Einführung in die Datenmaskierung
BigQuery unterstützt Datenmaskierung auf Spaltenebene. Sie können die Datenmaskierung nutzen, um Spaltendaten für Nutzergruppen selektiv zu verdecken und dennoch Zugriff auf die Spalte zuzulassen. Die Datenmaskierung basiert auf der Zugriffssteuerung auf Spaltenebene. Entsprechend sollten Sie sich mit dieser Funktion vertraut machen, bevor Sie fortfahren.
Wenn Sie die Datenmaskierung in Kombination mit der Zugriffssteuerung auf Spaltenebene verwenden, können Sie gemäß den Anforderungen verschiedener Nutzergruppen Zugriffsbereiche auf Spaltendaten konfigurieren, vom vollständigen bis zu keinem Zugriff. Bei Daten zu Steuernummern sollten Sie beispielsweise der Buchhaltung Zugriff auf die gesamte Analysegruppe, der Analystengruppe maskierten Zugriff und der Verkaufsgruppe keinen Zugriff gewähren.
Vorteile
Die Datenmaskierung bietet folgende Vorteile:
- Der Prozess der Datenweitergabe wird optimiert. Sie können sensible Spalten maskieren, um Tabellen mit größeren Gruppen zu teilen.
- Anders als bei der Zugriffssteuerung auf Spaltenebene müssen Sie bestehende Abfragen nicht durch den Ausschluss von Spalten, auf die Nutzer keinen Zugriff haben sollen, ändern. Wenn Sie die Datenmaskierung konfigurieren, maskieren vorhandene Abfragen Spaltendaten automatisch anhand der den Nutzern zugewiesenen Rollen.
- Sie können Richtlinien für den Datenzugriff in großem Maßstab anwenden. Sie können eine Datenrichtlinie schreiben, sie mit einem Richtlinien-Tag verknüpfen, und das Richtlinien-Tag dann auf eine beliebige Anzahl an Spalten anwenden.
- Das aktiviert die attributbasierte Zugriffssteuerung. Ein mit einer Spalte verknüpftes Richtlinien-Tag bietet kontextbezogenen Datenzugriff. Dieser wird durch die Datenrichtlinie und die Hauptkonten bestimmt, die mit diesem Richtlinien-Tag verknüpft sind.
Workflow zur Datenmaskierung
Es gibt zwei Möglichkeiten, Daten zu maskieren. Sie können eine Taxonomie und Richtlinien-Tags erstellen und dann Datenrichtlinien für die Richtlinien-Tags konfigurieren. Alternativ können Sie eine Datenrichtlinie direkt für eine Spalte in der Vorschau festlegen. So können Sie eine Datenmaskierungsregel Ihren Daten zuordnen, ohne Richtlinien-Tags zu verarbeiten oder zusätzliche Taxonomien zu erstellen.
Datenrichtlinie direkt für eine Spalte festlegen
Sie können die dynamische Datenmaskierung direkt für eine Spalte konfigurieren (Vorschau). Führen Sie dazu die folgenden Schritte aus:
Daten mit Richtlinien-Tags maskieren
Abbildung 1 zeigt den Workflow zum Konfigurieren der Datenmaskierung:
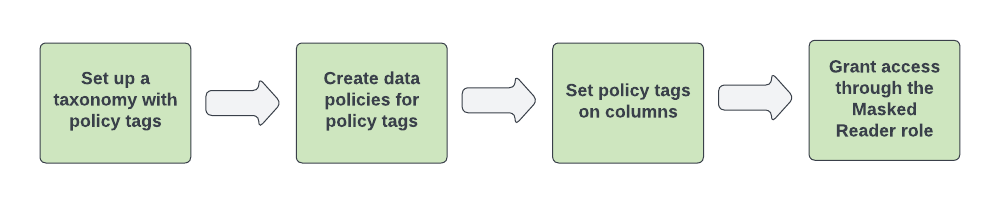 Abbildung 1. Komponenten der Datenmaskierung.
Abbildung 1. Komponenten der Datenmaskierung.
Zum Konfigurieren der Datenmaskierung führen Sie folgende Schritte aus:
- Richten Sie eine Taxonomie und ein oder mehrere Richtlinien-Tags ein.
Konfigurieren Sie Datenrichtlinien für die Richtlinien-Tags. Eine Datenrichtlinie ordnet dem Richtlinien-Tag eine Datenmaskierungsregel und ein oder mehrere Hauptkonten zu, die Nutzer oder Gruppen darstellen.
Wenn Sie mit der Google Cloud Console eine Datenrichtlinie erstellen, erstellen Sie in einem Schritt die Datenmaskierungsregel und geben die Hauptkonten an. Beim Erstellen einer Datenrichtlinie mit der BigQuery Data Policy API erstellen Sie im ersten Schritt die Datenrichtlinie und die Datenmaskierungsregel und geben die Hauptkonten für die Datenrichtlinie im zweiten Schritt an.
Weisen Sie die Richtlinien-Tags den Spalten in BigQuery-Tabellen zu, um die Datenrichtlinien anzuwenden.
Weisen Sie Nutzern, die Zugriff auf maskierte Daten haben sollen, die Rolle „BigQuery: Maskierter Leser“ zu. Weisen Sie als Best Practice die Rolle „Maskierter Leser“ auf Datenrichtlinienebene zu. Durch das Zuweisen der Rolle auf Projektebene oder höher werden Nutzern Berechtigungen für alle Datenrichtlinien unter dem Projekt erteilt. Dies kann zu Problemen bei übermäßigen Berechtigungen führen.
Das mit einer Datenrichtlinie verknüpfte Richtlinien-Tag kann auch für die Zugriffssteuerung auf Spaltenebene verwendet werden. In diesem Fall ist das Richtlinien-Tag auch mit einem oder mehreren Hauptkonten verknüpft, denen die Rolle "Data Catalog: Detaillierter Lesezugriff" zugewiesen ist. Dadurch können diese Hauptkonten auf die ursprünglichen, nicht maskierten Spaltendaten zugreifen.
Abbildung 2 zeigt, wie die Zugriffssteuerung auf Spaltenebene und die Datenmaskierung zusammenwirken:
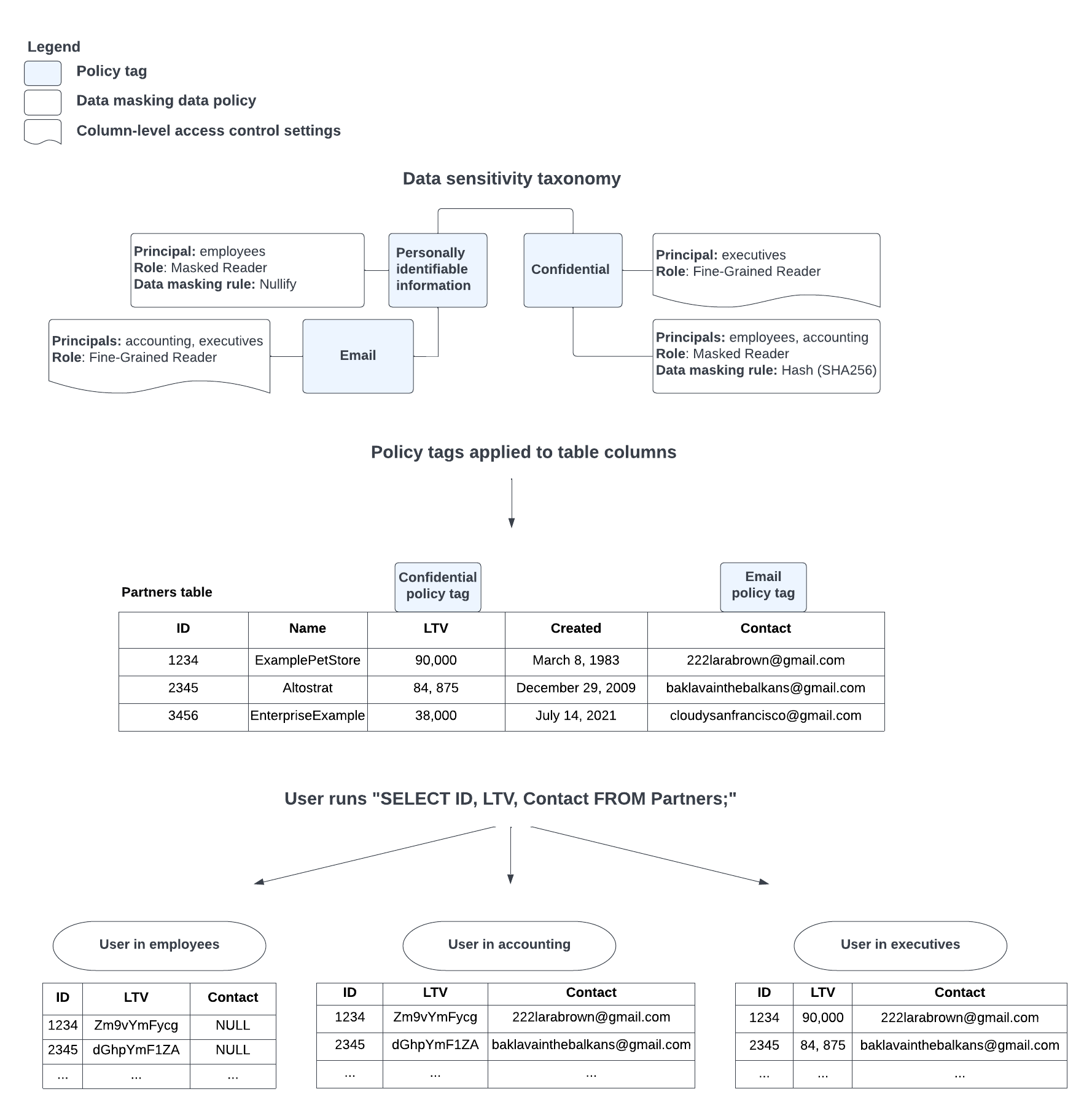 Abbildung 2. Komponenten der Datenmaskierung.
Abbildung 2. Komponenten der Datenmaskierung.
Weitere Informationen zur Rolleninteraktion finden Sie unter Interaktion der Rollen "Maskierter Leser" und "Detaillierter Lesezugriff". Weitere Informationen zur Übernahme von Richtlinien-Tags finden Sie unter Rollen und Hierarchie von Richtlinien-Tags.
Datenmaskierungsregeln
Wenn Sie die Datenmaskierung verwenden, wirdzur Abfragelaufzeit eine Datenmaskierungsregel basierend auf der Rolle des abfragenden Nutzers auf eine Spalte angewendet. Die Maskierung hat Vorrang vor allen anderen Vorgängen, die an der Abfrage beteiligt sind. Die Datenmaskierungsregel bestimmt den Typ der Datenmaskierung, die auf die Spaltendaten angewendet wird.
Sie können folgende Datenmaskierungsregeln verwenden:
Benutzerdefinierte Maskierungsroutine. Gibt den Wert der Spalte zurück, nachdem eine benutzerdefinierte Funktion (UDF) auf die Spalte angewendet wurde. Für die Verwaltung der Maskierungsregel sind Routineberechtigungen erforderlich. Diese Regel unterstützt standardmäßig alle BigQuery-Datentypen mit Ausnahme des Datentyps
STRUCT. Die Unterstützung anderer Datentypen alsSTRINGundBYTESist jedoch begrenzt. Die Ausgabe hängt von der definierten Funktion ab.Weitere Informationen zum Erstellen von benutzerdefinierten Funktionen für benutzerdefinierte Maskierungsroutinen finden Sie unter Benutzerdefinierte Maskierungsroutinen erstellen.
Datum-Jahr-Maske Gibt den Wert der Spalte zurück, nachdem der Wert für sein Jahr gekürzt wurde, wobei alle Nicht-Jahresteile des Werts auf den Beginn des Jahres festgelegt werden. Sie können diese Regel nur mit Spalten verwenden, die die Datentypen
DATE,DATETIMEundTIMESTAMPverwenden. Beispiel:Typ Original Maskiert DATE2030-07-17 2030-01-01 DATETIME2030-07-17T01:45:06 2030-01-01T00:00:00 TIMESTAMP2030-07-17 01:45:06 2030-01-01 00:00:00 Standardmaskierungswert. Gibt basierend auf dem Datentyp der Spalte einen Standardmaskierungswert für die Spalte zurück. Verwenden Sie diese Option, wenn Sie den Wert der Spalte ausblenden, den Datentyp aber anzeigen möchten. Wenn diese Datenmaskierungsregel auf eine Spalte angewendet wird, ist sie für
JOIN-Abfragevorgänge für Nutzer mit "Maskierter Leser"-Zugriff weniger nützlich. Dies liegt daran, dass ein Standardwert nicht ausreichend klar ist, um beim Zusammenführen von Tabellen nützlich zu sein.Die folgende Tabelle zeigt den Standardmaskierungswert pro Datentyp:
Datentyp Standardmaskierungswert STRING"" BYTESb'' INTEGER0 FLOAT0,0 NUMERIC0 BOOLEANFALSETIMESTAMP1970-01-01 00:00:00 UTC DATE1970-01-01 TIME00:00:00 DATETIME1970-01-01T00:00:00 GEOGRAPHYPOINT(0 0) BIGNUMERIC0 ARRAY[] STRUCTNOT_APPLICABLE
Richtlinien-Tags können nicht auf Spalten angewendet werden, die den Datentyp
STRUCTverwenden, können jedoch mit den Blattfeldern solcher Spalten verknüpft werden.JSONnull E-Mail-Maske. Gibt den Wert der Spalte zurück, nachdem der Nutzername einer gültigen E-Mail durch
XXXXXersetzt wurde. Wenn der Wert der Spalte keine gültige E-Mail-Adresse ist, wird der Wert der Spalte zurückgegeben, nachdem er über die Hash-Funktion SHA-256 ausgeführt wurde. Sie können diese Regel nur mit Spalten verwenden, die den DatentypSTRINGverwenden. Beispiel:Original Maskiert abc123@gmail.comXXXXX@gmail.comrandomtextjQHDyQuj7vJcveEe59ygb3Zcvj0B5FJINBzgM6Bypgw=test@gmail@gmail.comQdje6MO+GLwI0u+KyRyAICDjHbLF1ImxRqaW08tY52k=Die ersten vier Zeichen. Gibt die ersten vier Zeichen des Spaltenwerts zurück und ersetzt den Rest des Strings durch
XXXXX. Wenn der Wert der Spalte gleich oder kleiner als 4 Zeichen ist, wird der Wert der Spalte nach Ausführung der Hash-Funktion SHA-256 zurückgegeben. Sie können diese Regel nur mit Spalten verwenden, die den DatentypSTRINGverwenden.Hash (SHA-256). Gibt den Wert der Spalte zurück, nachdem er über die Hash-Funktion SHA-256 ausgeführt wurde. Verwenden Sie diese Option, wenn der Endnutzer diese Spalte in einem
JOIN-Vorgang für Abfragen verwenden können soll. Sie können diese Regel nur mit Spalten verwenden, die die DatentypenSTRINGoderBYTESverwenden.Die SHA-256-Funktion, die bei der Datenmaskierung verwendet wird, erhält den Typ bei, sodass der zurückgegebene Hashwert denselben Datentyp wie der Spaltenwert hat. Der Hashwert für einen
STRING-Spaltenwert hat beispielsweise auch den DatentypSTRING.Letzte vier Zeichen. Gibt die letzten vier Zeichen des Spaltenwerts zurück und ersetzt den Rest des Strings durch
XXXXX. Wenn der Wert der Spalte gleich oder kleiner als 4 Zeichen ist, wird der Wert der Spalte nach Ausführung der Hash-Funktion SHA-256 zurückgegeben. Sie können diese Regel nur mit Spalten verwenden, die den DatentypSTRINGverwenden.Auf null setzen. Gibt
NULLanstelle des Spaltenwerts zurück. Verwenden Sie diese Option, wenn Sie sowohl Wert als auch Datentyp der Spalte ausblenden möchten. Wenn diese Datenmaskierungsregel auf eine Spalte angewendet wird, ist sie fürJOIN-Abfragevorgänge für Nutzer mit "Maskierter Leser"-Zugriff weniger nützlich. Dies liegt daran, dass einNULL-Wert nicht ausreichend klar ist, um beim Zusammenführen von Tabellen nützlich zu sein.
Hierarchie der Datenmaskierungsregel
Sie können bis zu neun Datenrichtlinien für ein Richtlinien-Tag konfigurieren, wobei jeder eine andere Datenmaskierungsregel zugeordnet wird. Eine dieser Richtlinien ist für die Einstellungen für die Zugriffssteuerung auf Spaltenebene reserviert. Auf diese Weise können mehrere Datenrichtlinien basierend auf den Gruppen, in denen der Nutzer Mitglied ist, auf eine Spalte in der Nutzerabfrage angewendet werden. In diesem Fall wählt BigQuery anhand der folgenden Hierarchie aus, welche Datenmaskierungsregel angewendet werden soll:
- Benutzerdefinierte Maskierungsroutine
- Hash (SHA-256)
- E-Mail-Maske
- Letzte vier Zeichen
- Die ersten vier Zeichen
- Datum-Jahr-Maske
- Standardmaskierungswert
- Auf null setzen
Beispiel: Nutzer A ist sowohl ein Mitglied der Mitarbeiter- als auch der Buchhaltungsgruppen. Nutzer A führt eine Abfrage aus, die das sales_total-Feld enthält, auf das das Richtlinien-Tag confidential angewendet wurde. Dem Richtlinien-Tag confidential sind zwei Datenrichtlinien zugeordnet: eine hat die Mitarbeiterrolle als Hauptkonto und wendet die „Auf null setzen”-Regel zum Maskieren von Daten an, die andere hat die Abrechnungsrolle als Hauptkonto und wendet die Hash-Regel (SHA-256) zur Maskierung von Daten an. In diesem Fall wird die Hash-Datenmaskierungsregel (SHA-256) gegenüber der „Auf null setzen”-Datenmaskierungsregel priorisiert, sodass die Hash-Regel (SHA-256) in der Abfrage von Nutzer A auf den sales_total-Feldwert angewendet wird.
Abbildung 3 zeigt dieses Szenario:

Abbildung 3. Priorisierung von Datenmaskierungsregeln.
Rollen und Berechtigungen
Rollen zum Verwalten von Taxonomien und Richtlinien-Tags
Sie benötigen die Data Catalog-Rolle "Richtlinien-Tag-Administrator", um Taxonomien und Richtlinien-Tags zu erstellen und zu verwalten.
| Rolle/ID | Berechtigungen | Beschreibung |
|---|---|---|
Data Catalog-Richtlinien-Tag-Administrator/datacatalog.categoryAdmin
|
datacatalog.categories.getIamPolicydatacatalog.categories.setIamPolicydatacatalog.taxonomies.createdatacatalog.taxonomies.deletedatacatalog.taxonomies.getdatacatalog.taxonomies.getIamPolicydatacatalog.taxonomies.listdatacatalog.taxonomies.setIamPolicydatacatalog.taxonomies.updateresourcemanager.projects.getresourcemanager.projects.list
|
Gilt auf Projektebene. Diese Rolle berechtigt zu Folgendem:
|
Rollen zum Erstellen und Verwalten von Datenrichtlinien
Sie benötigen eine der folgenden BigQuery-Rollen, um Datenrichtlinien zu erstellen und zu verwalten:
| Rolle/ID | Berechtigungen | Beschreibung |
|---|---|---|
BigQuery-Datenrichtlinienadministrator/bigquerydatapolicy.admin BigQuery-Administrator/ bigquery.admin BigQuery-Dateninhaber/ bigquery.dataOwner
|
bigquery.dataPolicies.createbigquery.dataPolicies.deletebigquery.dataPolicies.getbigquery.dataPolicies.getIamPolicybigquery.dataPolicies.listbigquery.dataPolicies.setIamPolicybigquery.dataPolicies.update
|
Die Berechtigungen Diese Rolle berechtigt zu Folgendem:
|
datacatalog.taxonomies.get, die Sie von mehreren vordefinierten Rollen in Data Catalog erhalten können.
Rollen zum Anhängen von Richtlinien-Tags an Spalten
Sie benötigen die Berechtigungen datacatalog.taxonomies.get und bigquery.tables.setCategory, um Richtlinien-Tags an Spalten anzuhängen.
datacatalog.taxonomies.get ist in den Data Catalog-Richtlinien-Tags-Administrator- und Betrachterrollen enthalten.
bigquery.tables.setCategory ist in den Rollen "BigQuery-Administrator" (roles/bigquery.admin) und "BigQuery-Dateninhaber" (roles/bigquery.dataOwner) enthalten.
Rollen zum Abfragen maskierter Daten
Sie benötigen die Rolle "BigQuery: Maskierter Leser", um Daten aus einer Spalte abzufragen, in der die Datenmaskierung angewendet wurde.
| Rolle/ID | Berechtigungen | Beschreibung |
|---|---|---|
Maskierter Leser/bigquerydatapolicy.maskedReader
|
bigquery.dataPolicies.maskedGet |
Wird auf Datenrichtlinienebene angewandt. Diese Rolle ermöglicht die Anzeige der maskierten Daten einer Spalte, die mit einer Datenrichtlinie verknüpft ist. Darüber hinaus muss ein Nutzer die entsprechenden Berechtigungen zum Abfragen der Tabelle haben. Weitere Informationen finden Sie unter Erforderliche Berechtigungen. |
Interaktion der Rollen "Maskierter Leser" und "Detaillierter Lesezugriff"
Die Datenmaskierung basiert auf der Zugriffssteuerung auf Spaltenebene. Für eine bestimmte Spalte ist es möglich, dass einige Nutzer mit der Rolle "BigQuery: Maskierter Leser" maskierte Daten und andere Nutzer mit der Rolle "Data Catalog: Detaillierter Lesezugriff" nicht maskierte Daten lesen können, während wieder andere Nutzer beide oder keine dieser Optionen haben. Die Rollen interagieren so:
- Nutzer mit den Rollen "Detaillierter Lesezugriff" und "Maskierter Leser": Was der Nutzer sieht, hängt davon ab, wo in der Richtlinien-Tag-Hierarchie die jeweiligen Rollen zugewiesen wurden. Weitere Informationen finden Sie unter Autorisierungsübernahme in einer Richtlinien-Tag-Hierarchie.
- Nutzer mit der Rolle "Detaillierter Lesezugriff": Können nicht maskierte (nicht verdeckte) Spaltendaten sehen.
- Nutzer mit der Rolle "Maskierter Leser": Können maskierte (verdeckte) Spaltendaten sehen.
- Nutzer ohne Rolle: Berechtigung verweigert.
Wenn eine Tabelle gesicherte oder gesicherte und maskierte Spalten hat, muss ein Nutzer Mitglied der entsprechenden Gruppen sein, um eine SELECT * FROM-Anweisung für diese Tabelle ausführen zu können. Über diese Gruppen müssen die Rollen "Maskierter Leser" oder "Detaillierter Lesezugriff" für alle diese Spalten gewährt werden.
Nutzer, denen diese Rollen nicht zugewiesen sind, können stattdessen nur Spalten angeben, auf die sie über die SELECT-Anweisung Zugriff haben. Alternativ können sie SELECT * EXCEPT
(restricted_columns) FROM verwenden, um gesicherte oder maskierte Spalten auszuschließen.
Übernahme von Autorisierungen in einer Richtlinien-Tag-Hierarchie
Rollen werden ab dem Richtlinien-Tag ausgewertet, das mit einer Spalte verknüpft ist, und dann aufsteigend auf jeder folgenden Ebene der Taxonomie geprüft, bis klar wird, dass der Nutzer die entsprechenden Berechtigungen hat, oder bis das oberste Element des Richtlinien-Tag-Hierarchie erreicht wird.
Nehmen Sie zum Beispiel das Richtlinien-Tag und die Datenrichtlinienkonfiguration in Abbildung 4:
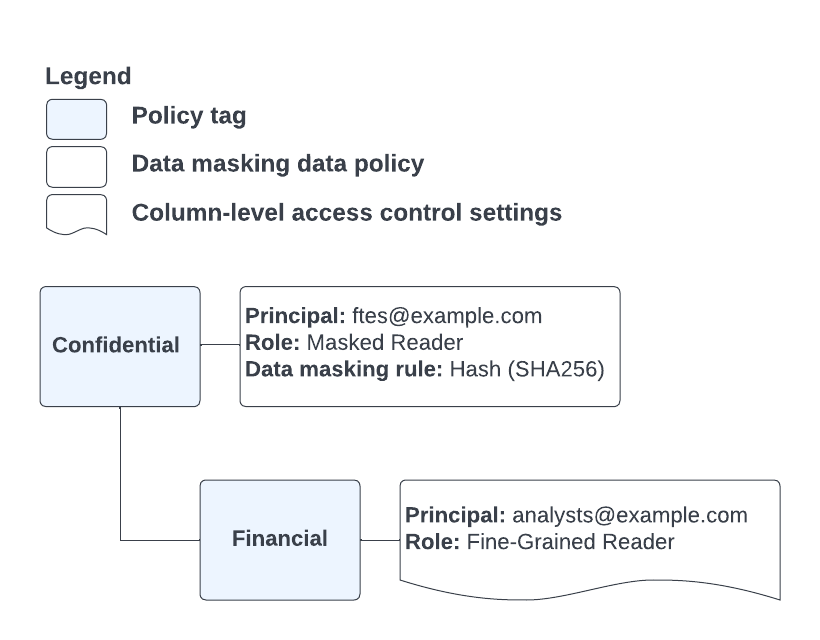
Abbildung 4. Konfiguration von Richtlinien-Tag und Datenrichtlinie.
Sie haben eine Tabellenspalte, die mit dem Richtlinien-Tag Financial annotiert ist, und einen Nutzer, der Mitglied der Gruppen ftes@example.com und analysts@example.com ist. Wenn dieser Nutzer eine Abfrage ausführt, die die annotierte Spalte enthält, wird sein Zugriff durch die in der Richtlinien-Tag-Taxonomie definierte Hierarchie bestimmt. Da dem Nutzer die Rolle "Data Catalog: Detaillierter Lesezugriff" durch das Richtlinien-Tag Financial zugewiesen ist, gibt die Abfrage nicht maskierte Spaltendaten zurück.
Wenn ein anderer Nutzer, der nur Mitglied der Rolle „ftes@example.com” ist, eine Abfrage ausführt, die die annotierte Spalte enthält, gibt die Abfrage Spaltendaten zurück, die mit dem SHA-256-Algorithmus gehasht wurden. Dies liegt daran, dass dem Nutzer vom Richtlinien-Tag Confidential, das dem Richtlinien-Tag Financial übergeordnet ist, die Rolle „BigQuery: Maskierter Leser” gewährt wird.
Ein Nutzer, der kein Mitglied einer dieser Rollen ist, erhält einen "Zugriff verweigert"-Fehler, wenn er versucht, die annotierte Spalte abzufragen.
Betrachten wir im Gegensatz zum vorherigen Szenario das Richtlinien-Tag und die Datenrichtlinienkonfiguration in Abbildung 5:
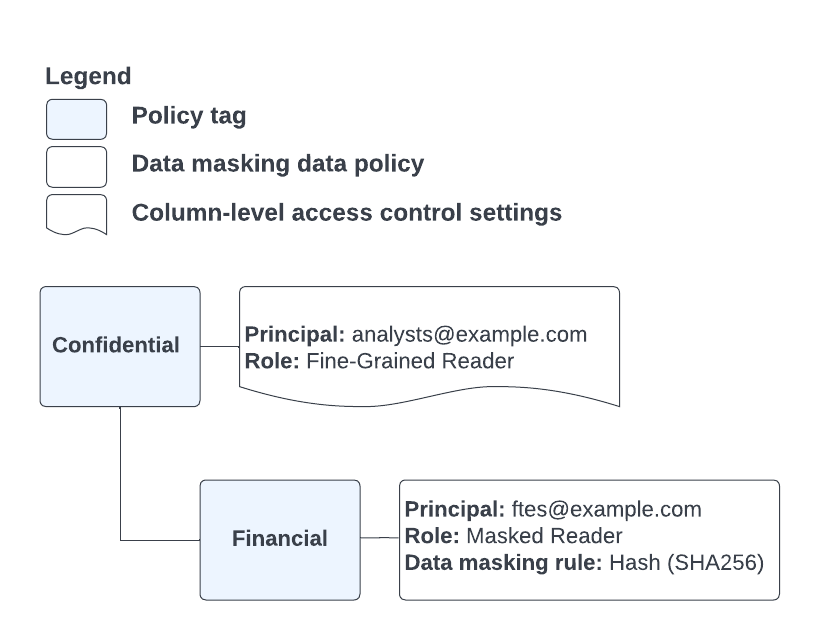
Abbildung 5. Konfiguration von Richtlinien-Tag und Datenrichtlinie.
Wir haben hier dieselbe Situation wie in Abbildung 4, aber dem Nutzer wird die Rolle "Detaillierter Lesezugriff" auf einer höheren und die Rolle "Maskierter Leser" auf einer niedrigeren Ebene der Richtlinien-Tag-Hierarchie zugewiesen. Aus diesem Grund gibt die Abfrage maskierte Spaltendaten für diesen Nutzer zurück. Dies passiert auch, wenn dem Nutzer die Rolle "Detaillierter Lesezugriff" weiter oben in der Tag-Hierarchie zugewiesen wurde, da der Dienst die erste zugewiesene Rolle verwendet, der er auf dem Weg durch die Richtlinien-Tag-Hierarchie für den zu prüfenden Nutzerzugriff begegnet.
Wenn Sie eine einzelne Datenrichtlinie erstellen und auf mehrere Ebenen einer Richtlinien-Tag-Hierarchie anwenden möchten, können Sie sie für das Richtlinien-Tag festlegen, das die oberste Hierarchieebene darstellt, auf die sie angewendet werden soll. Nehmen wir als Beispiel eine Taxonomie mit folgender Struktur:
- Richtlinien-Tag 1
- Richtlinien-Tag 1a
- Richtlinien-Tag 1ai
- Richtlinien-Tag 1b
- Richtlinien-Tag 1bi
- Richtlinien-Tag 1bii
- Richtlinien-Tag 1a
Soll eine Datenrichtlinie auf alle diese Richtlinien-Tags angewendet werden, so legen Sie die Datenrichtlinie für das Richtlinien-Tag 1 fest. Wenn Sie eine Datenrichtlinie auf das Richtlinien-Tag 1b und dessen untergeordnete Elemente anwenden möchten, legen Sie die Datenrichtlinie für das Richtlinien-Tag 1b fest.
Datenmaskierung mit inkompatiblen Funktionen
Wenn Sie BigQuery-Features verwenden, die nicht mit der Datenmaskierung kompatibel sind, behandelt der Dienst die maskierte Spalte als gesicherte Spalte und gewährt nur Nutzern mit der Rolle "Data Catalog: Detaillierter Lesezugriff" Zugriff.
Nehmen wir zum Beispiel das Richtlinien-Tag und die Datenrichtlinienkonfiguration in Abbildung 6:
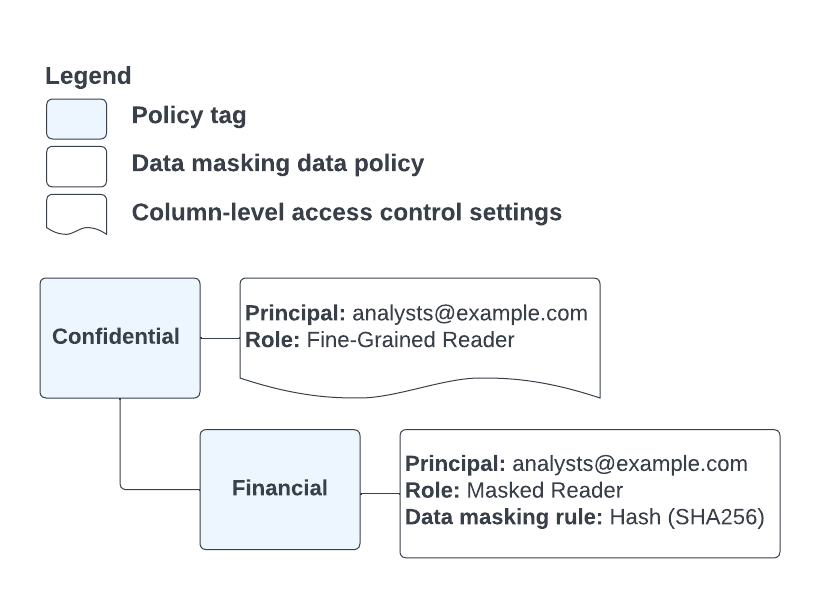
Abbildung 6. Konfiguration von Richtlinien-Tag und Datenrichtlinie.
Sie haben eine Tabellenspalte, die mit dem Richtlinien-Tag Financial annotiert ist, und einen Nutzer, der Mitglied der Gruppe analysts@example.com ist. Versucht dieser Nutzer, über eines der inkompatiblen Features auf die annotierte Spalte zuzugreifen, wird ein "Zugriff verweigert"-Fehler ausgegeben. Dies liegt daran, dass dem Nutzer durch den Richtlinien-Tag Financial die Rolle "BigQuery: Maskierter Leser" zugewiesen ist. In diesem Fall wäre jedoch die Rolle "Data Catalog: Detaillierter Lesezugriff" erforderlich.
Da der Dienst bereits eine anwendbare Rolle für den Nutzer ermittelt hat, wird die Richtlinien-Tag-Hierarchie nicht weiter auf zusätzliche Berechtigungen geprüft.
Beispiel: Datenmaskierung mit Ausgabe
Sehen Sie sich dieses Beispiel an, um zu sehen, wie Tags, Hauptkonten und Rollen zusammenarbeiten.
Auf example.com wird der grundlegende Zugriff über die Gruppe data-users@example.com gewährt. Alle Mitarbeiter, die regulären Zugriff auf BigQuery-Daten benötigen, sind Mitglieder dieser Gruppe. Diese hat alle erforderlichen Berechtigungen zum Lesen aus Tabellen sowie die Rolle "BigQuery: Maskierter Leser".
Mitarbeiter werden zusätzlichen Gruppen zugewiesen, die Zugriff auf gesicherte oder maskierte Spalten gewähren, sofern dies für ihre Arbeit erforderlich ist. Alle Mitglieder dieser zusätzlichen Gruppen sind auch Mitglieder von data-users@example.com. In Abbildung 7 sehen Sie, wie diese Gruppen den entsprechenden Rollen zugeordnet sind:
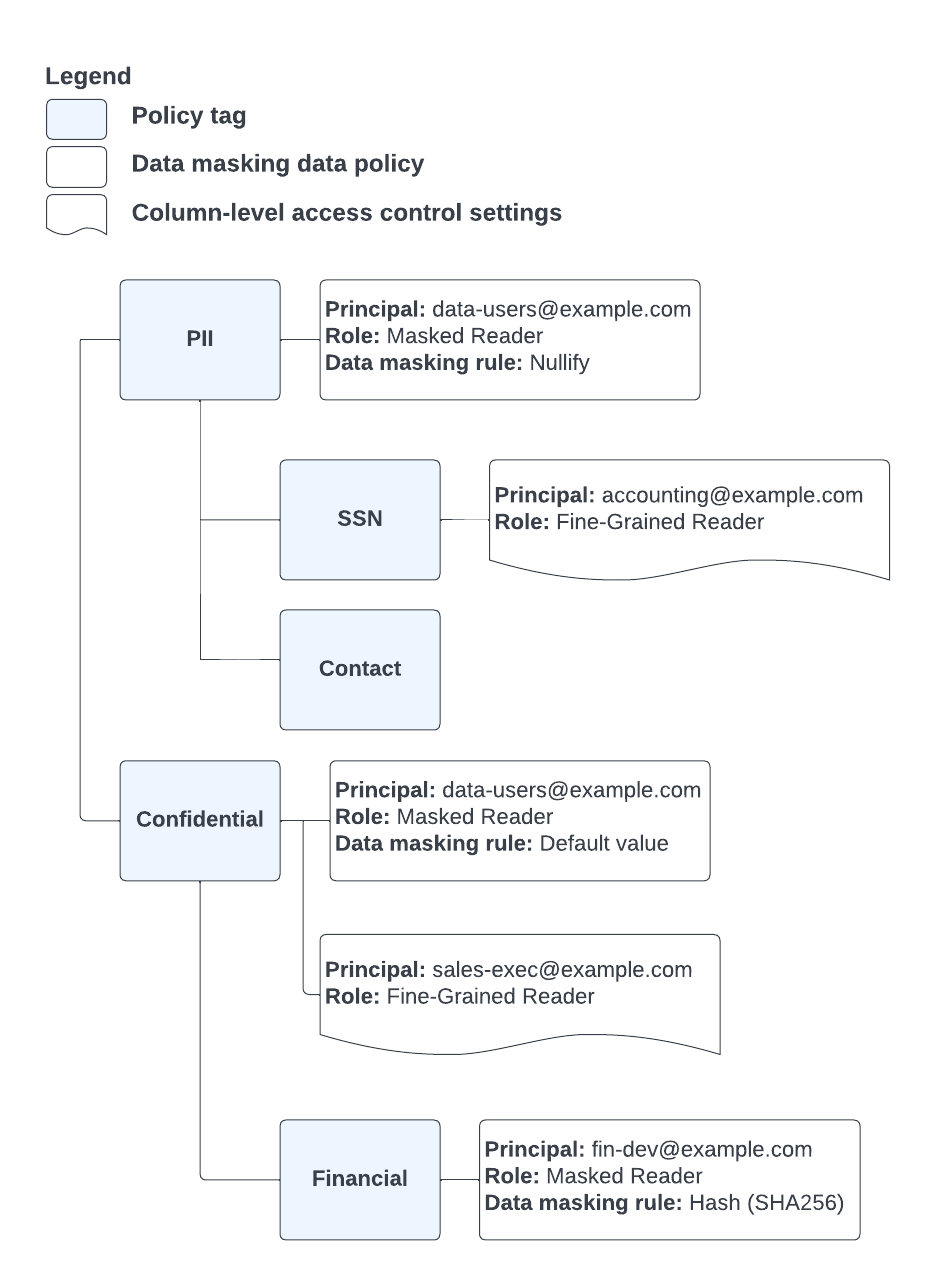
Abbildung 7. Richtlinien-Tags und Datenrichtlinien für example.com.
Die Richtlinien-Tags werden dann mit Tabellenspalten verknüpft, wie in Abbildung 8 dargestellt:
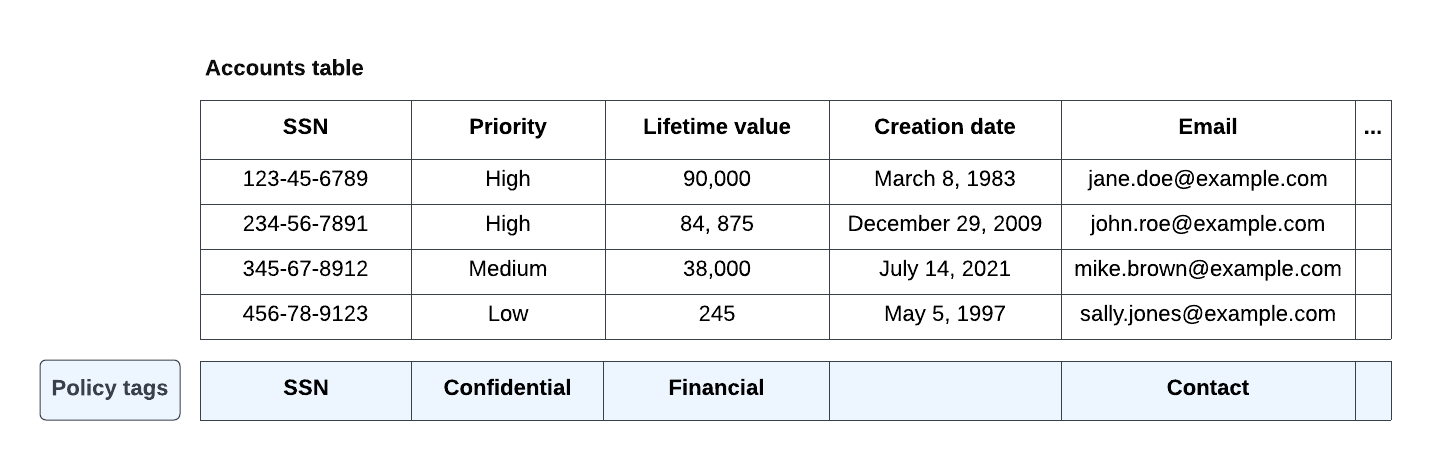
Abbildung 8. Tabellenspalten zugeordnete example.com-Richtlinien-Tags.
Abhängig von den Tags, die mit den Spalten verknüpft sind, führt SELECT * FROM Accounts; für die verschiedenen Gruppen zu folgenden Ergebnissen:
data-users@example.com: Diese Gruppe hat die Rolle "BigQuery: Maskierter Leser" für die Richtlinien-Tags
PIIundConfidential. Die folgenden Ergebnisse werden zurückgegeben:SSN Priorität Lifetime-Wert Erstellungsdatum E-Mail NULL "" 0 8. März 1983 NULL NULL "" 0 29. Dezember 2009 NULL NULL "" 0 14. Juli 2021 NULL NULL "" 0 5. Mai 1997 NULL accounting@example.com: Dieser Gruppe wurde die Rolle "Data Catalog: Detaillierter Lesezugriff" für das Richtlinien-Tag
SSNzugewiesen. Die folgenden Ergebnisse werden zurückgegeben:SSN Priorität Lifetime-Wert Erstellungsdatum NULL 123-45-6789 "" 0 8. März 1983 NULL 234-56-7891 "" 0 29. Dezember 2009 NULL 345-67-8912 "" 0 14. Juli 2021 NULL 456-78-9123 "" 0 5. Mai 1997 NULL sales-exec@example.com: Dieser Gruppe wurde die Rolle "Data Catalog: Detaillierter Lesezugriff" für das Richtlinien-Tag
Confidentialzugewiesen. Die folgenden Ergebnisse werden zurückgegeben:SSN Priorität Lifetime-Wert Erstellungsdatum E-Mail NULL Hoch 90.000 8. März 1983 NULL NULL Hoch 84.875 29. Dezember 2009 NULL NULL Mittel 38.000 14. Juli 2021 NULL NULL Niedrig 245 5. Mai 1997 NULL fin-dev@example.com: Diese Gruppe hat die Rolle "BigQuery: Maskierter Leser" für das Richtlinien-Tag
Financialerhalten. Die folgenden Ergebnisse werden zurückgegeben:SSN Priorität Lifetime-Wert Erstellungsdatum E-Mail NULL "" Zmy9vydG5q= 8. März 1983 NULL NULL "" GhwTwq6Ynm= 29. Dezember 2009 NULL NULL "" B6y7dsgaT9= 14. Juli 2021 NULL NULL "" Uh02hnR1sg= 5. Mai 1997 NULL Alle anderen Nutzer: Jeder Nutzer, der keiner der aufgeführten Gruppen angehört, erhält einen "Zugriff verweigert"-Fehler, da solchen Nutzern weder die Rolle "Data Catalog: Detaillierter Lesezugriff" noch die Rolle "BigQuery: Maskierter Leser" zugewiesen wurde. Zum Abfragen der
Accounts-Tabelle dürfen sie nur Spalten angeben, auf die sie in derSELECT * EXCEPT (restricted_columns) FROM AccountsZugriff haben, um gesicherte oder maskierte Spalten auszuschließen.
Kostengesichtspunkte
Die Datenmaskierung kann sich indirekt auf die Anzahl der verarbeiteten Byte auswirken und daher die Kosten der Abfrage beeinflussen. Wenn ein Nutzer eine Spalte abfragt, die für ihn mit den Regeln "Auf null setzen" oder "Standardmaskierungswert" maskiert ist, wird diese Spalte nicht gescannt, was weniger verarbeitete Byte bedeutet.
Limits und Einschränkungen
In den folgenden Abschnitten werden die Limits und Einschränkungen beschrieben, denen die Datenmaskierung unterliegt.
Datenrichtlinienverwaltung
- Dieses Feature ist möglicherweise nicht verfügbar, wenn Sie Reservierungen verwenden, die mit bestimmten BigQuery-Editionen erstellt wurden. Weitere Informationen dazu, welche Features in den einzelnen Editionen aktiviert sind, finden Sie unter Einführung in BigQuery-Editionen.
- Sie können bis zu neun Datenrichtlinien für jedes Richtlinien-Tag erstellen. Eine dieser Richtlinien ist für die Einstellungen für die Zugriffssteuerung auf Spaltenebene reserviert.
- Datenrichtlinien, die zugehörigen Richtlinien-Tags und alle Routinen, in denen sie verwendet werden, müssen sich im selben Projekt befinden.
Richtlinien-Tags
- Das Projekt, das die Taxonomie mit den Richtlinien-Tags enthält, muss zu einer Organisation gehören.
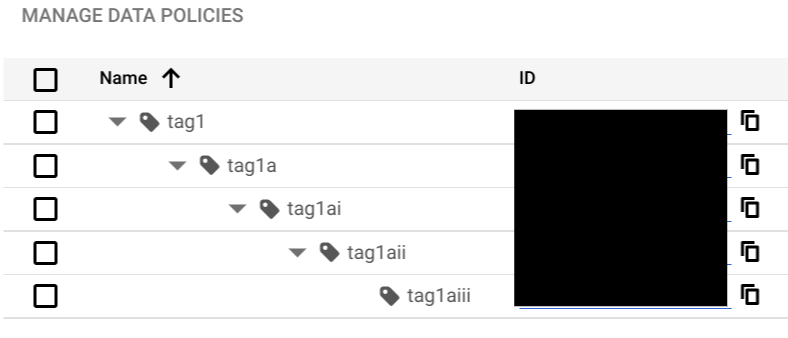
Eine Richtlinien-Tag-Hierarchie darf nicht mehr als fünf Ebenen vom Stammknoten bis zum untersten Untertag tief sein, wie im folgenden Screenshot dargestellt:
Zugriffssteuerung einrichten
Nachdem einer Taxonomie eine Datenrichtlinie mit mindestens einem Richtlinien-Tag zugeordnet wurde, wird die Zugriffssteuerung automatisch erzwungen. Um die Zugriffssteuerung zu deaktivieren, müssen Sie zuerst alle Datenrichtlinien löschen, die mit der Taxonomie verknüpft sind.
Materialisierte Ansichten und wiederholte Abfragen zur Datensatzmaskierung
Wenn Sie bereits materialisierte Ansichten haben, schlagen wiederholte Abfragen zur Datensatzmaskierung in der zugehörigen Basistabelle fehl. Löschen Sie die materialisierte Ansicht, um dieses Problem zu beheben. Wenn die materialisierte Ansicht aus anderen Gründen benötigt wird, können Sie sie in einem anderen Dataset erstellen.
Maskierte Spalten in partitionierten Tabellen abfragen
Abfragen mit Datenmaskierung für die partitionierten oder geclusterten Spalten werden nicht unterstützt.
SQL-Dialekte
Legacy-SQL wird nicht unterstützt.
Benutzerdefinierte Maskierungsroutinen
Für benutzerdefinierte Maskierungsroutinen gelten die folgenden Einschränkungen:
- Die benutzerdefinierte Datenmaskierung unterstützt alle BigQuery-Datentypen außer
STRUCT, da die Datenmaskierung nur auf Blattfelder des DatentypsSTRUCTangewendet werden kann. - Durch das Löschen einer benutzerdefinierten Maskierungsroutine werden nicht alle Datenrichtlinien gelöscht, die sie verwenden. Die Datenrichtlinien, die die gelöschte Maskierungsroutine verwenden, bleiben jedoch mit einer leeren Maskierungsregel erhalten. Nutzer mit der Rolle „Maskierter Leser“ für andere Datenrichtlinien mit demselben Tag können maskierte Daten sehen. Andere Nutzer sehen die Nachricht
Permission denied.Defekte Verweise auf leere Maskierungsregeln können durch automatisierte Prozesse nach sieben Tagen bereinigt werden.
Kompatibilität mit anderen BigQuery-Features
BigQuery API
Nicht mit der tabledata.list-Methode kompatibel. Wenn Sie tabledata.list aufrufen möchten, benötigen Sie vollen Zugriff auf alle Spalten, die von dieser Methode zurückgegeben werden. Die Rolle "Data Catalog: Detaillierter Lesezugriff" gewährt den erforderlichen Zugriff.
BigLake-Tabellen
Kompatibel. Richtlinien zur Datenmaskierung werden für BigLake-Tabellen erzwungen.
BigQuery Storage Read API
Kompatibel. Richtlinien zur Datenmaskierung werden in der BigQuery Storage Read API erzwungen.
BigQuery BI Engine
Kompatibel. Richtlinien zur Datenmaskierung werden in der BI Engine erzwungen. Abfragen, für die die Datenmaskierung aktiviert ist, werden nicht von BI Engine beschleunigt. Die Nutzung solcher Abfragen in Looker Studio kann dazu führen, dass zugehörige Berichte oder Dashboards langsamer und teurer werden.
BigQuery Omni
Kompatibel. Richtlinien zur Datenmaskierung werden für BigQuery Omni-Tabellen erzwungen.
Sortierung
Teilweise kompatibel. Sie können DDM auf zusammengeführte Spalten anwenden, die Maskierung erfolgt jedoch vor der Zusammenführung. Diese Reihenfolge der Vorgänge kann zu unerwarteten Ergebnissen führen, da die Sortierung die maskierten Werte möglicherweise nicht wie vorgesehen beeinflusst. So funktioniert beispielsweise der Abgleich ohne Berücksichtigung der Groß-/Kleinschreibung nach der Maskierung möglicherweise nicht. Es sind Workarounds möglich, z. B. die Verwendung benutzerdefinierter Maskierungsroutinen, die Daten normalisieren, bevor die Maskierungsfunktion angewendet wird.
Kopierjobs
Nicht kompatibel. Wenn Sie eine Tabelle von der Quelle an das Ziel kopieren möchten, benötigen Sie uneingeschränkten Zugriff auf alle Spalten in der Quelltabelle. Die Rolle "Data Catalog: Detaillierter Lesezugriff" gewährt den erforderlichen Zugriff.
Datenexport
Kompatibel. Wenn Sie die Rolle "BigQuery: Maskierter Leser" haben, werden die exportierten Daten maskiert. Wenn Sie die Rolle "Data Catalog: Detaillierter Lesezugriff" haben, werden die exportierten Daten nicht maskiert.
Sicherheit auf Zeilenebene
Kompatibel. Die Datenmaskierung wird zusätzlich zur Sicherheit auf Zeilenebene angewendet. Beispiel: Wenn eine Zeilenzugriffsrichtlinie auf location = "US" angewendet wird und location maskiert ist, können Nutzer Zeilen sehen, in denen location = "US", aber das Standortfeld ist maskiert.
In BigQuery suchen
Teilweise kompatibel. Sie können die SEARCH-Funktion für indexierte oder nicht indexierte Spalten aufrufen, auf die die Datenmaskierung angewendet wurde.
Wenn Sie die SEARCH-Funktion für Spalten aufrufen, auf die die Datenmaskierung angewendet wurde, müssen Sie Suchkriterien verwenden, die mit Ihrer Zugriffsebene kompatibel sind. Wenn Sie beispielsweise den „Maskierter Leser”-Zugriff mit einer Hashregel (SHA-256) für die Datenmaskierung haben, verwenden Sie den Hashwert in Ihrer SEARCH-Klausel. Beispiel:
SELECT * FROM myDataset.Customers WHERE SEARCH(Email, "sg172y34shw94fujaweu");
Wenn Sie detaillierten Lesezugriff haben, verwenden Sie den tatsächlichen Spaltenwert in Ihrer SEARCH-Klausel. Beispiel:
SELECT * FROM myDataset.Customers WHERE SEARCH(Email, "jane.doe@example.com");
Eine Suche ist weniger nützlich, wenn Sie "Maskierter Leser"-Zugriff auf eine Spalte haben, in der die verwendete Datenmaskierungsregel "Auf null setzen" oder "Standardmaskierungswert" ist. Dies liegt daran, dass die maskierten Ergebnisse, die Sie als Suchkriterien verwenden würden, (z. B. NULL oder "") nicht ausreichend klar sind, um nützlich zu sein.
Bei der Suche in einer indexierten Spalte, auf die die Datenmaskierung angewendet wurde, wird der Suchindex nur verwendet, wenn Sie detaillierten Lesezugriff auf die Spalte haben.
Snapshots
Nicht kompatibel. Wenn Sie einen Snapshot einer Tabelle erstellen möchten, benötigen Sie uneingeschränkten Zugriff auf alle Spalten in der Quelltabelle. Die Rolle "Data Catalog: Detaillierter Lesezugriff" gewährt den erforderlichen Zugriff.
Tabelle umbenennen
Kompatibel. Das Umbenennen von Tabellen wird durch die Datenmaskierung nicht beeinträchtigt.
Zeitreise
Kompatibel mit Zeit-Decorators und der Option FOR SYSTEM_TIME AS OF in SELECT-Anweisungen. Die Richtlinien-Tags für das aktuelle Dataset-Schema werden auf die abgerufenen Daten angewendet.
Abfrage-Caching
Teilweise kompatibel. BigQuery speichert Abfrageergebnisse im Cache etwa 24 Stunden lang, wobei der Cache ungültig wird, wenn zuvor Änderungen an den Tabellendaten oder dem Schema vorgenommen werden. Unter folgenden Umständen ist es möglich, dass ein Nutzer, der nicht die Rolle "Data Catalog: Detaillierter Lesezugriff" für eine Spalte hat, die Spaltendaten beim Ausführen einer Abfrage dennoch sehen kann:
- Einem Nutzer wurde die Rolle "Data Catalog: Detaillierter Lesezugriff" für eine Spalte zugewiesen.
- Der Nutzer führt eine Abfrage aus, die die eingeschränkte Spalte enthält, und die Daten sind im Cache gespeichert.
- Innerhalb von 24 Stunden nach Schritt 2 wird dem Nutzer die Rolle "BigQuery: Maskierter Leser" zugewiesen und die Rolle "Data Catalog: Detaillierter Lesezugriff" wird widerrufen.
- Innerhalb von 24 Stunden nach Schritt 2 führt der Nutzer dieselbe Abfrage aus; es werden die im Cache gespeicherten Daten zurückgegeben.
Platzhaltertabellenabfragen
Nicht kompatibel. Sie benötigen vollen Zugriff auf alle referenzierten Spalten in allen Tabellen, die der Platzhalterabfrage entsprechen. Die Rolle "Data Catalog: Detaillierter Lesezugriff" gewährt den erforderlichen Zugriff.
Nächste Schritte
- Schritt-für-Schritt-Anleitung zum Aktivieren der Datenmaskierung.