Migration von Amazon Redshift zu BigQuery: Übersicht
Dieses Dokument enthält eine Anleitung für die Migration von Amazon Redshift zu BigQuery, wobei die folgenden Themen behandelt werden:
- Strategien für die Migration
- Best Practices für die Abfrageoptimierung und Datenmodellierung
- Tipps zur Fehlerbehebung
- Anleitung zur Nutzerakzeptanz
Das sind die Ziele dieses Dokuments:
- Allgemeine Anleitungen für Organisationen, die von Amazon Redshift zu BigQuery migrieren, und Unterstützung bei der Neudefinition Ihres vorhandenen Datenpipelines, um BigQuery optimal zu nutzen
- Vergleich der Architekturen von BigQuery und Amazon Redshift, um zu ermitteln, wie vorhandene Features und Funktionen während der Migration implementiert werden Das Ziel ist es, Ihnen neue Möglichkeiten aufzuzeigen, die Ihrer Organisation durch BigQuery zur Verfügung stehen, und nicht, Funktionen eins zu eins mit Amazon Redshift abzubilden.
Dieses Dokument richtet sich an Unternehmensarchitekten, Datenbankadministratoren, Anwendungsentwickler und IT-Sicherheitsexperten. Es wird davon ausgegangen, dass Sie mit Amazon Redshift vertraut sind.
Verwenden Sie die Batch-SQL-Übersetzung, um Ihre SQL-Skripts im Bulk zu migrieren, oder die interaktive SQL-Übersetzung, um Ad-hoc-Abfragen zu übersetzen. Amazon Redshift SQL wird von beiden SQL-Übersetzungsdiensten vollständig unterstützt.
Aufgaben vor der Migration
Um eine erfolgreiche Data Warehouse-Migration zu gewährleisten, sollten Sie Ihre Migrationsstrategie frühzeitig im Zeitplan Ihres Projekts planen. Bei diesem Ansatz können Sie die Google Cloud Funktionen bewerten, die Ihren Anforderungen entsprechen.
Kapazitätsplanung
BigQuery verwendet Slots, um den Analysedurchsatz zu messen. Ein BigQuery-Slot ist die proprietäre Rechenkapazität von Google, die zum Ausführen von SQL-Abfragen erforderlich ist. BigQuery berechnet kontinuierlich, wie viele Slots von den Abfragen benötigt werden, während es Abfragen ausführt. Es ordnet aber basierend auf einem fairen Planer Slots zu.
Bei der Kapazitätsplanung für BigQuery-Slots können Sie zwischen den folgenden Preismodellen wählen:
- On-Demand-Preis: Bei On-Demand-Preisen berechnet BigQuery die Anzahl der verarbeiteten Byte (Datengröße), sodass Sie nur für die ausgeführten Abfragen zahlen. Weitere Informationen dazu, wie BigQuery die Datengröße bestimmt, finden Sie unter Datengrößenberechnung. Da Slots die zugrunde liegende Rechenkapazität bestimmen, können Sie für die BigQuery-Nutzung abhängig von der Anzahl der benötigten Slots (statt der verarbeiteten Byte) bezahlen. Standardmäßig sind alleGoogle Cloud -Projekte auf maximal 2.000 Slots beschränkt. BigQuery kann dieses Limit überschreiten, um Ihre Abfragen zu beschleunigen, ein Bursting ist jedoch nicht garantiert.
- Kapazitätsbasierte Preise: Bei kapazitätsbasierten Preisen erwerben Sie BigQuery-Slot-Reservierungen (mindestens 100), statt für die Byte zu bezahlen, die von ausgeführten Abfragen verarbeitet werden. Wir empfehlen kapazitätsbasierte für Data-Warehouse-Arbeitslasten in Unternehmen, bei denen häufig viele Abfragen für gleichzeitige Berichterstellung und ELT (Extract-Load-Transform) vorliegen, die eine vorhersehbare Nutzung haben.
Um die Slot-Schätzung zu unterstützen, empfehlen wir die Einrichtung von BigQuery-Monitoring mit Cloud Monitoring und die Analyse Ihrer Audit-Logs mit BigQuery. Sie können Looker Studio (hier ein Open-Source-Beispiel für ein Looker Studio-Dashboard) oder Looker verwenden, um die Audit-Logdaten von BigQuery zu visualisieren, insbesondere für die Slot-Nutzung in Abfragen und Projekten. Außerdem können Sie die Systemtabellendaten von BigQuery verwenden, um die Slot-Auslastung für Jobs und Reservierungen zu überwachen. Hier finden Sie ein Open-Source-Beispiel für ein Looker Studio-Dashboard. Durch regelmäßiges Monitoring und Analyse der Slot-Auslastung können Sie abschätzen, wie viele Slots Ihr Unternehmen benötigt, während Sie in Google Cloudwachsen.
Beispiel: Sie reservieren anfangs 4.000 BigQuery-Slots, um 100 Abfragen mit mittlerer Komplexität gleichzeitig auszuführen. Wenn Sie in den Ausführungsplänen Ihrer Abfragen hohe Wartezeiten feststellen und Ihre Dashboards eine hohe Slot-Auslastung zeigen, kann dies darauf hindeuten, dass Sie zusätzliche BigQuery-Slots benötigen, um Ihre Arbeitslasten zu unterstützen. Wenn Sie Slots selbst über jährliche oder dreijährige Zusicherungen erwerben möchten, können Sie über dieGoogle Cloud -Konsole oder das bq-Befehlszeilentool mit BigQuery-Reservierungen beginnen. Weitere Informationen zur Arbeitslastverwaltung, zur Abfrageausführung und zur BigQuery-Architektur finden Sie unter Migration zuGoogle Cloud: Ausführliche Ansicht.
Sicherheit in Google Cloud
In den folgenden Abschnitten werden allgemeine Amazon Redshift-Sicherheitskontrollen beschrieben und wie Sie dafür sorgen können, dass Ihr Data Warehouse in einerGoogle Cloud -Umgebung geschützt ist.
Identitäts- und Zugriffsverwaltung
Das Einrichten von Zugriffssteuerungen in Amazon Redshift umfasst das Schreiben von Amazon Redshift API-Berechtigungsrichtlinien und das Anhängen von Identitäten an Identity and Access Management (IAM). Die Amazon Redshift API-Berechtigungen ermöglichen Zugriff auf Clusterebene, bieten jedoch keine detaillierteren Zugriffsebenen als der Cluster. Wenn Sie einen detaillierteren Zugriff auf Ressourcen wie Tabellen oder Ansichten benötigen, können Sie Nutzerkonten in der Amazon Redshift-Datenbank verwenden.
BigQuery verwendet IAM, um den Zugriff auf Ressourcen detaillierter zu verwalten. In BigQuery stehen folgende Ressourcentypen zur Verfügung: Organisationen, Projekte, Datasets, Tabellen, Spalten und Ansichten. In der Richtlinienhierarchie von IAM sind die Datasets die untergeordneten Ressourcen von Projekten. Eine Tabelle übernimmt die Berechtigungen des Datasets, das sie enthält.
Weisen Sie einem Nutzer, einer Gruppe oder einem Dienstkonto mindestens eine Rolle zu, wenn Sie Zugriff auf eine Ressource gewähren möchten. Die Rollen "Organisation" und "Projekt" wirken sich auf die Fähigkeit zum Ausführen von Jobs aus. Die Rolle "Dataset" wiederum wirkt sich auf die Fähigkeit aus, auf die Daten in einem Projekt zuzugreifen oder sie zu bearbeiten.
IAM bietet folgende Rollentypen:
- Vordefinierte Rollen sollen allgemeine Anwendungsfälle und Zugriffskontrollmuster unterstützen.
- Benutzerdefinierte Rollen, die detaillierten Zugriff gemäß einer vom Nutzer angegebenen Liste von Berechtigungen ermöglichen
Innerhalb von IAM bietet BigQuery die Zugriffssteuerung auf Tabellenebene. Berechtigungen auf Tabellenebene bestimmen, welche Nutzer, Gruppen und Dienstkonten auf eine Tabelle oder Ansicht zugreifen können. Sie können einem Nutzer Zugriff auf bestimmte Tabellen oder Ansichten geben, ohne dadurch Zugriff auf das gesamte Dataset zu gewähren. Für einen detaillierteren Zugriff können Sie auch einen oder mehrere der folgenden Sicherheitsmechanismen implementieren:
- Die Zugriffssteuerung auf Spaltenebene ermöglicht einen differenzierten Zugriff auf sensible Spalten mithilfe von Richtlinien-Tags oder der typbasierten Klassifizierung von Daten.
- Mit der dynamischen Datenmaskierung auf Spaltenebene können Sie Spaltendaten selektiv für Nutzergruppen ausblenden und gleichzeitig den Zugriff auf die Spalte zulassen.
- Mit der Sicherheit auf Zeilenebene können Sie Daten filtern und den Zugriff auf bestimmte Zeilen in einer Tabelle anhand bestimmter Nutzerbedingungen ermöglichen.
Festplattenverschlüsselung
Neben der Identitäts- und Zugriffsverwaltung bietet die Datenverschlüsselung eine zusätzliche Verteidigungsschicht zum Schutz von Daten. Im Fall der Datenweitergabe sind verschlüsselte Daten nicht lesbar.
Bei Amazon Redshift ist die Verschlüsselung sowohl für inaktive Daten als auch für Daten bei der Übertragung nicht standardmäßig aktiviert. Die Verschlüsselung inaktiver Daten muss explizit aktiviert werden, wenn ein Cluster gestartet wird. Sie können auch einen vorhandenen Cluster ändern, um die Verschlüsselung des AWS Key Management Service zu verwenden. Die Verschlüsselung von Daten bei der Übertragung muss ebenfalls explizit aktiviert werden.
BigQuery verschlüsselt standardmäßig alle inaktiven und übertragenen Daten unabhängig von der Quelle oder einer anderen Bedingung. Dies kann nicht deaktiviert werden. BigQuery unterstützt auch vom Kunden verwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Keys, CMEK), wenn Sie Schlüsselverschlüsselungsschlüssel im Cloud Key Management Service steuern und verwalten möchten.
Weitere Informationen zur Verschlüsselung in Google Cloudfinden Sie in den Whitepapers zur Verschlüsselung inaktiver Daten und zur Verschlüsselung aktiver Daten.
Bei Daten bei der Übertragung in Google Cloud werden Daten verschlüsselt und authentifiziert, wenn sie außerhalb der physischen Grenzen übertragen werden, die von Google oder im Auftrag von Google kontrolliert werden. Innerhalb dieser Grenzen werden Daten bei der Übertragung im Allgemeinen authentifiziert, aber nicht unbedingt verschlüsselt.
Schutz vor Datenverlust
Compliance-Anforderungen können einschränken, welche Daten inGoogle Cloudgespeichert werden können. Mit dem Schutz sensibler Daten können Sie BigQuery-Tabellen scannen, um sensible Daten zu erkennen und zu klassifizieren. Wenn sensible Daten erkannt werden, können diese Daten durch Transformationen zur De-Identifikation im Rahmen des Schutzes sensibler Daten maskiert, gelöscht oder anderweitig verschleiert werden.
Migration zu Google Cloud: Grundlagen
In diesem Abschnitt erfahren Sie mehr über die Verwendung von Tools und Pipelines bei der Migration.
Migrationstools
BigQuery Data Transfer Service bietet ein automatisiertes Tool, mit dem Sie sowohl Schemas als auch Daten direkt von Amazon Redshift zu BigQuery migrieren können. In der folgenden Tabelle sind zusätzliche Tools für die Migration von Amazon Redshift zu BigQuery aufgeführt:
| Tool | Zweck |
|---|---|
| BigQuery Data Transfer Service | Führen Sie mit diesem vollständig verwalteten Dienst eine automatische Batchübertragung Ihrer Amazon Redshift-Daten zu BigQuery durch. |
| Storage Transfer Service | Importieren Sie Amazon S3-Daten schnell in Cloud Storage und richten Sie mit diesem vollständig verwalteten Dienst einen sich wiederholenden Zeitplan für die Datenübertragung ein. |
gcloud |
Kopieren Sie mithilfe dieses Befehlszeilentools Amazon S3-Dateien in Cloud Storage. |
| bq-Befehlszeilentool, also: Befehlszeilentool "bq" | Über dieses Befehlszeilentool können Sie mit BigQuery interagieren. Zu den gängigen Interaktionen gehören das Erstellen von BigQuery-Tabellenschemas, das Laden von Cloud Storage-Daten in Tabellen und das Ausführen von Abfragen. |
| Cloud Storage-Clientbibliotheken | Kopieren Sie Amazon S3-Dateien in Cloud Storage. Verwenden Sie dazu Ihr benutzerdefiniertes Tool, das auf der Cloud Storage-Clientbibliothek basiert. |
| BigQuery-Clientbibliotheken | Nutzen Sie Ihr benutzerdefiniertes Tool für die Interaktion mit BigQuery, das auf der BigQuery-Clientbibliothek basiert. |
| BigQuery-Abfrageplaner | Wiederkehrende SQL-Abfragen mit dieser integrierten BigQuery-Funktion planen |
| Cloud Composer | Transformationen und BigQuery-Ladejobs mithilfe dieser vollständig verwalteten Apache Airflow-Umgebung orchestrieren |
| Apache Sqoop | Senden Sie Hadoop-Jobs mit Sqoop und dem JDBC-Treiber von Amazon Redshift, um Daten aus Amazon Redshift in HDFS oder Cloud Storage zu extrahieren. Sqoop wird in einer Dataproc-Umgebung ausgeführt. |
Weitere Informationen zur Verwendung des BigQuery Data Transfer Service finden Sie unter Schema und Daten von Amazon Redshift migrieren.
Migration mithilfe von Pipelines
Ihre Datenmigration von Amazon Redshift zu BigQuery kann je nach den verfügbaren Migrationstools unterschiedliche Pfade verwenden. Die Liste in diesem Abschnitt ist nicht vollständig. Sie bietet aber einen Einblick in die verschiedenen Datenpipelinemuster, die beim Verschieben der Daten verfügbar sind.
Allgemeine Informationen zum Migrieren von Daten zu BigQuery mithilfe von Pipelines finden Sie unter Datenpipelines migrieren.
Extrahieren und Laden (EL)
Sie können eine EL-Pipeline mit BigQuery Data Transfer Service vollständig automatisieren, die automatisch die Schemas und Daten Ihrer Tabellen aus Ihrem Amazon Redshift-Cluster in BigQuery kopieren kann. Wenn Sie mehr Kontrolle über die Schritte Ihrer Datenpipeline haben möchten, können Sie eine Pipeline mit den in den folgenden Abschnitten beschriebenen Optionen erstellen.
Amazon Redshift-Dateiextraktion verwenden
- Export von Amazon Redshift-Daten nach Amazon S3
Kopieren Sie mit den folgenden Optionen Daten aus Amazon S3 in Cloud Storage:
Laden Sie Cloud Storage-Daten mit einer der folgenden Optionen in BigQuery:
Amazon Redshift JDBC-Verbindung verwenden
Verwenden Sie eines der folgenden Google Cloud -Produkte, um Amazon Redshift-Daten mit dem Amazon Redshift-JDBC-Treiber zu exportieren:
-
- Von Google bereitgestellte Vorlage: JDBC für BigQuery
-
Verbindung zu Amazon Redshift über JDBC mit Apache Spark herstellen
Verwenden Sie Sqoop und den Amazon Redshift JDBC-Treiber, um Daten von Amazon Redshift in Cloud Storage zu extrahieren
Extrahieren, Transformieren und Laden (ETL)
Folgen Sie den Empfehlungen für die Pipeline, die im Abschnitt Extrahieren und Laden (EL) beschrieben sind, wenn Sie einige Daten transformieren möchten, bevor Sie sie in BigQuery laden, und fügen Sie einen zusätzlichen Schritt zum Transformieren der Daten vor dem Laden in BigQuery hinzu.
Amazon Redshift-Dateiextraktion verwenden
Kopieren Sie mit den folgenden Optionen Daten aus Amazon S3 in Cloud Storage:
Transformieren Sie Ihre Daten und laden Sie sie anschließend in BigQuery mit einer der folgenden Optionen:
-
- Aus Cloud Storage lesen
- In BigQuery schreiben
- Von Google bereitgestellte Vorlage: Cloud Storage-Text nach BigQuery
Amazon Redshift JDBC-Verbindung verwenden
Verwenden Sie eines der im Abschnitt Extrahieren und Laden (EL) beschriebenen Produkte und fügen Sie einen zusätzlichen Schritt hinzu, um Ihre Daten vor dem Laden in BigQuery zu transformieren. Ändern Sie die Pipeline, um einen oder mehrere Schritte zum Transformieren der Daten vor dem Schreiben in BigQuery einzuführen.
-
- Klonen Sie den Vorlagencode zum JDBC für BigQuery und ändern Sie die Vorlage, um Apache Beam-Transformationen hinzuzufügen.
-
- Daten mit einem der CDAP-Plug-ins transformieren
Extrahieren, Laden und Transformieren (ELT)
Sie können Ihre Daten mit BigQuery selbst transformieren, indem Sie sie mit der Option Extrahieren und Laden (EL) in eine Staging-Tabelle laden. Anschließend transformieren Sie die Daten in dieser Staging-Tabelle mithilfe von SQL-Abfragen, die ihre Ausgabe in Ihre endgültige Produktionstabelle schreiben.
Change Data Capture (CDC)
Change Data Capture (CDC) ist eines von mehreren Softwaredesignmustern zum Verfolgen von Datenänderungen. Es wird häufig im Data-Warehouse-Prozess verwendet, da mit dem Data Warehouse Daten und deren Änderungen aus verschiedenen Quellsystemen über einen bestimmten Zeitraum sortiert und verfolgt werden.
Partnertools für die Datenmigration
Im ETL-Bereich (Extract, Transform and Load) gibt es mehrere Anbieter. Auf der BigQuery-Partnerwebsite finden Sie eine Liste der wichtigsten Partner und ihrer verfügbaren Lösungen.
Migration zu Google Cloud: Ausführliche Ansicht
In diesem Abschnitt erfahren Sie, wie sich die Data-Warehouse-Architektur, das Schema und der SQL-Dialekt auf die Migration auswirken.
Architekturvergleich
Sowohl BigQuery als auch Amazon Redshift basieren auf einer massiv parallelen Verarbeitungsarchitektur (MPP). Abfragen werden auf mehrere Server verteilt, um die Ausführung zu beschleunigen. In Bezug auf die Systemarchitektur unterscheiden sich Amazon Redshift und BigQuery hauptsächlich darin, wie Daten gespeichert und wie Abfragen ausgeführt werden. In BigQuery werden die zugrunde liegenden Hardware und Konfigurationen abstrahiert. Dank des Speichers und der Rechenleistung kann Ihr Data Warehouse ohne Eingriff wachsen.
Computing, Arbeitsspeicher und Speicher
In Amazon Redshift sind CPU, Arbeitsspeicher und Laufwerksspeicher über Rechenknoten miteinander verknüpft, wie in diesem Diagramm aus der Amazon Redshift-Dokumentation gezeigt. Clusterleistung und Speicherkapazität werden durch den Typ und die Anzahl der Compute-Knoten bestimmt, die beide konfiguriert werden müssen. Um den Rechen- oder Speicherbedarf zu ändern, müssen Sie die Größe des Clusters über einen Prozess anpassen, der einige Stunden oder zwei Tage oder länger dauern kann und der einen ganz neuen Cluster erstellt und die Daten dorthin kopiert. Amazon Redshift bietet außerdem RA3-Knoten mit verwaltetem Speicher, die Computing und Speicherung voneinander trennen. Der größte Knoten in der RA3-Kategorie hat eine Obergrenze von 64 TB an verwaltetem Speicher für jeden Knoten.
Von Anfang an verknüpft BigQuery nicht die Rechen-, Arbeitsspeicher- und Speicherressourcen, sondern behandelt stattdessen jede separat.
BigQuery-Computing wird durch Slots definiert, eine Rechenkapazitätseinheit, die zum Ausführen von Abfragen erforderlich ist. Google verwaltet die gesamte Infrastruktur, die ein Slot umschließt, sodass Sie nur die richtige Slotmenge für Ihre BigQuery-Arbeitslasten auswählen müssen. Informationen zur Entscheidung, wie viele Slots Sie für Ihr Data Warehouse erwerben, finden Sie in der Kapazitätsplanung. Der BigQuery-Speicher wird von einem verteilten Remote-Dienst bereitgestellt, der über das Petabit-Netzwerk von Google mit Compute-Slots verbunden ist und alle von Google verwaltet werden.
BigQuery und Amazon Redshift verwenden beide den spaltenorientierten Speicher, aber BigQuery nutzt Varianten und Verbesserungen für den spaltenorientierten Speicher. Während die Spalten codiert sind, werden verschiedene Statistiken zu den Daten beibehalten und später während der Abfrageausführung verwendet, um optimale Pläne zu kompilieren und den effizientesten Laufzeitalgorithmus auszuwählen. BigQuery speichert Ihre Daten im verteilten Dateisystem von Google, wo sie automatisch komprimiert, verschlüsselt, repliziert und verteilt werden. Dies wird erreicht, ohne dass die für Ihre Abfragen verfügbare Rechenleistung beeinträchtigt wird. Durch die Trennung von Speicher und Computing können Sie bis zu Dutzende Petabyte an Speicher nahtlos skalieren, ohne dass zusätzliche teure Rechenressourcen erforderlich sind. Es gibt noch eine Reihe anderer Vorteile der Trennung von Computing und Speicher.
Hoch- oder Herunterskalieren
Wenn der Speicher oder die Rechenleistung eingeschränkt wird, müssen Sie die Größe von Amazon Redshift-Clustern anpassen, indem Sie die Anzahl oder Typen der Knoten im Cluster ändern.
Wenn Sie die Größe eines Amazon Redshift-Clusters ändern, gibt es zwei Ansätze:
- Klassische Größe: Amazon Redshift erstellt einen Cluster, in den die Daten kopiert werden. Dieser Vorgang kann einige Stunden oder bis zu zwei Tage oder länger für große Datenmengen dauern.
- Elastische Größenänderung: Wenn Sie nur die Anzahl der Knoten ändern, werden Abfragen vorübergehend pausiert und Verbindungen nach Möglichkeit offen gehalten. Während der Größenänderung ist der Cluster schreibgeschützt. Die elastische Größenänderung dauert normalerweise 10 bis 15 Minuten, ist jedoch möglicherweise nicht für alle Konfigurationen verfügbar.
Da BigQuery ein PaaS-Dienst (Platform as a Service) ist, müssen Sie sich nur um die Anzahl der BigQuery-Slots kümmern, die Sie für Ihre Organisation reservieren möchten. Sie reservieren BigQuery-Slots in Reservierungen und weisen diesen Reservierungen dann Projekte zu. Informationen zum Einrichten dieser Reservierungen finden Sie unter Kapazitätsplanung.
Ausführung von Abfragen
Die Ausführungs-Engine von BigQuery ähnelt der von Amazon Redshift, wobei beide Ihre Abfrage orchestrieren, indem sie in Schritte (einen Abfrageplan) unterteilt, die Schritte (nach Möglichkeit gleichzeitig) ausgeführt und dann wieder zusammengesetzt werden. Amazon Redshift generiert einen statischen Abfrageplan, BigQuery jedoch nicht, da es Abfragepläne dynamisch optimiert, wenn Ihre Abfrage ausgeführt wird. BigQuery verteilt Daten mit dem Remote-Speicherdienst, während Amazon Redshift Daten mithilfe des lokalen Compute-Knotenspeichers nach dem Zufallsprinzip sortiert. Weitere Informationen zum Speichern von Zwischendaten in BigQuery aus verschiedenen Phasen Ihres Abfrageplans finden Sie unter In-Memory-Abfrageausführung in Google BigQuery.
Arbeitslastverwaltung in BigQuery
BigQuery bietet die folgenden Steuerelemente für die Arbeitslastverwaltung (WLM):
- Interaktive Abfragen, die so schnell wie möglich ausgeführt werden (Standardeinstellung).
- Batchabfragen, die in Ihrem Namen in die Warteschlange gestellt werden, werden gestartet, sobald inaktive Ressourcen im freigegebenen BigQuery-Ressourcenpool verfügbar sind.
Slot-Reservierungen über kapazitätsbasierte Preise. Anstatt für Abfragen nach Bedarf zu bezahlen, können Sie Buckets mit Slots, die als Reservierungen bezeichnet werden, dynamisch erstellen und verwalten und dann Projekte, Ordner oder Organisationen für diese Reservierungen zuweisen. Sie können Zusicherungen für BigQuery-Slots (mindestens 100) in flexiblen, monatlichen oder jährlichen Zusicherungen erwerben, um die Kosten zu minimieren. Standardmäßig verwenden Abfragen, die in einer Reservierung ausgeführt werden, inaktive Slots aus anderen Reservierungen automatisch.
Wie das folgende Diagramm zeigt, haben Sie eine Gesamt-Kapazität von 1.000 Slots für drei Arbeitslasttypen erworben: Data Science, ELT und Business Intelligence (BI). Zur Unterstützung dieser Arbeitslasten können Sie die folgenden Reservierungen erstellen:
- Sie können die Reservierung ds mit 500 Slots erstellen und dieser Reservierung alleGoogle Cloud Data Science-Projekte zuweisen.
- Sie können die Reservierung elt mit 300 Slots erstellen und die Projekte, die Sie für ELT-Arbeitslasten verwenden, dieser Reservierung zuweisen.
- Sie können die Reservierung bi mit 200 Slots erstellen und Projekte, die mit Ihren BI-Tools verknüpft sind, dieser Reservierung zuweisen.
Diese Konfiguration wird im folgenden Diagramm dargestellt:
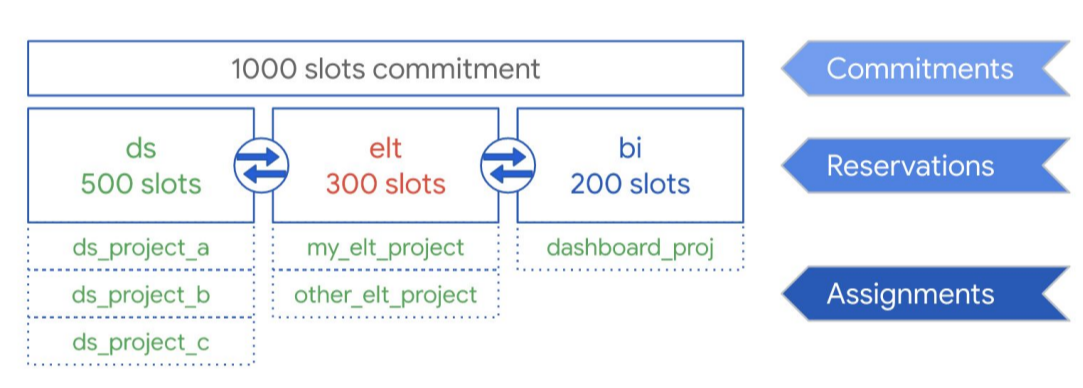
Anstatt Reservierungen an die Arbeitslasten Ihrer Organisation zu verteilen, z. B. an Produktion und Tests, können Sie je nach Anwendungsfall Reservierungen einzelnen Teams oder Abteilungen zuweisen.
Weitere Informationen finden Sie unter Arbeitslastverwaltung mit Reservierungen.
Arbeitslastverwaltung in Amazon Redshift
Amazon Redshift bietet zwei Arten von Arbeitslastverwaltung (WLM):
- Automatisch: Mit der automatischen WLM verwaltet Amazon Redshift die Gleichzeitigkeit von Abfragen und die Arbeitsspeicherzuordnung. Es werden bis zu acht Warteschlangen mit den Dienstklassenkennungen 100–107 erstellt. Der automatische WLM bestimmt die Menge der benötigten Ressourcen und passt die Gleichzeitigkeit entsprechend der Arbeitslast an. Weitere Informationen finden Sie unter Abfragepriorität.
- Manuell: Bei der manuellen WLM müssen Sie dagegen Werte für die Gleichzeitigkeit von Abfragen und die Speicherzuordnung angeben. Der Standardwert für manuelles WLM ist die Gleichzeitigkeit von fünf Abfragen. Der Arbeitsspeicher wird gleichmäßig auf alle fünf aufgeteilt.
Wenn die Gleichzeitigkeitsskalierung aktiviert ist, fügt Amazon Redshift automatisch zusätzliche Clusterkapazität hinzu, wenn Sie diese zur Verarbeitung einer Zunahme gleichzeitiger Leseabfragen benötigen. Bei der Gleichzeitigkeitsskalierung gibt es bestimmte regionale und Abfrageaspekte. Weitere Informationen finden Sie unter Kandidaten für die Gleichzeitigkeitsskalierung.
Dataset- und Tabellenkonfigurationen
BigQuery bietet eine Reihe von Möglichkeiten, um Ihre Daten und Tabellen zu konfigurieren, z. B. Partitionierung, Clustering und Datenlokalität. Diese Konfigurationen können große Tabellen verwalten und die Gesamtdatenlast und die Antwortzeit für Ihre Abfragen reduzieren, wodurch die operative Effizienz Ihrer Datenarbeitslasten erhöht wird.
Partitionierung
Bei der Tabellenpartitionierung werden die Tabellendaten in Segmente unterteilt, die als Partitionen bezeichnet werden. Die Daten einer partitionierten Tabelle lassen sich einfacher verwalten und abfragen. Nutzer teilen im Allgemeinen große Tabellen in viele kleinere Partitionen auf, wobei jede Partition die Daten eines Tages enthält. Die Partitionsverwaltung ist eine wichtige Abhängigkeit von der Leistung und Kosten von BigQuery, wenn Abfragen über einen bestimmten Zeitraum erfolgen, da BigQuery weniger Daten pro Abfrage scannen kann.
In BigQuery gibt es drei Arten der Tabellenpartitionierung:
- Nach Aufnahmezeit partitionierte Tabellen: Tabellen werden basierend auf der Aufnahmezeit der Daten partitioniert.
- Nach Spalte partitionierte Tabellen: Tabellen werden basierend auf der Spalte
TIMESTAMPoderDATEpartitioniert. - Nach Ganzzahlbereich partitionierte Tabellen: Tabellen werden nach einer Spalte mit Ganzzahlen partitioniert.
Eine spaltenbasierte, zeitpartitionierte Tabelle macht es überflüssig, das Partitionsbewusstsein unabhängig von der vorhandenen Datenfilterung in der gebundenen Spalte zu aufrechterhalten. Anhand des Werts der Daten werden Daten, die in eine spaltenbasierte, zeitpartitionierte Tabelle geschrieben werden, automatisch an die entsprechende Partition gesendet. Ebenso können Abfragen, die Filter für die Partitionierungsspalte angeben, die gescannten Gesamtdaten reduzieren, was zu einer verbesserten Leistung und geringeren Abfragekosten für On-Demand-Abfragen führen kann.
Die spaltenbasierte Partitionierung in BigQuery ähnelt der spaltenbasierten Partitionierung von Amazon Redshift mit einer etwas anderen Motivation. Amazon Redshift verwendet die spaltenbasierte Schlüsselverteilung, um verwandte Daten innerhalb desselben Compute-Knotens zu speichern, wodurch das Shuffling während Joins und Aggregationen letztendlich minimiert wird. BigQuery trennt den Speicher von der Rechenleistung, sodass die spaltenbasierte Partitionierung verwendet wird, um die Datenmenge zu minimieren, die Slots vom Laufwerk liest.
Sobald Slot-Worker ihre Daten von der Festplatte lesen, kann BigQuery die optimale Datenfragmentierung automatisch ermitteln und Daten mithilfe des speicherinternen Shuffle-Dienstes von BigQuery schnell neu partitionieren.
Weitere Informationen finden Sie unter Einführung in partitionierte Tabellen.
Clustering und Sortierschlüssel
Amazon Redshift unterstützt die Angabe von Tabellenspalten als komplexe oder verschränkte Sortierschlüssel. In BigQuery können Sie kumulierende Sortierschlüssel angeben, indem Sie Ihre Tabelle clustern. Geclusterte Tabellen verbessern die Abfrageleistung, da die Tabellendaten automatisch basierend auf dem Inhalt von bis zu vier Spalten sortiert werden, die im Schema der Tabelle angegeben sind. Diese Spalten werden verwendet, um verwandte Daten zu platzieren. Die von Ihnen angegebene Reihenfolge der Clustering-Spalten ist wichtig, da sie die Sortierreihenfolge der Daten bestimmt.
Clustering kann die Leistung bestimmter Abfragetypen verbessern, z. B. Abfragen, die Filterklauseln verwenden, und Abfragen, die Daten aggregieren. Wenn Daten von einem Abfrage- oder Ladejob in eine geclusterte Tabelle geschrieben werden, sortiert BigQuery die Daten anhand der Werte in den Clustering-Spalten automatisch. Mithilfe dieser Werte werden die Daten in mehreren Blöcken im BigQuery-Speicher organisiert. Wenn Sie eine Abfrage mit einer Klausel senden, die Daten basierend auf den Clustering-Spalten filtert, verwendet BigQuery die sortierten Blöcke, um Scans unnötiger Daten zu vermeiden.
Wenn Sie eine Abfrage senden, die Daten anhand der Werte in den Clustering-Spalten aggregiert, wird die Leistung verbessert, da die sortierten Blöcke für eine Zusammenstellung von Zeilen mit ähnlichen Werten sorgen.
Verwenden Sie Clustering in folgenden Fällen:
- In Ihren Redshift-Tabellen werden komplexe Sortierschlüssel konfiguriert.
- Das Filtern oder Aggregieren wird für bestimmte Spalten in den Abfragen konfiguriert.
Wenn Sie Clustering und Partitionierung zusammen verwenden, können Ihre Daten nach einer Datums-, Zeitstempel- oder Ganzzahlspalte partitioniert und dann in einer anderen Gruppe von Spalten geclustert werden (bis zu vier geclusterte Spalten insgesamt). In diesem Fall werden Daten in den einzelnen Partitionen anhand der Werte der Clustering-Spalten geclustert.
Wenn Sie Sortierschlüssel in Tabellen in Amazon Redshift angeben, abhängig von der Systemlast, führt Amazon Redshift die Sortierung automatisch mit der Rechenkapazität Ihres eigenen Clusters ein. Möglicherweise müssen Sie den Befehl VACUUM manuell ausführen, wenn Sie Ihre Tabellendaten so schnell wie möglich vollständig sortieren möchten, z. B. nach einer großen Datenmenge Laden. BigQuery sortiert diese Sortierung automatisch und verwendet nicht Ihre zugewiesenen BigQuery-Slots, sodass sich die Leistung Ihrer Abfragen nicht beeinträchtigt.
Weitere Informationen zur Arbeit mit geclusterten Tabellen finden Sie unter Einführung in geclusterte Tabellen.
Verteilungsschlüssel
Amazon Redshift verwendet Verteilungsschlüssel, um den Speicherort von Datenblöcken für die Ausführung seiner Abfragen zu optimieren. BigQuery verwendet keine Verteilungsschlüssel, da es automatisch Phasen in einem Abfrageplan ermittelt und hinzufügt, während die Abfrage ausgeführt wird, um die Datenverteilung auf die Worker der Abfrage zu verbessern.
Externe Quellen
Wenn Sie Amazon Redshift Spectrum zum Abfragen von Daten in Amazon S3 verwenden, können Sie das externe Datenquellen-Feature von BigQuery verwenden, um Daten direkt aus Dateien auf Cloud Storage abzufragen.
Zusätzlich zum Abfragen von Daten in Cloud Storage bietet BigQuery föderierte Abfragefunktionen zum direkten Abfragen von den folgenden Produkten:
- Cloud SQL (vollständig verwaltet MySQL oder PostgreSQL)
- Bigtable (vollständig verwaltetes NoSQL)
- Google Drive (CSV, JSON, Avro, Tabellen)
Datenlokalität
Sie können BigQuery-Datasets sowohl an regionalen als auch an multiregionalen Standorten erstellen, während Amazon Redshift nur regionale Standorte bietet. BigQuery bestimmt anhand der in der Anfrage referenzierten Datasets, wo die Lade-, Abfrage- oder Extraktionsjobs ausgeführt werden. Tipps zur Arbeit mit regionalen und multiregionalen Datasets finden Sie in den BigQuery-Standortüberlegungen.
Datentypzuordnung in BigQuery
Amazon Redshift-Datentypen unterscheiden sich von BigQuery-Datentypen. Weitere Informationen zu BigQuery-Datentypen finden Sie in der offiziellen Dokumentation.
BigQuery unterstützt auch die folgenden Datentypen, die kein direktes Amazon Redshift-Analog haben:
SQL-Vergleich
GoogleSQL ist mit dem SQL 2011-Standard kompatibel und bietet Erweiterungen, die die Abfrage verschachtelter und wiederholter Daten unterstützen. Amazon Redshift SQL basiert auf PostgreSQL, unterscheidet sich jedoch in einigen Fällen in der Amazon Redshift-Dokumentation. Einen detaillierten Vergleich zwischen der Syntax und den Funktionen von Amazon Redshift und GoogleSQL finden Sie im Amazon Redshift SQL-Übersetzungsleitfaden.
Mit dem Batch-SQL-Übersetzer können Sie Skripts und anderen SQL-Code von Ihrer aktuellen Plattform in BigQuery konvertieren.
Nach der Migration
Da Sie Skripts migriert haben, die nicht im Hinblick auf BigQuery entwickelt wurden, können Sie Techniken zur Optimierung der Abfrageleistung in BigQuery implementieren. Weitere Informationen finden Sie unter Einführung in die Optimierung der Abfrageleistung.
Nächste Schritte
- Schritt-für-Schritt-Anleitung zur Migration von Schemas und Daten von Amazon Redshift.
- Schritt-für-Schritt-Anleitung zum Migrieren von Amazon Redshift zu BigQuery mit VPC