tarifs de BigQuery Omni.
Quotas et limites
Pour en savoir plus sur les quotas BigQuery Omni, consultez la page Quotas et limites.
Si le résultat de votre requête dépasse 20 Gio, envisagez d'exporter les résultats vers Amazon S3 ou Blob Storage. Pour en savoir plus sur les quotas de l'API BigQuery Connection, consultez la page API BigQuery Connection.
Emplacements
BigQuery Omni traite les requêtes dans le même emplacement que l'ensemble de données contenant les tables que vous interrogez. Après avoir créé l'ensemble de données, la zone ne peut plus être modifiée. Vos données résident dans votre propre compte AWS ou Azure. Les régions BigQuery Omni sont compatibles avec les réservations de l'édition Enterprise et la tarification du calcul à la demande (analyse). Pour en savoir plus sur les éditions, consultez la page Présentation des éditions BigQuery.
| Description de la région | Nom de la région | Région BigQuery colocalisée | |
|---|---|---|---|
| AWS | |||
| AWS Est des États-Unis (Virginie du Nord) | aws-us-east-1 |
us-east4 |
|
| AWS Est des États-Unis (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS – Asie-Pacifique (Séoul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS – Asie-Pacifique (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS – Europe (Irlande) | aws-eu-west-1 |
europe-west1 |
|
| AWS – Europe (Francfort) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure – Est des États-Unis 2 | azure-eastus2 |
us-east4 |
|
Étapes suivantes
- Découvrez comment vous connecter à Amazon S3 et Blob Storage.
- Découvrez comment créer des tables BigLake Amazon S3 et Blob Storage.
- Découvrez comment interroger des tables BigLake Amazon S3 et Blob Storage.
- Découvrez comment joindre des tables BigLake Amazon S3 et Blob Storage à des tables Google Cloud à l'aide de jointures multicloud.
- Découvrez comment exporter les résultats de requêtes vers Amazon S3 et Blob Storage.
- Découvrez comment transférer des données depuis Amazon S3 et Blob Storage vers BigQuery.
- Découvrez comment configurer un périmètre VPC Service Controls.
- Découvrez comment spécifier votre emplacement.