Planifier des requêtes
Cette page décrit comment programmer des requêtes récurrentes dans BigQuery.
Vous pouvez programmer des requêtes à exécuter de façon récurrente. Les requêtes programmées doivent être écrites en GoogleSQL et peuvent inclure des instructions en langage de définition de données (LDD) et en langage de manipulation de données (LMD). Vous pouvez organiser les résultats de la requête par date et heure en paramétrant la chaîne de requête et la table de destination.
Lorsque vous créez ou mettez à jour la programmation d'une requête, l'heure programmée pour la requête est convertie de votre heure locale en heure UTC. L'heure UTC n'est pas affectée par l'heure d'été.
Avant de commencer
- Les requêtes programmées utilisent les fonctionnalités du service de transfert de données BigQuery. Vérifiez que vous avez effectué toutes les actions requises sur la page Activer le service de transfert de données BigQuery.
- Attribuez aux utilisateurs des rôles IAM (Identity and Access Management) incluant les autorisations nécessaires pour effectuer l'ensemble des tâches du présent document.
- Si vous envisagez de spécifier une clé de chiffrement gérée par le client (CMEK), assurez-vous que votre compte de service est autorisé à procéder au chiffrement et au déchiffrement, et que vous disposez de l'ID de ressource de la clé Cloud KMS requis pour utiliser des clés CMEK. Pour en savoir plus sur le fonctionnement des clés CMEK avec le service de transfert de données BigQuery, consultez la section Spécifier une clé de chiffrement avec des requêtes programmées.
Autorisations requises
Pour planifier une requête, vous devez disposer des autorisations IAM suivantes :
Pour créer le transfert, vous devez disposer des autorisations
bigquery.transfers.updateetbigquery.datasets.get, ou des autorisationsbigquery.jobs.create,bigquery.transfers.getetbigquery.datasets.get.Pour exécuter une requête programmée, vous devez disposer des autorisations suivantes :
- Autorisations
bigquery.datasets.getsur l'ensemble de données cible bigquery.jobs.create
- Autorisations
Pour modifier ou supprimer une requête programmée, vous devez disposer des autorisations bigquery.transfers.update et bigquery.transfers.get, ou de l'autorisation bigquery.jobs.create et être le propriétaire de la requête programmée.
Le rôle IAM prédéfini Administrateur BigQuery (roles/bigquery.admin) inclut les autorisations dont vous avez besoin pour planifier ou modifier une requête.
Pour en savoir plus sur les rôles IAM dans BigQuery, consultez la page Rôles prédéfinis et autorisations.
Pour créer ou mettre à jour des requêtes planifiées exécutées par un compte de service, vous devez avoir accès à ce compte de service. Pour en savoir plus sur l'attribution du rôle de compte de service aux utilisateurs, consultez la section Rôle Utilisateur du compte de service. Pour sélectionner un compte de service dans l'UI de requête programmée de la consoleGoogle Cloud , vous devez disposer des autorisations IAM suivantes :
iam.serviceAccounts.listpour lister vos comptes de service.iam.serviceAccountUserpour attribuer un compte de service à une requête programmée.
Options de configuration
Les sections suivantes décrivent les options de configuration.
Chaîne de requête
La chaîne de requête doit être valide et écrite en GoogleSQL. À chaque exécution, une requête programmée peut recevoir les paramètres de requête suivants.
Pour tester manuellement une chaîne de requête avec les paramètres @run_time et @run_date avant de programmer une requête, utilisez l'outil de ligne de commande bq.
Paramètres disponibles
| Paramètre | Type GoogleSQL | Valeur |
|---|---|---|
@run_time |
TIMESTAMP |
Représenté en temps UTC. Pour les requêtes programmées de façon récurrente, run_time représente l'heure d'exécution prévue. Par exemple, si la requête programmée est définie sur "toutes les 24 heures", la différence de run_time entre deux requêtes consécutives sera exactement de 24 heures, même si le temps d'exécution réel peut varier légèrement. |
@run_date |
DATE |
Représente une date de calendrier logique. |
Exemple
Le paramètre @run_time fait partie de la chaîne de requête de l'exemple suivant, où une requête est exécutée sur un ensemble de données public nommé hacker_news.stories.
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
Table de destination
Si la table de destination de vos résultats n'existe pas lors de la configuration de la requête programmée, BigQuery tentera de créer la table pour vous.
Si vous utilisez une requête LDD ou LMD, dans la console Google Cloud , choisissez la région ou l'emplacement de traitement. L'emplacement de traitement est requis pour les requêtes LDD ou LMD qui créent la table de destination.
Si la table de destination existe et que vous utilisez la préférence d'écriture WRITE_APPEND, BigQuery ajoute les données à la table de destination et tente de mapper le schéma.
BigQuery autorise automatiquement l'ajout et le réordonnancement de champs, et gère les champs facultatifs manquants. Si le schéma de la table change tellement entre les exécutions que BigQuery ne peut pas traiter les changements automatiquement, la requête programmée échoue.
Les requêtes peuvent référencer des tables provenant de différents projets et de différents ensembles de données. Lors de la configuration de votre requête programmée, il n'est pas nécessaire d'ajouter l'ensemble de données de destination au nom de la table. L'ensemble de données de destination est à spécifier séparément.
L'ensemble de données et la table de destination d'une requête planifiée doivent se trouver dans le même projet que la requête planifiée.
Préférence d'écriture
L'option d'écriture que vous choisissez permet de déterminer la manière dont les résultats de votre requête sont écrits sur une table de destination existante.
WRITE_TRUNCATE: si la table existe, BigQuery écrase les données de la table.WRITE_APPEND: si la table existe, BigQuery ajoute les données à la table.
Si vous utilisez une requête LDD ou LMD, vous ne pouvez pas utiliser l'option de préférence d'écriture.
Une table de destination est créée, écrasée ou modifiée seulement dans le cas où BigQuery est en mesure d'exécuter correctement la requête. Ces actions de création, d'écrasement ou d'ajout prennent la forme d'une mise à jour atomique en fin de tâche.
Clustering
Les requêtes programmées peuvent générer un clustering sur les nouvelles tables uniquement, lorsque la table est créée avec une instruction CREATE TABLE AS SELECT. Consultez la section Créer une table groupée à partir d'un résultat de requête de la page Utiliser les instructions de langage de définition de données.
Options de partitionnement
Les requêtes programmées peuvent générer des tables de destination partitionnées ou non partitionnées. Le partitionnement est disponible dans les méthodes de configuration de la console Google Cloud , de l'outil de ligne de commande bq et de l'API. Si vous utilisez une requête LDD ou LMD avec partitionnement, laissez le champ de partitionnement de la table de destination vide.
Vous pouvez utiliser les types de partitionnements de tables suivants dans BigQuery :
- Partitionnement par plages d'entiers : tables partitionnées en fonction des plages de valeurs d'une colonne
INTEGERspécifique. - Partitionnement par colonnes d'unités de temps : tables partitionnées en fonction d'une colonne
TIMESTAMP,DATEouDATETIME. - Partitionnement par date d'ingestion : tables partitionnées par date d'ingestion. BigQuery attribue automatiquement des lignes aux partitions en fonction de la date d'ingestion des données par BigQuery.
Pour créer une table partitionnée à l'aide d'une requête programmée dans la consoleGoogle Cloud , utilisez les options suivantes :
Pour utiliser le partitionnement par plages d'entiers, laissez le champ de partitionnement de la table de destination vide.
Pour utiliser le partitionnement par colonnes d'unités de temps, spécifiez le nom de la colonne dans le champ de partitionnement de la table de destination lorsque vous configurez une requête programmée.
Pour utiliser le partitionnement par date d'ingestion, laissez le champ de partitionnement de la table de destination vide et indiquez le partitionnement de la date dans le nom de la table de destination. Exemple :
mytable${run_date}. Pour en savoir plus, consultez la section Syntaxe des paramètres de modélisation.
Paramètres disponibles
Lors de la configuration de la requête programmée, vous pouvez définir la manière dont vous souhaitez partitionner la table de destination avec des paramètres d'exécution.
| Paramètre | Type de modèle | Valeur |
|---|---|---|
run_time |
Horodatage formaté | En heure UTC, selon l'exécution programmée. Pour les requêtes programmées de façon récurrente, run_time représente l'heure d'exécution prévue. Par exemple, si la requête programmée est définie sur "toutes les 24 heures", la différence de run_time entre deux requêtes consécutives sera exactement de 24 heures, même si le temps d'exécution réel peut varier légèrement.Consultez TransferRun.runTime. |
run_date |
Chaîne de date | Date du paramètre run_time au format %Y-%m-%d, par exemple 2018-01-01. Ce format est compatible avec les tables partitionnées par date d'ingestion. |
Système de modélisation
Les requêtes programmées supportent les paramètres d'exécution dans le nom de la table de destination avec une syntaxe de modélisation.
Syntaxe des paramètres de modélisation
La syntaxe de modélisation supporte la modélisation de base des chaînes et le décalage horaire. Les paramètres sont référencés dans les formats suivants :
{run_date}{run_time[+\-offset]|"time_format"}
| Paramètre | Objectif |
|---|---|
run_date |
Ce paramètre est remplacé par la date au format YYYYMMDD. |
run_time |
Ce paramètre accepte les propriétés suivantes :
|
- Aucun espace n'est autorisé entre run_time, offset et time format.
- Pour inclure des accolades littérales dans la chaîne, vous pouvez les échapper comme ceci :
'\{' and '\}'. - Pour inclure des guillemets littéraux ou une barre verticale dans la chaîne time_format, comme dans
"YYYY|MM|DD", vous pouvez les échapper dans la chaîne comme suit :'\"'ou'\|'.
Exemples de modélisation des paramètres
Les exemples suivants permettent d'illustrer la manière de définir les noms d'une table de destination avec différents formats d'heure, et en incluant un décalage de l'exécution.| run_time (UTC) | Paramètre modélisé | Nom de la table de destination de sortie |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}ou mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
Utiliser un compte de service
Vous pouvez configurer une requête programmée pour l'authentification comme compte de service. Un compte de service est un compte spécial associé à votre projet Google Cloud . Le compte de service peut exécuter des tâches, telles que des requêtes programmées ou des pipelines de traitement par lot, avec ses propres identifiants de service plutôt que ceux d'un utilisateur final.
Pour en savoir plus sur l'authentification avec des comptes de service, consultez la page Présentation de l'authentification.
Vous pouvez configurer la requête programmée avec un compte de service. Si vous vous êtes connecté avec une identité fédérée, vous devez disposer d'un compte de service pour créer un transfert. Si vous vous êtes connecté avec un compte Google, il n'est pas nécessaire de disposer d'un compte de service pour le transfert.
Vous pouvez mettre à jour une requête programmée existante avec les identifiants d'un compte de service à l'aide de l'outil de ligne de commande bq ou de la console Google Cloud . Pour en savoir plus, consultez Mettre à jour les identifiants d'une requête programmée.
Spécifier une clé de chiffrement avec des requêtes programmées
Vous pouvez spécifier des clés de chiffrement gérées par le client (CMEK) pour chiffrer les données d'une exécution de transfert. Vous pouvez utiliser une clé CMEK pour accepter les transferts provenant de requêtes programmées.Lorsque vous spécifiez une clé CMEK avec un transfert, le service de transfert de données BigQuery l'applique à tous les caches sur disque intermédiaires des données ingérées afin que l'intégralité du workflow de transfert de données soit compatible avec CMEK.
Vous ne pouvez pas mettre à jour un transfert existant pour ajouter une clé CMEK si le transfert n'a pas été initialement créé avec une clé CMEK. Par exemple, vous ne pouvez pas modifier une table de destination initialement chiffrée par défaut pour être chiffrée avec des clés CMEK. À l'inverse, vous ne pouvez pas modifier une table de destination chiffrée par CMEK pour obtenir un type de chiffrement différent.
Vous pouvez mettre à jour une clé CMEK pour un transfert si la configuration de celui-ci a été initialement créée avec un chiffrement CMEK. Lorsque vous mettez à jour une clé CMEK pour une configuration de transfert, le service de transfert de données BigQuery propage cette clé aux tables de destination à la prochaine exécution du transfert, où le service de transfert de données BigQuery remplace toutes les clés CMEK obsolètes par la nouvelle clé lors de l'exécution du transfert. Pour en savoir plus, consultez Mettre à jour un transfert.
Vous pouvez également utiliser les clés par défaut d'un projet. Lorsque vous spécifiez une clé de projet par défaut avec un transfert, le service de transfert de données BigQuery utilise cette clé pour toutes les nouvelles configurations de transfert.
Configurer des requêtes programmées
Pour obtenir une description de la syntaxe de programmation, consultez la section Mettre en forme l'élément schedule.
Pour en savoir plus sur la syntaxe des planifications, consultez la page Ressource : TransferConfig.
Console
Ouvrez la page BigQuery dans la console Google Cloud .
Exécutez la requête de votre choix. Lorsque vous êtes satisfait de vos résultats, cliquez sur Programmer.
Les options de requête programmées s'ouvrent dans le volet Nouvelle requête programmée.
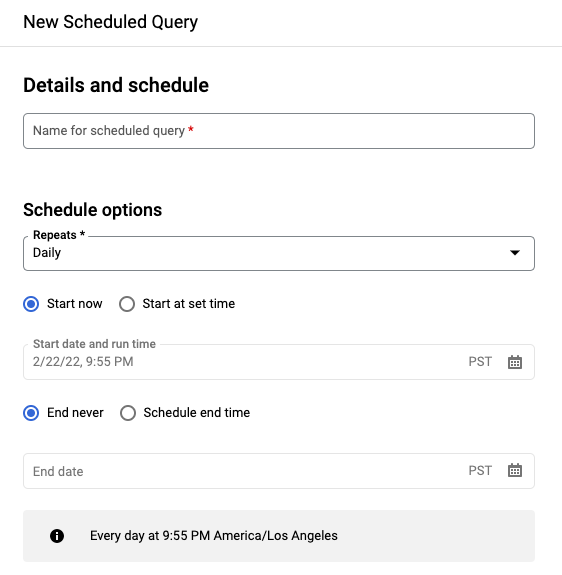
Dans le volet New scheduled query (Nouvelle requête programmée) :
- Sous Nom de la requête programmée, saisissez un nom, tel que
My scheduled query. Le nom de la requête programmée peut être toute valeur que vous pouvez identifier ultérieurement si vous devez modifier la requête. Facultatif : par défaut, la requête est planifiée pour s'exécuter Tous les jours. Vous pouvez modifier la programmation par défaut en sélectionnant une option dans le menu déroulant Périodicité :
Pour spécifier une fréquence personnalisée, sélectionnez Custom (Personnalisée), puis saisissez une spécification temporelle de type Cron dans le champ Custom schedule (Programmation personnalisée). Par exemple :
every mon 23:30ouevery 6 hours. Pour en savoir plus sur les programmations valides, y compris les intervalles personnalisés, consultez le champschedulesous Ressource :TransferConfig.
Pour modifier l'heure de début, sélectionnez l'option Démarrer à l'heure définie, puis saisissez la date et l'heure de début souhaitées.
Pour spécifier une heure de fin, sélectionnez l'option Définir une heure de fin, puis saisissez la date et l'heure de fin souhaitées.
Pour enregistrer la requête sans programmation afin de pouvoir l'exécuter à la demande ultérieurement, sélectionnez l'option À la demande dans le menu Périodicité.
- Sous Nom de la requête programmée, saisissez un nom, tel que
Pour une requête
SELECTen GoogleSQL, sélectionnez l'option Définir une table de destination pour les résultats de la requête et fournissez les informations suivantes sur l'ensemble de données de destination.- Sous Dataset name (Nom de l'ensemble de données), sélectionnez l'ensemble de données de destination.
- Sous Table name (Nom de la table), entrez le nom de la table de destination.
Sous Préférence d'écriture pour la table de destination, choisissez Ajouter à la table pour ajouter les données à la table ou Écraser la table pour écraser la table de destination.

Sélectionnez le type d'emplacement.
Si vous avez activé la table de destination pour les résultats de la requête, vous pouvez sélectionner Sélection automatique de l'emplacement pour sélectionner automatiquement l'emplacement où se trouve la table de destination.
Sinon, choisissez l'emplacement où sont situées les données interrogées.
Options avancées :
Facultatif : CMEK : Si vous utilisez des clés de chiffrement gérées par le client, vous pouvez sélectionner Customer-managed key (Clé gérée par le client) sous Advanced options (Options avancées). La liste des clés CMEK disponibles s'affiche. Pour en savoir plus sur le fonctionnement des clés de chiffrement gérées par le client (CMEK) avec le service de transfert de données BigQuery, consultez la section Spécifier une clé de chiffrement avec des requêtes programmées.
Authentifiez-vous avec un compte de service. Si un ou plusieurs comptes de service sont associés à votre projet Google Cloud , vous pouvez associer un compte de service à votre requête programmée plutôt que d'utiliser vos identifiants utilisateur. Sous Identifiants de requête programmée, cliquez sur le menu pour afficher la liste des comptes de service disponibles. Un compte de service est requis si vous êtes connecté en tant qu'identité fédérée.

Configurations supplémentaires :
Facultatif : Cochez la case Envoyer des notifications par e-mail pour autoriser les notifications par e-mail en cas d'échec de l'exécution des transferts.
Facultatif : Pour le champ Sujet Cloud Pub/Sub, saisissez le nom de votre sujet (par exemple,
projects/myproject/topics/mytopic).
Cliquez sur Enregistrer.
bq
Option 1 : Utilisez la commande bq query.
Pour créer une requête programmée, ajoutez les options destination_table (ou target_dataset), --schedule et --display_name à votre commande bq query.
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
Remplacez les éléments suivants :
name. Le nom à afficher pour la requête programmée. Le nom à afficher peut être toute valeur que vous pouvez identifier ultérieurement si vous devez modifier la requête.table. La table de destination des résultats de la requête.--target_datasetest un autre moyen de nommer l'ensemble de données cible pour les résultats de la requête, en cas d'utilisation avec des requêtes LDD et LMD.- Utilisez
--destination_tableou--target_dataset, mais pas les deux.
interval. En cas d'utilisation avecbq query, définit une requête programmée récurrente. La fréquence programmée d'exécution de la requête est requise. Pour en savoir plus sur les planifications valides, y compris les intervalles personnalisés, consultez le champschedulesous Ressource :TransferConfig. Exemples :--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
Indicateurs facultatifs :
--project_idest l'ID de votre projet. Si--project_idn'est pas spécifié, le projet par défaut est utilisé.--replaceremplace la table de destination par les résultats de la requête à chaque exécution de la requête programmée. Toutes les données existantes sont effacées. Pour les tables non partitionnées, le schéma est également effacé.--append_tableajoute les résultats à la table de destination.Pour les requêtes LDD et LMD, vous pouvez également définir l'option
--locationpour spécifier une région particulière de traitement. Si--locationn'est pas spécifié, l'emplacement Google Cloud le plus proche est utilisé.
Par exemple, la commande suivante crée une requête programmée nommée My Scheduled Query à l'aide de la requête SELECT 1 from mydataset.test.
La table de destination est mytable dans l'ensemble de données mydataset. La requête programmée est créée dans le projet par défaut :
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
Option 2 : Utilisez la commande bq mk.
Les requêtes programmées sont une sorte de transfert. Pour planifier une requête, vous pouvez utiliser l'outil de ligne de commande bq afin de créer une configuration de transfert.
Pour être programmées, les requêtes doivent être en SQL standard.
Saisissez la commande bq mk et spécifiez les options requises suivantes :
--transfer_config--data_source--target_dataset(facultatif pour les requêtes LDD et LMD)--display_name--params
Indicateurs facultatifs :
--project_idest l'ID de votre projet. Si--project_idn'est pas spécifié, le projet par défaut est utilisé.--schedulecorrespond à la fréquence d'exécution de la requête. Si--schedulen'est pas indiqué, la valeur par défaut est de toutes les 24 heures à partir de l'heure de création.Pour les requêtes LDD et LMD, vous pouvez également définir l'option
--locationpour spécifier une région particulière de traitement. Si--locationn'est pas spécifié, l'emplacement Google Cloud le plus proche est utilisé.--service_account_namepermet d'authentifier votre requête programmée avec un compte de service plutôt qu'avec votre compte utilisateur individuel.--destination_kms_keyspécifie l'ID de ressource de la clé si vous utilisez une clé de chiffrement gérée par le client (CMEK) pour ce transfert. Pour en savoir plus sur le fonctionnement des clés CMEK avec le service de transfert de données BigQuery, consultez la section Spécifier une clé de chiffrement avec des requêtes programmées.
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
Remplacez les éléments suivants :
dataset. Ensemble de données cible pour la configuration de transfert.- Ce paramètre est facultatif pour les requêtes LDD et LMD. Il est obligatoire pour toutes les autres requêtes.
name. Le nom à afficher pour la configuration de transfert. Le nom à afficher peut être toute valeur que vous pouvez identifier ultérieurement si vous devez modifier la requête.parameters. Contient les paramètres de la configuration de transfert créée au format JSON. Exemple :--params='{"param":"param_value"}'.- Pour une requête programmée, vous devez fournir le paramètre
query. - Le paramètre
destination_table_name_templateest le nom de votre table de destination.- Ce paramètre est facultatif pour les requêtes LDD et LMD. Il est obligatoire pour toutes les autres requêtes.
- Pour le paramètre
write_disposition, vous pouvez choisirWRITE_TRUNCATEpour tronquer (écraser) la table de destination ouWRITE_APPENDpour ajouter les résultats de la requête à la table de destination.- Ce paramètre est facultatif pour les requêtes LDD et LMD. Il est obligatoire pour toutes les autres requêtes.
- Pour une requête programmée, vous devez fournir le paramètre
data_source. La source de données :scheduled_query.- Facultatif : Le paramètre
--service_account_namepermet l'authentification avec un compte de service plutôt qu'avec un compte utilisateur individuel. - Facultatif :
--destination_kms_keyspécifie l'ID de ressource de la clé Cloud KMS (par exemple,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name).
Par exemple, la commande suivante crée une configuration de transfert de requête programmée nommée My Scheduled Query à l'aide de la requête SELECT 1
from mydataset.test. La table de destination mytable est tronquée à chaque écriture et l'ensemble de données cible est mydataset. La requête programmée est créée dans le projet par défaut et s'authentifie comme compte de service :
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com
La première fois que vous exécutez la commande, vous recevez un message de ce type :
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Suivez les instructions du message et collez le code d'authentification sur la ligne de commande.
API
Utilisez la méthode projects.locations.transferConfigs.create et fournissez une instance de la ressource TransferConfig.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Configurer des requêtes programmées avec un compte de service
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Afficher l'état d'une requête programmée
Console
Pour afficher l'état de vos requêtes programmées, cliquez sur Programmation dans le menu de navigation, puis filtrez les résultats sur Requête programmée. Cliquez sur une requête programmée pour en savoir plus.
bq
Les requêtes programmées sont une sorte de transfert. Pour afficher les détails d'une requête programmée, vous pouvez tout d'abord utiliser l'outil de ligne de commande bq afin de répertorier vos configurations de transfert.
Saisissez la commande bq ls, puis spécifiez l'option de transfert --transfer_config. Les options suivantes sont également requises :
--transfer_location
Exemple :
bq ls \
--transfer_config \
--transfer_location=us
Pour afficher les détails d'une seule requête programmée, saisissez la commande bq show et indiquez le transfer_path de cette requête programmée ou configuration de transfert.
Exemple :
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
Utilisez la méthode projects.locations.transferConfigs.list et fournissez une instance de la ressource TransferConfig.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Mettre à jour les requêtes programmées
Console
Pour mettre à jour une requête programmée, procédez comme suit :
- Dans le menu de navigation, cliquez sur Requêtes programmées ou Programmation.
- Dans la liste des requêtes programmées, cliquez sur le nom de la requête que vous souhaitez modifier.
- Sur la page Détails de la requête programmée qui s'affiche, cliquez sur Modifier.
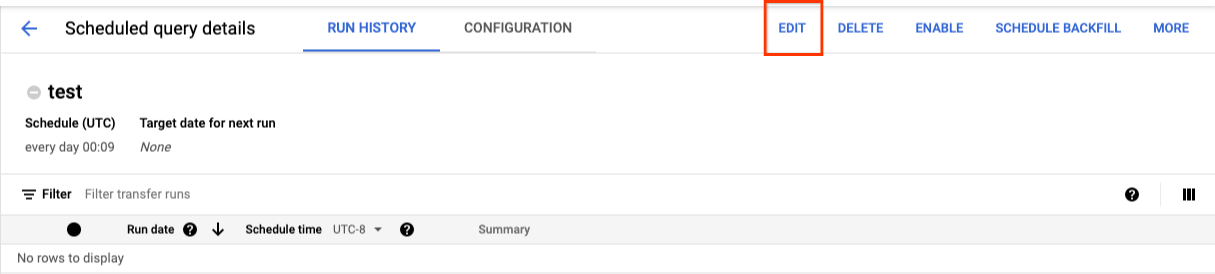
- Facultatif : modifiez le texte de la requête dans le volet de modification de la requête.
- Cliquez sur Schedule query (Programmer la requête), puis sélectionnez Update scheduled query (Mettre à jour la requête programmée).
- Facultatif : modifiez toute autre option de planification pour la requête.
- Cliquez sur Mettre à jour.
bq
Les requêtes programmées sont une sorte de transfert. Pour mettre à jour une requête programmée, vous pouvez utiliser l'outil de ligne de commande bq afin de créer une configuration de transfert.
Saisissez la commande bq update avec l'option --transfer_config requise.
Indicateurs facultatifs :
--project_idest l'ID de votre projet. Si--project_idn'est pas spécifié, le projet par défaut est utilisé.--schedulecorrespond à la fréquence d'exécution de la requête. Si--schedulen'est pas indiqué, la valeur par défaut est de toutes les 24 heures à partir de l'heure de création.--service_account_namene prend effet que si--update_credentialsest également défini. Pour en savoir plus, consultez la section Mettre à jour les identifiants d'une requête programmée.--target_dataset(facultatif pour les requêtes LDD et LMD) est un autre moyen de nommer l'ensemble de données cible pour les résultats de la requête, en cas d'utilisation avec des requêtes LDD et LMD.--display_nameest le nom de la requête programmée.--paramscorrespond aux paramètres de la configuration de transfert créée, au format JSON. Par exemple : --params='{"param":"param_value"}'.--destination_kms_keyspécifie l'ID de ressource de la clé Cloud KMS si vous utilisez une clé de chiffrement gérée par le client (CMEK) pour ce transfert. Pour en savoir plus sur le fonctionnement des clés de chiffrement gérées par le client (CMEK) avec le service de transfert de données BigQuery, consultez la section Spécifier une clé de chiffrement avec des requêtes programmées.
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
Remplacez les éléments suivants :
dataset. Ensemble de données cible pour la configuration de transfert. Ce paramètre est facultatif pour les requêtes LDD et LMD. Il est obligatoire pour toutes les autres requêtes.name. Le nom à afficher pour la configuration de transfert. Le nom à afficher peut être toute valeur que vous pouvez identifier ultérieurement si vous devez modifier la requête.parameters. Contient les paramètres de la configuration de transfert créée au format JSON. Exemple :--params='{"param":"param_value"}'.- Pour une requête programmée, vous devez fournir le paramètre
query. - Le paramètre
destination_table_name_templateest le nom de votre table de destination. Ce paramètre est facultatif pour les requêtes LDD et LMD. Il est obligatoire pour toutes les autres requêtes. - Pour le paramètre
write_disposition, vous pouvez choisirWRITE_TRUNCATEpour tronquer (écraser) la table de destination ouWRITE_APPENDpour ajouter les résultats de la requête à la table de destination. Ce paramètre est facultatif pour les requêtes LDD et LMD. Il est obligatoire pour toutes les autres requêtes.
- Pour une requête programmée, vous devez fournir le paramètre
- Facultatif :
--destination_kms_keyspécifie l'ID de ressource de la clé Cloud KMS (par exemple,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name). RESOURCE_NAME: nom de ressource du transfert (également appelé "configuration de transfert"). Si vous ne connaissez pas le nom de ressource du transfert, recherchez-le avecbq ls --transfer_config --transfer_location=location.
Par exemple, la commande suivante met à jour une configuration de transfert de requête programmée nommée My Scheduled Query avec la requête SELECT 1
from mydataset.test. La table de destination mytable est tronquée à chaque écriture et l'ensemble de données cible est mydataset :
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
Utilisez la méthode projects.transferConfigs.patch et indiquez le nom de ressource du transfert à l'aide du paramètre transferConfig.name. Si vous ne connaissez pas ce nom, exécutez la commande bq ls --transfer_config --transfer_location=location pour afficher tous les transferts ou appelez la méthode projects.locations.transferConfigs.list et indiquez l'ID de projet à l'aide du paramètre parent.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Mettre à jour des requêtes programmées avec des restrictions de propriété
Si vous essayez de mettre à jour une requête programmée qui ne vous appartient pas, la mise à jour peut échouer avec le message d'erreur suivant :
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Le propriétaire de la requête programmée est l'utilisateur associé à la requête programmée ou celui qui a accès au compte de service associé à celle-ci. L'utilisateur associé apparaît dans les détails de configuration de la requête programmée. Pour savoir comment mettre à jour la requête programmée afin d'en devenir propriétaire, consultez la section Mettre à jour les identifiants d'une requête programmée. Pour autoriser des utilisateurs à accéder à un compte de service, vous devez disposer du rôle Utilisateur du compte de service.
Voici les paramètres de restriction de propriété pour les requêtes programmées :
- Texte de la requête
- Ensemble de données de destination
- Modèle de nom de la table de destination
Mise à jour des identifiants d'une requête programmée
Si vous programmez une requête existante, il vous faudra peut-être mettre à jour les identifiants utilisateur de la requête. Les identifiants sont automatiquement mis à jour pour les nouvelles requêtes programmées.
Les situations suivantes peuvent également nécessiter la mise à jour des identifiants :
- Vous souhaitez interroger les données Google Drive dans une requête programmée.
Vous recevez une erreur INVALID_USER lorsque vous tentez de programmer la requête :
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERIDL'erreur suivante liée à la restriction des paramètres s'affiche lorsque vous essayez de mettre à jour la requête :
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Console
Pour mettre à jour les identifiants existants d'une requête programmée, procédez comme suit :
Recherchez et affichez l'état d'une requête programmée.
Cliquez sur le bouton MORE (Plus), puis sélectionnez Update credentials (Mettre à jour les identifiants).
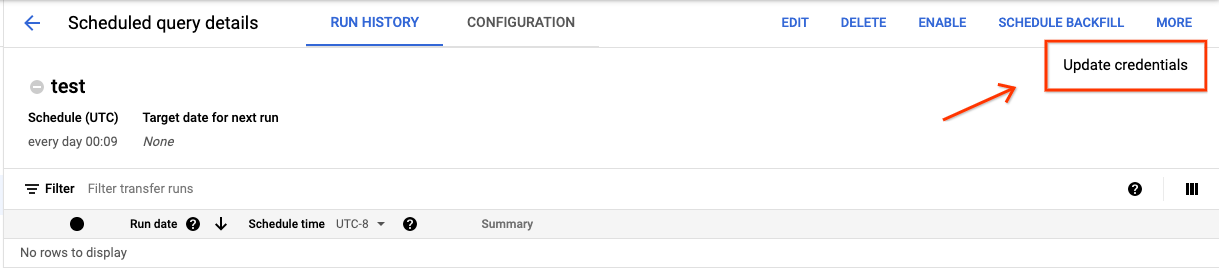
Attendez 10 à 20 minutes pour que la modification soit prise en compte. Vous devrez peut-être vider le cache de votre navigateur.
bq
Les requêtes programmées sont une sorte de transfert. Pour mettre à jour les identifiants d'une requête programmée, vous pouvez utiliser l'outil de ligne de commande bq afin de mettre à jour la configuration de transfert.
Saisissez la commande bq update, puis spécifiez l'option de transfert --transfer_config. Les options suivantes sont également requises :
--update_credentials
Option facultative :
--service_account_namepermet d'authentifier votre requête programmée avec un compte de service plutôt qu'avec votre compte utilisateur individuel.
Par exemple, la commande suivante met à jour la configuration de transfert d'une requête programmée pour qu'elle s'authentifie comme compte de service :
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Configurer une requête manuelle en fonction de dates de l'historique
En plus de la programmation de l'exécution ultérieure d'une requête, vous pouvez également déclencher des exécutions immédiates manuellement. Le déclenchement d'une exécution immédiate est nécessaire si votre requête utilise le paramètre run_date et qu'il existe des problèmes lors d'une exécution précédente.
Par exemple, tous les jours à 09h00, vous interrogez une table source sur les lignes correspondant à la date du jour. Cependant, vous constatez que les données n'ont pas été ajoutées à la table source au cours des trois derniers jours. Dans ce cas, vous pouvez configurer la requête pour qu'elle s'exécute sur des données historiques dans une plage de dates que vous spécifiez. Votre requête s'exécute avec des combinaisons de paramètres run_date et run_time correspondant aux dates que vous avez configurées dans votre requête programmée.
Après avoir configuré une requête programmée, vous pouvez l'exécuter en utilisant une plage de dates historique en procédant comme suit :
Console
Après avoir cliqué sur Programmer pour enregistrer votre requête programmée, vous pouvez cliquer sur le bouton Requêtes programmées pour afficher la liste des requêtes programmées. Cliquez sur n'importe quel nom pour afficher les détails de programmation de cette requête. En haut à droite de la page, cliquez sur Schedule backfill (Programmer le remplissage) pour spécifier une plage de dates historique.
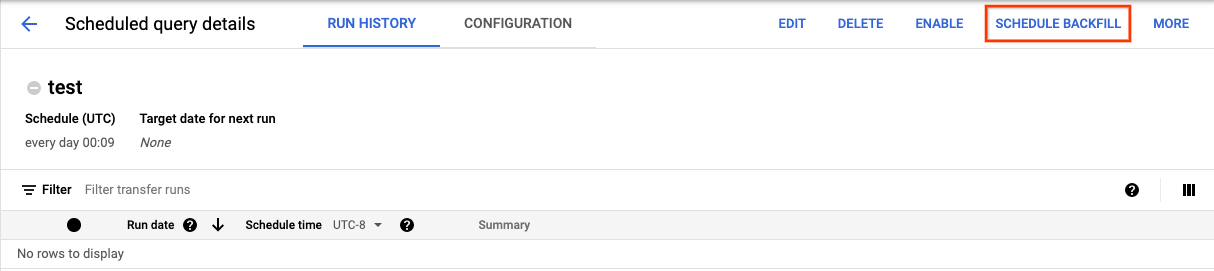
Les durées d'exécution choisies sont comprises dans la plage sélectionnée, y compris la première date et à l'exclusion de la dernière date.
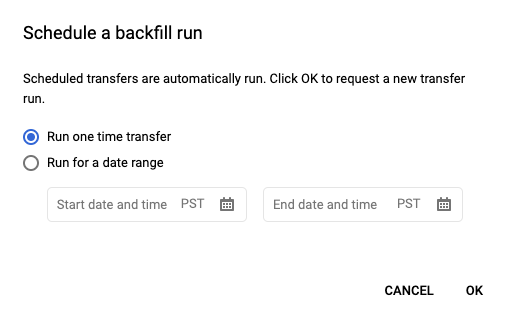
Exemple 1
Votre requête programmée est configurée pour s'exécuter selon l'heure du Pacifique every day 09:00. Il vous manque des données pour le 1er janvier, le 2 janvier et le 3 janvier. Choisissez la plage de dates historique suivante :
Start Time = 1/1/19
End Time = 1/4/19
Votre requête s'exécute avec les paramètres run_date et run_time correspondant aux heures suivantes :
- 1/1/19 09:00 (Heure du Pacifique)
- 1/2/19 09:00 (Heure du Pacifique)
- 1/3/19 09:00 (Heure du Pacifique)
Exemple 2
Votre requête programmée est configurée pour s'exécuter selon l'heure du Pacifique every day 23:00. Il vous manque des données pour le 1er janvier, le 2 janvier et le 3 janvier. Choisissez les plages de dates historiques suivantes (les dates ultérieures sont choisies, car UTC a une date différente à 23h00, heure du Pacifique) :
Start Time = 1/2/19
End Time = 1/5/19
Votre requête s'exécute avec les paramètres run_date et run_time correspondant aux heures suivantes :
- 02/01/2019 06:00 (UTC) ou 01/01/2019 23:00 (Heure du Pacifique)
- 03/01/2019 06:00 (UTC) ou 02/01/2019 23:00 (Heure du Pacifique)
- 04/01/2019 06:00 (UTC) ou 03/01/2019 23:00 (Heure du Pacifique)
Après avoir configuré les exécutions manuelles, actualisez la page pour les afficher dans la liste des exécutions.
bq
Pour exécuter manuellement la requête sur une plage de dates historique :
Entrez la commande bq mk et fournissez l'option d'exécution de transfert --transfer_run. Les options suivantes sont également requises :
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
Remplacez l'élément suivant :
start_timeetend_time. Horodatages se terminant par Z ou contenant un décalage de fuseau horaire valide. Exemples :- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name. Nom de ressource de la requête programmée (ou du transfert). Le nom de ressource est également appelé configuration de transfert.
Par exemple, la commande suivante programme un remplissage pour une ressource de requête programmée (ou une configuration de transfert) : projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7.
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Pour en savoir plus, consultez la page bq mk --transfer_run.
API
Exécutez la méthode projects.locations.transferConfigs.scheduleRun et fournissez le chemin d'accès à la ressource TransferConfig.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Configurer des alertes pour les requêtes programmées
Vous pouvez configurer des règles d'alerte pour les requêtes planifiées en fonction des métriques de nombre de lignes. Pour en savoir plus, consultez Configurer des alertes avec des requêtes programmées.
Supprimer des requêtes programmées
Console
Pour supprimer une requête programmée sur la page Requêtes programmées de la console Google Cloud :
- Dans le menu de navigation, cliquez sur Requêtes programmées.
- Dans la liste des requêtes programmées, cliquez sur le nom de la requête programmée que vous souhaitez supprimer.
Sur la page Détails de la requête programmée, cliquez sur Supprimer.
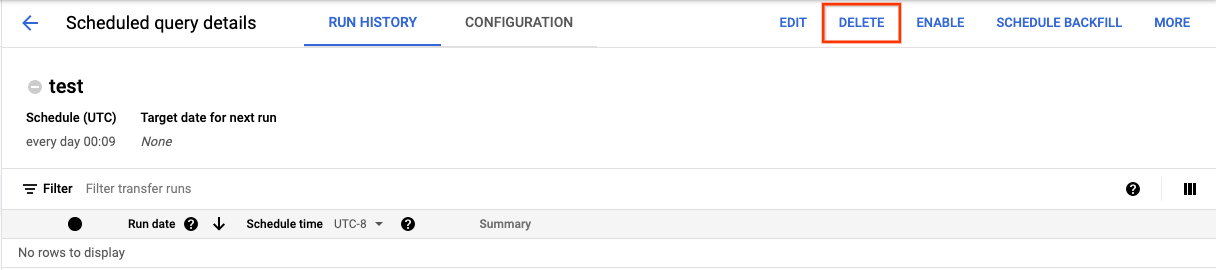
Vous pouvez également supprimer une requête programmée sur la page Programmation de la console Google Cloud :
- Dans le menu de navigation, cliquez sur Planification.
- Dans la liste des requêtes programmées, cliquez sur le menu Actions de la requête programmée que vous souhaitez supprimer.
Sélectionnez Supprimer.

Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Désactiver ou activer les requêtes programmées
Pour suspendre les exécutions programmées d'une requête sélectionnée sans supprimer la programmation, vous pouvez la désactiver.
Pour désactiver une programmation pour une requête sélectionnée, procédez comme suit :
- Dans le menu de navigation de la console Google Cloud , cliquez sur Planification.
- Dans la liste des requêtes programmées, cliquez sur le menu Actions de la requête programmée que vous souhaitez désactiver.
Sélectionnez Désactiver.

Pour activer une requête programmée désactivée, cliquez sur le menu Actions de la requête programmée que vous souhaitez activer, puis sélectionnez Activer.
Quotas
Les requêtes programmées sont toujours exécutées en tant que jobs de requête par lot et sont soumises aux mêmes quotas et limites BigQuery que les requêtes manuelles.
Bien que les requêtes programmées utilisent des fonctionnalités du service de transfert de données BigQuery, il ne s'agit pas de transferts, et elles ne sont pas soumises au quota de tâches de chargement.
L'identité utilisée pour exécuter la requête détermine les quotas appliqués. Cela dépend de la configuration de la requête programmée :
Identifiants du créateur (par défaut) : si vous ne spécifiez pas de compte de service, la requête planifiée s'exécute à l'aide des identifiants de l'utilisateur qui l'a créée. Le job de requête est facturé au projet du créateur et est soumis aux quotas de cet utilisateur et de ce projet.
Identifiants du compte de service : si vous configurez la requête planifiée pour qu'elle utilise un compte de service, elle s'exécute à l'aide des identifiants de ce compte. Dans ce cas, le job est toujours facturé au projet contenant la requête programmée, mais l'exécution est soumise aux quotas du compte de service spécifié.
Tarifs
Les prix des requêtes programmées sont les mêmes que pour les requêtes BigQuery manuelles.
Régions où le service est disponible
Les requêtes programmées sont disponibles aux emplacements suivants.
Régions
Le tableau suivant répertorie les régions Amériques où BigQuery est disponible.| Description de la région | Nom de la région | Détails |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Las Vegas | us-west4 |
|
| Los Angeles | us-west2 |
|
| Mexique | northamerica-south1 |
|
| Montréal | northamerica-northeast1 |
|
| Virginie du Nord | us-east4 |
|
| Oregon | us-west1 |
|
| Salt Lake City | us-west3 |
|
| São Paulo | southamerica-east1 |
|
| Santiago | southamerica-west1 |
|
| Caroline du Sud | us-east1 |
|
| Toronto | northamerica-northeast2 |
|
| Description de la région | Nom de la région | Détails |
|---|---|---|
| Delhi | asia-south2 |
|
| Hong Kong | asia-east2 |
|
| Jakarta | asia-southeast2 |
|
| Melbourne | australia-southeast2 |
|
| Mumbai | asia-south1 |
|
| Osaka | asia-northeast2 |
|
| Séoul | asia-northeast3 |
|
| Singapour | asia-southeast1 |
|
| Sydney | australia-southeast1 |
|
| Taïwan | asia-east1 |
|
| Tokyo | asia-northeast1 |
| Description de la région | Nom de la région | Détails |
|---|---|---|
| Belgique | europe-west1 |
|
| Berlin | europe-west10 |
|
| Finlande | europe-north1 |
|
| Francfort | europe-west3 |
|
| Londres | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Milan | europe-west8 |
|
| Pays-Bas | europe-west4 |
|
| Paris | europe-west9 |
|
| Stockholm | europe-north2 |
|
| Turin | europe-west12 |
|
| Varsovie | europe-central2 |
|
| Zurich | europe-west6 |
|
| Description de la région | Nom de la région | Détails |
|---|---|---|
| Dammam | me-central2 |
|
| Doha | me-central1 |
|
| Tel Aviv | me-west1 |
| Description de la région | Nom de la région | Détails |
|---|---|---|
| Johannesburg | africa-south1 |
Emplacements multirégionaux
Le tableau suivant répertorie les emplacements multirégionaux où BigQuery est disponible.| Description de la zone multirégionale | Nom de la zone multirégionale |
|---|---|
| Centres de données dans les États membres de l'Union européenne1 | EU |
| Centres de données aux États-Unis2 | US |
1 Les données situées dans la zone multirégionale EU ne sont stockées que dans l'un des emplacements suivants : europe-west1 (Belgique) ou europe-west4 (Pays-Bas).
L'emplacement exact où les données sont stockées et traitées est déterminé automatiquement par BigQuery.
2 Les données situées dans la zone multirégionale US ne sont stockées que dans l'un des emplacements suivants : us-central1 (Iowa), us-west1 (Oregon) ou us-central2 (Oklahoma). L'emplacement exact où les données sont stockées et traitées est déterminé automatiquement par BigQuery.
Étape suivante
- Pour obtenir un exemple de requête programmée qui utilise un compte de service et inclut les paramètres
@run_dateet@run_time, consultez la page Créer des instantanés de table avec une requête programmée.