Einführung in geclusterte Tabellen
Geclusterte Tabellen sind in BigQuery Tabellen, die eine benutzerdefinierte Sortierreihenfolge für Spalten haben und geclusterte Spalten nutzen. Geclusterte Tabellen können die Abfrageleistung verbessern und die Abfragekosten reduzieren.
In BigQuery ist eine geclusterte Spalte ein benutzerdefiniertes Tabellenattribut, das Speicherblöcke auf Basis der Werte in den geclusterten Spalten sortiert. Die Größe der Speicherblöcke wird an die Größe der Tabelle angepasst. Die Colocation erfolgt auf Ebene der Speicherblöcke und nicht auf Ebene der einzelnen Zeilen. Weitere Informationen zur Colocation in diesem Zusammenhang finden Sie unter Clustering.
Eine geclusterte Tabelle verwaltet die Sortiereigenschaften im Kontext jedes Vorgangs, der sie ändert. Bei Abfragen, die nach geclusterten Spalten filtern oder aggregieren, werden nur die relevanten Blöcke anhand der geclusterten Spalten anstelle der gesamten Tabelle oder Tabellenpartition gescannt. Daher ist BigQuery möglicherweise nicht in der Lage, die von der Abfrage zu verarbeitenden Byte oder die Abfragekosten genau zu schätzen. Es wird jedoch versuchen, die Gesamtzahl der Byte bei der Ausführung zu reduzieren.
Wenn Sie eine Tabelle mit mehreren Spalten clustern, bestimmt die Spaltenreihenfolge, welche Spalten Vorrang haben, wenn BigQuery die Daten sortiert und in Speicherblöcken gruppiert, wie im folgenden Beispiel dargestellt. Tabelle 1 zeigt das logische Layout des Speicherblocks einer nicht geclusterten Tabelle. Im Vergleich dazu ist Tabelle 2 nur nach der Spalte Country geclustert, während Tabelle 3 nach mehreren Spalten, Country und Status, geclustert ist.
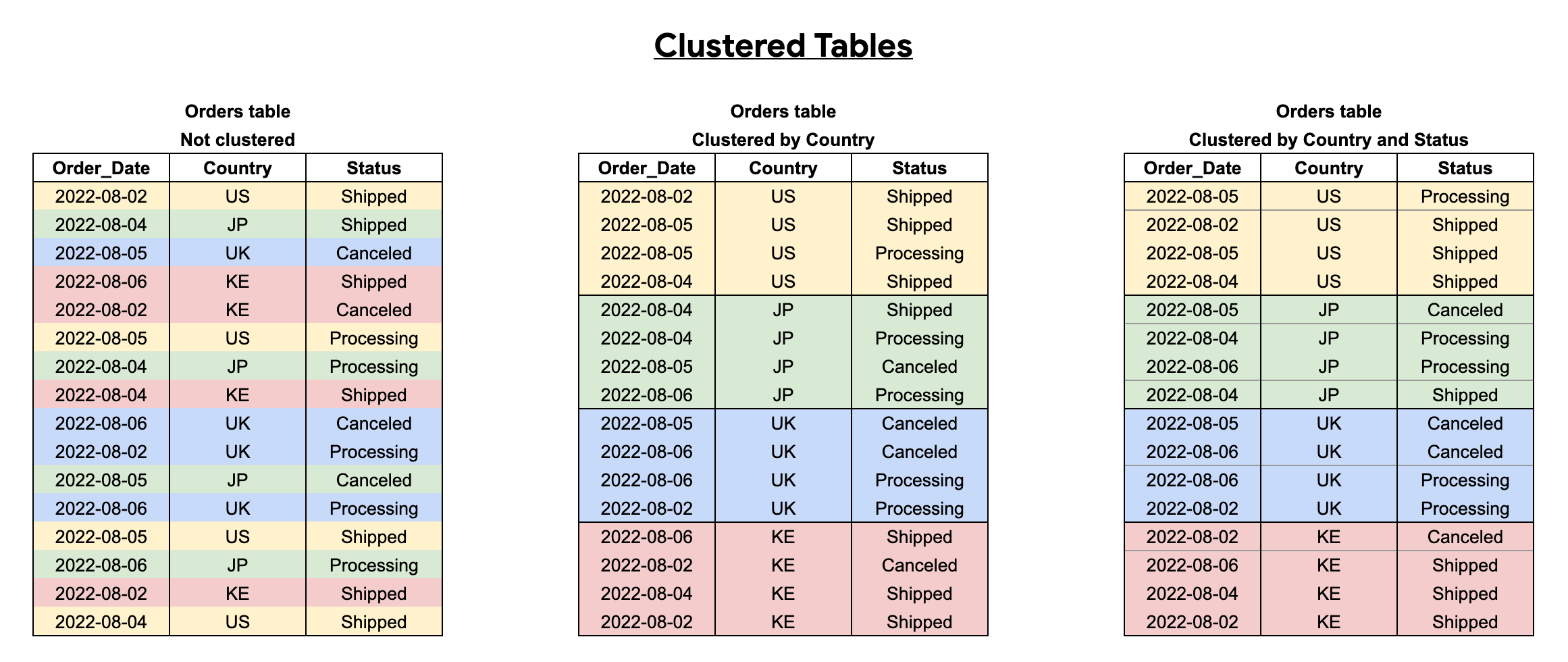
Wenn Sie eine geclusterte Tabelle abfragen, erhalten Sie vor der Abfrageausführung keine genaue Schätzung der Abfragekosten, da die Anzahl der zu scannenden Speicherblöcke vor der Abfrageausführung nicht bekannt ist. Die endgültigen Kosten werden nach Abschluss der Abfrageausführung ermittelt und basieren auf den spezifischen Speicherblöcken, die gescannt wurden.
Wann sollte Clustering verwendet werden?
Clustering befasst sich mit der Art und Weise, wie eine Tabelle gespeichert wird, und ist daher im Allgemeinen eine gute erste Option zur Verbesserung der Abfrageleistung. Daher sollten Sie immer das Clustering in Betracht ziehen, da es folgende Vorteile bietet:
- Nicht partitionierte Tabellen, die größer als 64 MB sind, profitieren wahrscheinlich vom Clustering. Ebenso profitieren Tabellenpartitionen mit einer Größe von über 64 MB wahrscheinlich vom Clustering. Das Clustering kleinerer Tabellen oder Partitionen ist möglich, die Leistungsverbesserung ist jedoch in der Regel vernachlässigbar.
- Wenn Ihre Abfragen häufig nach bestimmten Spalten filtern, beschleunigt das Clustering Abfragen, da die Abfrage nur die Blöcke scannt, die dem Filter entsprechen.
- Wenn Ihre Abfragen nach Spalten mit vielen unterschiedlichen Werten filtern (hohe Kardinalität), beschleunigt das Clustering diese Abfragen, indem BigQuery detaillierte Metadaten enthält, wo Eingabedaten abgerufen werden können.
- Mit Clustering kann die Größe der zugrunde liegenden Speicherblöcke der Tabelle an die Tabellengröße angepasst werden.
Sie können Ihre Tabelle zusätzlich zum Clustering partitionieren. Bei diesem Ansatz segmentieren Sie die Daten zuerst in Partitionen und gruppieren dann die Daten innerhalb jeder Partition nach den Clustering-Spalten. Ziehen Sie diesen Ansatz unter den folgenden Umständen in Betracht:
- Sie benötigen eine genaue Schätzung der Abfragekosten, bevor Sie eine Abfrage ausführen. Die Kosten für Abfragen von geclusterten Tabellen können erst nach der Ausführung der Abfrage ermittelt werden. Die Partitionierung bietet detaillierte Schätzungen der Abfragekosten, bevor Sie eine Abfrage ausführen.
- Die Partitionierung führt zu einer durchschnittlichen Partitionsgröße von mindestens 10 GB pro Partition. Durch das Erstellen vieler kleiner Partitionen werden die Metadaten der Tabelle vergrößert, was sich auf die Zugriffszeiten auf die Metadaten bei Abfragen der Tabelle auswirken kann.
- Sie müssen Ihre Tabelle kontinuierlich aktualisieren, möchten aber dennoch die Vorteile der Preise für langfristige Speicherung nutzen. Die Partitionierung ermöglicht es, dass jede Partition separat für die Berechtigung zu Langfristpreisen betrachtet werden kann. Wenn Ihre Tabelle nicht partitioniert ist, darf Ihre gesamte Tabelle 90 aufeinanderfolgende Tage lang nicht bearbeitet werden, damit sie für langfristige Preise in Betracht gezogen werden kann.
Weitere Informationen finden Sie unter Geclusterte und partitionierte Tabellen kombinieren.
Clusterspaltentypen und -reihenfolge
In diesem Abschnitt werden die Spaltentypen und die Funktionsweise der Spaltenreihenfolge beim Tabellen-Clustering beschrieben.
Clusterspaltentypen
Clusterspalten müssen Spalten der obersten Ebene sein, die nicht wiederholt werden. Sie müssen einem der folgenden Datentypen entsprechen:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
Weitere Informationen zu Datentypen finden Sie unter GoogleSQL-Datentypen.
Reihenfolge der Clusterspalten
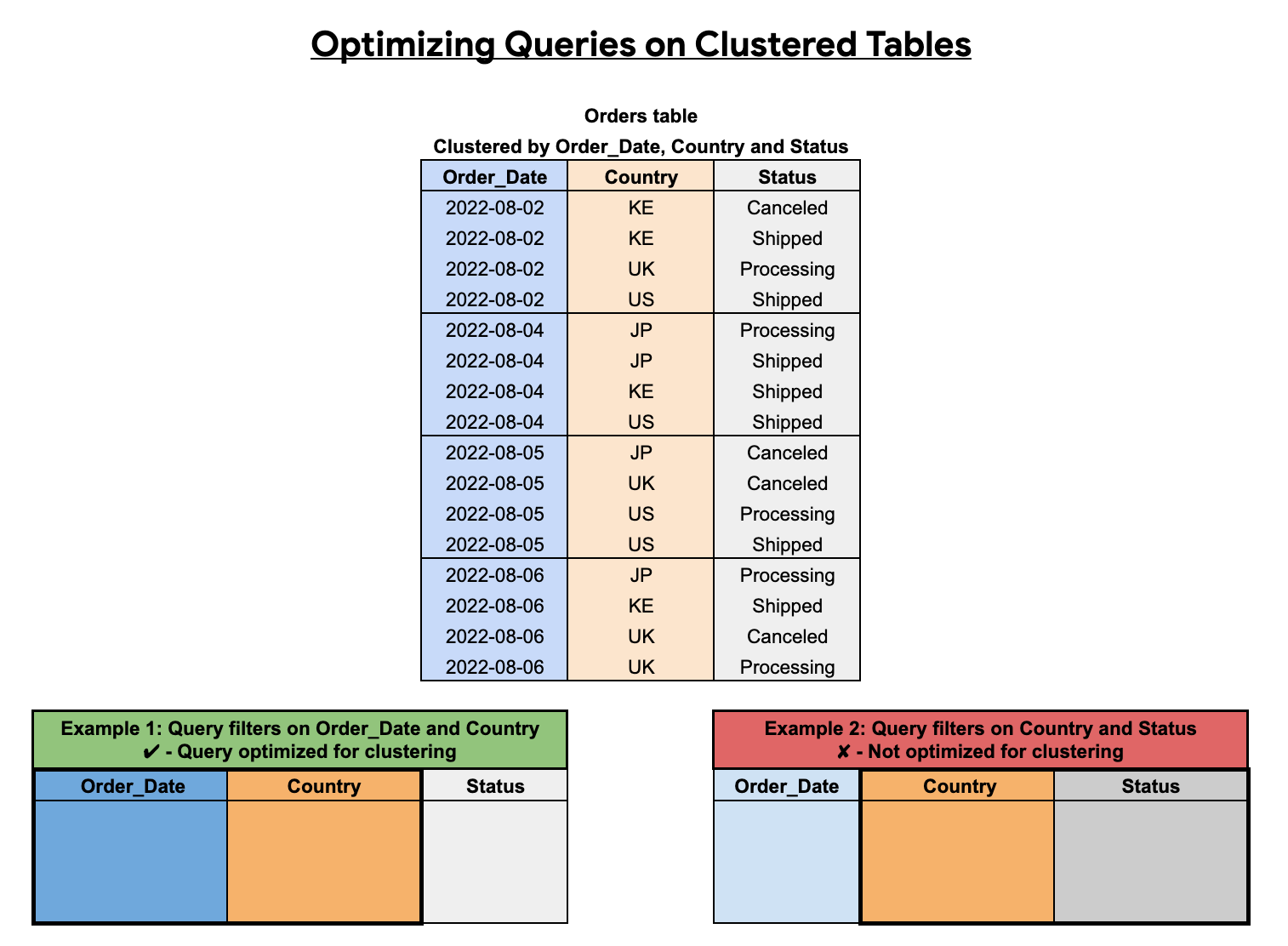
Die Reihenfolge der geclusterten Spalten wirkt sich auf die Abfrageleistung aus. Im folgenden Beispiel wird die Tabelle Orders mithilfe der Spaltensortierreihenfolge Order_Date, Country und Status geclustert. Die erste geclusterte Spalte in diesem Beispiel ist Order_Date. Eine Abfrage, die nach Order_Date und Country filtert, ist für das Clustering optimiert. Eine Abfrage, die nur nach Country und Status filtert, ist dagegen nicht optimiert.
Blockbereinigung
Mit geclusterten Tabellen können Sie Ihre Abfragekosten reduzieren, weil darin Daten bereinigt werden, damit nicht alle Daten von der Abfrage verarbeitet werden. Dieser Prozess wird als Blockbereinigung bezeichnet. BigQuery sortiert die Daten in einer geclusterten Tabelle nach den Werten in den Clustering-Spalten und organisiert sie in Blöcken.
Wenn Sie eine Abfrage für eine geclusterte Tabelle ausführen und die Abfrage einen Filter für die geclusterten Spalten enthält, verwendet BigQuery den Filterausdruck und die Blockmetadaten, um die von der Abfrage gescannten Blöcke zu bereinigen. So kann BigQuery ausschließlich relevante Blöcke scannen.
Bereinigte Blöcke werden nicht gescannt. Nur die gescannten Blöcke werden zur Berechnung der von der Abfrage verarbeiteten Byte verwendet. Die Anzahl der Byte, die von einer Abfrage für eine geclusterte Tabelle verarbeitet werden, entspricht der Summe der gelesenen Byte in den einzelnen Spalten, auf die sich die Abfrage bezieht – und zwar in allen gescannten Blöcken.
Wenn sich eine Abfrage mit mehreren Filtern mehrmals auf dieselbe geclusterte Tabelle bezieht, berechnet BigQuery die gescannten Spalten in den entsprechenden Blöcken für jeden einzelnen Filter. Ein Beispiel für die Funktionsweise der Blockbereinigung finden Sie unter Beispiel.
Geclusterte und partitionierte Tabellen kombinieren
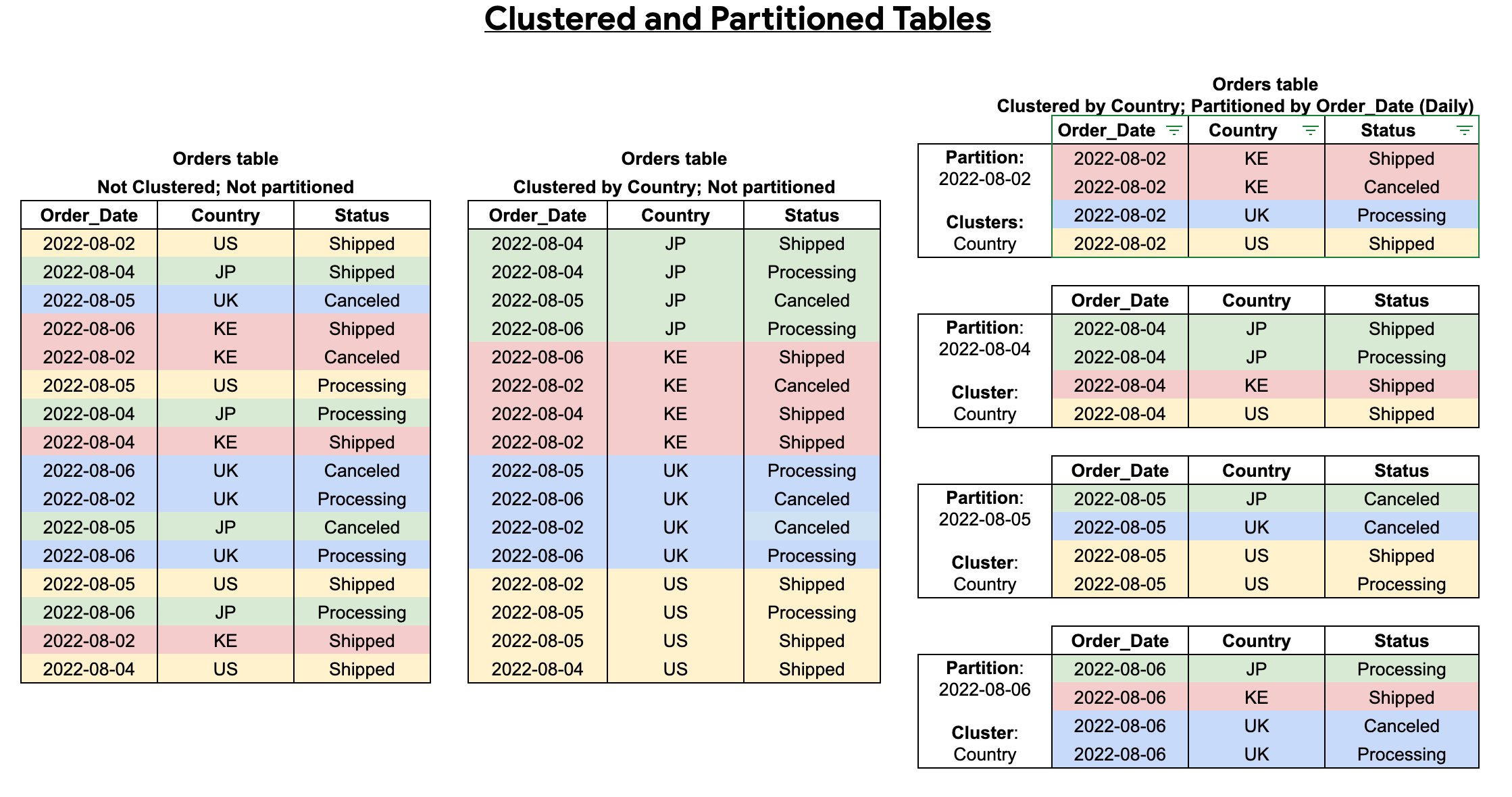
Sie können das Tabellen-Clustering mit der Tabellenpartitionierung kombinieren, um eine detaillierte Sortierung für die weitere Abfrageoptimierung zu erreichen.
In einer partitionierten Tabelle werden Daten in physischen Blöcken gespeichert, die jeweils eine Datenpartition enthalten. Die einzelnen partitionierten Tabellen verwalten verschiedene Metadaten zu den Sortiereigenschaften über alle Vorgänge hinweg, die sie ändern. Dank der Metadaten kann BigQuery die Abfragekosten genauer schätzen, bevor eine Abfrage ausgeführt wird. Bei der Partitionierung muss BigQuery jedoch mehr Metadaten verwalten als bei einer nicht partitionierten Tabelle. Mit zunehmender Anzahl der Partitionen erhöht sich die Menge der zu erhaltenden Metadaten.
Wenn Sie eine geclusterte und partitionierte Tabelle erstellen, so ermöglicht das eine genauere Sortierung, wie im folgenden Diagramm dargestellt:
Beispiel
Sie haben eine geclusterte Tabelle mit dem Namen ClusteredSalesData. Diese Tabelle ist nach der Spalte timestamp partitioniert und nach der Spalte customer_id geclustert. Die Daten sind in folgende Blöcke unterteilt:
| Partitionsbezeichner | Block-ID | Niedrigster Wert für customer_id im Block | Höchster Wert für customer_id im Block |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
Sie führen die folgende Abfrage für die Tabelle aus. Die Abfrage enthält einen Filter für die Spalte customer_id.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
Die vorherige Abfrage umfasst die folgenden Schritte:
- Sie scannt die Spalten
timestamp,customer_idundtotalSalein den Blöcken B2 und B4. - Sie bereinigt den Block B3 aufgrund des Filterprädikats
DATE(timestamp) = "2016-05-01"in der partitionierten Spaltetimestamp. - Sie bereinigt den Block B1 aufgrund des Filterprädikats
customer_id BETWEEN 20000 AND 23000in der Clustering-Spaltecustomer_id.
Automatisches Re-Clustering
Wenn Daten einer geclusterten Tabelle hinzugefügt werden, werden diese neuen Daten in Blöcken organisiert. Dadurch können neue Speicherblöcke erstellt oder vorhandene Blöcke aktualisiert werden. Die Blockoptimierung ist für eine optimale Abfrage- und Speicherleistung erforderlich, da neue Daten möglicherweise nicht mit vorhandenen Daten mit denselben Clusterwerten gruppiert sind.
BigQuery führt im Hintergrund ein automatisches Re-Clustering durch, um die Leistungsmerkmale geclusterter Tabellen beizubehalten. Bei partitionierten Tabellen wird das Clustering für Daten im Bereich jeder Partition beibehalten.
Beschränkungen
- Nur GoogleSQL wird zum Abfragen von geclusterten Tabellen und zum Schreiben von Abfrageergebnissen in geclusterte Tabellen unterstützt.
- Sie können nur bis zu vier Clustering-Spalten angeben. Wenn Sie zusätzliche Spalten benötigen, können Sie das Clustering mit der Partitionierung kombinieren.
- Wenn für das Clustering Spalten vom Typ
STRINGgenutzt werden, verwendet BigQuery nur die ersten 1.024 Zeichen, um die Daten zu clustern. Die Werte in den Spalten können jedoch aus mehr als 1.024 Zeichen bestehen. - Wenn Sie eine vorhandene nicht geclusterte Tabelle so ändern, dass sie geclustert wird, werden die vorhandenen Daten nicht automatisch geclustert. Nur neue Daten, die mit den geclusterten Spalten gespeichert werden, unterliegen einem automatischen Re-Clustering. Weitere Informationen zum Re-Clustern vorhandener Daten mithilfe einer
UPDATE-Anweisung finden Sie unter Clustering-Spezifikation ändern.
Kontingente und Beschränkungen geclusterter Tabellen
In BigQuery ist die Nutzung freigegebener Google Cloud Ressourcen durch Kontingente und Limits eingeschränkt, einschließlich Einschränkungen für bestimmte Tabellenvorgänge oder die Anzahl der innerhalb eines Tages auszuführenden Jobs.
Wenn Sie die Funktion für geclusterte Tabellen mit einer partitionierten Tabelle verwenden, unterliegen Sie den Beschränkungen für partitionierte Tabellen.
Kontingente und Beschränkungen gelten auch für die verschiedenen Arten von Jobs, die für geclusterte Tabellen ausgeführt werden können. Informationen zu den Jobkontingenten, die für Ihre Tabellen gelten, finden Sie unter Jobs unter „Kontingente und Limits“.
Preise für geclusterte Tabellen
Wenn Sie in BigQuery geclusterte Tabellen erstellen und verwenden, hängen die Kosten davon ab, welches Datenvolumen in den Tabellen gespeichert wird und welche Abfragen für die Daten ausgeführt werden. Weitere Informationen finden Sie unter Speicherpreise und Abfragepreise.
Wie andere BigQuery-Tabellenvorgänge nutzen geclusterte Tabellenvorgänge kostenlose BigQuery-Vorgänge, z. B. Batchladevorgänge, Tabellenkopien, automatisches Re-Clustering und Datenexport. Für diese Vorgänge gelten die BigQuery-Kontingente und -Limits. Weitere Informationen zu kostenlosen Vorgängen finden Sie unter Kostenlose Vorgänge.
Ein detailliertes Beispiel für die Preise geclusterter Tabellen finden Sie unter Speicher- und Abfragekosten schätzen.
Tabellensicherheit
Informationen zum Steuern des Zugriffs auf Tabellen in BigQuery finden Sie unter Zugriff auf Ressourcen mit IAM steuern.